ว่าสิ่งที่คิด มันจะ work หรือมีผู้ใช้งานหรือไม่ เพราะว่า แนวคิดที่คิดหรือทำมานั้น อาจจะเป็นเพียงสิ่งที่เราต้องการเองเท่านั้น !! ดังนั้นการลงทุนสร้างระบบจึงเรียบง่ายมาก ๆ คือเริ่มจาก Google Forms และ Google Sheets เท่านั้น (No Code ชัด ๆ) ไม่ต้องมาเสียเงินพัฒนา และดูแลหลังบ้านอะไร
Frontend = Google Forms
Database = Google Sheets
ตรงนี้เรียกว่า version 0
ต่อมาเพิ่มส่วนของ User Interface เข้ามา เพราะว่าข้อมูลเริ่มซับซ้อนขึ้น
เช่นข้อมูลเงินเดือน จากนั้นก็เพิ่ม API gateway และ AWS Lambda (serverless) เข้ามา เพื่อทำการตรวจสอบข้อมูล และ บันทึกข้อมูลไปยัง Google Sheets ต่อไป ส่วนนี้เรียกว่า version 1
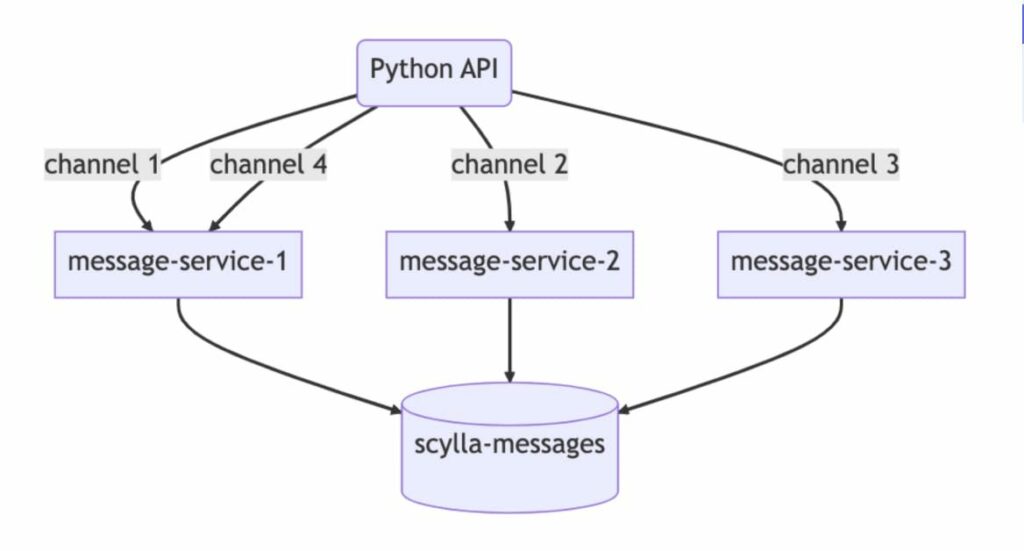
โดยทำการสร้าง API ใหม่ขึ้นมาเพื่อให้ทาง frontend เรียกใช้งาน ทำแบบค่อยเป็นค่อยไป จนย้ายทุกส่วนมายัง API ใหม่ ฝั่งของ API server พัฒนาด้วย Node.js ทำงานบนเครื่องเดียว สามารถรองรับผู้ใช้งาน 60K request ต่อชั่วโมง
จากบทความเรื่อง Law of Demeter (LoD) ในการเขียน code นั้น เพื่อช่วยลด coupling ระหว่าง class หรือเป็นแนวคิดที่ช่วยให้เรามีความรู้เกี่ยวกับปลายทางที่จะเรียกให้น้อยลง ทำให้มีอิสระมากยิ่งขึ้น
โดยถ้าเรานำแนวคิดนี้ มาใช้กับการแยก service ด้วย ก็น่าจะได้ผลดีเช่นกันนะ
ยกตัวอย่างเช่น
เรื่องแรก แต่ละ service ควรมีข้อมูลที่จะใช้เป็นของตัวเอง
ไม่ให้ใครมาใช้งานตรง ๆ หรือไม่ไปดึงข้อมูลจาก service มาใช้งานทุกครั้ง มองเป็นเรื่องของ local data ให้มากขึ้น ก็น่าจะช่วยเพิ่มความรวดเร็วในการทำงาน และเป็นอิสระจาก service อื่น ๆ มากขึ้น ทำให้ scale และ deploy ง่ายขึ้นอีก
เรื่องที่สอง ถ้าแต่ละ service ต้องใช้ข้อมูลจาก service อื่น ๆ ก็ควรมี interface ให้ใช้งาน
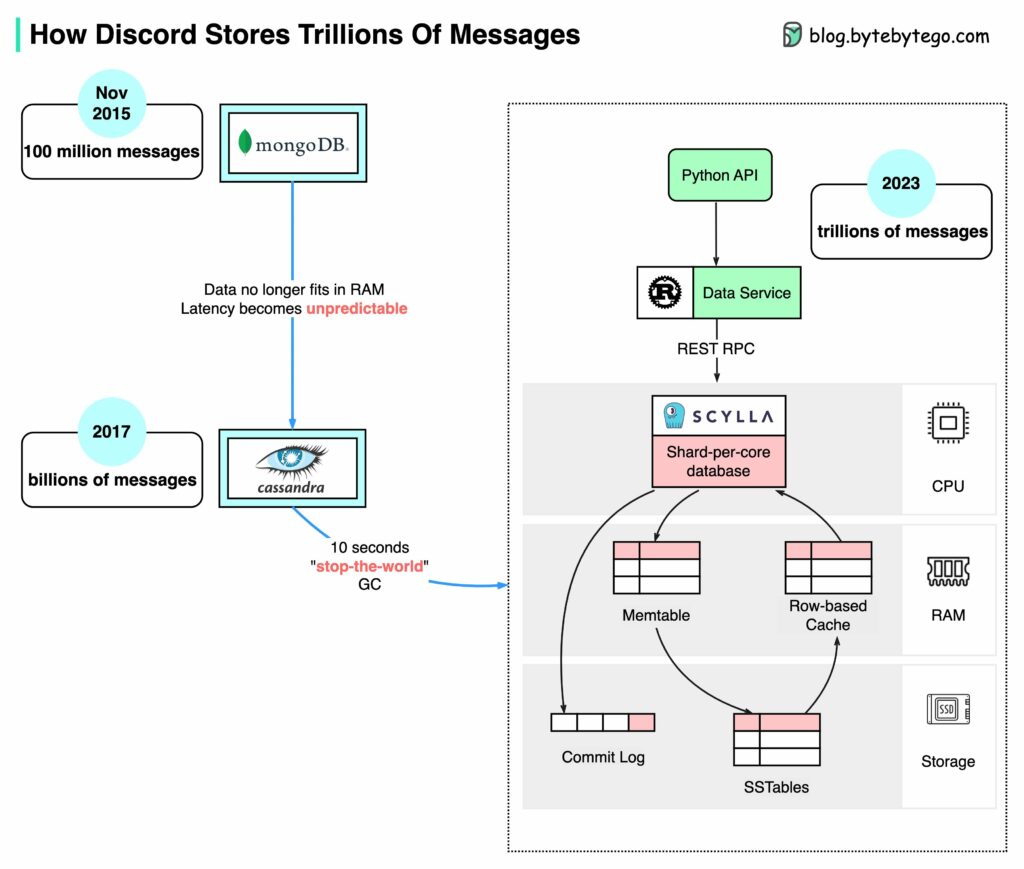
อ่านบทความเรื่อง Docker is deleting Open Source organisations - what you need to know ซึ่งทาง Docker ได้ส่ง email ถึง Docker Hub user ทุกคน ที่สร้างหรือใช้งาน organisation ว่าจะถูกลบ account และ image ทั้งหมด ถ้าไม่ทำการ upgrade plan ไปใช้ paid plan
ปล. ถ้าใช้แบบ personal จะไม่มีผลกระทบอะไร แต่ถ้าใครสร้าง organisation ขึ้นมาจะโดนหมด และส่วนใหญ่ที่ได้รับผลกระทบมาก ๆ คือ Open source community
คำถามจากการแบ่งปันการทดสอบระบบ web ด้วย Robot Framework และ SeleniumLibrary คือ ทำไม web browser มันปิดเองอัตโนมัติ หลังจากเมื่อทำการทดสอบเสร็จแล้ว ทั้ง Google Chrome และ Microsoft Edge
โดยใช้งาน library ดังนี้
robotframework 6.0
robotframework-seleniumlibrary 6.0
จากที่ไปอ่านเนื่องจากมีการเปลี่ยนแปลงที่ค่า setting นั่นเอง เพื่อไม่ให้เกิด process ของ webdriver ค้างในระบบ แต่ถ้าไม่ต้องการให้ปิด ก็สามารถใส่ option เข้าไปใน Open Browser ได้ดังนี้
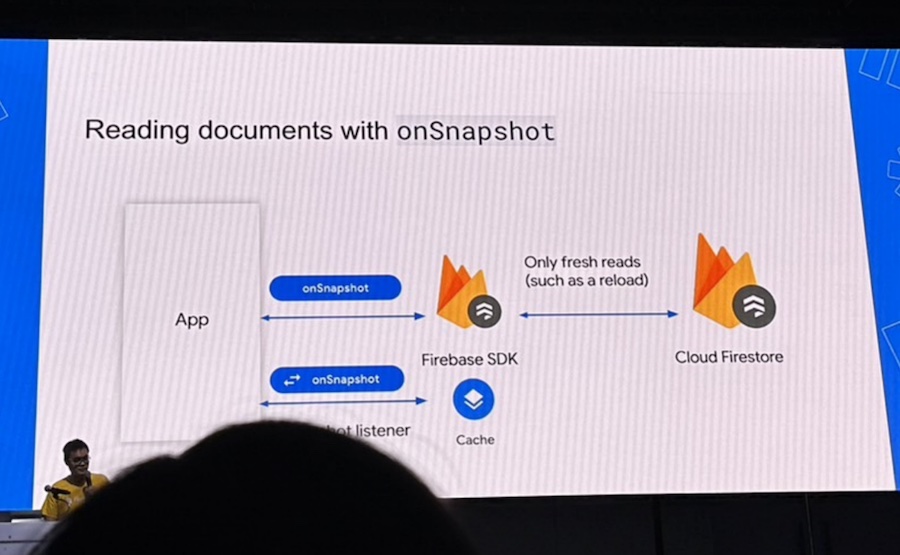
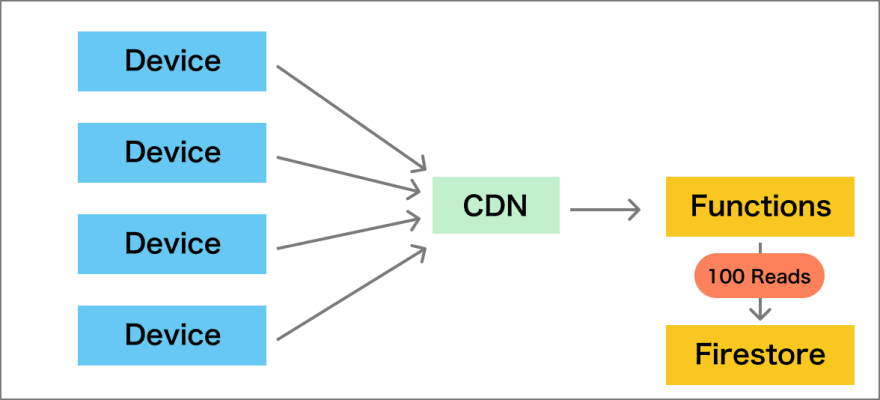
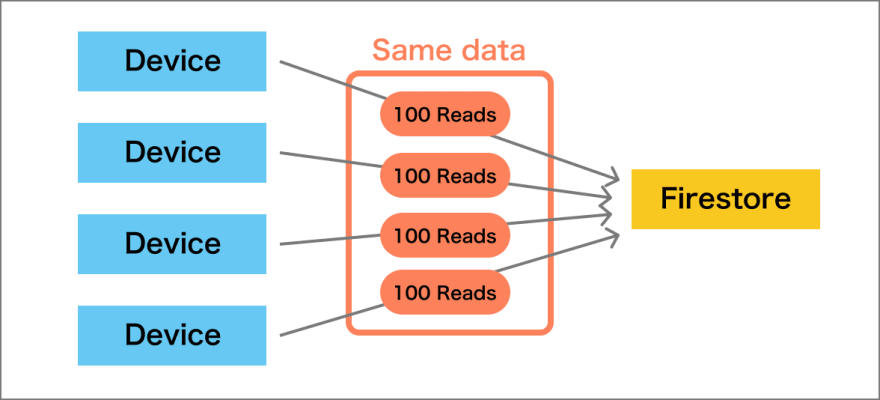
จากงาน Firebase Dev Day 2023 นั้น เข้ามาฟังเรื่อง Building a more Efficient Firestore Web App พอ เป็นเรื่องที่น่าสนใจมาก ๆ สำหรับการใช้งาน Firestore ใน web application ของเรา เน้นในเรื่องของการใช้งานให้ถูกต้องตามที่ต้องการ รวมทั้งยังช่วยลดค่าใช้จ่ายลงไปอีกด้วย
Microsoft Teams ได้ปล่อย public preview ออกมาให้ลองใช้งาน ซึ่งทำการเปลี่ยนทั้ง Architecture, User interface และ technology ที่ใช้พัฒนา เพื่อให้ตอบโจทย์เรื่อง
Speed
Performance
Flexible
Intelligence
หรือจะเรียกว่า "reimagining of Teams from the ground up"
ถ้าใครใช้งาน Microsoft Teams มา จะรู้ว่า การทำงานจริง ๆ นั้น ตรงข้ามกันเลย !! นั่นจึงเป็นเป้าหมายหลักของ version ใหม่ เนื่องจากได้รับ feedback ด้านลบเยอะมาก ๆ