![technology-radar]()
![technology-radar]()
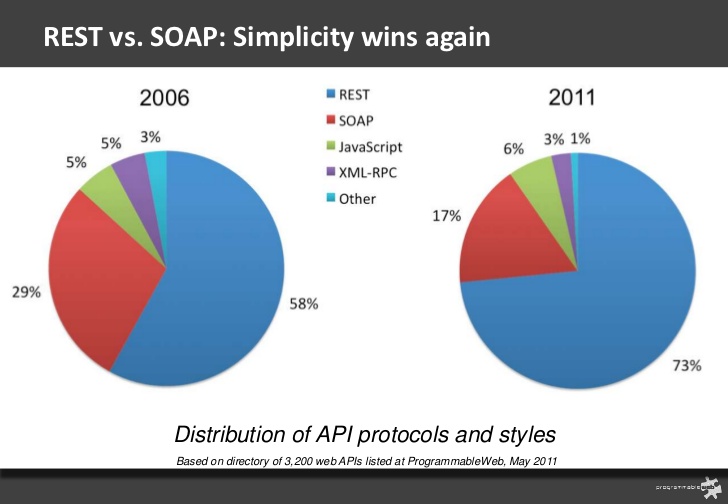
ทางบริษัท Thoughtworks จะสรุปเทคโนโลยีที่ใช้งาน และ แนวโน้มต่าง ๆ ในอนาคต
โดยในครั้งนี้จะเน้นใน 4 เรื่อง คือ
- Open Source
- Cloud และ Platform as a Service (PaaS)
- Docker ecosystem
- Over-Reactive ?
จึงนำมาสรุปนิดหน่อย
ซึ่งสามารถอ่านฉบับเต็ม ๆ ได้ที่
PDF Thoughtworks Technology Radar April 2016
สิ่งที่ developer น่าจะสนใจคือเรื่องของ Over-Reactive ?
ในปัจจุบันเรื่องของ Reactive programming ได้รับความนิยมอย่างมากมาย
ดังจะเห็นได้ว่าทุกภาษา program ล้วนมี Reactive extension/library/framework ให้ใช้งาน
ทั้งฝั่ง frontend และ backend
แต่การใช้ที่มากจนเกินไป หรือ หลากหลายรูปแบบจนเกินไป !!
มันก่อให้เกิดความซับซ้อนของระบบ
และยากต่อการทำความเข้าใจ
ดังนั้น ทีมพัฒนาความใช้งานในรูปแบบเดียวกัน
และใช้เท่าที่จำเป็น
อีกเรื่องที่น่าสนใจคือ Web Scale Envy
ว่าด้วยเรื่องของการขยายระบบ และ เรื่องของ performance
พบว่าหลาย ๆ ทีมมักจะมีปัญหาเรื่องนี้เสมอ
เนื่องจากเลือกใช้เครื่องมือที่มีความซับซ้อน
รวมทั้ง framework และ architecture ของระบบ
บ่อยครั้งที่ทีมพัฒนาจะไปอ้างถึง architecture และ เครื่องมือของ Twitter, Facebook และ Netflix
ซึ่งมีปริมาณการใช้งานที่สูงมาก ถึง โครตสูง
ดังนั้นจำเป็นต้องมีเครื่องมือ และ architecture ที่ซับซ้อนแบบนั้น
รวมทั้งความสามารถของแต่ละคนในทีมต้องสูงด้วยเช่นกัน
ถึงจะใช้งาน และ จัดการความซับซ้อนเหล่านี้ได้
แต่เมื่อย้อนกลับมาดูทีมพัฒนาของเราสิ
ดูปริมาณผู้ใช้งานสิ
ดูความสามารถของแต่ละคนในทีมสิ
มันต้องการความซับซ้อนเหล่านั้นหรือไม่ ?
ดังนั้น จึงแนะนำให้เริ่มต้นด้วยวิธีการที่เรียบง่ายก่อนนะ
เพื่อให้ระบบงานที่เราพัฒนาอยู่นั้นมันทำงานได้อย่างถูกต้อง
จากนั้นจึงค่อยคิดเรื่องการขยายระบบ และ performance ต่อไป
ตามธรรมเนียมของ Technology Radar จะแบ่งออกเป็น 4 กลุ่มคือ
- Techniques
- Tools
- Platforms
- Languages และ Framework
ซึ่งจะสรุปบางตัวที่ผมสนใจจากแต่ละกลุ่มมาอธิบายนิดหน่อย
จะเน้นสิ่งใหม่ ๆ ที่เข้ามา ทั้งดีและไม่ดี
พยายามจะไม่ให้ซ้ำจากรายงานครั้งที่ผ่านมา
ThoughtWorks Technology Radar ประจำเดือนพฤศจิกายน 2015
1. Techniques
เทคนิคใหม่ ๆ ที่เข้ามาอยู่ในกลุ่ม Assess
จะเป็นเรื่องของ
security ทั้ง Content security policy และ
OWASP
เนื่องจากทีมพัฒนาส่วนใหญ่ ไม่ค่อยนำเรื่อง security มาพูดคุยตั้งแต่เริ่มต้นการพัฒนา
บางทีมอาจจะไม่สนใจเลยด้วยซ้ำ
เนื่องจากคนส่วนใหญ่มีความรู้ด้านนี้น้อยมาก ๆ
ซึ่งสิ่งเหล่านี้มันคือความเสี่ยงของระบบงานมาก ๆ
แต่เรามักมองข้ามไปกันหมด
ดังนั้นความเพิ่มเรื่อง security เข้าไปใน functional requirement ด้วยนะ
ไม่ว่าจะเป็น
- Authentication process
- Access control
- Error handling
- Logging
มันจะทำให้เห็นว่าต้องพัฒนา และ ทดสอบอะไรบ้างนั่นเอง
ส่วนเรื่องที่ไม่ควรทำ หรือ ถ้าจะทำต้องใช้ความระมัดระวังอย่างสูง !!
การติดตั้ง CI server ที่เดียวเพื่อให้ทุก ๆ ทีมใช้งาน
มันเคยเป็นแนวคิดที่ดี
เนื่องจากจะได้ใช้งานเพียงที่เดียว
ทำให้จัดการ และ monitoring ได้ง่าย
แต่เมื่อมีระบบมากขึ้น คนใช้เยอะขึ้น
การใช้งานเพียงเครื่องเดียวมันก่อให้เกิดปัญหามากมายตามมา
ตัวอย่างเช่น
- เกิดข้อขัดแย้งในเรื่องของ configuration ที่หลากหลาย
- การเข้าคิวเพื่อที่จะ build หรือ ทำงาน
- การทำงานชนกัน
- ถ้าเครื่องนี้ล่มไป พังกันทุกทีมแน่นอน !!
- อื่น ๆ อีกมากมาย
ซึ่งมันเป็น Single Point of Failure (SPoF) ชัด ๆ
ดังนั้นก่อนใช้งานต้องพิจารณาถึงข้อดีและข้อเสียให้มาก
คำแนะนำคือ แยก CI Server ตามทีมที่ทำงาน หรือ ระบบไปเลยนะครับ
เรื่องต่อมาคือ Big Data Envy !!
ในปัจจุบันนั้นคำว่า Big Data มันเข้าไปอยู่ในทุกองค์กรแล้ว
ซึ่งเข้าใจกันแล้วว่ามันคืออะไร มีคุณค่าอย่างไร
แต่ปัญหาที่เกิดตามมาก็คือ การนำเครื่องมือที่ไม่เหมาะสมมาใช้งาน !!
เช่นการนำเครื่องมือที่มีความซับซ้อนมาก ๆ
มาจัดการกับข้อมูลที่ไม่ใช่ Big Data
บ่อยครั้งพบว่า ข้อมูลที่มีอยู่นั้น
สามารถสิเคราะห์ และ ประมวลผล เพียงเครื่องมือง่าย ๆ
หรือใช้คอมพิวเตอร์เพียงเครื่องเดียว
หรือใช้เพียง RDBMS ปกติก็ทำได้แล้ว
หรือไม่เช่นนั้น ก่อนที่จะประมวลผลข้อมูล
ช่วยเลือกเฉพาะข้อมูลที่ต้องการ และ จำเป็นมา
จากนั้นจึงใช้เครื่องมือง่าย ๆ มาช่วยวิเคราะห์ และ ประมวลผล
ปล. อย่าทำอะไรที่มากเกินความจำเป็นนะครับ
และให้เข้าใจด้วยว่ากำลังจะทำอะไร
2. Platforms
เป็นที่แน่นอนว่า
Docker เข้ามาเป็น Platform หลักไปแล้ว
ซึ่งตอบสนองความต้องการทั้งจาก
ทีมพัฒนา, ทีม operation และ ทีม infrastructure
และยังได้เกิด Docker ecosystem ขึ้นมาเยอะมาก ๆ
ส่วนตัวอื่น ๆ ที่น่าสนใจ เช่น
- Realm คือ database สำหรับ mobile application เน้นเรื่อง high performance เป็นหลัก แน่นอนว่ามันเข้ามาเพื่อแทนที่ SQLite และ Core Data
- TensorFlow เป็น open source เรื่อง Machine Learning จาก Google ซึ่งพลาดไม่ได้ด้วยประการทั้งปวง
ส่วนเรื่องที่ต้องพึงระวังคือ Overambitious API Gateway !!
หรือการจัดการ และ ใช้งาน API Gateway ที่ยาก และซับซ้อนเกินไป
แทนที่จะส่งผลดี กลับส่งผลร้ายออกมาแทน !!
เนื่องจากแนวคิดของ API Gateway นั้น
มันทำให้เราง่ายต่อการจัดการเรื่องพื้นฐาน
เช่น authentication, authorization และ rate-limit ต่าง ๆ
แต่สำหรับงานอื่น ๆ พวก data transform, data processing นั้น
มันไม่จำเป็นต้องมาผ่าน API Gateway เลย
เพราะว่า ทำให้ควบคุม และ จัดการได้ยาก
ดังนั้นควรให้ไปอยู่ใน application หรือ service นั้น ๆ ไปเลย
ปล. อะไรที่มันเยอะ มันยาก มันซับซ้อนเกินไป
นั่นแสดงว่า คุณกำลังเดินผิดทางนะ
3. Tools
เป็นกลุ่มเครื่องมือต่าง ๆ ซึ่งมีเครื่องมือใหม่ ๆ เข้ามาเยอะมาก
เริ่มต้นด้วย capsul
เป็น service discovery tool ถูกย้ายมาในส่วนของ Adopt
นั่นคือ แนะนำให้นำไปใช้งานบน production ได้เลย มันแจ่มมาก ๆ (ผมก็ใช้อยู่)
ทำให้เราสามารถดูได้ว่า
ในระบบของเรานั้นมี service อะไรทำงานอยู่บ้าง
แน่นอนว่า สามารถทำงานกับ Docker ได้อย่างสบาย
ต่อมาคือ เรื่องของ security อีกแล้วนั่นคือ OWASP Dependency-Check
เป็นเครื่องมือสำหรับช่วยตรวจสอบเรื่อง security
แน่นอนว่า มันทำให้ชีวิตของ developer ดีขึ้นแน่นอน
ถ้าไม่เชื่อก็ลองนำไปใช้กันดูสิ
โดยใช้ได้ทั้ง Java, .Net, Ruby, Python และ Node.js
ส่วนเรื่องที่ต้องระมัดระวังคือ Jenkins as a Deployment Pipeline
ซึ่งจะพูดถึงกรณีที่ กระบวนการ build มันมีความซับซ้อนมาก
ต้องการเครื่องมือสร้างมาเพื่อจัดการโดยเฉพาะ
ถึงแม้ใน Jenkins จะมี plugin ชื่อว่า Deployment Pipeline
ถึงแม้ใน Jenkins 2.0 จะมี plugin ชื่อว่า Pipeline as Code
แต่ก็ยังเป็นเพียง plugin
ไม่ได้ทำการเปลี่ยน core หรือ การทำงานหลักของ Jenkins เลย
เพื่อให้จัดการเรื่อง deployment pipeline โดยเฉพาะ
ปล. ผมยังไม่เคยเจอปัญหาเท่าไร
เพราะว่า build pipeline ของผมยังไม่ซับซ้อนนั่นเอง
โดยในปัจจุบันมีเครื่องมือที่สร้างมาเพื่อ Deployment Pipeline เลย เช่น
4. Language และ Framework
ขอบอกได้เลยว่า มันเยอะมาก ๆ ไม่รู้จะเยอะไปไหน !!
กลุ่มที่สามารถนำไปใช้กันได้เลย คือ
- ES6
- React.js
- Spring Boot
- Swift
สิ่งที่เกี่ยวกับ Mobile เยอะเลย เช่น
- Butterknife
- Dagger
- React Native
- Rebolectric
- Alamofire
- OkHttp
ส่วน JavaScript ก็เพียบ เช่น
- Ember.js
- Redux
- AngularJS
- Cylon.js
- Aurelia
และตัวอื่น ๆ ที่น่าสนใจ คือ Elm และ Elixir
สุดท้ายลองถามตัวเราเองสิว่า
มีเรื่องอะไรที่ไม่รู้บ้าง ?

 วันนี้มีโอกาสได้แบ่งปันความรู้เรื่อง Continuous Integration (CI)
สำหรับปรับปรุงคุณภาพของการพัฒนา Software ให้ดีขึ้น
โดยหัวใจของ CI นั้นประกอบไปด้วย 2 คำคือ
วันนี้มีโอกาสได้แบ่งปันความรู้เรื่อง Continuous Integration (CI)
สำหรับปรับปรุงคุณภาพของการพัฒนา Software ให้ดีขึ้น
โดยหัวใจของ CI นั้นประกอบไปด้วย 2 คำคือ

 เรามักจะได้ยินคำว่า
เรามักจะได้ยินคำว่า 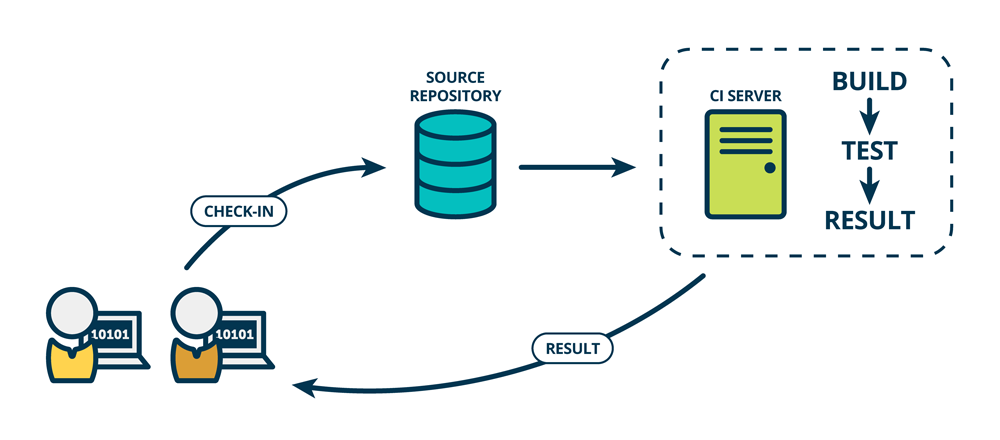
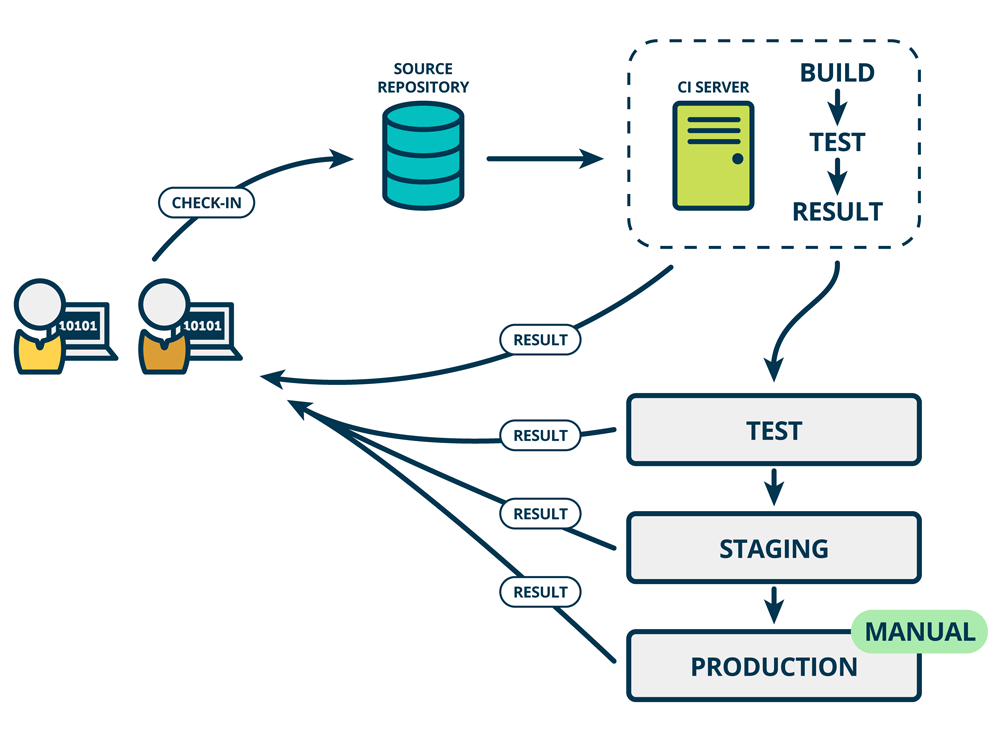 คำตอบคือ
ต้องจัดการและเตรียม Deployment Pipeline
เพื่อทำให้เราสามารถ deploy และ ทดสอบในแต่ละ environment ได้อย่างรวดเร็ว
และจะทำให้เรามั่นใจ และ เชื่อมั่นต่อ code และ ระบบมากยิ่งขึ้น
โดยในแต่ละ environment นั้นควรทำการทดสอบอบบขนาน (Parallel testing)
เพื่อให้ได้รับ feedback ที่รวดเร็วมากขึ้น
คำตอบคือ
ต้องจัดการและเตรียม Deployment Pipeline
เพื่อทำให้เราสามารถ deploy และ ทดสอบในแต่ละ environment ได้อย่างรวดเร็ว
และจะทำให้เรามั่นใจ และ เชื่อมั่นต่อ code และ ระบบมากยิ่งขึ้น
โดยในแต่ละ environment นั้นควรทำการทดสอบอบบขนาน (Parallel testing)
เพื่อให้ได้รับ feedback ที่รวดเร็วมากขึ้น
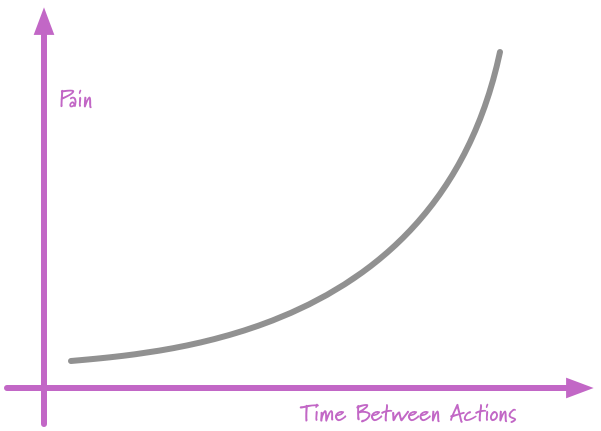 ลองคิดดูสิว่า
ถ้าเราสามารถทำบ่อย ๆ ได้ แสดงว่า
งานเหล่านั้นต้องมีขนาดเล็ก ๆ
รวมทั้งทำให้เราสามารถนำ feedback ไปปรับปรุงได้อย่างรวดเร็ว
และทำให้เราสร้างสิ่งที่ใช่มากขึ้น
สิ่งที่สองคือ ต้องทำงานแบบอัตโนมัติ
ถ้ายังทำงานแบบ manual หรือใช้คนมาก ๆ แล้ว
เป็นไปไม่ได้เลยที่จะได้รับ feedback อย่างรวดเร็ว และ บ่อย ๆ
เพราะว่า คนมีชีวิตจิตใจ สร้างความผิดพลาดได้เสมอ
ดังนั้น งานอะไรที่ทำซ้ำ ๆ ก็ ลด ละ เลิก
และให้ทำงานแบบอัตโนมัติซะ
ดังนั้นเมื่อเข้าใจขั้นตอนการทำงานต่าง ๆ แล้ว
จึงไปศึกษา และ เลือกเครื่องมือที่เหมาะสมกับความต้องการต่อไป
อย่าเริ่มจากเครื่องมือนะครับ !!
ลองคิดดูสิว่า
ถ้าเราสามารถทำบ่อย ๆ ได้ แสดงว่า
งานเหล่านั้นต้องมีขนาดเล็ก ๆ
รวมทั้งทำให้เราสามารถนำ feedback ไปปรับปรุงได้อย่างรวดเร็ว
และทำให้เราสร้างสิ่งที่ใช่มากขึ้น
สิ่งที่สองคือ ต้องทำงานแบบอัตโนมัติ
ถ้ายังทำงานแบบ manual หรือใช้คนมาก ๆ แล้ว
เป็นไปไม่ได้เลยที่จะได้รับ feedback อย่างรวดเร็ว และ บ่อย ๆ
เพราะว่า คนมีชีวิตจิตใจ สร้างความผิดพลาดได้เสมอ
ดังนั้น งานอะไรที่ทำซ้ำ ๆ ก็ ลด ละ เลิก
และให้ทำงานแบบอัตโนมัติซะ
ดังนั้นเมื่อเข้าใจขั้นตอนการทำงานต่าง ๆ แล้ว
จึงไปศึกษา และ เลือกเครื่องมือที่เหมาะสมกับความต้องการต่อไป
อย่าเริ่มจากเครื่องมือนะครับ !!

 คำถามหนึ่งที่ได้ยินบ่อยมาก ๆ สำหรับการนำ Elasticsearch มาใช้งานนั่นก็คือ
คำถามหนึ่งที่ได้ยินบ่อยมาก ๆ สำหรับการนำ Elasticsearch มาใช้งานนั่นก็คือ
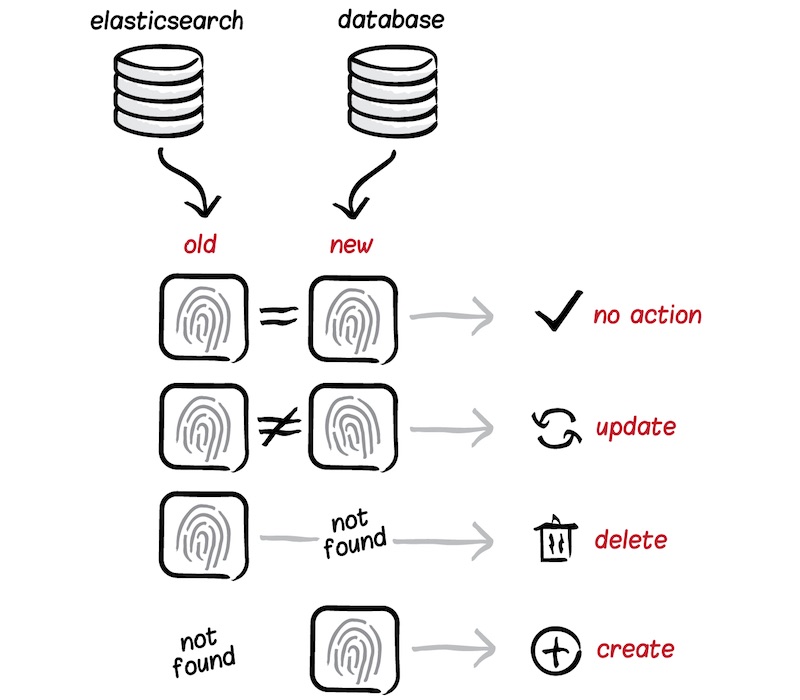
 รูปแบบที่ 2
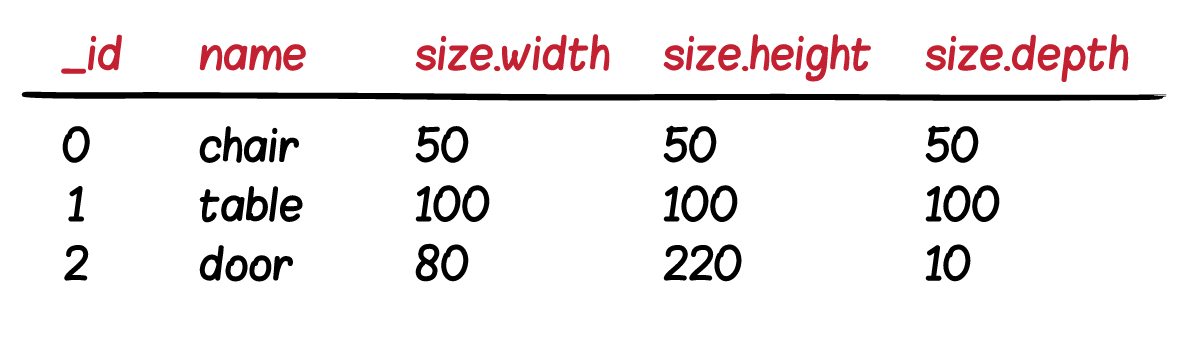
ข้อมูลจำนวนมากกว่า 1 row จาก Database คือ 1 Document ใน Elasticsearch
แสดงดังรูป
รูปแบบที่ 2
ข้อมูลจำนวนมากกว่า 1 row จาก Database คือ 1 Document ใน Elasticsearch
แสดงดังรูป
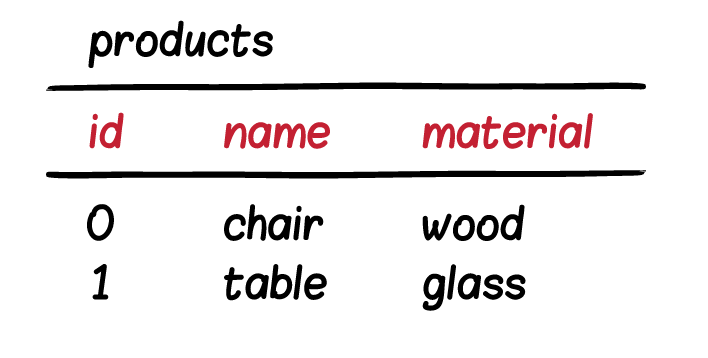
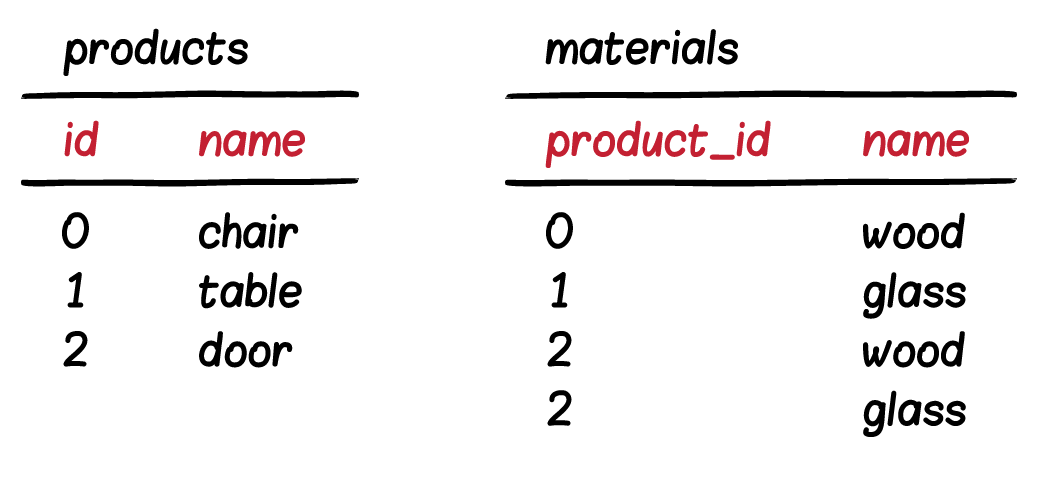 ดังนั้นสิ่งที่ต้องทำก่อนนำข้อมูลเข้า Elasticsearch คือ
ต้องทำการ join ข้อมูลจาก 2 Table ก่อนเสมอ
แสดงดังรูป
ดังนั้นสิ่งที่ต้องทำก่อนนำข้อมูลเข้า Elasticsearch คือ
ต้องทำการ join ข้อมูลจาก 2 Table ก่อนเสมอ
แสดงดังรูป
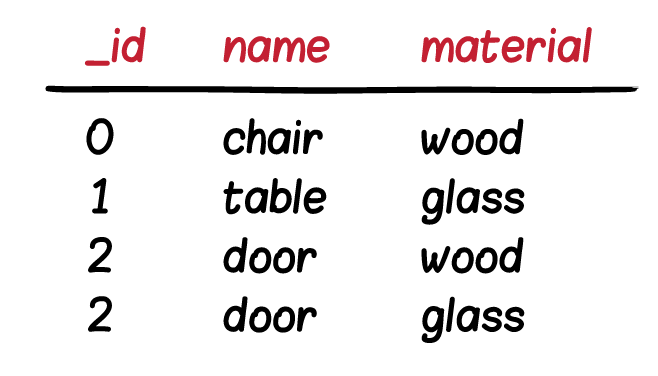 จากนั้นในการจัดเก็บที่ Elasticsearch
ก็ให้เก็บลง field/property ในรูปแบบของ
จากนั้นในการจัดเก็บที่ Elasticsearch
ก็ให้เก็บลง field/property ในรูปแบบของ  ก่อนที่จะจัดเก็บข้อมูลลงไปยัง Elasticsearch
ต้องทำการ join ข้อมูลกันก่อน
และเลือกเฉพาะ column ที่จำเป็นต่อการใช้งานเท่านั้น
ไม่ควรเก็บข้อมูลที่ไม่จำเป็นหรือไม่ได้ใช้งาน
ส่วนข้อมูลจาก sizes มีโครงสร้างแบบ Nested object
หรือข้อมูล 1 product จะอยู่ใน 1 document เท่านั้น
แสดงดังรูป
ก่อนที่จะจัดเก็บข้อมูลลงไปยัง Elasticsearch
ต้องทำการ join ข้อมูลกันก่อน
และเลือกเฉพาะ column ที่จำเป็นต่อการใช้งานเท่านั้น
ไม่ควรเก็บข้อมูลที่ไม่จำเป็นหรือไม่ได้ใช้งาน
ส่วนข้อมูลจาก sizes มีโครงสร้างแบบ Nested object
หรือข้อมูล 1 product จะอยู่ใน 1 document เท่านั้น
แสดงดังรูป

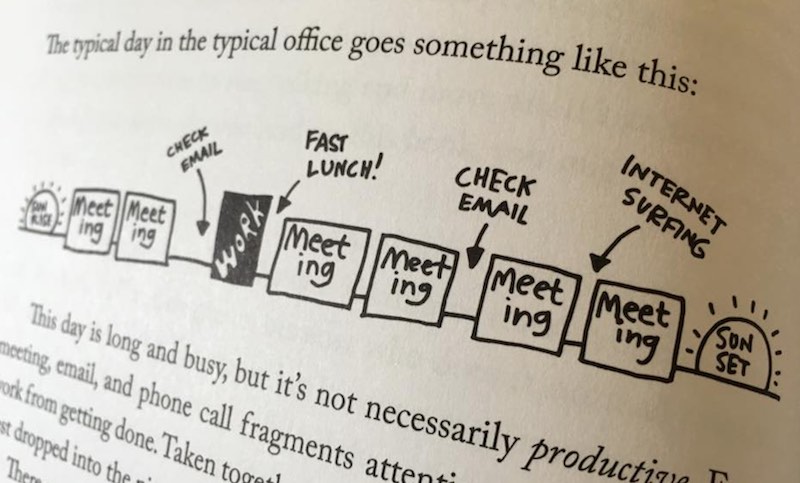
 วันนี้ระหว่างเดินทางกลับจากเชียงใหม่ เดินผ่านร้านหนังสือในสนามบิน
เห็นหนังสือชื่อว่า
วันนี้ระหว่างเดินทางกลับจากเชียงใหม่ เดินผ่านร้านหนังสือในสนามบิน
เห็นหนังสือชื่อว่า  เริ่มด้วยที่มาที่ไปของคำว่า Sprint หรือรอบการทำงาน
ว่าทำไมต้อง Sprint ละ 5 วัน ?
โดยมาจากการลองผิดลองถูก
ตั้งแต่รอบละ 2-4 สัปดาห์ พบว่า
รอบการทำงานมันยาวนานเกินไป
และไม่ได้ผลที่ต้องการเมื่อจบ Sprint การทำงาน
หรือได้รับ feedback จากผู้ใช้งานจริง ๆ ช้าไป
บางครั้งจมอยู่กับปัญหา และ ไม่ focus ในเป้าหมาย
อันเนื่องมาจากเป้าหมายมันใหญ่ และ เยอะจนเกินไป !!
เริ่มด้วยที่มาที่ไปของคำว่า Sprint หรือรอบการทำงาน
ว่าทำไมต้อง Sprint ละ 5 วัน ?
โดยมาจากการลองผิดลองถูก
ตั้งแต่รอบละ 2-4 สัปดาห์ พบว่า
รอบการทำงานมันยาวนานเกินไป
และไม่ได้ผลที่ต้องการเมื่อจบ Sprint การทำงาน
หรือได้รับ feedback จากผู้ใช้งานจริง ๆ ช้าไป
บางครั้งจมอยู่กับปัญหา และ ไม่ focus ในเป้าหมาย
อันเนื่องมาจากเป้าหมายมันใหญ่ และ เยอะจนเกินไป !!
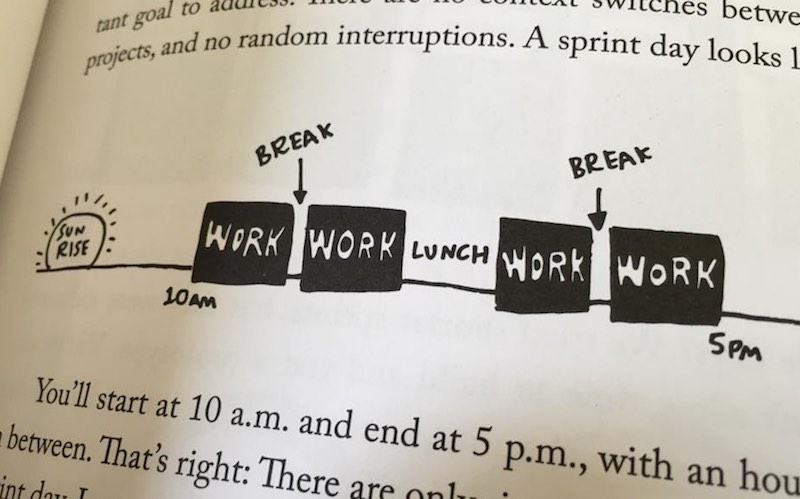
 ดังนั้น การทำงานใน Sprint 5 วันนั้น จำเป็นต้องเปลี่ยนจังหวะการทำงานใหม่
โดยให้เริ่มทำงานตั้งแต่ 10.00 - 17.00 น.
ช่วงที่หายไป คือ
ดังนั้น การทำงานใน Sprint 5 วันนั้น จำเป็นต้องเปลี่ยนจังหวะการทำงานใหม่
โดยให้เริ่มทำงานตั้งแต่ 10.00 - 17.00 น.
ช่วงที่หายไป คือ
 ในหนังสือแนะนำเรื่อง The no-device rule
นั่นคือ ให้ทุกคนปิดโทรศัพท์ และ สิ่งรบกวนต่าง ๆ
หรือถ้าจะรับโทรศัพท์ หรือ chat ก็ให้ออกไปข้างนอก
ไม่ใช่เล่นไป คุยไป ทำงานไป
เพื่อให้ทุกคนมีสมาธิกับงานที่ทำ
เนื่องจากถ้าไม่มีการจัดเตรียมพื้นที่การทำงานที่เหมาะสม ก็ไม่สามารถทำงานร่วมกันได้
เช่น ห้อง โต๊ะ เก้าอี้ พวก whiteboard และ อุปกรณ์ต่าง ๆ
ที่พร้อมจะเปลี่ยนแปลงและเคลื่อนย้ายอยู่ตลอดเวลา
ในหนังสือแนะนำเรื่อง The no-device rule
นั่นคือ ให้ทุกคนปิดโทรศัพท์ และ สิ่งรบกวนต่าง ๆ
หรือถ้าจะรับโทรศัพท์ หรือ chat ก็ให้ออกไปข้างนอก
ไม่ใช่เล่นไป คุยไป ทำงานไป
เพื่อให้ทุกคนมีสมาธิกับงานที่ทำ
เนื่องจากถ้าไม่มีการจัดเตรียมพื้นที่การทำงานที่เหมาะสม ก็ไม่สามารถทำงานร่วมกันได้
เช่น ห้อง โต๊ะ เก้าอี้ พวก whiteboard และ อุปกรณ์ต่าง ๆ
ที่พร้อมจะเปลี่ยนแปลงและเคลื่อนย้ายอยู่ตลอดเวลา

 เมื่อมีการพูดถึงคำว่า Continuous Integration (CI) และ Continuous Delivery (CD) แล้ว
คนส่วนใหญ่มักจะคิดถึง หรือ พูดถึงเครื่องมือต่าง ๆ ก่อน
ไม่ว่าจะเป็น Jenkins บ้างล่ะ
ไม่ว่าจะเป็น Bamboo บ้างล่ะ
ไม่ว่าจะเป็น Travis CI บ้างล่ะ
ไม่ว่าจะเป็น Circle CI บ้างล่ะ
ไม่ว่าจะเป็น Docker บ้างล่ะ
ไม่ว่าจะเป็น Ansible บ้างล่ะ
ซึ่งเครื่องมือเหล่านี้มันเป็นเพียงตัวช่วยทำให้ความต้องการเราสำเร็จเท่านั้น
แต่ก่อนอื่นต้องเข้าใจตัวเองก่อนว่า
เมื่อมีการพูดถึงคำว่า Continuous Integration (CI) และ Continuous Delivery (CD) แล้ว
คนส่วนใหญ่มักจะคิดถึง หรือ พูดถึงเครื่องมือต่าง ๆ ก่อน
ไม่ว่าจะเป็น Jenkins บ้างล่ะ
ไม่ว่าจะเป็น Bamboo บ้างล่ะ
ไม่ว่าจะเป็น Travis CI บ้างล่ะ
ไม่ว่าจะเป็น Circle CI บ้างล่ะ
ไม่ว่าจะเป็น Docker บ้างล่ะ
ไม่ว่าจะเป็น Ansible บ้างล่ะ
ซึ่งเครื่องมือเหล่านี้มันเป็นเพียงตัวช่วยทำให้ความต้องการเราสำเร็จเท่านั้น
แต่ก่อนอื่นต้องเข้าใจตัวเองก่อนว่า

 วันนี้นั่งสรุปการนำ
วันนี้นั่งสรุปการนำ 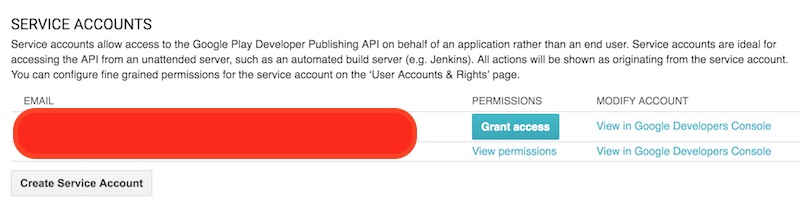 จากนั้นให้ทำการสร้าง Service Account key
จากนั้นให้ทำการสร้าง Service Account key
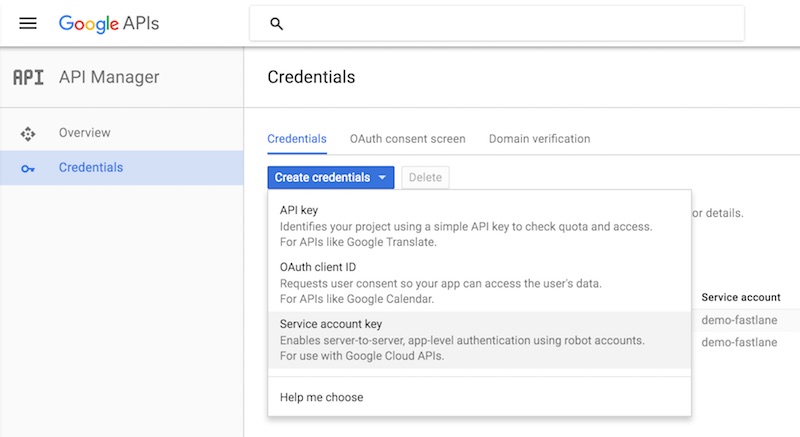 ให้เลือก Key type เป็น JSON
และอย่าลืม download มาเก็บไว้ที่เครื่อง
ซึ่งผมตั้งชื่อไฟล์นี้ว่า google_play.json
เนื่องจากจะต้องใช้ใน suppply นั่นเอง
ให้เลือก Key type เป็น JSON
และอย่าลืม download มาเก็บไว้ที่เครื่อง
ซึ่งผมตั้งชื่อไฟล์นี้ว่า google_play.json
เนื่องจากจะต้องใช้ใน suppply นั่นเอง
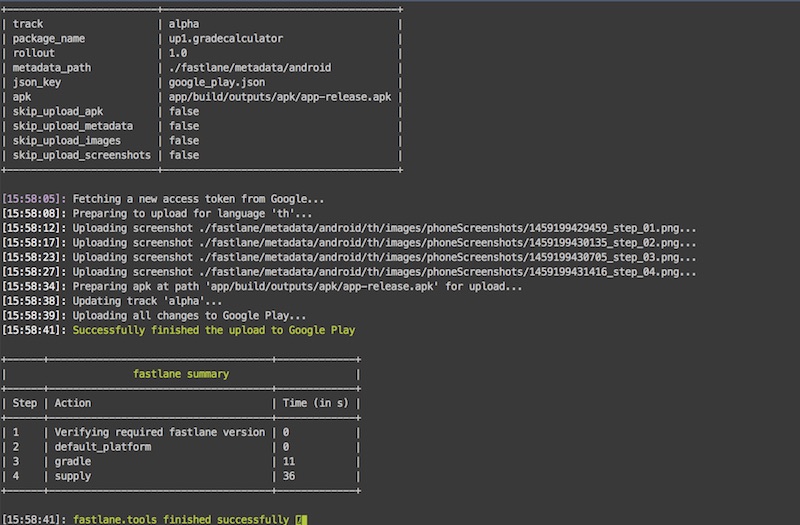
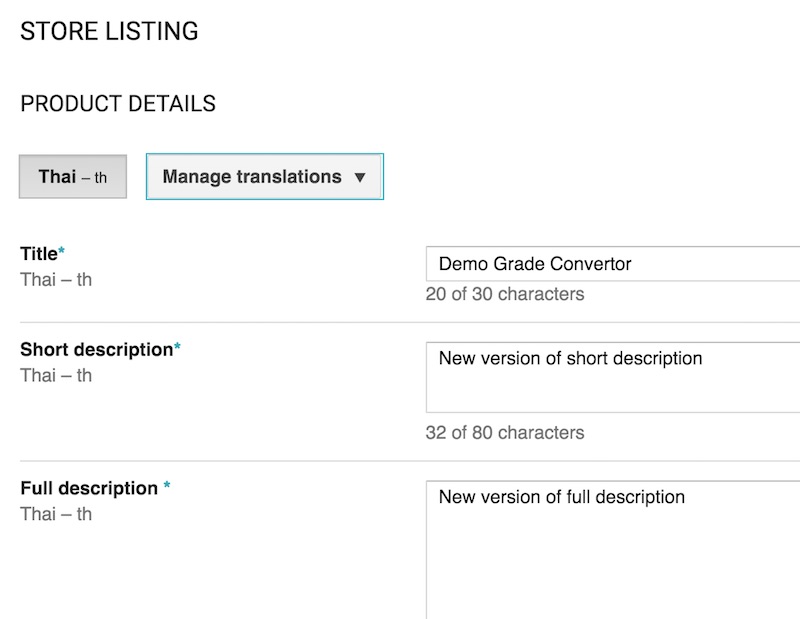 รูปภาพการทำงานของ App แสดงดังรูป
รูปภาพการทำงานของ App แสดงดังรูป

 จากการพูดคุยกับหลายทีม พบว่า
ปัญหาอย่างหนึ่งที่มักพบเจอคือ
การเชื่อมต่อกับระบบต่าง ๆ ผ่าน REST APIs
หรือแม้แต่การพัฒนาระบบเดียวกันที่ต้องแบ่งเป็น 2 ทีม คือ
จากการพูดคุยกับหลายทีม พบว่า
ปัญหาอย่างหนึ่งที่มักพบเจอคือ
การเชื่อมต่อกับระบบต่าง ๆ ผ่าน REST APIs
หรือแม้แต่การพัฒนาระบบเดียวกันที่ต้องแบ่งเป็น 2 ทีม คือ
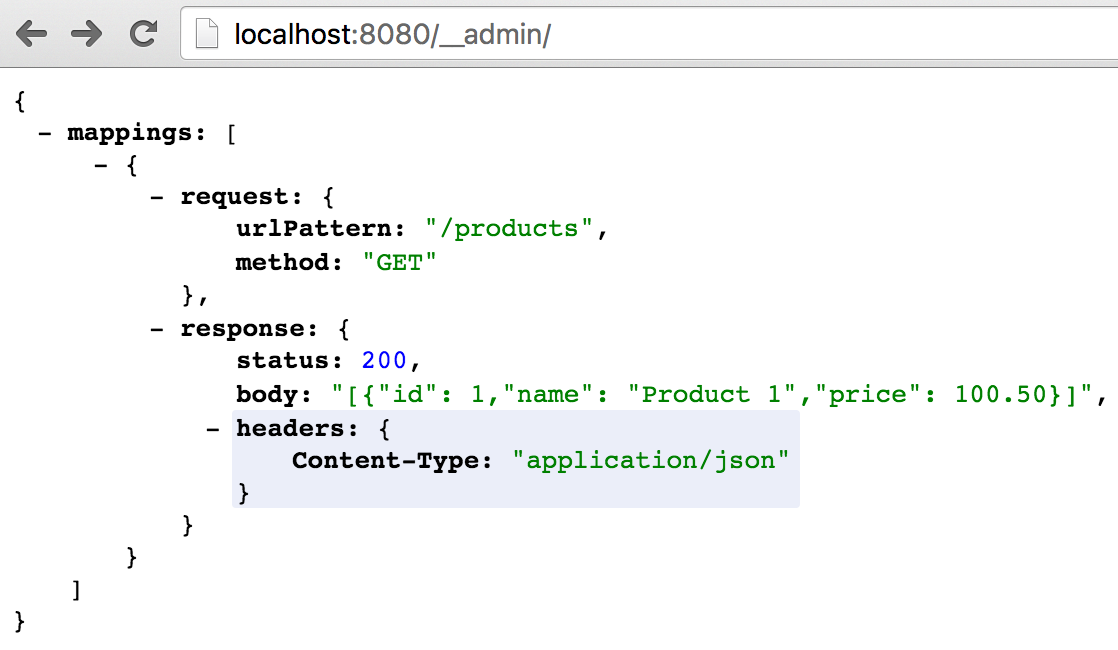
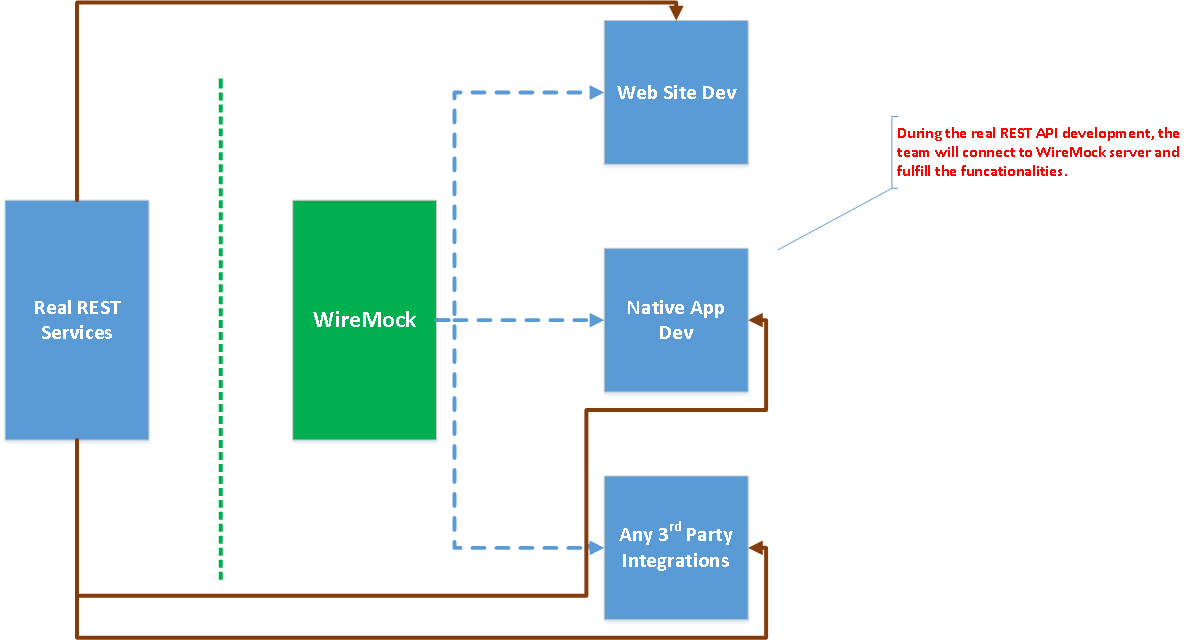 มาดูตัวอย่างการใช้งาน WireMock กันนิดหน่อย
มาดูตัวอย่างการใช้งาน WireMock กันนิดหน่อย
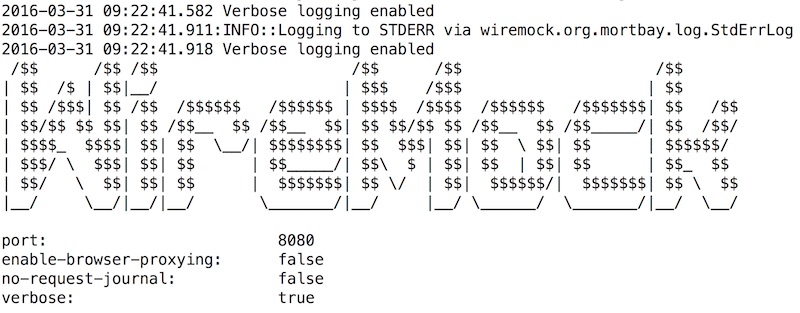 โดยค่า default นั้นจะทำงานที่ port 8080
แต่เราสามารถเปลี่ยน port ได้ด้วยคำสั่ง
[code]$java -jar wiremock-1.57-standalone.jar --port 9090 --verbose[/code]
สามารถดูการใช้งานเพิ่มเติมได้ที่
โดยค่า default นั้นจะทำงานที่ port 8080
แต่เราสามารถเปลี่ยน port ได้ด้วยคำสั่ง
[code]$java -jar wiremock-1.57-standalone.jar --port 9090 --verbose[/code]
สามารถดูการใช้งานเพิ่มเติมได้ที่ 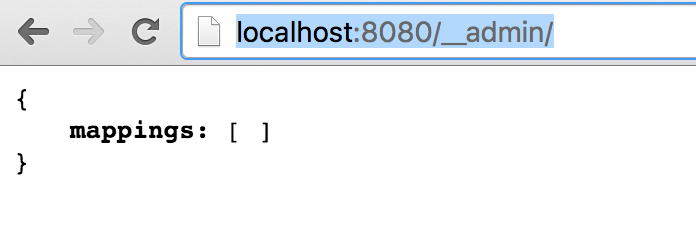
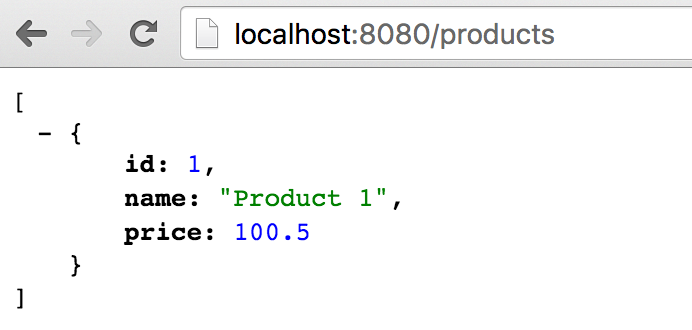 หรือสามารถทดสอบผ่าน Postman หรือ REST Client หรือ Curl ก็ได้นะ
เลือกได้ตามความสะดวกของแต่ละคน
เพียงเท่านี้ก็สามารถจำลอง API Server ด้วย WireMock กันได้แล้วนะ
หรือสามารถทดสอบผ่าน Postman หรือ REST Client หรือ Curl ก็ได้นะ
เลือกได้ตามความสะดวกของแต่ละคน
เพียงเท่านี้ก็สามารถจำลอง API Server ด้วย WireMock กันได้แล้วนะ

 ไม่มีอะไรมาก แค่อยากจะแนะนำ
ไม่มีอะไรมาก แค่อยากจะแนะนำ 


 วันนี้มีโอกาสมาแบ่งปันเรื่อง Continuous Delivery with Fastlane
ในงาน iOS Dev Meetup ครั้งที่ 4 จากกลุ่ม
วันนี้มีโอกาสมาแบ่งปันเรื่อง Continuous Delivery with Fastlane
ในงาน iOS Dev Meetup ครั้งที่ 4 จากกลุ่ม  โดยแนวคิดเบื้องต้นของ CD คือ Continuous Integration(CI)
นั่นคือ ต้องทำการ build -> test -> run อยู่บ่อย ๆ
เพื่อทำให้เรารู้ feedback หรือ ผลการทำงานหลังการเปลี่ยนแปลงสิ่งต่าง ๆ ได้อย่างรวดเร็ว
แน่นอนว่า การทำงานแบบ manual หรือ ให้คนทำส่วนนี้
จะได้รับ feedback ที่ช้ามาก ๆ
และไม่สามารถไม่สามารถทำงานได้บ่อยเท่าที่ต้องการ
ดังนั้น จึงต้องสร้างระบบการทำงานแบบอัตโนมัติขึ้นมา (Automation)
โดยแนวคิดเบื้องต้นของ CD คือ Continuous Integration(CI)
นั่นคือ ต้องทำการ build -> test -> run อยู่บ่อย ๆ
เพื่อทำให้เรารู้ feedback หรือ ผลการทำงานหลังการเปลี่ยนแปลงสิ่งต่าง ๆ ได้อย่างรวดเร็ว
แน่นอนว่า การทำงานแบบ manual หรือ ให้คนทำส่วนนี้
จะได้รับ feedback ที่ช้ามาก ๆ
และไม่สามารถไม่สามารถทำงานได้บ่อยเท่าที่ต้องการ
ดังนั้น จึงต้องสร้างระบบการทำงานแบบอัตโนมัติขึ้นมา (Automation)

 จากงาน iOS Dev Meetup ครั้งที่ 4
มีหนึ่ง session พูดเรื่อง
จากงาน iOS Dev Meetup ครั้งที่ 4
มีหนึ่ง session พูดเรื่อง 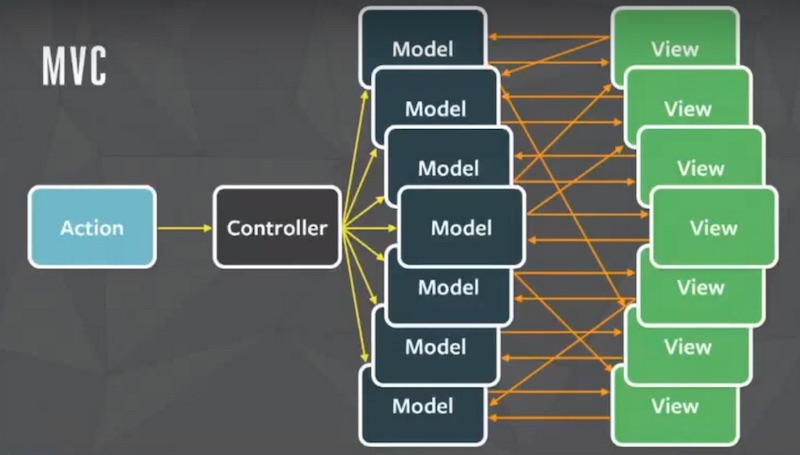 ดังนั้นจึงเกิดคำถามว่า
แล้วเราจะจัดการ State ต่าง ๆ เหล่านี้ของระบบอย่างไรดี ?
หนึ่งในคำตอบนั้นคือ Redux นั่นเอง
ดังนั้นจึงเกิดคำถามว่า
แล้วเราจะจัดการ State ต่าง ๆ เหล่านี้ของระบบอย่างไรดี ?
หนึ่งในคำตอบนั้นคือ Redux นั่นเอง
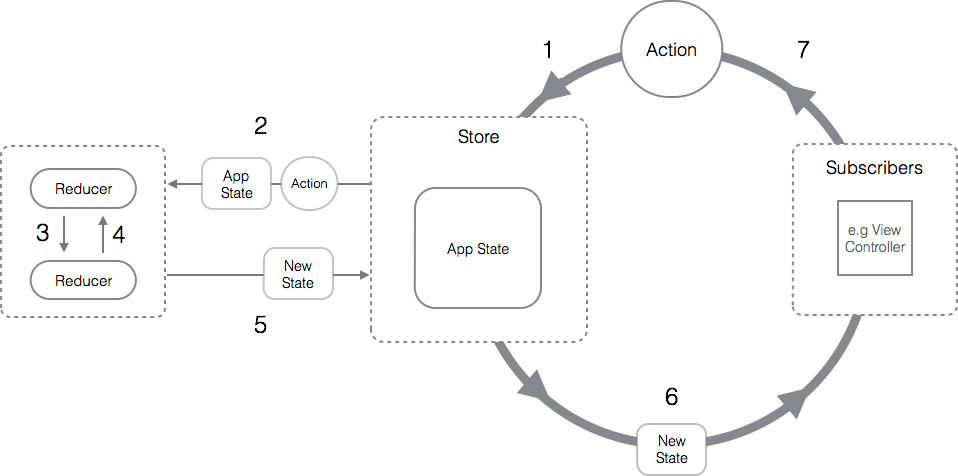 คำอธิบาย
คำอธิบาย
 จากงาน iOS Dev Meetup #4 มีการพูดถึงภาษา Kotlin กันพอสมควร
ว่าตัวภาษามันเกือบจะเหมือนกับภาษา Swift เลย
ต่างกันเพียง
จากงาน iOS Dev Meetup #4 มีการพูดถึงภาษา Kotlin กันพอสมควร
ว่าตัวภาษามันเกือบจะเหมือนกับภาษา Swift เลย
ต่างกันเพียง



 พอดีกำลังศึกษาการพัฒนา Android app ด้วยภาษา Kotlin
แต่ดันไปเจอคำแนะนำหนึ่งที่น่าสนใจคือ
พอดีกำลังศึกษาการพัฒนา Android app ด้วยภาษา Kotlin
แต่ดันไปเจอคำแนะนำหนึ่งที่น่าสนใจคือ

 เนื่องจากต้องการพัฒนา Application ด้วยภาษา Kotlin
ทั้งในฝั่ง Android และ Server (REST API)
ดังนั้นจึงอยากรู้ว่า ในฝั่ง Server จะพัฒนาได้อย่างไร
และง่ายเพียงใด
มาเริ่มกันเลยดีกว่า
เนื่องจากต้องการพัฒนา Application ด้วยภาษา Kotlin
ทั้งในฝั่ง Android และ Server (REST API)
ดังนั้นจึงอยากรู้ว่า ในฝั่ง Server จะพัฒนาได้อย่างไร
และง่ายเพียงใด
มาเริ่มกันเลยดีกว่า

 จากบทความเรื่อง
จากบทความเรื่อง 
 ทางบริษัท Thoughtworks จะสรุปเทคโนโลยีที่ใช้งาน และ แนวโน้มต่าง ๆ ในอนาคต
โดยในครั้งนี้จะเน้นใน 4 เรื่อง คือ
ทางบริษัท Thoughtworks จะสรุปเทคโนโลยีที่ใช้งาน และ แนวโน้มต่าง ๆ ในอนาคต
โดยในครั้งนี้จะเน้นใน 4 เรื่อง คือ


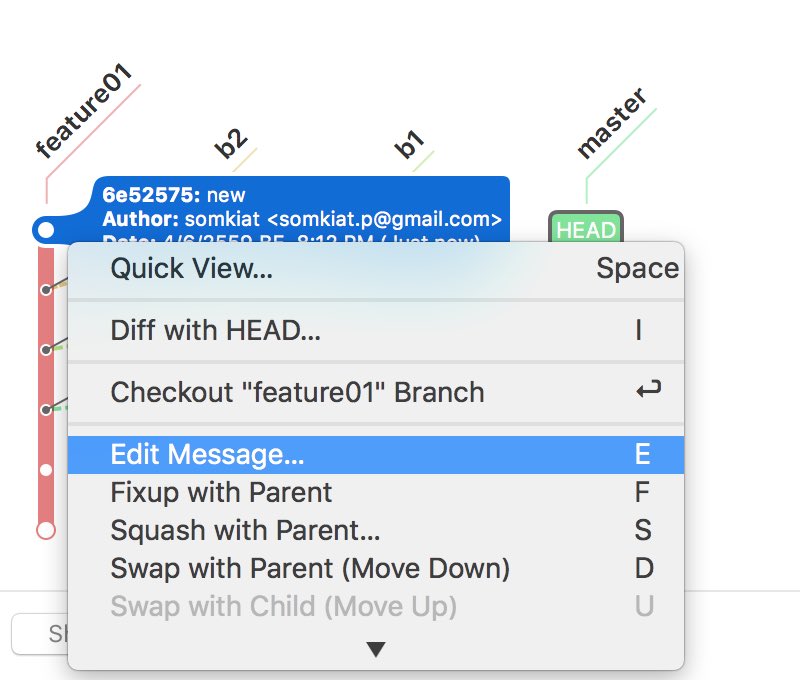 แสดง log ของ commit message นิดหน่อย
แสดง log ของ commit message นิดหน่อย
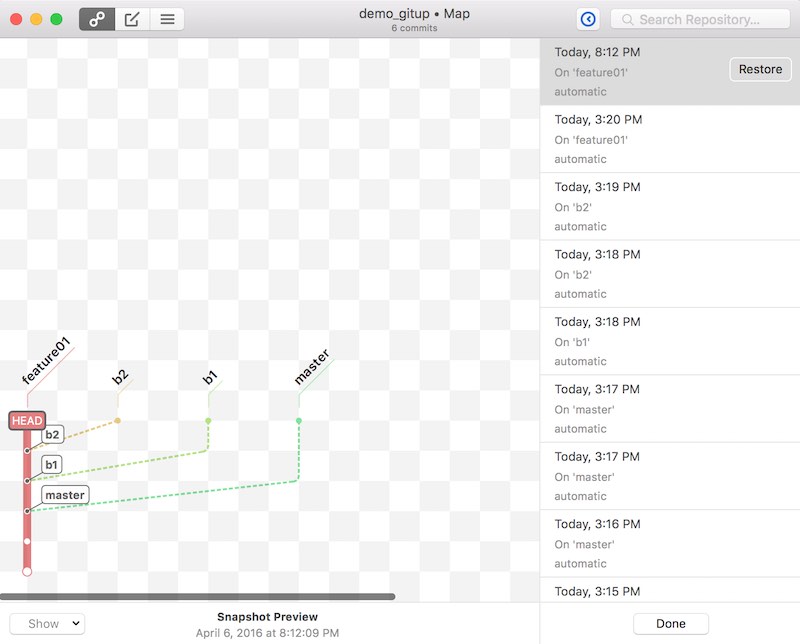

 เป็นเรื่องปกติของ Developer ทุกคนที่ต้องผจญภัยกับ Legacy Code
แต่สำหรับ Developer หน้าใหม่ ๆ นั้น
อาจจะมีความคิด และ ความคาดหวังว่า
เมื่อเข้ามาทำงานแล้ว ต้องมาพัฒนา feature ใหม่
ต้องมีเขียน code ใหม่ โดยไม่สนใจใคร
แต่ในโลกความเป็นจริงมันไม่เคยเป็นเช่นนั้นเลย
เนื่องจากต้องเข้าไปแก้ไขสิ่งเล็ก ๆ ที่เรียกว่า Legacy Code
บางคนเรียกว่า Death Star !!
บางคนอาจจะบอกว่า ซวยล่ะ งานเข้าแน่นอน !!
ดังนั้นเรามาดูกันหน่อยว่าจะรับมือกับมันอย่างไรบ้าง ?
เป็นเรื่องปกติของ Developer ทุกคนที่ต้องผจญภัยกับ Legacy Code
แต่สำหรับ Developer หน้าใหม่ ๆ นั้น
อาจจะมีความคิด และ ความคาดหวังว่า
เมื่อเข้ามาทำงานแล้ว ต้องมาพัฒนา feature ใหม่
ต้องมีเขียน code ใหม่ โดยไม่สนใจใคร
แต่ในโลกความเป็นจริงมันไม่เคยเป็นเช่นนั้นเลย
เนื่องจากต้องเข้าไปแก้ไขสิ่งเล็ก ๆ ที่เรียกว่า Legacy Code
บางคนเรียกว่า Death Star !!
บางคนอาจจะบอกว่า ซวยล่ะ งานเข้าแน่นอน !!
ดังนั้นเรามาดูกันหน่อยว่าจะรับมือกับมันอย่างไรบ้าง ?





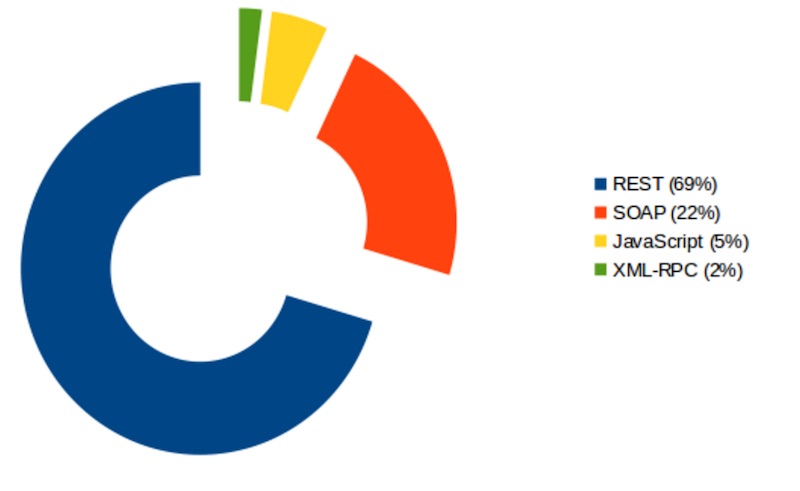 สิ่งหนึ่งที่ developer ควรทำความเข้าใจก็คือ
เรื่องของ
สิ่งหนึ่งที่ developer ควรทำความเข้าใจก็คือ
เรื่องของ