![cd-at-instagram]()
![cd-at-instagram]()
วันนี้เห็นมีการ share บทความเรื่อง
Continuous Deployment at Instagram
เป็นบทความที่อธิบายขั้นตอนการ deploy ระบบงานของ Instagram ว่าเป็นอย่างไร
ดังนั้นจึงทำการแปล และ สรุปส่วนที่น่าสนใจไว้นิดหน่อย
ซึ่งถือว่าเป็นแนวทางหนึ่งของการพัฒนา software ที่ดี
เริ่มกันเลยดีกว่า
ระบบ Instagram นั้น ทำการ deploy code ส่วน backend ประมาณวันละ 30-40 ครั้งต่อวัน
หรือว่าทำทุก ๆ ครั้งเมื่อมีการเปลี่ยนแปลง code ที่ branch master
โดยส่วนใหญ่แล้วจะไม่มีคนเข้าไปมีส่วนร่วมเลย !!
นั่นคือทำงานแบบอัตโนมัตินั่นเอง
เป็นไงล่ะ แค่เริ่มต้นก็ต้องร้อง ว้าววววว กันแล้ว
และทาง Instagram บอกว่า
ด้วยขนาดและการ scale ของระบบนั้น
ต้องการการทำงานในรูปแบบนี้ ซึ่งมันแจ่ม และ เหมาะมาก ๆ
ดังนั้นมาเรียนรู้กันว่า Instagram ทำกันอย่างไร ?
เริ่มด้วยคำถามอีกแล้ว ทำไปทำไม ?
ข้อดีของ Continuous Deployment มีดังนี้
ทำให้ทีมพัฒนาทำงานได้รวดเร็วขึ้น
เนื่องจากสามารถทำการ deploy code ได้บ่อยเท่าที่ต้องการ
ไม่ต้องมารอช่วงเวลา และ จำนวนครั้งที่จำกัดในการ deploy ต่อวัน
ผลที่ตามมาก็คือ ไม่ต้องสูญเสียเวลาไปโดยเปล่าประโยชน์
รวมทั้งค่อย ๆ ทำการเปลี่ยนแปลงระบบไปทีละเล็กละน้อย
ทำให้รู้ว่าแต่ละการเปลี่ยนแปลงมันผิดหรือถูกได้รวดเร็วขึ้น
เนื่องจากทำการ deploy ทุก ๆ การเปลี่ยนแปลง
ทำให้ไม่ต้องมานั่งหาข้อผิดพลาดจากการเปลี่ยนแปลงมากมาย
ดังนั้น ถ้าการเปลี่ยนแปลงไหนผิด ก็จะรู้ได้ทันที
ทำให้สามารถระบุปัญหาได้ทันที และ แก้ไขได้รวดเร็วขึ้น
แนวคิดนี้คือ Fail fast, Break things จริง ๆ
มันคุ้น ๆ ไหม ถ้าการ deploy แต่ละครั้งมีการเปลี่ยนแปลงเยอะ ๆ
การหาข้อผิดพลาดแต่ละเรื่องก็ยากใช่ไหม ?
ทำการสร้างระบบอย่างไร ?
การพัฒนาระบบ Continuous Deployment จะประสบความสำเร็จได้นั้น
มันมาจากหลายปัจจัย
จะสร้างครั้งเดียวให้เสร็จนั้น เป็นไปไม่ได้เลย !!
ดังนั้นวิธีการที่ทำคือ ค่อย ๆ สร้างอย่างยั่งยืน (Iterative approch)
ค่อย ๆ สร้างที่ละส่วนขึ้นมา
จากนั้นดูผลลัพธ์และทำการปรับปรุงให้ดียิ่งขึ้นอย่างสม่ำเสมอ
จนทำให้ได้ระบบ Continuous Deployment ในปัจจุบันขึ้นมาได้
ก่อนที่จะมีระบบ Continuous Deployment นั้น ทำการ deploy อย่างไร ?
นักพัฒนาทุกคนจะทำการ deploy การเปลี่ยนแปลงต่าง ๆ เอง
โดยงานเหล่านี้คืองาน ad-doc หรืองานที่ไม่ได้เตรียมการไว้ล่วงหน้า
ซึ่งจะทำการ run script การ rollout เอง
หรือบางครั้งก็ต้องรอคนอื่น ๆ ที่จะ deploy ด้วย
โดยขั้นตอนแรกทำการ deploy ไปยังเครื่อง production server เพียง 1 ตัว
เพื่อทดสอบว่า การทำงานมันถูกต้องตามที่คาดหวังหรือไม่ ?
ด้วยการ run ระบบ และเข้าไปดู logg ที่ server
ถ้าผลจาก logg ไม่มีข้อผิดพลาดอะไร
ก็จะทำการ deploy ไปยังเครื่องทั้งหมด
โดยระบบ logging ของการ rollout/deploy จะเรียกว่า
Sauron
ชื่อคุ้น ๆ ไหม จากเรื่อง The Lord of the Rings นั่นเอง
ปล.
การทดสอบนั้นใช้ traffic จริง ๆ กันเลยนะ
ต่อมาเริ่มมีการเตรียมเครื่อง server สำหรับการทดสอบโดยเฉพาะเรียกว่า Canary server
ทำให้ควบคุมการ deploy และทดสอบได้ง่ายกว่า
แต่การทดสอบเพียงตรวจสอบการ log การทำงานอย่างเดียวมันไม่เพียงพอ
จึงได้เพิ่มให้ทำการ run ชุดการทดสอบ
ซึ่งแต่ก่อนชุดการทดสอบมีอยู่แล้ว
เพียงแต่ถูกทดสอบเฉพาะเครื่องของนักพัฒนาแต่ละคนเท่านั้น
ดังนั้นจึงทำการติดตั้ง และ configuration Jenkins server ขึ้นมา
เพื่อทำการทดสอบในทุก ๆ การเปลี่ยนแปลงที่ branch master
และส่งผลการทดสอบไปยังเครื่อง Sauron
ดังนั้นในตอนนี้เครื่อง Sauron จะรู้ว่า
ในแต่ละการเปลี่ยนแปลงผ่านการทดสอบหรือไม่ ?
ถ้าไม่ผ่านการทดสอบ
การเปลี่ยนแปลงเหล่านั้นก็ไม่ถูกสนใจ หรือนำไป deploy
ส่งผลทำให้การ deploy มีประสิทธิภาพยิ่งขึ้น
คือ ไม่ deploy สิ่งผิด ๆ ขึ้นไป
โดยที่ Facebook นั้น
ใช้ Fabricator สำหรับการทำ code review
ใช้ Sandcastle สำหรับสร้างระบบ Continuous Integration ซึ่งสามารถทำงานร่วมกับ Fabricator ได้
ซึ่ง Sandcastle จะทำการทดสอบทุก ๆ ครั้งที่มีการเปลี่ยนแปลง
และส่งผลการทดสอบของการเปลี่ยนแปลงนั้นออกมา
จากนั้นเริ่มสร้างระบบการทำงานแบบอัตโนมัติขึ้นมา
เมื่อระบบการทำงานรู้แล้วว่า
ในแต่ละการเปลี่ยนแปลงมีสถานะเป็นอย่างไร
ต้องใช้คนมาตัดสินใจว่า จะต้องทำอย่างไรต่อไป
เช่นตัดสินใจว่า ต้องทำการ rollout/deploy การเปลี่ยนแปลงใด
เมื่อผ่านไปสักระยะ จะเริ่มเห็นรูปแบบการทำงาน
และทำการสร้าง algorithm สำหรับตัดสินใจว่า rollout/deploy อะไรบ้างขึ้นมา
โดยรูปแบบที่ได้คือ
- ต้องผ่านการทดสอบทั้งหมด
- จำนวนการเปลี่ยนแปลงต้องน้อย ๆ
แต่ถ้ามีจำนวนการเปลี่ยนแปลงที่ผ่านการทดสอบมาก ๆ
จะเลือกมาเพียง 3 การเปลี่ยนแปลงเท่านั้น
จากนั้นจำเป็นต้องมี algorithm สำหรับการตรวจสอบผลการ rollout/deploy ด้วย
ว่าการทำงานมันสำเร็จ หรือ ล้มเหลว
นั่นคือ ถ้ามีเครื่องที่ทำการ deploy ผิดพลาดเกิน 1%
แสดงว่าการ deploy ครั้งนั้นล้มเหลว
ดังนั้นเมื่อระบบบอกว่า การเปลี่ยนแปลง A ต้องทำการ deploy แล้วนะ
ระบบการ deploy จะทำงานแบบอัตโนมัติ ดังนี้
- ทำการ deploy การเปลี่ยนแปลง A ไปยัง Canary server
- ทำการทดสอบอีกรอบ
- ทำการ deploy ไปยังทุก ๆ เครื่อง
โดยในช่วงแรก ๆ นั้นจะมีคนที่มาดูแลการ deploy
แต่เมื่อผ่านไปสักระยะ ก็ไม่จำเป็นต้องมีคนมาดูแลอีกต่อไปแล้ว
แต่เส้นทางนี้ ใช่ว่าจะโรยด้วยกลีบกุหลาบ ปัญหาก็เพียบเช่นกัน !!
โดยมีข้อผิดพลาด และ บกพร่องไปมากมาย อาทิเช่น
การทดสอบที่ผิดพลาดและล่าช้า
นั่นคือ การทดสอบมันผิดพลาดได้ง่าย หรือ ไม่เสถียรนั่นเอง
บางครั้งทดสอบผ่าน บางครั้งทดสอบผิดพลาด
รวมทั้งการทดสอบมันช้า !!
แทนที่ระบบการทำงานจะดี กลับสร้างปัญหาให้อีก
มันขัดแย้งกับข้อดีของ Continuous Deployment เลยนะ
ดังนั้นจึงต้องลงทั้งแรงกายและแรงใจ
เพื่อปรับปรุงให้การทดสอบจากเดิมที่ใช้เวลา 12-15 นาที ให้เหลือเพียง 5 นาที
รวมทั้งแก้ไขระบบ infrastructure เพื่อทำให้ระบบการทดสอบมีความน่าเชื่อถือ และ เสถียรขึ้น
ส่วนเรื่อง backlog ยังอ่านไม่เข้าใจ ขอข้ามไปก่อน !!
มาดูเรื่อง Key Principle หรือแนวคิดของการสร้างกันหน่อยว่ามีอะไรบ้าง ?
1. Tests หรือชุดการทดสอบแบบอัตโนมัติ
ต้องทำงานอย่างรวดเร็ว
มีจำนวน test coverage ที่เหมาะสม ไม่จำเป็นต้อง 100%
เนื่องจากการทดสอบต้องทดสอบอยู่บ่อย ๆ
ทั้งก่อนส่งการเปลี่ยนแปลง
ทั้งระหว่างการทำ code review
ทั้งหลังจากการ deploy
2. Canary
ต้องมี canary server เพื่อป้องกันการ deploy การเปลี่ยนแปลงที่แย่ ๆ ขึ้นไป
แน่นอนว่า ไม่ได้ต้องการการทำงานที่สมบูรณ์แบบ
แต่ต้องการเพียงข้อมูลเชิงสถิติแบบง่าย ๆ
เพื่อช่วยวิเคราะห์ว่า แต่ละการเปลี่ยนแปลงส่งผลกระทบอย่างไร
3. Automate the normal case
เราไม่สามารถให้ทำงานแบบอัตโนมัติได้ทุก ๆ กรณี
ดังนั้น ให้สร้างระบบทำงานแบบอัตโนมัติ
เฉพาะส่วนที่เรารู้ และเป็นกรณีแบบปกติทั่วไป
แต่ถ้ามีเหตุการณ์หรือกรณีอะไรที่ดูแปลก ๆ หรือผิดปกติ
ให้ระบบหยุดการทำงานทันที และให้คนเข้ามาจัดการต่อไป
4. Make people comfortable
ปัญหาเรื่องคน มันคือกำแพงที่ยิ่งใหญ่และใหญ่ยิ่ง
ของการสร้างระบบการทำงานแบบอัตโนมัติ
เนื่องจากคนที่ทำงานอยู่ตรงนั้นก่อนหน้านี้ จะรู้สึกว่า
ตัวเองไม่มีความสำคัญ และ ไม่สามารถควบคุมอะไรเองได้เลย
ดังนั้นสิ่งที่ต้องทำก็คือ
การทำงานของระบบต้องแสดงออกมาให้ทุกคนเห็นอย่างชัดเจน
ว่ามีงานอะไรที่ทำเสร็จไปแล้วบ้าง
ว่ามีงานอะไรที่กำลังทำอยู่บ้าง
ว่าสิ่งที่ทำคืออะไร
เพื่อทำให้เห็นว่า สิ่งต่าง ๆ เหล่านี้มันเข้ามาช่วยนะ
5. Expect bad deploys
ต้องทำการระบุว่าการเปลี่ยนแปลงใดที่มันแย่ ๆ ให้เร็วที่สุด
เพื่อทำให้เราสามารถ rollback ได้รวดเร็ว
นั่นคือลดผลกระทบจากความผิดพลาดนั่นเอง
สิ่งต่าง ๆ เหล่านี้ทุกบริษัทสามารถนำไปสร้างเองได้เลย
โดยที่ระบบ Continuous Deployment ไม่จำเป็นต้องมีความซับซ้อน
ให้เริ่มจากวิธีการที่ง่าย ๆ เน้นทำตามแนวคิดทั้ง 5 ข้อ
เพื่อทำการแก้ไข และ ปรับปรุงกันต่อไป
สุดท้ายแล้วระบบ Continuous Deployment ของ Instagram ยังคงพัฒนาต่อไป
แน่นอนว่าในตอนนี้ ระบบมันยังทำงานได้ดี และ เหมาะสมสำหรับสถานะปัจจุบันของระบบ
แต่ก็ยังมีสิ่งต่าง ๆ มากมายที่ต้องทำการปรับปรุง ดังนี้
Keeping it fast
เนื่องจากระบบของ Instgram มันโตขึ้นสูงมาก ๆ
ทำให้จำนวนการเปลี่ยนแปลงสูงมากเช่นเดียวกัน
ดังนั้นต้องการให้ระบบ rollout/deploy ให้เร็วที่สุดเท่าที่จะทำได้
วิธีการหนึ่งที่น่าจะเอาเข้ามาทำคือ
การแบ่งการ rollout/deploy ออกเป็นหลาย ๆ สถานะ
และสร้าง pipeline ของการทำงานขึ้นมา
Adding canary
เนื่องจากนำนวนการเปลี่ยนแปลงสูงขึ้น
เครื่อง canary ก็ได้กลายเป็นปัญหาคอขวด
ดังนั้นการเพิ่มเครื่อง canary จึงมีความสำคัญมาก
More data
สิ่งที่ต้องการคือ ข้อมูล
เพื่อทำให้ระบบรู้ว่า การเปลี่ยนแปลงใด ๆ มันแย่ได้ดีขึ้น
เพื่อขจัดสิ่งที่แย่ ๆ ออกไปจากสายการ rollout/deploy
เช่น logging การทำงานของแต่ละ feature กันไปเลย
Improving detection
ทำการปรับปรุงการตรวจสอบหลังจากทำการ rollout/deploy ออกไปแล้ว
แทนที่จะทำเพียงการทดสอบ และ deploy ไปทุก ๆ เครื่อง
ก็น่าจะทำการแบ่งการ deploy ออกเป็น region หรือ cluster
จากนั้นทำการตรวจสอบและตัดสินใจว่า จะทำการ deploy ต่อไปหรือไม่
เป็นอย่างไรบ้างสำหรับระบบ Continuous Deployment ของ Instagram
น่าจะพอทำให้เห็นว่า
การ rollout/deploy ทุก ๆ การเปลี่ยนแปลง
มันเป็นเรื่องที่เป็นไปได้
และช่วยลดความเสี่ยงจากข้อผิดพลาดต่าง ๆ ด้วยสิ
อะไรที่มันเจ็บก็ให้ทำบ่อย ๆ กันนะครับ
ต้องสร้างระบบขึ้นมา โดยมีพื้นฐานอยู่บนสิ่งที่เรียกว่า
คุณภาพ
และความไว้เนื้อเชื่อใจกันนั่นเอง
รวมทั้งต้องค่อย ๆ สร้างขึ้นมาและเรียนรู้ไปกับมัน
แต่คำถามที่น่าจะอยู่ในใจของใครหลาย ๆ คนคือ
แล้วแต่ละการเปลี่ยนแปลงมันเป็นอย่างไร ?
เป็น feature ?
เป็น bug ?
เป็น ....
ผมก็ไม่รู้เหมือนกัน แต่เชื่อว่าแต่ละการเปลี่ยนแปลงต้องมีคุณค่าสิ !!

 นั่งอ่านบทความเรื่อง Compile ‘android:best:1.1.1’
มันมีเนื้อหาที่ Android Developer ทุกคนไม่น่าพลาด
ประกอบไปด้วย
นั่งอ่านบทความเรื่อง Compile ‘android:best:1.1.1’
มันมีเนื้อหาที่ Android Developer ทุกคนไม่น่าพลาด
ประกอบไปด้วย

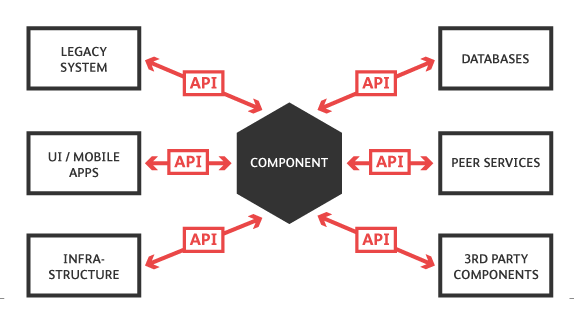 จากการพูดคุยเรื่อง
จากการพูดคุยเรื่อง 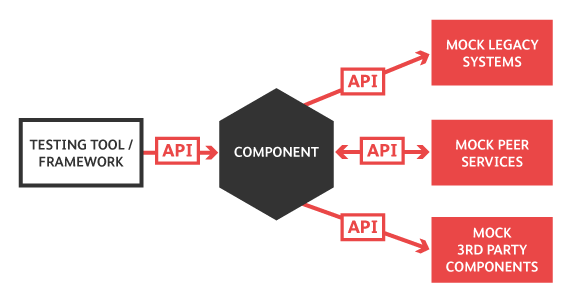 ทั้งสองแนวทางนั้น ต้องแก้ไข code เดิมให้ทดสอบได้ง่ายขึ้น
แน่นอนว่า code ดีขึ้นแน่นอน
และ code แต่ละส่วนควรมี Unit testing ครอบคลุมเสมอนะ
เพื่อทำให้เรารู้ว่า กำลังทำอะไร แก้ไขปัญหาอะไร และ จะทำงานเสร็จเมื่อไร
ทั้งสองแนวทางนั้น ต้องแก้ไข code เดิมให้ทดสอบได้ง่ายขึ้น
แน่นอนว่า code ดีขึ้นแน่นอน
และ code แต่ละส่วนควรมี Unit testing ครอบคลุมเสมอนะ
เพื่อทำให้เรารู้ว่า กำลังทำอะไร แก้ไขปัญหาอะไร และ จะทำงานเสร็จเมื่อไร

 วันนี้มานั่งฟังการแบ่งปันเรื่อง Docker ที่
วันนี้มานั่งฟังการแบ่งปันเรื่อง Docker ที่  ตัวอย่างของ Dockerfile และ python project อยู่ที่
ตัวอย่างของ Dockerfile และ python project อยู่ที่ 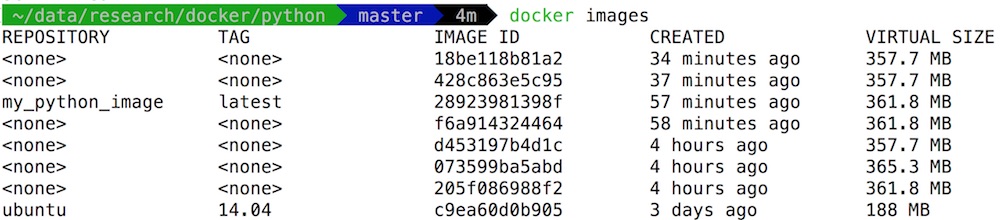 ขนาด image เมื่อใช้ Alpine
ขนาด image เมื่อใช้ Alpine


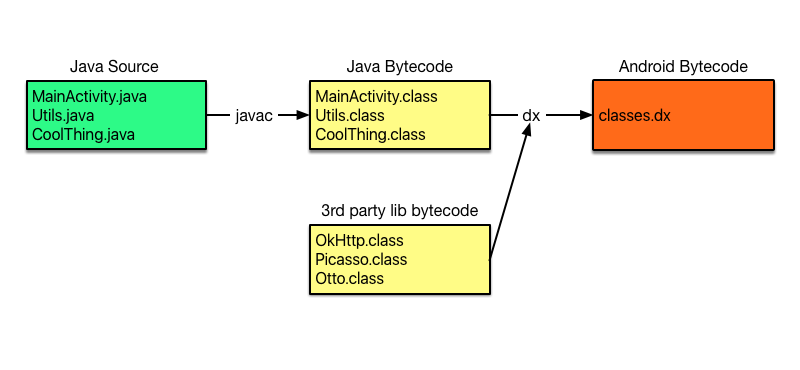
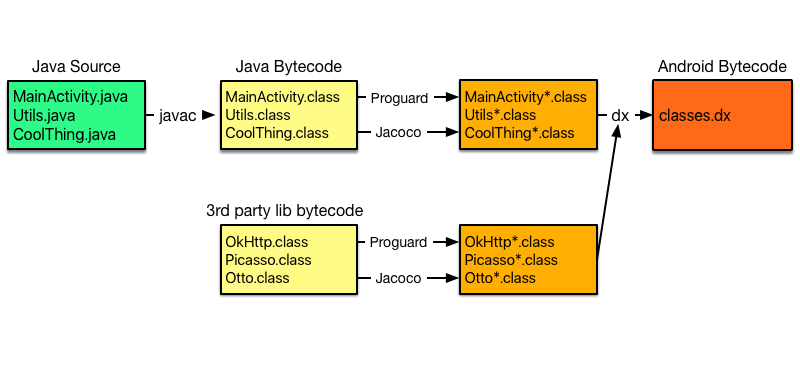
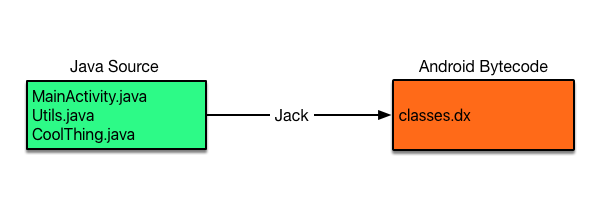

 จากบทความเรื่อง
จากบทความเรื่อง 
 วันนี้เห็นมีการ share บทความเรื่อง
วันนี้เห็นมีการ share บทความเรื่อง 
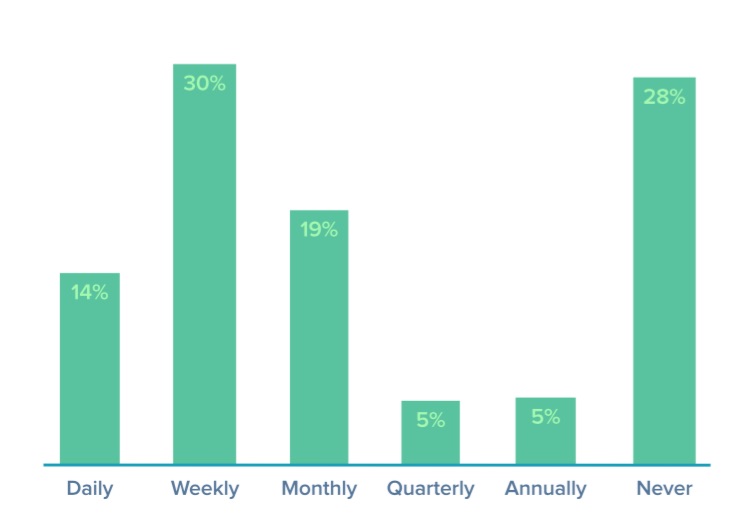
 ข้อมูลจากผลแบบสำรวจ
ข้อมูลจากผลแบบสำรวจ 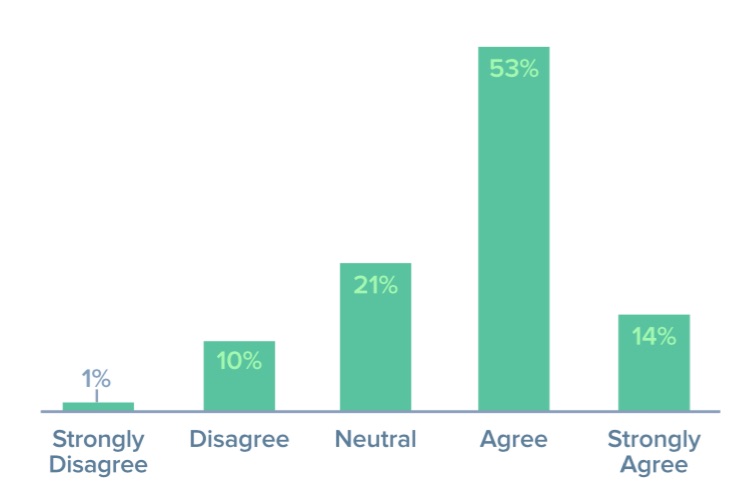
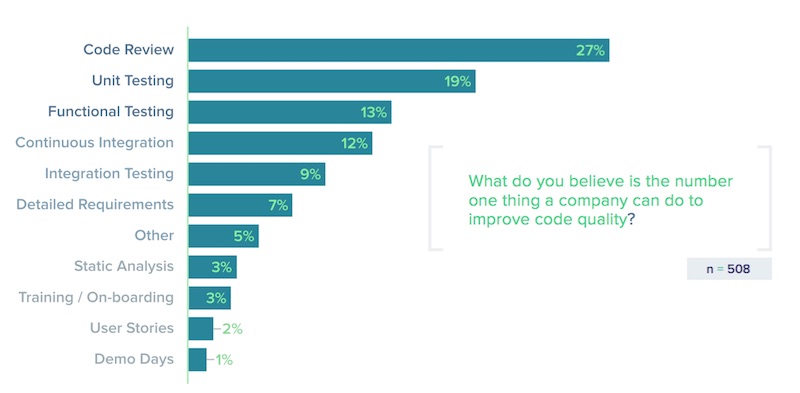 สิ่งที่เราได้รับรู้ก็คือ Code Review และ Unit testing
มันส่งผลอย่างมากต่อคุณภาพของระบบงาน
โดยทั้งสองเรื่องมันไม่ใช่สิ่งแปลกใหม่อะไรเลยในการพัฒนา software
แต่มันทำให้เราเห็นชัดขึ้นว่า
ทีมพัฒนา software เริ่มมีความรู้ความเข้าใจแล้วว่า
ทั้ง Code Review และ Unit testing มันมีความสำคัญอย่างไร !!
สิ่งที่เราได้รับรู้ก็คือ Code Review และ Unit testing
มันส่งผลอย่างมากต่อคุณภาพของระบบงาน
โดยทั้งสองเรื่องมันไม่ใช่สิ่งแปลกใหม่อะไรเลยในการพัฒนา software
แต่มันทำให้เราเห็นชัดขึ้นว่า
ทีมพัฒนา software เริ่มมีความรู้ความเข้าใจแล้วว่า
ทั้ง Code Review และ Unit testing มันมีความสำคัญอย่างไร !!
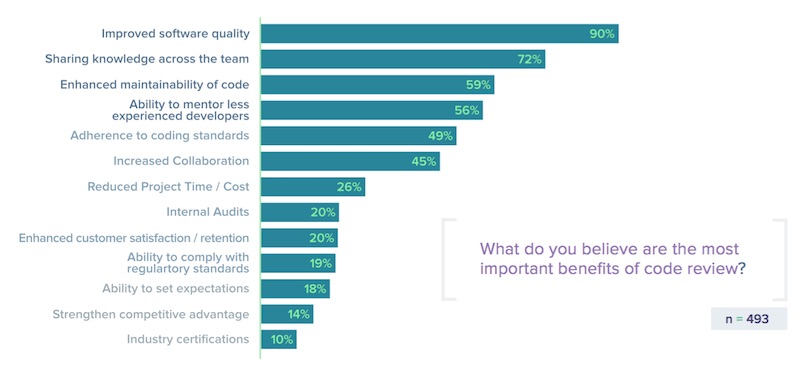
 โดยรูปแบบในการทำ Code Review นั้นจะมี 2 แบบคือ
โดยรูปแบบในการทำ Code Review นั้นจะมี 2 แบบคือ
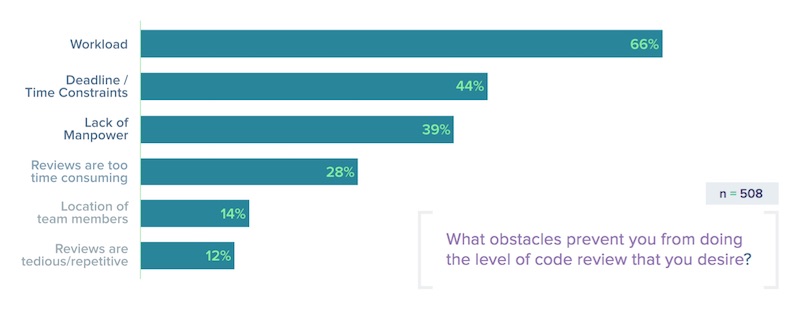 ซึ่งถือว่าเป็นอีกหนึ่งความท้าทายขององค์กร และ ทีมพัฒนา ว่า
ถ้าต้องการปรับปรุงคุณภาพของระบบงานแล้ว
คุณก็ต้องพยายามลดปัญหาและอุปสรรคเหล่านี้ลงไป
เพราะว่า ปัญหาและอุปสรรคเหล่านี้ มันไม่ใช่เรื่องแปลกใหม่ในการพัฒนา software เลยนะ
สามารถอ่านเพิ่มเติมได้ที่
ซึ่งถือว่าเป็นอีกหนึ่งความท้าทายขององค์กร และ ทีมพัฒนา ว่า
ถ้าต้องการปรับปรุงคุณภาพของระบบงานแล้ว
คุณก็ต้องพยายามลดปัญหาและอุปสรรคเหล่านี้ลงไป
เพราะว่า ปัญหาและอุปสรรคเหล่านี้ มันไม่ใช่เรื่องแปลกใหม่ในการพัฒนา software เลยนะ
สามารถอ่านเพิ่มเติมได้ที่ 
 Spaghetti Driven Development มันเป็นอย่างไร ?
เป็นอีกหนึ่งวิธีการของการพัฒนา software !!
โดยมีขั้นตอนดังนี้
Spaghetti Driven Development มันเป็นอย่างไร ?
เป็นอีกหนึ่งวิธีการของการพัฒนา software !!
โดยมีขั้นตอนดังนี้

 ก่อนจะนำการทดสอบแบบอัตโนมัติเข้ามาประยุกต์ใช้งานนั้น
สิ่งที่ควรต้องพิจารณาก่อนคือ
ประโยชน์ที่จะได้รับ และ ค่าใช้จ่ายที่ต้องลงทุนไป
ซึ่งทั้งสองอย่างนี้ต้องมีความสมดุลกันนะ
โดยทำการสรุปไว้ดังนี้
ก่อนจะนำการทดสอบแบบอัตโนมัติเข้ามาประยุกต์ใช้งานนั้น
สิ่งที่ควรต้องพิจารณาก่อนคือ
ประโยชน์ที่จะได้รับ และ ค่าใช้จ่ายที่ต้องลงทุนไป
ซึ่งทั้งสองอย่างนี้ต้องมีความสมดุลกันนะ
โดยทำการสรุปไว้ดังนี้

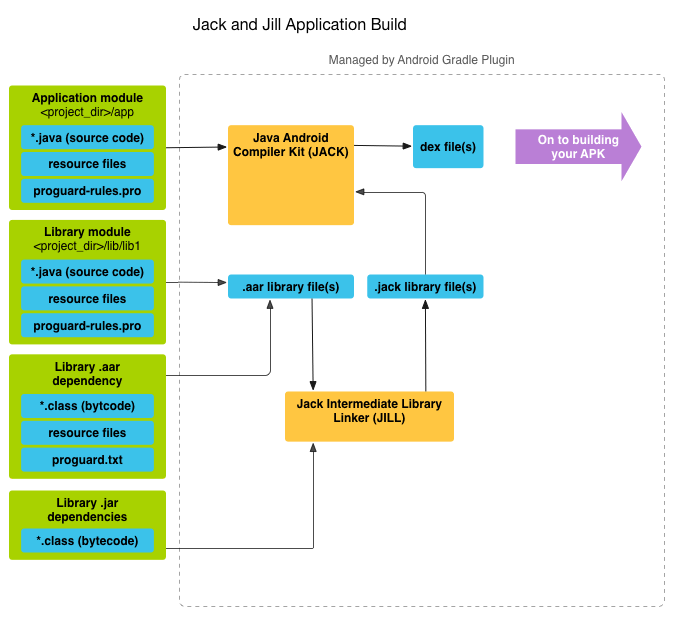
 ทีมพัฒนา Android เพิ่งปล่อย Android N Preview ออกมา (ก็นานอยู่นะ)
ซึ่งมีการเพิ่มเติมและปรับปรุงความสามารถต่าง ๆ มากมาย
หนึ่งในนั้นคือ feature ต่าง ๆ จาก Java 8
สำหรับ Jack compiler เท่านั้นนะ
ดังนั้นเมื่อมีของใหม่ ๆ ออกมาให้ลอง
จะพลาดได้อย่างไร มาลองใช้งานกันดูสักหน่อย
ถ้าใครยังไม่รู้จัก Jack compiler แนะนำให้ไปอ่าน
blog เรื่อง
ทีมพัฒนา Android เพิ่งปล่อย Android N Preview ออกมา (ก็นานอยู่นะ)
ซึ่งมีการเพิ่มเติมและปรับปรุงความสามารถต่าง ๆ มากมาย
หนึ่งในนั้นคือ feature ต่าง ๆ จาก Java 8
สำหรับ Jack compiler เท่านั้นนะ
ดังนั้นเมื่อมีของใหม่ ๆ ออกมาให้ลอง
จะพลาดได้อย่างไร มาลองใช้งานกันดูสักหน่อย
ถ้าใครยังไม่รู้จัก Jack compiler แนะนำให้ไปอ่าน
blog เรื่อง 



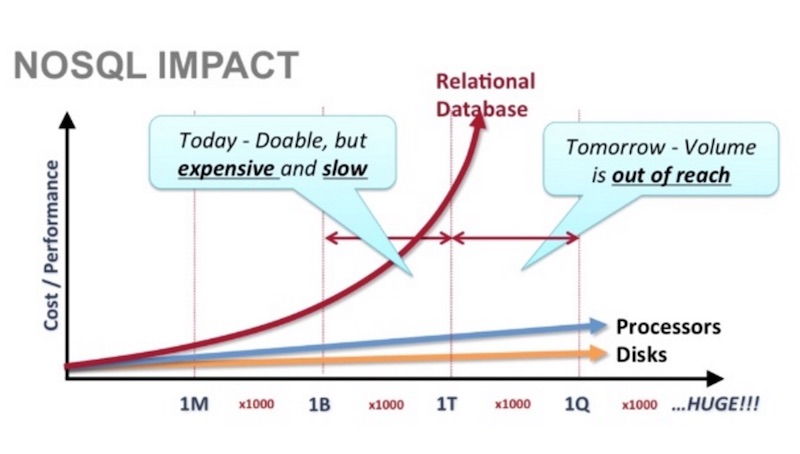 ดังนั้นยักษ์ใหญ่แห่งวงการ internet คือ Google และ Amazon
จึงสร้างระบบจัดการข้อมูลของตัวเองขึ้นมา
Google สร้าง
ดังนั้นยักษ์ใหญ่แห่งวงการ internet คือ Google และ Amazon
จึงสร้างระบบจัดการข้อมูลของตัวเองขึ้นมา
Google สร้าง 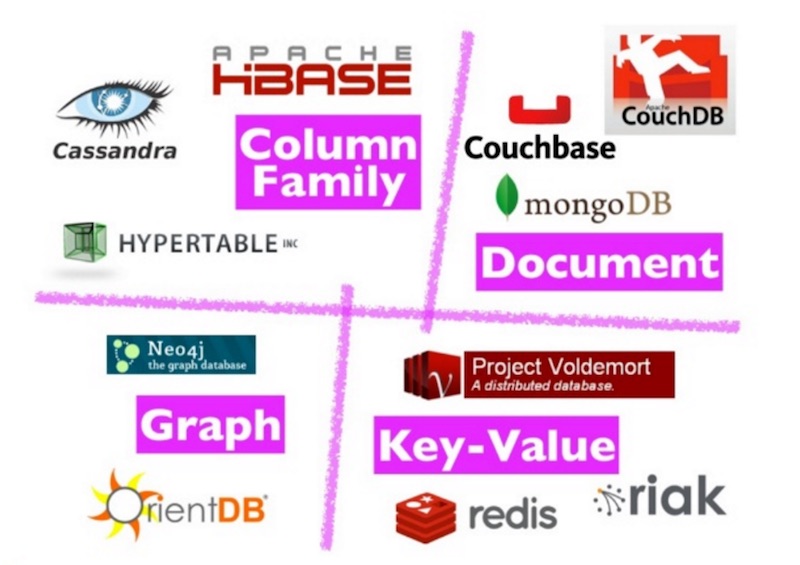
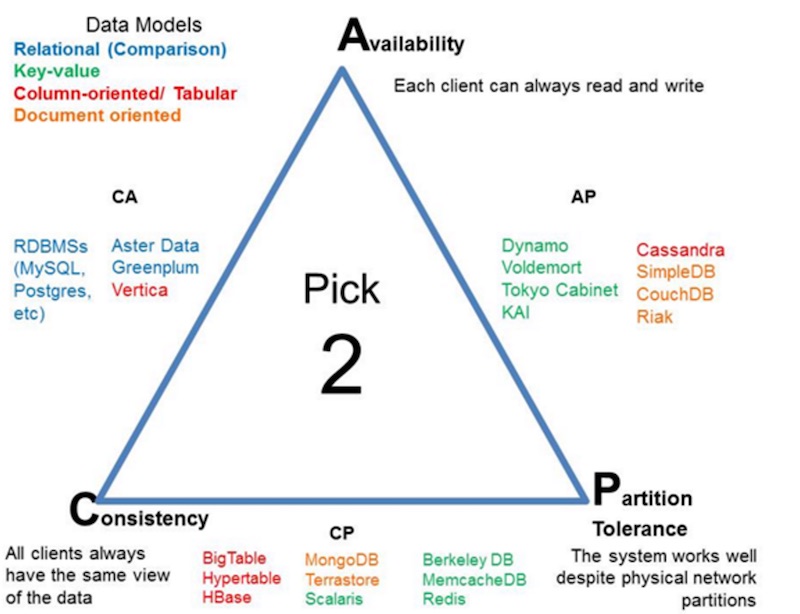 โดยที่ CA คือ RDBMS
ดังนั้นจึงเหลือเพียง 2 ทางเลือกคือ CP และ AP
ซึ่งเป็นทางเลือกของการสร้าง NoSQL ชนิดต่าง ๆ นั่นเอง
จะเลือก CP หรือ AP นั่นคือ สิ่งที่คุณต้องตัดสินใจ
ว่าระบบของคุณจะเลือกอะไรระหว่า Consistency กับ Availability
ส่วน Partition tolerance มันเป็นความสามารถที่ NoSQL ทุกตัวต้องทำได้
โดยที่ CA คือ RDBMS
ดังนั้นจึงเหลือเพียง 2 ทางเลือกคือ CP และ AP
ซึ่งเป็นทางเลือกของการสร้าง NoSQL ชนิดต่าง ๆ นั่นเอง
จะเลือก CP หรือ AP นั่นคือ สิ่งที่คุณต้องตัดสินใจ
ว่าระบบของคุณจะเลือกอะไรระหว่า Consistency กับ Availability
ส่วน Partition tolerance มันเป็นความสามารถที่ NoSQL ทุกตัวต้องทำได้

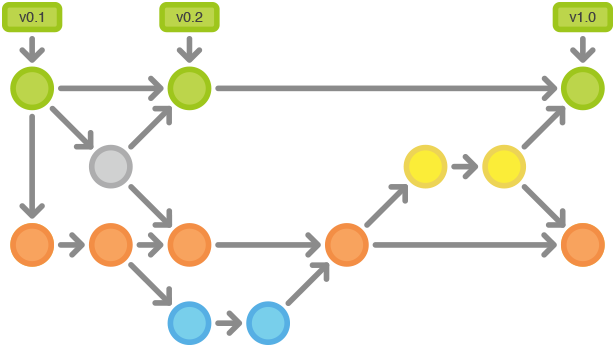 วันนี้มีโอกาสไปแบ่งปันเรื่อง Branching Strategy
ในงาน
วันนี้มีโอกาสไปแบ่งปันเรื่อง Branching Strategy
ในงาน  แต่คนส่วนใหญ่กลับไม่อ่านข้อนี้ !!
แต่คนส่วนใหญ่กลับไม่อ่านข้อนี้ !!
 คำถามต่อไปคือ
แนวทางเหล่านี้มันเหมาะสมกับระบบงานของเราหรือไม่ ?
แนวทางเหล่านี้มันเหมาะสมกับทีมของเราหรือไม่ ?
แนวทางเหล่านี้ได้รับการสนับสนุนจากฝ่าย management หรือไม่ ?
ถ้าได้รับคำตอบที่ดี ก็น่าจะทำให้ผลออกมามันดี
แต่ส่วนใหญ่จะได้ผลตรงกันข้าม !!
คำถามต่อไปคือ
แนวทางเหล่านี้มันเหมาะสมกับระบบงานของเราหรือไม่ ?
แนวทางเหล่านี้มันเหมาะสมกับทีมของเราหรือไม่ ?
แนวทางเหล่านี้ได้รับการสนับสนุนจากฝ่าย management หรือไม่ ?
ถ้าได้รับคำตอบที่ดี ก็น่าจะทำให้ผลออกมามันดี
แต่ส่วนใหญ่จะได้ผลตรงกันข้าม !!

 วันนี้มีโอกาสแลกเปลี่ยนแนวทางการทดสอบ Web application
โดยเครื่องมือที่ได้รับความนิยมอย่างมาก ก็คือ
วันนี้มีโอกาสแลกเปลี่ยนแนวทางการทดสอบ Web application
โดยเครื่องมือที่ได้รับความนิยมอย่างมาก ก็คือ 
 จากหนังสือ
จากหนังสือ 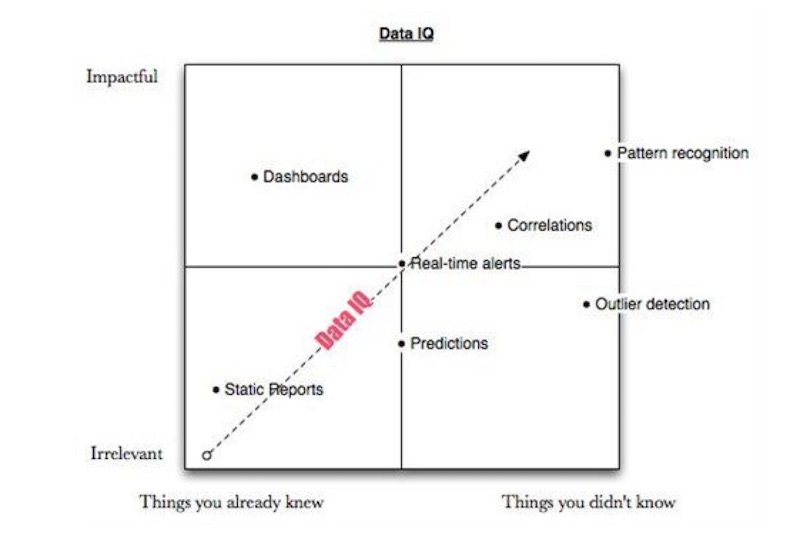 คำอธิบาย
เริ่มจาก Static Report
เป็นรายงานทั่วไปที่จะตอบคำถามต่าง ๆ ที่เราต้องการ
ซึ่งเป็นสิ่งที่เฉพาะเจาะจงมาก ๆ
โดยใน Data IQ นั้นใช้ประโยชน์ได้น้อยที่สุด
และเป็นงานที่น่าเบื่อที่สุด
แต่เป็นสิ่งที่ใช้งานมากที่สุด !!!
Dashboard
ทำการแสดงข้อมูล และ คำตอบต่าง ๆ ที่เราต้องการ
และทำการ update ข้อมูลเหล่านั้นแบบ real-time
แต่ข้อมูลที่แสดงใน dashboard นั้น
จะตอบคำถามเท่าที่เราตั้งไว้ตั้งแต่แรก
ซึ่งไม่สามารถเปลี่ยนแปลงได้ ทำให้มันไม่ค่อยยืดหยุ่นสักเท่าไรนัก
Outlier หรือ ข้อมูลที่ผิดปกติ
เราสามารถค้นหาและตรวจจับข้อมูลเหล่านี้ได้
เพื่อนำมาวิเคราะห์หาโอกาส และ คำเตือนต่าง ๆ ได้
บางครั้งข้อมูลเหล่านี้อาจจะมีขนาดใหญ่มาก ๆ
หรือเล็กมาก ๆ จนไม่สามารถมองเห็นด้วยตา
มันทำให้เราเข้าใจข้อมูลที่มีอยู่ในมือมากยิ่งขึ้น
Correlation หรือ ความสัมพันธ์ของข้อมูล
เราสามารถค้นหาและตรวจจับข้อมูลเหล่านี้ได้
เพื่อค้นหาข้อมูลที่มีความสำคัญ
เช่นเมื่อข้อมูลมีการเปลี่ยนแปลงจะส่งผลกระทบอย่างไรบ้าง ?
แนวโน้มของข้อมูลเป็นอย่างไร ?
รูปแบบของข้อมูลเป็นอย่างไร ?
Prediction หรือ การทำนายสิ่งต่าง ๆ ที่จะเกิดขึ้นในอนาคต
เป็นสิ่งที่มีประโยชน์อย่างมาก
แต่มักมีข้อจำกัดที่มาจากข้อมูลนั่นเอง
เช่นข้อมูลที่นำมาใช้ในการทำนายไม่ถูกต้อง ไม่ครบ หรือ เลือกข้อมูลผิด เป็นต้น
แต่ถ้าสามารถแก้ไขปัญหาเหล่านี้ไปได้
จะทำให้การ Prediction มีประโยชน์อย่างสุด ๆ ไปเลย
Pattern recognition แปลเป็นไทยคือ การรู้จำรูปแบบ !!
เป็นคำที่พูดถึงกันอย่างกว้างขวาง และ มีประสิทธิภาพอย่างสูง
ซึ่งมันประกอบไปด้วยแนวคิดต่าง ๆ ดังต่อไปนี้
คำอธิบาย
เริ่มจาก Static Report
เป็นรายงานทั่วไปที่จะตอบคำถามต่าง ๆ ที่เราต้องการ
ซึ่งเป็นสิ่งที่เฉพาะเจาะจงมาก ๆ
โดยใน Data IQ นั้นใช้ประโยชน์ได้น้อยที่สุด
และเป็นงานที่น่าเบื่อที่สุด
แต่เป็นสิ่งที่ใช้งานมากที่สุด !!!
Dashboard
ทำการแสดงข้อมูล และ คำตอบต่าง ๆ ที่เราต้องการ
และทำการ update ข้อมูลเหล่านั้นแบบ real-time
แต่ข้อมูลที่แสดงใน dashboard นั้น
จะตอบคำถามเท่าที่เราตั้งไว้ตั้งแต่แรก
ซึ่งไม่สามารถเปลี่ยนแปลงได้ ทำให้มันไม่ค่อยยืดหยุ่นสักเท่าไรนัก
Outlier หรือ ข้อมูลที่ผิดปกติ
เราสามารถค้นหาและตรวจจับข้อมูลเหล่านี้ได้
เพื่อนำมาวิเคราะห์หาโอกาส และ คำเตือนต่าง ๆ ได้
บางครั้งข้อมูลเหล่านี้อาจจะมีขนาดใหญ่มาก ๆ
หรือเล็กมาก ๆ จนไม่สามารถมองเห็นด้วยตา
มันทำให้เราเข้าใจข้อมูลที่มีอยู่ในมือมากยิ่งขึ้น
Correlation หรือ ความสัมพันธ์ของข้อมูล
เราสามารถค้นหาและตรวจจับข้อมูลเหล่านี้ได้
เพื่อค้นหาข้อมูลที่มีความสำคัญ
เช่นเมื่อข้อมูลมีการเปลี่ยนแปลงจะส่งผลกระทบอย่างไรบ้าง ?
แนวโน้มของข้อมูลเป็นอย่างไร ?
รูปแบบของข้อมูลเป็นอย่างไร ?
Prediction หรือ การทำนายสิ่งต่าง ๆ ที่จะเกิดขึ้นในอนาคต
เป็นสิ่งที่มีประโยชน์อย่างมาก
แต่มักมีข้อจำกัดที่มาจากข้อมูลนั่นเอง
เช่นข้อมูลที่นำมาใช้ในการทำนายไม่ถูกต้อง ไม่ครบ หรือ เลือกข้อมูลผิด เป็นต้น
แต่ถ้าสามารถแก้ไขปัญหาเหล่านี้ไปได้
จะทำให้การ Prediction มีประโยชน์อย่างสุด ๆ ไปเลย
Pattern recognition แปลเป็นไทยคือ การรู้จำรูปแบบ !!
เป็นคำที่พูดถึงกันอย่างกว้างขวาง และ มีประสิทธิภาพอย่างสูง
ซึ่งมันประกอบไปด้วยแนวคิดต่าง ๆ ดังต่อไปนี้


 Failed test or exam and disappointed woman[/caption]
คำถามที่น่าสนใจเกี่ยวกับ Test-Driven Development (TDD)
Failed test or exam and disappointed woman[/caption]
คำถามที่น่าสนใจเกี่ยวกับ Test-Driven Development (TDD)



 คำถามที่มักได้ยินมาเสมอ
ฟังดูแล้ว TDD (Test-Driven Development) มันเป็นแนวคิดที่ดีนะ
แต่เราควรนำมาใช้หรือเปล่านะ ?
มันเหมาะสมกับเราหรือเปล่านะ ?
ก่อนที่จะตอบนั้น ผมแนะนำให้ทดลองก่อนไหม
ว่าแนวคิด และ เทคนิคของ TDD
มันช่วยปรับปรุง code และ การพัฒนาระบบงานหรือไม่ ?
คำถามที่มักได้ยินมาเสมอ
ฟังดูแล้ว TDD (Test-Driven Development) มันเป็นแนวคิดที่ดีนะ
แต่เราควรนำมาใช้หรือเปล่านะ ?
มันเหมาะสมกับเราหรือเปล่านะ ?
ก่อนที่จะตอบนั้น ผมแนะนำให้ทดลองก่อนไหม
ว่าแนวคิด และ เทคนิคของ TDD
มันช่วยปรับปรุง code และ การพัฒนาระบบงานหรือไม่ ?

 คำถามที่น่าสนใจสำหรับการนำ Robotframework
มาใช้ทดสอบ web application ที่มีหลายภาษาคือ
จะทำการทดสอบอย่างไรดี ?
จะทำการวางโครงสร้างอย่างไรดี ?
คำถามที่น่าสนใจสำหรับการนำ Robotframework
มาใช้ทดสอบ web application ที่มีหลายภาษาคือ
จะทำการทดสอบอย่างไรดี ?
จะทำการวางโครงสร้างอย่างไรดี ?

 วันนี้ไปแบ่งปันเรื่อง
วันนี้ไปแบ่งปันเรื่อง 
 หลังจากอ่านบทความเรื่อง
หลังจากอ่านบทความเรื่อง