![perf]()
![perf]()
ทำการแปลบางส่วนจากบทความเรื่อง
Performance Testing in a Nutshell
ซึ่งทำการอธิบายเรื่องของ Performance Testing ได้อย่างน่าสนใจ
ทั้งแนวคิด และ แนวทางในการทดสอบ
ทั้งการเตรียม environment ต่าง ๆ
ทั้งการเขียน script เพื่อทดสอบ
ทั้งการวิเคราะห์ผลการทดสอบ
ทั้งการ monitoring ระบบ
และ Lesson learn ต่าง ๆ
ดังนั้น เรามาเริ่มเดินทางไปยัง Performance Testing กันเลย
เรื่องของ Performance testing เป็นสิ่งที่มักหลงลืมกันได้ง่าย
แต่มักจะมีความสำคัญเมื่อถึงเวลาส่งมอบระบบงาน (Deadline)
เนื่องจาก เรามักทดสอบในช่วงท้ายของการพัฒนาระบบงาน
ทำเหมือนกับว่า การทดสอบมันไม่จำเป็น หรือ เป็นชนชั้นที่สอง !!
คำถามคือ ถ้าทดสอบแล้วไม่ผ่านจะต้องทำอย่างไร ?
1. ต้องแก้ไขให้ทดสอบผ่านให้ได้ บ่อยครั้งต้องรื้อ !!
2. ขยายเครื่องได้ไหม ? บ่อยครั้งมันคือการหนีปัญหา
3. ปล่อยมันไปก่อน พยายามพูดต่าง ๆ นานา เพื่อให้ลูกค้ายอมรับ
4. ???
ดังนั้น ความท้าทายหนึ่งที่ เราจะต้องทำก็คือ
การทำ Performance testing ตั้งแต่เริ่มการพัฒนาระบบงาน
แต่ว่าจะทำอย่างไรดีล่ะ ?
ก่อนจะเริ่มทำการทดสอบ ควรต้องทำความเข้าใจระบบ
โดยเริ่มจากการตั้งคำถาม ตัวอย่างเช่น
ระบบงานเป็นอย่างไร ?
จะเตรียม traffic สำหรับทดสอบเท่าไร ? เป็นการประมาณการล้วน ๆ
จะทำการวิเคราะห์ผลการทดสอบอย่างไร ?
ซึ่งควรนำข้อมูลจากอดีตมาเป็นข้อมูลตั้งต้น
และข้อมูลคาดการณ์ในอนาคตมาไว้เป็นเป้าหมาย
ถ้าระบบมีผู้ใช้งานที่สูงมาก ๆ จนรับไหมไหวแล้ว
ระบบจะมีวิธีการรองรับ และ จัดการอย่างไร ?
คำถามเหล่านี้ ควรถามตั้งแต่เริ่มต้นของการพัฒนาระบบ
เพื่อให้เห็นถึงความสำคัญ ว่ามันกระทบต่อ business อย่างไร
เพื่อให้เห็นว่าต้องลงทุนในเรื่องนี้ด้วย
แล้วจะทำให้เห็นค่าใช้จ่ายรวมที่ชัดเจนมากยิ่งขึ้น
คำเตือน
อย่าปล่อยให้การพูดคุยเรื่อง Performance test ไปอยู่ช่วงกลาง หรือ ช่วงท้ายของการพัฒนา
มิเช่นนั้น ค่าใช้จ่ายมันจะเพิ่มแบบทวีคูณ
ในการพัฒนาระบบงานนั้น
เรื่องการทดสอบ Performance ควรจะต้องเกิดขึ้นอยู่อย่างเสมอ
และเป็นสิ่งที่ต้องการการทำงานเป็นทีม
ทั้ง developer, tester, operation และคนที่เกี่ยวข้อง
เพื่อทำการทดสอบ ดูแลรักษาระบบ
และให้ผลการทดสอบมันใกล้กับสิ่งที่คาดหวังไว้
เนื่องจากการทดสอบมันต้องการคนที่มีความรู้มากมาย
ไว้ว่าจะเป็นเรื่อง การเขียน test script
ไม่ว่าจะเป็นเรื่อง การใช้เครื่องมือ
ไม่ว่าจะเป็นเรื่อง การวิเคราะห์ผล
ไม่ว่าจะเป็นเรื่อง การ monitoring ระบบ
ไม่ว่าจะเป็นเรื่อง แผนการทดสอบ
ไม่ว่าจะเป็นเรื่อง การทดสอบซ้ำ ซึ่งต้อง reset ระบบกลับไปยังจุดเริ่มต้นเหมือนกัน
ไม่ว่าจะเป็น ....
มันเยอะมาก ๆ
ดังนั้นมาดูกันว่า เราจะต้องเตรียมอะไรกันบ้าง ?
1. เรื่องของ Environment
ถ้าเป็นแต่ก่อนเราจะใช้เครื่องภายในองค์กร
แต่มันก็มีข้อจำกัดหลาย ๆ อย่าง
ซึ่งปัจจุบันมีเรื่องของ Cloud เข้ามาช่วย
ทำให้การทดสอบมันง่ายและสะดวกมากยิ่งขึ้น
ที่สำคัญ การดูแลรักษาก็ง่ายกว่าเดิมอีก
แต่ถ้าองค์กรไหนที่มีข้อจำกัดมากมาย
เช่นการเข้าถึง server ต่าง ๆ จากภายนอกต้องผ่าน VPN, Firewall
หรือบางที่ก็ไม่สามารถเข้าถึงได้เลย
มีทางเดียวก็คือ ต้องซื้อเครื่องที่ใหญ่กว่าเดิม หรือ จำนวนเครื่องมากขึ้น
เพื่อทำให้การทดสอบมันมากขึ้นนั่นเอง
มาถึงเรื่องของ configuration ต้องคล้ายหรือเหมือน production ให้มากที่สุด
เพื่อลดความผิดพลาดต่าง ๆ จากการทดสอบ
2. เรื่องของ test script
ประกอบไปด้วย
การจัดการเรื่อง session
การจัดการเรื่อง caching
และที่สำคัญมากคือ ควรทำการทดสอบในหลาย ๆ layer ตาม Pyramid testing
ตัวอย่างเช่น
การทดสอบระดับ functional
การทดสอบในระดับ service
การทดสอบในระดับ integration ระหว่าง service
การทดสอบในระดับ system
ซึ่งการทดสอบในหลายระดับ
มันช่วยทำให้เราสามารถค้นหา และ ระบุตำแหน่งของปัญหา
ที่เกิดจากการทดสอบ performance ได้ง่ายและรวดเร็ว
3. เรื่องของระบบ Monitoring ระบบ
ในการทดสอบ performance ของระบบนั้น
ระบบ monitoring มันมีความสำคัญอย่างมาก ขาดไม่ได้เลย
คำถามแรก คือ ทำอย่างไรล่ะ ?
การติดตั้งเครื่องมือสำหรับระบบ monitoring นั้น
ควรให้อยู่ใกล้กับ application server ให้มากที่สุด
เพื่อหลีกเลี่ยงปัญหาทางด้าน network
เพื่อหลีกเลี่ยงปัญหาการสูญหายของข้อมูล
แต่ไม่ควรติดตั้งไว้เครื่องเดียวกับระบบที่ถูกทดสอบโดยเด็ดขาด
มิเช่นนั้น มันจะส่งผลกระทบต่อผลการทำงานของระบบ !!
คำถามต่อมา เราจะวัดค่าอะไรจากระบบ Monitoring บ้างล่ะ ?
แบ่งออกเป็นสองส่วนคือ
1. Application level
สิ่งที่ต้องดูเลยก็คือ
- Response time คือเวลาการทำงานของแต่ละ request ตั้งแต่เริ่มต้นจนสิ้นสุด
- Throughput คือจำนวน request ที่ระบบทำงานได้ในเวลาหนึ่ง ๆ เช่น จำนวน request ใน 1 วินาทีเป็นต้น
2. Infrastructure level
สิ่งที่ต้องดูเลยก็คือ การใช้งาน CPU และ Memory ของแต่ละเครื่อง และ service
ซึ่งมีเครื่องมือในการแสดงผล และ วิเคราะห์ เช่น Graphite, Jemalloc และ JProfile เป็นต้น
เมื่อทำการทดสอบเสร็จสิ้นในแต่ละครั้งควรทำการบันทึกผลไว้เสมอ
มันจะทำให้เราเห็นว่า
การทำงานของระบบมีแนวโน้มอย่างไร
จากนั้นทำการวิเคราะห์เจาะเกมส์
เพื่อทำให้เรารู้ว่าต้องปรับปรุงและแก้ไขอย่างไร
ว่าระบบส่วนไหนเกิดปัญหาคอขวดบ้าง
ทั้งวิธีการทดสอบ และ ระบบงาน
4. เรื่องของเครื่องมือ
การเลือกเครื่องมือสำหรับการทดสอบ performace มันเป็นอีกเรื่องที่สำคัญ
โดยมีคำแนะนำสำหรับการเลือกดังนี้
- ง่ายต่อการสร้าง และ ดูแล user agent หรือไม่ ?
- ง่ายต่อการสร้าง และ ดูแลการทดสอบหรือไม่ ?
- มี log ไว้สำหรับการ debug และ ตรวจสอบผลการทดสอบหรือไม่ ?
- สร้างจำนวน user session เยอะ ๆ หรือไม่ ?
- สามารถจัดการเรื่องของ Ramp up/Ramp down ได้หรือไม่ ?
- สามารถทดสอบแบบ Data-Driven ได้หรือไม่ ?
- สามารถทำงานร่วมกับระบบ Web และ API ได้หรือไม่ ?
- สามารถทำงานหลาย OS ได้หรือไม่ ?
- สามารถจัดเก็บประวัติการทดสอบได้หรือไม่ ?
- สามารถแสดงผลการทดสอบในรูปแบบต่าง ๆ ได้หรือไม่ ?
- สามารถทำงานแบบอัตโนมัติร่วมกับระบบ Continuous Integration ได้หรือไม่ ?
- สามารถทำงานบน mobile ได้หรือไม่ ?
- สามารถทดสอบบน browser ชนิดต่าง ๆ ได้หรือไม่ ?
- สามารถจำลองความเร็วของ network ได้หรือไม่ ? เช่น 2G, 3G เป็นต้น
ปิดท้ายด้วย Lesson learn ที่น่าสนใจ
1. หลีกเลี่ยงการทำงานแบบ backgroud process
เนื่องจากเป้าหมายหลักของการทดสอบ
เพื่อรองรับและให้บริการแก่ผู้ใช้งาน หรือ ลูกค้า
ดังนั้น ถ้าแต่ละ request จากผู้ใช้งานมายังระบบงาน
แล้วระบบไปทำงานเหล่านั้นแบบ background process
มันคือการซ่อนปัญหาไว้
ข้อดีของการทำแบบนี้คือ ระบบทำงานได้อย่างรวดเร็ว
ข้อเสียของการทำแบบนี้คือ เพิ่มความซับซ้อนของระบบขึ้นอย่างมาก
การแก้ไข คือ ควรเพิ่มจำนวนเครื่องขึ้นมา
เพื่อรองรับผู้ใช้งานดีกว่านะ
2. การทดสอบแต่ละครั้ง ควรเปลี่ยนค่าต่าง ๆ เพียงหนึ่งค่าเท่านั้น (One Parameter Principle )
ในการทดสอบนั้น
เรามักจะทำการแก้ไขค่า configuration ต่าง ๆ
แต่ขอแนะนำให้เปลี่ยนครั้งละ 1 ค่าเท่านั้น
เพื่อทำให้เราเห็นว่า ค่าใดมันส่งผลดีผลเสียต่อระบบบ้าง
ดังนั้น ให้ทำการทดสอบแบบ small step แบบนี้ไปเรื่อย ๆ
ทำการวิเคราะห์ และ แก้ไขต่อไป
3. ให้คิดถึงพฤติกรรมการใช้งานจริง ๆ ของผู้ใช้งานเป็นหลัก
Flow ของการทดสอบนั้น
ควรเป็นสิ่งที่ผู้ใช้งานส่วนใหญ่ใช้จริง ๆ มิใช่การมโนขึ้นมาเอง
ถ้าเป็นระบบงานเดิม หรือ Legacy system
ก็ให้เอาข้อมูลจาก production server มาวิเคราะห์ซะ
4. ว่าด้วยเรื่องของการทำ Caching
ในบางครั้งการทำ caching ขึ้นมาก็ช่วยทำให้ประสิทธิภาพของระบบดีขึ้น
แต่ในบางครั้งก็ไม่ได้ส่งผลดีอะไรขึ้นมา
ดังนั้น ตรงนี้ควรทำความเข้าใจเกี่ยวกับ caching ให้ดี
แถม caching มันมีหลาย layer อีกด้วย
- ไม่ว่าจะเป็นระดับ network
- ไม่ว่าจะเป็นระดับ application
- ไม่ว่าจะเป็นระดับ service
- ไม่ว่าจะเป็นระดับ database
5. ระมัดระวังการ query ที่ใช้เวลา และ resource เยอะ ๆ
ถ้า query สำหรับการดึงข้อมูลจาก database มันแย่ มันช้า หรือ ใช้ resource มากมาย
จะส่งผลให้การทำงานของระบบช้าลงไปอย่างมาก
ดังนั้นสิ่งที่ต้องมีก็คือ
ระบบ monitoring สำหรับการทำงานของการ query หรือ Slow log
เพื่อทำให้เรารู้ว่า มีจุดใจที่ต้องแก้ไขบ้าง
6. ลดจำนวนการเรียกใช้งานระหว่างระบบ
มักพบว่าระหว่างฝั่ง frontend และ backend นั้น
ในแต่ละ feature มักจะมีการเรียกใช้งาน backend จาก frontend จำนวนมาก
บางครั้งมากจนเกินไป หรือ ถี่จนเกินไป
ดังนั้น แนะนำให้ลดจำนวนการเรียกใช้งานลงซะ
วันนี้คุณทำ Performance testing กันหรือยัง ?
วันนี้คุณทำ Performance testing กันอย่างไร ?

 วันนี้เจอปัญหาที่น่าสนใจสำหรับการทดสอบ Android app ด้วย Espresso
มีอาการ คือ ไม่สามารถทำการทดสอบได้ และ ผลการทดสอบผิดพลาด
ซึ่งเป็นปัญหาเกี่ยวกับ permission ของ Android app นั่นเอง
โดยจะเจอปัญหานี้บน Android M หรือ Android 6 Marshmallow
เนื่องจากรูปแบบของการจัดการ permission ที่เปลี่ยนไป
มาดูวิธีการแก้ไขว่าทำอย่างไร ?
ป.ล.
สามารถอ่านเพิ่มเติมเรื่อง Working with Permission ได้ที่ Android Developer
ขอขอบคุณผู้สร้างปัญหา คุณเก้อ
วันนี้เจอปัญหาที่น่าสนใจสำหรับการทดสอบ Android app ด้วย Espresso
มีอาการ คือ ไม่สามารถทำการทดสอบได้ และ ผลการทดสอบผิดพลาด
ซึ่งเป็นปัญหาเกี่ยวกับ permission ของ Android app นั่นเอง
โดยจะเจอปัญหานี้บน Android M หรือ Android 6 Marshmallow
เนื่องจากรูปแบบของการจัดการ permission ที่เปลี่ยนไป
มาดูวิธีการแก้ไขว่าทำอย่างไร ?
ป.ล.
สามารถอ่านเพิ่มเติมเรื่อง Working with Permission ได้ที่ Android Developer
ขอขอบคุณผู้สร้างปัญหา คุณเก้อ

 ในปัจจุบันเรื่องของ Data Science ถูกพูดถึงกันอย่างมาก
มักจะมาพร้อมกับคำว่า Big Data
ดังนั้น เราดูกันหน่อยว่า
ในปัจจุบันเรื่องของ Data Science ถูกพูดถึงกันอย่างมาก
มักจะมาพร้อมกับคำว่า Big Data
ดังนั้น เราดูกันหน่อยว่า
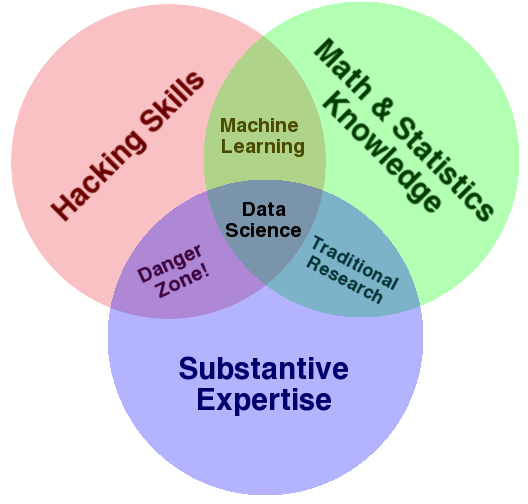
 ความแตกต่างระหว่างนักสถิติ (Statistician) กับ Data Scientist คือ
นักสถิติจะนำข้อมูลมา run regression ตามสมการทางสถิติ
ส่วน Data Scientist นั้นจะต้องไปหาข้อมูลที่ต้องการ จัดโครงสร้าง
ตัดส่วนที่ไม่จำเป็นออกไป
ทำการวิเคราะห์
จากนั้นทำการสื่อสาร สรุปผลการวิเคราะห์ให้อยู่ในรูปแบบที่เข้าใจง่าย
เช่น อยู่ในรูปแบบของ vistualization เป็นต้น
จะสังเกตุได้ว่า Data Scientist นั้นต้องการข้อมูลที่มีคุณภาพ
นั่นคือ จำเป็นต้องมีแหล่งข้อมูลที่มีคุณภาพ
เพื่อให้ได้ผลที่มีคุณภาพนั่นเอง
ความแตกต่างระหว่างนักสถิติ (Statistician) กับ Data Scientist คือ
นักสถิติจะนำข้อมูลมา run regression ตามสมการทางสถิติ
ส่วน Data Scientist นั้นจะต้องไปหาข้อมูลที่ต้องการ จัดโครงสร้าง
ตัดส่วนที่ไม่จำเป็นออกไป
ทำการวิเคราะห์
จากนั้นทำการสื่อสาร สรุปผลการวิเคราะห์ให้อยู่ในรูปแบบที่เข้าใจง่าย
เช่น อยู่ในรูปแบบของ vistualization เป็นต้น
จะสังเกตุได้ว่า Data Scientist นั้นต้องการข้อมูลที่มีคุณภาพ
นั่นคือ จำเป็นต้องมีแหล่งข้อมูลที่มีคุณภาพ
เพื่อให้ได้ผลที่มีคุณภาพนั่นเอง

 ทำการแปลบางส่วนจากบทความเรื่อง
ทำการแปลบางส่วนจากบทความเรื่อง 
 คำพูดเกี่ยวกับทีมพัฒนาที่มักได้ยินจากฝ่าย Management, Team lead, Product Manager และ ...
คือ ทีมพัฒนาทำงานช้า หรือ ทำงานยังไม่เร็วตามความต้องการ
คำถามคือ ถ้าต้องการให้ทีมพัฒนาทำงานเร็วขึ้นต้องทำอย่างไร ?
คำตอบที่มักจะได้รับคือ
คำพูดเกี่ยวกับทีมพัฒนาที่มักได้ยินจากฝ่าย Management, Team lead, Product Manager และ ...
คือ ทีมพัฒนาทำงานช้า หรือ ทำงานยังไม่เร็วตามความต้องการ
คำถามคือ ถ้าต้องการให้ทีมพัฒนาทำงานเร็วขึ้นต้องทำอย่างไร ?
คำตอบที่มักจะได้รับคือ

 จากบทความเรื่อง
จากบทความเรื่อง 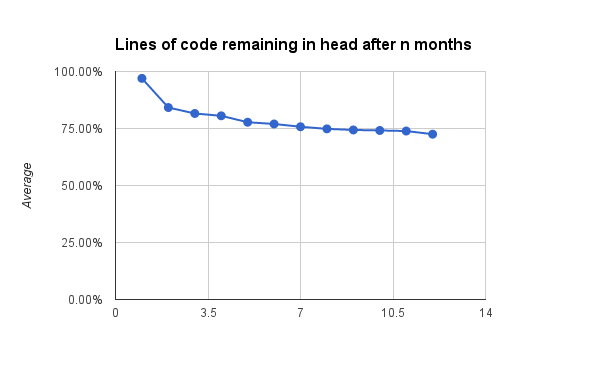 ลองคิดดูสิว่า
กว่า 70% ของ code ที่เราเขียนไม่ถูกเปลี่ยนแปลงเลย
มันหมายความว่าอย่างไร ?
ลองคิดดูสิว่า
กว่า 70% ของ code ที่เราเขียนไม่ถูกเปลี่ยนแปลงเลย
มันหมายความว่าอย่างไร ?

 การ deploy มันคืออะไร ?
มันคือการพูดถึงขั้นตอนการของนำ code แต่ละบรรทัด
ย้ายไปยัง server ต่าง ๆ หรือไม่ ?
นั่นหมายความว่า
เรากำลังแก้ไขปัญหาบางอย่าง
เรากำลังทำงานที่น่าเบื่อซำแล้วซ้ำอีก
ไม่ว่าจะใช้เครื่องมือใด ๆ ก็ตาม
แต่เรากลับพบว่า เครื่องมือใด ๆ ก็ไม่ใช่ปัญหา
แล้วปัญหามันเกิดขึ้นมาได้อย่างไรล่ะ ?
การ deploy มันคืออะไร ?
มันคือการพูดถึงขั้นตอนการของนำ code แต่ละบรรทัด
ย้ายไปยัง server ต่าง ๆ หรือไม่ ?
นั่นหมายความว่า
เรากำลังแก้ไขปัญหาบางอย่าง
เรากำลังทำงานที่น่าเบื่อซำแล้วซ้ำอีก
ไม่ว่าจะใช้เครื่องมือใด ๆ ก็ตาม
แต่เรากลับพบว่า เครื่องมือใด ๆ ก็ไม่ใช่ปัญหา
แล้วปัญหามันเกิดขึ้นมาได้อย่างไรล่ะ ?



 ภาษาโปรแกรมใหม่อีกตัวได้ถือกำเนิดมาอีกแล้ว
แต่ว่ามันคือภาษาที่ประกอบไปด้วยชุดของ Emoji น่ารัก ๆ
ซึ่งน่าจะเคยเห็นกันมาพอสมควรจากภาษา Swift
แต่ตอนมีคนสร้างภาษาโปรแกรมใหม่ที่เรียกว่า
ภาษาโปรแกรมใหม่อีกตัวได้ถือกำเนิดมาอีกแล้ว
แต่ว่ามันคือภาษาที่ประกอบไปด้วยชุดของ Emoji น่ารัก ๆ
ซึ่งน่าจะเคยเห็นกันมาพอสมควรจากภาษา Swift
แต่ตอนมีคนสร้างภาษาโปรแกรมใหม่ที่เรียกว่า 
 วันนี้ได้เริ่มอ่านหนังสือ
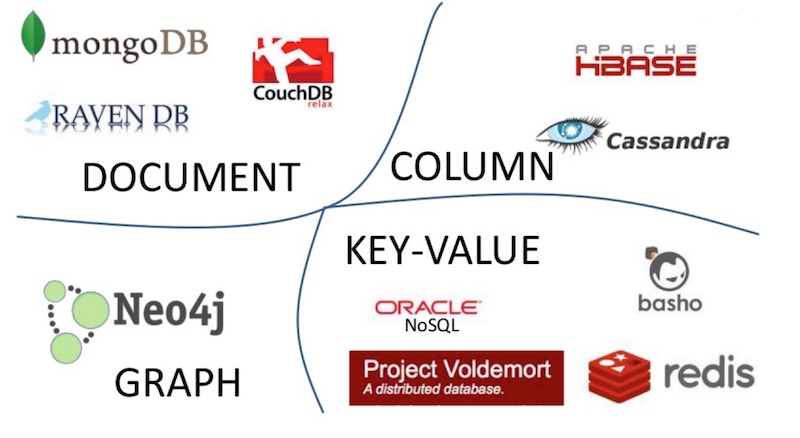
วันนี้ได้เริ่มอ่านหนังสือ 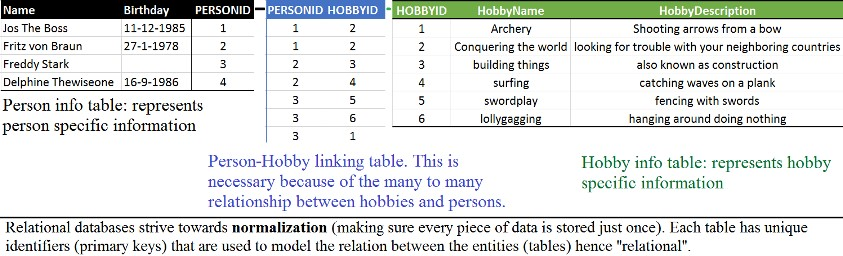 มาดูว่าโครงสร้างข้อมูลของ NoSQL Database แต่ละชนิดเป็นอย่างไร
มาดูว่าโครงสร้างข้อมูลของ NoSQL Database แต่ละชนิดเป็นอย่างไร
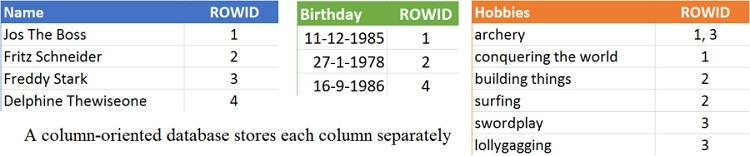
 ดังนั้น เพื่อเพิ่มความเร็วในการเข้าถึงข้อมูล
เราจึงทำการสร้าง index ให้ตาม column ที่เราต้องการ
แต่มันเป็นการเพิ่ม overhead ให้แก่ระบบ
ลองคิดดูว่า ถ้าเราทำการ index ทุก ๆ column ล่ะ !!
ดังนั้น Column-Oriented Database จึงสร้างมาเพื่อช่วยแก้ไขปัญหาเหล่านี้
โดยแต่ละ column จะถูกจัดเก็บแยกกัน
ทำให้การเข้าถึงข้อมูลในแต่ละ column เร็วขึ้น
รวมทั้งทำให้ง่ายต่อการบีบอัดข้อมูลอีกด้วย
เนื่องจากในแต่ละตารางจัดเก็บข้อมูลเพียงชนิดเดียว
แสดงดังรูป
ดังนั้น เพื่อเพิ่มความเร็วในการเข้าถึงข้อมูล
เราจึงทำการสร้าง index ให้ตาม column ที่เราต้องการ
แต่มันเป็นการเพิ่ม overhead ให้แก่ระบบ
ลองคิดดูว่า ถ้าเราทำการ index ทุก ๆ column ล่ะ !!
ดังนั้น Column-Oriented Database จึงสร้างมาเพื่อช่วยแก้ไขปัญหาเหล่านี้
โดยแต่ละ column จะถูกจัดเก็บแยกกัน
ทำให้การเข้าถึงข้อมูลในแต่ละ column เร็วขึ้น
รวมทั้งทำให้ง่ายต่อการบีบอัดข้อมูลอีกด้วย
เนื่องจากในแต่ละตารางจัดเก็บข้อมูลเพียงชนิดเดียว
แสดงดังรูป
 ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Column-Oriented เช่น
ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Column-Oriented เช่น
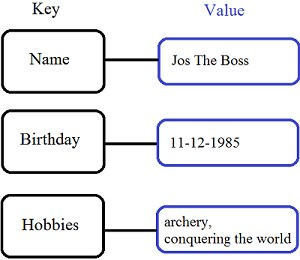 ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Key-Value เช่น
ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Key-Value เช่น
 ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Document เช่น
ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Document เช่น
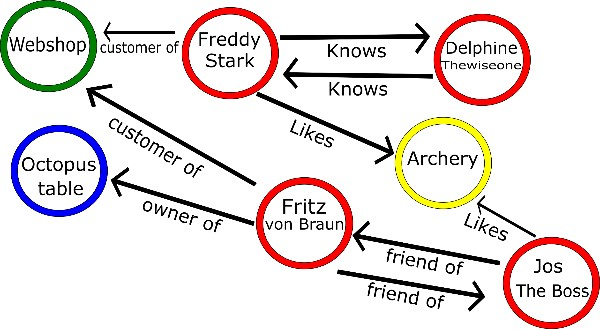 ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Graph เช่น
ตัวอย่าง product ที่มีโครงสร้างข้อมูลเป็น Graph เช่น

 คำถามที่น่าสนใจ สำหรับการพัฒนาระบบงาน
คำถามที่น่าสนใจ สำหรับการพัฒนาระบบงาน

 เมื่อเช้านี้เห็นมีการ share บทความเรื่อง
เมื่อเช้านี้เห็นมีการ share บทความเรื่อง 
 วันนี้อ่านหนังสือเรื่อง
วันนี้อ่านหนังสือเรื่อง 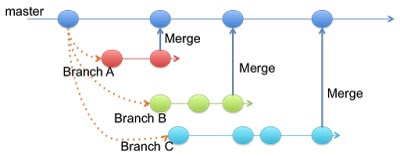 ข้อควรระวัง
แต่ละงานที่ทำนั้น ควรเป็นงานที่เล็ก ๆ
ไม่เช่นนั้น จะทำให้ local branch ยาวนานเกินไป
ก็จะทำให้เกิด merge conflict กันเยอะ
แต่ละงานที่มำนั้น ควรเป็น code ที่แยกออกจากกันชัดเจน
ไม่เช่นนั้น ก็จะทำให้เกิด merge conflict กันเยอะ
อีกอย่างหนึ่งที่ควรพึงระวัง
ถ้าทำการ merge แบบ manual เยอะ ๆ
แสดงว่า คุณกำลังมาผิดทาง เช่น
ข้อควรระวัง
แต่ละงานที่ทำนั้น ควรเป็นงานที่เล็ก ๆ
ไม่เช่นนั้น จะทำให้ local branch ยาวนานเกินไป
ก็จะทำให้เกิด merge conflict กันเยอะ
แต่ละงานที่มำนั้น ควรเป็น code ที่แยกออกจากกันชัดเจน
ไม่เช่นนั้น ก็จะทำให้เกิด merge conflict กันเยอะ
อีกอย่างหนึ่งที่ควรพึงระวัง
ถ้าทำการ merge แบบ manual เยอะ ๆ
แสดงว่า คุณกำลังมาผิดทาง เช่น
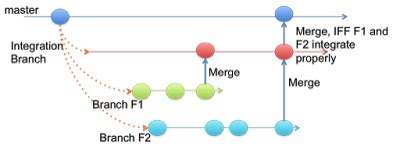 ดังนั้นสถานะของ code บน branch หลัก
คือพร้อมที่จะ dpeloy/release อยู่ตลอดเวลา
อีกอย่างหนึ่งที่เห็นได้ชัดเจนก็คือ มีการทำงานแบบ manual เยอะมาก ๆ
ดังนั้น เราสามารถลดด้วยการทำระบบทำงานแบบอัตโนมัติเข้ามาช่วย
ทั้งการ merge การทดสอบ และ การ deploy ระบบงาน
ตัวอย่างที่นำวิธีการนี้ไปประยุกต์ใช้งาน เช่น
ดังนั้นสถานะของ code บน branch หลัก
คือพร้อมที่จะ dpeloy/release อยู่ตลอดเวลา
อีกอย่างหนึ่งที่เห็นได้ชัดเจนก็คือ มีการทำงานแบบ manual เยอะมาก ๆ
ดังนั้น เราสามารถลดด้วยการทำระบบทำงานแบบอัตโนมัติเข้ามาช่วย
ทั้งการ merge การทดสอบ และ การ deploy ระบบงาน
ตัวอย่างที่นำวิธีการนี้ไปประยุกต์ใช้งาน เช่น 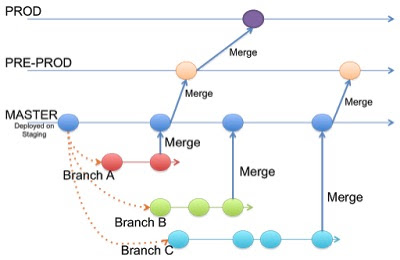
![branch-by-release[4]](http://www.somkiat.cc/wp-content/uploads/2016/03/branch-by-release4.png)

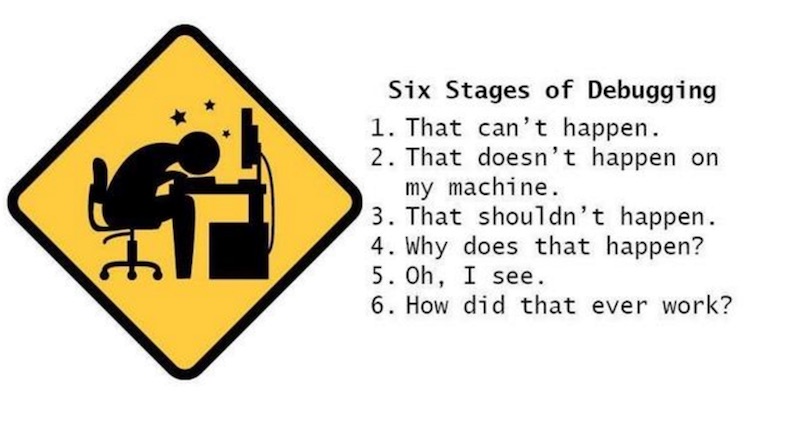 เห็นใน Facebook มีการ share เรื่องราวของ Six Stages of Debugging
ซึ่งเป็นปฏิกิริยาของ developer สำหรับการ debug code
เพื่อทำการหาสาเหตุว่า ทำไม code ถึงทำงานไม่ถูกต้อง
ประกอบไปด้วย
เห็นใน Facebook มีการ share เรื่องราวของ Six Stages of Debugging
ซึ่งเป็นปฏิกิริยาของ developer สำหรับการ debug code
เพื่อทำการหาสาเหตุว่า ทำไม code ถึงทำงานไม่ถูกต้อง
ประกอบไปด้วย


 วันนี้เพิ่งเห็นว่าทาง Yahoo ได้เปิดเผยฐานข้อมูลขนาดใหญ่ให้ใช้งานกันได้แล้ว
ตามจริงประกาศออกมาตั้งแต่เดือนมกราคมแล้วนะ !!
ตกข่าวสุด ๆ ดังนั้นจึงนำมาสรุปกันนิดหน่อย
ทาง Yahoo ได้เปิดฐานข้อมูล
วันนี้เพิ่งเห็นว่าทาง Yahoo ได้เปิดเผยฐานข้อมูลขนาดใหญ่ให้ใช้งานกันได้แล้ว
ตามจริงประกาศออกมาตั้งแต่เดือนมกราคมแล้วนะ !!
ตกข่าวสุด ๆ ดังนั้นจึงนำมาสรุปกันนิดหน่อย
ทาง Yahoo ได้เปิดฐานข้อมูล 
 โดยข้อมูลเหล่านี้ น่าจะเป็นประโยชน์สำหรับ
โดยข้อมูลเหล่านี้ น่าจะเป็นประโยชน์สำหรับ

 หลังจากทำการ update Swift 2.2
ผลที่ได้คือ warning ใน code เพียบเลย !!
ดังนั้นจึงทำการอ่าน และ สรุปสิ่งที่เปลี่ยนกันหน่อยสิว่ามีอะไรบ้าง ?
ซึ่งพบว่า
หลังจากทำการ update Swift 2.2
ผลที่ได้คือ warning ใน code เพียบเลย !!
ดังนั้นจึงทำการอ่าน และ สรุปสิ่งที่เปลี่ยนกันหน่อยสิว่ามีอะไรบ้าง ?
ซึ่งพบว่า
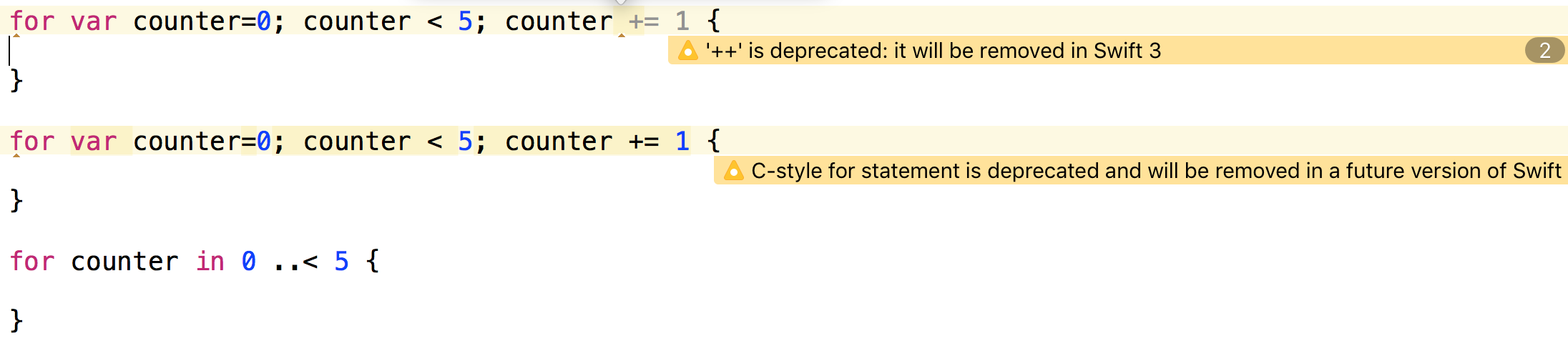
 ดังนั้นจึงมีผลทำให้ for loop แบบ C-Style ได้รับผลกระทบไปด้วย
แนะนำให้ใช้ loop over a range ซะ
ดังนี้
ดังนั้นจึงมีผลทำให้ for loop แบบ C-Style ได้รับผลกระทบไปด้วย
แนะนำให้ใช้ loop over a range ซะ
ดังนี้
 สำหรับการใช้งาน range ก็อย่าไปทำแบบตัวเริ่มต้นมากกว่าตัวสิ้นสุดนะ
ไม่งั้นจะเกิด Runtime error ( Compile ผ่านนะ )
แนะนำให้ใช้ method reverse() ซะ
สำหรับการใช้งาน range ก็อย่าไปทำแบบตัวเริ่มต้นมากกว่าตัวสิ้นสุดนะ
ไม่งั้นจะเกิด Runtime error ( Compile ผ่านนะ )
แนะนำให้ใช้ method reverse() ซะ



 ปัญหาที่ developer ส่วนใหญ่มักจะบ่นก็คือ
งานเยอะ
เวลาน้อย
มีแต่งานเร่ง กับ งานด่วน
ทุกคนต้องการเร็วที่สุดเหมือนกันหมด
แต่ปัญหาหลัก ๆ คือ developer จัดสรรเวลาได้ดีเพียงใด
เราเสียเวลาไปกับอะไรบ้างในขณะที่เขียน code
ดังนั้นมาตอบคำถามเหล่านี้ก่อนสิ
ปัญหาที่ developer ส่วนใหญ่มักจะบ่นก็คือ
งานเยอะ
เวลาน้อย
มีแต่งานเร่ง กับ งานด่วน
ทุกคนต้องการเร็วที่สุดเหมือนกันหมด
แต่ปัญหาหลัก ๆ คือ developer จัดสรรเวลาได้ดีเพียงใด
เราเสียเวลาไปกับอะไรบ้างในขณะที่เขียน code
ดังนั้นมาตอบคำถามเหล่านี้ก่อนสิ

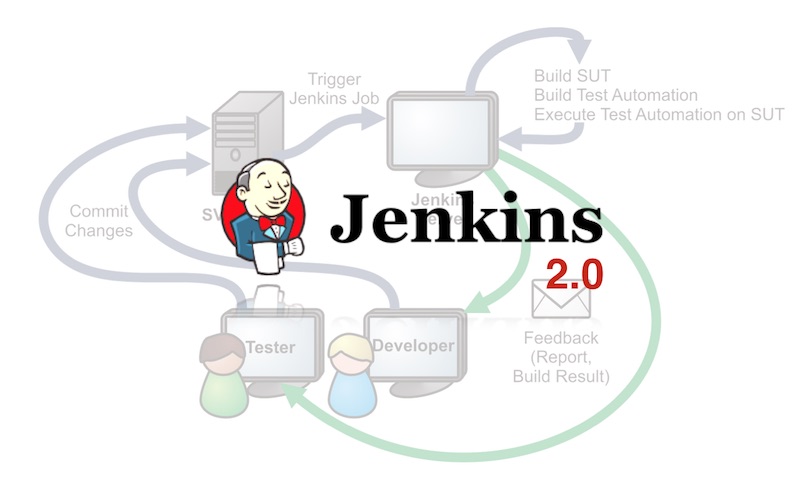 ตอนนี้
ตอนนี้ 
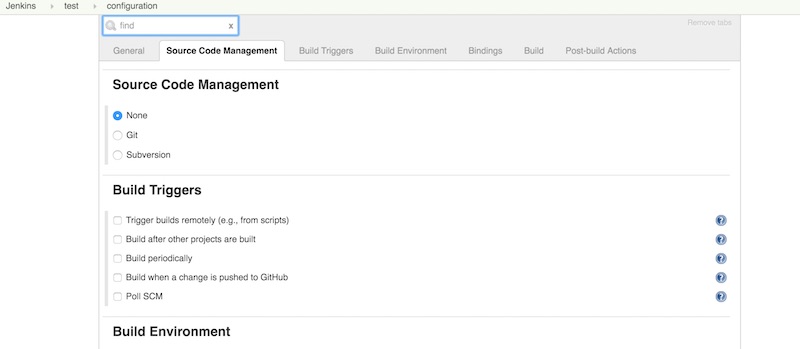
 อีกทั้งยังทำการปรับปรุง User Interface ในหน้าต่าง ๆ อีก
ตัวอย่างเช่นหน้า Configuration ของแต่ละ Item/Job
แสดงดังรูป
อีกทั้งยังทำการปรับปรุง User Interface ในหน้าต่าง ๆ อีก
ตัวอย่างเช่นหน้า Configuration ของแต่ละ Item/Job
แสดงดังรูป
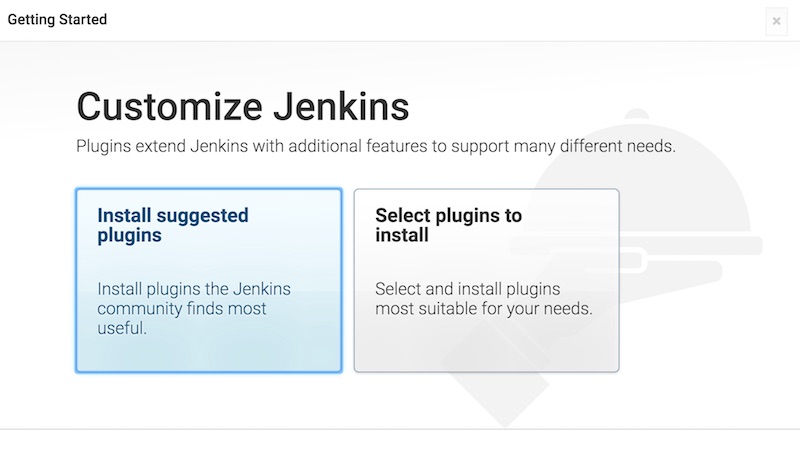
 จากนั้นเข้าสู่หน้าแนะนำ plugin และ ติดตั้งกัน
แนะนำให้เลือก Install suggested plugins
แล้วจะมี feature ให้ใช้เยอะมาก ๆ
ทำการติดตั้ง plugin
จากนั้นเข้าสู่หน้าแนะนำ plugin และ ติดตั้งกัน
แนะนำให้เลือก Install suggested plugins
แล้วจะมี feature ให้ใช้เยอะมาก ๆ
ทำการติดตั้ง plugin
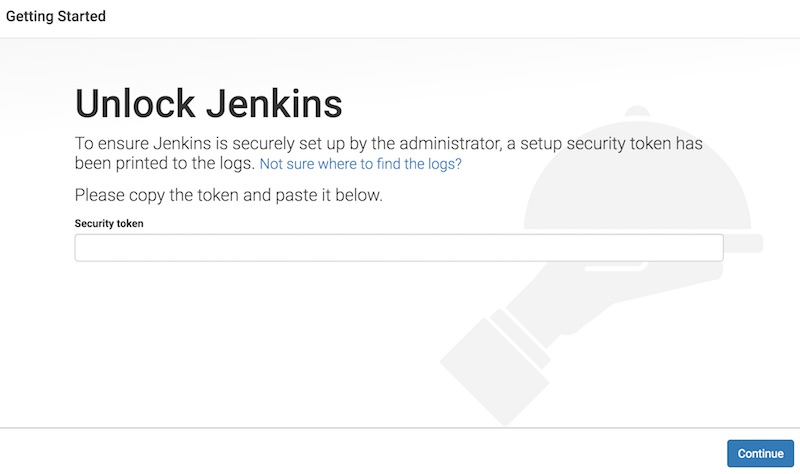
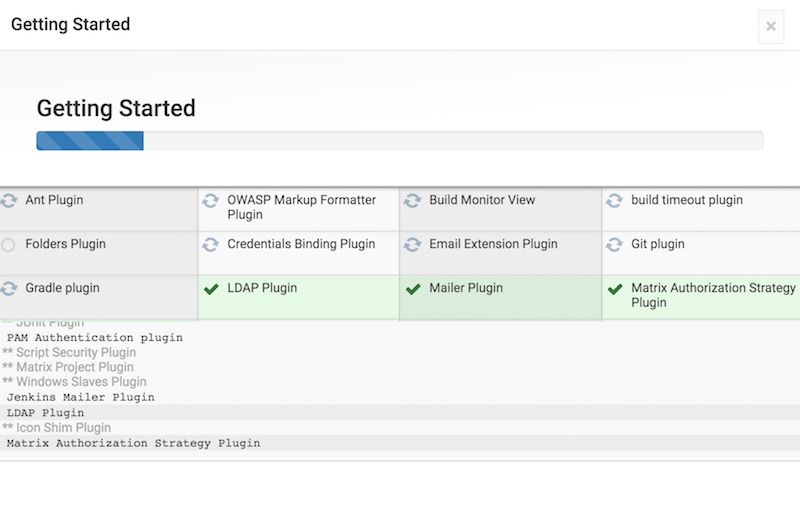 ต่อมาให้ทำการสร้าง username ที่เป็น Admin เพื่อจัดการระบบ
ถือว่าเป็นการปรับปรุงเรื่อง security ของ Jenkins กันเลยทีเดียว
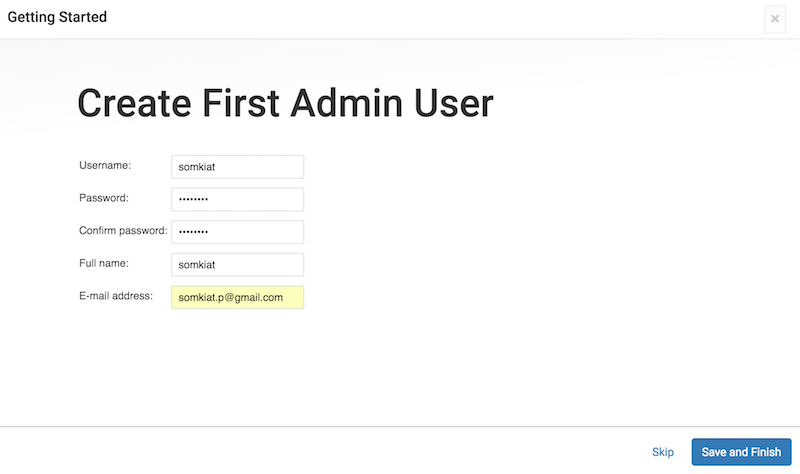
ต่อมาให้ทำการสร้าง username ที่เป็น Admin เพื่อจัดการระบบ
ถือว่าเป็นการปรับปรุงเรื่อง security ของ Jenkins กันเลยทีเดียว
 เข้าสู่หน้าหลักของ Jenkins
พบว่ายังคงหน้าตาเหมือนกับ version ก่อนหน้า
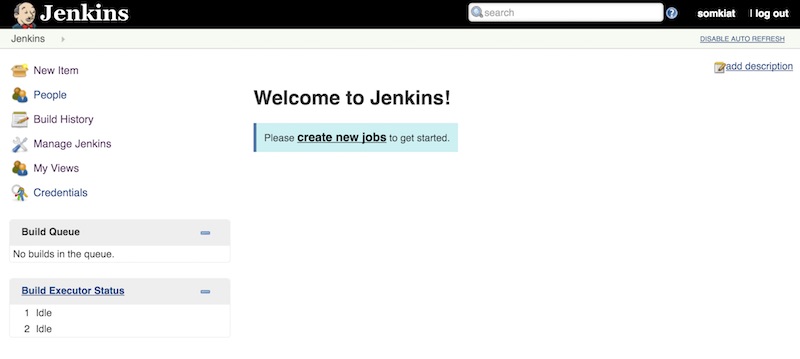
เข้าสู่หน้าหลักของ Jenkins
พบว่ายังคงหน้าตาเหมือนกับ version ก่อนหน้า
 จากการทดลองใช้งาน Jenkins 2.0 preview มา
ก็หน้าตาดูดีขึ้นมา จัดการ plugin ได้ดี
ส่วนเรื่องอื่น ๆ ต้องลองใช้งานกันต่อไป
ส่วนแผนการพัฒนา feature ต่าง ๆ
จากการทดลองใช้งาน Jenkins 2.0 preview มา
ก็หน้าตาดูดีขึ้นมา จัดการ plugin ได้ดี
ส่วนเรื่องอื่น ๆ ต้องลองใช้งานกันต่อไป
ส่วนแผนการพัฒนา feature ต่าง ๆ 
 ได้อ่านผลการสำรวจเรื่อง ความปลอดภัยของ Mobile app
จาก
ได้อ่านผลการสำรวจเรื่อง ความปลอดภัยของ Mobile app
จาก 
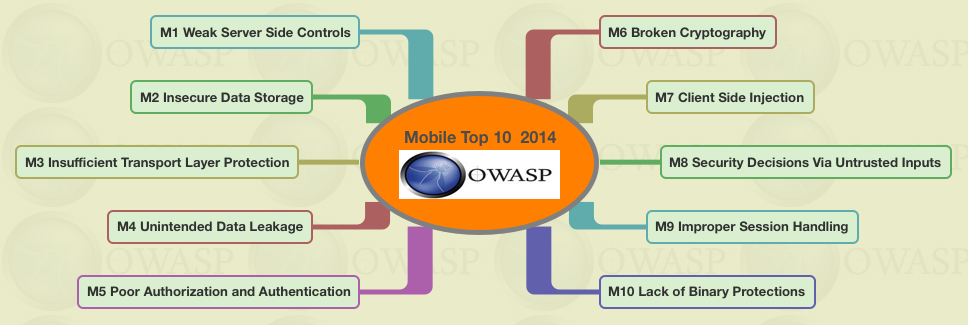
 สามารถอ่านข้อมูลการสำรวจเพิ่มเติมจาก
สามารถอ่านข้อมูลการสำรวจเพิ่มเติมจาก

 ในการทดสอบ Software นั้น มีวิธีการและแนวทางที่เยอะมาก
ดังนั้น เรามาลองแบ่งกลุ่มของการทดสอบ
ตามแนวทางของ
ในการทดสอบ Software นั้น มีวิธีการและแนวทางที่เยอะมาก
ดังนั้น เรามาลองแบ่งกลุ่มของการทดสอบ
ตามแนวทางของ 
