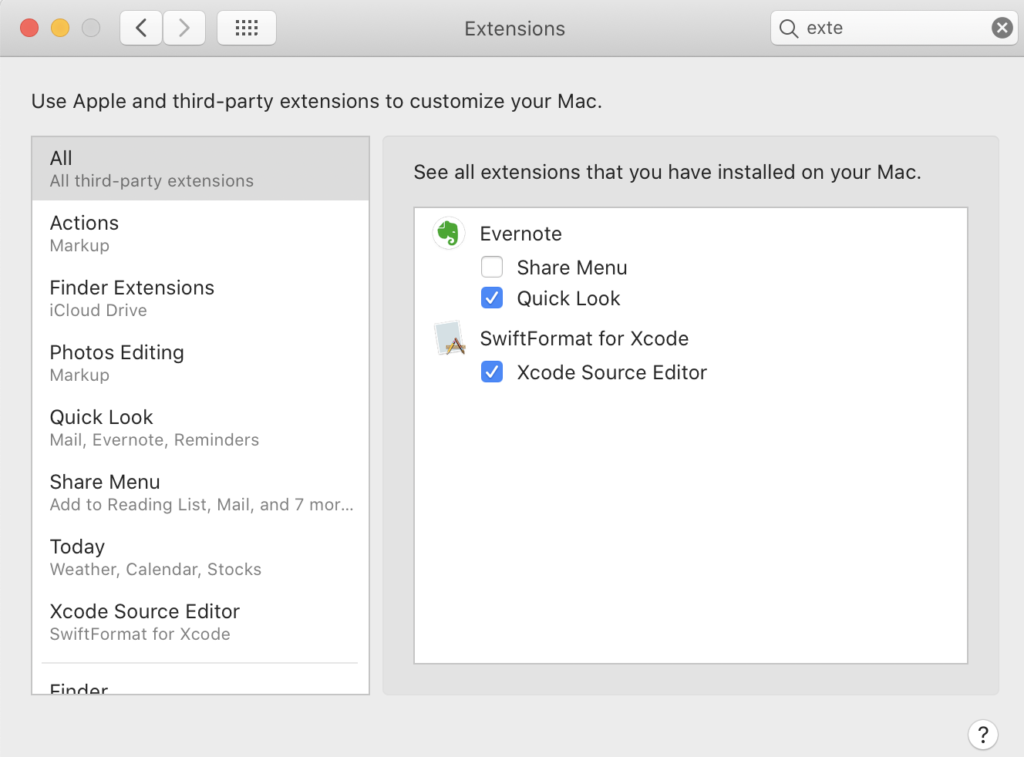
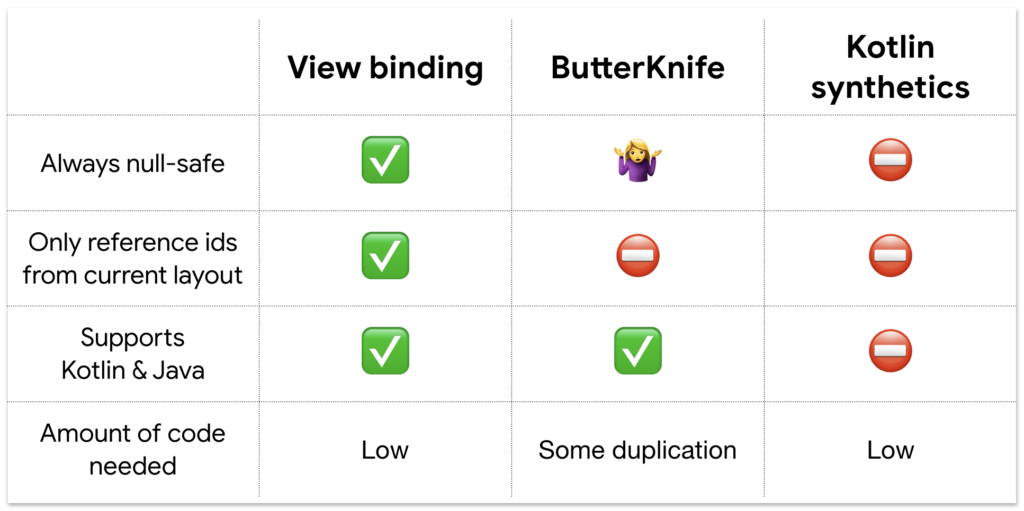
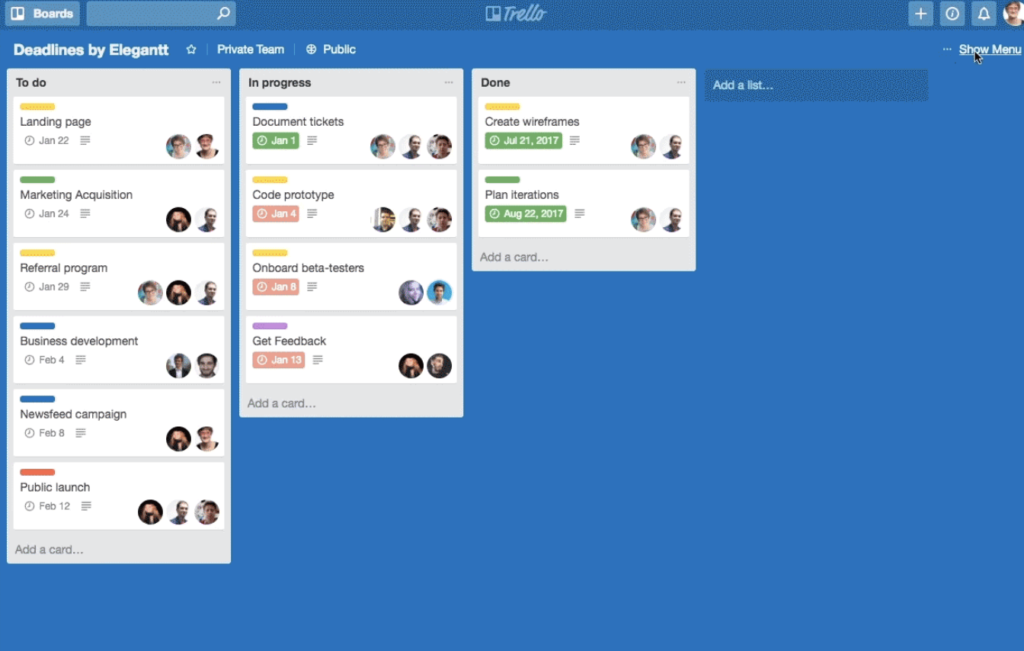
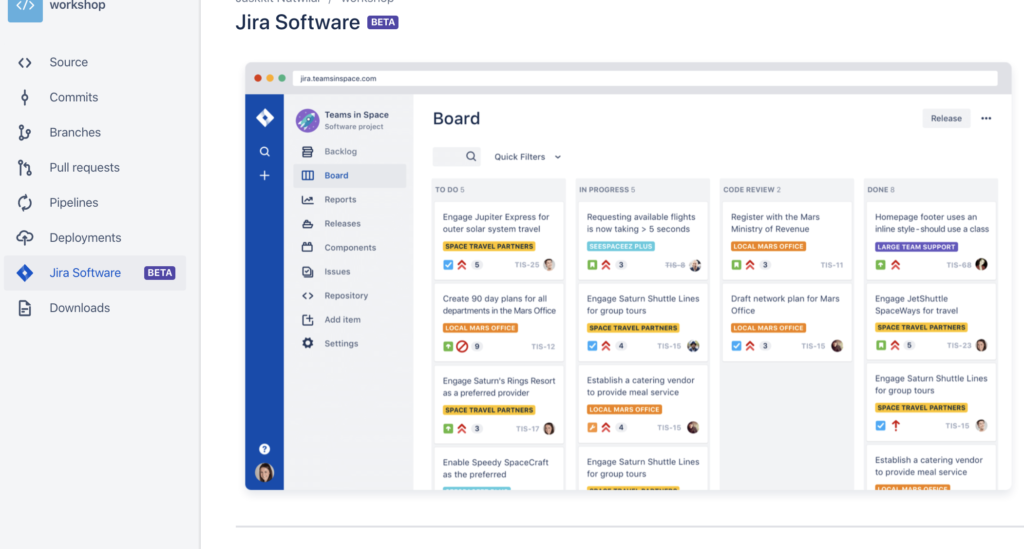
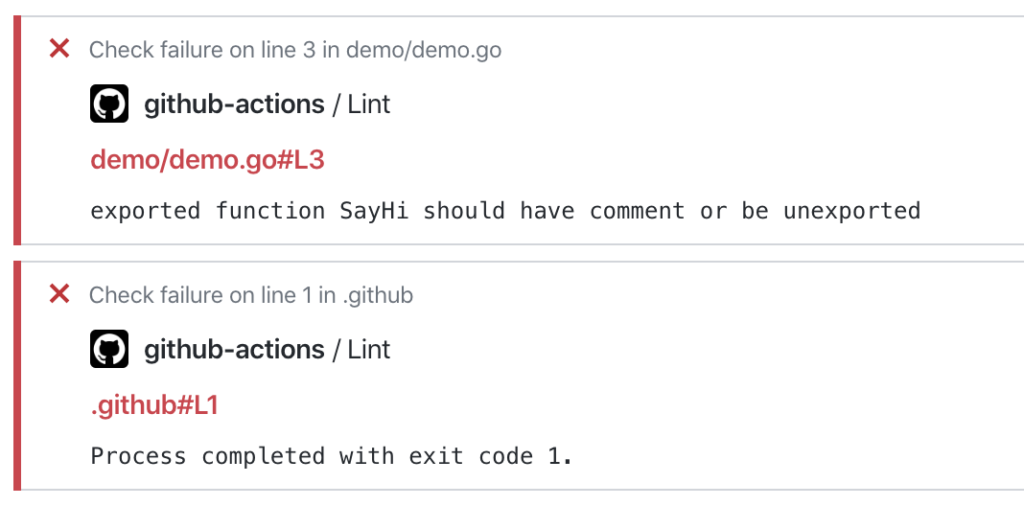
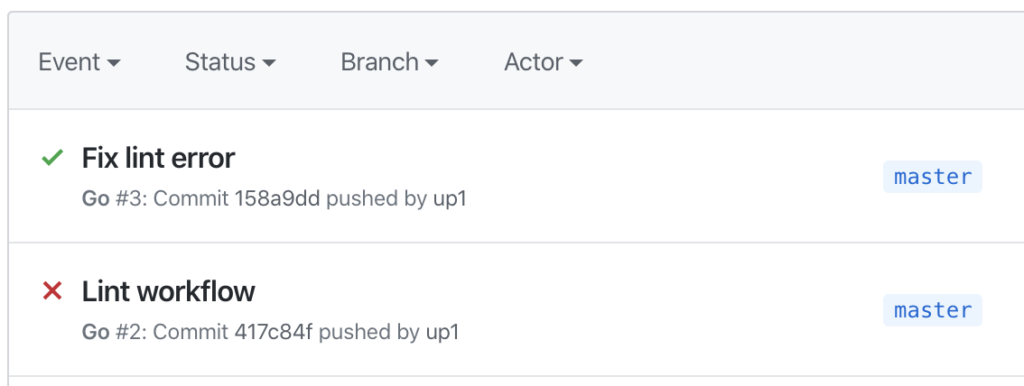
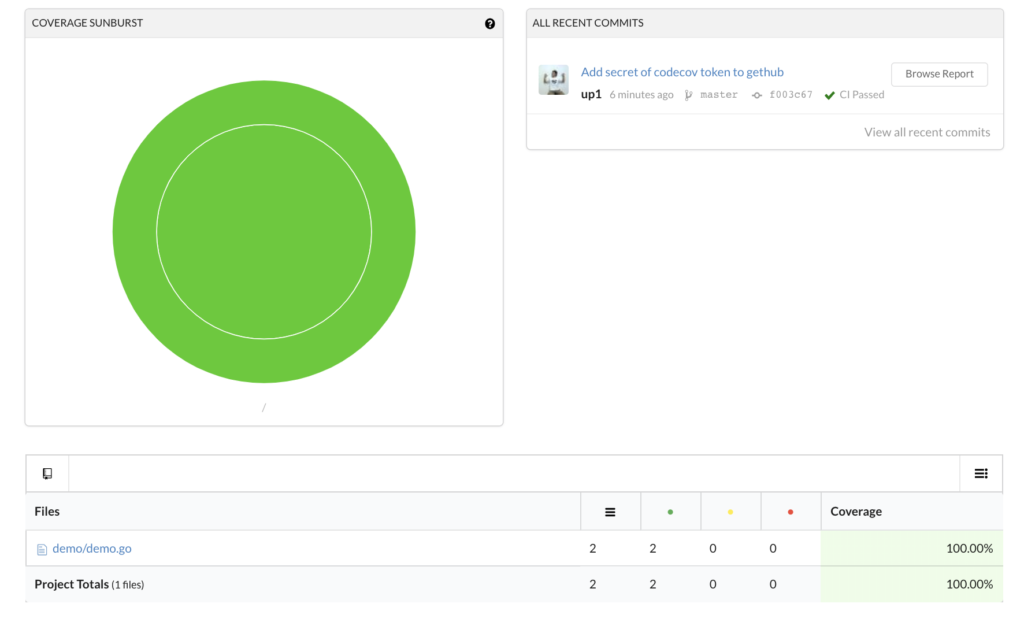
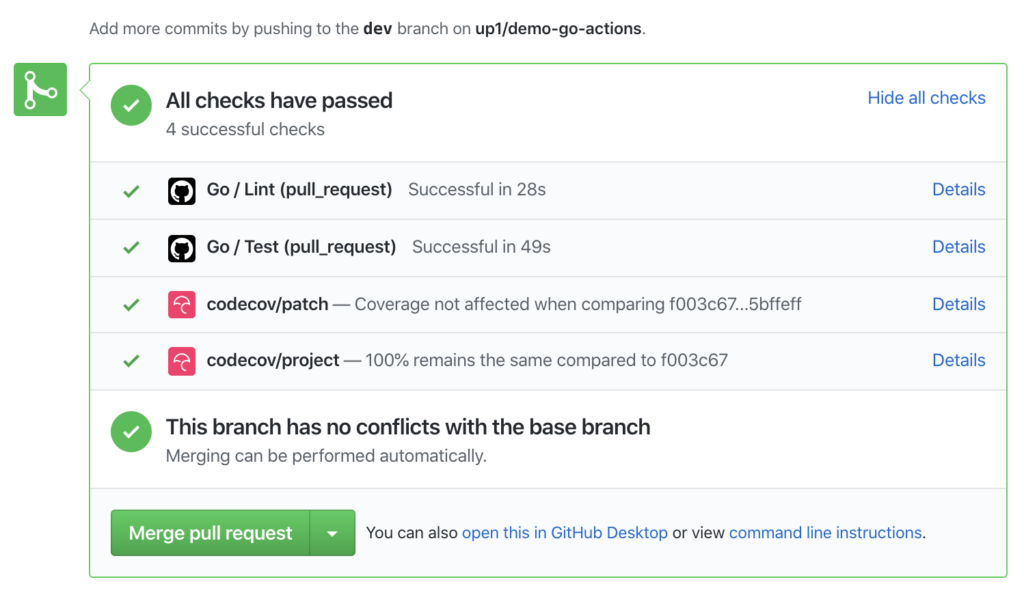
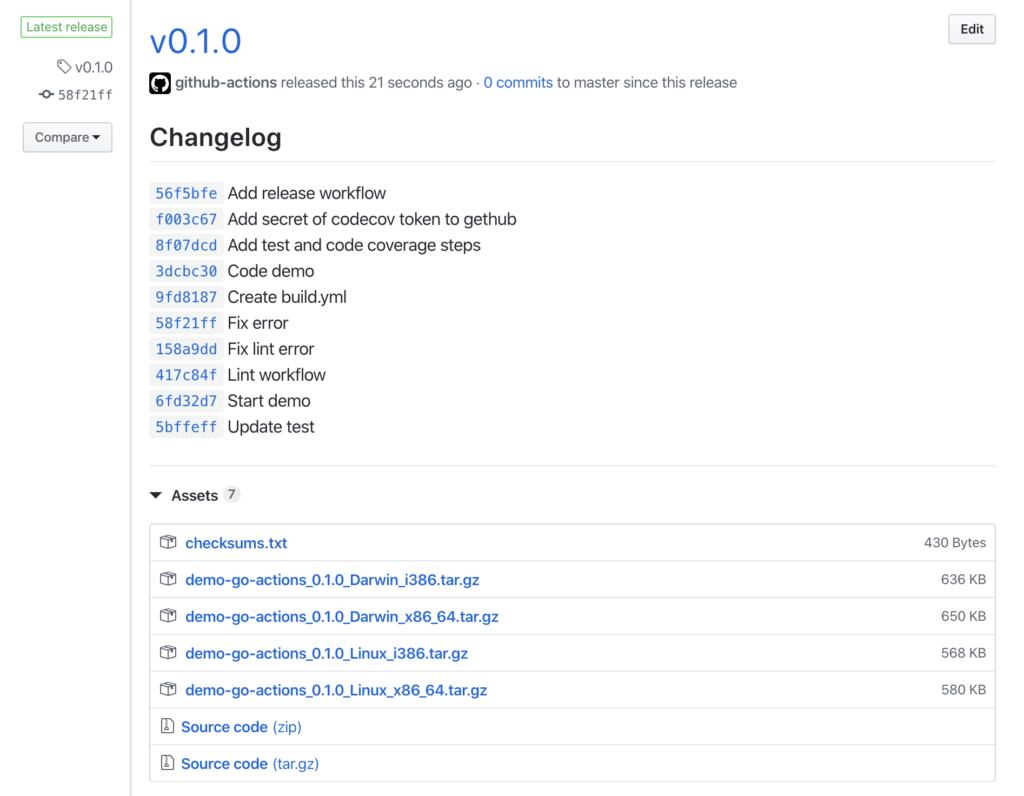
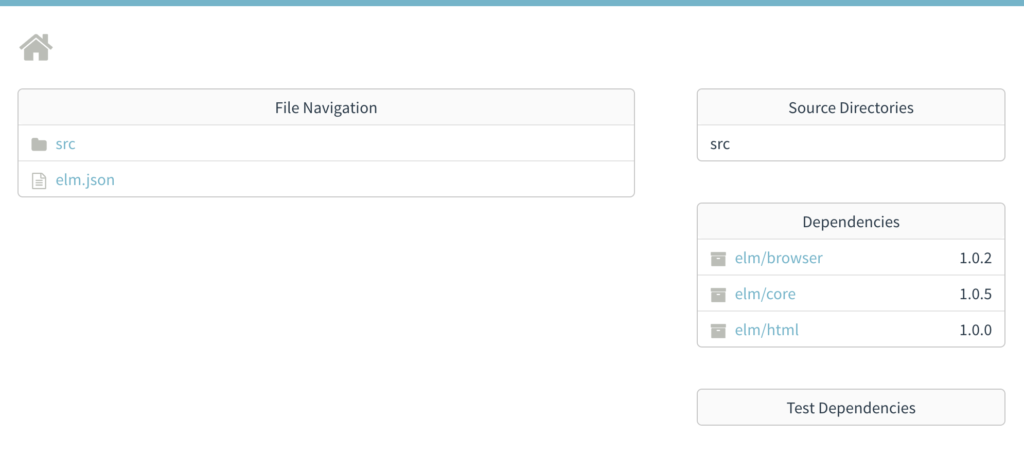
แน่นอนว่า แตกต่างกันอีก จะใช้ Format code แบบอัตโนมัติจาก XCode ก็พึ่งไม่ค่อยได้ เลยมีโอกาสได้ลอง Swift Format ผลออกมาใช้ได้เลย แถมใช้งานง่ายด้วย เนื่องจากมีทั้งแบบ
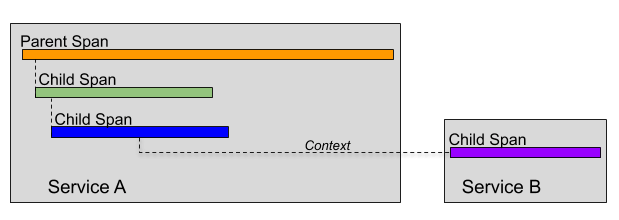
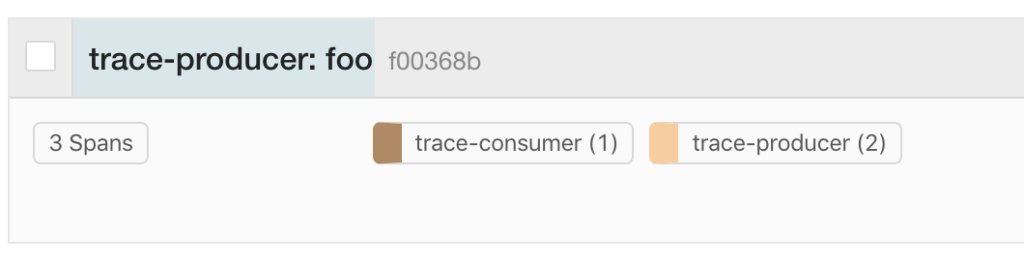
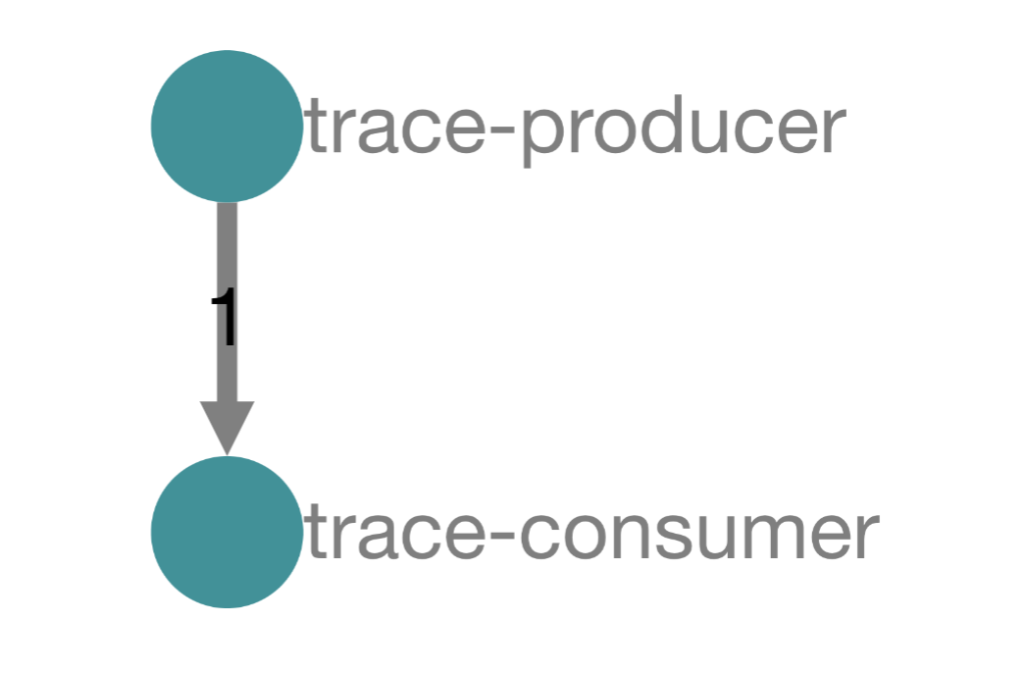
จากบทความเรื่อง The Elephant in the Architecture นั้น ทำการอธิบายถึงที่มาที่ไปของปัญหาต่าง ๆ ที่เกิดขึ้นในการออกแบบ software ว่าเราทำการออกแบบด้วยแนวคิดอย่างไร ? ซึ่งแนวทางนั้นจะเทียบเคียงได้กับ สำนวน The Elephant in the room นั่นคือ เราทุกคนนั้นเห็นปัญหา เห็นข้อเท็จจริงต่าง ๆ อย่างชัดเจน แต่ทุกคนหลีกเลี่ยงที่จะพูดถึงมัน เหมือนกับการมีช้างอยู่ในห้อง แต่ทุกคนจะไม่พยายามหรือมองเห็นมันนั่นเอง
คำถามคือ แล้วจะแก้ไขปัญหาได้อย่างไร ?
โดยในบทความจะอธิบายถึง
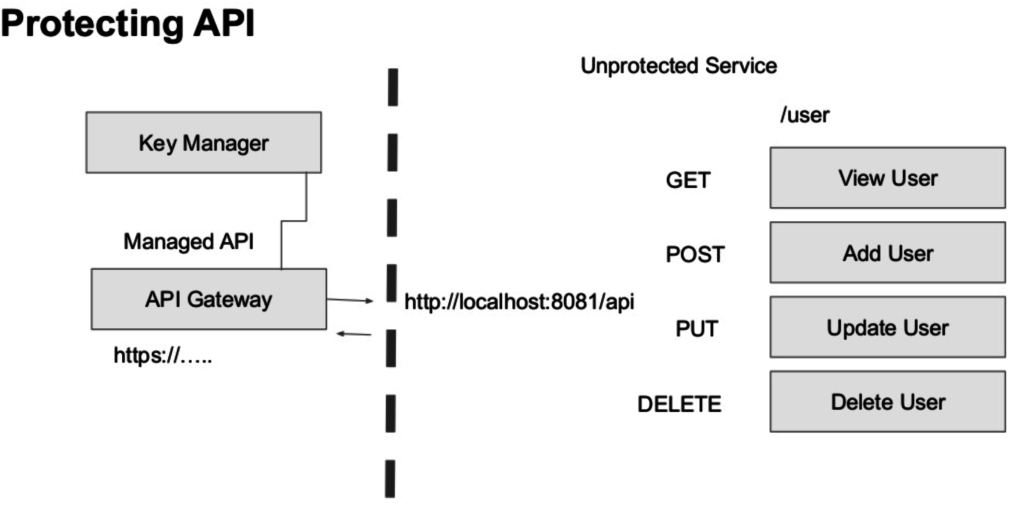
เหตุผลในการตัดสินใจเลือกแนวทางในการออกแบบ architecture ของ software ว่า ควรที่จะต้องออกแบบตาม business value เป็นหลัก เนื่องจากพบว่าส่วนใหญ่แล้ว ถ้าพูดถึงการออกแบบ architecture ของ software เรามักจะพูดถึงเรื่องของ Architecture attribute มากกว่า Business attribute
แต่กลับไม่เคยพูดถึงว่า ระบบที่ออกแบบมามานั้น มีคุณค่าเชิง business อย่างไรบ้าง สร้างมาเพื่อสนับสนุน business นั้น ๆ จริงไหม Architecture ที่ออกแบบมามันตอบโจทย์ business อะไรบ้าง
หรือถ้าเรานำเอาเรื่องของ bussiness value มาพูดถึงก่อน technical เราน่าจะได้ระบบงานที่เฉพาะเจาะจงกับ business นั้นเลยหรือไม่ ซึ่งน่าจะมีผลดีต่อ business มากกว่าหรือไม่ ? ซึ่งตรงนี้ก็น่าคิดนะ
ช่วงนี้การทำงานแบบ Remote หรือ Work From Home (WFH) หรือบางคนอาจจะแย้งว่า มันคือ Work From Coffee shop มากกว่า แน่นอนว่า การทำงานแบบ Remote ของทีมพัฒนา software จำเป็นต้องมีเครื่องมือที่ดี เพื่อให้ทำงานร่วมงานกันได้ดี ดังนั้นเรามาแบ่งปันกันหน่อยว่า ใช้เครื่องมือะไรกันบ้าง
ทาง O'reilly ได้ปล่อยหนังสือแบบฟรี ๆ ชื่อว่า What is SRE ? ซึ่งย่อมาจาก Site Reliability Engineering เป็นอีกเรื่องที่สำคัญของระบบงานในปัจจุบัน เพื่อช่วยทำให้ระบบงานมีความถูกต้องและน่าเชื่อถือ
บทที่ 1 เรื่อง Why is This a Great Time to Learn Elm ? ทำไมถึงเป็นช่วงเวลาที่ดีมาก ๆ สำหรับการเรียนรู้ Elm โดยจะมีเนื้อหาประกอบไปด้วยสิ่งต่าง ๆ ดังนี้
Elm คืออะไร
จุดเด่นของ Elm สำหรับการพัฒนา frontend ของ web
เปรียบเทียบกับ JavaScript
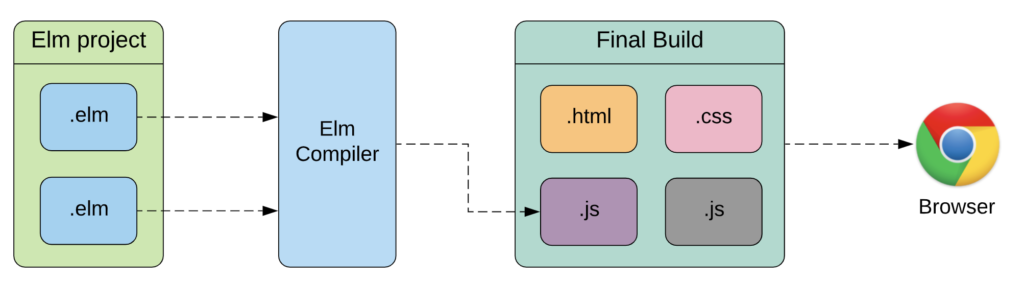
เริ่มต้นพัฒนาระบบงานด้วย Elm ซึ่งมีตัวช่วยทั้ง Ellie-app, Cloud9 และ Text Editor
มาเริ่มกันเลย
Elm คืออะไร
เป้าหมายหลัก ๆ คือ นำแนวทาง functional programming มาใช้สำหรับการพัฒนา frontend ของ web และช่วยทำให้ได้รับระสบการณ์ในการพัฒนาที่ดีกว่าเดิม รวมทั้งยังช่วยลดปัญหา error ที่มักเจอบน production เช่น JavaScript error เป็นต้น
นั่นหมายความว่า Elm จะทำการตรวจสอบในช่วง compile time ว่า จะมี error ใด ๆ มีโอกาศเกิดขึ้นได้บ้าง ทำให้เรารู้ปัญหาต่าง ๆ ตั้งแต่การ coding กันเลย นั่นช่วยสร้างความมั่นใจให้นักพัฒนาได้อย่างสูง
ที่สำคัญ Elm สร้างด้วยแนวทางของ functional programming หนึ่งในนั้นคือ Pure function ช่วยทำให้ไม่เกิด side effect รวมทั้งเรื่องของ immutable ด้วย ทำให้การ debug ง่ายขึ้นเป็นกอง