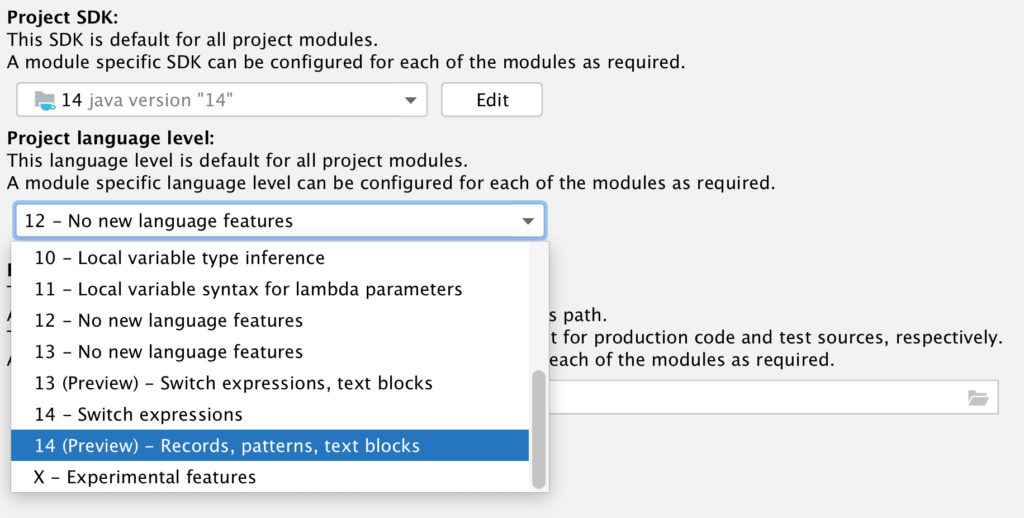
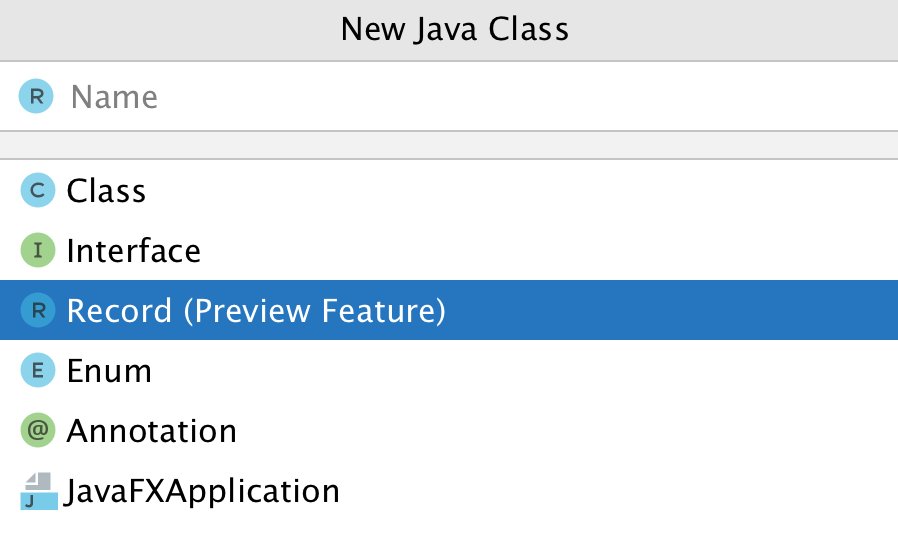
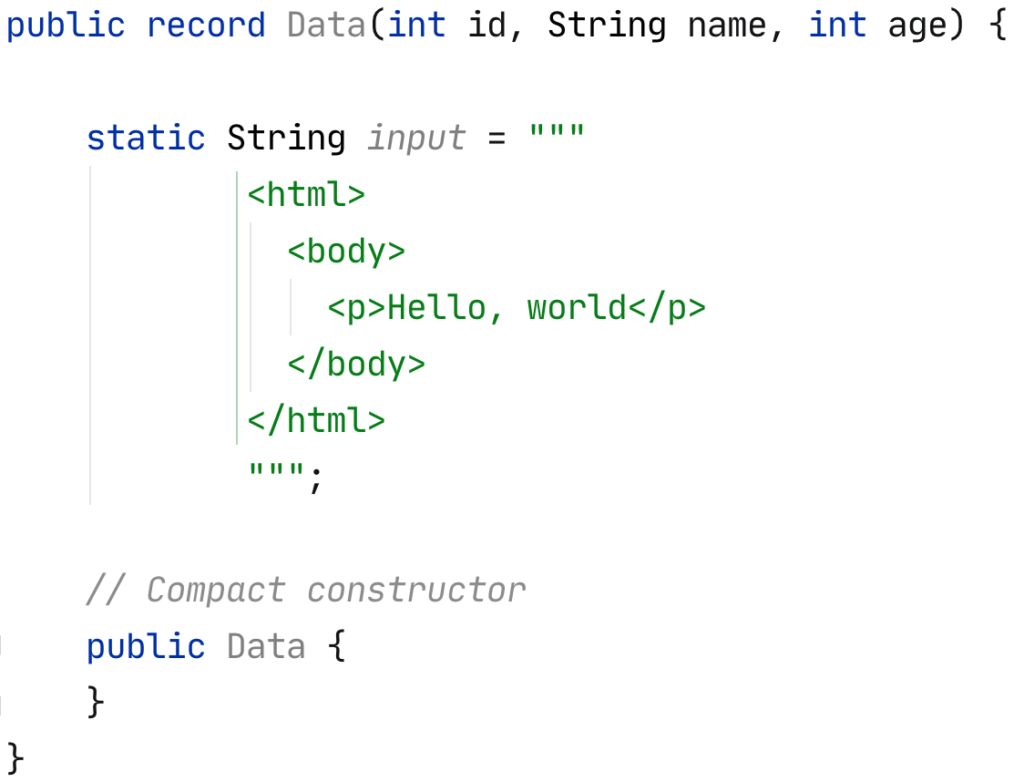
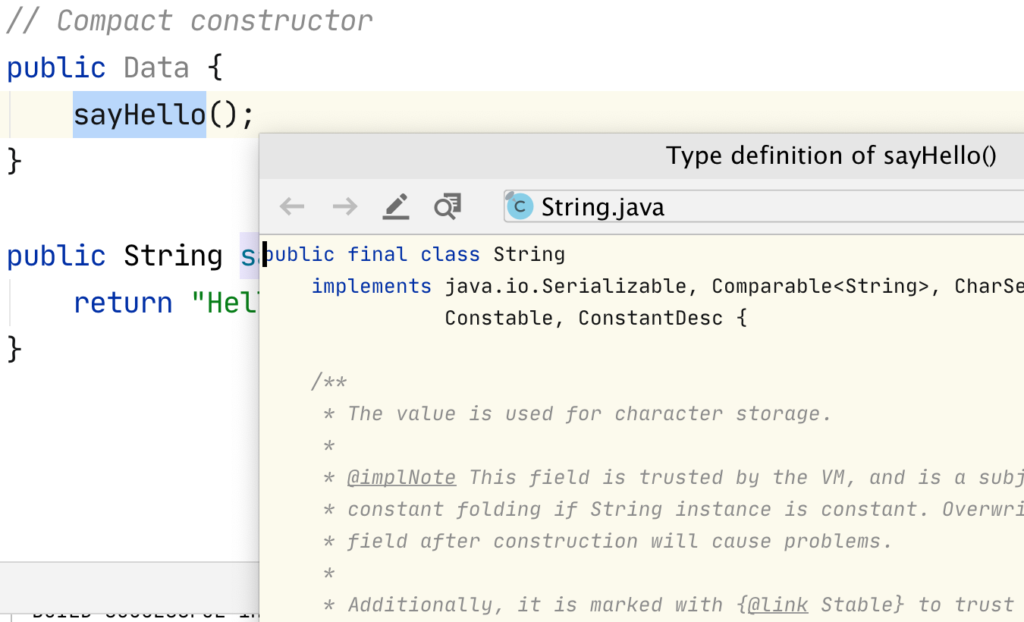
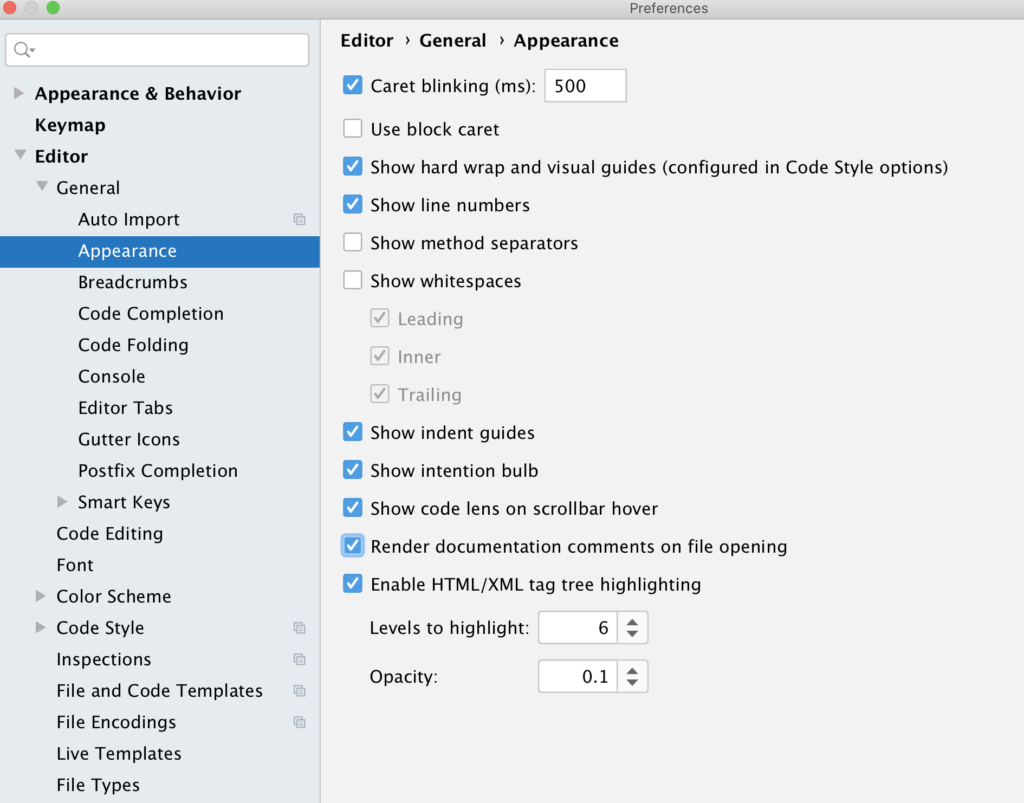
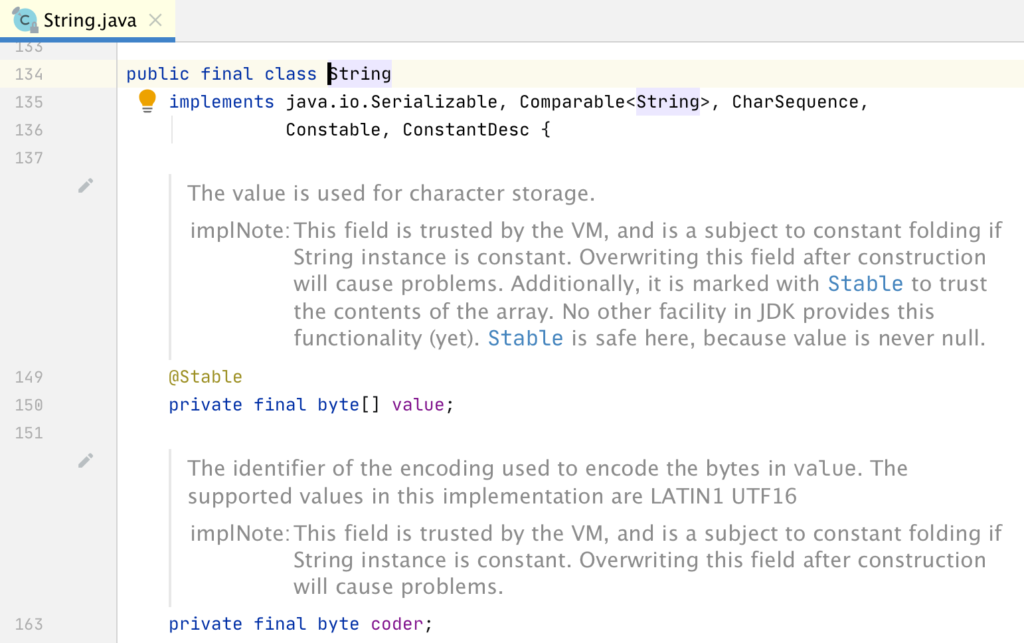
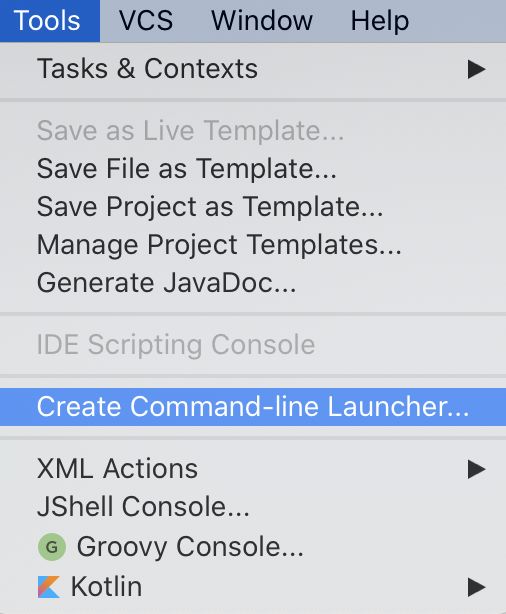
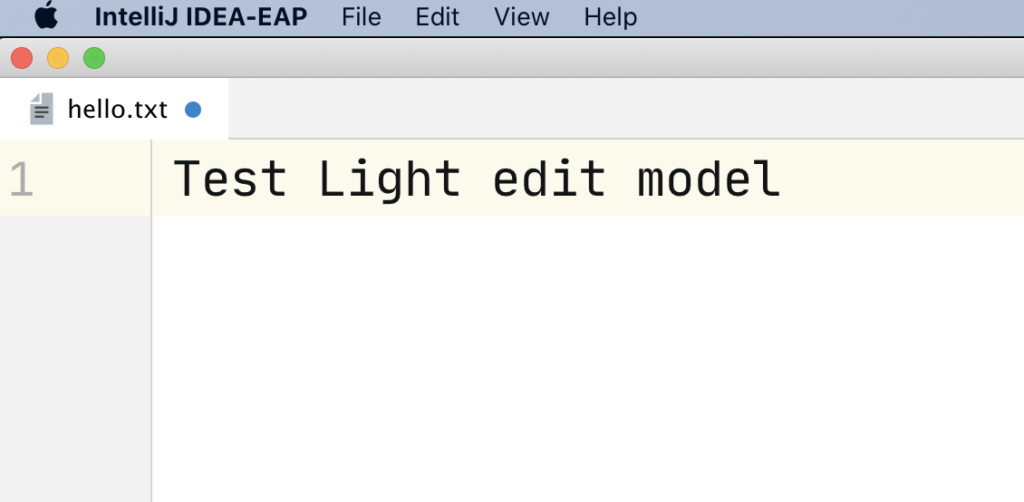
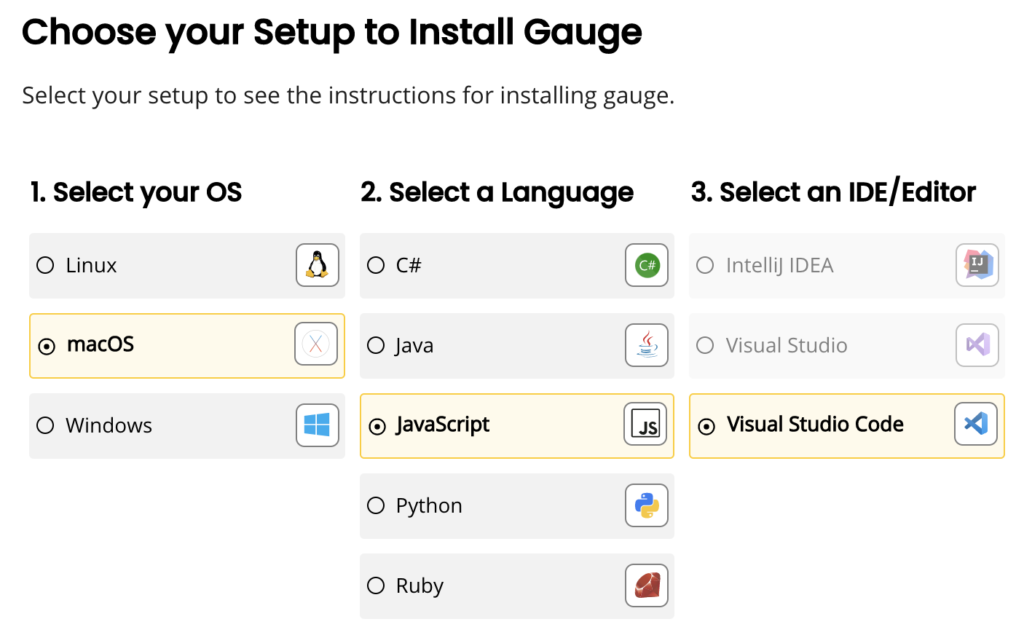
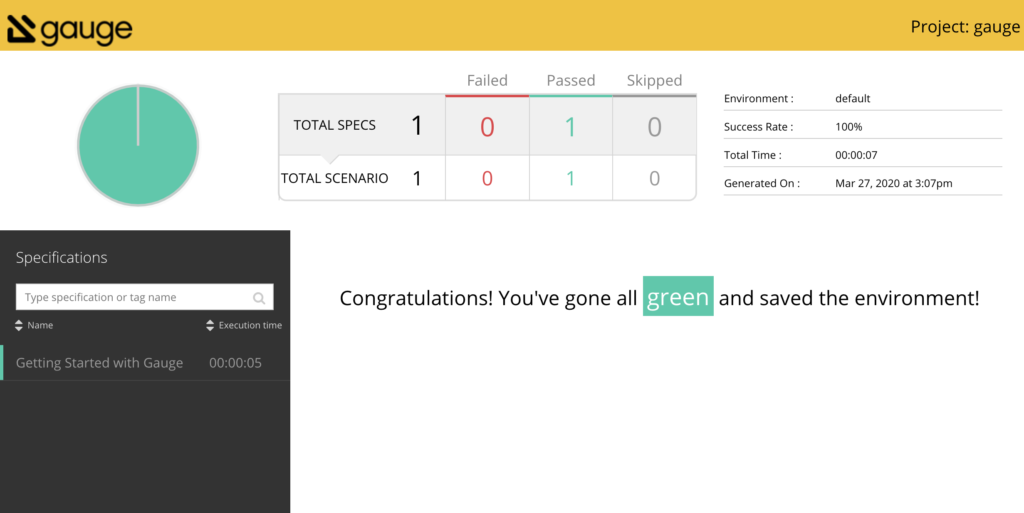
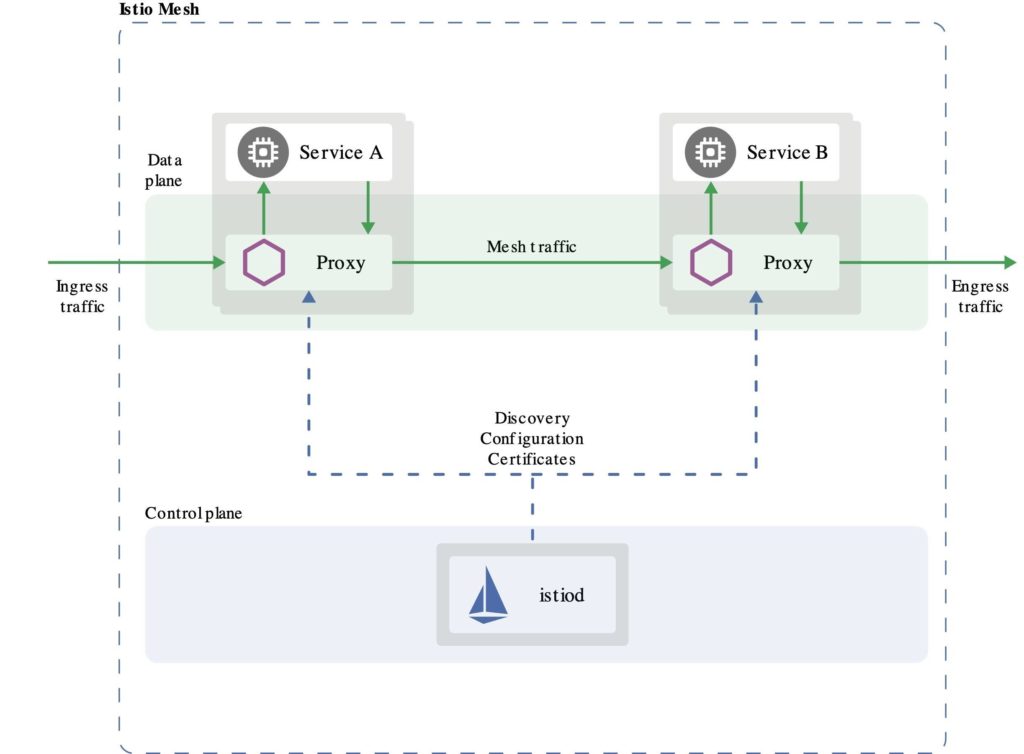
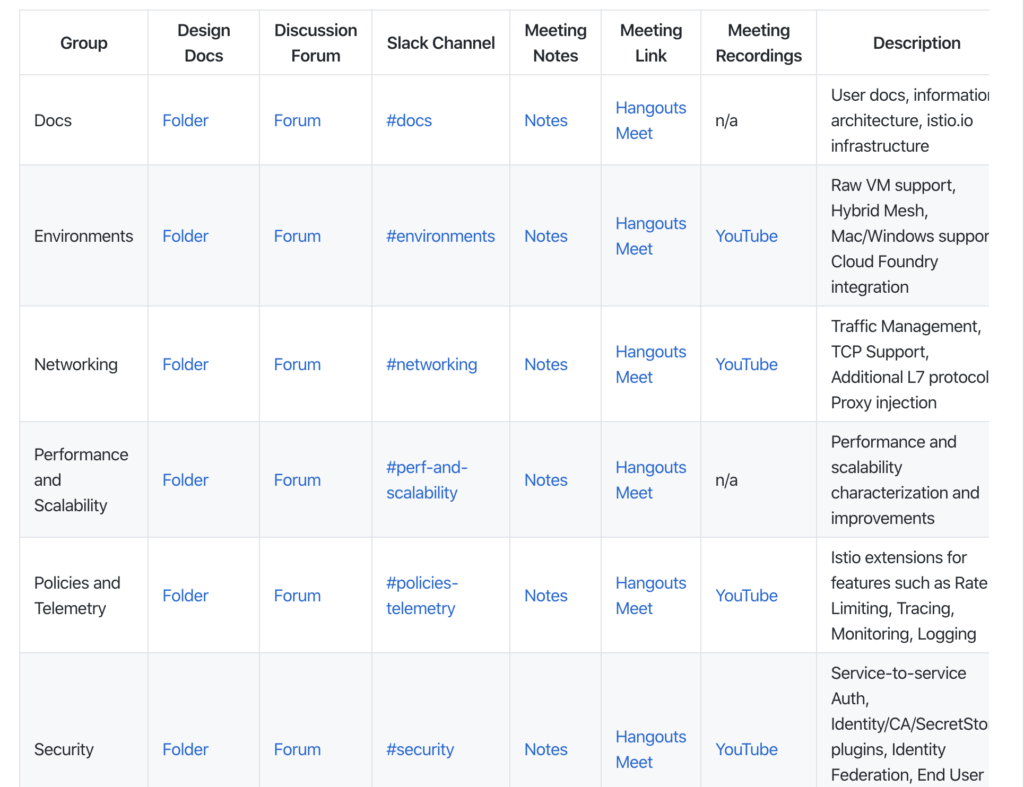
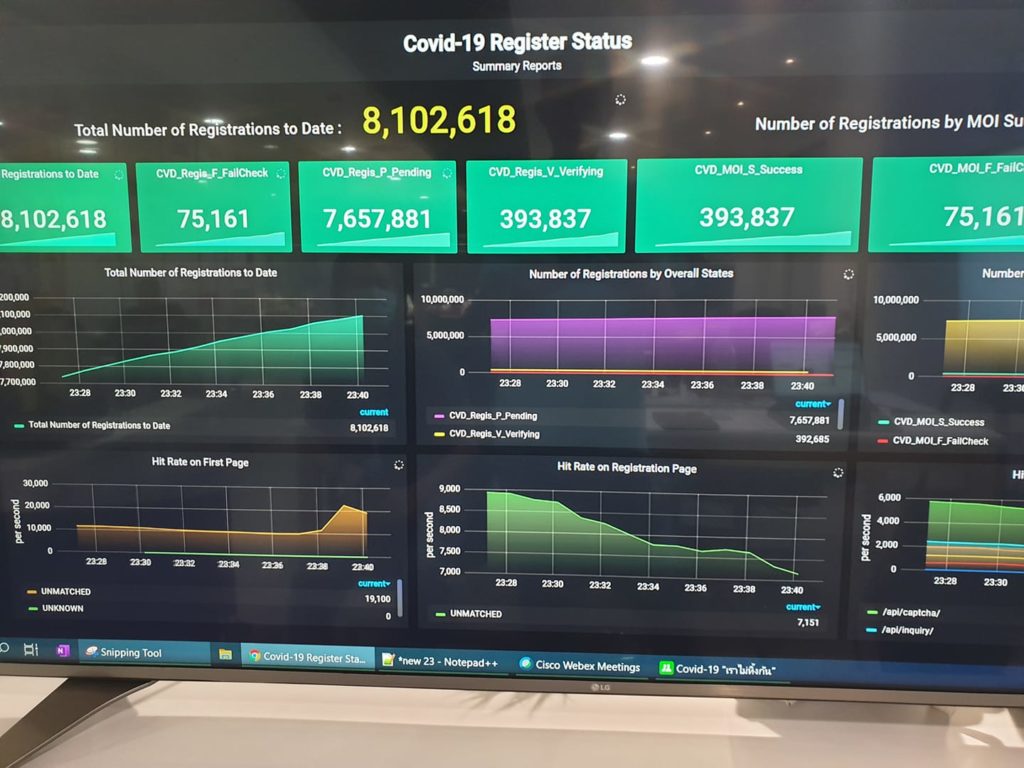
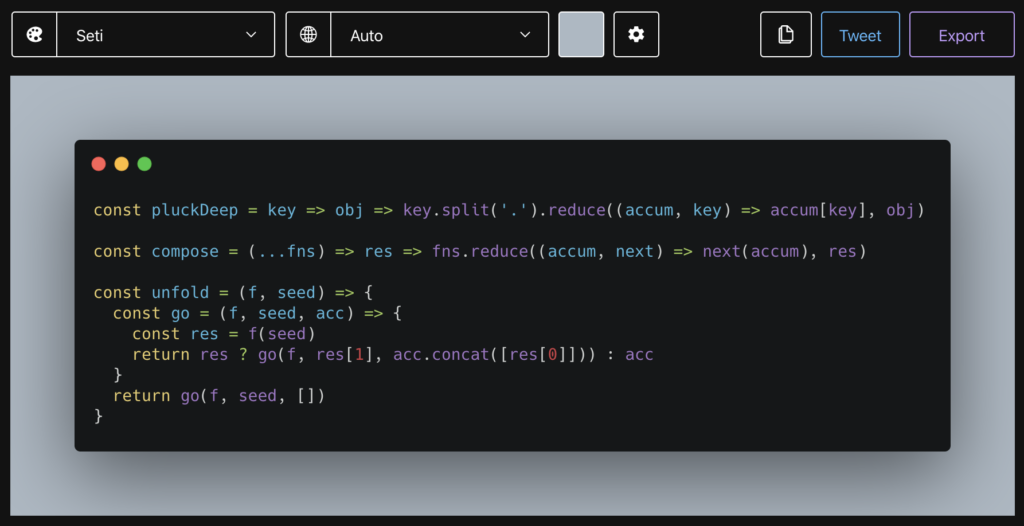
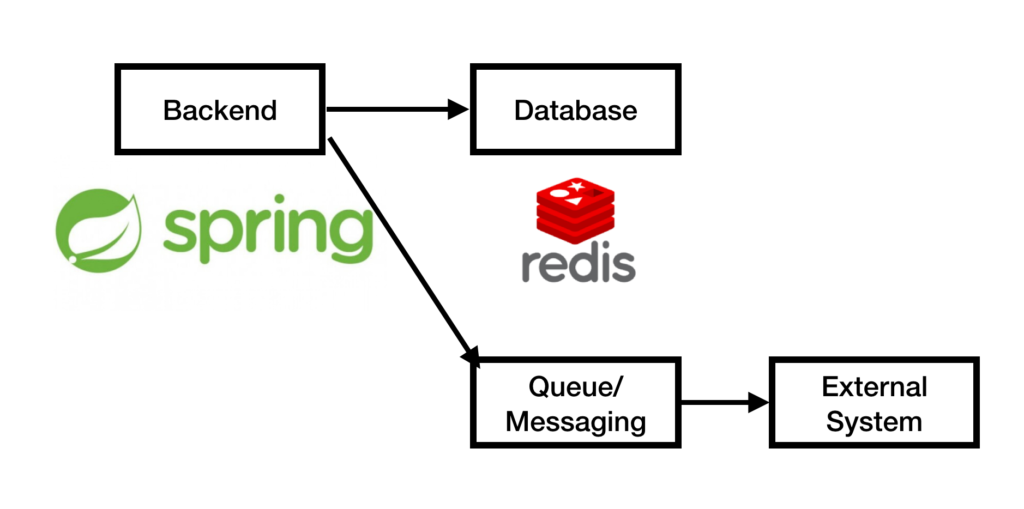
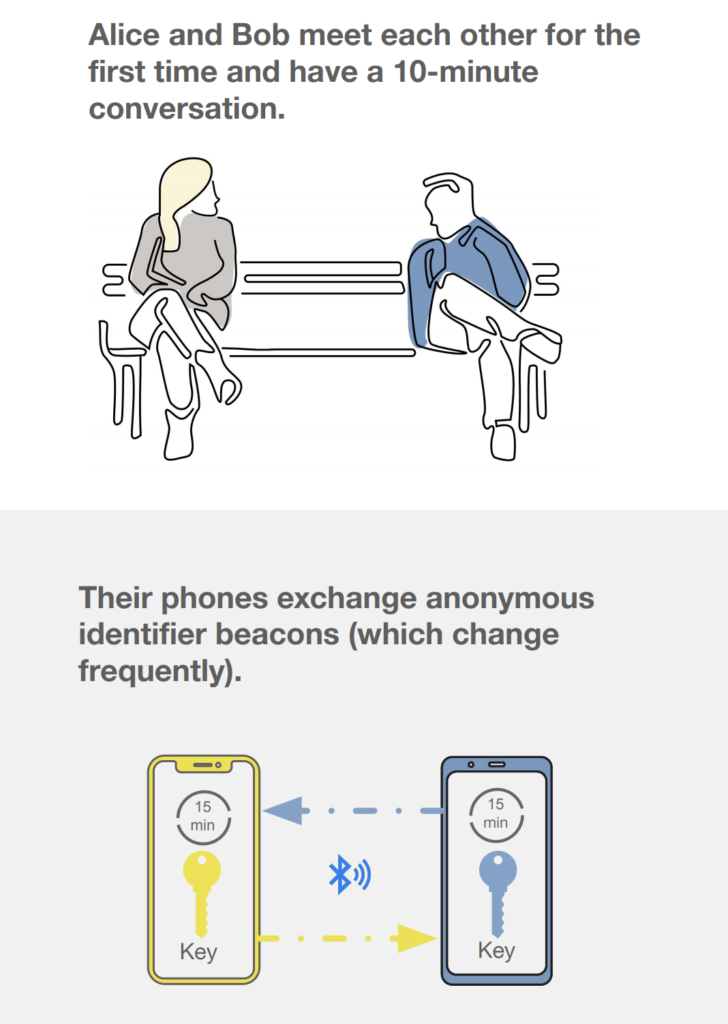
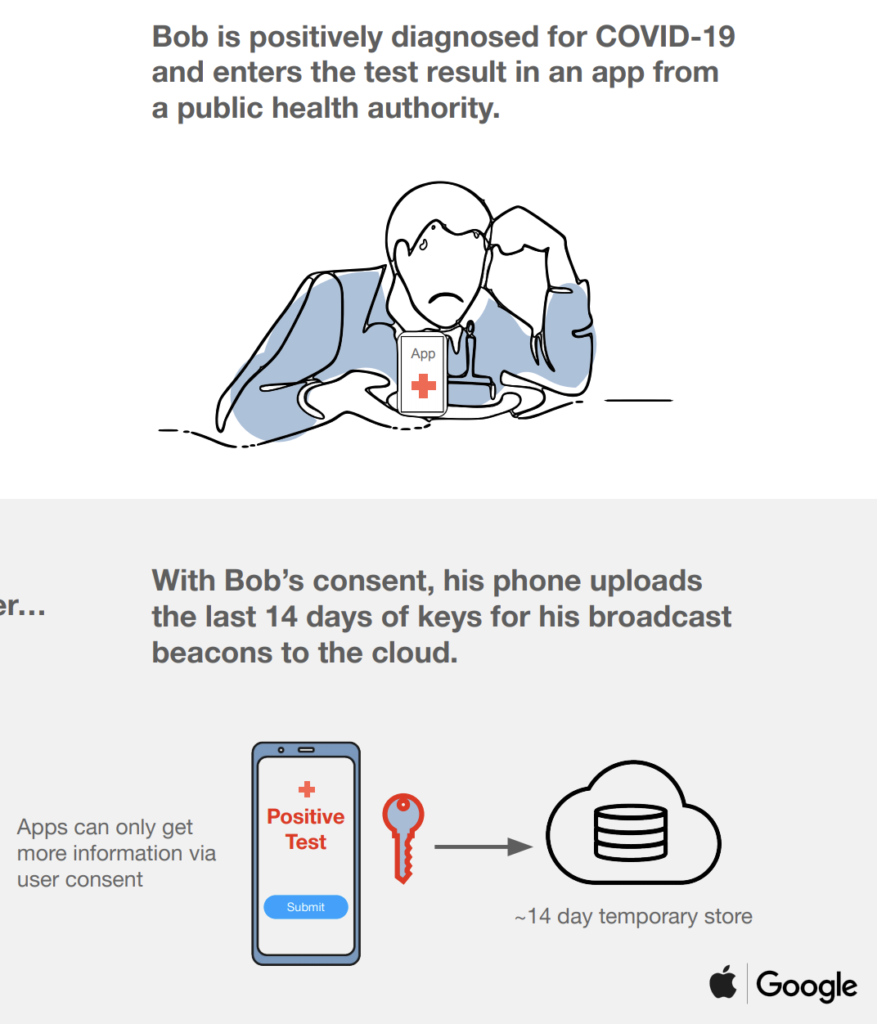
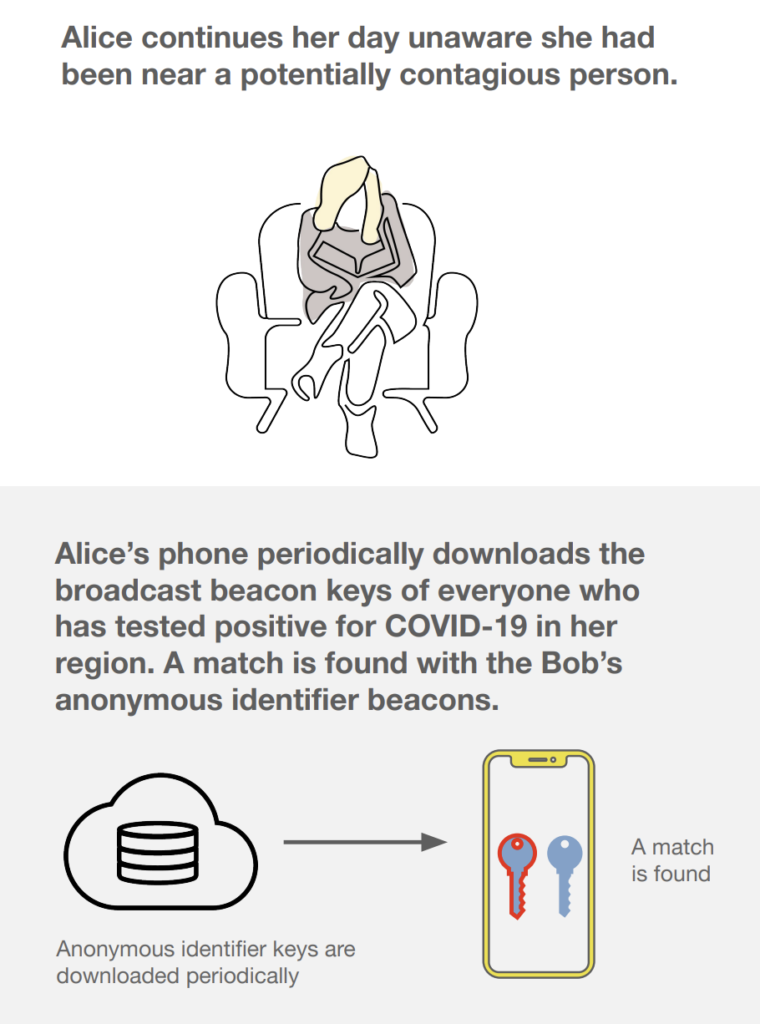
ในการ run End-to-End test นั้น สามารถใส่ option grep และ invertGrep ได้ เพื่อทำการเลือก test case ที่จะ run ได้ด้วย ชื่อในรูปแบบที่ต้องการ แน่นอนว่าสนับสนุน Regular expression ทำให้การทดสอบมีคงวามยืดหยุ่นมากยิ่งขึ้น
ยกตัวอย่างเช่น จะ run test case ที่ไม่มีคำว่า welcome
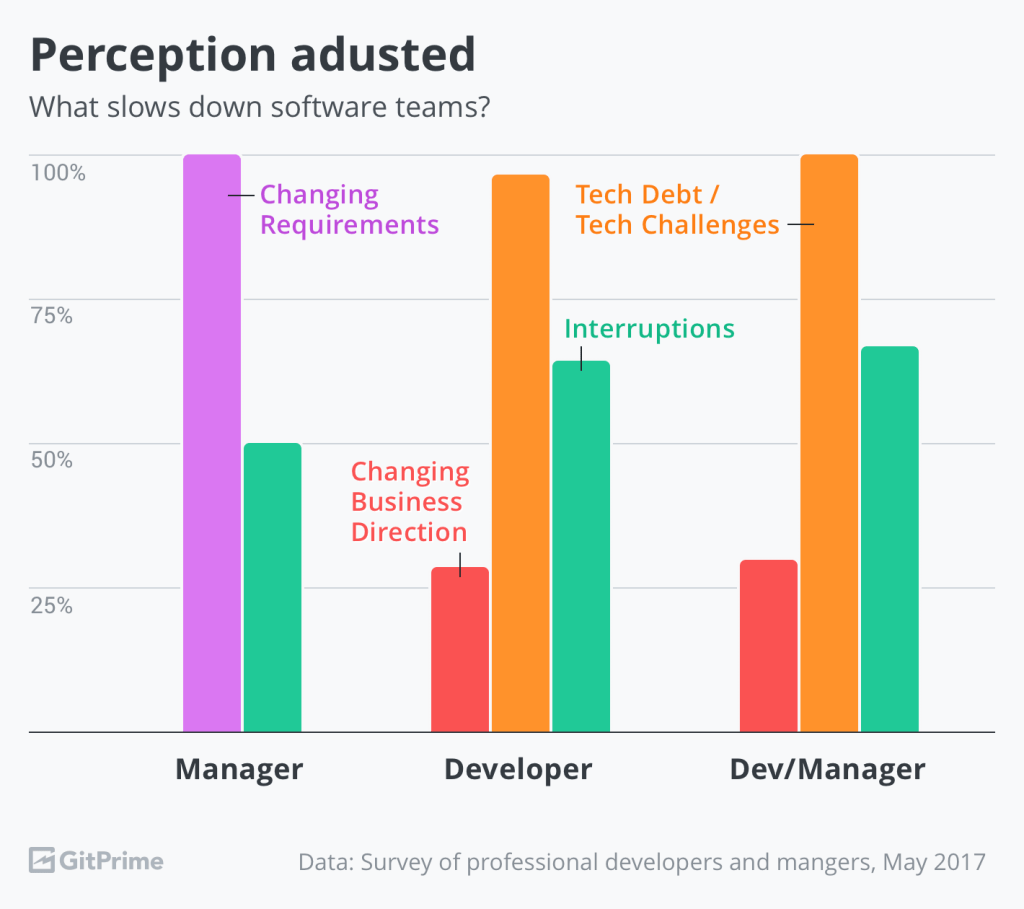
อ่านบทความจากการทำแบบสำรวจเมื่อปี 2018 (เก่าแล้ว แต่น่าจะมีโยชน์) เป็นเรื่อง Developer Team Performance :: Why your team slows down and What to do about it จากการสำรวจได้ข้อมูลที่น่าสนใจมากมาย เนื่องจากมีสาเหตุมากมายที่ส่งผลให้ทีมช้าลง ทั้งจากภายนอกและภายใน ล้วนนำไปสู่การส่งมอบงานที่ล่าช้าและไม่ตรงตามที่คาดหวัง แน่นอนว่า มันเกิดขึ้นบ่อยมาก !!!
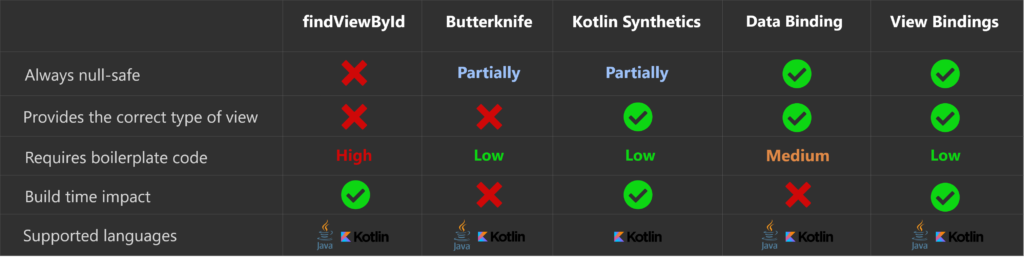
อ่านบทความเรื่อง Evolution of Finding Views by ID in Android ทำให้เราเห็นวิวัฒนาการของ Find View by ID ในการพัฒนา Android app มีความเป็นมาที่ยาวนานและน่าสนใจจริง ๆ จึงเขียนสรุปสิ่งที่ได้จากบทความนี้ไว้หน่อย ถ้าไม่มี ID ใน view ของ Android app ก็ยากที่จะทดสอบแบบอัตโนมัติอย่างมาก
ในการพัฒนา Android app นั้น
นักพัฒนาทุกคนจะทำการเข้าถึง element ต่าง ๆ ในไฟล์ XML Layout จะต้องใช้งานผ่าน method findViewById() อย่างแน่นอน มันดูง่ายมาก ๆ นะ
แต่มาจาก Android เลยก็คือ Data binding library ทำให้ทำการ binding element ต่าง ๆ ในไฟล์ Layout XML เข้ากับ Data sources ได้ ซึ่งทำได้ในไฟล์ Layout XML นั่นเอง จากนั้น Android Studio จะทำการ generate class จากไฟล์ Layout XML ให้อัตโนมัติ เช่น activity_main.xml จะ generate class ActivityMainBinding มาให้ ใช้งานได้ทั้ง Java และ Kotlin