แต่มีหลาย ๆ project ไม่ได้ทำเช่นนี้ ทำให้เกิดการจัดรูปแบบของ code ตามใจตัวเองเยอะมาก ๆ ซึ่งทำให้การทำงานร่วมกันลำบากน่าดู ยกตัวอย่างสิ่งที่เจอบ่อยคือ space bar vs tab เป็นต้น
ก่อนจบมีอีกเรื่องเพิ่งเจอเลยคือ ขยัน comment code เหลือเกิน Version control ก็ใช้ อะไรไม่ใช้ก็ลบไปสิ จะ comment ไว้ทำไม ?
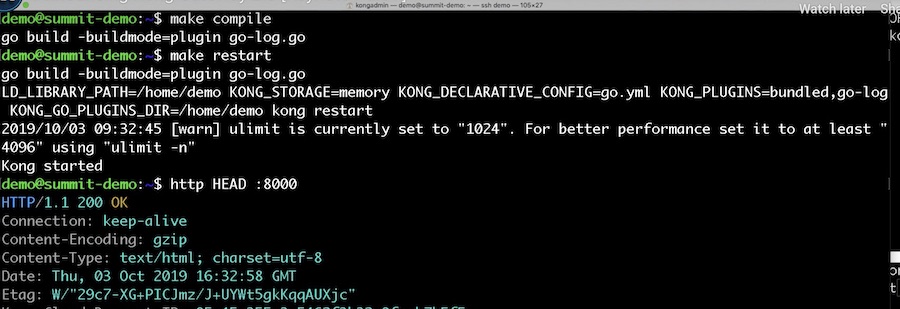
แนะนำให้ใช้ Kong Preview Version (Alpha) แต่จากที่ลอง run แล้วมันเดี้ยง ๆ เลยไปใช้ version 2.0.0rc1 แทน ซึ่งทั้งสอง version นี้แตกต่างกันเรื่อง config ของ DBless
โดยใน Kong Preview Version นั้นต้องกำหนด environment variable ชื่อว่า KONG_STORAGE: memory แต่ใน version 2.0.0rc1 นั้นต้องใช้ KONG_DATABASE: off เช่นเดิม
ทั้งเรื่องของ communication หรือการติดต่อสื่อสารระหว่าง services รวมไปถึงเรื่องการจัดการ state หรือ data ที่กระจายอยู่ในแต่ละ services ว่าต้องทำอย่างไร
ปิดท้ายด้วยการสรุปเกี่ยวกับ Redis + Microservices
ไว้ดังนี้
Database ที่ช้า ๆ ไม่น่าจะเหมาะกับ Microservices
Redis สามารถใช้เป็น database ของแต่ละ service ได้ เนื่องจากสามารถ config ให้ persist ข้อมูลบน disk ได้ ข้อมูลไม่หาย ดังนั้นควรใช้ disk ที่มีความเร็วสูงนะ
ได้รับงานเล็ก ๆมาลองทำเล่นดู นั่นคือ การดึงข้อมูลจาก web มาเพื่อใช้งานต่อไป เนื่องจาก web ปลายทางไม่มี API เตรียมไว้ให้ ดังนั้นการดึงข้อมูลหรือเรียกว่า Web Scraping จึงเป็นทางเลือกที่น่าสนใจ แต่ก็ต้องระวังด้วยว่า web ปลายทางจะ block หรือตรวจจับการดึงข้อมูลรูปแบบนี้หรือไม่
เมื่อได้รู้ความต้องการและปัญหาที่ต้องแก้ไขแล้ว
จึงมาถึงเครื่องมือที่ใช้งาน ซึ่งจากที่เคยทำมามีเยอะเลย ทั้งเรียกไปยังปลายทางตรง ๆ แล้วเอาข้อมูลมา processing ต่อ หรือเปิด web browser แล้วตัดเอาข้อมูลใน element ที่ต้องการมา
โดยแนวทางที่เลือกคือ เปิด web browser นี่แหละ แต่จะเป็น web browser ขึ้นมาก็น่าจะช้ามาก ๆ ดังนั้นจึงเลือกเป็น headless mode ดีกว่า และ library แรกที่เด้งมาจากในหัวเลยคือ Puppeteer นั่นเอง ก็เลยใช้ซะ ทำงานผ่าน DevTool protocol สำหรับควบคุม Google Chrome เท่านั้น ซึ่งเร็วแน่นอน !!
ไปยังหน้าหรือ URL ของ web ที่เราต้องการ แน่นอนว่า ใส่ option ไปได้อีก
ทำการเข้าถึง element ที่เราต้องการนำข้อมูลมาใช้งาน โดยสามารถเข้าถึงได้ด้วย selector ของ element นั้น ๆ ตรงนี้ก็ต้องใช้ความเข้าในเรื่อง Web และ DOM กันนิดหน่อย แต่ไม่ยากจนเกินไป
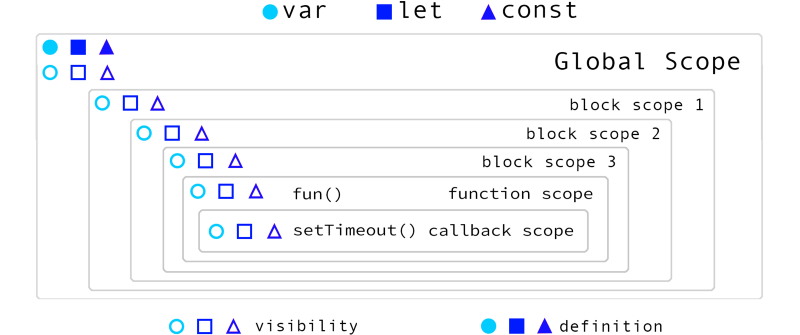
ใช้งานก่อนการประกาศได้ด้วย แต่ค่าที่ได้คือ undefined ซึ่งไม่ error ด้วย !! แถมตัวแปรที่ประกาศด้วย var คือ i นั้น สามารถถูกใช้งานนอก for loop ได้อีกด้วย เนื่องจาก var นั้นจะมีขอบเขตการทำงานในระดับ function นั่นเอง !! งงดีไหมละ ? ดังนั้น var ก็ไม่ควรใช้ ถ้าไม่เข้าใจหรือรู้จักมันดีพอ !! หรืออย่าใช้เลยดีกว่า
ส่วน let นั้นเพิ่มเข้ามาใน ES6
เพื่อแก้ไขความมึนงงของ var และลดขอบเขตการทำงานอยู่ใน block scope เท่านั้น และไม่สามารถใช้งานก่อนทำการประกาศได้
จากบทความเรื่อง Coding with Feature Flags: How-to Guide and Best Practices ทำการอธิบายเกี่ยวกับ Feature Flag ว่าคืออะไร เป็นอย่างไรบ้าง มีปัญหาอะไรที่ต้องได้รับการแก้ไข มีรูปแบบการใช้งานอย่างไรบ้าง จึงทำการสรุปสิ่งที่น่าสนใจไว้นิดหน่อย ลองไปอ่านเพิ่มเติมและนำไปใช้งานกันดู
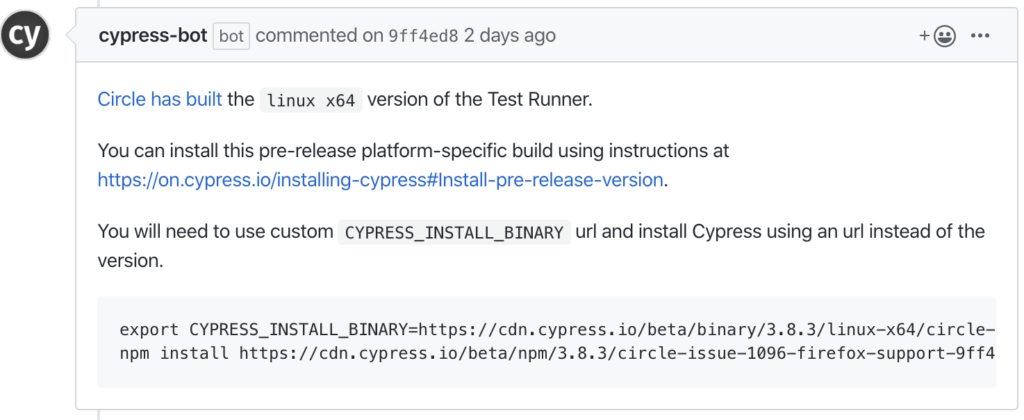
ทำการติดตั้งแบบ Pre-release version นั่นเอง หรือไปดูใน PR#1359 ก็ได้ เราสามารถทำการลอง run ตามได้เลย แนะนำให้ดูใน comment ล่าสุด จะเป็นการ run แบบอัตโนมัติ ซึ่ง run OS Linux นะ
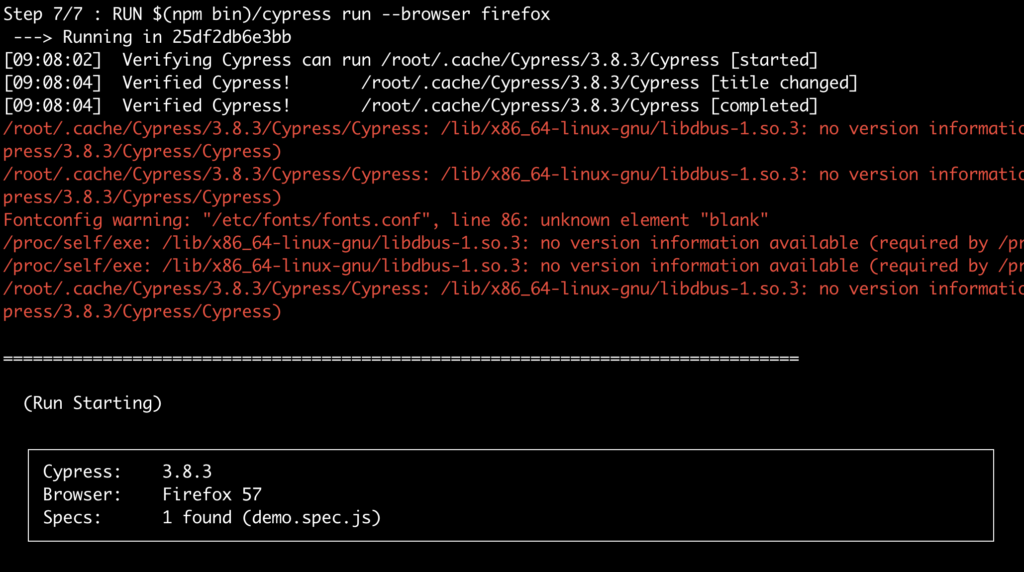
ทำการกำหนด environment variable ชื่อว่า CYPRESS_INSTALL_BINARY ของ cypress ใน version ที่กำลังทดสอบ จากนั้นก็ทำการติดตั้ง ซึ่งถ้าเป็นชาว Linux ไม่น่ามีปัญหาอะไร สามารถใช้งาน $cyprees run --browser firefox ได้เลย