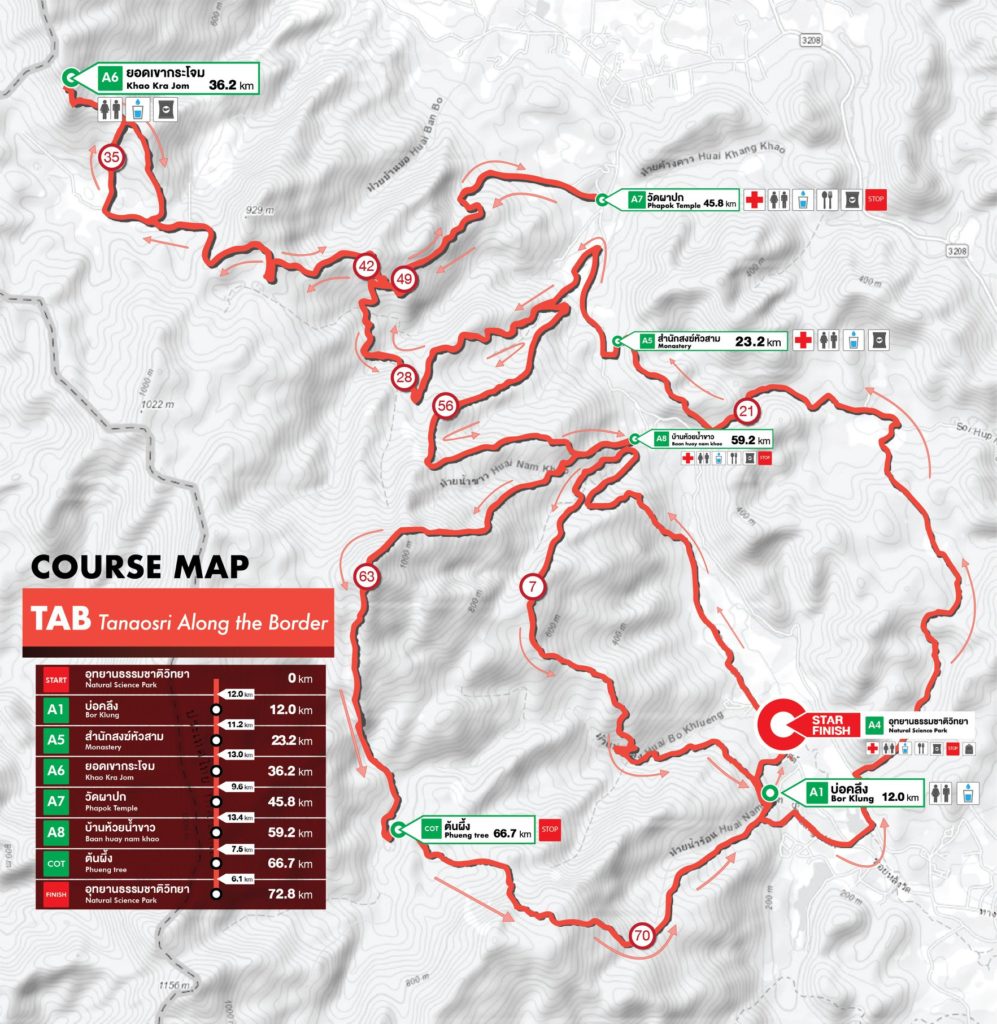
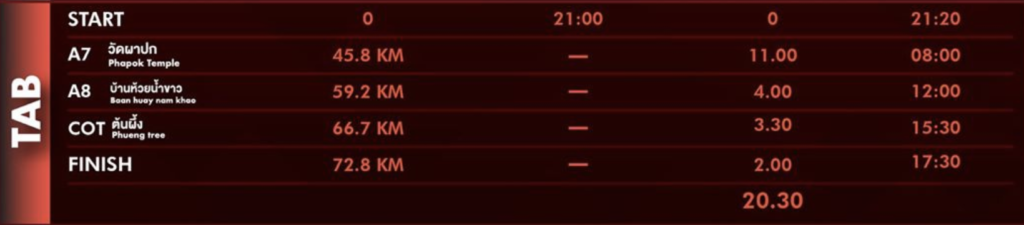
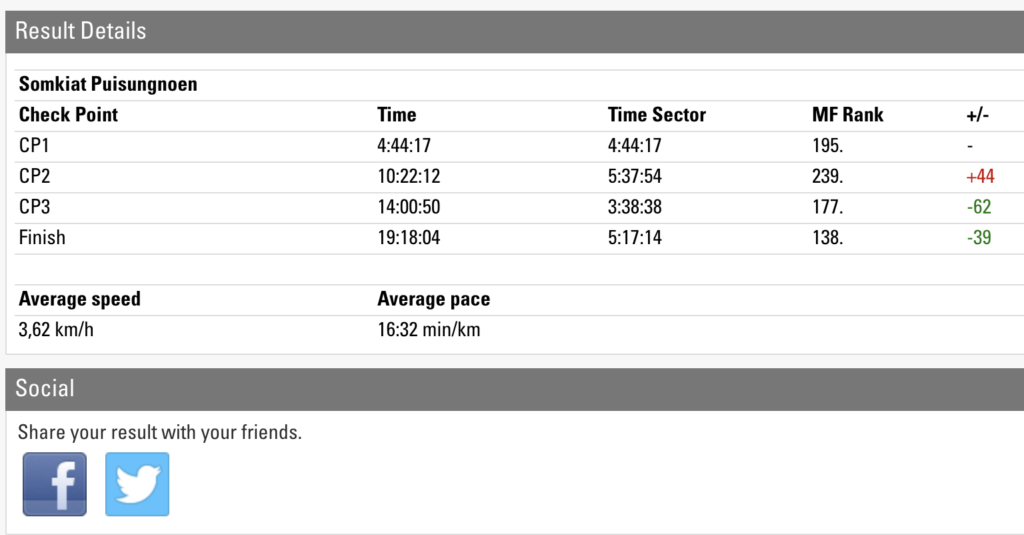
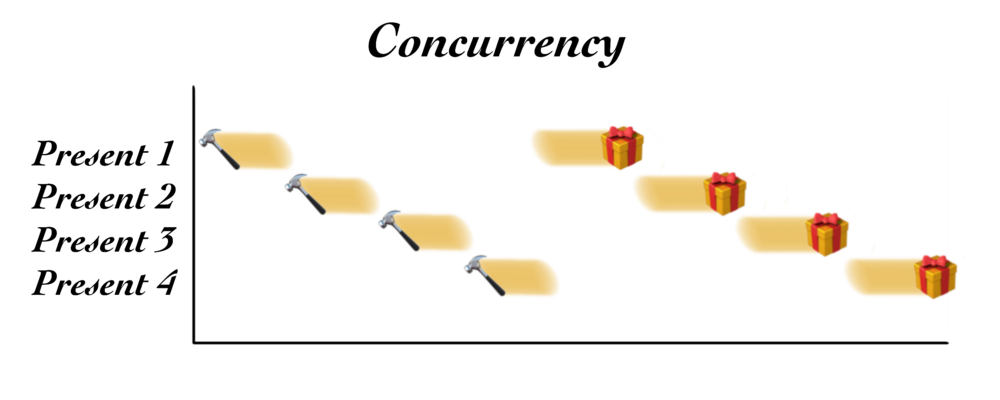
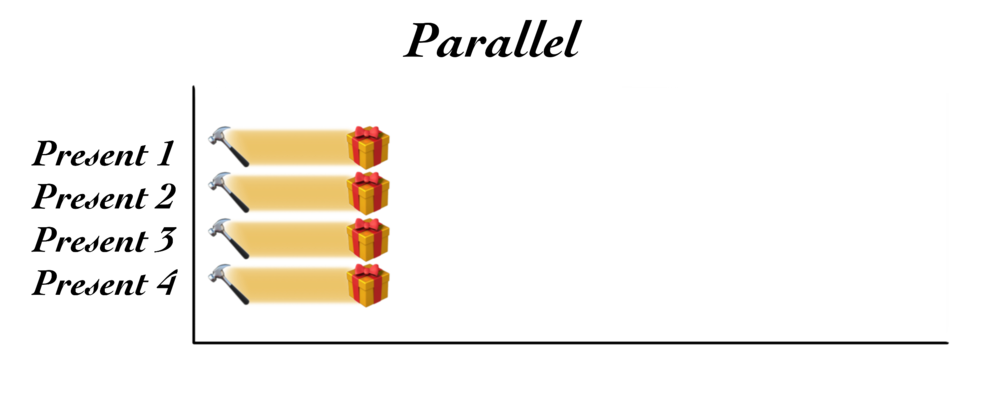
สำหรับใครเป็นแฟนหนังสือ The Phoenix Project
ไม่น่าพลาดกับหนังสือใหม่ชื่อว่า The Unicorn Project
เล่าเรื่องราวเกี่ยวกับ DevOps transformation
อาจจะไม่ถูกใจกับองค์กรขนาดใหญ่ เพราะว่าเกือบทุกอย่างที่มันจะขัดแย้ง
โดยจะแนะนำ 5 แนวทางสำหรับการทำงาน
ซึ่งจะช่วยขับเคลื่อนองค์กรไปในทางที่ยั่งยืน
5 แนวทางประกอบไปด้วย
- Locality and Simplicity
- Focus, Flow, and Joy
- Improvement of Daily Work
- Psychological Safety
- Customer Focus
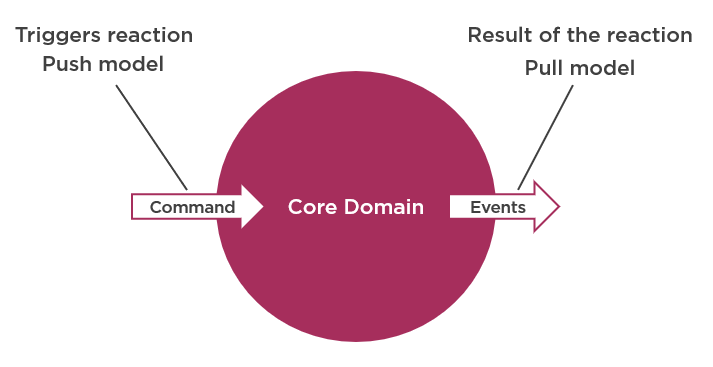
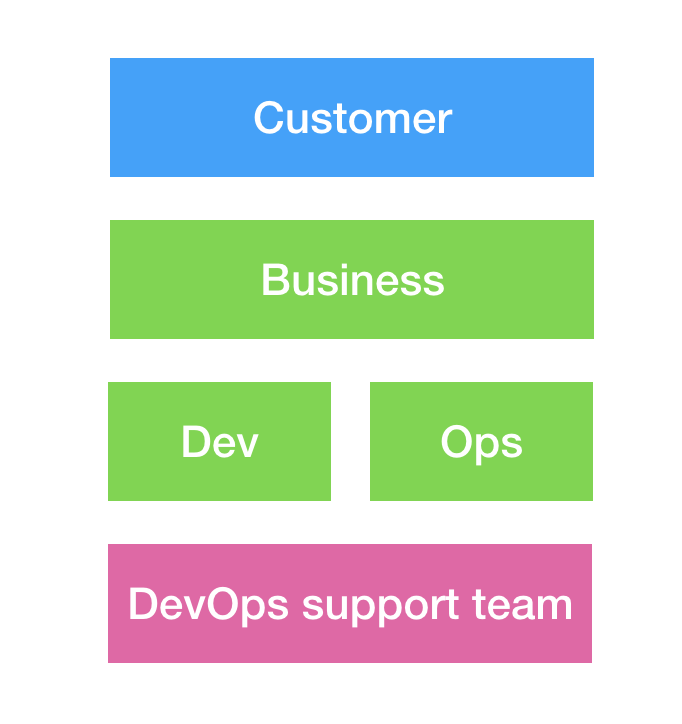
Locality and Simplicity
เน้นไปที่การออกแบบระบบและองค์กร
เน้นไปที่ locality ของทีมงาน
มีการอ้างอิงไปถึงแนวทาง Two-pizza rule team
เน้นที่กระบวนการทำงานที่ Simplicity
นั่นคือ กระบวนการทำงานที่ช่วยเหลือให้คนทำงาน
สามารถทำงานได้ง่าย มิใช่ทำให้การทำงานยากขึ้น !!
โลกภายนอกเราควบคุมมันยาก
ส่วนโลกภายในองค์กรเราน่าจะควบคุมได้และควรมีประโยชน์ต่อคนทำงาน
มาที่ code ของระบบงาน
ในหนังสือมีคำถามหนึ่งที่น่าสนใจคือ
เป็นไปได้ไหม ที่เราจะรู้ได้ทันทีว่า เมื่อมีการเปลี่ยนแปลงใด ๆ ในระบบงานแล้ว
เราสามารถรู้ผลจากการเปลี่ยนแปลงนั้นได้อย่างรวดเร็ว
ถ้าทำได้นั่นคือ Simplicity เลยนะ
หรือถ้าทดสอบผ่านหมดแล้ว
สามารถนำ code ชุดนี้ deploy ขึ้น production ได้ไหม ?
ถ้าตอบว่าไม่ได้ หรือต้องผ่านการ UAT หรือทดสอบในวันจันทร์ก่อน !!
คิดว่าเราน่าจะมีปัญหาเรื่องของ Locality and Simplicity
Focus, Flow, and Joy
มันเป็นเรื่องความรู้สึกของคนทำงานในแต่ละวัน
ว่าการทำงานมันน่าเบื่อไหม
ว่าจะทำอะไรแต่ละอย่างต้องรอคนอื่น ๆ ก่อน
ยิ่งถ้าคนหนึ่งไม่อยู่แล้วคนส่วนใหญ่ต้องรอ แบบนี้ไม่น่าจะดี
มีงานหลาย ๆ อย่างซ่อนไว้ หรือ รู้อยู่ไม่กี่คน
บางงานก็มีคนเดียวที่รู้
หนักกว่านั้น ไม่รู้ว่ามันทำงานอย่างไร รู้อย่างเดียวว่ามันทำงานได้ !!
สิ่งต่าง ๆ เหล่านี้ส่งผลต่อคนทำงานทั้งนั้น
ทั้งไม่ได้ Focus กับงานจริง ๆ
ทั้ง Flow การทำงานแย่
ทั้งไม่สนุกกับงานเลย
จะดีกว่าไหมที่เราจะ Focus ไปที่งานที่สำคัญจริง ๆ
ค่อย ๆ สร้างสิ่งที่สำคัญออกมาทีละชิ้น
จากนั้นส่งมันไปให้ผู้ใช้งาน
เพื่อรับ feedback มาปรับปรุงต่อไป
มันน่าจะช่วยทำให้คนทำงานรู้สึกดีกว่าหรือไม่ ?
ได้รับทั้งความท้าท้าย ได้เรียนรู้ ได้ค้นหา ได้ฝึกฝนจนเชี่ยวชาญ
และที่สำคัญคือ สนุกกับสิ่งที่ทำ
Improvement of Daily Work
เป็นองค์กรและทีมที่มีการปรับปรุงการทำงานในทุกวันอย่างต่อเนื่อง
มันคือองค์กรแบบ Continuous Learning
ยกตัวอย่างเช่น
ระบบงานเคยสามารถเพิ่ม feature ใหม่ ๆ เข้ามาได้ในระยะเวลาไม่กี่สัปดาห์
แต่เมื่อเวลาผ่านไปสัก 1-2 ปี กลับพบว่า
เราใช้เวลาในการเพิ่ม feature ใหม่ ๆ นานนับเดือน
มันแสดงให้เห็นว่า เราไม่ได้เรียนรู้อะไรเลย
รู้ทั้งรู้ว่ามีปัญหา กลับไม่ทำการปรับปรุงให้ดีขึ้น
ก่อนที่จะเพิ่ม feature ใหม่เข้าไป
แต่กลับเน้นที่จำนวน feature มากกว่าคุณภาพ
สุดท้ายมันก็ส่งผลกระทบต่อองค์กรเช่นเดิม !!
หนักกว่านั้น มีหลาย ๆ feature จำเป็นต้องทำงานกับหลาย ๆ ทีม
ส่งผลให้กว่าจะนัดคุยกัน
กว่าจะตกลงกัน
กว่าจะพัฒนา
กว่าจะทดสอบ
กว่าจะ deploy
ต้องใช้เวลานานมาก ๆ นี่คือปัญหาหรือไม่ ?
หรือมันกลับกลายเป็นเรื่องปกติขององค์กร ?
ดังนั้นต้องกลับไปเรื่องแรกคือ Locality and Simplicity
และเรื่อง Focus, Flow, and Joy
Psychological Safety
ปัญหาต่อมาที่ทำให้คนทำงานไม่อยากหรือกล้าที่จะปรับปรุงอะไรเลย
เนื่องจากถ้าทำผิดขึ้นมาแล้ว จะมีบทลงโทษ
ทำให้ทุกคนมีความกลัว
ส่วนใหญ่จะเลือกทางปลอดภัยคือ ไม่ต้องทำอะไรใหม่ ไหลตามน้ำไป !!
ลองดูในองค์กรว่า
เมื่อระบบมีปัญหาขึ้นมาแล้ว
จะมีคำถามว่า ใครเป็นต้นเหตุของปัญหาหรือไม่ ?
ถ้ามีบอกได้เลยว่า น่ากลัวมาก ๆ
ส่วนการแก้ไขปัญหาเหล่านี้ ก็ชอบทำแบบไม่แก้ไขที่ต้นเหตุ
แต่กลับไปแก้ไขที่ปลายเหตุเช่น
เราต้องสร้างกฏการทำงานใหม่ขึ้นมา
เราต้องมีขั้นตอนสำหรับการ approve เพิ่มเข้ามา
นี่คือตัวอย่างของการแก้ไขปัญหา ด้วยการสร้างปัญหาขึ้นมาหรือไม่ ?
ดังนั้นสิ่งที่จำเป็นมาก ๆ คือ ความรู้สึกปลอดภัย
ถ้ามีปัญหาเกิดขึ้นแล้ว
ควรถามว่า อะไรที่ทำให้เกิดปัญหามากกว่าเป็นใคร
และทุกคนต้องพยายามคิดว่า จะทำอะไรในวันพรุ่งนี้ให้ดีกว่าวันนี้อยู่อย่างเสมอ
Customer Focus
เรื่องนี้คงไม่ต้องอธิบายแล้วนะ
ตอนนี้เปิดให้ pre-order กันแล้วที่ ITRevolution.com
และทาง InfoQ ก็ได้ตัดบางส่วนของหนังสือมาให้อ่านกัน
Reference Websites