ช่วงวันหยุดหยิบหนังสือ Remote : Office not required มาอ่านอีกครั้ง เป็นหนังสือที่เขียนออกมาตั้งแต่ปี 2013 แล้ว อธิบายถึงการทำงานแบบ Remote หรือบางคนเรียกว่า Work from Home ซึ่งผมก็มีโอกาสได้ลองทำงานแบบนี้ไป 3 projects ก็เลยทำการสรุปการอ่านหนังสือเล่มนี้ไว้นิดหน่อย
จากบทที่ 1 ของหนังสือ Clean Agile : Back to Basics ว่าด้วยเรื่อง Introduction to Agile พูดเรื่องของ the Iron Cross of project management ซึ่งประกอบไปด้วย
In some ways, programming is like painting. You start with a blank canvas and certain basic raw materials. You use a combination of science, art, and craft to determine what to do with them. - Andrew Hunt
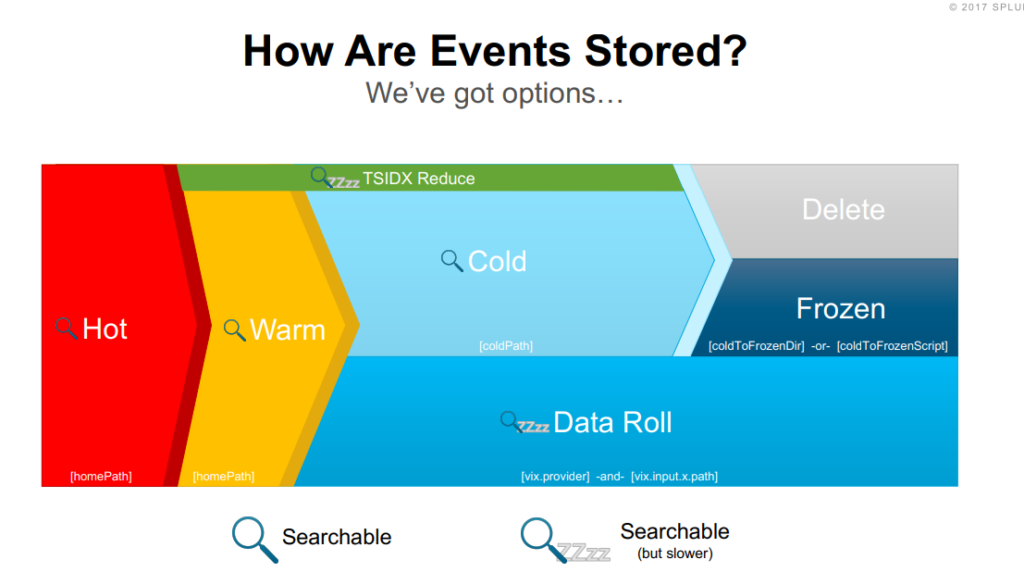
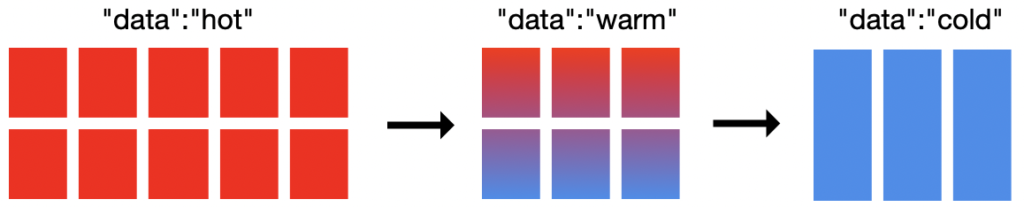
กำหนดนโยบายของ index แต่ละประเภทผ่าน ILM API ได้เลย แน่นอนว่า เราสามารถกำหนดรูปแบบการ rolling data ได้เลย ตามความต้องการ เช่น
ตามขนาดหรืออายุของข้อมูล เพื่อสร้าง index ใหม่ขึ้นมา
กำหนดจุดหรือเวลาของ index ที่ไม่ถูกทำการแก้ไขได้
ทำการกำหนดจุดหรือเวลาให้ลบ index ไปเลย
มาดูตัวอย่างของการใช้งาน ILM API
สำหรับกำหนด Hot index ให้สร้าง index ใหม่ เมื่อ Index มีขนาดใหญ่กว่า 50GB และข้อมูลมีอายุไม่เกิน 30 วัน และจะทำการลบเมื่อข้อมูลไม่ถูกใช้งานเกิน 90 วันขึ้นไป เขียนคำสั่งได้ดังนี้
ระหว่างนั่งรอเครื่องบินเข้ากรุงเทพ อ่านบทความเรื่อง The Current and Future State of Testing: a Conversation with Lisa Crispin พูดคุยเรื่อง สถานะปัจจุบันของการทดสอบ software ว่าเป็นอย่างไร ? ยิ่งปัจจุบันมีการพัฒนาระบบงานเป็นรอบสั้น ๆ ด้วยแล้ว การทดสอบจะเป็นอย่างไร ? ยังคงทำงานในรูปแบบเดิม คือรอให้พัฒนาเสร็จทั้งหมดก่อน แล้วจึงทำการทดสอบเพื่อหาข้อผิดพลาดอยู่ไหม ? การทำสอบควรเป็น manual หรือ automation ? มาดูกันเลย
การทดสอบระบบงานในโลกที่การพัฒนาระบบงานเป็นแบบรอบสั้น ๆ ( Iteration and Incremental )
ถ้าทีมมีการพูดว่า ชุดการทดสอบพังอีกแล้ว !!! แบบนี้บ่อย ๆ แสดงว่านี่คือปัญหา ต้องรีบหยุดและแก้ไขมันซะ ถ้า test case อะไรที่ไม่จำเป็น ไม่สำคัญก็ลบทิ้งไป ถ้า test case อะไรที่จำเป็น สำคัญ ก็ทำให้มันน่าเชื่อถือ เนื่องจากเราต้องมีความเชื่อมั่นใจ test case ต่าง ๆ ที่สร้างขึ้นมาเสมอ
การจะทำให้ test case มันมีความน่าเชื่อถือ จำเป็นต้องพูดคุย และ ทำงานร่วมกับผู้เชี่ยวชาญด้านอื่น ๆ ด้วย เช่น infrastructure และ database administrator เป็นต้น ทำให้เรื่องของ communication และ collaboration เป็นความสามารถพื้นฐานที่ทุก ๆ คนต้องมี
วันที่ 10 พฤศจิกายนที่ผ่านมา ครบรอบ 10 ปีของภาษา Go ทำให้นึกถึงวันแรกที่ภาษา Go ถูกปล่อยออกมาให้ใช้งาน ซึ่ง blog แรกที่ทางทีมพัฒนาภาษา Go เขียนขึ้นมา คือ Hey! Ho! Let's Go! ใครยังจำได้บ้าง ?
โดยใน blog แรกนี้อธิบายว่า ภาษา program ควรทำงานได้อย่างรวดเร็ว ภาษา program ควรต้องเพิ่ม productivity ในการพัฒนา ภาษา program ควรต้องมีความสนุก นี่คือเป้าหมายหลักของภาษา Go
ภาษา Go นั้นนำความดีงามมาจากภาษาต่าง ๆ เรื่องความเร็วของการพัฒนา เอามาจากภาษา program แบบ dynamic เหมือนกับภาษา Python เรื่องของ performance ที่ดี เรื่องของ type safty เหมือนกับภาษา C หรือ C++ และ code ที่ถูก compile แล้ว ต้องมีความเร็วใกล้เคียงกับภาษา C นั่นหมายความว่า ภาษา Go จะช่วยทำให้เราไปได้เร็วขึ้น