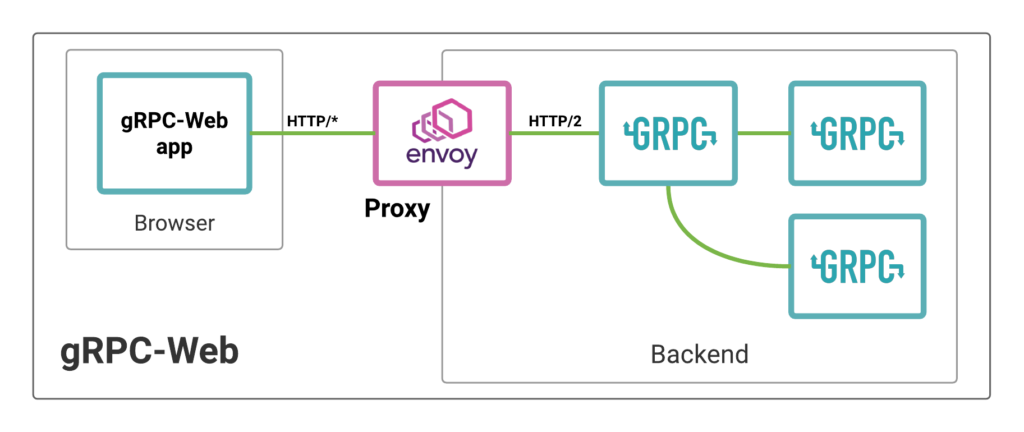
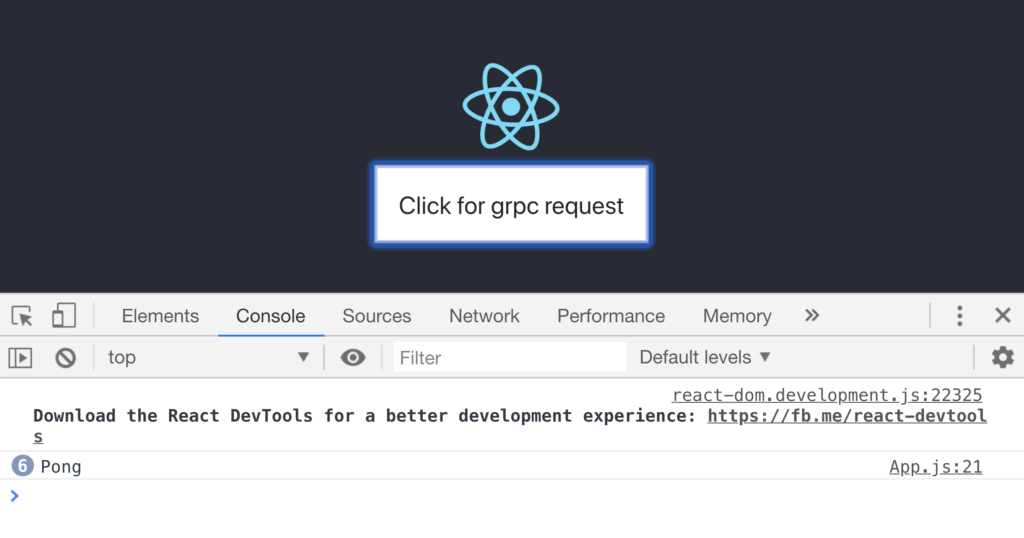
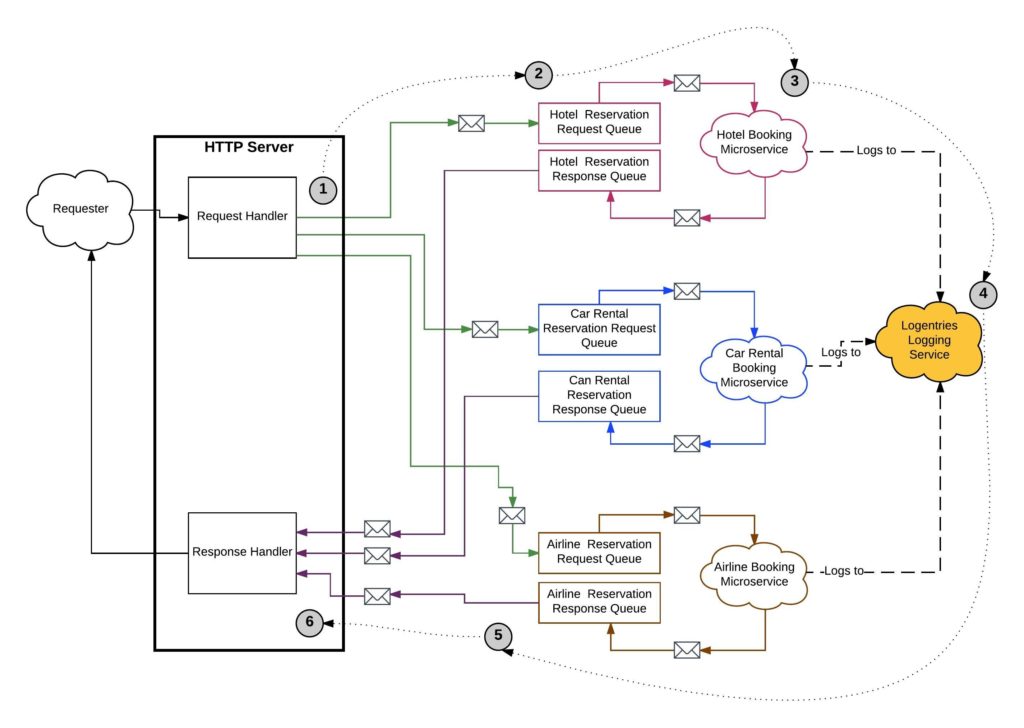
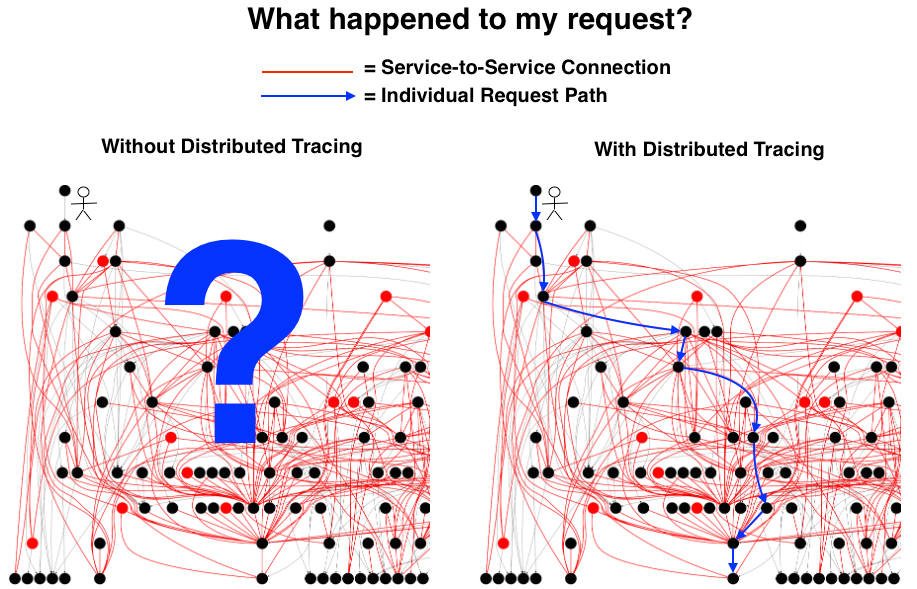
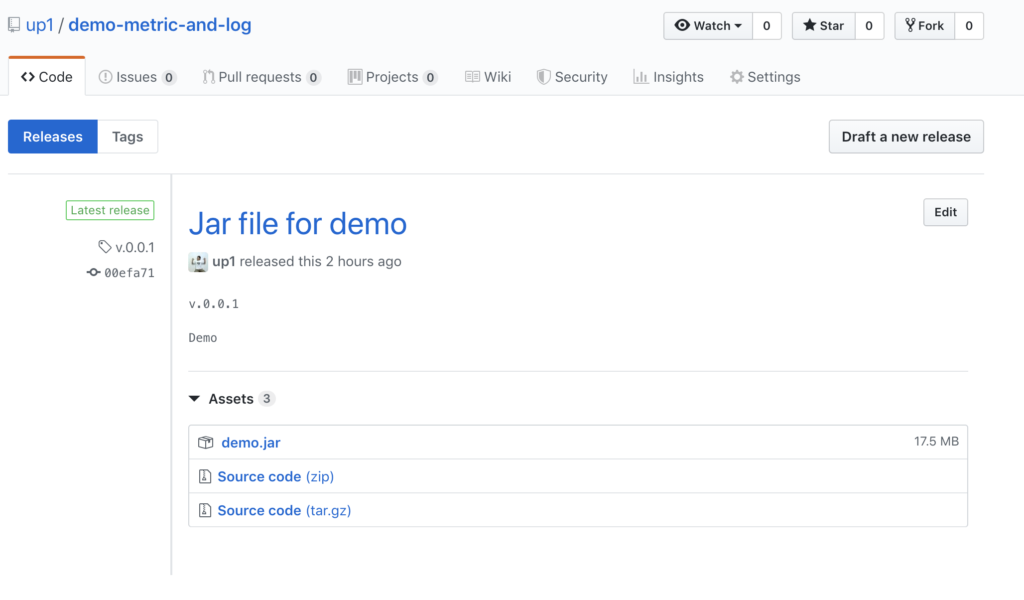
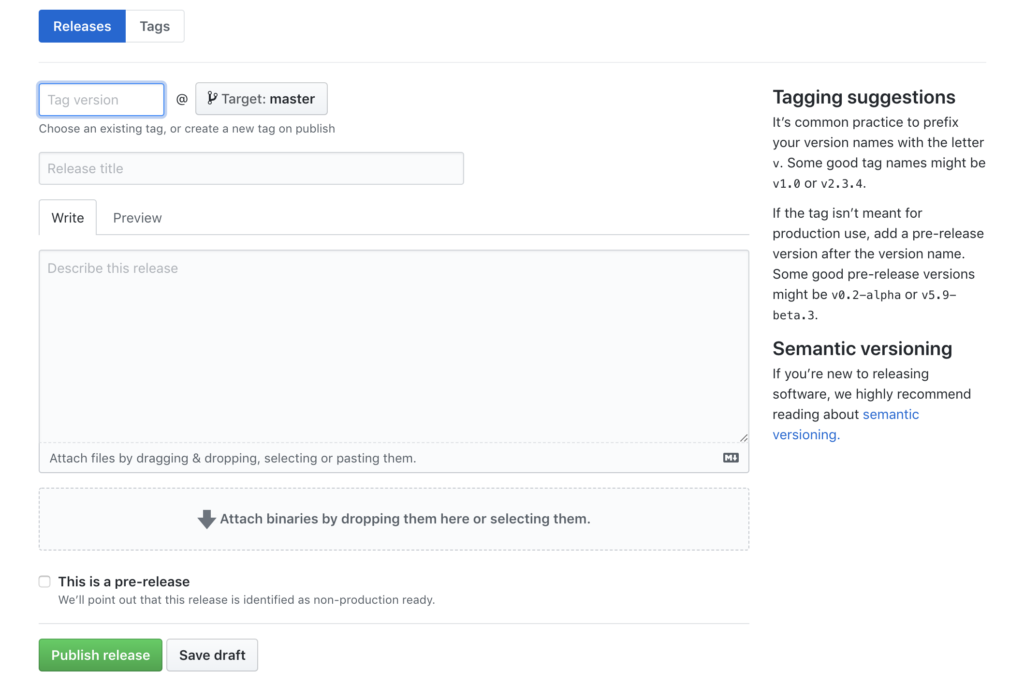
อ่านบทความเรื่อง มาทำ gRPC Service ด้วย Go กัน ดูแล้วน่าสนใจดี ก็เลยคิดว่า น่าจะลองเรียก gRPC service จากฝั่ง web browser กันหน่อย นั่นคือการเรียกใช้งานผ่าน gRPC Web นั่นเอง ดังนั้นมาลองดูกันหน่อย
ดังนั้นทีม infrastructure, network หรือ operation team จะต้องแข็งแกร่ง และทำงานร่วมกัน development team ได้อย่างดี แต่ถ้าไม่ส่งเสริมกันก็อาจจะก่อให้เกิดปัญหาใหญ่ตามมาได้
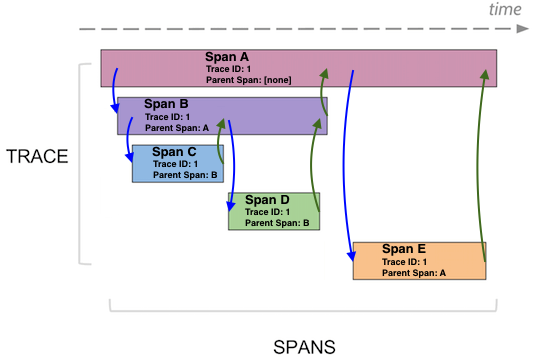
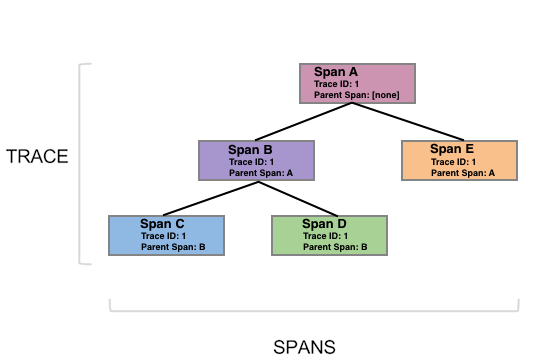
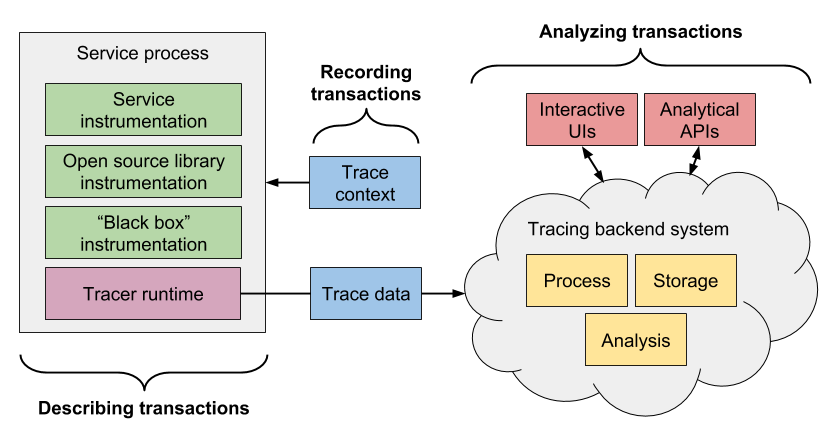
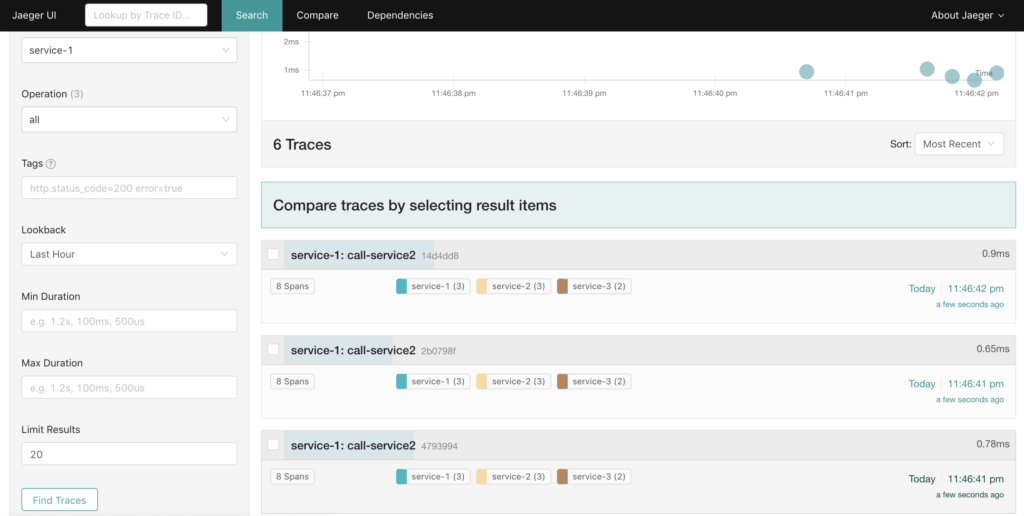
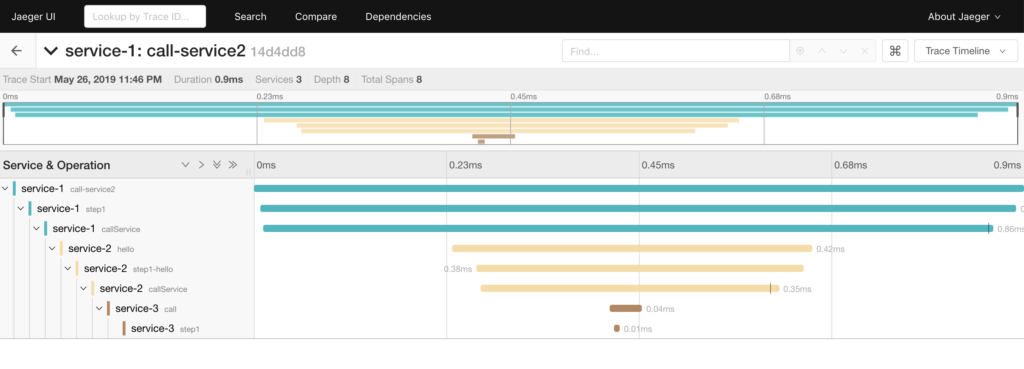
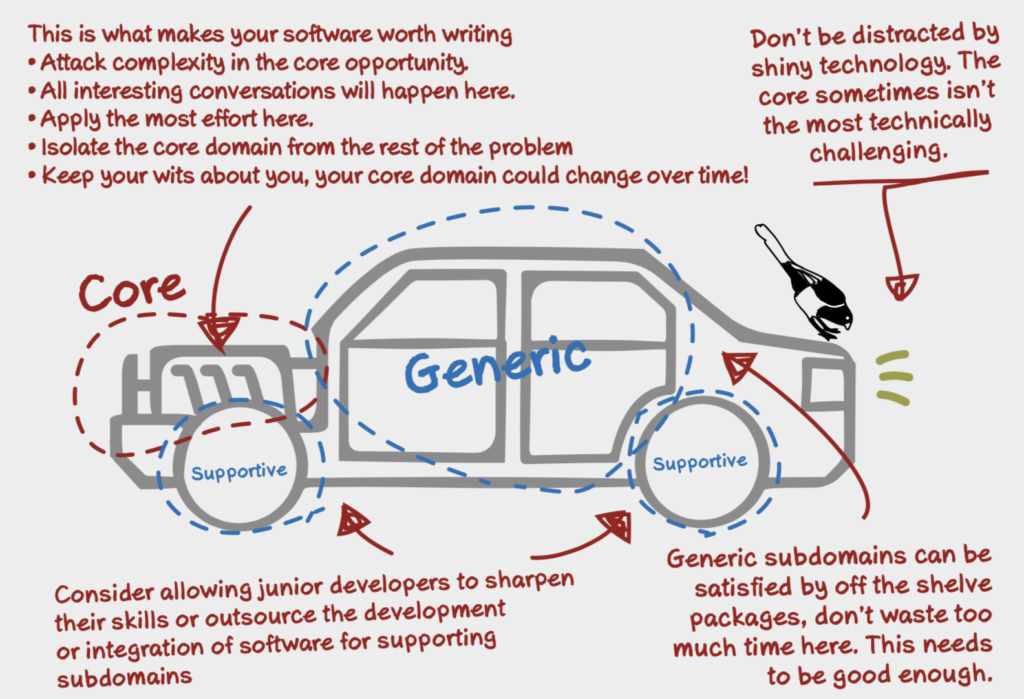
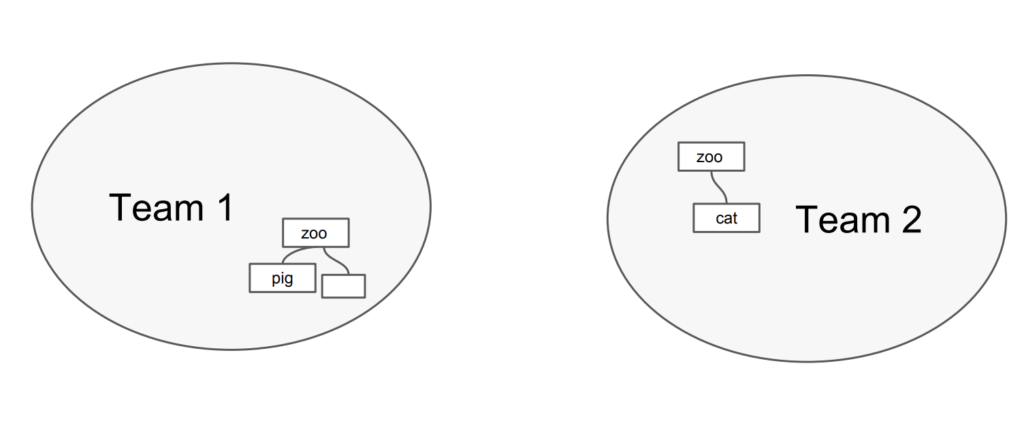
การจัดการเรื่อง communication ระหว่าง services
เนื่องจากเราทำงานแบ่งเป็น service ย่อย ๆ แล้ว แต่ละ service อาจต้องติดต่อสื่อสารกัน คำถามที่น่าสนใจคือ การติดต่อสื่อสารจะเป็นอย่างไร ทั้ง Synchronous และ Asyschonous เพราะว่าทั้งสองแบบก็มีข้อดีและข้อเสียต่างกันไป
หนักว่านั้น ถ้าแต่ละ service มันมีปัญหาหรือพังขึ้นมา จะทำการจัดการแก้ไขอย่างไร หรือรู้จุดที่เกิดปัญหาได้รวดเร็วอย่างไร บางครั้งเราจะใช้ค่า MTTR (Mean Time To Recovery) มาใช้วัดผลอีกด้วย
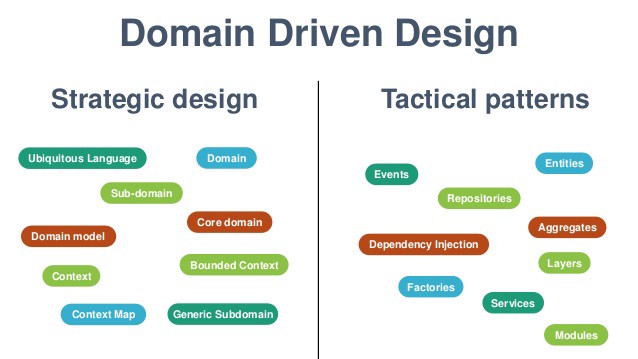
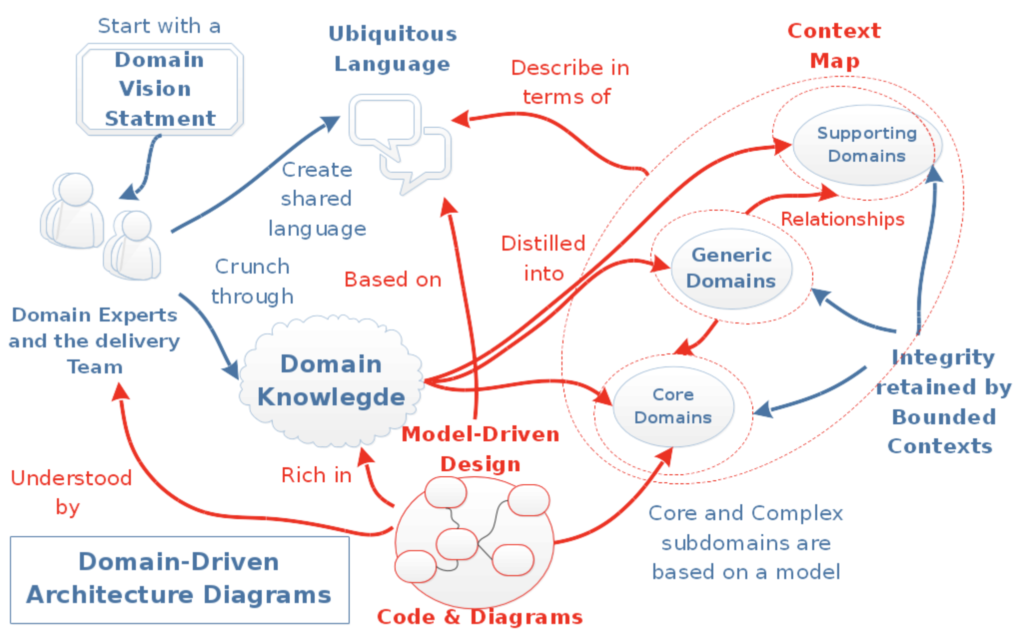
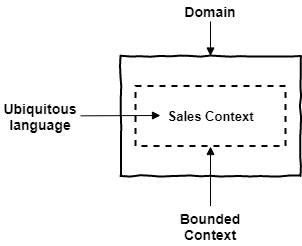
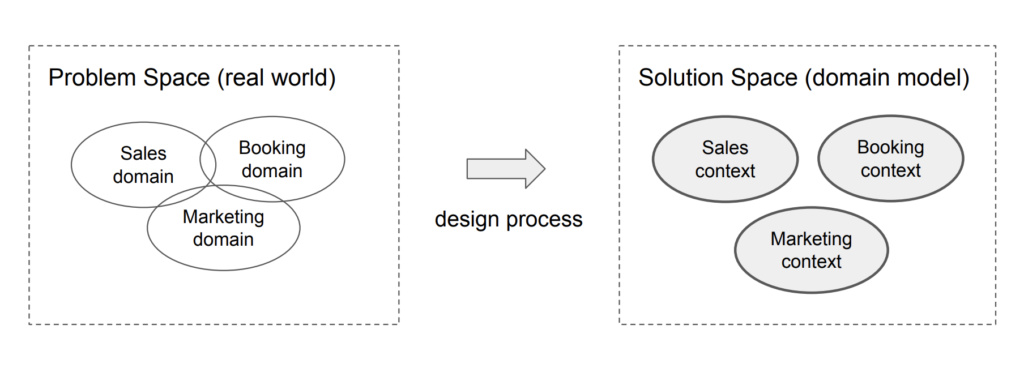
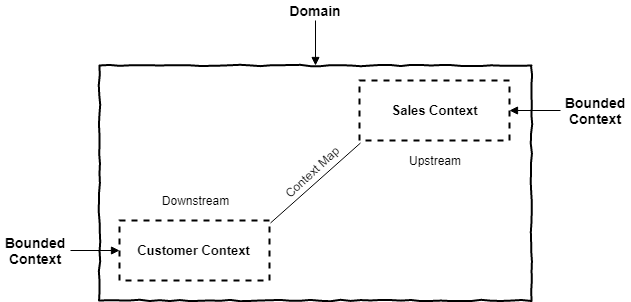
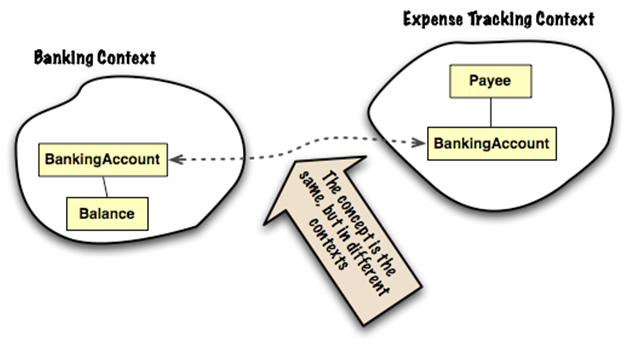
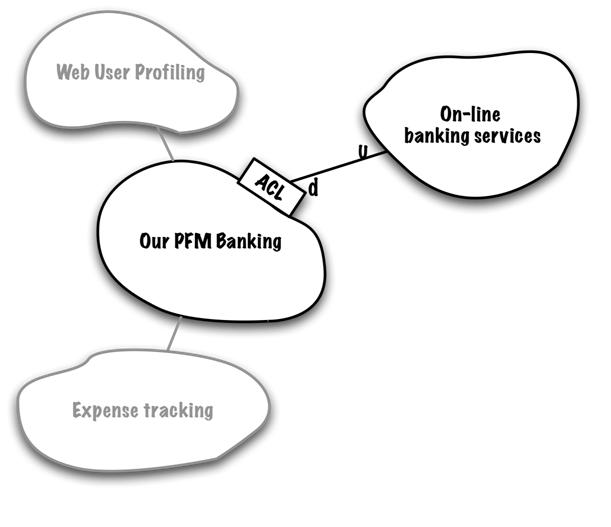
ดังนั้นเพื่อลดปัญหานี้ จึงมีแนวคิดที่จะพยายามสร้างกลุ่มของ APIs ใน boundary context ที่ถูกเรียกใช้ไว้เลย โดยใน API นี้จะมีกลุ่มของ service ที่ผู้เรียกใช้งานต้องการ และมีมาตรฐานชัดเจน
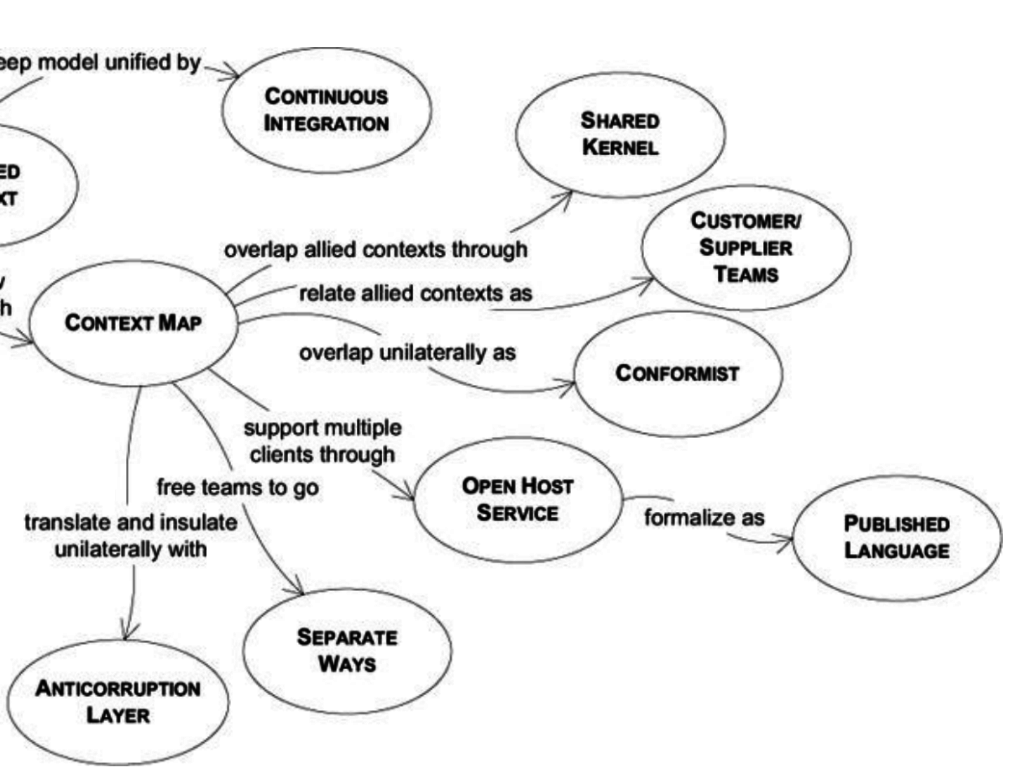
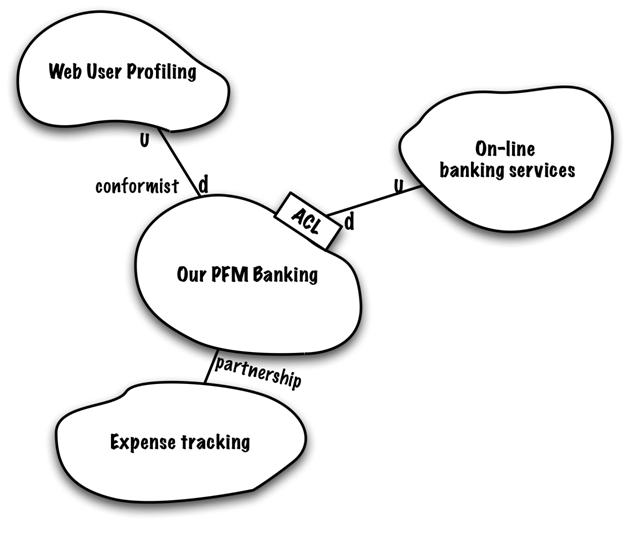
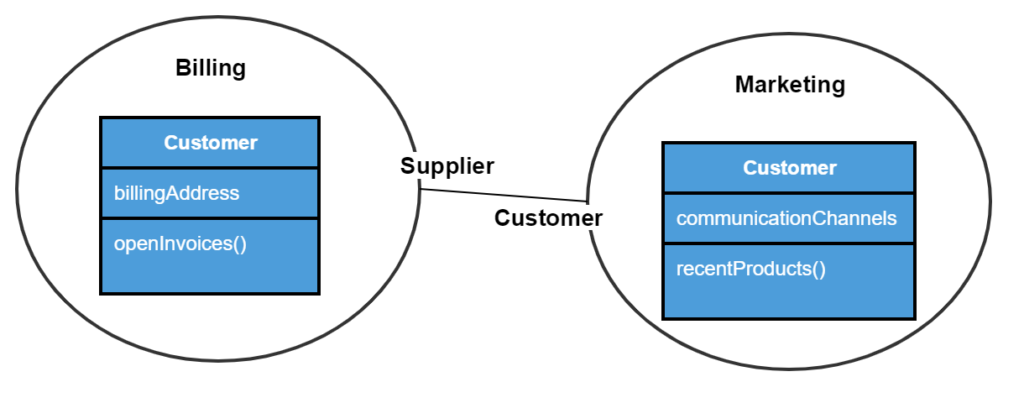
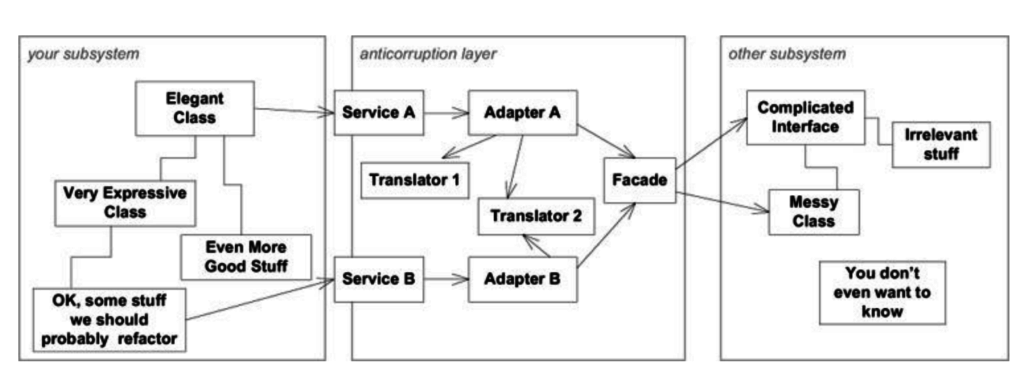
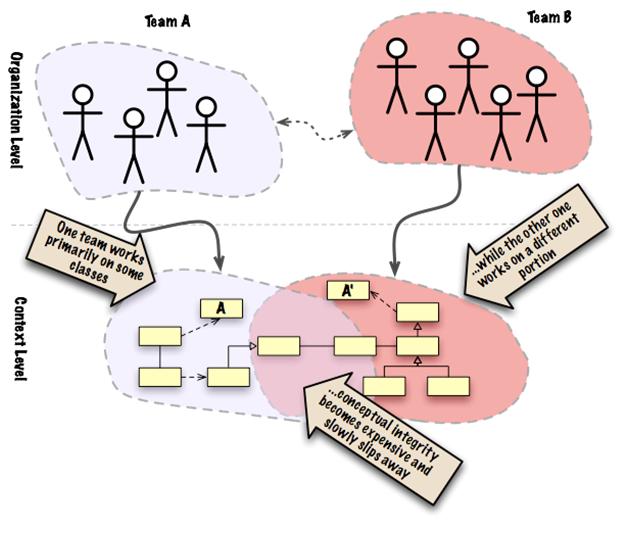
พบว่ามีแนวคิดคล้าย ๆ Conformist เลย แต่ต่างกันตรงที่ data model ของข้อมูลที่คุยกัน กับ standard ของการเรียกใช้ที่เป็นกลาง เช่น WebService หรือ RESTFul API เป็นต้น โดยที่ทั้งสองฝั่งคือ ผู้เรียกใช้และผู้ให้บริการต้องตกลงกันไว้ หรือพูดคุยกันมากขึ้นนั่นเอง ทำให้ทั้งสองฝั่งทำงานร่วมกันได้ง่ายขึ้น เน้นไปที่ส่วนการ integration มากกว่า implementation
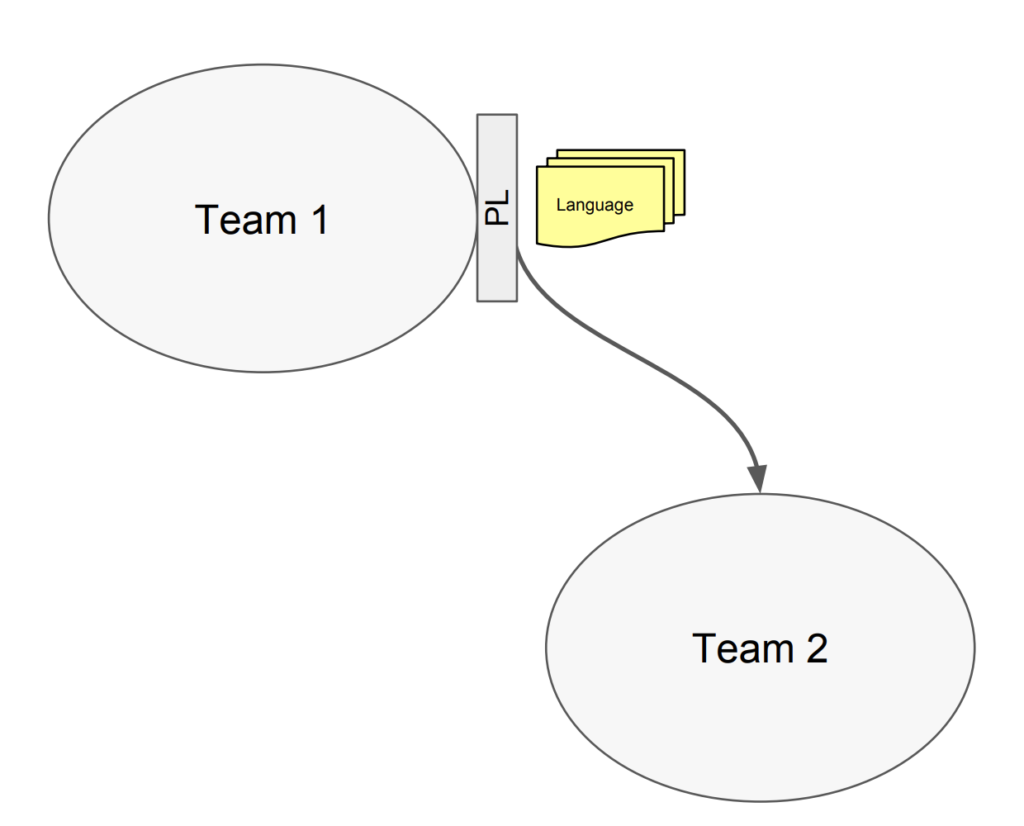
7. Published Language
ในส่วนนี้จะมีพัฒนาการมาจาก Open Host Service แต่ Open Host Service นั้นยังต้องคุยกันระหว่างทีมสูง ว่าแต่ละทีมจะมี data model ระหว่างกันอย่างไร ถึงแม้จะมี standard ในการพูดคุยแล้วก็ตาม ที่สำคัญยังคงผูกมัดกันอย่างมาก
ปัญหาหนึ่งที่ได้มักเจอเมื่อใช้งาน Docker compose คือ ลำดับการ start ของ service ต่าง ๆ นั่นเอง แน่นอนว่าใน docker compose ก็จะมี depends_on ให้ใช้งาน แต่ปัญหาก็ยังมีอยู่คือ Service ต่าง ๆ ก็ start ตามลำดับ แต่ว่ามีบาง service ที่ start แล้วแต่ยังไม่พร้อมใช้งาน ซึ่งอาจจะทำให้เกิดปัญหากับ service อื่น ๆ ที่ต้องใช้งานตอน start เช่นกัน
ยกตัวอย่างเช่น Service A เป็น database Service B ทำหน้าที่สร้าง table และ สร้างข้อมูล แน่นอนว่า ถ้าใช้ depends_on ก็ได้แค่ลำดับ คือ ให้สร้าง service A ก่อน B แต่ B จะทำงานผิด ถ้า A ยังไม่ start เสร็จสมบูรณ์