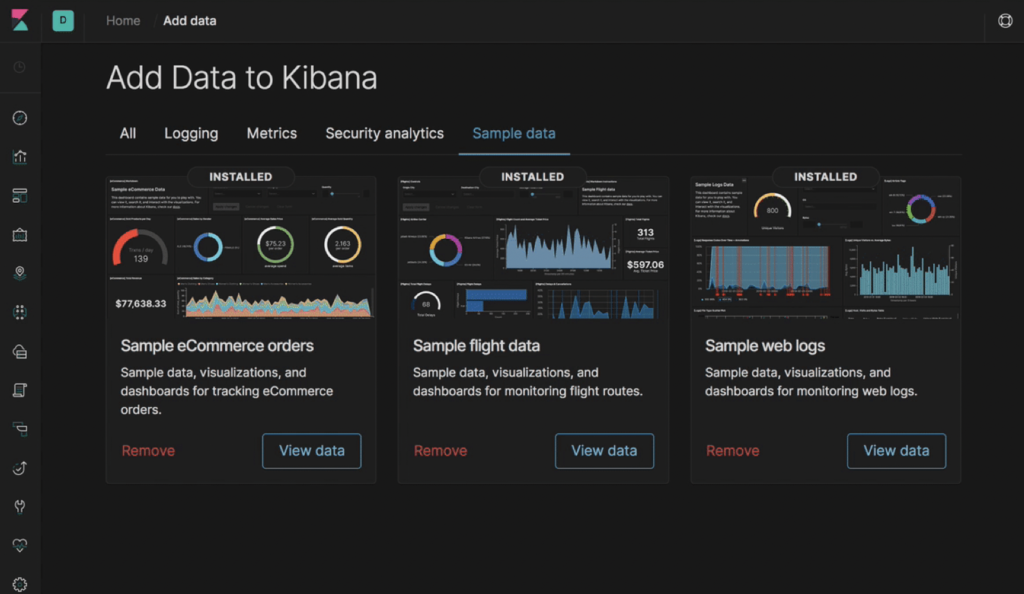
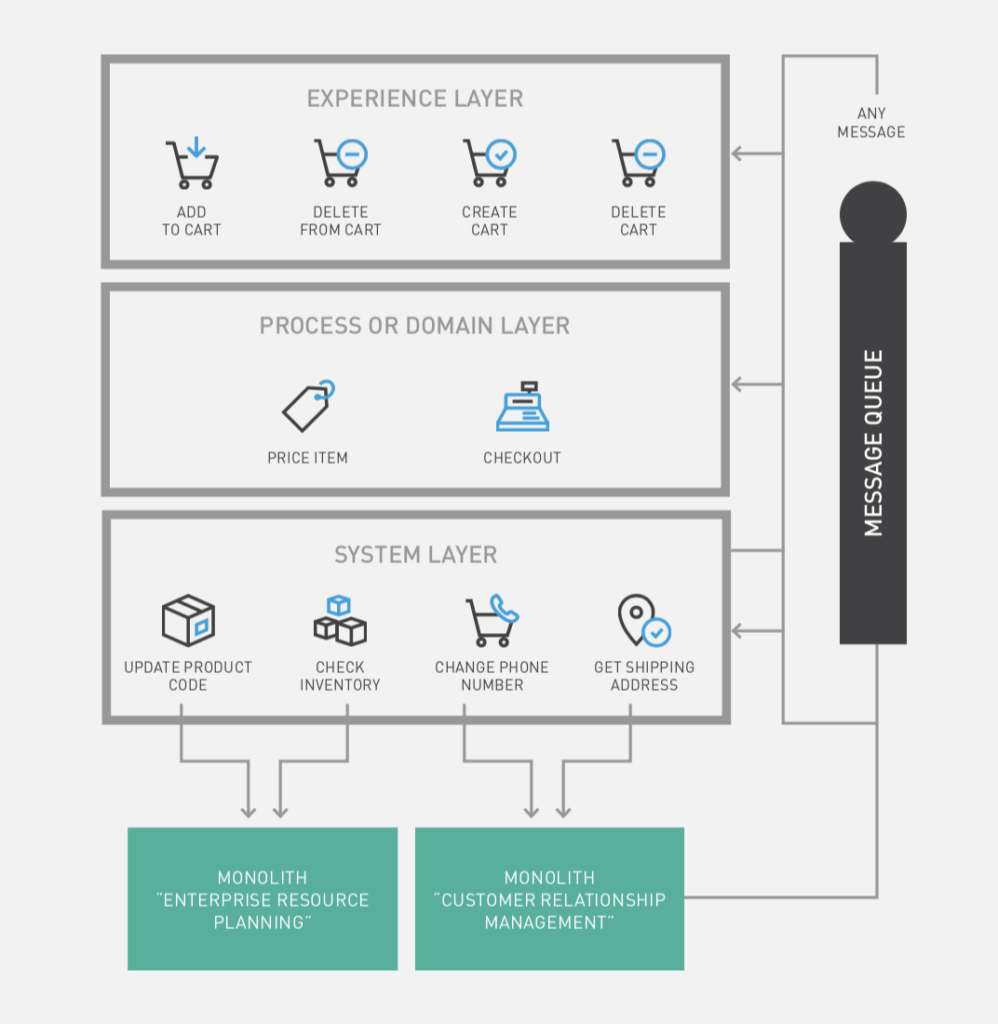
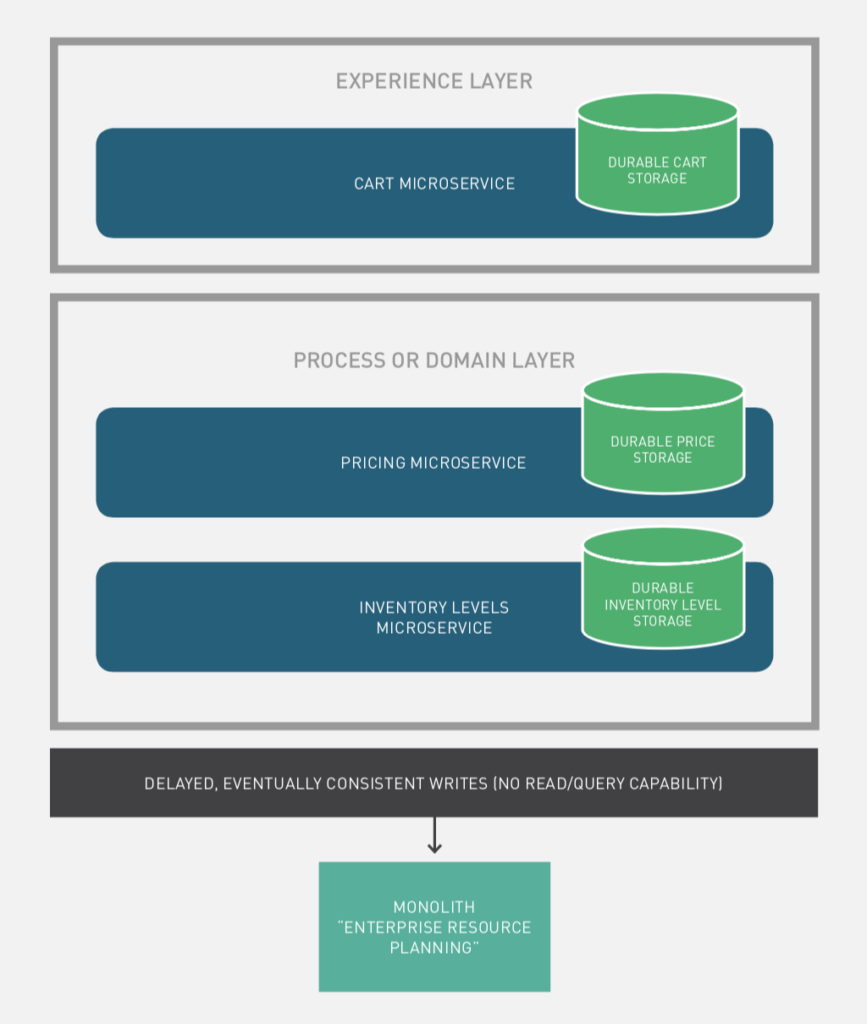
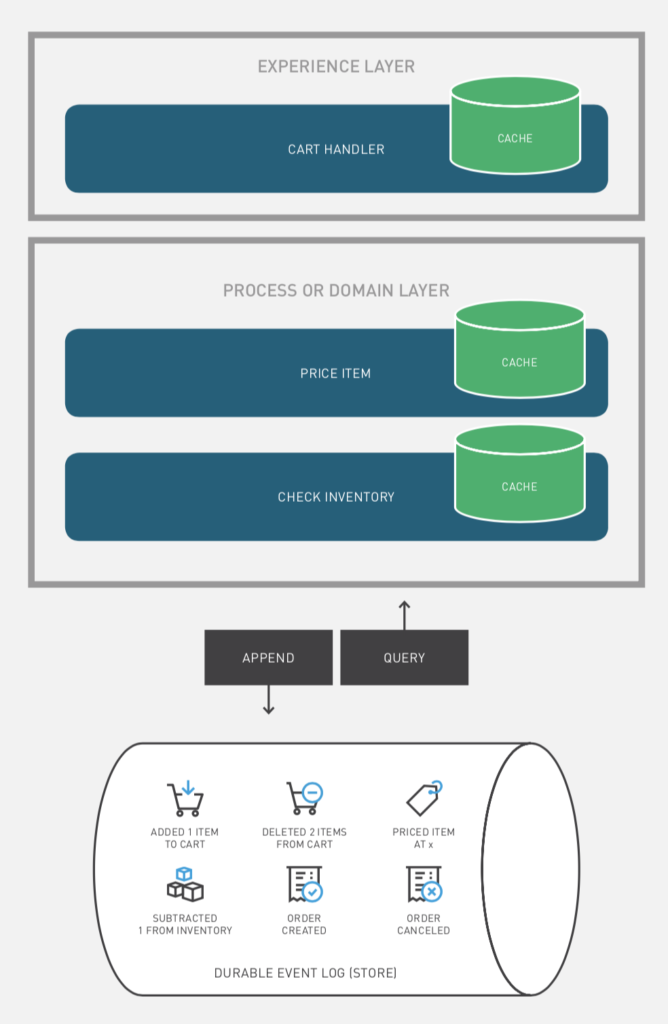
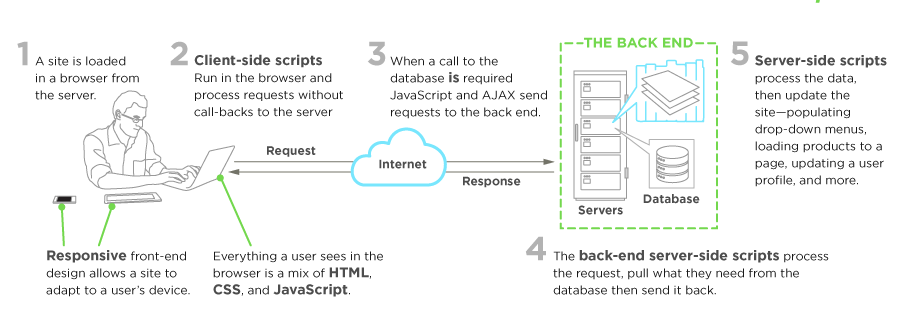
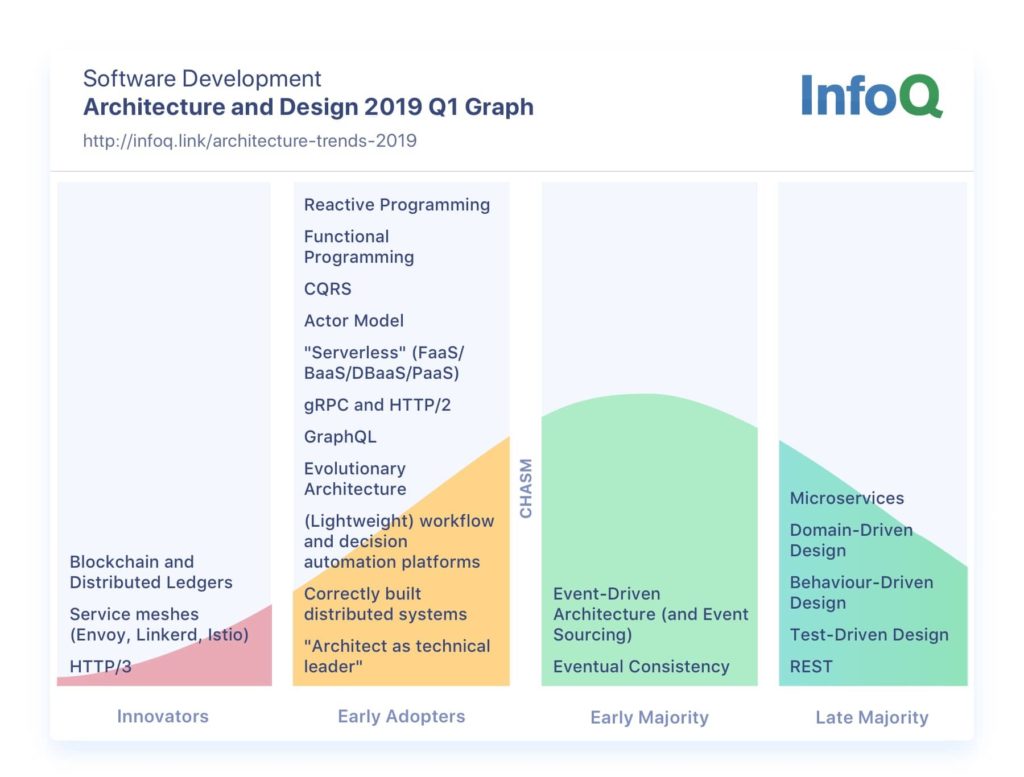
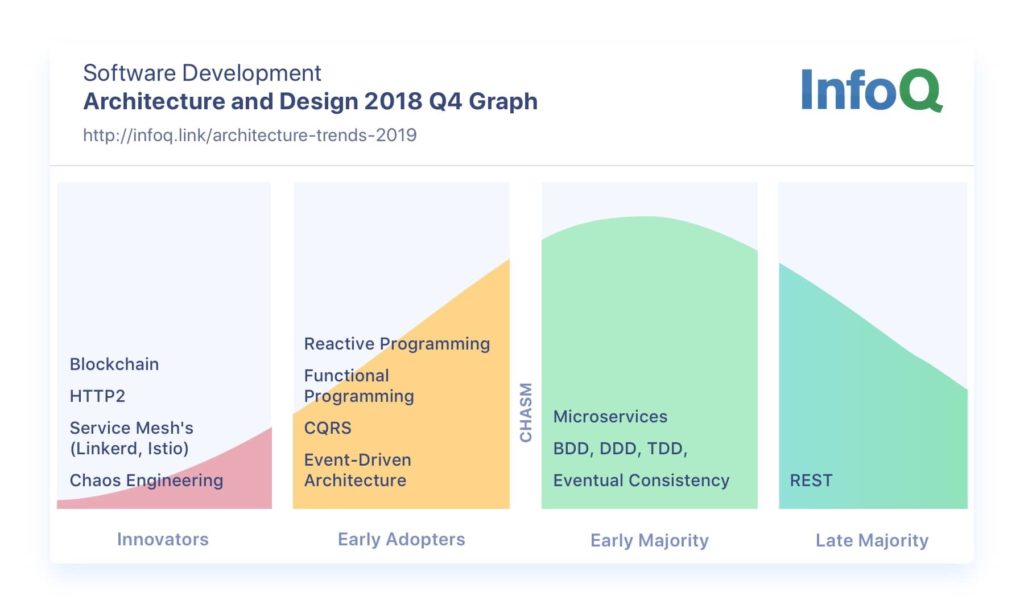
หลังจากทาง Cloudflare ทำการเปิด opensource Wrangler CLI
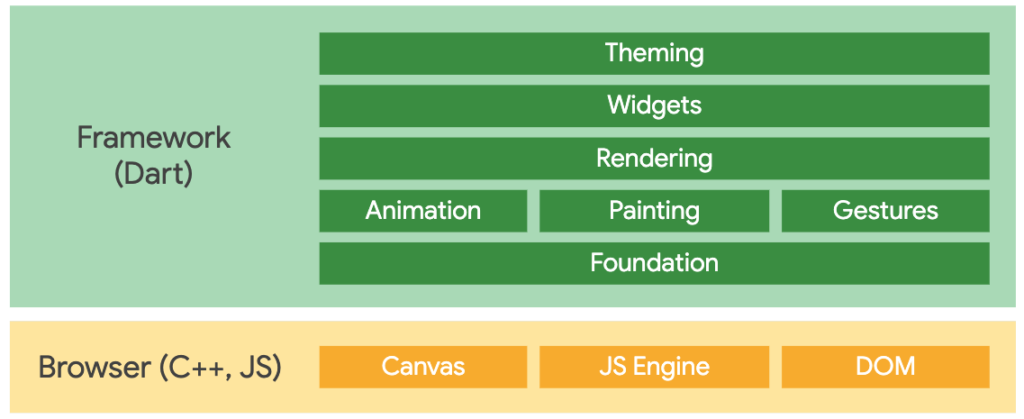
เป็นชุด CLI สำหรับการสร้าง Serverless ที่พัฒนาด้วยภาษา Rust
และทำการ compile เป็น WebAssembly
จากนั้นก็ preview และ publish ขึ้น Cloudflare Workers แบบง่าย ๆ กันเลย
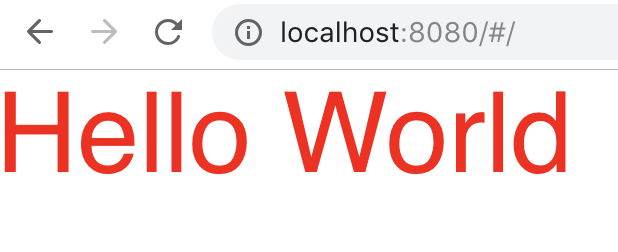
ดังนั้นลองมา Hello World กันหน่อย
มาเริ่มกันเลย
ปล.
เขียนทั้งภาษา Rust
เขียนทั้ง WebAssembly
สนุกแน่นอนครับ
มันออกจะงง ๆ หน่อย แต่น่าจะเป็นแนวทางในอนาคตก็ได้นะ
เริ่มต้นด้วยการติดตั้ง Wrangler CLI ก่อน
สามารถติดตั้งผ่าน Cargo ได้เลย
ดังนั้นควรเขียนภาษา Rust มานิดหน่อยเช่น Hello World
ทำการติดตั้งดังนี้
ปล. สำหรับชาว Mac อาจจะเจอปัญหาเรื่องของ openssh
แนะนำให้ทำการติดตั้ง openssh1.1 นะครับ
มาสร้าง project กันเลยด้วย Wrangler CLI
[gist id="39534653b7dd6438808456f9b36dab71" file="1.txt"]ถ้าไม่ใส่ชื่อ project จะสร้าง directory ชื่อว่า wasm-worker ขึ้นมา
ลองเข้าไปดู จะพบว่าสร้างอะไรให้ก็ไม่รู้ เยอะมาก ๆ !!
จากนั้นทำการ build ด้วยคำสั่ง
[gist id="39534653b7dd6438808456f9b36dab71" file="2.txt"]ผลลัพธ์ที่ได้จะอยู่ใน directory ชื่อว่า pkg นั่นเอง
ถ้าต้องการทดสอบบน localhost เองแล้ว บอกเลยว่าทำไม่ได้นะ
ต้องทำการ run บน Cloudflare Workers เท่านั้น
แต่โชคดีหน่อยว่า
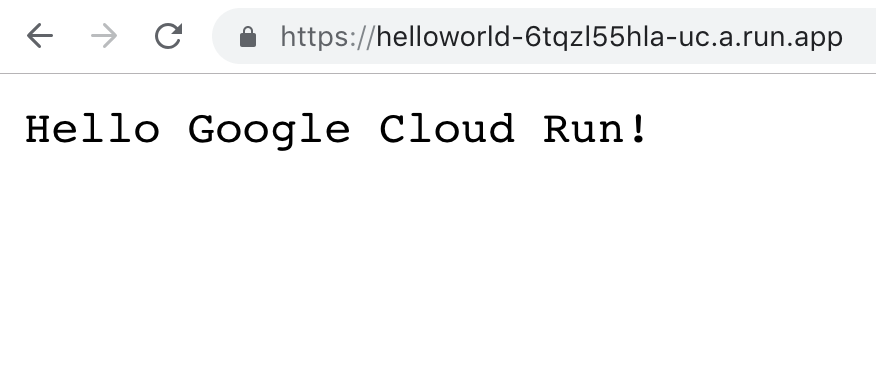
ไม่ต้องมี account บน Cloudflare Workers ก็สามารถทดสอบได้ ด้วยการใช้คำสั่ง $wrangler preview ได้เลย
จะทำการเปิด browser ให้เราทดลองใช้งานกันอีกด้วย
สบายขึ้นเยอะเลย
แต่จากที่ลองใช้งานเรื่อย ๆ พบว่า
ก็ยังเจอ bug เยอะพอสมควร
ยกตัวอย่างเช่น Resource เต็ม และ load พวก library ไม่ขึ้นนะครับ
มาลองสร้าง function ให้มันรับค่าชื่อไปหน่อยสิ
เพื่อให้ส่งค่าไปยัง function กันบ้าง
เพื่อให้รู้สึกว่าได้เขียน Rust และ WebAssembly กัน
เริ่มจากการแก้ไขไฟล์ src/lib.rs
สำหรับการสร้าง function เพื่อรับค่าชื่อ ตามที่ต้องการ
ต่อจากนั้นทำการแก้ไขไฟล์ worker/worker.js
สำหรับรับค่าจาก HTTP Request
ไม่งั้นมันจะดูแห้ง ๆ ไป
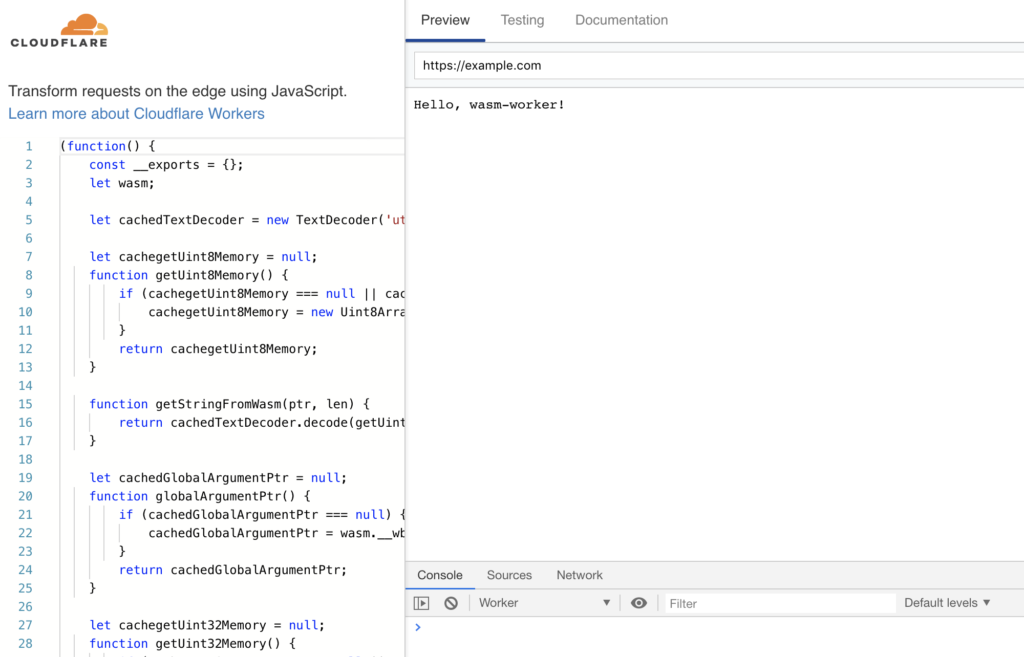
เมื่อทุกอย่างเรียบร้อย
ก็ทำการ build และ preview จะได้ผลการทำงานดังนี้
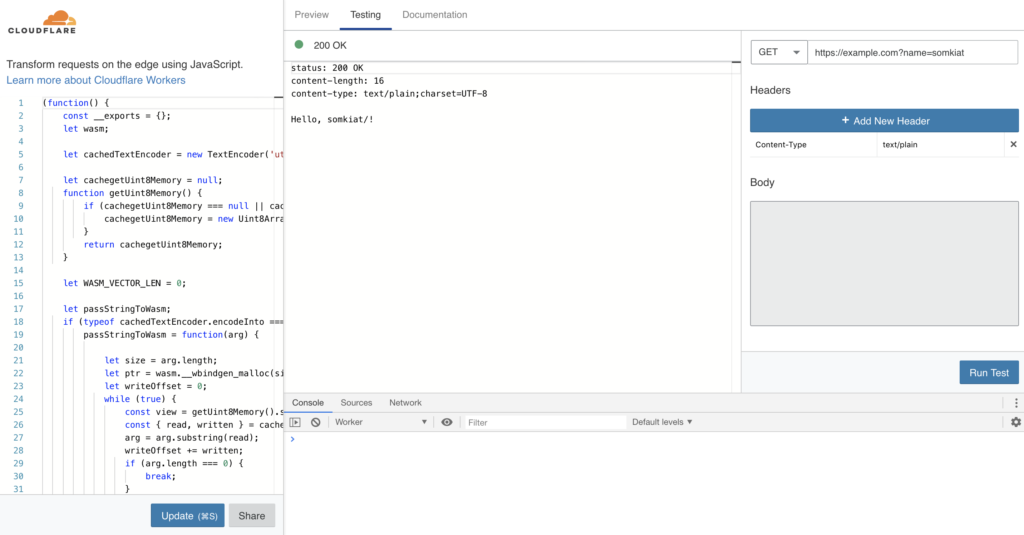
จะ publish ก็ไม่มีเงิน !!
ใครสนใจลองไป Activate worker กันได้เลย

https://www.cloudflare.com/plans/
ลองไปเล่นกันดูครับ สนุกแปลก ๆ งง ๆ ดี กับตัวภาษา
แต่มันส์แน่นอนครับ
Reference Websites
- https://blog.cloudflare.com/introducing-wrangler-cli/
- https://www.infoq.com/news/2019/03/cloudfare-wrangler-wasm-rust
- https://blog.cloudflare.com/cloudflare-workers-as-a-serverless-rust-platform/