Documentation test อารมณ์เดียวกับ Docstring ใน Python เลย
พอจะเริ่มด้วยการเขียน test คำถามแรกเลยโครงสร้าง project ต้องเป็นอย่างไร ?
ไปอ่านเอกสารก็งง ๆ ดังนั้นมาเริ่มที่ unit test ก่อนเลย สร้างไฟล์ชื่อว่า hello.rs ขึ้นมา ในไฟล์นี้มีทั้ง production code และ test code เลย ปลายทางได้แบบนี้
ต่อมาเรื่องของการตั้งชื่อ function ต้องเป็น sneck case นะ ส่วนตัวแปรที่เป็น local ให้ขึ้นต้นด้วยเครื่องหมาย underscore (_) มิเช่นนั้นจะทำการเตือนดังนี้ ชีวิตดีมาก ๆ มีเครื่องมือช่วย
มีโอกาสไปร่วมงาน Meetup ของทาง ThoughtWorks Tech Talks ประจำเดือนมีนาคม ในหนังข้อเรื่อง CI/CD pipeline :: The Good and The Bad ซึ่งมีหลายเรื่องที่น่าสนใจ เพื่อนำมาประยุกต์ใช้งาน จึงทำการสรุปไว้นิดหน่อย
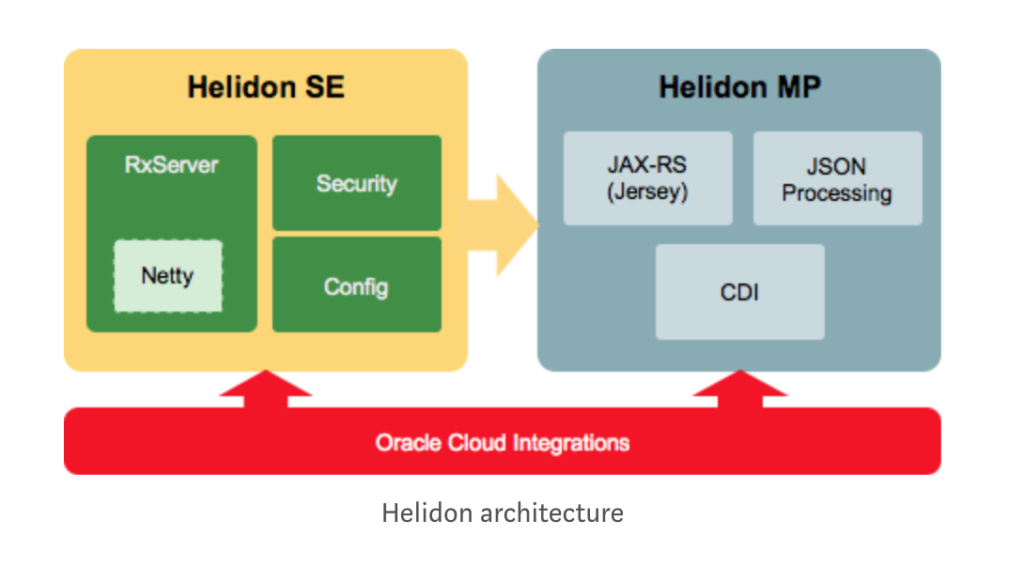
คำอธิบาย ทำการสร้าง Web server ขึ้นมาซึ่ง run ที่ port 8080 (Reactive Web Server) แน่นอนว่า Web server คือ Netty นั่นเอง ทำการกำหนด routing ของ API หน้าตามันคุ้น ๆ เหมือน NodeJS เลย เนื่องจากได้แรงบันดาลในมานั่นเอง
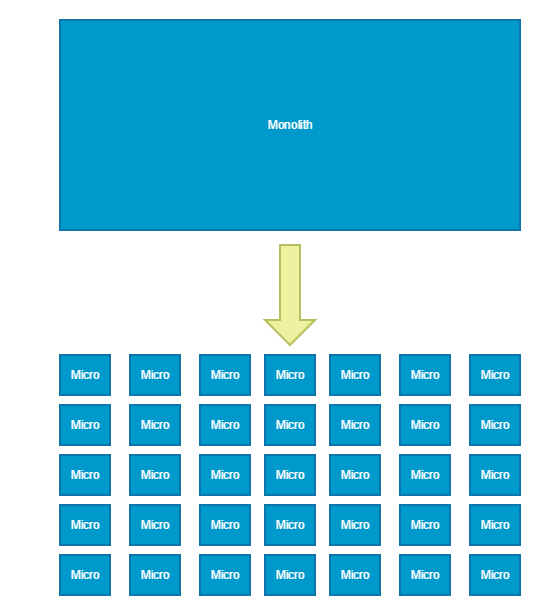
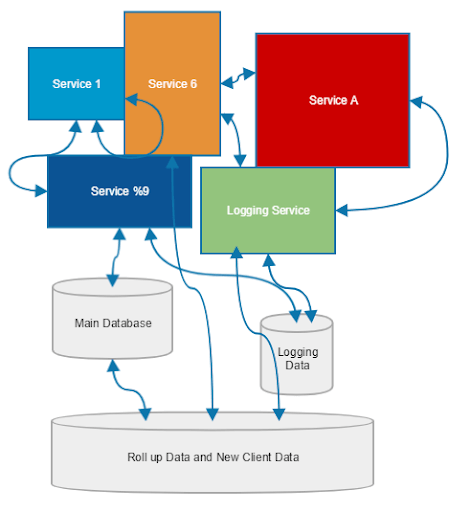
กลับไม่เป็นไปตามที่คิดที่ฝันคือ มันกลายเป็นว่าแต่ละ service คือ Monolith เช่นเดิม !! แถมทำให้การ deploy, testing และ ดูแลรักษายากและนานขึ้นอีก หนักกว่านั้น เปลี่ยนแปลงการทำงานของ service หนึ่ง กลับส่งผลกระทบต่อภาพรวมของระบบ แถมหาปัญหายากกว่าเดิมอีก
จะ scale service หนึ่ง ดันต้องไป scale service อื่น ๆ อีก ปัญหาจัดการเรื่องของ transaction อีก หา service ไม่เจออีก ทำไมปัญหามันเยอะขนาดนี้ ? ไหนใคร ๆ ก็บอกว่าแยกเป็น service เล็ก ๆ แล้วมันดีนะ สงสัยแนวคิดนี้ไม่ดีแน่ ๆ !!
แบ่งเป็น service ย่อย ๆ ยกเว้น data กลับไม่แยก
สิ่งที่ชอบทำต่อการการแบ่ง service ที่ไม่ถูกต้อง หรือ ไม่เหมาะสม ก็คือ การไม่แยก data ออกมาตามแต่ละ service เพราะว่า การที่จะแยก data ออกมาตามแต่ละ service มันยากมาก ๆ ทั้ง
แยก database ออกมาใน server เดียวกัน
แยก database ตามแต่ละ server ไปเลย
แต่ปัญหาที่เจอคือ database ที่ใช้นั้น มักจะมีเรื่องของ licence การจะแยกออกมานั่นหมายความว่า ค่าใช้จ่ายสูงขึ้นอย่างมาก ไหนจะเรื่องของการจัดการข้อมูล รวมไปถึงระบบอื่น ๆ ที่ต้องใช้งาน data อีกด้วย ถ้าต้องการใช้ data จากหลาย ๆ service จะทำอย่างไร ? ดังนั้น เพื่อความง่ายก็ไม่ต้องแยกดีกว่า
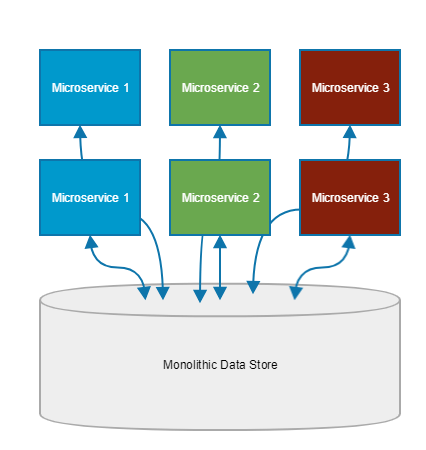
ผลที่ตามมาคือ ทุก service ยังคงใช้ database เดียวกัน ถ้ามีการเปลี่ยนแปลง หรือ database มีปัญหา ผลกระทบที่ตามมาคือ ทุก ๆ service ที่ใช้งานก็พังไปด้วยสิ ซึ่งมันขัดแย้งกับแนวคิดของ microservices อย่างมาก ที่แต่ละ service ต้องทำงานจบในตัวเอง ไม่ยืมจมูกคนอื่นหายใจ แสดงดังรูป
กลับไม่เป็นไปตามที่คิดที่ฝันคือ มันกลายเป็นว่าแต่ละ service คือ Monolith เช่นเดิม !! แถมทำให้การ deploy, testing และ ดูแลรักษายากและนานขึ้นอีก หนักกว่านั้น เปลี่ยนแปลงการทำงานของ service หนึ่ง กลับส่งผลกระทบต่อภาพรวมของระบบ แถมหาปัญหายากกว่าเดิมอีก
จะ scale service หนึ่ง ดันต้องไป scale service อื่น ๆ อีก ปัญหาจัดการเรื่องของ transaction อีก หา service ไม่เจออีก ทำไมปัญหามันเยอะขนาดนี้ ? ไหนใคร ๆ ก็บอกว่าแยกเป็น service เล็ก ๆ แล้วมันดีนะ สงสัยแนวคิดนี้ไม่ดีแน่ ๆ !!
แบ่งเป็น service ย่อย ๆ ยกเว้น data กลับไม่แยก
สิ่งที่ชอบทำต่อการการแบ่ง service ที่ไม่ถูกต้อง หรือ ไม่เหมาะสม ก็คือ การไม่แยก data ออกมาตามแต่ละ service เพราะว่า การที่จะแยก data ออกมาตามแต่ละ service มันยากมาก ๆ ทั้ง
แยก database ออกมาใน server เดียวกัน
แยก database ตามแต่ละ server ไปเลย
แต่ปัญหาที่เจอคือ database ที่ใช้นั้น มักจะมีเรื่องของ licence การจะแยกออกมานั่นหมายความว่า ค่าใช้จ่ายสูงขึ้นอย่างมาก ไหนจะเรื่องของการจัดการข้อมูล รวมไปถึงระบบอื่น ๆ ที่ต้องใช้งาน data อีกด้วย ถ้าต้องการใช้ data จากหลาย ๆ service จะทำอย่างไร ? ดังนั้น เพื่อความง่ายก็ไม่ต้องแยกดีกว่า
ผลที่ตามมาคือ ทุก service ยังคงใช้ database เดียวกัน ถ้ามีการเปลี่ยนแปลง หรือ database มีปัญหา ผลกระทบที่ตามมาคือ ทุก ๆ service ที่ใช้งานก็พังไปด้วยสิ ซึ่งมันขัดแย้งกับแนวคิดของ microservices อย่างมาก ที่แต่ละ service ต้องทำงานจบในตัวเอง ไม่ยืมจมูกคนอื่นหายใจ แสดงดังรูป
ก็พาไปถึงการจ้างงานในตำแหน่ง Data Science เราต้องการ Data Science ที่เก่งเรื่อง Computer Science เราต้องการ Data Science ที่เก่งเรื่องคณิตศาสตร์และสถิติ เราต้องการ Data Science ที่เก่งเรื่อง Business Domain เมื่อเอาความสามารถทั้งสามส่วนมาก็พบว่า มันคือ set ว่าง หรือไม่มีนั่นเอง !!
นักพัฒนาส่วนใหญ่มองว่า เรื่องของการเขียน Unit test และ Code review เป็นเรื่องปกติที่พึงกระทำ เพราะว่ามันคือหนึ่งในแนวปฏิบัติที่จะช่วยทำให้การพัฒนาระบบงานสำเร็จ