เรื่องที่ 33 Methods with Value Receivers Can't Change the Original Value
Method receiver นั้นจะเหมือนกับ argument ของ function นั่นคือ ถ้าทำการประกาศแบบปกติ จะเป็นการ pass by value (เป็นค่าของข้อมูล ไม่ใช่ตำแหน่ง) ทำให้เมื่อทำการแก้ไขข้อมูลแล้ว จะไม่กระทบกับข้อมูลต้นทางหรือ original ดัง code ตัวอย่าง
ดูแล้วเป็นสิ่งที่เรียบง่ายมาก ๆ ไม่น่าสนใจอะไร แต่จริง ๆ แล้วเป็นรูปแบบที่มีประสิทธิภาพอย่างมาก เนื่องจาก ช่วยทำให้เราแรกการออกแบบ data model ที่เหมาะสม ต่อการทำงานทั้ง read และ write โดยที่ data model เหล่านั้นยังคงทำงานอยู่บนข้อมูลชุดเดียวกัน Data model ก็คือมุมมองที่มีต่อข้อมูล ซึ่งการทำงานต่างกัน มุมมองย่อมต่างกัน
เมื่อย้อนกลับมาดูแล้ว พบว่า เรามักใช้ data model ชุดเดียวกันเสมอ สำหรับทุก ๆ เรื่อง ทำไมนะ ?
มีให้ทั้ง Google Chrome และ Firefox ซึ่ง extension ไม่ได้ทำอะไรมาก เพียงเพิ่มปุ่มชื่อว่า Open in Git History เข้ามา เมื่อกดปุ่มแล้วจะไปยัง url ตามวิธีที่ 1 นั่นเอง
อีกเรื่องที่น่าสนใจคือ การ integrate กับ User Interface
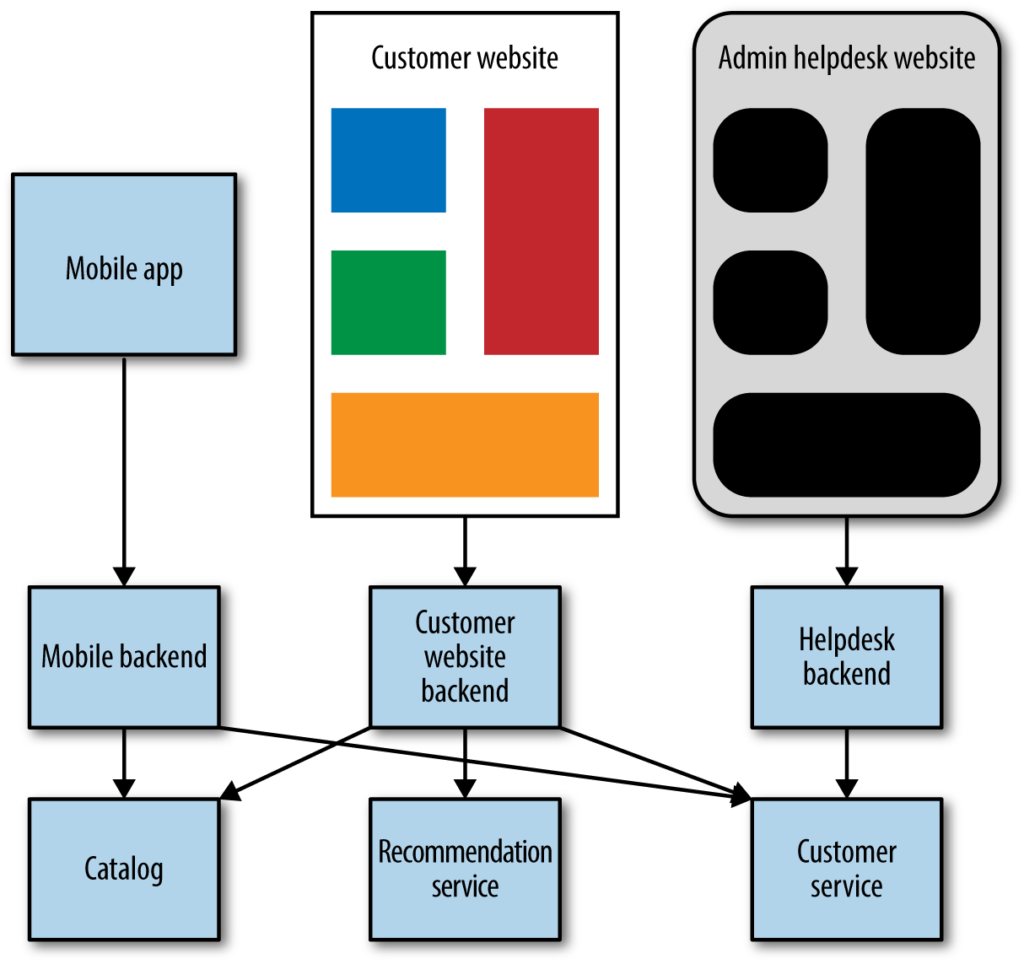
เนื่องจาก user interface นั่นคือ ฝั่งที่ทำการรวบรวมหรือเรียกใช้งานหลาย service ทำให้การทำงานจริง ๆ อาจจะเกิดปัญหาเรื่องการติดต่อสื่อสารไปยัง service ต่าง ๆ ดังนั้นจึงแนะนำให้สร้าง composition service ขึ้นมา เพื่อทำงานตามความต้องการของ user interface ไปเลย
ยกตัวอย่างเช่น user interface มีทั้ง Mobile, Web และ Admin ก็ให้มี composition service ของแต่ละ user interface เรามักจะเรียก service เหล่านี้ว่า Backend for Frontend (BFF) แสดงดังรูป
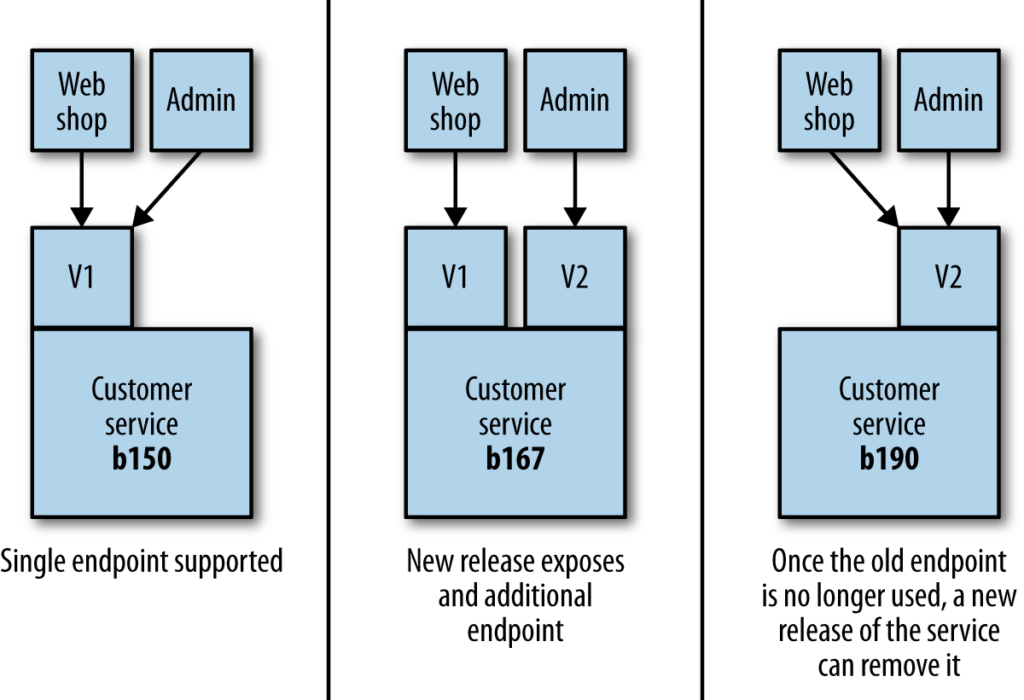
รวมไปถึงการจัดการ version ของ service ก็สำคัญมาก ๆ เพื่อสร้างความน่าเชื่อถือให้กับ service
เรื่องที่ผมชอบมาก ๆ คือ Split the monolith
หรือการแยก service จากระบบเดิม แน่นอนว่า ต้องมีเหตุผลในการแยกดังนี้
เหตุผลในการเปลี่ยนแปลง เมื่อแยก service ออกมาแล้วการเปลี่ยนแปลงต้องเป็นเฉพาะ service นั้น ๆ เท่านั้น ไม่ไปทำให้ service อื่นเปลี่ยนด้วย ถ้าแยกออกมาแล้ว ยังต้องเปลี่ยนเพราะว่า service อื่นเปลี่ยน แบบนี้เราจะแยกออกมาทำไมกัน
โครงสร้างของทีม การแยกทีมออกมาดูแต่ละ service ก็ทำให้จำนวน code น้อยลง การดูแลง่ายขึ้น ยิ่งถ้าทำงานต่างที่กัน น่าจะทำให้ตอบรับโจทย์หรือปัญหามากขึ้น
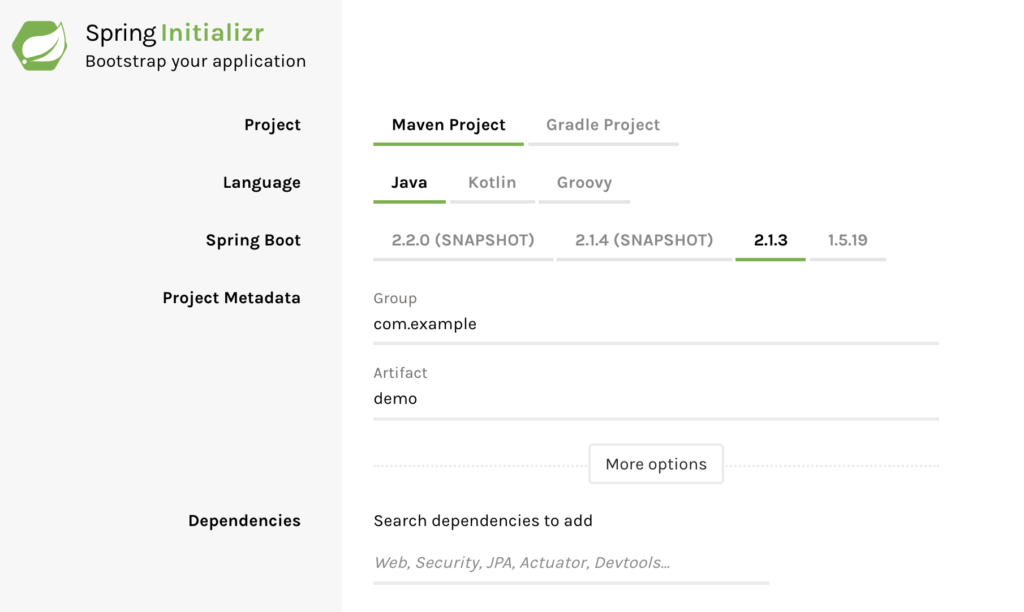
ค่ำนี้เข้าไปที่หน้า web ของ Spring Initializr ซึ่งเป็นหน้าสำหรับช่วยสร้าง Spring Boot Project พบว่าเปลี่ยนไปอย่างน่าตกใจ เลยนำข่าวมาบอก ที่สำคัญใช้ง่ายขึ้นกว่าเดิม
สิ่งที่เปลี่ยนแล้วชอบประกอบไปด้วย
UI ที่เปลี่ยนไป ดูไม่อึดอัดเหมือนเดิม
มีให้เลือกว่าจะ packaging เป็นอะไรคือ JAR หรือ WAR file
จากบทความ Using Go Modules จาก website หลักของภาษา Go ทำการอธิบายการใช้งาน Go Module ซึ่งใน Go version 1.13 เป็นต้นไปจะเป็นค่า default สำหรับการพัฒนา ดังนั้นควรทำการซึกษาและใช้งานกันได้แล้ว ประกอบไปด้วย
การสร้าง module ใหม่
การเพิ่ม dependency เข้ามาใหม่
การ upgrade dependency ต่าง ๆ
การเพิ่ม dependency เข้ามายัง major version
การ upgrade dependency เข้ามายัง major version
การลบ dependency ที่ไม่ได้ใช้ออกไป
โดยจะทำการสรุปไว้ 3 เรื่องพอคือ
การสร้าง module ใหม่
การเพิ่ม dependency เข้ามาใหม่
การลบ dependency ที่ไม่ได้ใช้ออกไป
Module นั้นคือกลุ่มของ Go package ที่ถูกจัดเก็บในรูปแบบของ tree