เป็นเทคนิคหนึ่งในการพัฒนาระบบงาน
เพื่อแยกส่วนการทำงานออกเป็น service ย่อย ๆ ที่มีขนาดเล็ก (คำถามคือ อะไรคือคำว่าเล็ก ?)
แต่ละ service มีการทำงานเพียงอย่างเดียว (Single Responsibility)
แต่ละ service ต้องให้ทำงานจบในตัวเอง (Self service) นั่นคือมี data store หรือที่จัดเก็บข้อมูลของแต่ละ service
แต่ถ้าต้องเรียกหรือทำงานร่วมกับ service อื่น ๆ ต้องไม่ลึกเกิน 3 ชั้น (อ้างอิงจาก Service Principle)
เนื่องจากจะทำให้ service มีความซับซ้อนเกินไป
ที่สำคัญการทำงานร่วมกับ service อื่น ๆ ทำให้เกิดปัญหาตามมามากมาย
ที่สำคัญขัดแย้งกับแนวคิดข้างต้น
ผลที่ได้คือ
Service ง่ายต่อการทำความเข้าใจ
Service ง่ายต่อการพัฒนา
Service ง่ายต่อการทดสอบ
Service ง่ายต่อการ deploy
Service ง่ายต่อการ scale
ที่สำคัญของการแยกเป็น service เล็ก ๆ คือ
ทำให้แต่ละทีมสามารถพัฒนา Service ไปพร้อม ๆ กันได้
รวมทั้งแต่ละทีมพัฒนา service สามารถทำได้ตั้งแต่ พัฒนา ทดสอบและ deploy เองได้ (Autonomous Team)
นั่นคือแต่ละทีมสามารถปิดงานได้อย่างอิสระ
แน่นอนว่า มันส่งผลต่อโครงสร้างและขั้นตอนการทำงานของทีมและบริษัทอย่างแน่นอน
ลองคิดดูสิว่า
ถ้าขั้นตอนการทำงานยังซับซ้อน มากมาย ล่าช้าแล้ว
แต่นำ Microservice มาใช้งาน มันจะรอดไหม ?
แต่ว่าเราจะแยก service ในแนวทางของ Microservice ทำได้อย่างไรบ้าง ?
คำถามต่อมาคือ ขนาดของ service จะมีขนาดเล็ก มันต้องเล็กเพียงใด ?
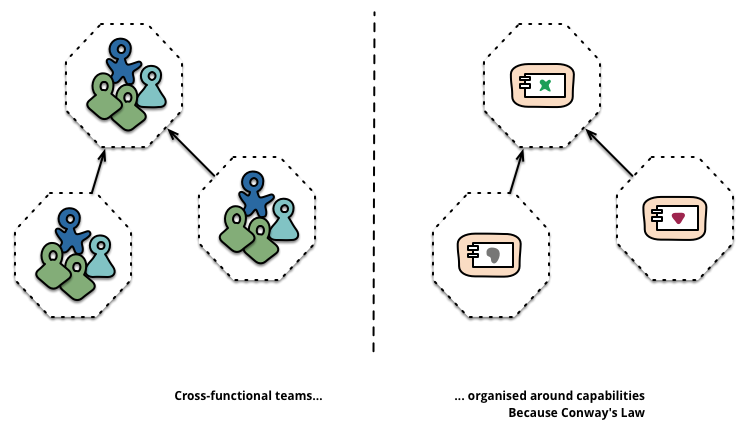
จากข้างต้นบอกว่า แต่ละ service ต้องมีทีมที่ดูแล เรียกว่า Cross-functional team
ดังนั้นขนาดของ service จะใหญ่เพียงใดนั้น
ตอบได้ง่าย ๆ คือ ทีมนั้น ๆ สามารถดูแล service ได้หรือไม่ ? (You build it, You run it)
ระบบงานที่เราสร้างมานั้น ไม่ได้เน้นไปที่จำนวน feature ให้ใช้งาน
แต่เน้นไปที่คุณค่าของระบบงานที่ให้ทางผู้ใช้งานและ business
รวมทั้งขนาดของ service ที่เล็ก จะยิ่งช่วยทำให้
ทีมพัฒนาและผู้ใช้งาน รวมทั้ง business ใกล้ชิดกันมากขึ้น
ซึ่งมันส่งผลดีต่อทุกฝ่าย
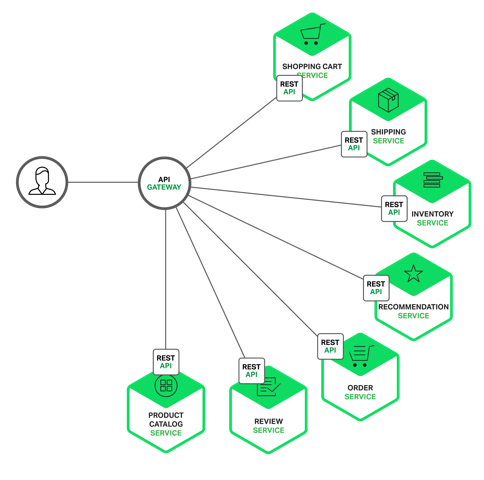
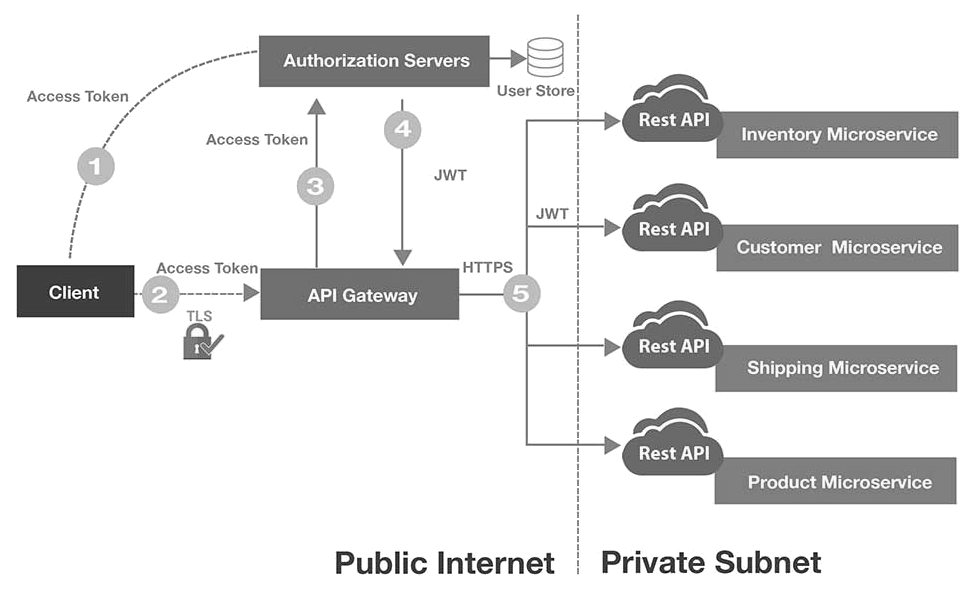
API gateway เนื่องจากจำนวน service มีจำนวนมาก ถ้าเรียกใช้งาน service-to-service จำนวนมาก ๆ แล้ว น่าจะทำให้เกิดความยุ่งเหยิงได้ ดังนั้นเราจึงนำ API gateway มาเป็นคนกลางของการติดต่อสื่อสาร แต่ต้องระวังอย่างให้กลายเป็นคอขวดหรือ Single Point of Failure ด้วยละ
แสดงดังรูป
ไม่ใช้งาน API gatewayใช้งาน API gateway มาใช้งาน เพื่อแก้ไขปัญหา แต่ก็มีปัญหาอย่างอื่นให้แก้ไขและรับมือนะ
The observer pattern is a software design pattern in which an object, called the subject,maintains a list of its dependents, called observers,and notifies them automatically of any state changes,usually by calling one of their methods.
publish–subscribe is a messaging pattern where senders is messages, called publishers,do not program the messages to be sent directly to specific receivers, called subscribers,but instead categorize published messages into classes without knowledge of which subscribers
ใน blog นี้ได้หยิบหัวข้อเรื่องของ Microservice API Gateway มาอธิบาย
เพื่อให้เห็นภาพและเข้าใจว่า
มันคืออะไร
ทำไมต้องนำมาใช้งาน
ถ้าไม่ใช้ได้ไหม
มาเริ่มกันเลย
API Gateway คืออะไร ?
เรียนได้ว่าเป็น Single Point of Contract ของ service จำนวนมากมายของเรา
ยิ่งในโลกของ Microservice จะมี service จำนวนมาก
ทำให้การเข้าถึง service เหล่านั้นน่าจะยาก
จึงน่าจะมีตัวกลางในการเข้าถึงดีกว่าไหม ?
โดยใน API Gateway นั้นจะมีความสามารถต่าง ๆ ดังนี้
เป็นตัวแปลง protocol การติดต่อสื่อสารระหว่าง service กับผู้ใช้งาน เช่นผู้ใช้งานติดต่อมายัง API Gateway ผ่าน HTTP จากนั้น API Gateway ก็ทำการติดต่อไปยัง service ผ่าน protocol อื่น ๆ ตามแต่ละ service ต่อไปได้
ลดความซับซ้อนของ Microservice ลง ทำให้แต่ละ service ไปเน้นที่ business เป็นหลัก
เมื่อมันมีข้อดีก็ต้องมีข้อเสีย !!!
กลายเป็น Single Point of Failure ไปได้
ใครเป็นคนดูแลระบบนี้ ?
จำเป็นต้องมี infrastructure ที่ดี
อาจจะทำให้ business logic ไปอยู่ใน API Gateway มากเกินไป ทำให้เกิด vendor locked-in ได้ง่าย
เมื่อเกิดปัญหาขึ้นมา แต่ละคนจะโทษกันไปกันมา เช่น
Backend team จะไปโทษ frontend team
Frontend team จะไปโทษคนออกแบบ
คนออกแบบจะไปโทษคนให้ requirement
คนให้ requirement จะไปโทษ business
Business จะไปโทษ ....
คำถามคือ ใครผิด ?
เมื่อเป็นเช่นนี้ก็ทำให้ไม่มีใครอยากจำทำอะไร
เสียทั้งเวลาและความรู้สึก
ยามเช้านั่งอ่านบทความเรื่อง Don’t be the software developer you hate to work with
อธิบายว่านักพัฒนา software แบบไหนที่ไม่มีใครอยากทำงานด้วย
ซึ่งสรุปไว้ 8 ข้อ
ผมคิดว่า น่าจะใช้ได้ทุก ๆ สายอาชีพนะ
เลยทำการสรุปมาไว้นิดหน่อย
Available kernels:java /Library/Frameworks/Python.framework/Versions/3/share/jupyter/kernels/javapython2 /Library/Frameworks/Python.framework/Versions/3/share/jupyter/kernels/python3
จากบทความเรื่อง 50 Shades of Go: Traps, Gotchas, and Common Mistakes for New Golang Devs
ทำการสรุปเรื่องต่าง ๆ ที่น่าสนใจสำหรับการพัฒนาระบบด้วยภาษา Go
ซึ่งเป็นสิ่งที่นักพัฒนาทั้งผู้เริ่มต้นไปจนถึงมีประสบการณ์มักจะไม่เข้าใจหรือทำผิด
ดังนั้นบทความนี้จึงทำการสรุปมาให้ เพื่อลดข้อผิดพลาด
รวมไปถึงย่นเวลาในการศึกษาอีกด้วย
เนื่องจากมี 50 เรื่อง เลยแบ่งออกเป็น blog ละ 10 เรื่องน่าจะดีกว่า
มาเริ่มกันเลย
แต่ในภาษา go แตกต่าง เพราะว่าการส่งข้อมูลชนิด array ไปยัง function มันคือการ copy value ของ array ดังนั้น ถ้าใน function ทำการแก้ไขค่าของ array จะไม่กระทบต้นทางเลย ซึ่งตรงนี้อาจจะทำให้นักพัฒนาที่เริ่มต้นกับภาษา go สับสนได้ง่าย
เรื่องที่ 13 ข้อควรระวังในการใช้ range กับ slice และ array
ข้อควรระวังในการวน loop ด้วยคำสั่ง for ซึ่งมักจะใช้ร่วมกับ range โดยที่ค่าที่ return กลับมาจาก range มี 2 ค่าคือ index กับ value สิ่งที่ผิดพลาดมาก ๆ คือ ประกาศตัวแปรมารับเพียงค่าเดียว ซึ่งจะได้ค่า index นั่นเอง ไม่ใช่ค่าของ value !!
ในภาษา go นั้นเรื่องความยาวของ string จะต่างจากภาษาอื่น โดยถ้าใช้งานผ่าน function len() แล้ว ผลที่ได้คือ จำนวนของ byte ไม่ใช้จำนวนของ character ทำให้ผลลัพธ์ที่ได้ต่างไปดังนี้

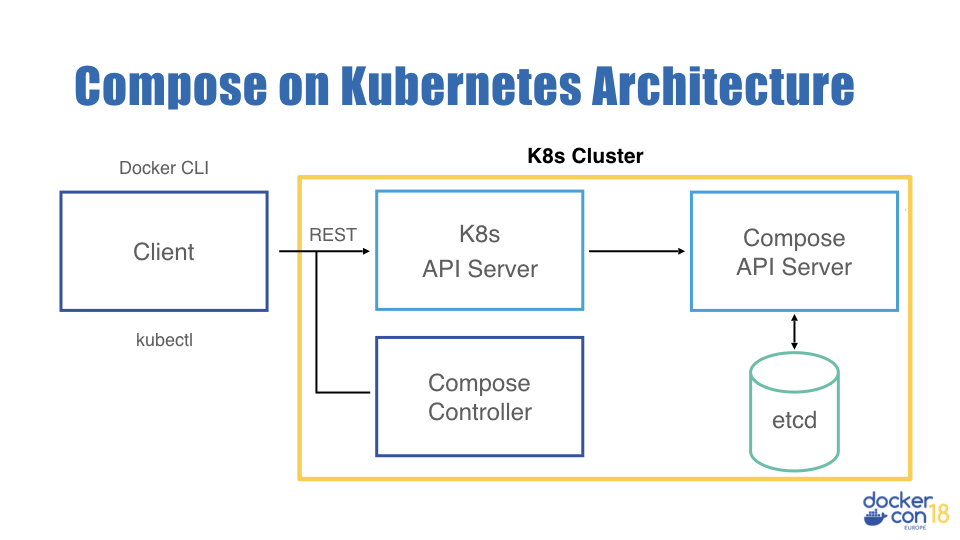 ส่วนเรื่องของ compatability สามารถดูได้เช่นกันจาก
Natively support Compose files on Kubernetes
ส่วนเรื่องของ compatability สามารถดูได้เช่นกันจาก
Natively support Compose files on Kubernetes

 เริ่มต้นจากสถาปัตยกรรมของระบบงาน (Application Architecture)
สถาปัตยกรรมของ software นั้นมีหลากหลายรูปแบบ
แต่แนวโน้มของสถาปัตยกรรมต่าง ๆ ล้วนพยายามแยกส่วนการทำงานออกเป็นชิ้นเล็ก (Decomposition)
โดยแต่ละชิ้นต้องทำงานได้ด้วยตัวเอง (Service)
ระบบงานใหญ่ ๆ เรามักจะเรียกว่า Monolithic
ส่วนระบบงานที่เราทำการแบ่งเป็น Service เล็ก ๆ จะเรียกว่า Microservice
แสดงดังรูป
เริ่มต้นจากสถาปัตยกรรมของระบบงาน (Application Architecture)
สถาปัตยกรรมของ software นั้นมีหลากหลายรูปแบบ
แต่แนวโน้มของสถาปัตยกรรมต่าง ๆ ล้วนพยายามแยกส่วนการทำงานออกเป็นชิ้นเล็ก (Decomposition)
โดยแต่ละชิ้นต้องทำงานได้ด้วยตัวเอง (Service)
ระบบงานใหญ่ ๆ เรามักจะเรียกว่า Monolithic
ส่วนระบบงานที่เราทำการแบ่งเป็น Service เล็ก ๆ จะเรียกว่า Microservice
แสดงดังรูป
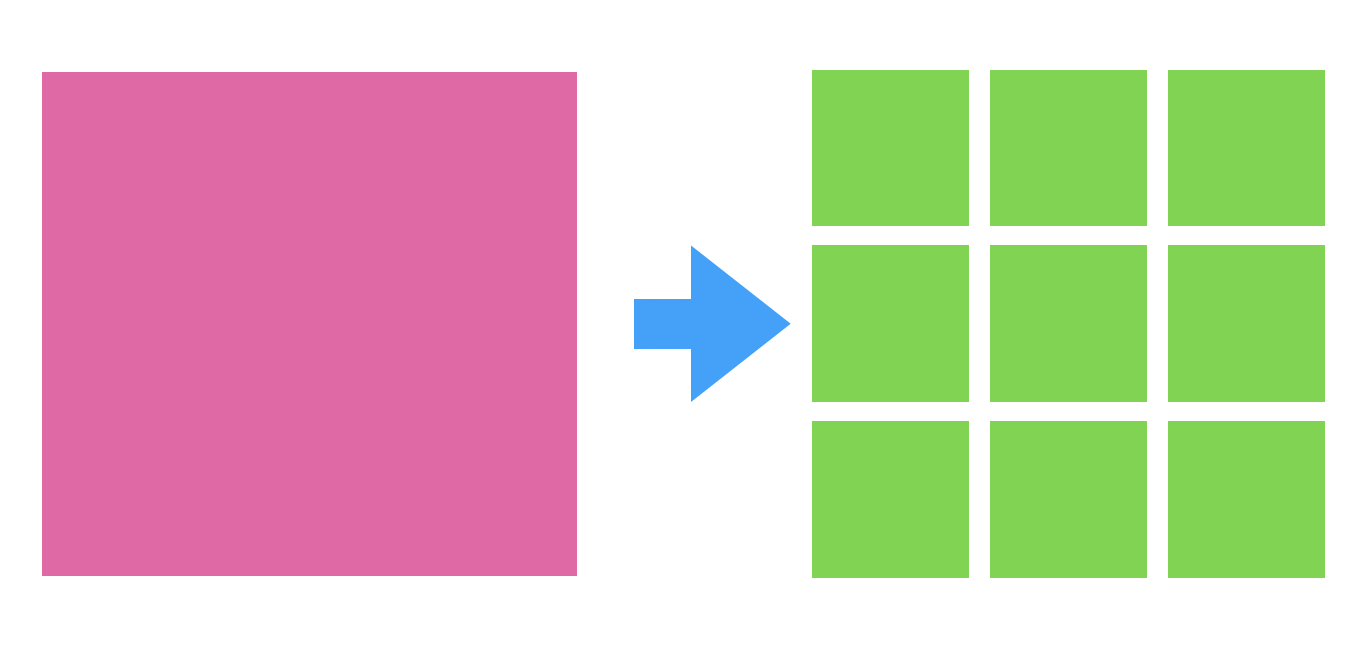 คำถามที่น่าสนใจคือ Monolithic มันไม่ดีหรือ ?
ตอบได้เลยว่า ดีสิ
ด้วยเหตุผลดังนี้
คำถามที่น่าสนใจคือ Monolithic มันไม่ดีหรือ ?
ตอบได้เลยว่า ดีสิ
ด้วยเหตุผลดังนี้
 ด้วยเหตุผลเหล่านี้ นักพัฒนาระบบงาน
จึงพยายามหาแนวทางในการแก้ไข
หนึ่งในการแก้ไขปัญหาคือ การแยกส่วนทำงานต่าง ๆ ออกจากกัน (Decomposition)
หรืออีกชื่อที่เราชอบเรียกกันคือ
ด้วยเหตุผลเหล่านี้ นักพัฒนาระบบงาน
จึงพยายามหาแนวทางในการแก้ไข
หนึ่งในการแก้ไขปัญหาคือ การแยกส่วนทำงานต่าง ๆ ออกจากกัน (Decomposition)
หรืออีกชื่อที่เราชอบเรียกกันคือ 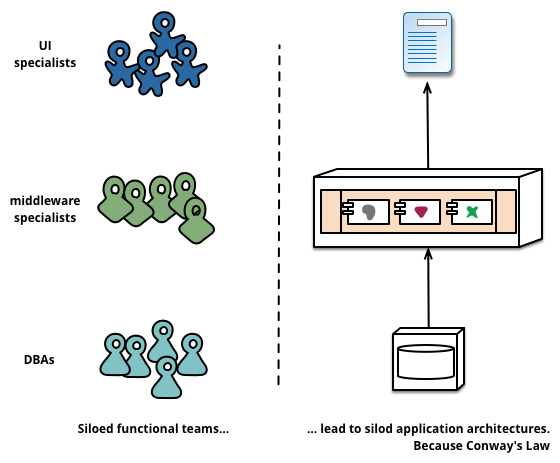
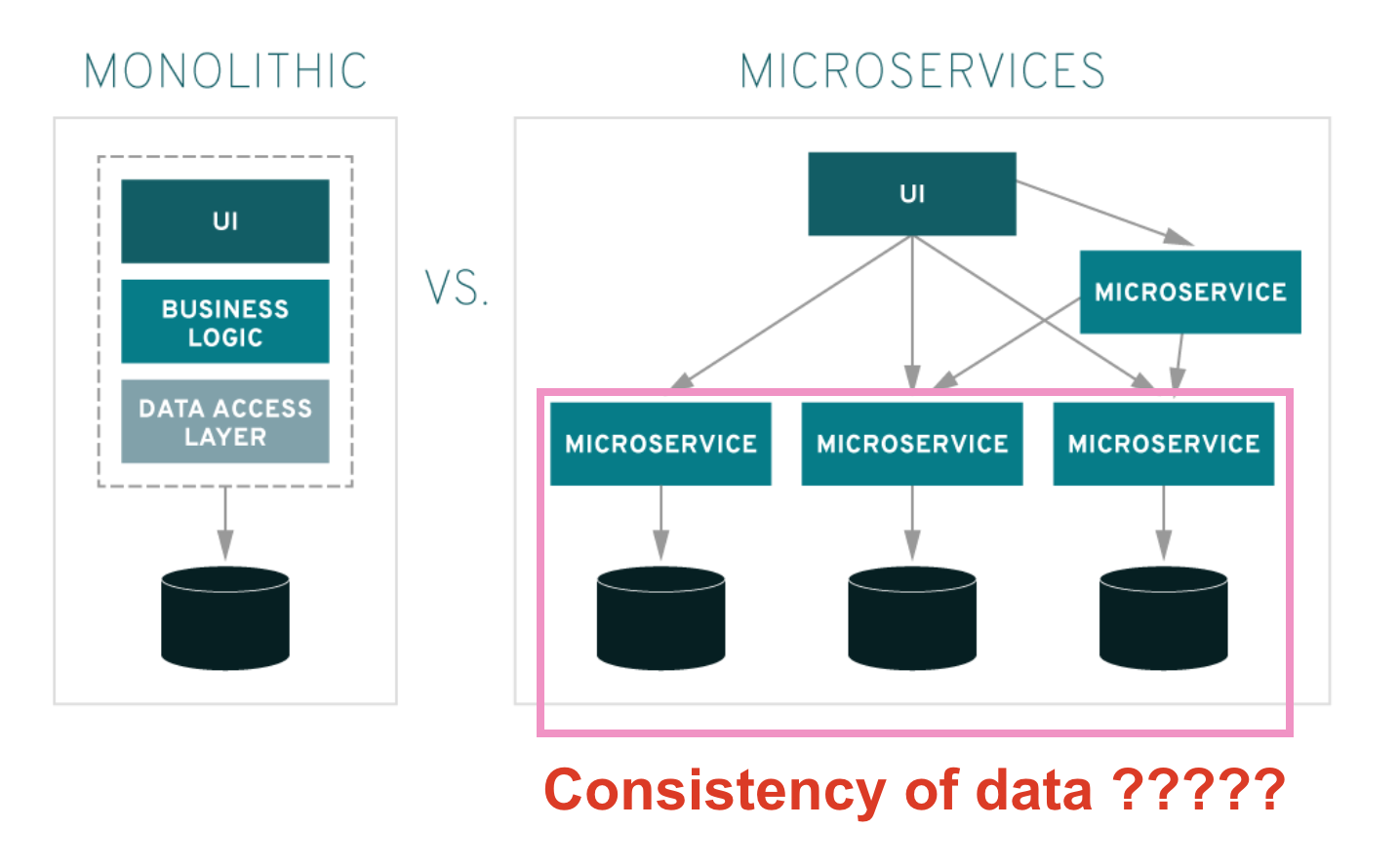 วิธีการจัดการปัญหาเรื่อง ความถูกต้องของข้อมูล (Data consistency) มีดังนี้
วิธีการจัดการปัญหาเรื่อง ความถูกต้องของข้อมูล (Data consistency) มีดังนี้
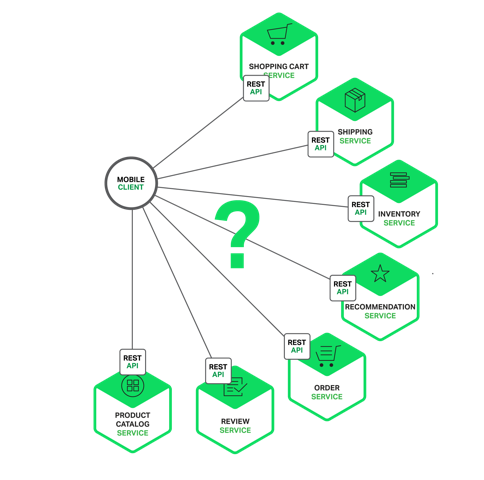 ใช้งาน API gateway มาใช้งาน เพื่อแก้ไขปัญหา แต่ก็มีปัญหาอย่างอื่นให้แก้ไขและรับมือนะ
ใช้งาน API gateway มาใช้งาน เพื่อแก้ไขปัญหา แต่ก็มีปัญหาอย่างอื่นให้แก้ไขและรับมือนะ
 แต่เมื่อระบบอยู่ในรูปแบบ Microservice แล้ว
นั่นคือจำนวน service มากกว่า 1 service
คำถามที่น่าสนใจคือ เราจะทำการทดสอบกันอย่างไร ?
แต่เมื่อระบบอยู่ในรูปแบบ Microservice แล้ว
นั่นคือจำนวน service มากกว่า 1 service
คำถามที่น่าสนใจคือ เราจะทำการทดสอบกันอย่างไร ?
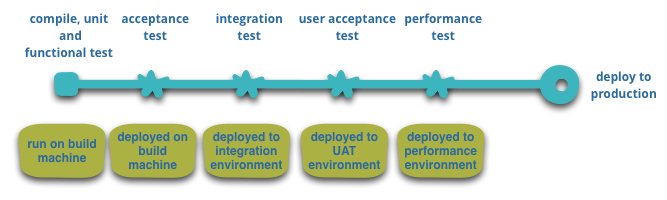
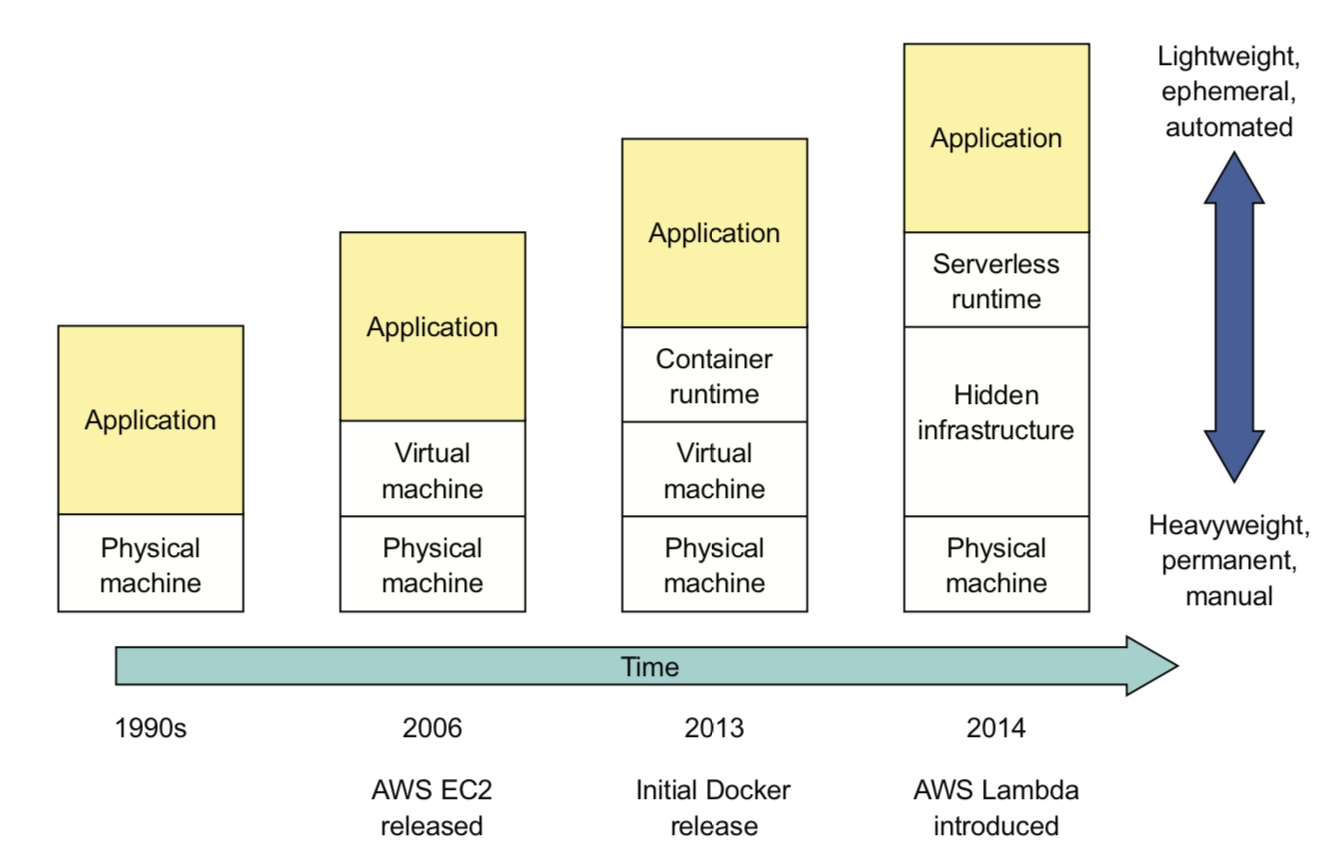 เราสามารถสรุปรูปแบบของการ deploy Microservice ได้ดังนี้
เราสามารถสรุปรูปแบบของการ deploy Microservice ได้ดังนี้
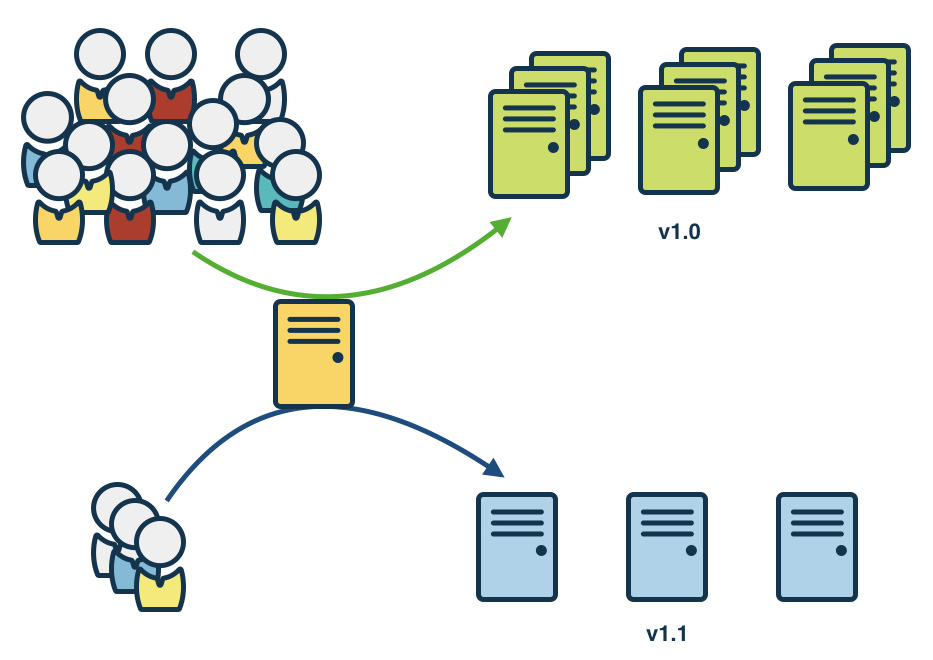
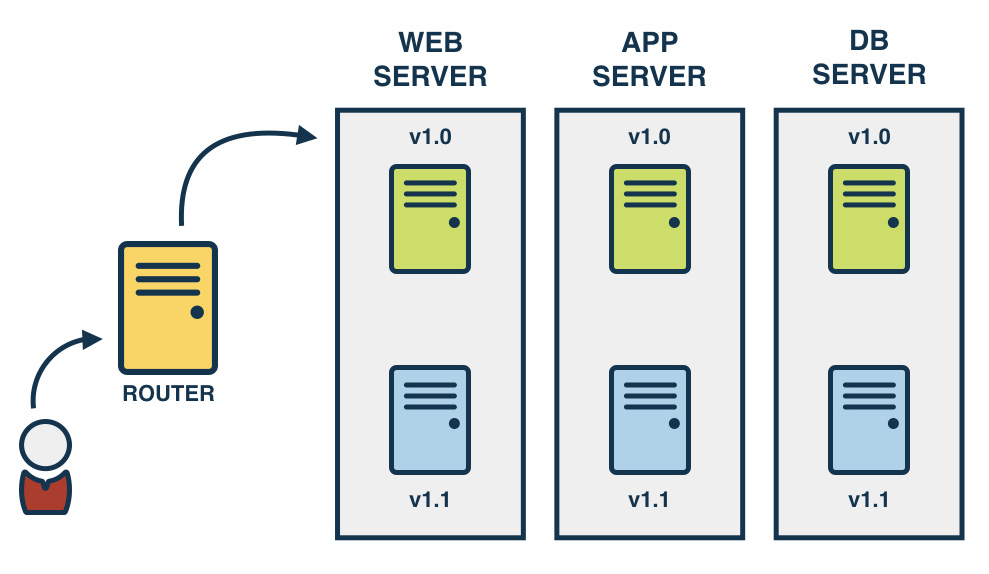 หรือจะเป็น Canary Deployment
แสดงดังรูป
หรือจะเป็น Canary Deployment
แสดงดังรูป

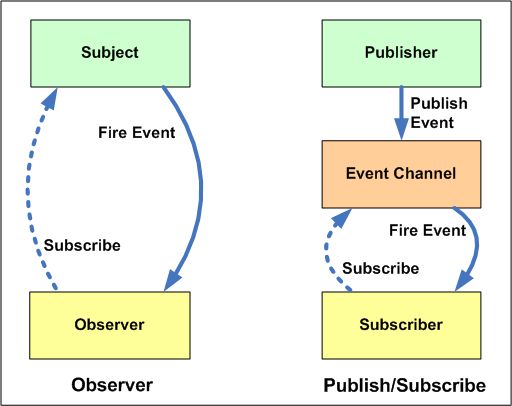
 เห็นผ่าน ๆ ว่ามีการพูดถึงความแตกต่างของ Observer pattern และ Publish-Subscribe pattern ว่าเป็นอย่างไร ?
เป็นคำถามที่น่าสนใจมาก ๆ
แต่ก่อนที่จะคุยกันว่า มันต่างกันอย่างไร
ควรที่จะรู้ก่อนไหมว่า แต่ละตัวมันคืออะไร ?
ดังนั้นมาดูกันหน่อยสิ
เริ่มด้วยข้อมูลที่ Wikipedia กันเลย
ถ้าตั้งใจหาและอ่านจะเจอแน่ ๆ ดังนี้
เห็นผ่าน ๆ ว่ามีการพูดถึงความแตกต่างของ Observer pattern และ Publish-Subscribe pattern ว่าเป็นอย่างไร ?
เป็นคำถามที่น่าสนใจมาก ๆ
แต่ก่อนที่จะคุยกันว่า มันต่างกันอย่างไร
ควรที่จะรู้ก่อนไหมว่า แต่ละตัวมันคืออะไร ?
ดังนั้นมาดูกันหน่อยสิ
เริ่มด้วยข้อมูลที่ Wikipedia กันเลย
ถ้าตั้งใจหาและอ่านจะเจอแน่ ๆ ดังนี้
 Reference Websites
Reference Websites

 จากหนังสือ
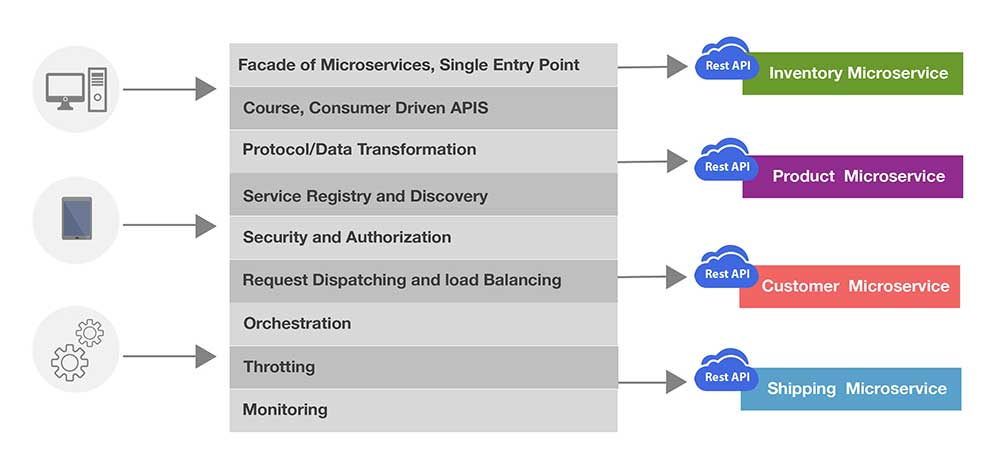
จากหนังสือ 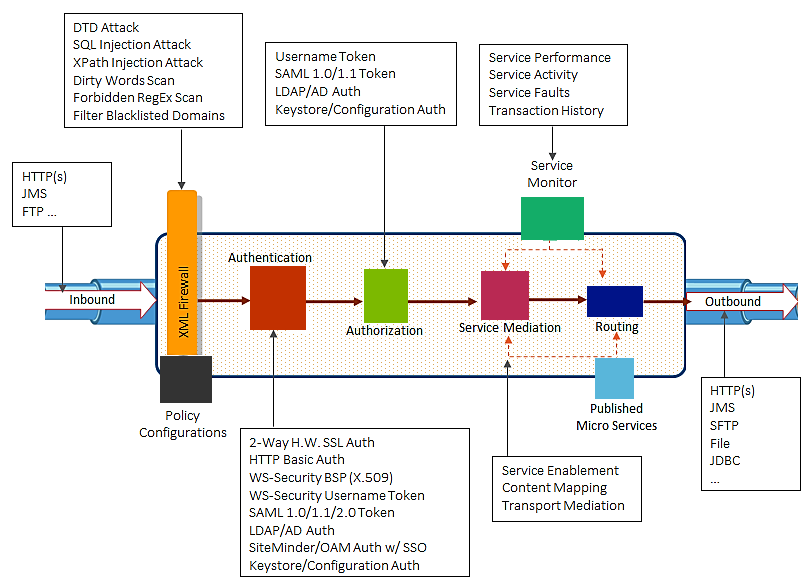 เมื่อระบบงานมีผู้ใช้งานจากหลาย ๆ ช่องทาง
เช่น Web, Mobile และ application เป็นต้น
สามารถเข้าใช้งานระบบเพียงที่เดียว
และจะทำให้ผู้สร้างและดูแลระบบสะดวกสบายขึ้น
เมื่อระบบงานมีผู้ใช้งานจากหลาย ๆ ช่องทาง
เช่น Web, Mobile และ application เป็นต้น
สามารถเข้าใช้งานระบบเพียงที่เดียว
และจะทำให้ผู้สร้างและดูแลระบบสะดวกสบายขึ้น

 นั่งอ่านหนังสือเกี่ยวกับการพัฒนา software
มีเรื่องที่น่าสนใจคือ สาเหตุที่ทำให้ project มันล้มเหลวหรือ fail
มาจากหลายสาเหตุมาก ๆ เลยสรุปไว้นิดหน่อย
บางครั้งมีงานออกมาดีมาก แต่ทีมแตกกระจาย
บางครั้งไม่มีงานออกมา แต่ทีมดีมาก
บางครั้งทีมแย่และงานก็แย่
คำถามคือ คำว่าล้มเหลววัดจากอะไร ?
นั่งอ่านหนังสือเกี่ยวกับการพัฒนา software
มีเรื่องที่น่าสนใจคือ สาเหตุที่ทำให้ project มันล้มเหลวหรือ fail
มาจากหลายสาเหตุมาก ๆ เลยสรุปไว้นิดหน่อย
บางครั้งมีงานออกมาดีมาก แต่ทีมแตกกระจาย
บางครั้งไม่มีงานออกมา แต่ทีมดีมาก
บางครั้งทีมแย่และงานก็แย่
คำถามคือ คำว่าล้มเหลววัดจากอะไร ?

 นั่งอ่านบทความเกี่ยวกับ
นั่งอ่านบทความเกี่ยวกับ
 เรื่องของเทคโนโลยีนั้นมีการเปลี่ยนแปลงเสมอ
รวมทั้งเรื่องของภาษาโปรแกรมก็เช่นกัน
แต่ละภาษามีทั้ง
สร้างขึ้นมาใหม่และปรับปรุงให้ดีขึ้น
เพื่อให้เหมาะสมกับรูปแบบงานในลักษณะต่าง ๆ กันไป
ทาง Oreilly ทำการสรุป 6 ภาษาโปรแกรมที่น่าจับตามองในปี 2019
ซึ่งดูจากความนิยมและขนาดของ community ที่ใหญ่ขึ้น
ประกอบไปด้วย
เรื่องของเทคโนโลยีนั้นมีการเปลี่ยนแปลงเสมอ
รวมทั้งเรื่องของภาษาโปรแกรมก็เช่นกัน
แต่ละภาษามีทั้ง
สร้างขึ้นมาใหม่และปรับปรุงให้ดีขึ้น
เพื่อให้เหมาะสมกับรูปแบบงานในลักษณะต่าง ๆ กันไป
ทาง Oreilly ทำการสรุป 6 ภาษาโปรแกรมที่น่าจับตามองในปี 2019
ซึ่งดูจากความนิยมและขนาดของ community ที่ใหญ่ขึ้น
ประกอบไปด้วย

 ในปี 2018 นั้นได้สอนและแนะนำเกี่ยวกับการพัฒนาระบบงานด้วยภาษา Java เยอะพอควร
สิ่งที่หนึ่งที่มักจะแนะนำคือ
เรื่องที่นักพัฒนาภาษา Java มักทำผิด
ยกตัวอย่างเช่น
ในปี 2018 นั้นได้สอนและแนะนำเกี่ยวกับการพัฒนาระบบงานด้วยภาษา Java เยอะพอควร
สิ่งที่หนึ่งที่มักจะแนะนำคือ
เรื่องที่นักพัฒนาภาษา Java มักทำผิด
ยกตัวอย่างเช่น

 ยามเช้านั่งอ่านบทความเรื่อง
ยามเช้านั่งอ่านบทความเรื่อง 
 จากการไปแนะนำเรื่อง Docker มาก็มีคำถามเรื่อง Security !!
ผมก็ไม่ค่อยมีประสบการณ์เรื่องนี้มากนัก
แต่ก็ไปเจอว่าทาง OWASP นั้นได้สร้าง
จากการไปแนะนำเรื่อง Docker มาก็มีคำถามเรื่อง Security !!
ผมก็ไม่ค่อยมีประสบการณ์เรื่องนี้มากนัก
แต่ก็ไปเจอว่าทาง OWASP นั้นได้สร้าง 
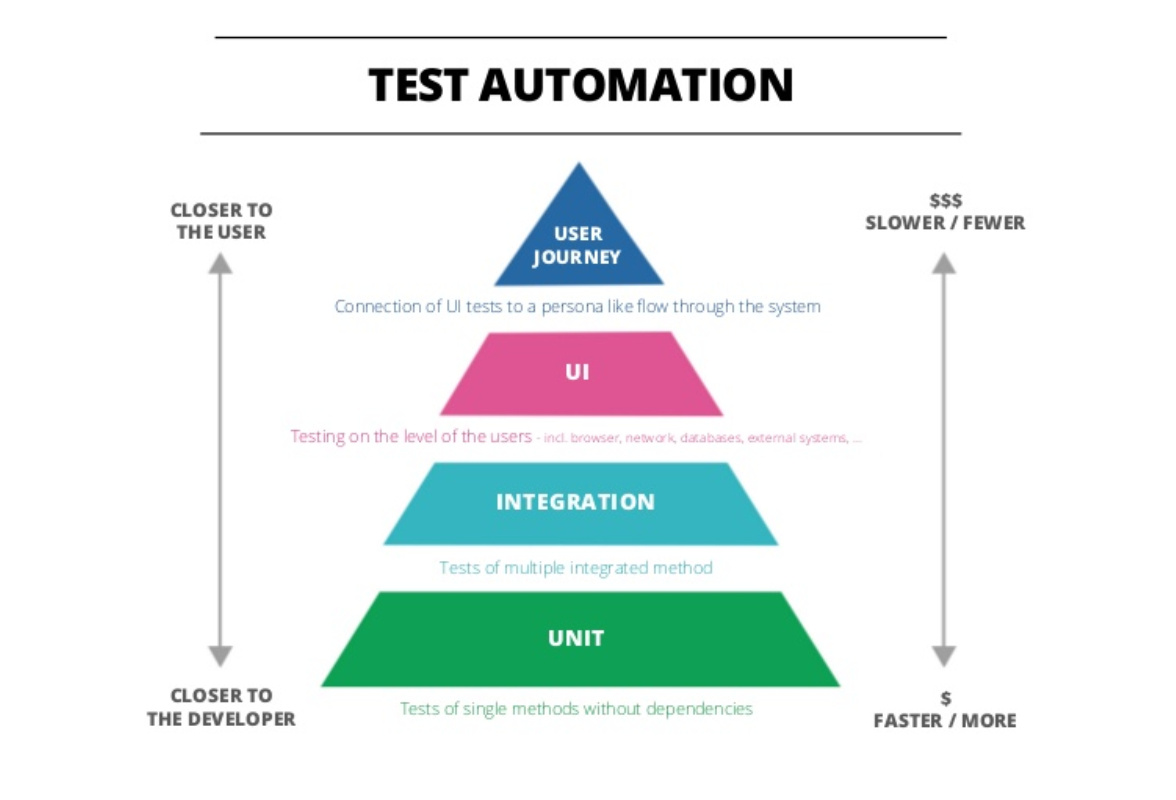
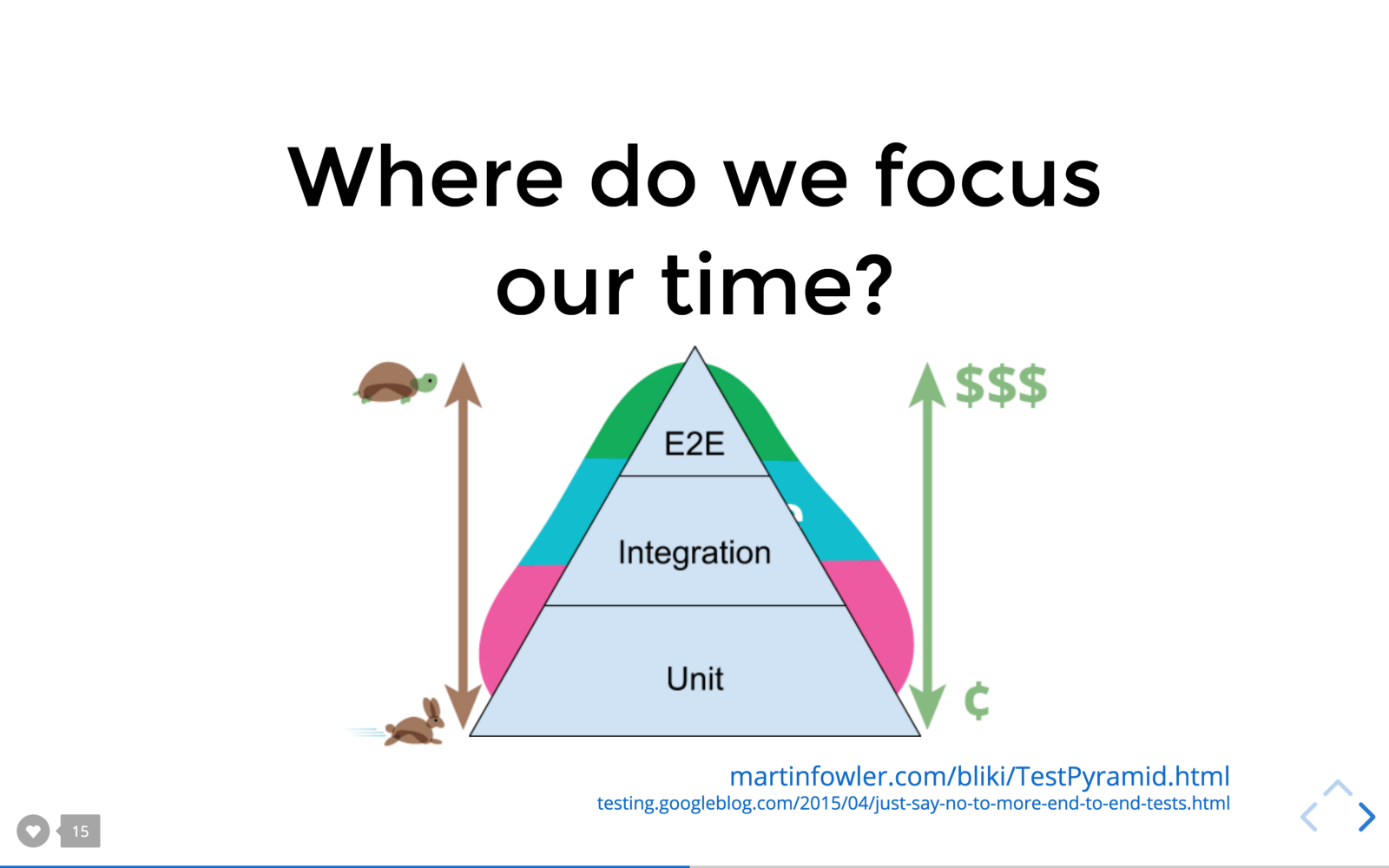 จากรูปนั้นคือ Test Pyramid
โดยเวลาและ resource ที่ต้องใช้สำหรับการเขียน ทดสอบ และดูแลรักษา automated test
จะมากขึ้นจากล่างขึ้นบนคือ Unit > Integration > End-to-End
นั่นหมายความว่า ให้เน้นในส่วนของ Unit test มาก ๆ
แต่สิ่งหนึ่งที่ไม่ได้แสดงใน Test Pyramid คือ ความเชื่อมั่น
ซึ่ง End-to-End test นั้นสร้างและทดสอบก็ช้า ใช้ resource เยอะ
แต่เรื่องของความเชื่อมันในการทดสอบก็สูงด้วย
ดังนั้นผู้เขียนบทความจึงเน้นไปที่เรื่องของความเชื่อมั่นของการทดสอบ
จึงได้คิด The Test Trophy ขึ้นมา
https://twitter.com/kentcdodds/status/960723172591992832?lang=en
แน่นอนว่า แนวคิดนี้ก็มีข้อขัดแย้งกับ Unit test
แสดงดังรูป
จากรูปนั้นคือ Test Pyramid
โดยเวลาและ resource ที่ต้องใช้สำหรับการเขียน ทดสอบ และดูแลรักษา automated test
จะมากขึ้นจากล่างขึ้นบนคือ Unit > Integration > End-to-End
นั่นหมายความว่า ให้เน้นในส่วนของ Unit test มาก ๆ
แต่สิ่งหนึ่งที่ไม่ได้แสดงใน Test Pyramid คือ ความเชื่อมั่น
ซึ่ง End-to-End test นั้นสร้างและทดสอบก็ช้า ใช้ resource เยอะ
แต่เรื่องของความเชื่อมันในการทดสอบก็สูงด้วย
ดังนั้นผู้เขียนบทความจึงเน้นไปที่เรื่องของความเชื่อมั่นของการทดสอบ
จึงได้คิด The Test Trophy ขึ้นมา
https://twitter.com/kentcdodds/status/960723172591992832?lang=en
แน่นอนว่า แนวคิดนี้ก็มีข้อขัดแย้งกับ Unit test
แสดงดังรูป
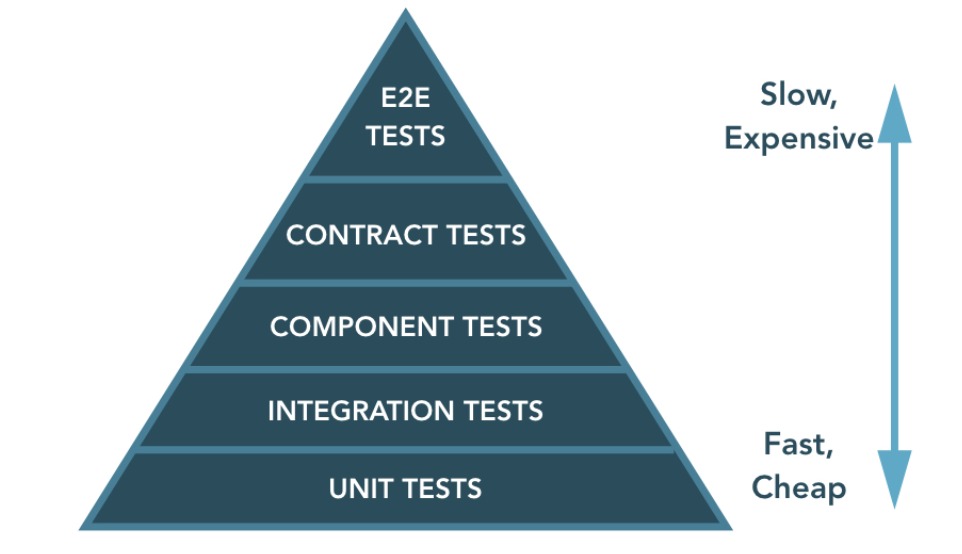
 โดย Unit test ก็คือการทดสอบในแต่ละส่วน ซึ่งทำงานถูกตามที่ต้องการ
แต่ไม่ได้หมายความว่า รวมกันแล้วจะทำงานได้ถูก
ดังนั้นสิ่งที้่ขาดไม่ได้คือ แต่ละส่วนงานต้องทำงานด้วยกันได้
นั่นคือ Integration test นั่นเอง
สิ่งที่ต้องคิดเพิ่มคือ ในการเขียน automated test นั้น
ต้องคิดถึงทั้งความเชื่อมั่น ความเร็วและค่าใช้จ่ายที่ลงไป
ว่ามันคุ้มไหม ?
โดย Unit test ก็คือการทดสอบในแต่ละส่วน ซึ่งทำงานถูกตามที่ต้องการ
แต่ไม่ได้หมายความว่า รวมกันแล้วจะทำงานได้ถูก
ดังนั้นสิ่งที้่ขาดไม่ได้คือ แต่ละส่วนงานต้องทำงานด้วยกันได้
นั่นคือ Integration test นั่นเอง
สิ่งที่ต้องคิดเพิ่มคือ ในการเขียน automated test นั้น
ต้องคิดถึงทั้งความเชื่อมั่น ความเร็วและค่าใช้จ่ายที่ลงไป
ว่ามันคุ้มไหม ?

 หลังจากที่ Microsoft ซื้อ GitHub.com ไปก็เริ่มมีการเปลี่ยนแปลง
หนึ่งในนั้นคือ
หลังจากที่ Microsoft ซื้อ GitHub.com ไปก็เริ่มมีการเปลี่ยนแปลง
หนึ่งในนั้นคือ  แน่นอนว่ามี
แน่นอนว่ามี 
 มีคำถามว่า
เราจะฝึกแก้ไขปัญหาต่าง ๆ ในเชิงการเขียนโปรแกรมอย่างไรดี ?
มีขั้นตอนอย่างไรบ้าง ?
ต้องทำอะไรบ้าง ?
คำตอบง่าย ๆ สำหรับผมคือ
เป็นคำถามที่ยากมาก ๆ ไม่รู้เหมือนกัน
เพราะว่า ผมก็แย่มาก ๆ ในเรื่องนี้
แต่ก็มีคำแนะนำนิดหน่อยดังนี้ น่าจะพอเป็นแนวทางและมีประโยชน์บ้าง
มีคำถามว่า
เราจะฝึกแก้ไขปัญหาต่าง ๆ ในเชิงการเขียนโปรแกรมอย่างไรดี ?
มีขั้นตอนอย่างไรบ้าง ?
ต้องทำอะไรบ้าง ?
คำตอบง่าย ๆ สำหรับผมคือ
เป็นคำถามที่ยากมาก ๆ ไม่รู้เหมือนกัน
เพราะว่า ผมก็แย่มาก ๆ ในเรื่องนี้
แต่ก็มีคำแนะนำนิดหน่อยดังนี้ น่าจะพอเป็นแนวทางและมีประโยชน์บ้าง

 มาติดตั้งกัน
เริ่มด้วยสิ่งที่ต้องมีก่อนคือ
มาติดตั้งกัน
เริ่มด้วยสิ่งที่ต้องมีก่อนคือ
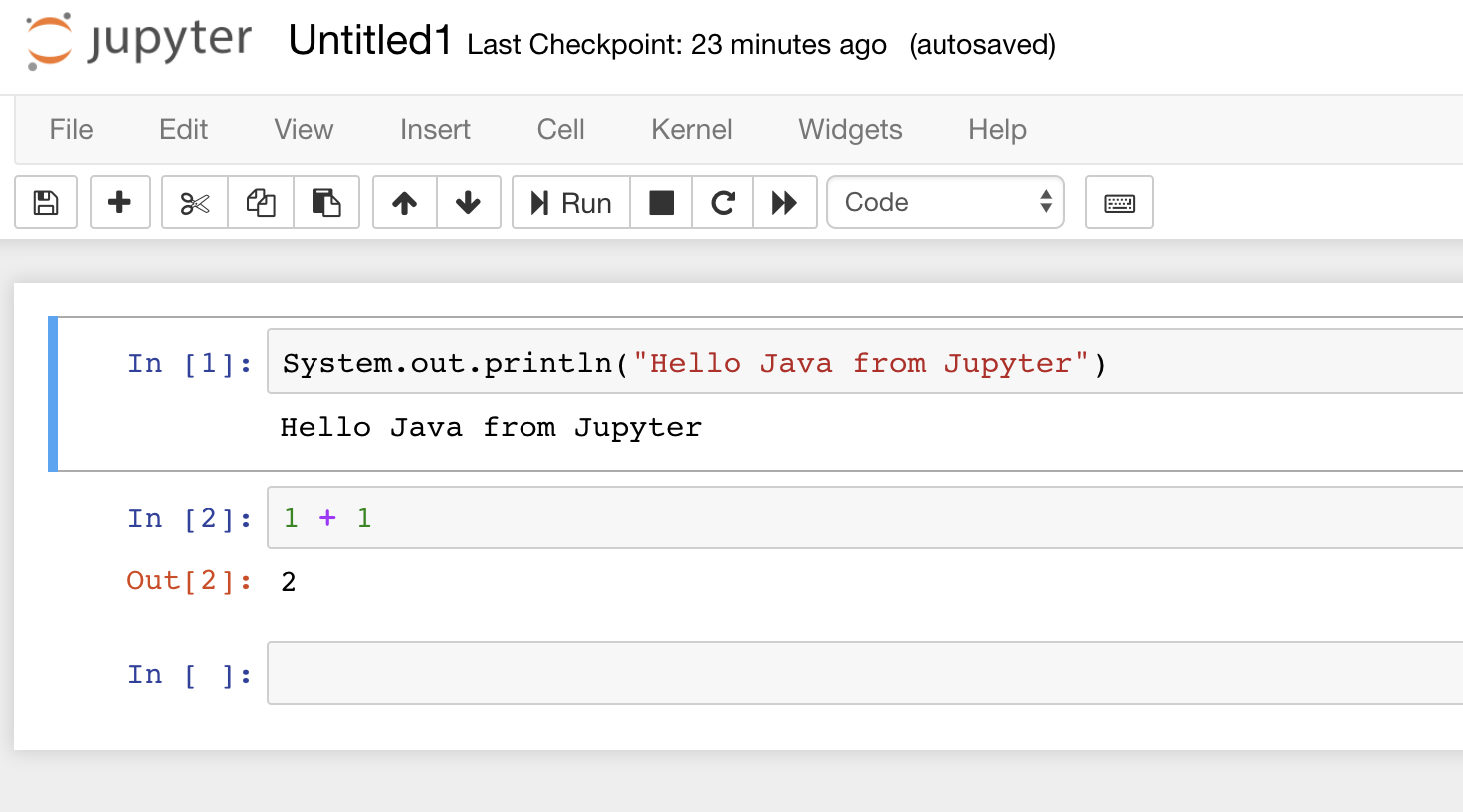 เพียงเท่านี้ก็ใช้งานได้แล้ว ง่ายมาก ๆ
Reference Websites
เพียงเท่านี้ก็ใช้งานได้แล้ว ง่ายมาก ๆ
Reference Websites

 จากบทความเรื่อง
จากบทความเรื่อง