![]()
![]()
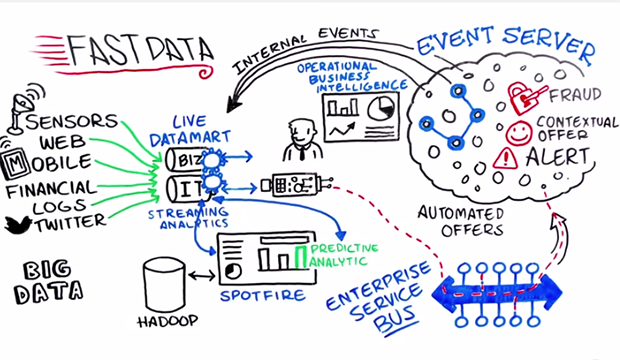
โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่
ขนาดของข้อมูลนั้นกลายเป็นเรื่องปกติไปแล้ว
ทั้งจาก business transaction, operation, logging และ IoT
แต่สิ่งที่สำคัญมากกว่าคือ
ความเร็วของระบบให้ทันต่อความต้องการ
เพื่อใช้ในการวิเคราะห์และตัดสินใจต่อไป
ยิ่งระบบสมัยใหม่ ทำการจัดเก็บข้อมูลการใช้งานเยอะมาก ๆ
ทั้งสถิติการใช้งาน เช่นการ click การ view และ การดู
เพื่อเรียนรู้พฤติกรรมการใช้งาน และ ปรับปรุงระบบได้อย่างทันท่วงที
ดังนั้นจำเป็นต้องมีกระบวนการจัดเก็บ ทำความสะอาด
วิเคราะห์ และแสดงผลได้เร็ว ดี ละเอียดและเข้าใจได้ง่าย
![]()
มีทางเลือกสำหรับระบบจัดการสิ่งต่าง ๆ เหล่านี้คือ
ซื้อ
ทำเอง
ให้คนอื่นทำให้
เลือกเอาเองนะครับ
แต่ในบทความนี้เราลองมาดูว่า โครงสร้างที่น่าจะเหมาะสมกับ Fast data เป็นอย่างไรบ้าง ?
ซึ่งต้องการให้การประมวลผลเร็ว ๆ
ดังนั้นน่าจะต้องคิดใหม่ ทำใหม่กัน
เพราะว่า จะมาประมวลผลแบบ batch หรือ offline คงไม่เพียงพอต่อความต้องการ
โดยในการจะสร้างระบบนั้นต้องพิจารณาในเรื่องของ
- การนำข้อมูลเข้าที่มีประสิทธิภาพ
- การจัดเก็บข้อมูลและการดึงข้อมูลที่ยืดหยุ่น
- การวิเคราะห์ข้อมูลที่สะดวกและหลากหลาย
- การแสดงผล
หรืออาจจะมองไปถึงเรื่องของ
Reactive คือ การขยายเข้าหรือออกตามความต้องการได้
Resilient และ
Responsive คือ สามารถทำงานได้ แม้จะมีส่วนใด ๆ ที่ล่มไป
มาดูในแต่ละส่วนกัน
1. การนำข้อมูลเข้า
โดยข้อมูลเข้ามีที่มามากมาย
มีรูปแบบที่แตกต่างกันเช่น plain text, JSON, XML
เป็นส่วนที่บอกว่า ข้อมูลจะเข้ามาสู่ระบบมากน้อยเพียงใด
โดยปกติจะมีขั้นตอนดังนี้
- Parsing
- Validation
- Cleansing
- De-duping
- Transformation
แนวทางที่น่าสนใจของการนำข้อมูลเข้าคือ
การทำงานควรเป็นแบบ Asynchronous
เช่นการส่งข้อมูลในแต่ละขั้นตอน ถ้ามารอกันคงช้าน่าดู
ส่วนพวกการทำ parsing จนถึง transform ข้อมูลนั้นใช้ resource ต่าง ๆ เยอะมาก
ดังนั้นก็ควรทำงานแบบขนานกันไปด้วย
นั่นคือ ควรมีการนำระบบ Messaging-Oriented Middleware (MOM) มาใช้
ซึ่งมีเครื่องมือต่าง ๆ มากมายเช่น
- Apache Kafka
- Akka Stream
- ActiveMQ
- RabbitMQ
- JBoss AMQ
โดยตัวที่แนะนำ คือ Apache Kafka
2. การจัดเก็บข้อมูล
แนะนำให้ทดลองใช้งานหลาย ๆ อย่าง
เพื่อให้เข้าใจ
เพื่อให้รู้ว่าเหมาะหรือไม่กับระบบงานของเรา
ซึ่งเชื่อเถอะว่า ทุก ๆ ปัญหาที่เราพบเจอนั้น มักจะมี solution หรือการแก้ไขไว้แล้ว
ดังนั้นไม่จำเป็นต้องสร้างขึ้นมาใหม่จากศูนย์เอง
ทั้งปัญหาเรื่องการอ่านข้อมูล
ทั้งปัญหาเรื่องการเขียนข้อมูล
ทั้งปัญหาเรื่องการแก้ไขข้อมูล
โดยที่จัดเก็บข้อมูลที่ดีจะช่วยลด
เวลาในการออกแบบ
เวลาในการประมวลผล
เวลาในการ transfer ข้อมูล
ประหยัดที่จัดเก็บ
ต่อมาสิ่งที่นำมาใช้งานต้องสามารถ configuration ได้ง่าย
และปรับแต่งตามที่ต้องการได้
ทั้งการ replication และ ความถูกต้องของข้อมูล
ในส่วนของการออกแบบ data model นั้น
มันขึ้นอยู่กับระบบและการนำไปใช้งาน
แต่ให้เน้นไปที่ performance เป็นหลัก
ในส่วนของเครื่องมือก็มีให้เลือกใช้เพียบ เช่น
- Apache Cassandra
- Couchbase
- Apache Hive
- Riak
- Redis
- MongoDB
- MariaDB
โดยตัวที่แนะนำ คือ Apache Cassandra
3. การประมวลผลข้อมูล
สำหรับระบบ Fast data นั้นมีการประมวลผลทั้ง Batching และ Streaming รวมกันไป
นั่นคือเลือกวิธีการให้เหมาะสมกับงานนั่นเอง
ยกตัวอย่างเช่น
ระบบงานต้องการการทำงานแบบ realtime คงไม่ใช้วิธีการแบบ batching หรอกนะ
หรือถ้ามีระบบ ETL แบบเดิม ๆ อยู่ ซึ่งทำงานแบบ bacthing
คงไม่มีใครบ้าระห่ำย้ายมาทำงานแบบ realtime หรือ streaming หมดหรอกนะ
โดยที่เครื่องมือบางตัวอาจจะแบ่งการทำงานเป็นส่วนเล็ก ๆ
แต่ละส่วนการทำงานจะทำงานแบบ bactching หรือ micro-batching
จากนั้นตัวควบคุมการทำงานหลักทำงานแบบ streaming
ซึ่งวิธีการทำงานแบบนี้จะเรียกว่า hybrid
อีกเครื่องคือ จะทำการบน disk หรือ memory ดีละ
ก็เหมือนข้างต้นนั่นเอง
ทำงานบน disk ไปหมดก็ไม่ดี มันช้า
ทำงานบน memory ไปหมดก็ไม่ได้ มันเปลือง
เราพูดถึงความเร็วคือ data locallly มากกว่า
นั่นคือ ประมวลผลข้อมูลที่อยู่ใกล้ ๆ
ซึ่งเร็วต่อการทำงาน และ transfer ข้อมูล
ดังนั้นเครื่องมือหลาย ๆ ตัว
จะทำงานแบบการกระจายข้อมูลไปในแต่ละที่
จากนั้นจึงรวมผลการทำงานเข้าด้วยกัน
คุ้น ๆ กับวิธีการทำงานหรือไม่ ?
โดยเครื่องมือมีให้ใช้เยอะมาก ๆ ยกตัวอย่างเช่น
- Apache Spark
- Apache Flink
- Apache Storm
- Apache Beam
- Tensorflow
โดยตัวที่แนะนำ คือ Apache Spark สำหรับ micro-batching และ Apache Flink สำหรับ streaming
4. การแสดงผลข้อมูล
เป็นส่วนที่ใช้อธิบายผลการประมวลผลข้อมูลให้ผู้ใช้งานทั่วไปเข้าใจได้ง่าย
เป็นขั้นตอนที่ไม่ง่ายเลย
เนื่องจากต้องใช้ศาตร์และศิลป์เยอะสูงมาก ๆ
ที่สำคัญต้องโดนใจ ถูกต้อง เข้าใจง่ายและเร็ว
ดังนั้น การ process เยอะ ๆ ในขณะแสดงผลเป็นสิ่งต้องห้ามอย่างมาก
ข้อมูลก่อนนำมาแสดงผล ต้องเป็นข้อมูลที่สรุปมาแล้ว
เช่นข้อมูลตามหมวดหมู และ ตามช่วงเวลาเป็นต้น
ข้อมูลแต่ละชุดทำขึ้นมาเพื่อการแสดงผลแบบเฉพาะเจาะจงเท่านั้น
อย่านำข้อมูลชุดเดียวแล้วไปแสดงในทุกรูปแบบ
มิเช่นนั้นจะช้าอย่างมาก
ส่วนของเครื่องมือก็เยอะนะ ยกตัวอย่างเช่น
- Notebook report เช่น Jupiter notebook และ Apache Zeppelin
- Tableau
- D3.js
- Gephi
แต่ทั้งหมดนี้ ต้องการ infrastructure ที่ดีด้วยเช่นกัน
ดังนั้น operation จำเป็นต้องปรับและเปลี่ยนด้วย
จากที่เคยทำแต่ scale-up ต้องเปลี่ยนมาเป็น scale-out
รวมทั้งเรื่องการนำ opensource มาใช้งาน
แนวคิดและแนวปฏิบัติ DevOps จึงมีความสำคัญอย่างมาก
เพื่อลดการ rework ต่าง ๆ ลงไป
เช่นทีมพัฒนาสามารถทดสอบระบบ
บน environment ที่เหมือนหรือคล้ายกับ production เป็นต้น
ส่วนของเครื่องมีในการจัดการก็มีเยอะมากเช่นเดิม
- Docker
- Kubernetes
- Spinnaker
- Apache Mesos
ทั้งหมดนี้เป็นคำแนะนำเล็ก ๆ น้อย ๆ สำหรับระบบ Fast Data
เพื่อช่วยทำให้การจัดการข้อมูลมีประสิทธิภาพที่ดีขึ้นตั้งแต่
การนำข้อมูลเข้า
การจัดเก็บข้อมูล
การประมวลผลข้อมูล
การแสดงผลข้อมูล
Reference Websites
https://www.oreilly.com/ideas/from-big-data-to-fast-data

 Puppeteer เป็น Node library พัฒนาจาก Google
เตรียมชุดของ API สำหรับการควบคุม Google Chrome (Headless และ Non-headless)
หรือ Chromium ผ่าน DevTool protocol
ที่สำคัญไม่ต้องทำงานผ่าน Web Driver อีกต่อไป
ซึ่งถ้าใครใช้งานผ่าน Selenium จะรู้ว่ามันน่าเบื่อมาก ๆ
เพราะว่าต้อง update version ตาม Google Chrome !!
ข้อดีคือ ลด dependency ต่าง ๆ
สำหรับการควบคุมหรือจัดการ Google Chrome
แต่ก็ต้องแลกมาด้วยการเรียนรู้เพิ่มเติมนะ
นั่นคือต้องเขียนชุดการทดสอบด้วย NodeJS
แต่งานสายนี้ก็ต้องเรียนรู้อยู่แล้ว
ดังนั้นมาเริ่มใช้งานกัน
Puppeteer เป็น Node library พัฒนาจาก Google
เตรียมชุดของ API สำหรับการควบคุม Google Chrome (Headless และ Non-headless)
หรือ Chromium ผ่าน DevTool protocol
ที่สำคัญไม่ต้องทำงานผ่าน Web Driver อีกต่อไป
ซึ่งถ้าใครใช้งานผ่าน Selenium จะรู้ว่ามันน่าเบื่อมาก ๆ
เพราะว่าต้อง update version ตาม Google Chrome !!
ข้อดีคือ ลด dependency ต่าง ๆ
สำหรับการควบคุมหรือจัดการ Google Chrome
แต่ก็ต้องแลกมาด้วยการเรียนรู้เพิ่มเติมนะ
นั่นคือต้องเขียนชุดการทดสอบด้วย NodeJS
แต่งานสายนี้ก็ต้องเรียนรู้อยู่แล้ว
ดังนั้นมาเริ่มใช้งานกัน

 ทาง
ทาง 



 ทำการ configuration API Gateway ดังนี้
API Name = hello-go
Deployment stage = prod
Security = Open
ทำการ configuration API Gateway ดังนี้
API Name = hello-go
Deployment stage = prod
Security = Open
 จากนั้นทำการบันทึก จะได้ URL ของ function ดังนี้
จากนั้นทำการบันทึก จะได้ URL ของ function ดังนี้


 Tracing เป็นอีกเรื่องหนึ่งที่ service หรือระบบงานต่าง ๆ ต้องมีเสมอ
และมันมีประโยชน์ต่อระบบและทีมพัฒนาอย่างมาก
แต่เราพบว่าระบบงานส่วนใหญ่ไม่มี หรือ มีน้อยมาก ๆ
ดังนั้นเรามาลองสร้างระบบงานที่มีการ tracing การทำงานของระบบ
สิ่งที่ใช้ในการพัฒนาประกอบไปด้วย
Tracing เป็นอีกเรื่องหนึ่งที่ service หรือระบบงานต่าง ๆ ต้องมีเสมอ
และมันมีประโยชน์ต่อระบบและทีมพัฒนาอย่างมาก
แต่เราพบว่าระบบงานส่วนใหญ่ไม่มี หรือ มีน้อยมาก ๆ
ดังนั้นเรามาลองสร้างระบบงานที่มีการ tracing การทำงานของระบบ
สิ่งที่ใช้ในการพัฒนาประกอบไปด้วย
 มาเริ่มพัฒนาระบบงานกันดีกว่า
มาเริ่มพัฒนาระบบงานกันดีกว่า

 เข้าไปดูรายละเอียดของแต่ละกลุ่มของ request หรือ Span
เข้าไปดูรายละเอียดของแต่ละกลุ่มของ request หรือ Span
 ในรายละเอียดของแต่ละ Span มันลงรายละเอียดของการทำงานเลยทีเดียว
ทั้ง class และ method
ในรายละเอียดของแต่ละ Span มันลงรายละเอียดของการทำงานเลยทีเดียว
ทั้ง class และ method

 เข้าไปดูรายละเอียดของแต่ละกลุ่มของ request หรือ Span
เข้าไปดูรายละเอียดของแต่ละกลุ่มของ request หรือ Span
 ในรายละเอียดของแต่ละ Span มันลงรายละเอียดของการทำงานเลยทีเดียว
ทั้ง class และ method
ในรายละเอียดของแต่ละ Span มันลงรายละเอียดของการทำงานเลยทีเดียว
ทั้ง class และ method
 เพียงเท่านี้เราก็ได้ระบบ tracing ของ service ต่าง ๆ
ที่พัฒนาด้วย Spring Boot แล้วนะ
น่าจะช่วยทำให้นักพัฒนาเห็นการทำงานที่ชัดเจน รวมทั้งหาปัญหาได้ง่ายขึ้น
ตัวอย่าง source code อยู่ที่
เพียงเท่านี้เราก็ได้ระบบ tracing ของ service ต่าง ๆ
ที่พัฒนาด้วย Spring Boot แล้วนะ
น่าจะช่วยทำให้นักพัฒนาเห็นการทำงานที่ชัดเจน รวมทั้งหาปัญหาได้ง่ายขึ้น
ตัวอย่าง source code อยู่ที่ 
 ในช่วงที่ผ่านมาได้มีการพูดถึง
ในช่วงที่ผ่านมาได้มีการพูดถึง 
 จากหนังสือ
จากหนังสือ 
 มีโอกาสได้แบ่งปันเรื่อง Microservices มากขึ้น
ทำให้เห็นมุมมองต่าง ๆ มากขึ้นเช่นกัน
หนึ่งในนั้นคือ
มีโอกาสได้แบ่งปันเรื่อง Microservices มากขึ้น
ทำให้เห็นมุมมองต่าง ๆ มากขึ้นเช่นกัน
หนึ่งในนั้นคือ 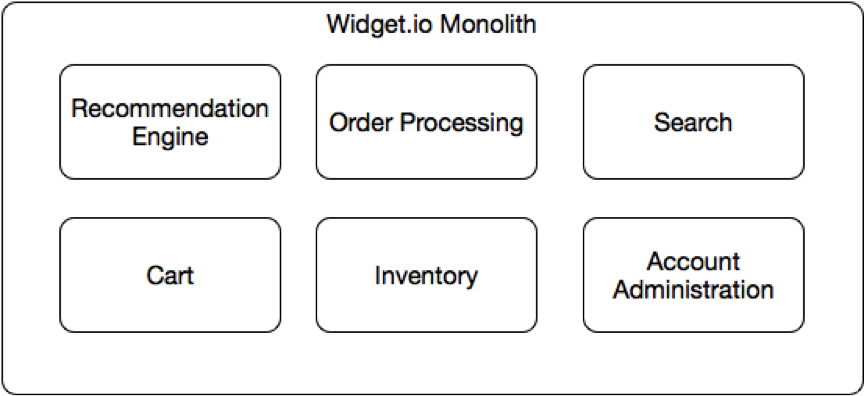
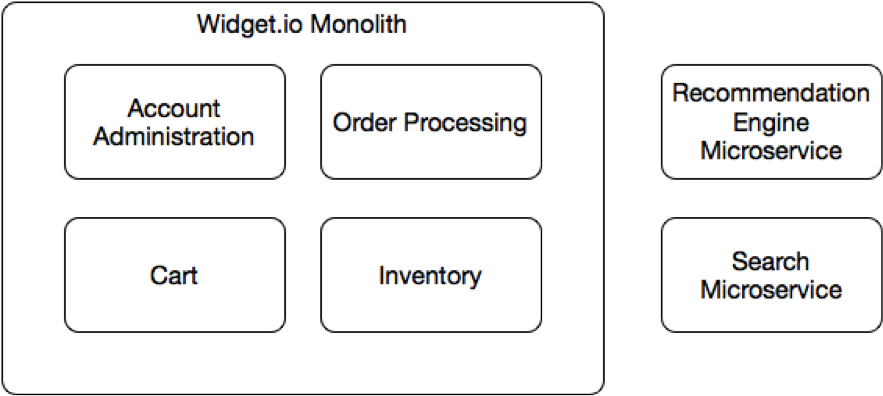
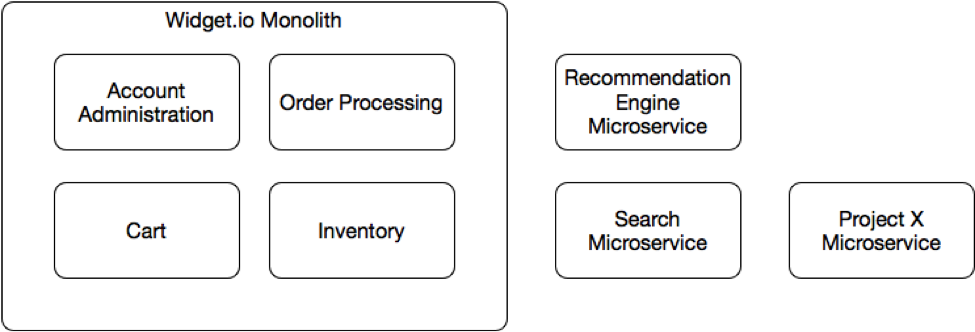
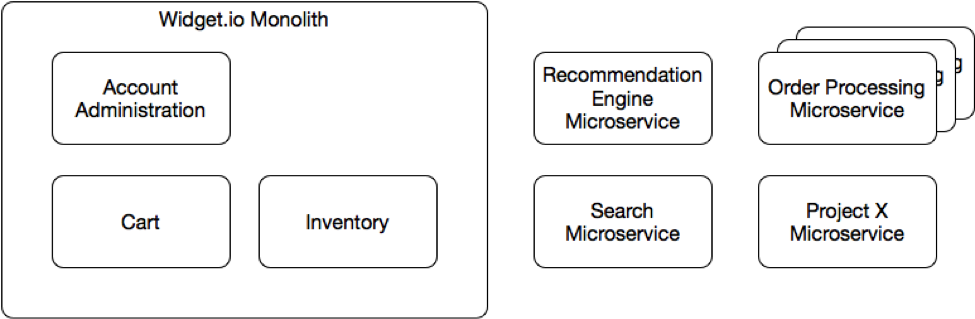
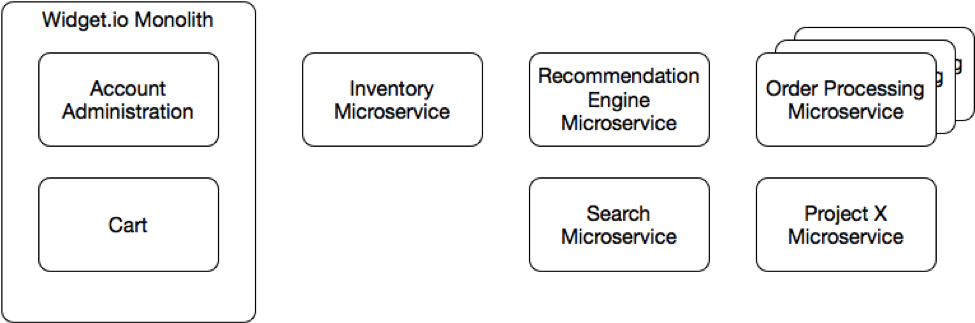

 จากหนังสือ
จากหนังสือ  การทดสอบทั้งหมดนี้
เพื่อช่วยทำให้แน่ใจว่า ระบบงานสามารถตอบรับการทำงานจากผู้ใช้งานได้
และอย่างถูกต้องตามที่คาดหวัง
รวมทั้งทำให้เข้าใจการทำงานและพฤติกรรมต่าง ๆ ของระบบ
สุดท้ายการทดสอบต่าง ๆ
ควรต้องทำงานอยู่อย่างเสมอ
ควรทำงานได้อย่างรวดเร็ว เพื่อให้ได้รับ feedback ที่รวดเร็ว
เพื่อทำให้แน่ใจว่าระบบงานพร้อมอยู่ตลอดเวลา
การทดสอบทั้งหมดนี้
เพื่อช่วยทำให้แน่ใจว่า ระบบงานสามารถตอบรับการทำงานจากผู้ใช้งานได้
และอย่างถูกต้องตามที่คาดหวัง
รวมทั้งทำให้เข้าใจการทำงานและพฤติกรรมต่าง ๆ ของระบบ
สุดท้ายการทดสอบต่าง ๆ
ควรต้องทำงานอยู่อย่างเสมอ
ควรทำงานได้อย่างรวดเร็ว เพื่อให้ได้รับ feedback ที่รวดเร็ว
เพื่อทำให้แน่ใจว่าระบบงานพร้อมอยู่ตลอดเวลา



 อ่านเจอข่าวว่า
อ่านเจอข่าวว่า 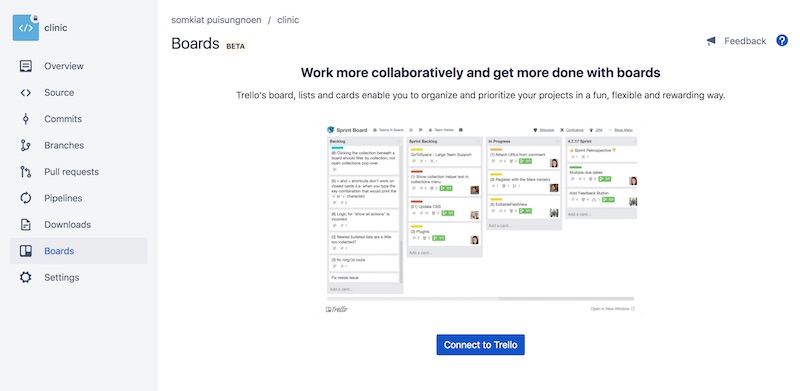 จากนั้นทำการเชื่อมต่อกับ Trello
ซึ่งสามารถสร้างหรือเลือก Board ที่มีอยู่แล้วได้
จากนั้นทำการเชื่อมต่อกับ Trello
ซึ่งสามารถสร้างหรือเลือก Board ที่มีอยู่แล้วได้
 ทำการกำหนดสิทธิ์ในการเข้าใช้งาน Board นั้น ๆ
มีทั้ง Admin, Write และ Read ให้เลือก
ทำการกำหนดสิทธิ์ในการเข้าใช้งาน Board นั้น ๆ
มีทั้ง Admin, Write และ Read ให้เลือก
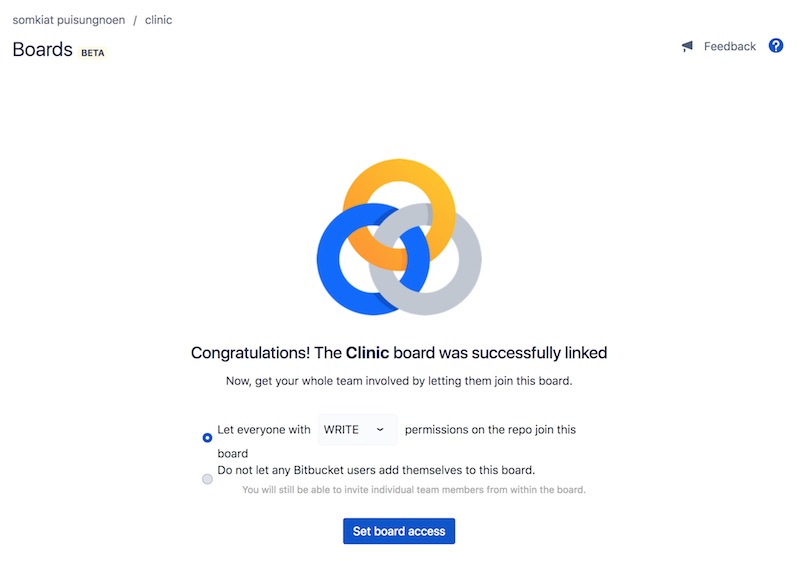 จากนั้นก็จะมี Board สวย ๆ จาก Trello มาแสดงใน Repository ใน Bitbucket แล้วนะ
จากนั้นก็จะมี Board สวย ๆ จาก Trello มาแสดงใน Repository ใน Bitbucket แล้วนะ
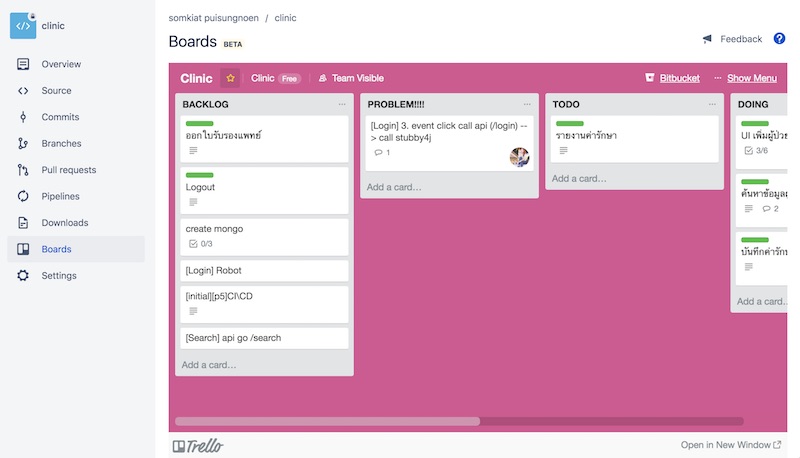 แต่ก็เป็นเพียงการนำ Board มาแสดงเท่านั้นเอง
ยังไม่ integrate กันดีเท่าไรนัก
ซึ่งตรงนี้ Github ทำได้ดีกว่า
แต่ Board ของ Trello มันสวยนะเออ
ดังนั้นลองมาใช้กันดูครับ สะดวกขึ้นเยอะ
ไม่ต้องเปิดสลับไปมาแล้วนะ
พอลองไปใน Card แต่ละใบ จะพบว่า
มีความสามารถดังนี้อีกด้วย
เช่นการ attach เข้าไปยัง Pull Request/Branch/Commit ใน repository ที่ Bitbucket ได้อีกด้วย
แต่ก็เป็นเพียงการนำ Board มาแสดงเท่านั้นเอง
ยังไม่ integrate กันดีเท่าไรนัก
ซึ่งตรงนี้ Github ทำได้ดีกว่า
แต่ Board ของ Trello มันสวยนะเออ
ดังนั้นลองมาใช้กันดูครับ สะดวกขึ้นเยอะ
ไม่ต้องเปิดสลับไปมาแล้วนะ
พอลองไปใน Card แต่ละใบ จะพบว่า
มีความสามารถดังนี้อีกด้วย
เช่นการ attach เข้าไปยัง Pull Request/Branch/Commit ใน repository ที่ Bitbucket ได้อีกด้วย
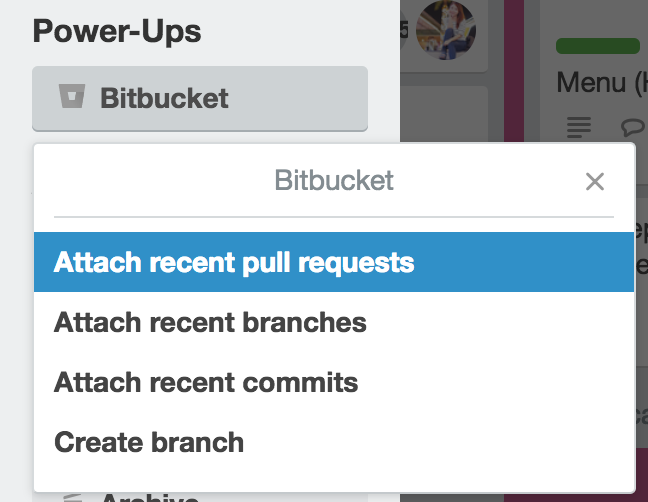
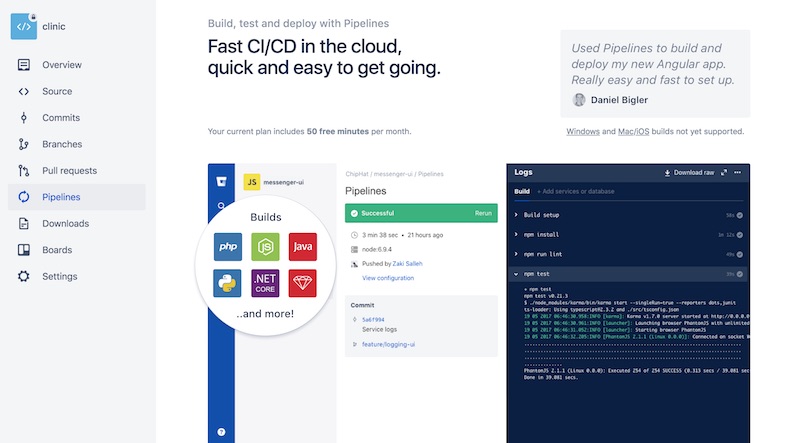 ตัวอย่างระบบงานพัฒนาด้วยภาษา Go
ก็สามารถทำการเพิ่ม config ได้ดังนี้
ตัวอย่างระบบงานพัฒนาด้วยภาษา Go
ก็สามารถทำการเพิ่ม config ได้ดังนี้
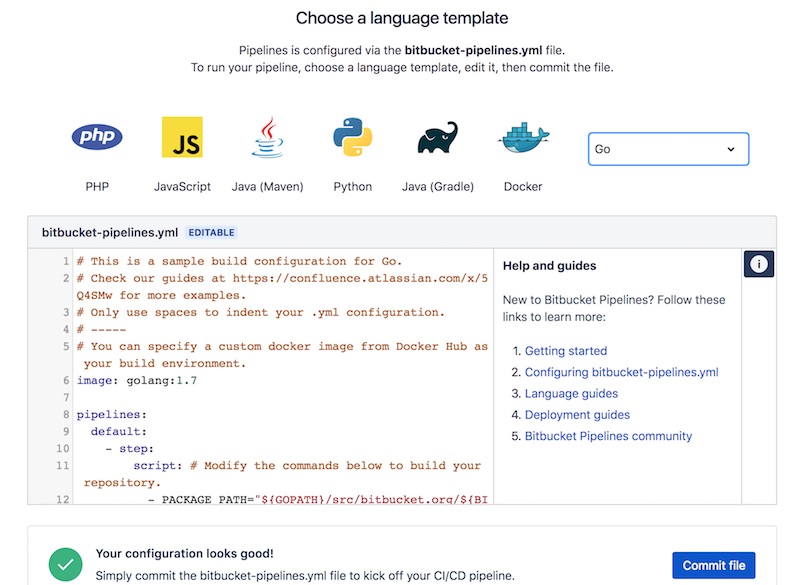 จากนั้นทำการ run สิครับ ได้ผลการทำงานดังนี้
เป็นความสามารถที่น่าสนใจ
ดังนั้นลองใช้งานกันดูครับ มันง่ายมาก ๆ
จากนั้นทำการ run สิครับ ได้ผลการทำงานดังนี้
เป็นความสามารถที่น่าสนใจ
ดังนั้นลองใช้งานกันดูครับ มันง่ายมาก ๆ
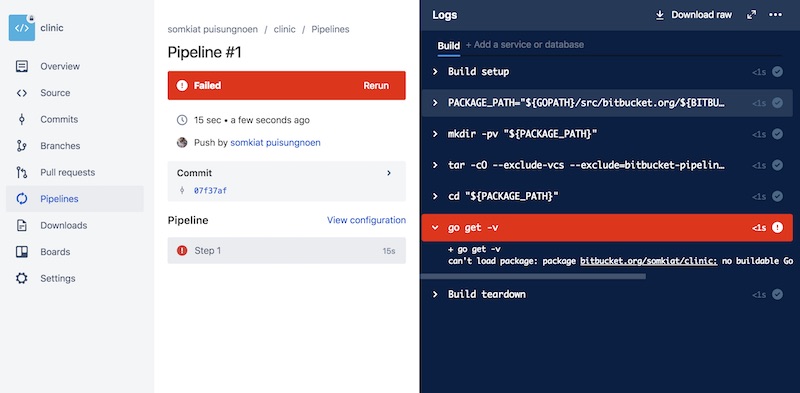 มาถึงตรงนี้ Bitbucket น่าใช้ขึ้นมาเป็นกองครับ
มาถึงตรงนี้ Bitbucket น่าใช้ขึ้นมาเป็นกองครับ

 ว่าด้วยเรื่อง Continuous Integration นั้น
มันช่วยลดปัญหา หรือ ช่วยหาข้อผิดพลาดของระบบ
ที่มีการเปลี่ยนแปลงอยู่ตลอดเวลา
แน่นอนว่ามีคุณค่า (Value) มากมาย
แต่บ่อยครั้งกลับพบว่า
คุณค่าเหล่านั้นของ Continuous Integration ถูกลดค่าหรือทำลายลงไป
ดังนั้นมาดูกันหน่อย
ว่าด้วยเรื่อง Continuous Integration นั้น
มันช่วยลดปัญหา หรือ ช่วยหาข้อผิดพลาดของระบบ
ที่มีการเปลี่ยนแปลงอยู่ตลอดเวลา
แน่นอนว่ามีคุณค่า (Value) มากมาย
แต่บ่อยครั้งกลับพบว่า
คุณค่าเหล่านั้นของ Continuous Integration ถูกลดค่าหรือทำลายลงไป
ดังนั้นมาดูกันหน่อย

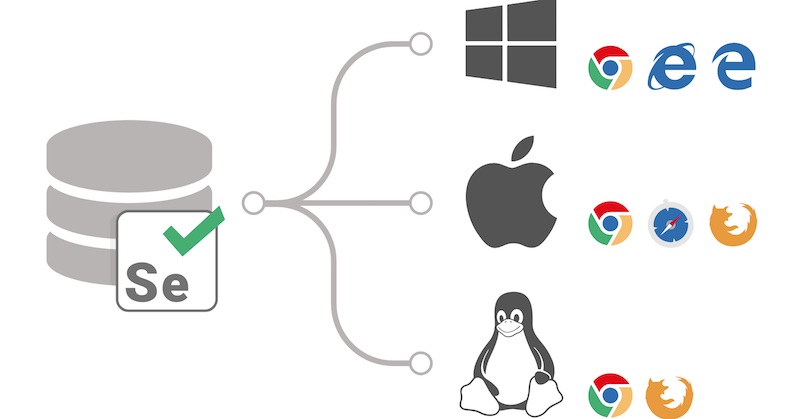
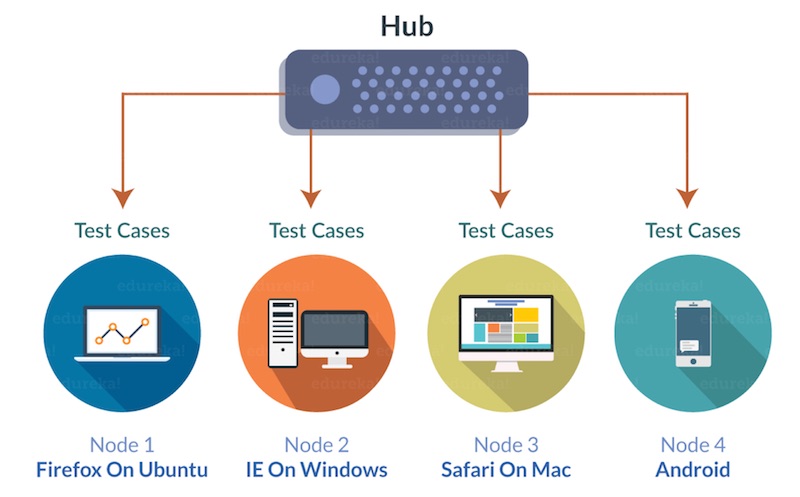
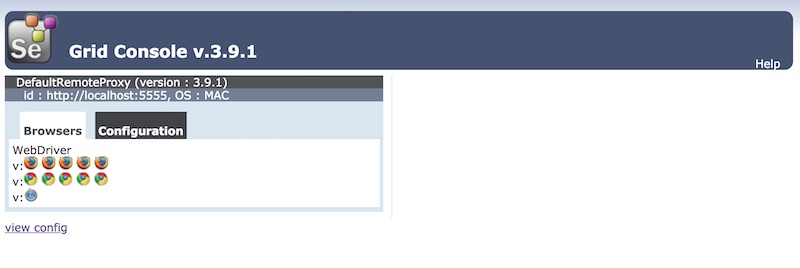 การติดตั้งในรูปแบบนี้นั้น ดูแลรักษาไม่ง่ายเลย
ทั้งการ download และติดตั้ง dependency ต่าง ๆ ของแต่ละ node
ทั้ง process ของ java ที่อาจใช้ memory จนเกิดปัญหา out of memory ได้
ทั้งการจัดการ node ต่าง ๆ แบบ manual เช่น restart node เมื่อเกิดปัญหา
ทั้งปัญหาในการดูแลรักษา
ทั้งปัญหาเรื่องของการขยายระบบ
การติดตั้งในรูปแบบนี้นั้น ดูแลรักษาไม่ง่ายเลย
ทั้งการ download และติดตั้ง dependency ต่าง ๆ ของแต่ละ node
ทั้ง process ของ java ที่อาจใช้ memory จนเกิดปัญหา out of memory ได้
ทั้งการจัดการ node ต่าง ๆ แบบ manual เช่น restart node เมื่อเกิดปัญหา
ทั้งปัญหาในการดูแลรักษา
ทั้งปัญหาเรื่องของการขยายระบบ
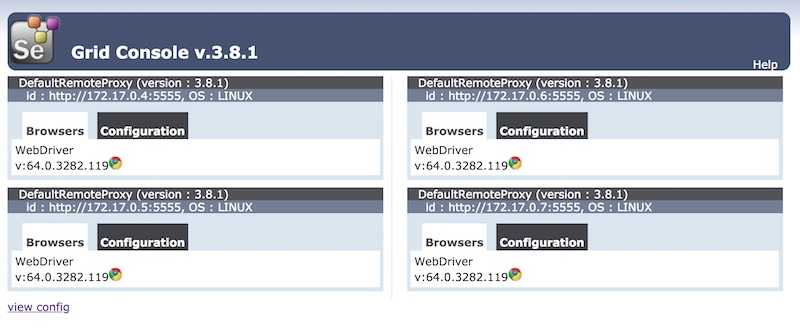 เพียงเท่านี้ก็สามารถติดตั้งและใช้งาน Selenium Grid แบบง่าย ๆ ได้แล้ว
ดังนั้นอย่าลืมนำ Selenium Grid ไปใช้งานกันนะครับ
Reference Website
เพียงเท่านี้ก็สามารถติดตั้งและใช้งาน Selenium Grid แบบง่าย ๆ ได้แล้ว
ดังนั้นอย่าลืมนำ Selenium Grid ไปใช้งานกันนะครับ
Reference Website

 หลังดูบอลมานั่งเขียน Android app ด้วยภาษา Kotlin กันหน่อย
ซึ่งเป็นภาษาที่มีความสามารถที่ดีมากมาย
หนึ่งในนั้นคือ Data Class ที่ Java Developer ถือว่าเป็น killer feature เลยนะ
เพราะว่า ไม่ต้องมาเขียนหรือ generate getter/setter method เอง
ดังนั้นทุกคนก็จะ convert พวก POJO class มาเป็น Data Class กันหมดเลย
รู้กันไหมว่า ความสามารถนี้มันมาพร้อม cost นะ
มาลองดูกัน
หลังดูบอลมานั่งเขียน Android app ด้วยภาษา Kotlin กันหน่อย
ซึ่งเป็นภาษาที่มีความสามารถที่ดีมากมาย
หนึ่งในนั้นคือ Data Class ที่ Java Developer ถือว่าเป็น killer feature เลยนะ
เพราะว่า ไม่ต้องมาเขียนหรือ generate getter/setter method เอง
ดังนั้นทุกคนก็จะ convert พวก POJO class มาเป็น Data Class กันหมดเลย
รู้กันไหมว่า ความสามารถนี้มันมาพร้อม cost นะ
มาลองดูกัน



 อ่านเจอบทความที่น่าสนใจเรื่อง
อ่านเจอบทความที่น่าสนใจเรื่อง 
 มีโอกาส review code ของชาว Data Science หรือบางที่เรียกว่า Data Science Team/Project
ซึ่ง code ต่าง ๆ ที่เขียนขึ้นมานั้นมันทำงานได้ดีตามที่ต้องการ
เขียนจากทั้งนักพัฒนาจริง ๆ และ ไม่ใช่จากสายนักพัฒนา
แน่นอนว่า มันไม่แปลกอะไรเลย
แต่พบว่า code ส่วนใหญ่มันส่งกลิ่นแปลก ๆ มากพอควร
ถ้าเรายังอยู่กับ code แบบนี้ต่อไป
คิดว่า ไม่น่าจะส่งผลดีต่อทีม และ บริษัทเลย
ดังนั้นจึงให้คำแนะนำไปนิดหน่อย
น่าจะพอมีประโยชน์ หรือ อาจจะทำให้เสียกำลังใจก็เป็นไปได้
มีโอกาส review code ของชาว Data Science หรือบางที่เรียกว่า Data Science Team/Project
ซึ่ง code ต่าง ๆ ที่เขียนขึ้นมานั้นมันทำงานได้ดีตามที่ต้องการ
เขียนจากทั้งนักพัฒนาจริง ๆ และ ไม่ใช่จากสายนักพัฒนา
แน่นอนว่า มันไม่แปลกอะไรเลย
แต่พบว่า code ส่วนใหญ่มันส่งกลิ่นแปลก ๆ มากพอควร
ถ้าเรายังอยู่กับ code แบบนี้ต่อไป
คิดว่า ไม่น่าจะส่งผลดีต่อทีม และ บริษัทเลย
ดังนั้นจึงให้คำแนะนำไปนิดหน่อย
น่าจะพอมีประโยชน์ หรือ อาจจะทำให้เสียกำลังใจก็เป็นไปได้

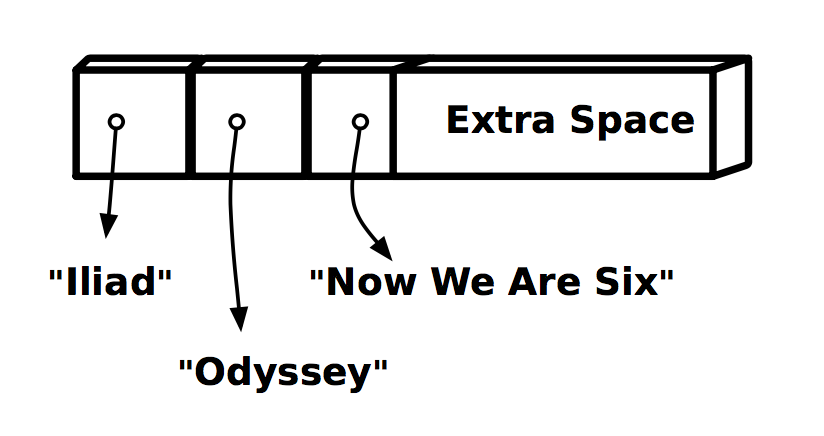 แต่ List จะตรงข้ามกับ Vector เลย เพราะว่าคือ Linked List
แสดงดังรูป
แต่ List จะตรงข้ามกับ Vector เลย เพราะว่าคือ Linked List
แสดงดังรูป
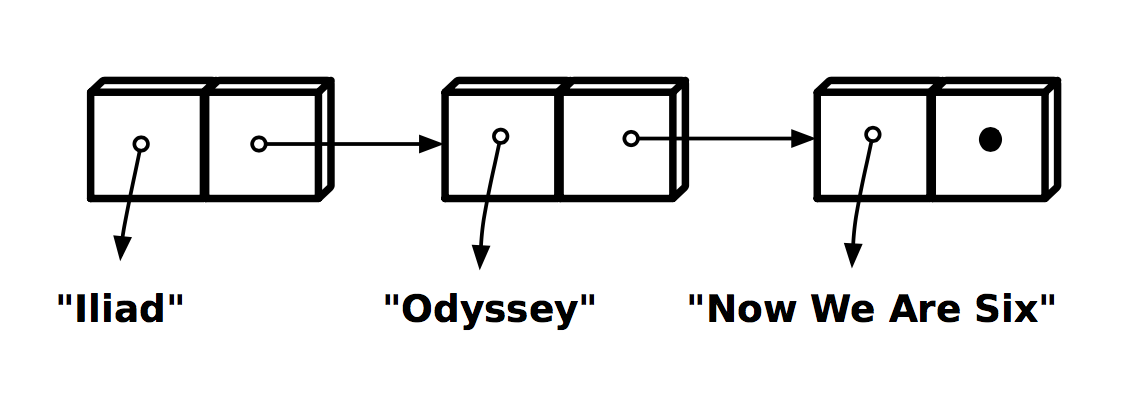 ส่งผลให้การเข้าถึงข้อมูลในแต่ละตำแหน่งต่างกัน
โดยการเข้าถึงของ Vector จะเร็วกว่า List
เพราะว่าใช้การคำนวณทางคณิตศาสตร์
ส่วน List ต้องไปตามลำดับที่ link กันไว้
แต่การใช้งานต้อดู use case ด้วยว่าอะไรที่เหมาะกับ Vector หรือ List
ส่งผลให้การเข้าถึงข้อมูลในแต่ละตำแหน่งต่างกัน
โดยการเข้าถึงของ Vector จะเร็วกว่า List
เพราะว่าใช้การคำนวณทางคณิตศาสตร์
ส่วน List ต้องไปตามลำดับที่ link กันไว้
แต่การใช้งานต้อดู use case ด้วยว่าอะไรที่เหมาะกับ Vector หรือ List

 ในวันที่ 18 กุมภาพันธ์ 2561 ที่ผ่านมามีโอกาสไปแบ่งปัน
เรื่อง ก้าวแรกสู่สังเวียนการใช้งาน Wordpress ที่งาน
ในวันที่ 18 กุมภาพันธ์ 2561 ที่ผ่านมามีโอกาสไปแบ่งปัน
เรื่อง ก้าวแรกสู่สังเวียนการใช้งาน Wordpress ที่งาน 
 เมื่อวันที่ 16 กุมภาพันธ์ 2561 ที่ผ่านมา
ทีมพัฒนาภาษา
เมื่อวันที่ 16 กุมภาพันธ์ 2561 ที่ผ่านมา
ทีมพัฒนาภาษา  ส่วนพวก Library อื่น ๆ ที่เปลี่ยนก็เช่น
ส่วนพวก Library อื่น ๆ ที่เปลี่ยนก็เช่น

 โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่
โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่

 สัปดาห์ที่ผ่านมามีโอกาสสอนและแบ่งปัน
เรื่อง
สัปดาห์ที่ผ่านมามีโอกาสสอนและแบ่งปัน
เรื่อง