![]()
![]() จาก Part ที่ 1
จาก Part ที่ 1 นั้นเริ่มด้วยการทดสอบระบบ web ด้วย library ชื่อว่า Enzyme
ซึ่งจะจำลองการทำงานของ React component ขึ้นมาให้
เราได้ทำการติดตั้ง configuration ตลอดจนเริ่มเขียนชุดการทดสอบแรกไปแล้ว
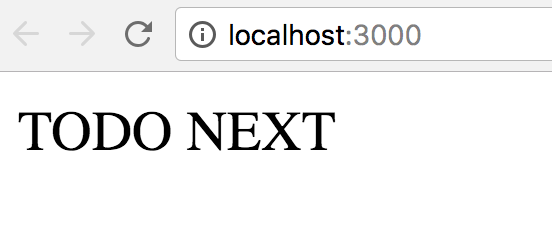
ใน Part 2 นี้จะเริ่มพัฒนาระบบเครื่องคิดเลขกัน
โดยจะพยายามเริ่มด้วยชุดการทดสอบ
หรือคิดก่อนว่าเราจะทำอะไร และ ต้องได้อะไรออกมา
แน่นอนว่ายังคงใช้ Enzyme นั่นเอง
มาเริ่มกันดีกว่า
สิ่งที่ต้องคิดและออกแบบก่อนคือ เครื่องคิดเลขของเราเป็นอย่างไร ?
ทั้ง feature และหน้าตาของระบบ
เพื่อความง่ายของระบบเลยให้มีความสามารถดังนี้
- มีช่อง input ให้ใส่ 2 ตัว
- สามารถเลือกบวก ลบ คูณและหารได้
- แสดงผลของการทำงาน
ดังนั้นเรามาเริ่มกันดีกว่า
ขั้นตอนที่ 1 ในหน้าจอการทำงานของเครื่องคิดเลข ต้องมีอะไรบ้าง ?
- ต้องมี form 1 form
- ต้องมีช่องให้กรอกตัวเลข 2 ช่อง
- ต้องมีปุ่มให้กดคือ บวก ลบ คูณหาร นั่นคือ 4 ปุ่ม
- ต้องมีที่ว่างสำหรับการแสดงผลลัพธ์
คิดอะไรไม่ออกเขียนชุดการทดสอบก่อนเลย
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="test_01.js"]
แน่นอนว่าผลการทดสอบต้องไม่ผ่านอย่างแน่นอน
ดังนั้นเริ่มเขียน code เพื่อให้ชุดการทดสอบผ่าน
ตรงนี้ก็เอาที่สบายใจนะครับ ว่าจะสวยงามกันอย่างไร
สำหรับผมก็เขียนง่าย ๆ แบบนี้เพื่อให้ผ่านก็พอ
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="1.js"]
หลังจากที่ชุดการทดสอบแรกผ่านไปแล้ว
คำถามที่ใครหลาย ๆ คนน่าจะคิดคือ
ชุดการทดสอบนี้มันไม่น่าเชื่อถือเลยนะ ?
เนื่องจากทำการตรวจสอบแบบหลวม ๆ มาก
คำตอบคือ ใช่แล้ว
นั่นคือสิ่งที่นักพัฒนาต้องเพิ่มชุดการทดสอบ
เพื่อทำให้เรามีความมั่นใจขึ้น
ดังนั้นนักพัฒนาทั้งหลายลองหยุดคิดหน่อยสิว่า
ต้องเพิ่มชุดการทดสอบอะไรบ้าง
เน้นว่า เพื่อทำให้มั่นใจหน้าแรกของเครื่องคิดเลขนะ
ยังไม่ต้องมี action หรือ event อะไรเลย
จากนั้นก็ลงมือทำกันเลยนะ
ผมมั่นใจว่า ทุก ๆ คนจะมีชุดการทดสอบที่แตกต่างกัน
ดังนั้นอย่าลืมเอามา share กันนะ
ขั้นตอนที่ 2 เมื่อการแสดงผลเรามั่นใจแล้ว มาถึงการทำงานหลักกัน
ซึ่งมีเรื่องหลัก ๆ ให้คิดคือจะทดสอบอะไรดี
ในตอนนี้มี 2 ส่วนงานคือ
ส่วนที่ 1 การคำนวณบวก ลบ คูณและหาร นั่นคือ Unit test ปกติ
ส่วนที่ 2 การทดสอบกรอกข้อมูลผ่าน form จากนั้นเลือกการคำนวณและแสดงผลด้วย Enzyme
ในตอนนี้เรากำลังฝึกเชียนชุดการทดสอบ
ดังนั้นเขียนมันไปทั้งคู่เลยดีกว่า
เริ่มจากการเขียน Unit test ของการบวก ลบ คูณและหารกันก่อน
จะเขียนบวกให้ดูกันก่อน
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="test_02.js"]
ผลที่ได้จากการทดสอบคือ พังสิครับ !!
เพราะว่า function plus() มันยังไม่มี
ดังนั้นก็ทำการสร้างมันขึ้นมาและเขียน logic การทำงานดังนี้
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="2.js"]
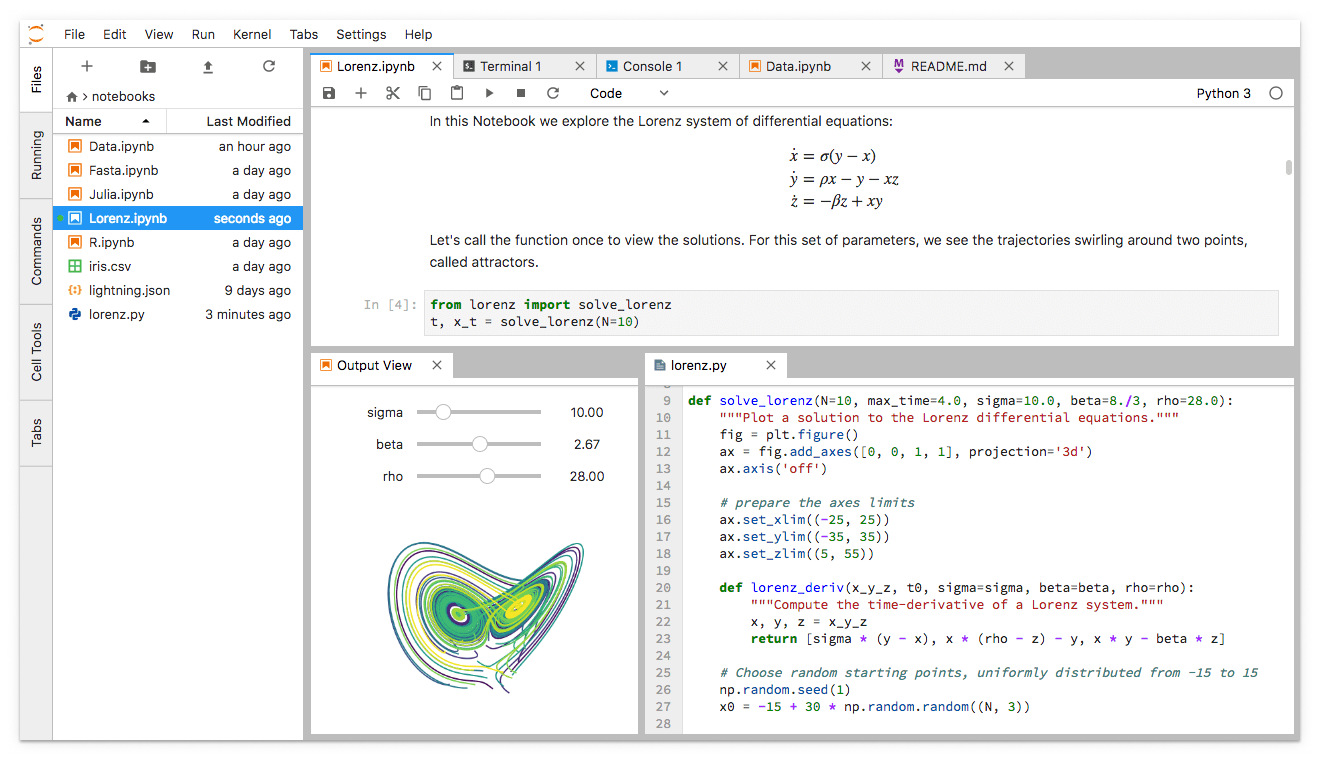
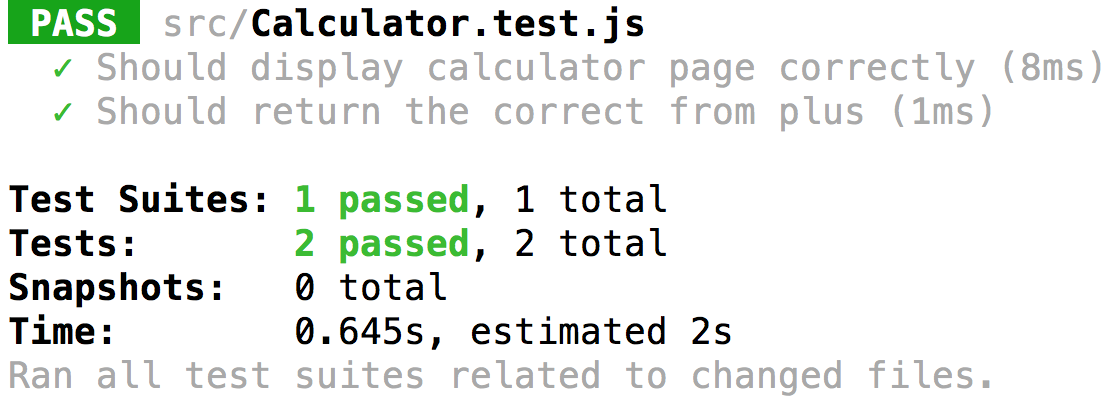
ในตอนนี้เราก็จะมีชุดการทดสอบ 2 ตัวแล้วนะ
![]()
สิ่งที่ทุกคนต้องทำเพิ่มคือ ลบ คูณ หาร นะครับ
ให้ระวังตรงหารด้วยนะ เพราะว่า หารด้วยคูณไม่ได้นะครับ !!
ลงมือทำกันได้เลยนะ
เมื่อเรียบร้อยแล้ว เรามาทดสอบการทำงานของ Calculator component ด้วย Enzyme กัน
เป็นการทดสอบมุมมองของคนใช้งานนั่นคือ
- ทำการกรอกข้อมูลตัวเลข 2 ตัว
- ทำการเลือกว่าจะทำอะไรระหว่าง บวก ลบ คูณ หาร นั่นคือการกดปุ่ม
- แสดงผลการทำงาน
มาเริ่มเขียนชุดการทดสอบดีกว่า ทำสักตัวให้ดูคือ
การบวกเลข 1 กับ 2
แน่นอนว่าต้องแสดงผลเป็น 3 ดังนี้
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="test_03.js"]
สำหรับชุดการทดสอบนี้ บอกให้เราเริ่มพัฒนา React app แบบจริงจังแล้วนะ
ทั้งการจัดการข้อมูลของ input ทั้งสองตัว
ทั้งการดักจับ action ของการกดปุ่มบวก
ทั้งการใช้งาน state เพื่อจัดเก็บข้อมูลผลการบวก
ซึ่งถือว่ามีหลายสิ่งอย่างมาก ๆ
มาดูในแต่ละส่วนกัน
ส่วนที่ 1 คือ constructor สำหรับกำหนดค่าต่าง ๆ
ทั้ง state เริ่มต้น
ทั้ง element ต่าง ๆ
ทั้ง function สำหรับการดักจับ event ของการกดปุ่ม
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="3_1.js"]
ส่วนที่ 2 คือส่วนของ function เมื่อทำการกดปุ่มบวก คือ onPlus()
จะทำการแปลง input มาอยู่ในตัวเลขฐานสิบ
จากนั้นทำการเรียกใช้งานการบวกเลขที่เขียนไว้ก่อนหน้าแล้ว
เมื่อได้ผลลัพธ์จะทำการ update ค่าใน state ดังนี้
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="3_2.js"]
ส่วนที่ 3 คือส่วนการแสดงผลนั่นเอง
[gist id="14c1928deed2f1adb94bcad4a834d7f2" file="3_3.js"]
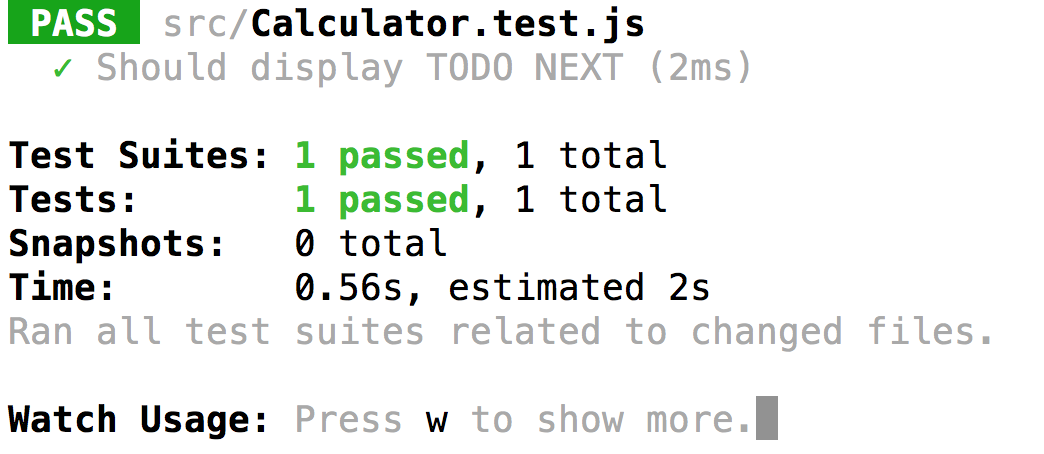
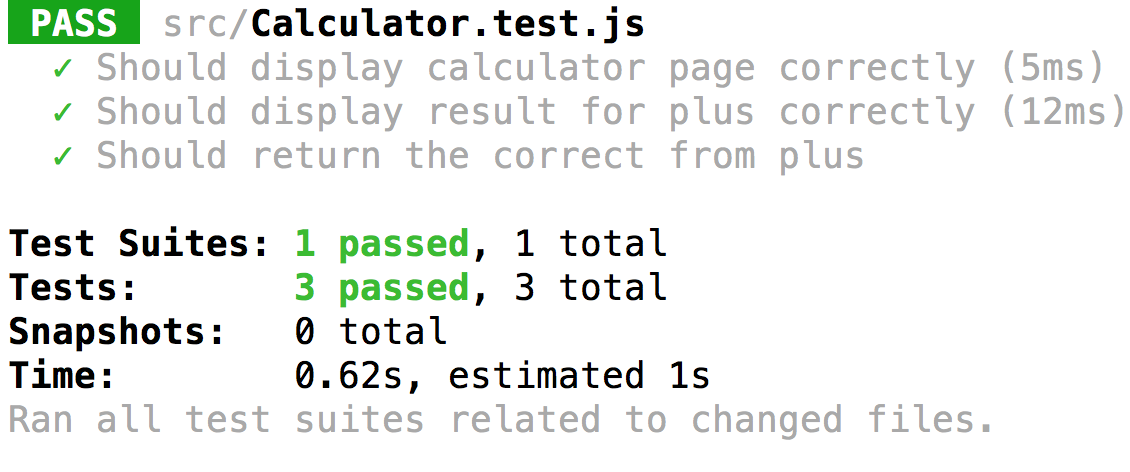
ในส่วนนี้ต้องค่อย ๆ ทำไปทีละขั้นตอนนะ
แล้วจะได้ผลการทดสอบดังนี้
![]()
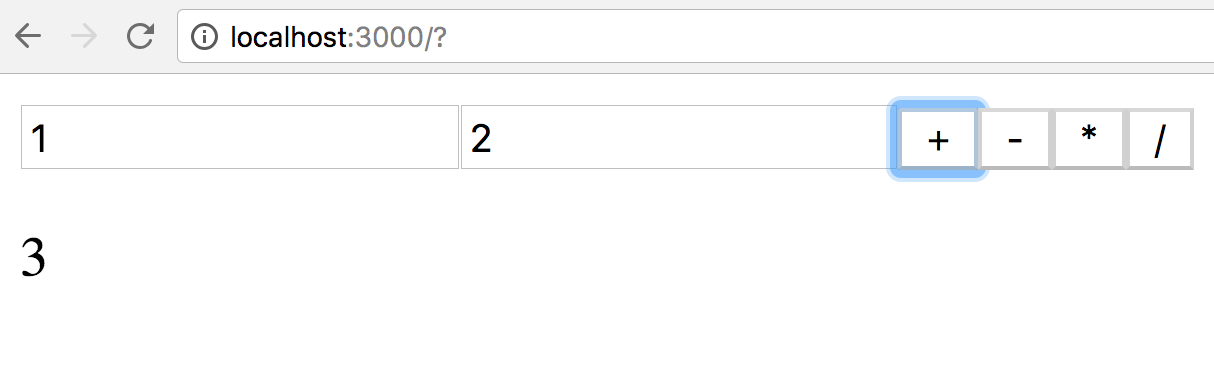
เมื่อผ่านแล้ว ลองเพิ่มชุดการทดสอบของ ลบ คูณและหารดูนะครับ
ผลการทำงานของระบบที่สร้าง หน้าตาง่าย ๆ แบบนี้
![]()
จะเห็นได้ว่า ชุดการทดสอบจะช่วยสร้างความมั่นใจในการพัฒนาระบบให้เรา
แต่กว่าจะมั่นใจได้ ก็ต้องใช้เวลาสำหรับการเรียนรู้วิธีการสักพัก
แต่คิดว่า ไม่น่ายากเท่าไร ต้องฝึก และ ฝึก และ ฝึก เท่านั้น
ปล. สังเกตไหมว่า เวลาในการทดสอบของแต่ละชุดการทดสอบมันแตกต่างกัน
นั่นคือสิ่งที่ต้องพึงระวังเมื่อจำนวนชุดการทดสอบเยอะขึ้น
มิเช่นนั้นการทดสอบจะใช้เวลานานมาก ๆ
ใน Part ต่อไปเราจะมาลองทดสอบรูปแบบอื่น ๆ กันบ้างนะ
ค่อย ๆ ทำ ค่อย ๆ เรียนรู้กันไปครับ
Code ตัวอย่างอยู่ที่
Github::Up1::Workshop React Testing
ขอให้สนุกกับการ coding ครับ

 คำถามที่น่าสนใจสำหรับการใช้งาน git คือ
มี branch เยอะไหม ?
มีปัญหาเกี่ยวกับการใช้ branch ไหม ?
code ปัจจุบันที่ branch ไหน ?
มีปัญหาในการ merge code ไหม ?
หลายคนพยายามหาเครื่องมือช่วยเหลือ
แต่ต้นเหตุของปัญหาคือ
branch ที่สร้างขึ้นมามากมายนั่นเอง
ที่สำคัญมักจะมี branch จำนวนมากที่ไม่ถูกใช้งาน
ดังนั้นควรหัดลบ branch ที่ไม่ใช้งานกันหน่อยไหม ?
เช่นลบ remote branch
[code]
$git remote prune origin
[/code]
เช่นลบ local branch ที่ merge เข้าไปยัง master หรือ develop branch
[code]
$git branch --merged | grep -E -v "master|develop" | xargs git branch -d
[/code]
เพื่อความสะดวกก็สร้าง alias ซะ
[code]
[alias]
po = !git remote prune origin
dm = !git branch --merged | grep -E -v \"master|develop\" | xargs git branch -d
[/code]
เพียงเท่านั้น น่าจะทำให้ชีวิตดีขึ้นมาบ้าง
อะไรที่ไม่ได้ใช้งาน ก็ลบไปเถอะนะ
ไม่ต้องเสียดายหรอก
คำถามที่น่าสนใจสำหรับการใช้งาน git คือ
มี branch เยอะไหม ?
มีปัญหาเกี่ยวกับการใช้ branch ไหม ?
code ปัจจุบันที่ branch ไหน ?
มีปัญหาในการ merge code ไหม ?
หลายคนพยายามหาเครื่องมือช่วยเหลือ
แต่ต้นเหตุของปัญหาคือ
branch ที่สร้างขึ้นมามากมายนั่นเอง
ที่สำคัญมักจะมี branch จำนวนมากที่ไม่ถูกใช้งาน
ดังนั้นควรหัดลบ branch ที่ไม่ใช้งานกันหน่อยไหม ?
เช่นลบ remote branch
[code]
$git remote prune origin
[/code]
เช่นลบ local branch ที่ merge เข้าไปยัง master หรือ develop branch
[code]
$git branch --merged | grep -E -v "master|develop" | xargs git branch -d
[/code]
เพื่อความสะดวกก็สร้าง alias ซะ
[code]
[alias]
po = !git remote prune origin
dm = !git branch --merged | grep -E -v \"master|develop\" | xargs git branch -d
[/code]
เพียงเท่านั้น น่าจะทำให้ชีวิตดีขึ้นมาบ้าง
อะไรที่ไม่ได้ใช้งาน ก็ลบไปเถอะนะ
ไม่ต้องเสียดายหรอก

 วันนี้ทำการ review code ภาษา Java
ได้เห็นรูปแบบการเขียน code แปลก ๆ หลายอย่าง
แน่นอนว่า สิ่งเหล่านั้นสามารถเขียนได้หลายแบบ
บางรูปแบบมันน่าสนใจมาก ๆ
ลองมาดูกันหน่อย
วันนี้ทำการ review code ภาษา Java
ได้เห็นรูปแบบการเขียน code แปลก ๆ หลายอย่าง
แน่นอนว่า สิ่งเหล่านั้นสามารถเขียนได้หลายแบบ
บางรูปแบบมันน่าสนใจมาก ๆ
ลองมาดูกันหน่อย

 มาลองใช้งานกันครับ น่าใช้มาก ๆ
อีกไม่นานจะออก version 1.0
ซึ่งน่าจะค่อย ๆ เข้ามาแทนที่ Jupyter เดิม
อีกอย่างเราสามารถพัฒนา extension เข้าไปได้อีกด้วย
ไปดู
มาลองใช้งานกันครับ น่าใช้มาก ๆ
อีกไม่นานจะออก version 1.0
ซึ่งน่าจะค่อย ๆ เข้ามาแทนที่ Jupyter เดิม
อีกอย่างเราสามารถพัฒนา extension เข้าไปได้อีกด้วย
ไปดู 
 สิ่งที่น่าสนใจอย่างหนึ่งของนักพัฒนา software คือ
มักจะพัฒนาให้มันเสร็จตามเวลา
ส่วนเรื่องของความถูกต้องและคุณภาพก็ให้ความสำคัญนะ
แต่ไม่ค่อยเน้นมากเท่าไร !!
บ่อยครั้งกลับพบว่า
จำนวนข้อผิดพลาดจำนวนมากจากการพัฒนา
จากสิ่งที่บอกว่าเสร็จแล้ว
เป็นประเด็นที่น่าสนใจคือ
สิ่งที่นักพัฒนาบอกว่า เสร็จมันคืออะไรกันแน่ ?
บางครั้งสิ่งที่มีปัญหากลับไม่ใช่สิ่งที่นักพัฒนาสร้าง
แต่กว่าจะหาจุดหรือต้นเหตุของปัญเจอ
ต้องใช้เวลานานมาก ๆ (Debugging)
ส่วนเวลาในการแก้ไขก็เยอะตามเวลาที่กว่าจะหาเจอ (Mean Time To Recover/Detection)
สิ่งที่น่าสนใจอย่างหนึ่งของนักพัฒนา software คือ
มักจะพัฒนาให้มันเสร็จตามเวลา
ส่วนเรื่องของความถูกต้องและคุณภาพก็ให้ความสำคัญนะ
แต่ไม่ค่อยเน้นมากเท่าไร !!
บ่อยครั้งกลับพบว่า
จำนวนข้อผิดพลาดจำนวนมากจากการพัฒนา
จากสิ่งที่บอกว่าเสร็จแล้ว
เป็นประเด็นที่น่าสนใจคือ
สิ่งที่นักพัฒนาบอกว่า เสร็จมันคืออะไรกันแน่ ?
บางครั้งสิ่งที่มีปัญหากลับไม่ใช่สิ่งที่นักพัฒนาสร้าง
แต่กว่าจะหาจุดหรือต้นเหตุของปัญเจอ
ต้องใช้เวลานานมาก ๆ (Debugging)
ส่วนเวลาในการแก้ไขก็เยอะตามเวลาที่กว่าจะหาเจอ (Mean Time To Recover/Detection)

 เห็นมีการพูดถึง
เห็นมีการพูดถึง 
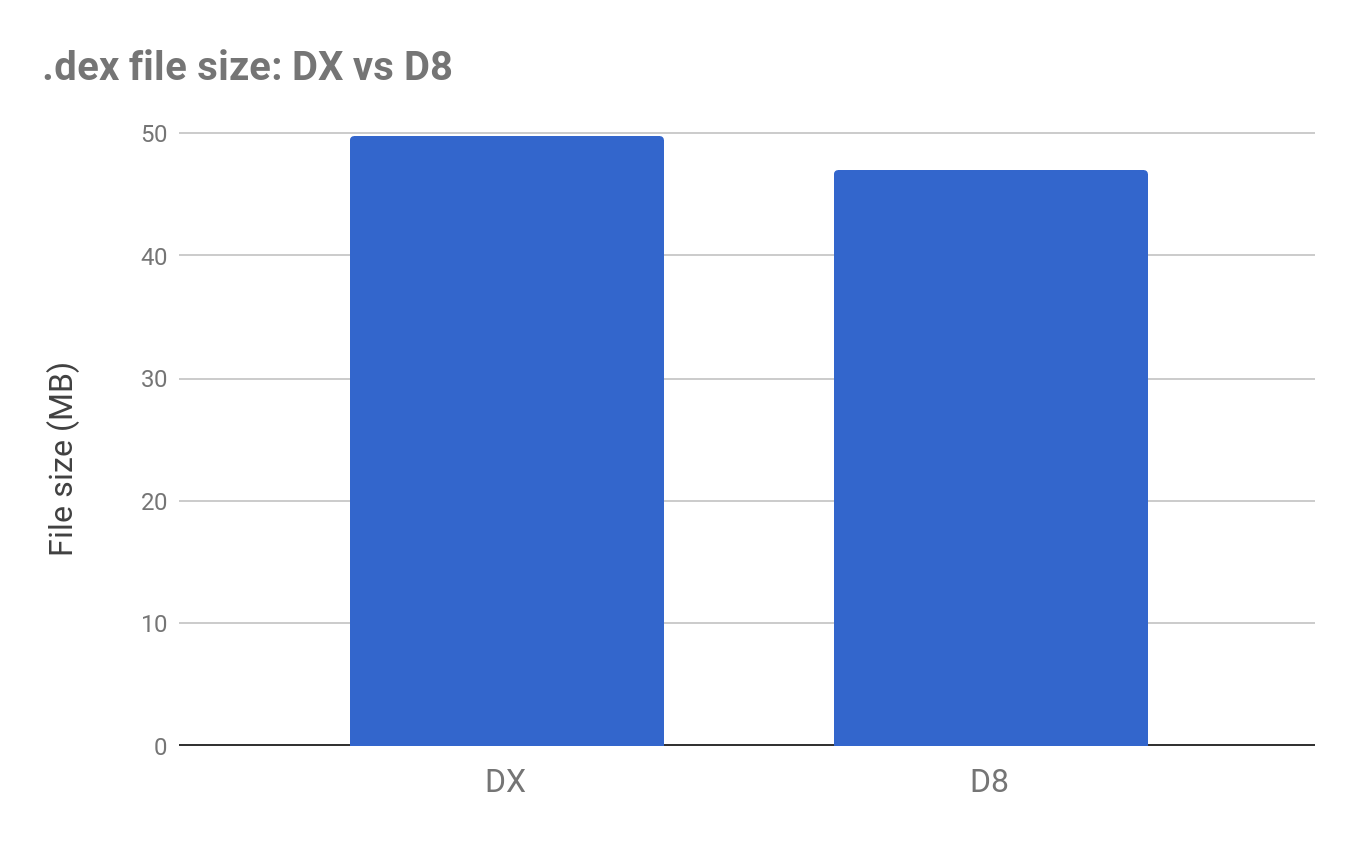
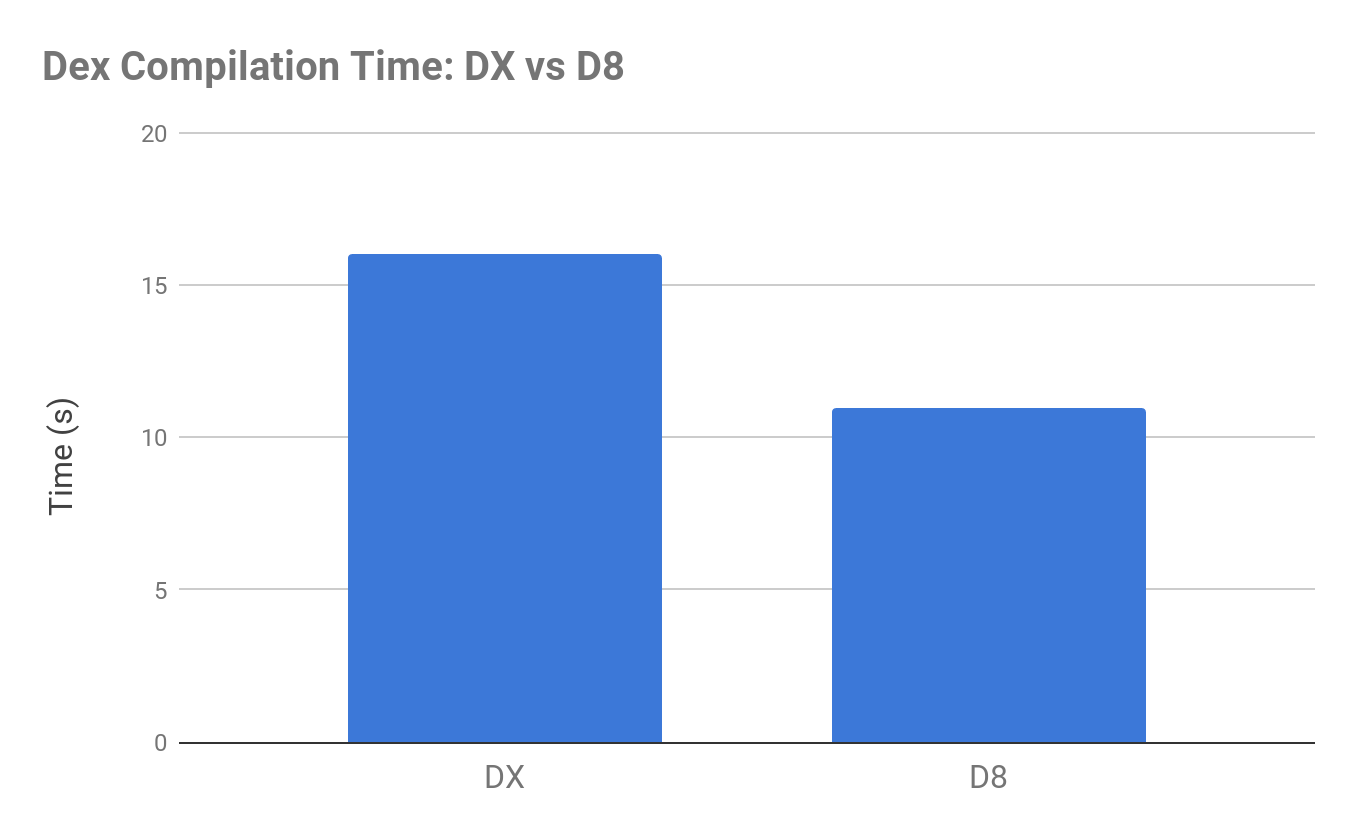
 ปัญหาอย่างหนึ่งของการพัฒนา Android app คือ การทดสอบ
แต่เมื่อเขียนชุดการทดสอบแล้ว มักจะมีการเปิดให้ทำ Code coverage เสมอ
ซึ่งเครื่องมือที่ใช้คือ Jacoco
แต่ปัญหาที่ตามมาจากการเปิดให้ทำ Code coverage คือ ความช้าของการ build
ดังนั้นเรามาเปิดหรือปิดความสามารถนี้กันหน่อย
ปัญหาอย่างหนึ่งของการพัฒนา Android app คือ การทดสอบ
แต่เมื่อเขียนชุดการทดสอบแล้ว มักจะมีการเปิดให้ทำ Code coverage เสมอ
ซึ่งเครื่องมือที่ใช้คือ Jacoco
แต่ปัญหาที่ตามมาจากการเปิดให้ทำ Code coverage คือ ความช้าของการ build
ดังนั้นเรามาเปิดหรือปิดความสามารถนี้กันหน่อย

 ใน Spring Boot 2.0.0.RELEASE นั้น
ได้เปลี่ยนรูปแบบของ Metric ของ service จาก Actuator ไปยัง Micrometer
ซึ่งแน่นอนว่า การใช้งานก็เปลี่ยนไปพอควร
ดังนั้นมาลองใช้งาน
ใน Spring Boot 2.0.0.RELEASE นั้น
ได้เปลี่ยนรูปแบบของ Metric ของ service จาก Actuator ไปยัง Micrometer
ซึ่งแน่นอนว่า การใช้งานก็เปลี่ยนไปพอควร
ดังนั้นมาลองใช้งาน 
 ตอนเช้าได้อ่าน
ตอนเช้าได้อ่าน


 เนื่องจากทีมสอนมีแนวความคิดว่า
น่าจะลองเปลี่ยนโจทย์ของการทำ workshop กันหน่อย
ซึ่งจัดที่
เนื่องจากทีมสอนมีแนวความคิดว่า
น่าจะลองเปลี่ยนโจทย์ของการทำ workshop กันหน่อย
ซึ่งจัดที่ 
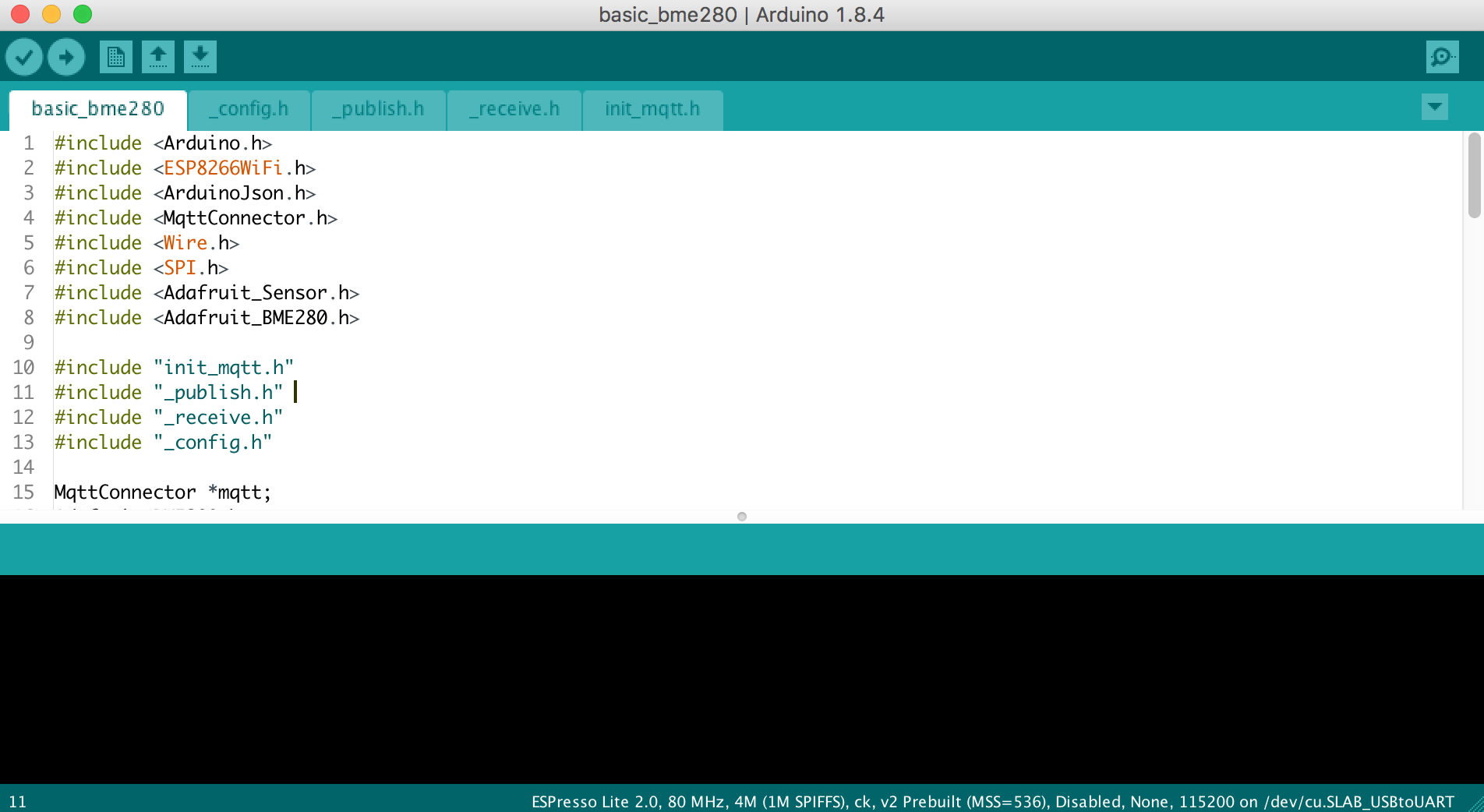 โดยในขั้นตอนนี้เองที่ต้องเดินทางมายังเชียงใหม่
เพื่อให้ทาง Nat ช่วยสอน และ แนะนำการใช้งานและพัฒนาสำหรับการใช้งานเบื้องต้น
เป็นการเปิดหูเปิดตาทางด้าน hardware และ IoT มากมาย
ภาษาที่ใช้งานก็เป็นภาษา C นั่นเอง
โดยในขั้นตอนนี้เองที่ต้องเดินทางมายังเชียงใหม่
เพื่อให้ทาง Nat ช่วยสอน และ แนะนำการใช้งานและพัฒนาสำหรับการใช้งานเบื้องต้น
เป็นการเปิดหูเปิดตาทางด้าน hardware และ IoT มากมาย
ภาษาที่ใช้งานก็เป็นภาษา C นั่นเอง
 แต่งานก็ง่ายขึ้นมาอีก
เนื่องจากทาง Nat ได้เขียนโปรแกรมตัวอย่าง
สำหรับการใช้งาน board ให้ไว้แล้ว
ทั้งการดึงข้อมูลจาก sessor
ทั้งการติดต่อผ่าน WIFI เพื่อให้สามารถส่งข้อมูลเข้าหรือออกจาก board ได้ง่ายขึ้น
ตัวอย่างของ source code
[gist id="59450956c0afc1037c4a4a11142276ca" file="hello.c"]
แต่งานก็ง่ายขึ้นมาอีก
เนื่องจากทาง Nat ได้เขียนโปรแกรมตัวอย่าง
สำหรับการใช้งาน board ให้ไว้แล้ว
ทั้งการดึงข้อมูลจาก sessor
ทั้งการติดต่อผ่าน WIFI เพื่อให้สามารถส่งข้อมูลเข้าหรือออกจาก board ได้ง่ายขึ้น
ตัวอย่างของ source code
[gist id="59450956c0afc1037c4a4a11142276ca" file="hello.c"]
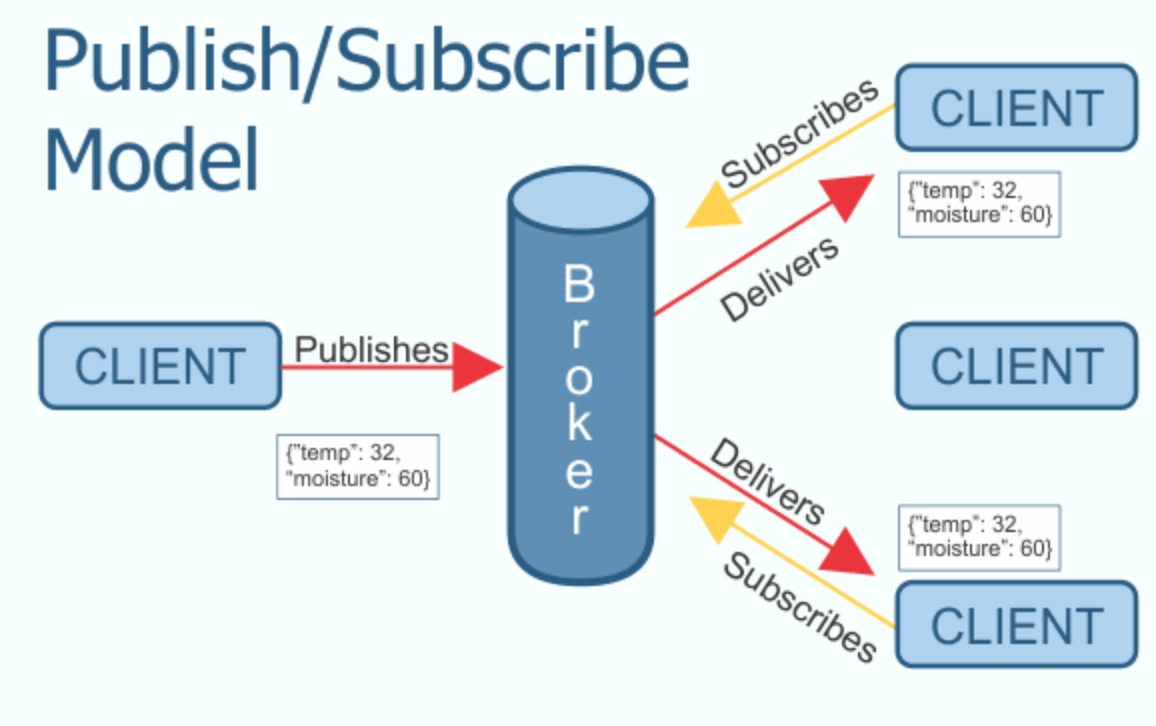 คำอธิบายง่าย ๆ
คำอธิบายง่าย ๆ


 มีโอกาสไปแบ่งปันเรื่องการทดสอบแบบอัตโนมัติสำหรับ Mobile app ทั้ง iOS และ Android
คำถามที่น่าสนใจคือ
ทุกวันนี้ Mobile app ที่พัฒนากันนั้น ทดสอบกันอย่างไร ?
ทดสอบด้วยคนหรือแบบอัตโนมัติเป็นหลัก ?
ถ้าทดสอบด้วยคน
คำถามต่อมาคือ ทดสอบทุก ๆ feature ไหม ?
มีโอกาสไปแบ่งปันเรื่องการทดสอบแบบอัตโนมัติสำหรับ Mobile app ทั้ง iOS และ Android
คำถามที่น่าสนใจคือ
ทุกวันนี้ Mobile app ที่พัฒนากันนั้น ทดสอบกันอย่างไร ?
ทดสอบด้วยคนหรือแบบอัตโนมัติเป็นหลัก ?
ถ้าทดสอบด้วยคน
คำถามต่อมาคือ ทดสอบทุก ๆ feature ไหม ?

 Code ที่เราเขียนเองมันดีสุด ๆ แล้ว
เป็นแนวคิดที่อันตรายมาก ๆ
มันจะเป็นสิ่งที่ขัดขวางการพัฒนาของเราเอง
เพราะว่ามันทำให้เราคิดว่า ไม่มีอะไรให้เรียนรู้อีกแล้ว
ดังนั้นลด ego ของตัวเองลง
สนใจทีมงานให้มากกว่าสนใจตัวเอง
หิวกระหายในการเรียนรู้สิ่งใหม่ ๆ และพัฒนาตนเองอยู่อย่างเสมอ
ที่สำคัญต้องแบ่งปันไปสู่คนอื่นอีกด้วย
Code ที่เราเขียนเองมันดีสุด ๆ แล้ว
เป็นแนวคิดที่อันตรายมาก ๆ
มันจะเป็นสิ่งที่ขัดขวางการพัฒนาของเราเอง
เพราะว่ามันทำให้เราคิดว่า ไม่มีอะไรให้เรียนรู้อีกแล้ว
ดังนั้นลด ego ของตัวเองลง
สนใจทีมงานให้มากกว่าสนใจตัวเอง
หิวกระหายในการเรียนรู้สิ่งใหม่ ๆ และพัฒนาตนเองอยู่อย่างเสมอ
ที่สำคัญต้องแบ่งปันไปสู่คนอื่นอีกด้วย

 จากบทความเรื่อง
จากบทความเรื่อง
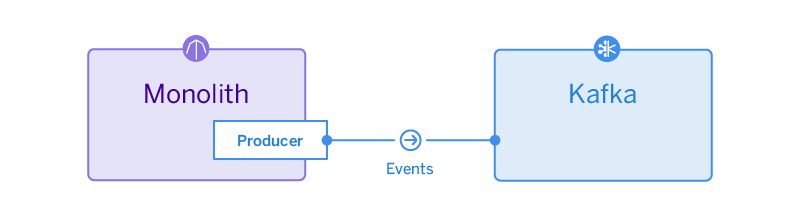
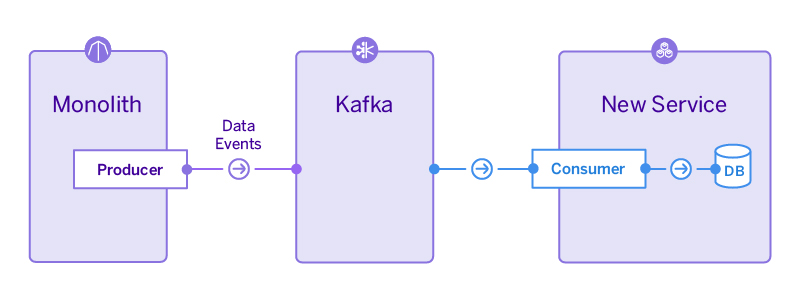
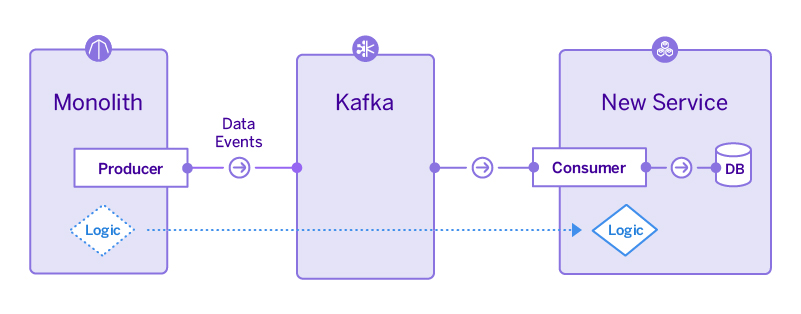
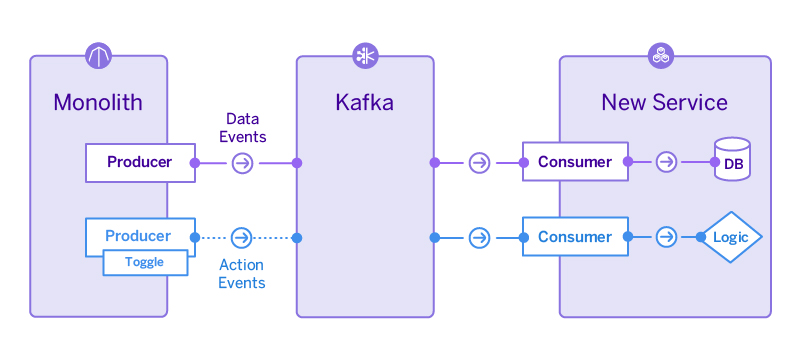
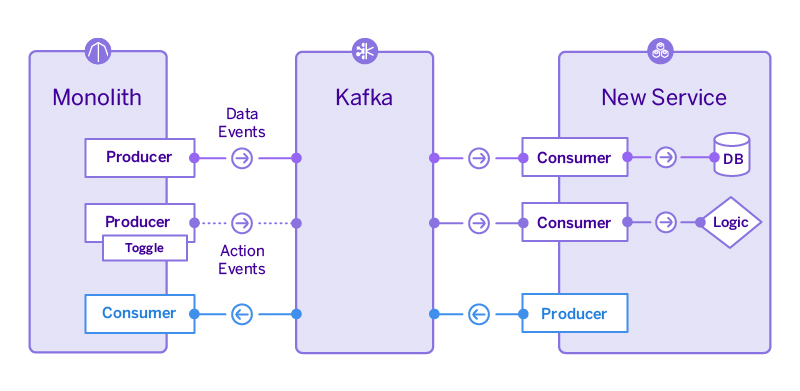

 เห็น
เห็น
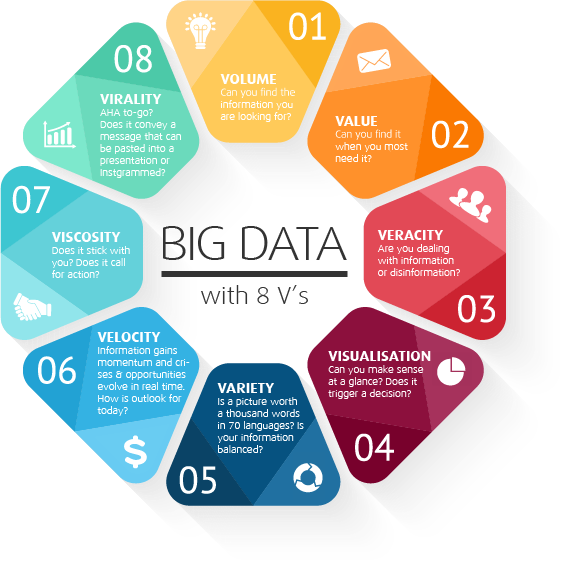
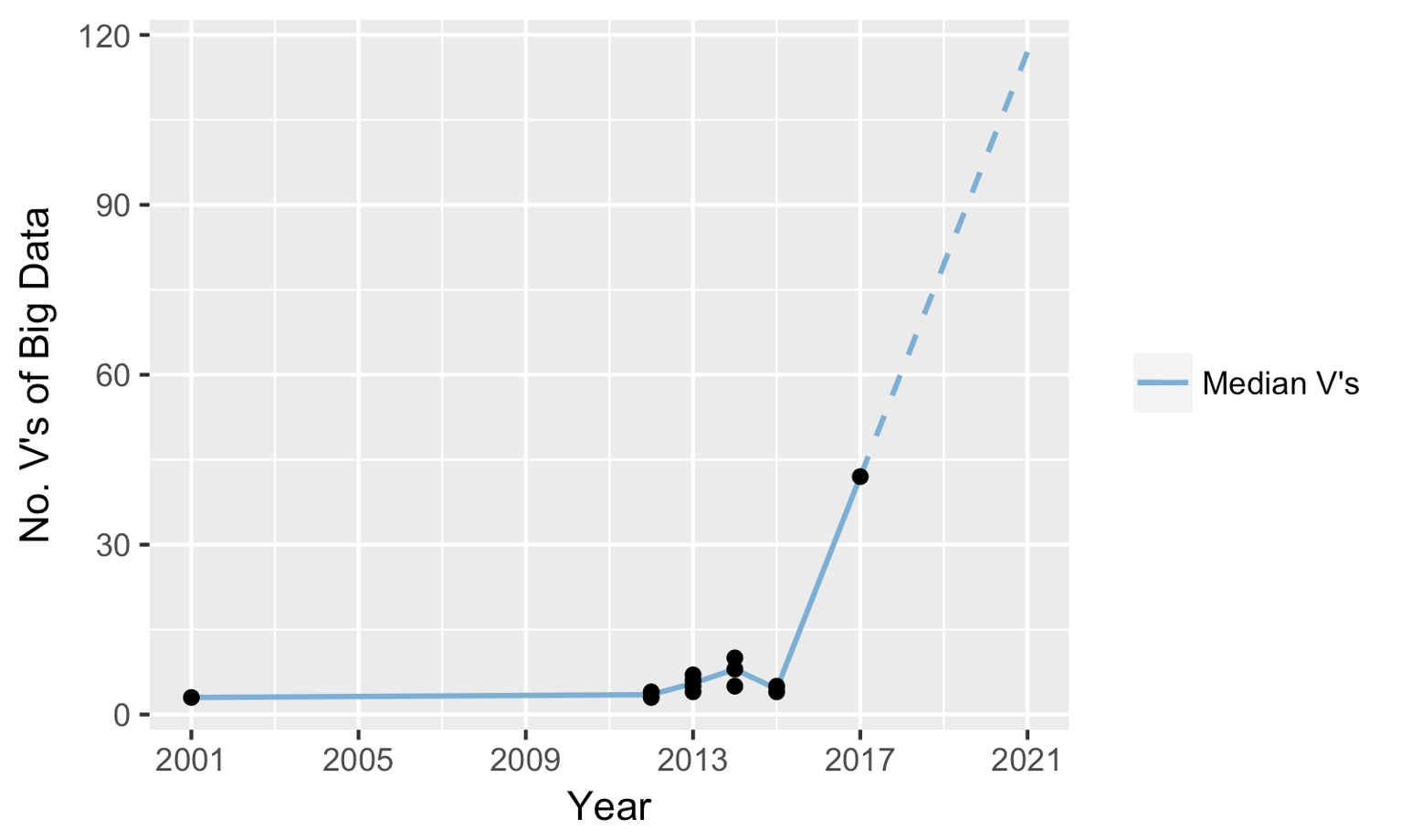

 ในการพัฒนา software นั้น การทดสอบเป็นสิ่งที่สำคัญมาก ๆ
เพื่อทำให้นักพัฒนามีความมั่นใจต่อการพัฒนา
แน่นอนว่า การทดสอบเหล่านั้นจำเป็นต้องทำงานแบบอัตโนมัติอีกด้วย
ในการพัฒนา software นั้น การทดสอบเป็นสิ่งที่สำคัญมาก ๆ
เพื่อทำให้นักพัฒนามีความมั่นใจต่อการพัฒนา
แน่นอนว่า การทดสอบเหล่านั้นจำเป็นต้องทำงานแบบอัตโนมัติอีกด้วย


 มีโอกาสไปแบ่งปันเรื่องการพัฒนา software
ซึ่งพยายามแนะนำการพัฒนาที่ขับเคลื่อนด้วยการทดสอบ
หมายถึงการขับเคลื่อนด้วยความเข้าใจในปัญหาก่อนที่จะลงมือทำ
ปัญหาก็เช่นกัน มันใหญ่เกินที่จะแก้ไขเพียงครั้งเดียวหรือไม่
หรือต้องทำการแบ่งเป็นปัญหาเล็ก ๆ
แล้วค่อย ๆ จัดการทีละปัญหา
เนื่องจากพบว่า ส่วนใหญ่แล้วเราจะลงมือทำทันที
ไม่ว่าเราจะเข้าใจปัญหาหรือไม่ก็ตาม
ไม่ว่าปัญหานั้นจะเล็กหรือใหญ่
ผลจากการทำคือ ปัญหาทั้งนั้น
ซึ่งอาจจะส่งผลกระทบหลาย ๆ อย่าง
ทั้งการทำงานที่ไม่ถูกต้องตามความต้องการ
ทั้งเป็นการแก้ไขปัญหาเฉพาะหน้า ไม่แก้ไขที่ต้นเหตุ
ทั้งสิ้นเปลืองเวลา คน และค่าใช้จ่ายอย่างมาก
มีโอกาสไปแบ่งปันเรื่องการพัฒนา software
ซึ่งพยายามแนะนำการพัฒนาที่ขับเคลื่อนด้วยการทดสอบ
หมายถึงการขับเคลื่อนด้วยความเข้าใจในปัญหาก่อนที่จะลงมือทำ
ปัญหาก็เช่นกัน มันใหญ่เกินที่จะแก้ไขเพียงครั้งเดียวหรือไม่
หรือต้องทำการแบ่งเป็นปัญหาเล็ก ๆ
แล้วค่อย ๆ จัดการทีละปัญหา
เนื่องจากพบว่า ส่วนใหญ่แล้วเราจะลงมือทำทันที
ไม่ว่าเราจะเข้าใจปัญหาหรือไม่ก็ตาม
ไม่ว่าปัญหานั้นจะเล็กหรือใหญ่
ผลจากการทำคือ ปัญหาทั้งนั้น
ซึ่งอาจจะส่งผลกระทบหลาย ๆ อย่าง
ทั้งการทำงานที่ไม่ถูกต้องตามความต้องการ
ทั้งเป็นการแก้ไขปัญหาเฉพาะหน้า ไม่แก้ไขที่ต้นเหตุ
ทั้งสิ้นเปลืองเวลา คน และค่าใช้จ่ายอย่างมาก

 อ่านเอกสารของ
อ่านเอกสารของ 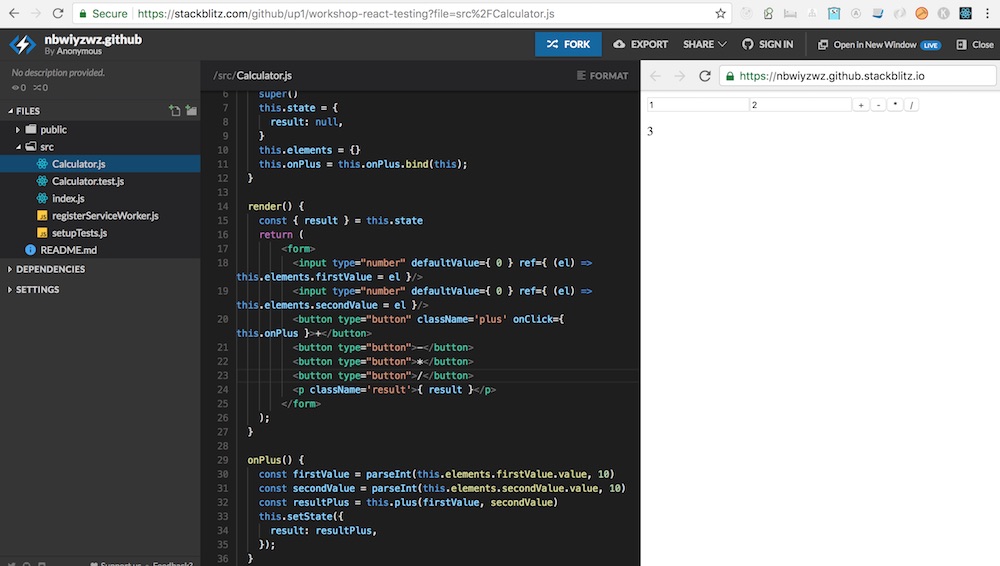 Reference Website
Reference Website

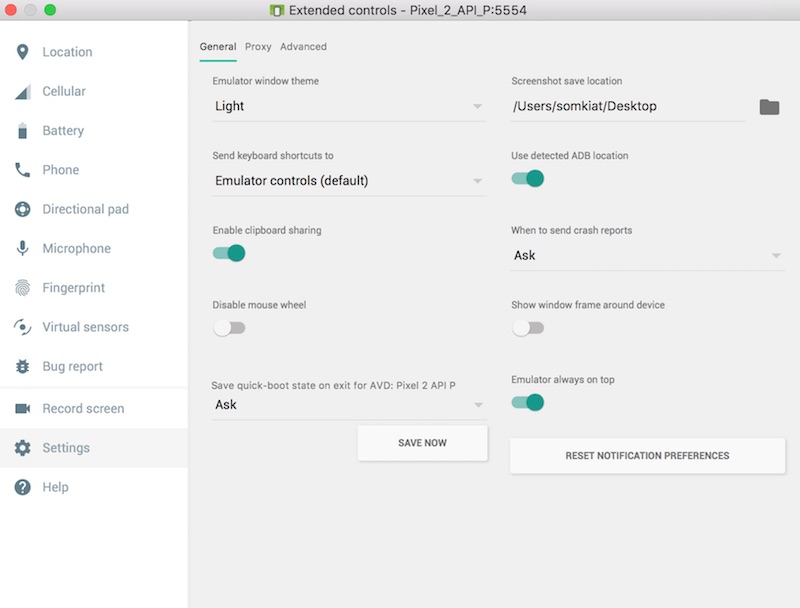 จากนั้นทำการปิด Emulator จะถามว่าต้องการบันทึกหรือไม่
จากนั้นทำการปิด Emulator จะถามว่าต้องการบันทึกหรือไม่
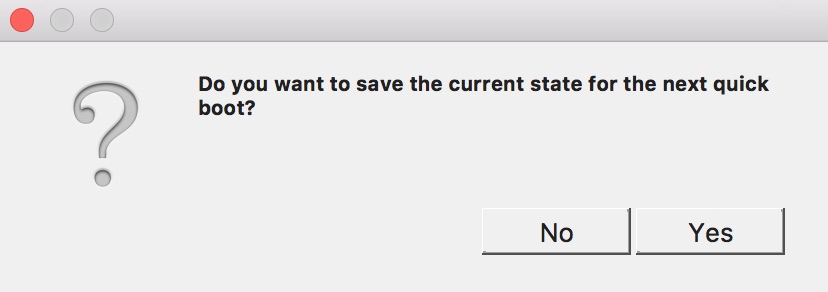 ถ้าตอบ Yes จะทำการบันทึก state ดังรูป
ถ้าตอบ Yes จะทำการบันทึก state ดังรูป
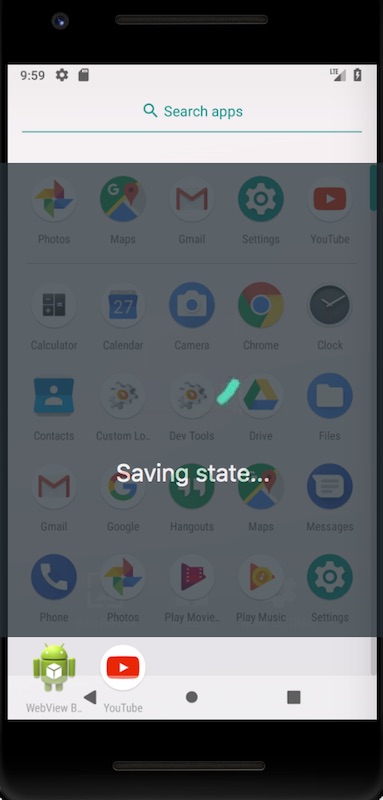 จากนั้นลองเปิด Emulator ขึ้นมาใหม่จะเร็วมาก
แต่เปลือง disk น่าดูเช่นเดิม
ส่วนการใช้ Memory ก็สูงกว่า Android Studio ไปแล้วนะ !!
จากนั้นลองเปิด Emulator ขึ้นมาใหม่จะเร็วมาก
แต่เปลือง disk น่าดูเช่นเดิม
ส่วนการใช้ Memory ก็สูงกว่า Android Studio ไปแล้วนะ !!
