![]()
![]()
จากบทความเรื่อง
Write a Kubernetes-ready service from zero step-by-step
ทำการสรุป workflow หรือขั้นตอนของการพัฒนาระบบ REST API ด้วยภาษา Go
เริ่มตั้งแต่การพัฒนา API แบบง่าย ๆ
จากนั้นทำการเพิ่มความสามารถที่จำเป็นต้องมีทั้ง logging, health check และ graceful shutdown
รวมไปถึงการ deploy ระบบงาน
ซึ่งในตัวอย่างจะทำการสร้าง Docker Image
และทำการ deploy ด้วย Kubernetes
จึงทำการแปลและสรุปในแบบที่เข้าใจไว้นิดหน่อย
มาเริ่มกันเลย
ขั้นตอนที่ 1 สร้างระบบ API แบบง่าย ๆ ด้วย Hello World
อย่าลืมทำการทดสอบว่า ทำงานได้ตามที่ต้องการด้วย
มี code ดังนี้
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="1.go"]
ขั้นตอนที่ 2 อย่าลืมการเขียน logging ของระบบ
ทำตั้งแต่เริ่มจะได้งาม ๆ
จะได้รู้ว่าควรหรือไม่ควรเขียนอะไร !!
มี library หรือ framework ให้ใช้เพียบเช่น log,
glog และ
logrus เป็นต้น
ตัวอย่างการเพิ่ม log ใน API แบบง่าย ๆ คือ
- การ start service
- service start เรียบร้อย
- service เกิด error ขึ้นมา
Code น่าจะดูดีขึ้นนะ
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="2.go"]
ขั้นตอนที่ 3 ทำการเพิ่ม router ของ API เข้าไป
ในระบบ API นั้นจะมี endpoint หรือของการทำงานจำนวนมาก
ซึ่งจะกำหนดไว้ในส่วนที่เรียกว่า
router
ถ้ายังทำใน package main หรือในไฟล์เดียว มันจะเยอะเกินไป
ทำให้ดูและและจัดการยาก
ดังนั้นแยกออกมาดีกว่า
ส่วนการพัฒนา router ของ API
ขึ้นอยู่ที่ความชอบว่าจะใช้ library หรือ framework อะไร เช่น
gorilla/mux เป็นต้น
หรือจะเขียนเองเด้วย package net/http ก็ได้ เอาที่สบายใจ
ในการเขียน code นั้นส่วนการจัดการ router ไม่น่าจะอยู่ใน package main นะ !!
ตรงนี้คือการแบ่งหน้าที่รับผิดชอบไปในแต่ละ package
ซึ่งเป็นแนวปฏิบัติที่ดี
ข้อดีคือแก้ไขและดูแลรักษาได้ง่าย
ใคร ๆ เขาก็ทำกันแบบนี้นะ ใช่หรือเปล่า ?
ดังนั้นในระบบของเราจะมี 2 package คือ
- package main สำหรับเริ่ม
- package handlers สำหรับจัดการเรื่องของ router
เริ่มด้วยการสร้างไฟล์ handlers.go สำหรับจัดการ router
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="3.go"]
ต่อมาสร้างไฟล์ home.go สำหรับทำงานในส่วนของ endpoint ชื่อว่า /home
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="4.go"]
จากนั้นทำการแก้ไข main.go เพื่อให้ไปใช้ router ที่สร้างขึ้นมา
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="5.go"]
ก่อนใช้งานก็ต้องติดตั้ง github.com/gorilla/mux ก่อนผ่าน go get !!
ขั้นตอนที่ 4 ว่าด้วยเรื่องของการจัดการ dependency หรือ library ต่าง ๆ
สำหรับระบบใหญ่ และ การทำงานเป็นทีม
สิ่งที่ควรมีคือ เครื่องมือในการจัดการ dependency หรือ library ต่าง ๆ ที่ใช้งาน
ซึ่งใน go นั้นมีให้ใช้เยอะมาก
ทั้งการเขียน shell/bat script กับการใช้ go get
ทั้งการใช้ตัวจัดการ dependency เช่น
dep และ
glide เป็นต้น
โดยในบทความจะใช้ dep ซึ่งติดตั้งไม่ยาก
สามารถใช้งานได้ง่าย ๆ ดังนี้
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="6.txt"]
เพียงเท่านี้ก็มีตัวจัดการ dependency แล้วนะ ง่ายมาก ๆ
ขั้นตอนที่ 5 อย่าลืมชุดการทดสอบ API
เพื่อความสบายใจ สิ่งที่ต้องทำคือ สร้างชุดการทดสอบของ API แรกขึ้นมา
การเริ่มต้นที่ดี มีชัยไปกว่าครึ่งนะครับ
มาเขียนชุดการทดสอบ API กัน
ข้อดีของ go คือมี package ชื่อว่า
httptest มาให้ใช้แล้วนะสิ
มาเขียนกันเถอะ
เริ่มด้วย test case ง่าย ๆ คือ success ไงละ
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="7.go"]
ขั้นตอนที่ 6 จัดการเรื่องของ configuration ของระบบ
ซึ่งจาก
The twelve-factor app นั้น
แนะนำให้ทำการแยก configuration ออกจาก code หรือระบบงานด้วย
นั่นคือให้ใส่ configuration ไว้ในแต่ละ environment แทน
จะเห็นได้ว่าใน code ตัวอย่าง
ทำการ hard code Port ไว้
ดังนั้นเราสามารถทำการเปลี่ยน port ของ API ไปไว้ใน environment variable
จากนั้นใน code ก็เปลี่ยนไปดึงจาก environment variable แทน
ทำให้ง่ายต่อการเปลี่ยนแปลงอีกด้วย ดังนี้
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="8.go"]
ขั้นตอนที่ 7 จัดการเรื่องของ Health check และความพร้อมของ API
เริ่มเข้าสู่เรื่องของ operation ต่าง ๆ ของการ deploy ระบบงาน
ในส่วนนี้ทำให้รู้ว่า API ยังมีชีวิตดีอยู่หรือไม่
ถ้าไม่ จะได้ทำการ restart service ใหม่ขึ้นมา
รวมทั้งยังตรวจสอบความพร้อมต่าง ๆ ของ API
เช่นถ้ามีการใช้ database แล้ว ถ้า API/service ไม่สามารถติดต่อ database ได้
ก็ให้ทำการนำ service นี้ออกไป หรือ ไม่ให้เข้าใช้งานเป็นต้น
ตัวอย่างของ health check ของ API
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="9.go"]
ขั้นตอนที่ 8 ว่าด้วยเรื่องของ Graceful shutdown
เมื่อต้องการที่จะลบหรือหยุดการทำงานของ API แล้ว
สิ่งที่ต้องทำคือ อย่าไปหยุดหรือขัดการทำงานของงานที่ยังทำไม่เสร็จ
ดังนั้นต้องรอจนไปกว่างานทั้งหมดจะทำงานเสร็จ
โดยที่ package http.Server ในภาษา go ตั้งแต่ version 1.8 ขึ้นมาสนับสนุน
แต่วิธีการเขียนจะยากนิดหน่อย
เพราะว่านำ go routine/channel มาใช้ด้วย
สามารถเขียนได้ดังนี้
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="10.go"]
มาถึงตรงนี้จะเห็นได้ว่า
ในการพัฒนาระบบ API นั้นจำเป็นต้องมีสิ่งต่าง ๆ มากกว่า feature นะครับ
ซึ่งทีมพัฒนาต้องให้ความสำคัญด้วยมาก ๆ
อย่าไปทำในช่วงท้าย หรือ ก่อนทำการ deploy
ให้คิด วางแผน และ ลงมือทำตั้งแต่เนิ่น ๆ
จะได้รู้และเข้าใจปัญหา เพื่อแก้ไขกันต่อไป
เข้าสู่ขั้นตอนการ build, ship และ run หรือการ deploy
โดยขั้นตอนเหล่านี้มักจะเรียกว่า Continuous Integration และ Continuous Delivery/Deployment
มาดูกันว่าเป็นอย่างไรบ้าง ?
ซึ่งในบทความจะใช้ Docker และ Kubernetes
มาเริ่มกันเลย
ขั้นตอนที่ 9 ทำการสร้าง Dockerfile เพื่อใช้สำหรับการสร้าง image สำหรับ deploy ต่อไป
เมื่อทุกอย่างพร้อมแล้ว
สิ่งที่ต้องกำหนดคือ กระบวนการ build -> test -> run ที่เป็นมาตรฐาน
เพื่อให้ทุก ๆ คนในทีมทำงานในรูปแบบเดียวกัน
อีกทั้งยังได้ artifact หรือ software package เอาไว้ deploy ต่อไป
ในส่วนนี้มีวิธีการมากมาย
ทั้ง shell/bat script
ทั้ง Makefile
ทั้ง manual process
แต่ในปัจจุบันสิ่งที่ได้รับความนิยมคือ Containerization
เครื่องมือที่ใช้คือ Docker
ดังนั้นเรามาทำการสร้าง Dockerfile เพื่อใช้สร้าง Docker Image กัน
เพื่อใช้ในการ deploy ต่อไป
สิ่งที่ต้องการคือ
- สร้าง Dockerfile
- ทำการ compile -> test -> build software package
- ทำการสร้าง image ไว้สำหรับการ deploy
ซึ่งเราสามารถใช้
Docker multi-stage build ได้
ยกตัวอย่างเช่น
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="Dockerfile"]
จะเห็นได้ว่า กระบวนการต่าง ๆ ทั้ง compile, test และ สร้าง software package อยู่ในนี้
ที่สำคัญ version ต่าง ๆ ของ software ถูกกำหนดไว้ชัดเจนอีกด้วย
ดังนั้นปัญหาน่าจะลดไปได้มาก
การใช้งานก็ง่ายมาก ๆ ดังนี้
[code]
$docker build -t api:1.0 .
$docker run --rm -p 8080:8080 api:1.0
[/code]
ตอนนี้เราได้ Docker Image ที่พร้อมเอาไป deploy แล้วนะ
ทั้งใช้ Docker (ในตัวอย่าง run ไปแล้ว)
ทั้งใช้ Docker Swarm
ทั้งใช้ Kubernetes
เอาที่สบายใจนะครับ
ขั้นตอนที่ 10 ทำการ deploy ระบบ API ด้วย Kubernetes
ในการ deploy ด้วย Kubernetes ต้องจัดเต็ม
ทั้ง service
ทั้ง deployment
ทั้ง ingress
ซึ่งสามารถทำการ configuration ได้ดังนี้
ซึ่งสามารถแยกไฟล์ หรือ รวมไฟล์ได้ประมาณนี้
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="tmp.yaml"]
เมื่อทุกอย่างพร้อม ทำการ deploy ด้วย Kubernetes
ในตัวอย่างจะใช้ minikube เพื่อให้ run แบบ local/stanalone ได้
และทดสอบซะ
[gist id="5d8a524111c8a6f453a3cbffb1190d07" file="11.txt"]
เพียงเท่านี้เราก็ได้ระบบ API แบบง่าย ๆ
ที่พัฒนาด้วยภาษา Go มีทั้ง logging, health check และ graceful shutdown
ไปจนถึงการสร้าง Docker Image และ deploy ด้วย Kubernetes อีกด้วย
น่าจะทำให้เห็น workflow หรือขั้นตอนการพัฒนาที่ดีกว่าเดิม
ขอให้สนุกกับการ coding ครับ
ปล. สิ่งที่ไม่ได้อธิบายคือ เรื่องของ versioning และ Makefile นะครับ

 อ่านไปเจอเรื่อง Test-Driven Bugfixing (TDB)
จากหนังสือ Test Driven Development for Embedded C
เป็นแนวทางที่น่าสนใจ
สำหรับการเขียนชุดการทดสอบแบบอัตโนมัติขึ้นมา
นักพัฒนาน่าจะลองนำไปใช้กันดูนะ
ปล. ผมชอบเรียกว่า Bug-Driven Development
อ่านไปเจอเรื่อง Test-Driven Bugfixing (TDB)
จากหนังสือ Test Driven Development for Embedded C
เป็นแนวทางที่น่าสนใจ
สำหรับการเขียนชุดการทดสอบแบบอัตโนมัติขึ้นมา
นักพัฒนาน่าจะลองนำไปใช้กันดูนะ
ปล. ผมชอบเรียกว่า Bug-Driven Development

 มีโอกาสไปแบ่งปันเรื่องของ DevOps มานิดหน่อย
มีหลายเรื่องที่น่าสนใจ
ทั้งแนวคิด ทั้งประโยชน์ ทั้งเครื่องมือต่าง ๆ
แต่สิ่งที่น่าสนใจคือ การนำไปประยุกต์ใช้งาน
บางที่ถึงขั้นตั้งเป็นนโยบายเลยเช่น DevOps transformation
ที่สำคัญถ้าไปฟังสัมมนาเกี่ยวกับ DevOps
จะไม่ค่อยมีการพูดถึงด้านแย่ ๆ เลย
มันแปลกดี
สงสัยคนเราชอบฟังแต่ด้านดี ๆ
ดังนั้น จึงขอนำอีกด้านหรืออีกมุมมองมาสรุปไว้หน่อย
เกี่ยวกับการนำ DevOps มาประยุกต์ใช้งาน
มีโอกาสไปแบ่งปันเรื่องของ DevOps มานิดหน่อย
มีหลายเรื่องที่น่าสนใจ
ทั้งแนวคิด ทั้งประโยชน์ ทั้งเครื่องมือต่าง ๆ
แต่สิ่งที่น่าสนใจคือ การนำไปประยุกต์ใช้งาน
บางที่ถึงขั้นตั้งเป็นนโยบายเลยเช่น DevOps transformation
ที่สำคัญถ้าไปฟังสัมมนาเกี่ยวกับ DevOps
จะไม่ค่อยมีการพูดถึงด้านแย่ ๆ เลย
มันแปลกดี
สงสัยคนเราชอบฟังแต่ด้านดี ๆ
ดังนั้น จึงขอนำอีกด้านหรืออีกมุมมองมาสรุปไว้หน่อย
เกี่ยวกับการนำ DevOps มาประยุกต์ใช้งาน

 ทาง
ทาง 
 จากบทความว่าด้วย
จากบทความว่าด้วย 

 ว่าง ๆ ลองไปดูภาษา Groovy พบสิ่งที่น่าสนใจคือ
สนับสนุนการพัฒนา Android app แล้วนะ (ตามจริงนานแล้วนะ)
โดยใช้ plugin ชื่อว่า
ว่าง ๆ ลองไปดูภาษา Groovy พบสิ่งที่น่าสนใจคือ
สนับสนุนการพัฒนา Android app แล้วนะ (ตามจริงนานแล้วนะ)
โดยใช้ plugin ชื่อว่า 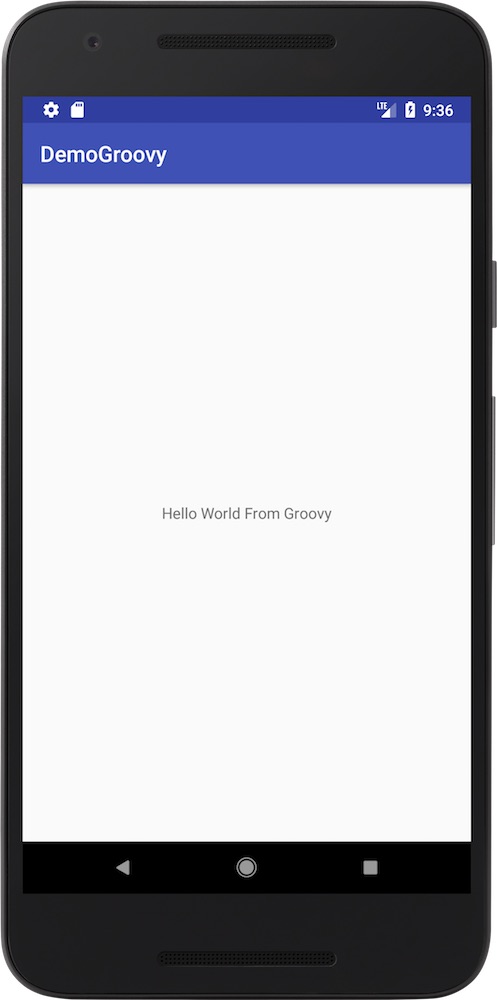

 เมื่อสิ้นปี 2017 เข้าสู่ปี 2018
ก็ต้องทำการสรุปสิ่งต่าง ๆ ในการเขียน blog ไว้หน่อย
ซึ่งมีตัวเลขที่น่าสนใจดังนี้
เมื่อสิ้นปี 2017 เข้าสู่ปี 2018
ก็ต้องทำการสรุปสิ่งต่าง ๆ ในการเขียน blog ไว้หน่อย
ซึ่งมีตัวเลขที่น่าสนใจดังนี้

 จากหนังสือ
จากหนังสือ 
 จากบทความใน
จากบทความใน
 หลังจากที่ดู VDO เรื่อง
หลังจากที่ดู VDO เรื่อง 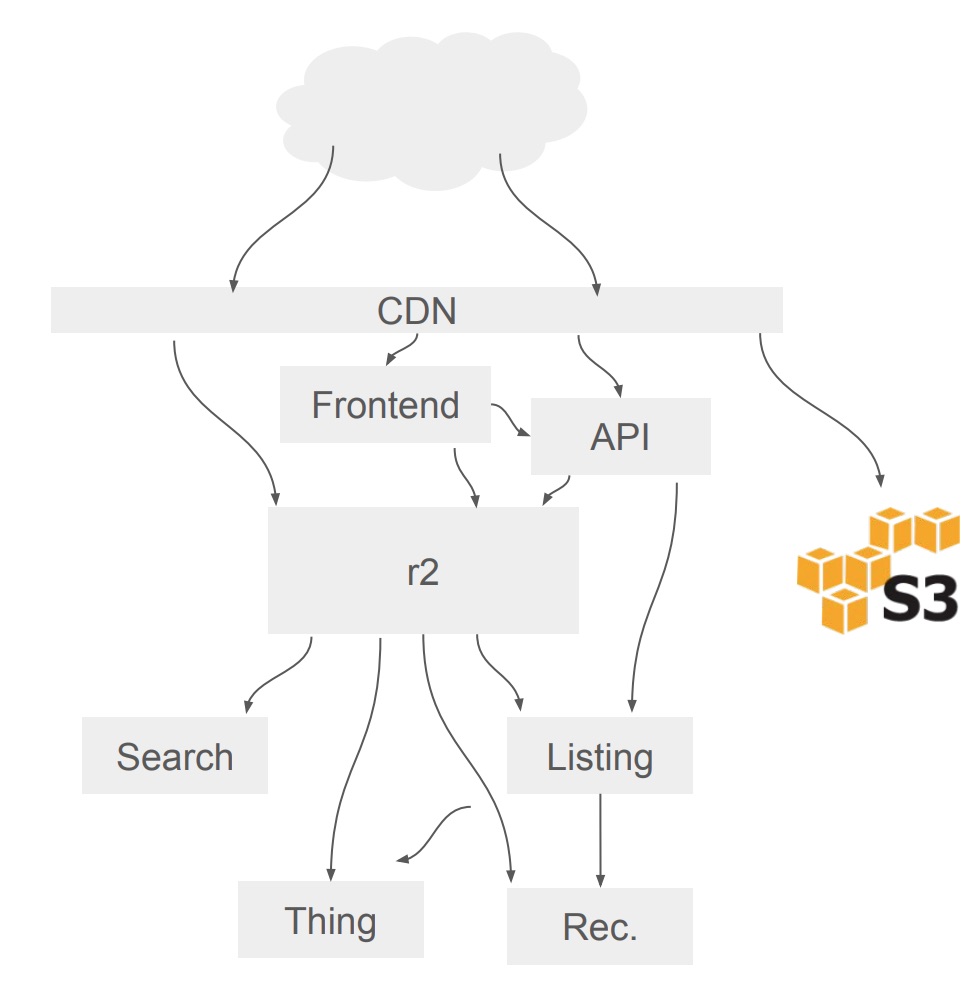 คำอธิบาย
คำอธิบาย
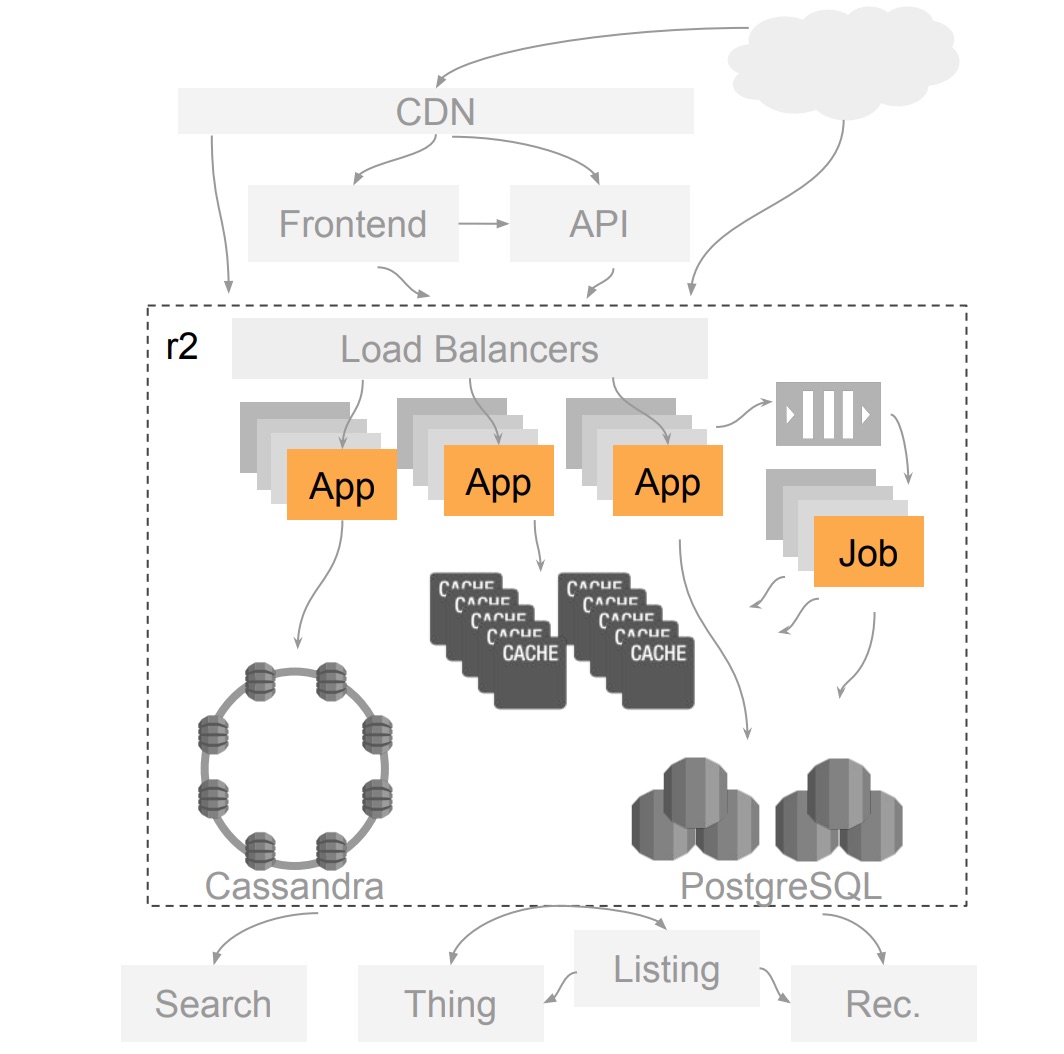
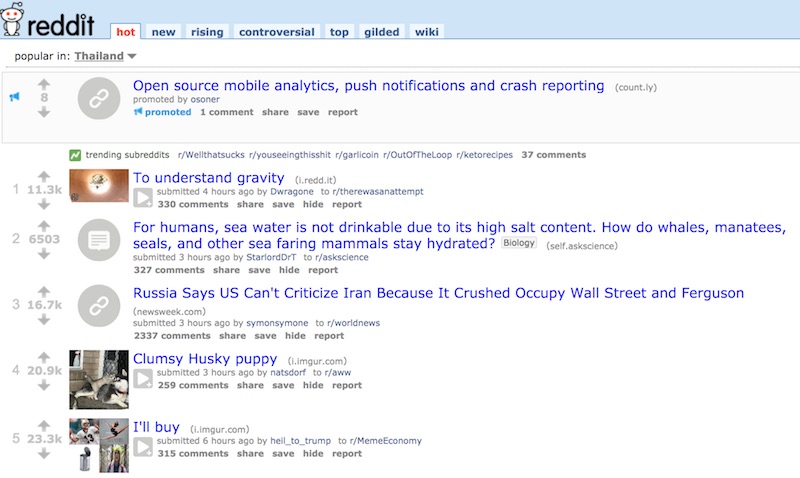 ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ถ้าเป็นคำสั่ง SQL ทั่วไปก็เพียง select * from links order by hot(ups, downs);
ส่วนผลการดึงข้อมูลก็ทำ caching ไว้
โดยที่ caching จะถูกทำลายเมื่อมีหัวข้อใหม่และมีการ vote !!
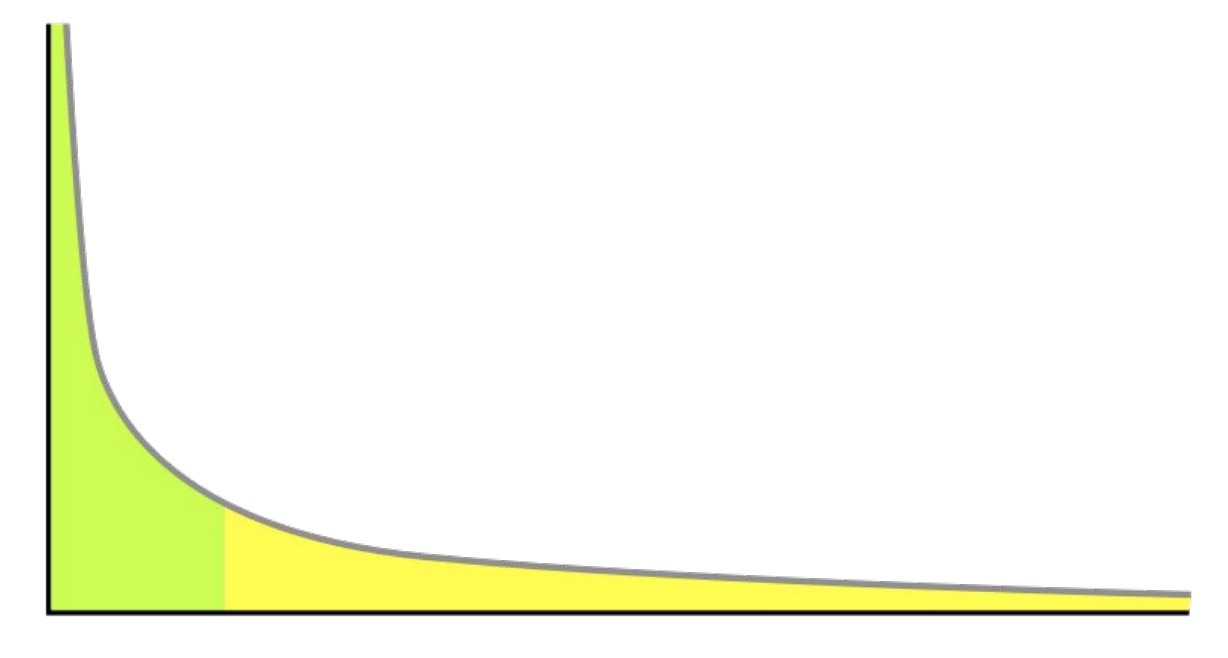
ถ้าดูจากสถิติของการ vote แล้ว
คิดว่า caching มันจะช่วยอะไรไหม ?
แน่นอนว่า ไม่ได้ช่วยอะไรเลย !!
เพราะว่าข้อมูลมันเปลี่ยนอยู่ตลอดเวลา
ดังนั้นจึงเกิดแนวคิดใหม่ ๆ เพื่อแก้ไขปัญหา
ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ถ้าเป็นคำสั่ง SQL ทั่วไปก็เพียง select * from links order by hot(ups, downs);
ส่วนผลการดึงข้อมูลก็ทำ caching ไว้
โดยที่ caching จะถูกทำลายเมื่อมีหัวข้อใหม่และมีการ vote !!
ถ้าดูจากสถิติของการ vote แล้ว
คิดว่า caching มันจะช่วยอะไรไหม ?
แน่นอนว่า ไม่ได้ช่วยอะไรเลย !!
เพราะว่าข้อมูลมันเปลี่ยนอยู่ตลอดเวลา
ดังนั้นจึงเกิดแนวคิดใหม่ ๆ เพื่อแก้ไขปัญหา
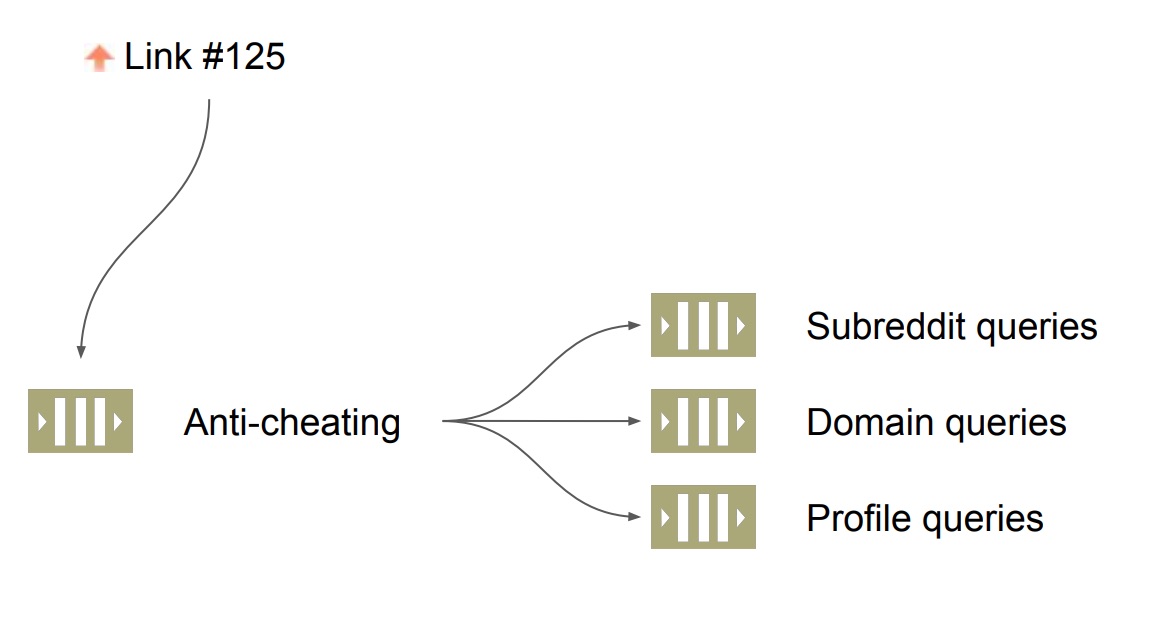
 เมื่อลงไปดูในรายละเอียดพบว่า
มีการ post link ของ domain อื่น ๆ เข้ามายัง Reddit.com เยอะมาก ๆ
หนึ่งในนั้นคือ imgur.com
ซึ่งส่งผลต่อการเปลี่ยนแปลงการ caching ของ Listing
ดังนั้นจำเป็นต้องแยก Job queue ออกตาม domain เพิ่มเข้ามาอีก
ในตอนนี้ระบบ Job queue จะแยกตาม
เมื่อลงไปดูในรายละเอียดพบว่า
มีการ post link ของ domain อื่น ๆ เข้ามายัง Reddit.com เยอะมาก ๆ
หนึ่งในนั้นคือ imgur.com
ซึ่งส่งผลต่อการเปลี่ยนแปลงการ caching ของ Listing
ดังนั้นจำเป็นต้องแยก Job queue ออกตาม domain เพิ่มเข้ามาอีก
ในตอนนี้ระบบ Job queue จะแยกตาม

 เห็นใน facebook มีคำถามว่า
เขียน Unit testing แบบไหนถึงดี ?
เป็นคำถามที่ตอบยากมาก ๆ
เพราะว่าคำว่า "ดี" นั้นแตกต่างกันเหลือเกิน
แต่คิดว่ามันเป็นสิ่งที่ดีนะ
จึงเริ่มด้วยคำถามก่อนว่า
เห็นใน facebook มีคำถามว่า
เขียน Unit testing แบบไหนถึงดี ?
เป็นคำถามที่ตอบยากมาก ๆ
เพราะว่าคำว่า "ดี" นั้นแตกต่างกันเหลือเกิน
แต่คิดว่ามันเป็นสิ่งที่ดีนะ
จึงเริ่มด้วยคำถามก่อนว่า

 หลังจากที่
หลังจากที่ 

 มีโอกาสไปแบ่งปันเรื่อง Agile in Real World ในค่าย
มีโอกาสไปแบ่งปันเรื่อง Agile in Real World ในค่าย 
 จากบทความเรื่อง
จากบทความเรื่อง 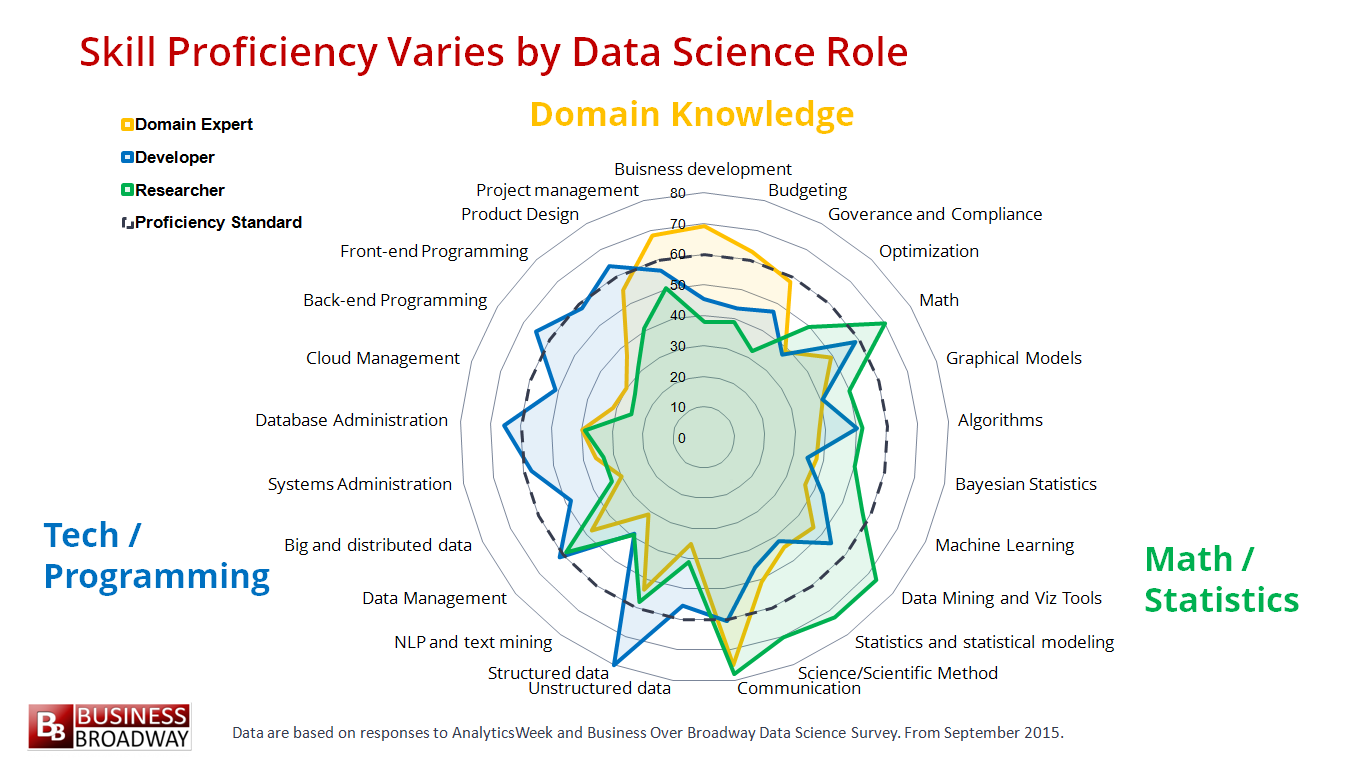
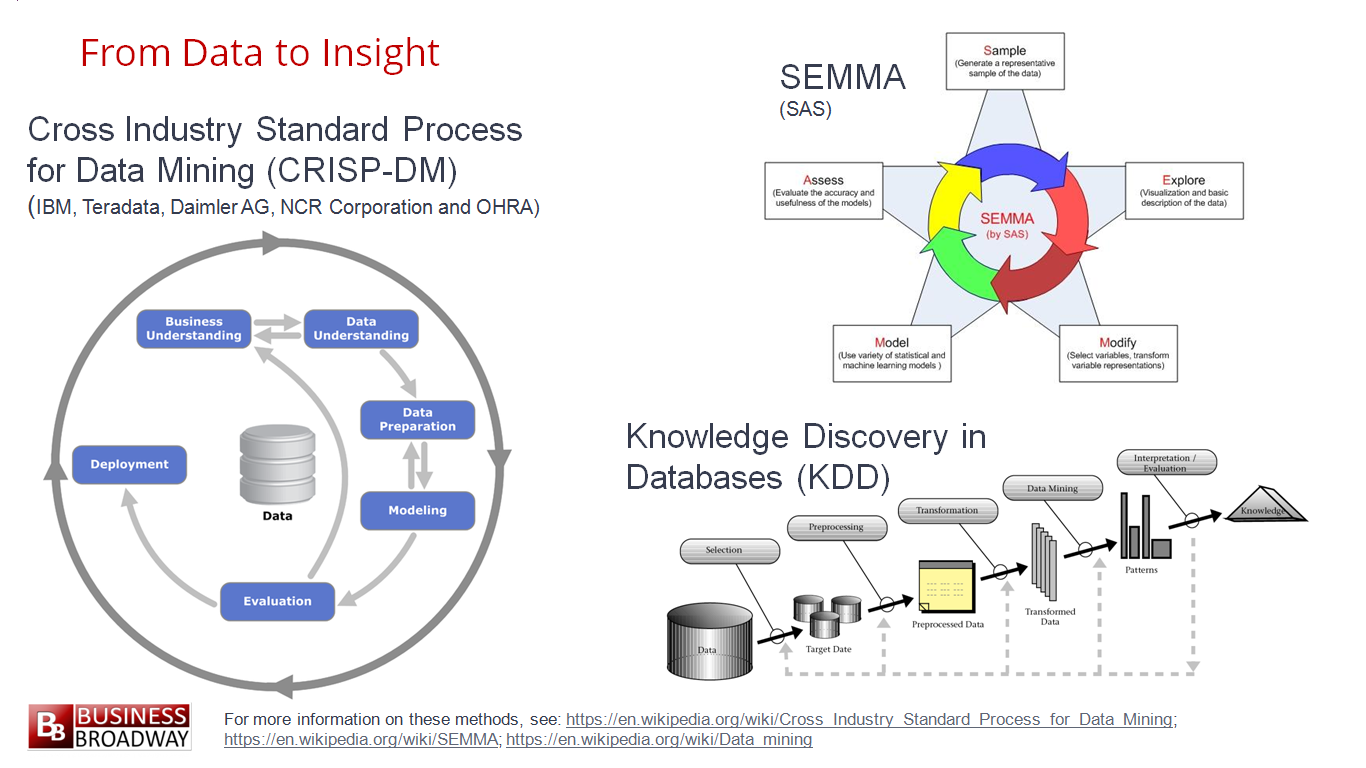
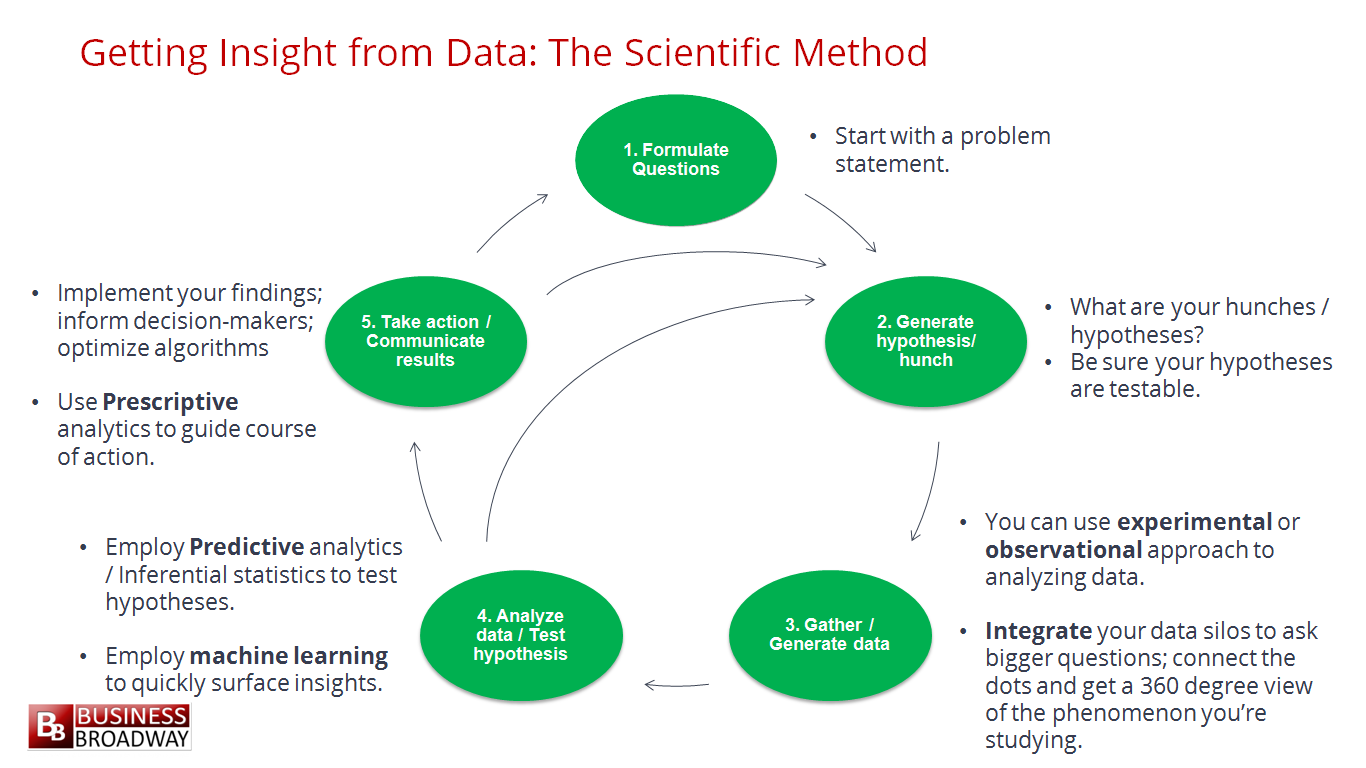
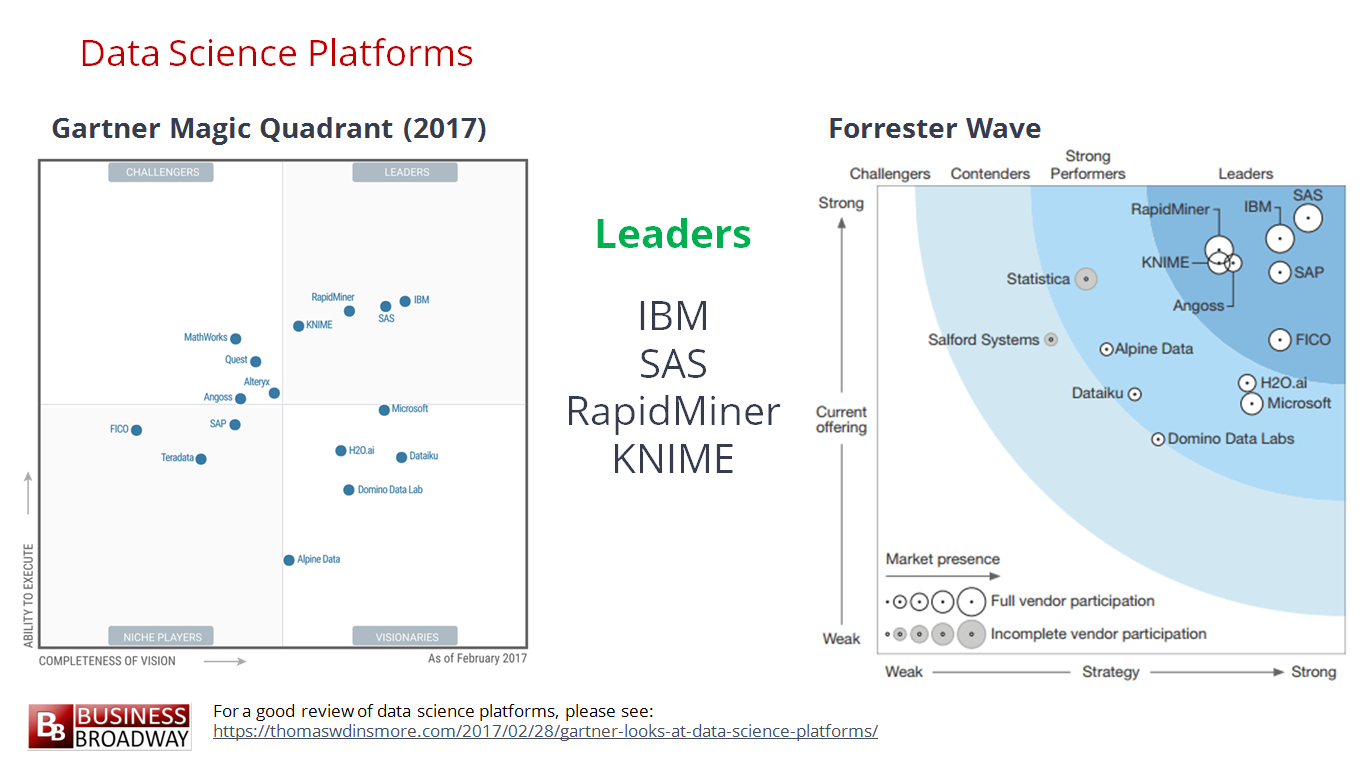

 ในปัจจุบันเทคโนโลยีต่าง ๆ มันเยอะเหลือเกิน
โลกของ Java ก็เช่นเดียวกัน (น่าจะเรียกโลกของ JVM ดีกว่านะ)
ดังนั้นมาดูกันหน่อยว่า
สำหรับ Java Developer แล้วควรต้องศึกษาอะไรบ้าง ?
เพื่อให้ทันโลกในปี 2018 นี้
เริ่มด้วยภาษาเครื่องมือและ framework ต่าง ๆ
ในปัจจุบันเทคโนโลยีต่าง ๆ มันเยอะเหลือเกิน
โลกของ Java ก็เช่นเดียวกัน (น่าจะเรียกโลกของ JVM ดีกว่านะ)
ดังนั้นมาดูกันหน่อยว่า
สำหรับ Java Developer แล้วควรต้องศึกษาอะไรบ้าง ?
เพื่อให้ทันโลกในปี 2018 นี้
เริ่มด้วยภาษาเครื่องมือและ framework ต่าง ๆ

 มีโอกาสไปแบ่งปันเรื่อง Agile มานิดหน่อย
โดยทำการหยิบยกปัญหาที่ Developer มักต้องพบเจอมาถาม
เมื่อ Developer อยู่ภายใต้ความกดดันแล้ว
หนึ่งในความกดดันที่พบบ่อย ๆ คือ Deadline
สิ่งที่จะเลือกทำมีอะไรบ้าง เพื่อให้เสร็จตามเวลา ?
ซึ่งคำตอบส่วนใหญ่เป็นดังนี้
มีโอกาสไปแบ่งปันเรื่อง Agile มานิดหน่อย
โดยทำการหยิบยกปัญหาที่ Developer มักต้องพบเจอมาถาม
เมื่อ Developer อยู่ภายใต้ความกดดันแล้ว
หนึ่งในความกดดันที่พบบ่อย ๆ คือ Deadline
สิ่งที่จะเลือกทำมีอะไรบ้าง เพื่อให้เสร็จตามเวลา ?
ซึ่งคำตอบส่วนใหญ่เป็นดังนี้

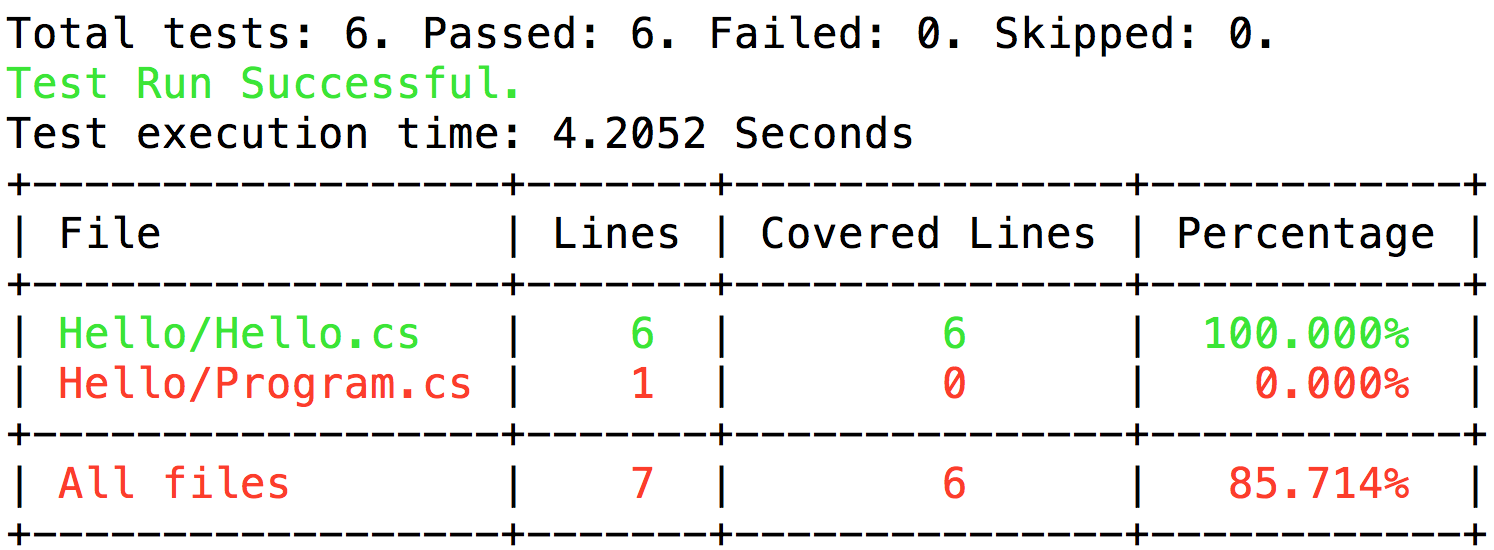
 Code Coverage เป็นสิ่งหนึ่งที่สำคัญ
เพื่อช่วยทำให้ทีมพัฒนารู้ว่า code ส่วนใด
ที่ยังไม่ถูกทดสอบหรือ execute บ้าง
แต่สำหรับ .Net Core บน Mac และ Linux นั้น
กลับไม่มี Code Coverage tool ให้ใช้งานเลย
มีเฉพาะบน Windows เท่านั้น
แต่โชคดีมีผู้ใหญ่ใจดี สร้างเครื่องมือไว้ให้
ยกตัวอย่างเช่น
Code Coverage เป็นสิ่งหนึ่งที่สำคัญ
เพื่อช่วยทำให้ทีมพัฒนารู้ว่า code ส่วนใด
ที่ยังไม่ถูกทดสอบหรือ execute บ้าง
แต่สำหรับ .Net Core บน Mac และ Linux นั้น
กลับไม่มี Code Coverage tool ให้ใช้งานเลย
มีเฉพาะบน Windows เท่านั้น
แต่โชคดีมีผู้ใหญ่ใจดี สร้างเครื่องมือไว้ให้
ยกตัวอย่างเช่น
 ขอให้สนุกกับการ coding ครับ
ขอให้สนุกกับการ coding ครับ

 ออกมาแล้วสำหรับ
ออกมาแล้วสำหรับ 
 เพียงเท่านี้ก็ใช้งานได้แล้ว ง่ายไหมละ !!
โดยที่แนวคิดและแนวทางของคนที่ใช้ Docker Swarm มาก่อนแล้ว
ไม่ต้องเปลี่ยนเยอะ
ทั้งความเรียบง่าย
ทั้งความเร็ว
ดังนั้นมาลองใช้กันดูครับ
เพียงเท่านี้ก็ใช้งานได้แล้ว ง่ายไหมละ !!
โดยที่แนวคิดและแนวทางของคนที่ใช้ Docker Swarm มาก่อนแล้ว
ไม่ต้องเปลี่ยนเยอะ
ทั้งความเรียบง่าย
ทั้งความเร็ว
ดังนั้นมาลองใช้กันดูครับ

 ทุกคนย่อมเคยทำผิดพลาดมาก่อนเสมอ
ยิ่งในการพัฒนา software แล้ว
ความผิดพลาดมักเกิดขึ้นมากมายและบ่อยครั้ง
ยังไม่พอเรามักจะเห็นความผิดพลาดที่เกิดขึ้นอยู่บ่อย ๆหรือ ซ้ำ ๆ
ดังนั้นจึงทำการสรุปไว้นิดหน่อย
ทุกคนย่อมเคยทำผิดพลาดมาก่อนเสมอ
ยิ่งในการพัฒนา software แล้ว
ความผิดพลาดมักเกิดขึ้นมากมายและบ่อยครั้ง
ยังไม่พอเรามักจะเห็นความผิดพลาดที่เกิดขึ้นอยู่บ่อย ๆหรือ ซ้ำ ๆ
ดังนั้นจึงทำการสรุปไว้นิดหน่อย

 วันนี้เห็น tweet ใน Twitter เรื่อง
วันนี้เห็น tweet ใน Twitter เรื่อง 
 จากบทความเรื่อง
จากบทความเรื่อง