![]()
![]()
จากบทความเรื่อง
How to ship production grade Go ?
แนะนำสิ่งที่ควรต้องทำก่อนที่จะทำการ deploy code ขึ้นไปยัง production server
ซึ่งมีหลายสิ่งอย่างที่ควรทำ
มิเช่นนั้นอาจจะเจอปัญหาต่าง ๆ มากมาย
ทั้งที่คาดหวังและไม่คาดหวังแน่นอน
ดังนั้นเรามาเตรียมความพร้อมกัน
จึงนำมาแปลและสรุปไว้นิดหน่อย
ในบทความนี้จะยกตัวอย่างระบบที่พัฒนาด้วยภาษา Go
มีเป้าหมายเพื่อส่งมอบ code
ที่มีความน่าเชื่อถือ
ที่สามารถระบุและบอกปัญหาได้
ซึ่งพร้อมสำหรับการ deploy
สิ่งที่นักพัฒนาระบบด้วยภาษา Go ต้องทำประกอบไปด้วย ( แบบ minimal สุด ๆ)
- การจัดการ Error ต่าง ๆ
- เมื่อเกิด Panic ขึ้นมา ควรทำการแจ้งให้รู้ทันที
- กำหนดมาตรฐานของ logging message ให้ชัดเจน
- ระบบงานต้องมีการเก็บ metric ต่าง ๆ เสมอ
- ทำการทดสอบในระดับต่าง ๆ ทั้ง unit, integration และ acceptance test พร้อมตรวจดูค่า coverage ด้วย
มาดูรายละเอียดในแต่ละข้อกัน
ระบบงานที่พัฒนาด้วยภาษา Go นั้น
เรื่องของ Error และ Panic จำเป็นต้องจัดการให้ดี
มาดูที่ Error กันก่อน
ภาษา Go นั้นในแต่ละ method จะทำการ return ค่า Error กลับมาเสมอ
เพื่อบอกสถานะของการทำงานว่าเป็นอย่างไร
ถ้า Error เป็น nil แสดงว่ามีสถานะเป็นปกติ
แต่ถ้าไม่ nil หมายถึงเกิดเหตุการณ์ที่ไม่ปกติขึ้นมาแล้ว
ดังนั้น developer สามารถจัดการกับ Error ได้ง่ายมาก ๆ
โดยที่ package สำหรับการจัดการ Error ที่ใช้บ่อย ๆ คือ Errors
มันใช้ง่ายและมีประโยชน์อย่างมาก
ที่สำคัญ ควรดัก error เดิมเพียงครั้งเดียวหรือที่เดียวนะ
ไม่ใช่โยนและ print error message ไปเรื่อย ๆ
รวมทั้งถ้าจะ print error message ต้องมีรูปแบบที่เป็นมาตรฐานทั้งระบบนะ
มิฉะนั้นจะหา error ยากมาก ๆ
[gist id="3ef77e23a1db736bb3781872a8529ea0" file="error.go"]
ต่อมาเรื่องของ Panic ถ้าเกิดขึ้นมาต้องแจ้งหรือส่งข้อมูลออกมาทันที
ถ้าเกิด Panic ขึ้นมาในระบบงานแล้ว
เราไม่สามารถจัดการได้เหมือน Error
ดังนั้นถ้าจัดการหรือเรียกว่า recover ไม่ดีแล้ว
ระบบงานก็จะหยุดทำงานได้เลย
ซึ่งส่งผลเสียต่องานอย่างมาก
สิ่งที่ควรทำคือ การ recover นั่นเอง
ที่สำคัญคือ
เมื่อเกิด Panic ขึ้นมาต้องแจ้งมายังทีมพัฒนาหรือผู้ดูแลด้วย
เช่นผ่าน Email, Slack, Line หรืออะไรก็ตามที่ทำให้รู้ทันที
เนื่องจาก Panic มันคือสิ่งที่สำคัญมาก ๆ
อย่าปล่อยให้หลุดมือไปเด็ดขาด
มาดูตัวอย่างกัน
[gist id="3ef77e23a1db736bb3781872a8529ea0" file="panic.go"]
เรื่องของ Logging ต้องกำหนดรูปแบบมาตรฐานขึ้นมา
ปัญหาของการจัดเก็บ log คือ รูปแบบที่ไร้ซึ่งมาตรฐาน
ใครอยากเขียนแบบไหนก็ทำไป !!
ซึ่งยากต่อการดูแล
ซึ่งยากต่อการนำมาใช้งาน
โดยมี library ช่วยจัดการเยอะมาก
ยกตัวอย่างเช่น Logrus, Zap และ Log15 เป็นต้น
ตัวอย่างที่ดี เช่น
การจัดการในรูปแบบ key-value ด้วย Logrus
[gist id="3ef77e23a1db736bb3781872a8529ea0" file="log.go"]
เมื่อ log มีโครงสร้างที่ดีและมีมาตรฐานแล้ว
ก็อย่าเขียนลงไฟล์อย่างเดียวนะ
ให้ไปจัดเก็บในระบบอื่น ๆ บ้าง
เพื่อช่วยให้วิเคราะห์ได้ง่ายขึ้น
ยกตัวอย่างเช่น การใช้งาน
ELK stack เป็นต้น
ต่อมาต้องจัดการเรื่องของ Metric ต่าง ๆ ด้วย
สิ่งที่มักจะมีเสมอคือ Monitoring สำหรับ Server
เพื่อดูการใช้งานต่าง ๆ และ performance ของ server
เช่น CPU, Memory, Disk และ Network เป็นต้น
แต่สิ่งที่มักขาดหายไปเสมอคือ Metric ของระบบงานหรือ application นั่นเอง !!
แต่คำถามที่เกิดขึ้นคือ
จะเก็บ metric อะไรบ้างละ ?
ตอบได้ยากมาก ๆ
เพราะว่าแต่ละระบบมันแตกต่างกัน ความต้องการต่างกัน
ยกตัวอย่างเช่น ระบบ REST APIs
สิ่งที่อยากรู้น่าจะประกอบไปด้วย
- จำนวน request และ response ในแต่ละช่วงเวลา เช่น นาที ชั่วโมง วัน เป็นต้น
- จำนวน success และ error ของ response
- Response time ของแต่ละ request รวมไปถึงค่าทางสถิติต่าง ๆ เช่น Max, Min, Average และ Percentile เป็นต้น
- แยกข้อมูลในแต่ละ endpoint
- เรื่องของ rate limit การใช้งานของผู้ใช้แต่ละคน
ถามว่าเยอะไหม ?
ตอบเลยว่ามาก
แต่สิ่งเหล่านี้น่าจะเป็นคำถามที่ต้องเกิดขึ้นมาตั้งแต่ต้น
มันคือสิ่งที่ทำให้เราเข้าใจระบบ และ ความต้องการ
รวมไปถึงการทำงานของระบบมากขึ้น
ยกตัวอย่างเช่น
เคยตั้งคำถามไหมว่า ทำไมคุณต้อง deploy ระบบในช่วงหลังเที่ยงคืน ?
ทำตาม ๆ กันมา
หรือนำข้อมูลจาก Metric ที่เก็บไว้มาใช้ในการตัดสินใจ
คำถามต่อมา คือ เก็บที่ไหนละ ?
ตอบได้เลยว่า มีให้เพียบ
ใช้ทั้งเก็บข้อมูลในรูปแบบ time serie
ใช้ทั้ง aggregation
ใช้ทั้งแสดงผลในรูปแบบกราฟสวย ๆ และเข้าใจง่าย
ยกตัวอย่างเช่น
แน่นอนว่ามี library ที่เขียนด้วยภาษา Go ให้ใช้งานแน่นอน
คำถามสุดท้ายคือ
ระบบของคุณมีแล้วหรือยัง ?
เรื่องสุดท้ายคือ การทดสอบแบบอัตโนมัติ
ในฐานนะของ developer
code ที่เขียนขึ้นมานั้น ถูกทดสอบหรือไม่ ?
code ที่เขียนขึ้นมานั้น มีชุดการทดสอบแบบอัตโนมัติหรือไม่ ?
การทดสอบมีทั้ง
- End-to-End test
- Integration test
- Unit test
โดยที่ภาษา Go นั้นมี package testing มาให้อยู่แล้ว
ถ้าทดสอบทำงานเกี่ยวกับพวก HTTP ก็มีให้ใช้อีกคือ
testing/httptest
ถ้าทดสอบการทำงานเกี่ยวกับ io.Reader และ io.Writer ก็มี
testing/iotest
ถ้าระบบมี input ที่ซับซ้อนแนะนำให้ใช้งาน
go-fuzz
ดังนั้นถามระบบไหนที่พัฒนาด้วยภาษา Go แล้วไม่เขียนชุดการทดสอบ
ถือว่าบาปมาก ๆ
ถ้าไม่อยากบาป ก็เขียนเถอะนะ
ถ้าคุณกำลังจะ deploy ระบบ ที่ไม่มีชุดการทดสอบขึ้น production แล้ว
แนะนำว่าให้หยุด !!
แล้วมาเขียนชุดการทดสอบก่อนเถอะนะ
เพื่อทำให้มั่นใจก่อน deploy
ที่สำคัญ Go มีตัวช่วยในการดูค่า test coverage อีกด้วยนะ
โดยที่ไม่ต้องติดตั้งอะไรเพิ่มเลย
ดังนั้นใช้มันซะ
มันคือเพื่อที่ดีมาก ๆ ของคุณ
แนะนำให้ทำการทดสอบบ่อย ๆ และทำตั้งแต่เริ่มต้นนะครับ
ชีวิตจะดีขึ้นกว่าเดิมแน่นอน
แค่เขียน ชีวิตก็เปลี่ยน
จากนั้นถ้ามีชุดการทดสอบแบบอัตโนมัติแล้ว
ก็ให้ทำการ run ทุกครั้งแบบอัตโนมัติเมื่อ code เปลี่ยนแปลงกันไปเลย
สุดท้ายแล้ว ที่อธิบายมาคือ checklist แบบ minimal สุด ๆ
นักพัฒนาลองทำการตรวจสอบระบบงานที่พัฒนาหน่อยสิว่า
มีสิ่งต่าง ๆ เหล่านี้ครบหรือยัง
ถ้ายังแสดงว่า คุณจะยังไม่พร้อม deploy ขึ้น production
ถึง deploy ไปก็เกิดปัญหามากมายตามมา
แถมหาจุดเกิดเหตุและแก้ไขช้าอีกด้วย
ส่วนระบบที่พัฒนาด้วยภาษาโปรแกรมอื่น ๆ ก็ใช้ได้เช่นเดียวกัน
วันนี้ระบบคุณพร้อมแล้วหรือยัง ?

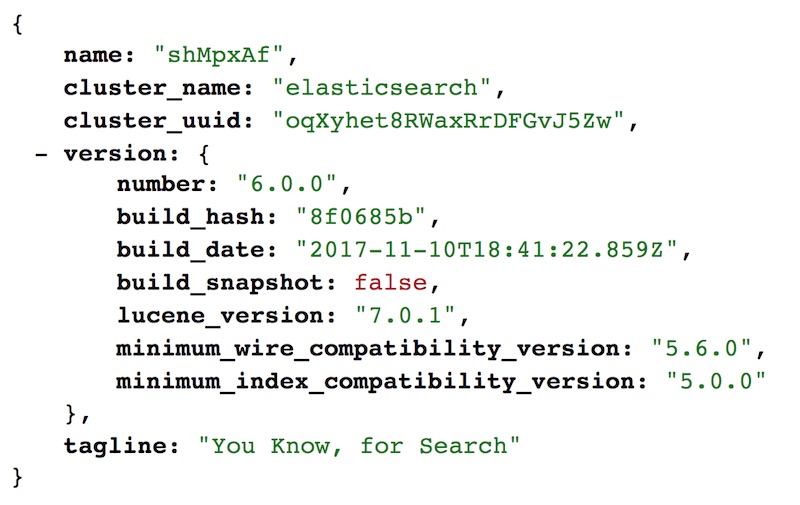
 ทาง Elastic ได้ปล่อย Elasticsearch 6.0.0 ออกมา
ต้องบอกว่า Elastic Stack สินะ
เพราะว่า product ทุกตัวจะปล่อยออกมาพร้อมกันทั้งหมด
เช่น Elasticsearch, Kibana และ Logstash (ELK)
ดังนั้นมาดูกันหน่อยว่ามีอะไรเปลี่ยนแปลงไปบ้าง
ทาง Elastic ได้ปล่อย Elasticsearch 6.0.0 ออกมา
ต้องบอกว่า Elastic Stack สินะ
เพราะว่า product ทุกตัวจะปล่อยออกมาพร้อมกันทั้งหมด
เช่น Elasticsearch, Kibana และ Logstash (ELK)
ดังนั้นมาดูกันหน่อยว่ามีอะไรเปลี่ยนแปลงไปบ้าง
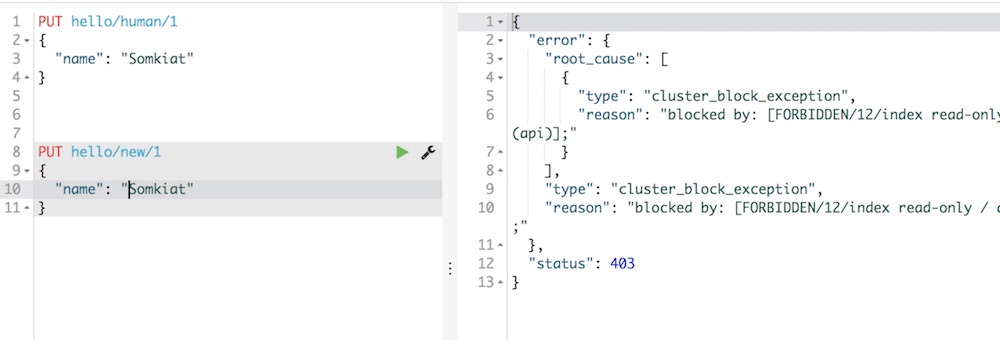
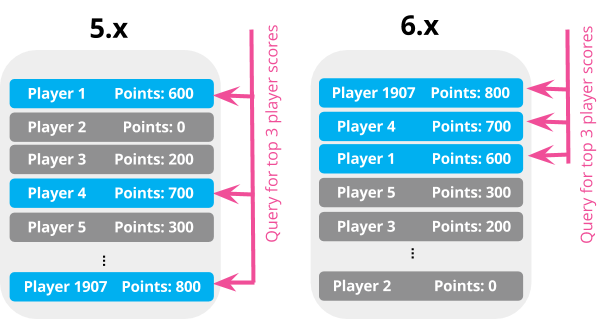 สุดท้ายอย่าลืมดู log การทำงานด้วยว่ามีอะไรที่ Deprecated บ้างนะครับ
สามารถดูการเปลี่ยนแปลงต่าง ๆ ได้ที่ Release notes
สุดท้ายอย่าลืมดู log การทำงานด้วยว่ามีอะไรที่ Deprecated บ้างนะครับ
สามารถดูการเปลี่ยนแปลงต่าง ๆ ได้ที่ Release notes

 ช่วงเย็น ๆ เห็นบทสัมภาษณ์ของ
ช่วงเย็น ๆ เห็นบทสัมภาษณ์ของ 
 เมื่อวานเห็น code ที่น่าสนใจเกี่ยวกับเรื่อง Null Pointer Exception (NPE)
มีทั้งทำให้เกิด หรือ ไม่เกิด
แต่ประเด็นเหล่านั้นไม่น่าสนใจเท่ากับว่า
วันนี้ Java Developer ทำการจัดการกับ NPE กันอย่างไร ?
เมื่อวานเห็น code ที่น่าสนใจเกี่ยวกับเรื่อง Null Pointer Exception (NPE)
มีทั้งทำให้เกิด หรือ ไม่เกิด
แต่ประเด็นเหล่านั้นไม่น่าสนใจเท่ากับว่า
วันนี้ Java Developer ทำการจัดการกับ NPE กันอย่างไร ?
 คำถามที่น่าสนใจกว่าคือ จัดการกับ NPE กันอย่างไร ?
คำถามที่น่าสนใจกว่าคือ จัดการกับ NPE กันอย่างไร ? ดังนั้นแก้ไขใหม่ซะ จะเป็นดังนี้
[gist id="092191a351aec1a7e75b10a1b1a13d68" file="5.java"]
แต่ถ้าใช้ IDE ดี ๆ มันก็จะแนะนำวิธีการแก้ไขให้เพียบนะครับ
เอาที่สบายใจกันได้เลย ดังรูป
ดังนั้นแก้ไขใหม่ซะ จะเป็นดังนี้
[gist id="092191a351aec1a7e75b10a1b1a13d68" file="5.java"]
แต่ถ้าใช้ IDE ดี ๆ มันก็จะแนะนำวิธีการแก้ไขให้เพียบนะครับ
เอาที่สบายใจกันได้เลย ดังรูป
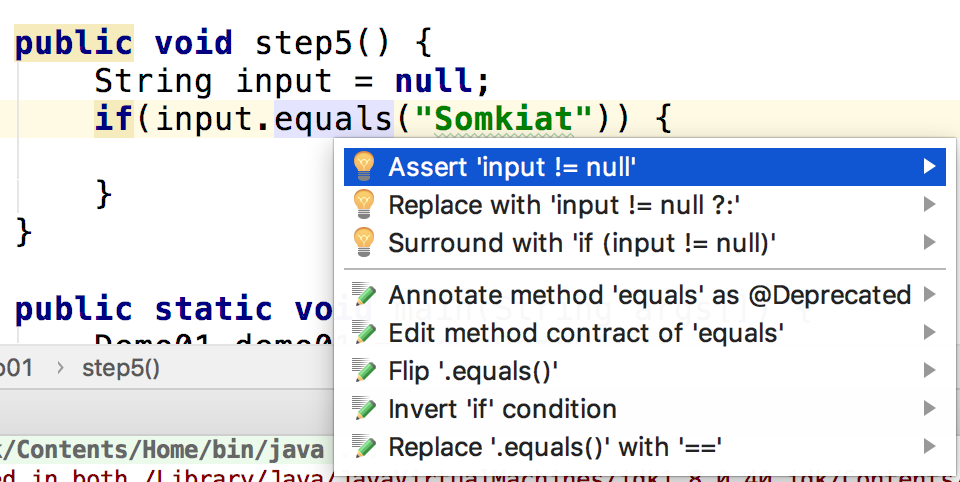

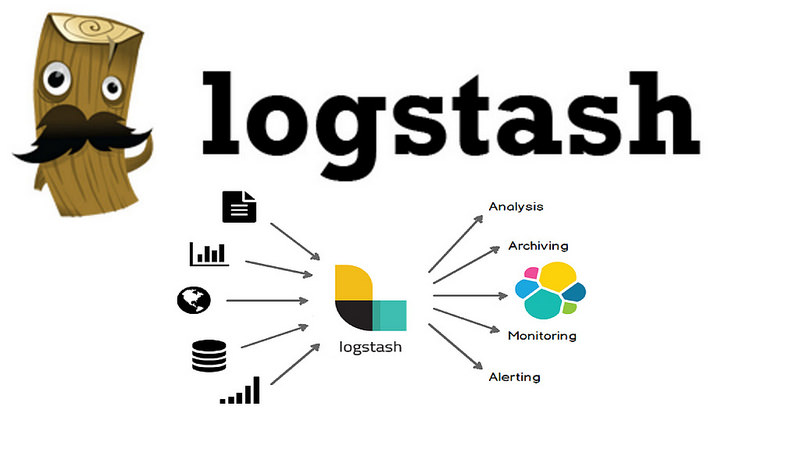 จาก
จาก 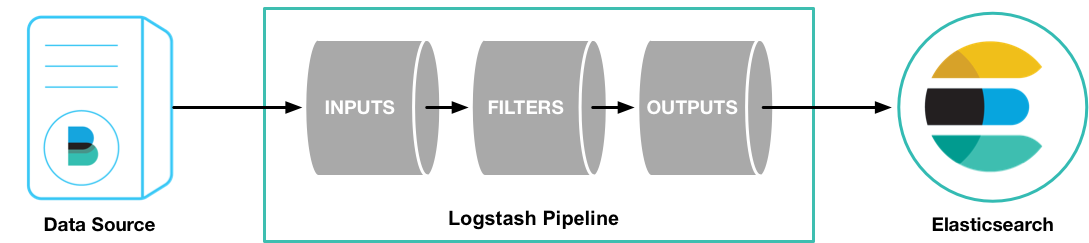

 จากหนังสือ
จากหนังสือ 
 การพัฒนา software ในปัจจุบัน
สิ่งที่สำคัญมาก ๆ คือ
การพัฒนา software ในปัจจุบัน
สิ่งที่สำคัญมาก ๆ คือ
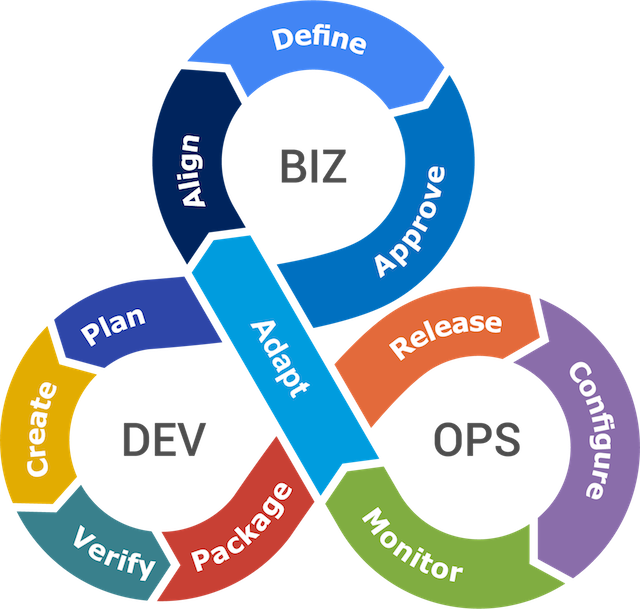

 ในโลกของการพัฒนา software นั้น
พบว่ามีตำแหน่งที่ไม่เกี่ยวกับการเขียน code หรือ programming เยอะมาก ๆ
ดังนั้นมาช่วยบอกหน่อยสิว่า
มีตำแหน่งอะไรบ้าง ?
ในโลกของการพัฒนา software นั้น
พบว่ามีตำแหน่งที่ไม่เกี่ยวกับการเขียน code หรือ programming เยอะมาก ๆ
ดังนั้นมาช่วยบอกหน่อยสิว่า
มีตำแหน่งอะไรบ้าง ?

 มีแนวคิดหนึ่งที่น่าสนใจเกี่ยวกับการพัฒนา Software
ลองคิดดูสิว่า
ถ้าเราต้องการทำ feature ใหม่ขึ้นมาสักตัว
สิ่งแรกที่ต้องทำก่อนคือ เขียน Document หรือเอกสารต่าง ๆ ก่อนนะ
ตัวที่สำคัญมาก ๆ คือ User manual document !!
คำถามที่น่าสนใจ คือ
ยังไม่เริ่มพัฒนาเลย จะเขียนได้อย่างไร ?
คำตอบคือ
นั่นแหละคือปัญหาของ requirement
ที่คุณยังไม่รู้แม้กระทั่งว่าจะใช้งานกันอย่างไร ?
เริ่มขั้นตอนการทำงานตรงไหน ?
จะจัดการต่อไปอย่างไร ?
ที่สำคัญแสดงว่า คุณไม่ได้สนใจอะไรเลย
มีแค่จะเอานั่นเอานี่
สุดท้ายมันก็เจอปัญหาเดิม ๆ กันใช่ไหม ?
ยิ่งคนที่อยู่ปลายน้ำ ที่ต้องโดนด่าตลอดคือใคร ?
บางที่อาจจะเป็น Call center ที่
ไม่รู้แม้กระทั่งว่า มันมี feature นี้ด้วยหรอ !!
มีแนวคิดหนึ่งที่น่าสนใจเกี่ยวกับการพัฒนา Software
ลองคิดดูสิว่า
ถ้าเราต้องการทำ feature ใหม่ขึ้นมาสักตัว
สิ่งแรกที่ต้องทำก่อนคือ เขียน Document หรือเอกสารต่าง ๆ ก่อนนะ
ตัวที่สำคัญมาก ๆ คือ User manual document !!
คำถามที่น่าสนใจ คือ
ยังไม่เริ่มพัฒนาเลย จะเขียนได้อย่างไร ?
คำตอบคือ
นั่นแหละคือปัญหาของ requirement
ที่คุณยังไม่รู้แม้กระทั่งว่าจะใช้งานกันอย่างไร ?
เริ่มขั้นตอนการทำงานตรงไหน ?
จะจัดการต่อไปอย่างไร ?
ที่สำคัญแสดงว่า คุณไม่ได้สนใจอะไรเลย
มีแค่จะเอานั่นเอานี่
สุดท้ายมันก็เจอปัญหาเดิม ๆ กันใช่ไหม ?
ยิ่งคนที่อยู่ปลายน้ำ ที่ต้องโดนด่าตลอดคือใคร ?
บางที่อาจจะเป็น Call center ที่
ไม่รู้แม้กระทั่งว่า มันมี feature นี้ด้วยหรอ !!

 เนื่องจากเพิ่งผ่านการ review code มากว่า 41 project
ก็ได้เห็นรูปแบบของ code ที่น่าสนใจหลาย ๆ อย่าง
ทั้งเรื่องความซับซ้อน
ทั้งเรื่องของ indent
ทั้งเรื่องของการ hard code
ทั้งเรื่องของการ comment
ทั้งเรื่องการ debug code
ทั้งเรื่องของการตั้งชื่อ
ทั้งเรื่องของ code ที่ไม่ใช้งานหรือมีมากเกินความจำเป็น
จึงทำการสรุปไว้ใน slide นิดหน่อย
[slideshare id=83835878&doc=sck-example-171211082038&h=640&w=480]
คำถามที่น่าสนใจคือ
เรารู้หรือไม่ว่า code เหล่านี้มันไม่ดี ?
เรารู้หรือไม่ว่า code เหล่านี้มันไม่ดีอย่างไร ?
ถ้าเราสามารถตอบได้
คำถามที่จำตามมาคือ จะทำการแก้ไขได้อย่างไรบ้าง ?
เพื่อทำให้ code มันดีขึ้น
เนื่องจากเพิ่งผ่านการ review code มากว่า 41 project
ก็ได้เห็นรูปแบบของ code ที่น่าสนใจหลาย ๆ อย่าง
ทั้งเรื่องความซับซ้อน
ทั้งเรื่องของ indent
ทั้งเรื่องของการ hard code
ทั้งเรื่องของการ comment
ทั้งเรื่องการ debug code
ทั้งเรื่องของการตั้งชื่อ
ทั้งเรื่องของ code ที่ไม่ใช้งานหรือมีมากเกินความจำเป็น
จึงทำการสรุปไว้ใน slide นิดหน่อย
[slideshare id=83835878&doc=sck-example-171211082038&h=640&w=480]
คำถามที่น่าสนใจคือ
เรารู้หรือไม่ว่า code เหล่านี้มันไม่ดี ?
เรารู้หรือไม่ว่า code เหล่านี้มันไม่ดีอย่างไร ?
ถ้าเราสามารถตอบได้
คำถามที่จำตามมาคือ จะทำการแก้ไขได้อย่างไรบ้าง ?
เพื่อทำให้ code มันดีขึ้น

 ไปงาน Kotlin meetup 1.2 มา
มีทั้งเรื่องของ
ไปงาน Kotlin meetup 1.2 มา
มีทั้งเรื่องของ 
 เรื่องเล่าที่น่าสนใจเกี่ยวกับการนำ
เรื่องเล่าที่น่าสนใจเกี่ยวกับการนำ 
 จากเอกสารของภาษา
จากเอกสารของภาษา 
 สิ่งที่น่าสนใจสำหรับคำว่า DevOps
ซึ่งได้กลายเป็นคำที่ถูกพูดถึงอย่างมาก
หนักไปกว่านั้น เรามีการเปิดรับสมัครตำแหน่ง DevOps อีกด้วย
ทั้ง ๆ ที่มันไม่ควรจะมีตำแหน่งนี้เลย
แต่มันควรเป็นแนวคิด แนวปฏิบัติสำหรับทุกคนที่เกี่ยวข้อง
เป็นสิ่งที่ควรเกิดขึ้นในการพัฒนา software
เพื่อช่วยปรับปรุงเวลา
ตั้งแต่เรื่องของการรับ requirement
เปลี่ยนจาก requirement ไปเป็นสิ่งที่อยู่ในมือของผู้ใช้งาน
ไปจนถึงการดูแลรักษาระบบ ปรับปรุง และ operate ต่าง ๆ
ให้เร็ว และ ดีขึ้นอย่างต่อเนื่อง
สิ่งที่น่าสนใจสำหรับคำว่า DevOps
ซึ่งได้กลายเป็นคำที่ถูกพูดถึงอย่างมาก
หนักไปกว่านั้น เรามีการเปิดรับสมัครตำแหน่ง DevOps อีกด้วย
ทั้ง ๆ ที่มันไม่ควรจะมีตำแหน่งนี้เลย
แต่มันควรเป็นแนวคิด แนวปฏิบัติสำหรับทุกคนที่เกี่ยวข้อง
เป็นสิ่งที่ควรเกิดขึ้นในการพัฒนา software
เพื่อช่วยปรับปรุงเวลา
ตั้งแต่เรื่องของการรับ requirement
เปลี่ยนจาก requirement ไปเป็นสิ่งที่อยู่ในมือของผู้ใช้งาน
ไปจนถึงการดูแลรักษาระบบ ปรับปรุง และ operate ต่าง ๆ
ให้เร็ว และ ดีขึ้นอย่างต่อเนื่อง



 เรื่องของ Technical Debt หรือ หนี้เชิงเทคนิค
มันเป็นสิ่งที่ใช้อธิบายว่า
สิ่งที่ทีมพัฒนาสร้างขึ้นมานั้น
มันค่อย ๆ ทำร้ายเราเรื่อย ๆ คล้าย ๆ มะเร็งร้าย
ถ้าไม่ตรวจร่างกายหรือระบบอยู่บ่อย ๆ แล้ว
ผลที่ตามมาคือ อาการจะออกมาเมื่อถึงระยะท้าย ๆ
ซึ่งแก้ไขไม่ทันแล้ว !!
หรือไม่เช่นนั้น ก็ต้องใช้ค่ารักษาที่สูงมาก ๆ
เรื่องของ Technical Debt หรือ หนี้เชิงเทคนิค
มันเป็นสิ่งที่ใช้อธิบายว่า
สิ่งที่ทีมพัฒนาสร้างขึ้นมานั้น
มันค่อย ๆ ทำร้ายเราเรื่อย ๆ คล้าย ๆ มะเร็งร้าย
ถ้าไม่ตรวจร่างกายหรือระบบอยู่บ่อย ๆ แล้ว
ผลที่ตามมาคือ อาการจะออกมาเมื่อถึงระยะท้าย ๆ
ซึ่งแก้ไขไม่ทันแล้ว !!
หรือไม่เช่นนั้น ก็ต้องใช้ค่ารักษาที่สูงมาก ๆ

 การทดสอบช่วยทำให้เห็นว่า
สิ่งที่สร้างตามความต้องการมันเป็นอย่างไร
ทำการอธิบายว่า การสร้างในแต่ละส่วนเป็นอย่างไร ทำงานอย่างไร
โดยที่การทดสอบมีทั้ง Manual และ Automation
เรื่องของ Automation test นั้นเป็นรูปแบบหนึ่งของ Risk management
ซึ่งช่วยลดความเสี่ยงต่าง ๆ ของระบบงานลงไป
แน่นอนว่า ต้องทำงานแบบอัตโนมัติ
แต่สิ่งหนึ่งที่มักไม่พูดถึงกันคือ
การสร้างชุดการทดสอบนั่นเอง
ซึ่งมันไม่ง่ายเลย มีค่าใช้จ่ายสูงทั้งในแง่ของจำนวนคนและเวลาที่ใช้
ส่วน Manual testing มักจะทำในช่วยท้าย ๆ ของขั้นตอนการพัฒนา
ซึ่งต้องการคนทดสอบจำนวนมาก ตามขนาดของระบบ
อีกทั้งการทดสอบแต่ละครั้งต้องใช้เวลาและค่าใช้จ่ายสูง
การทดสอบช่วยทำให้เห็นว่า
สิ่งที่สร้างตามความต้องการมันเป็นอย่างไร
ทำการอธิบายว่า การสร้างในแต่ละส่วนเป็นอย่างไร ทำงานอย่างไร
โดยที่การทดสอบมีทั้ง Manual และ Automation
เรื่องของ Automation test นั้นเป็นรูปแบบหนึ่งของ Risk management
ซึ่งช่วยลดความเสี่ยงต่าง ๆ ของระบบงานลงไป
แน่นอนว่า ต้องทำงานแบบอัตโนมัติ
แต่สิ่งหนึ่งที่มักไม่พูดถึงกันคือ
การสร้างชุดการทดสอบนั่นเอง
ซึ่งมันไม่ง่ายเลย มีค่าใช้จ่ายสูงทั้งในแง่ของจำนวนคนและเวลาที่ใช้
ส่วน Manual testing มักจะทำในช่วยท้าย ๆ ของขั้นตอนการพัฒนา
ซึ่งต้องการคนทดสอบจำนวนมาก ตามขนาดของระบบ
อีกทั้งการทดสอบแต่ละครั้งต้องใช้เวลาและค่าใช้จ่ายสูง
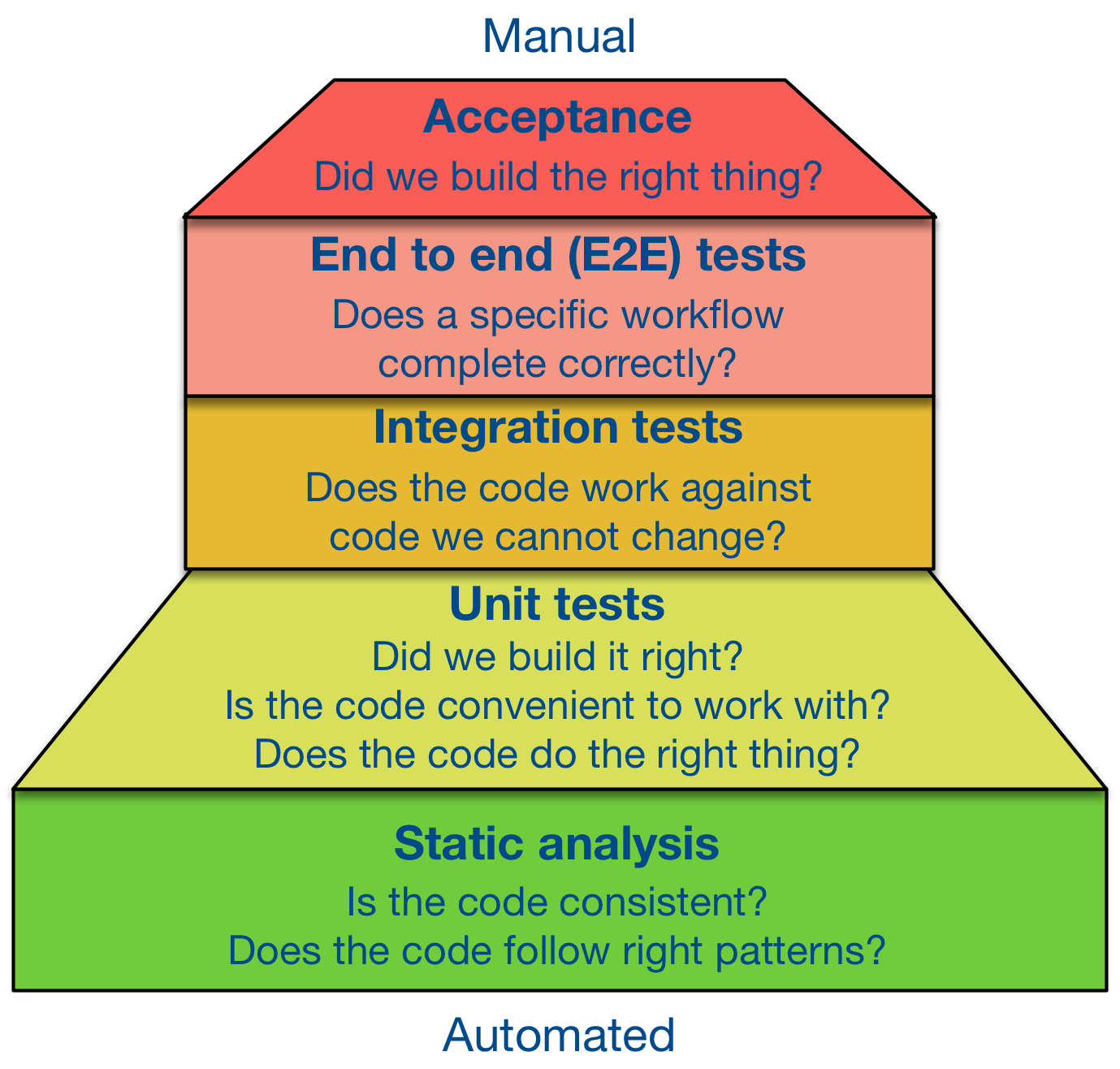



 จากบทความเรื่อง
จากบทความเรื่อง 
 ปัญหาหลักที่มักเจอเกี่ยวกับการจัดการ source code
ด้วย VCS (Version Control System) เช่น Git คือ
เราจะเลือก branch strategy แบบไหนดี ?
ยกตัวอย่างเช่น
ปัญหาหลักที่มักเจอเกี่ยวกับการจัดการ source code
ด้วย VCS (Version Control System) เช่น Git คือ
เราจะเลือก branch strategy แบบไหนดี ?
ยกตัวอย่างเช่น

 ช่วงนั่งรอขึ้นเครื่องบินกลับบ้าน
ได้อ่านเรื่อง Prevent Bugs เป็นบทที่ 5 จากหนังสือ
ช่วงนั่งรอขึ้นเครื่องบินกลับบ้าน
ได้อ่านเรื่อง Prevent Bugs เป็นบทที่ 5 จากหนังสือ