![]()
![]() มีโอกาสคุยกับกลุ่มในสาย Data Science พบว่า
มีโอกาสคุยกับกลุ่มในสาย Data Science พบว่า
ปัญหาหลัก ๆ ของคนกลุ่มนี้คือ เรื่องการจัดการ environment ที่ใช้งาน
ประกอบไปด้วย
- ปัญหาในการติดตั้ง software
- ปัญหาในการติดตั้ง library หรือ dependency ต่าง ๆ
- ปัญหาในการ configuration และ setting ค่าต่าง ๆ
ทำให้ขั้นตอนการวิเคราะห์ข้อมูลมันช้าอย่างมาก
บางคนใช้ได้ บางคนใช้ไม่ได้
บางองค์กรต้องรอให้ฝ่าย IT มาทำการติดตั้งให้
ถ้าขั้นตอนการทำงานช้า ก็รอกันต่อไป
หรือแม้แต่การนำเครื่องมือใหม่ ๆ มาใช้ ก็ยากเย็นเหลือเกิน
บางครั้งทำเองได้ แต่ก็ลืม
ลืมขั้นตอนการติดตั้งและ configuration
ลืม configuration ค่าต่าง ๆ ที่ไปหาจาก internet !!
บ่อยครั้งพบว่า library ต่าง ๆ ที่ใช้
ไม่ได้ update version ใหม่ ๆ มาใช้เลย
บางคนใช้ version เก่า ๆ มาเป็นปี ๆ !!
เราทำงานเป็นทีม Data Science นะ
แต่ว่า ... แต่ละคนต่างคนต่างทำ
OS ที่ใช้งานต่างกัน
เครื่องมือที่ใช้ต่างกัน หรือถ้าเหมือนกัน แต่ configuration ต่างกัน
หรือทำไปเปลี่ยนไป
หรือไม่สามารถ run งานเก่า ๆ ได้เลย
เนื่องจาก environment ต่าง ๆ มันเปลี่ยนไปหมดแล้ว
ผลที่ตามมาแล้วจะทำอย่างไรละ ?
ต้องทิ้งงานนั้นกันไปหรืออย่างไร ?
ยิ่งรับสมาชิกใหม่เข้ามาในทีมยิ่งลำบาก
เพราะว่า เพียงแค่การติดตั้ง environment ให้เริ่มทำงานได้ก็ยากแล้ว
บางคนถึงขั้นถอดใจ ออกดีกว่า
สุดท้ายถ้าทำการ update/upgrade สิ่งต่าง ๆ แล้ว
ไม่รู้เลยว่ามันส่งผลกระทบต่อส่วนการทำงานใดบ้าง
ดังนั้นก็วนกลับไปเรื่องเดิมคือ ไม่ต้องทำอะไร มันทำงานได้ !!
บริษัทต่าง ๆ เขาแก้ไขปัญหานี้อย่างไรกันนะ ?
เท่าที่คุยมาก็มีอยู่ 2 แบบคือ
- แบบที่ 1 ใครอยากทำอะไร ติดตั้งอะไรก็ทำไปเลย ง่ายนะ เร็วด้วย แต่ว่าต่างคนก็ต่างไปคนละทาง
- แบบที่ 2 บริษัททำการควบคุมทุกอย่าง ลงได้เท่าที่กำหนดเท่านั้น ทำให้ฝ่าน IT ควบคุมได้หมด แต่สำหรับคนใช้มันยากต่อการเปลี่ยนแปลงมาก ๆ
ไม่ว่าแบบไหนก็มีปัญหากันไปคนละแบบ
แต่ก็ไม่ได้แก้ไขปัญหาให้หมดไป
ดังนั้นมีวิธีการอื่น ๆ อีกไหมละ ?
หนึ่งในวิธีการที่ขอแนะนำคือ Docker
ยิ่งที่โลกของ Data Science ยิ่งต้องใช้กัน
เนื่องจากมีเครื่องมือ และ library ต่าง ๆ เป็นจำนวนมาก
ถ้าเรามีชุดเครื่องมือเตรียมไว้ให้ทั้งหมด
จากนั้นแต่ละคนก็นำสิ่งที่เตรียมไว้ไปใช้งาน
น่าจะลดปัญหาไปได้เยอะ และน่าจะเริ่มงานได้อย่างรวดเร็ว
ปัญหาที่มักเจอเช่น Python 2.7 vs 3.x
คำถามคือ ลำบากไหมที่ต้องสลับ version ของ Python ไปมา !!
เลยยกตัวอย่างของการนำ Docker มาแก้ไขปัญหาเหล่านี้นิดหน่อย
เริ่มด้วยการสร้าง Docker Image สำหรับ Python 3 ขึ้นมาก่อน
มี library ที่ต้องการใช้คือ
ทำการกำหนด library เหล่านี้ไว้ในไฟล์ชื่อว่า requirements.txt
[gist id="e5bf51998c094843bcce62818defb2e2" file="requirements.txt"]
ทำการสร้าง Dockerfile ไว้ใช้สำหรับสร้าง Docker Image
มีขั้นตอนดังนี้
- เลือก base image เป็น Python 3.6.8
- กำหนด working directory
- ทำการ copy ไฟล์ requirements.txt เข้าไป
- ทำการ copy ไฟล์ทั้งหมดเข้าไป
- ทำการติดตั้ง library ต่าง ๆ ที่กำหนดไว้ในไฟล์ requirement.txt
- กำหนดให้ทำการ run คำสั่ง python app.py เพื่อทดสอบไฟล์ที่เราต้องการนั่นคือ app.py
[gist id="e5bf51998c094843bcce62818defb2e2" file="Dockerfile"]
เรายังขาดไฟล์ app.py ซึ่งเป็น code ทำงานของเรานั่นเอง
ตรงนี้เอาที่สบายใจเลย
เมื่อทุกอย่างเรียบร้อย ทำการสร้าง image จาก Dockerfile
และสร้าง container เพื่อทำงานตามที่ต้องการ ดังนี้
[code]
$docker image build -t my_python_3 .
$docker container run --rm my_python_3:latest
[/code]
เพียงเท่านี้ก็สามารถทำงานได้แล้ว
ง่ายมาก ๆ แต่ที่เหลือยากหมดเลย !!!
ขอยกตัวอย่าง Docker image ที่น่าสนจาก Kaggle
ประกอบไปด้วย
แต่ขนาดของ Docker image เหล่านี้จะมีขนาดใหญ่มาก ๆ
เนื่องจากมี library ต่าง ๆ เพียบนะครับ
ยกตัวอย่างเช่น kaggle/python มีขนาดกว่า 900 MB
ดังนั้นใช้งานแบบมีสตินะครับ
เพียงนำสิ่งเหล่านี้ไปใช้ ก็สามารถเริ่มในสิ่งที่ต้องการได้แล้ว
ถ้าใครไม่พอใจ ก็นำไปแก้ไขหรือสร้างใหม่ให้กับทีมได้เลยครับ
แต่สิ่งที่สำคัญคือ
ตอบรับกับความต้องการหรือการเปลี่ยนแปลงได้รวดเร็วเพียงใด
ลดผลกระทบจากการเปลี่ยนแปลงให้น้อยหรือไม่เกิดเลยได้อย่างไร
ขอให้สนุกกับการ coding ครับ

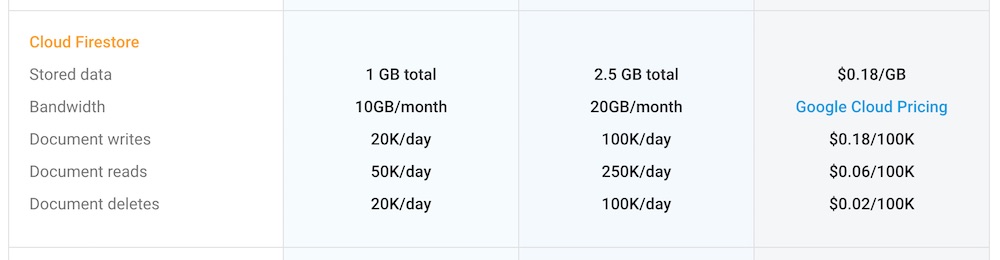
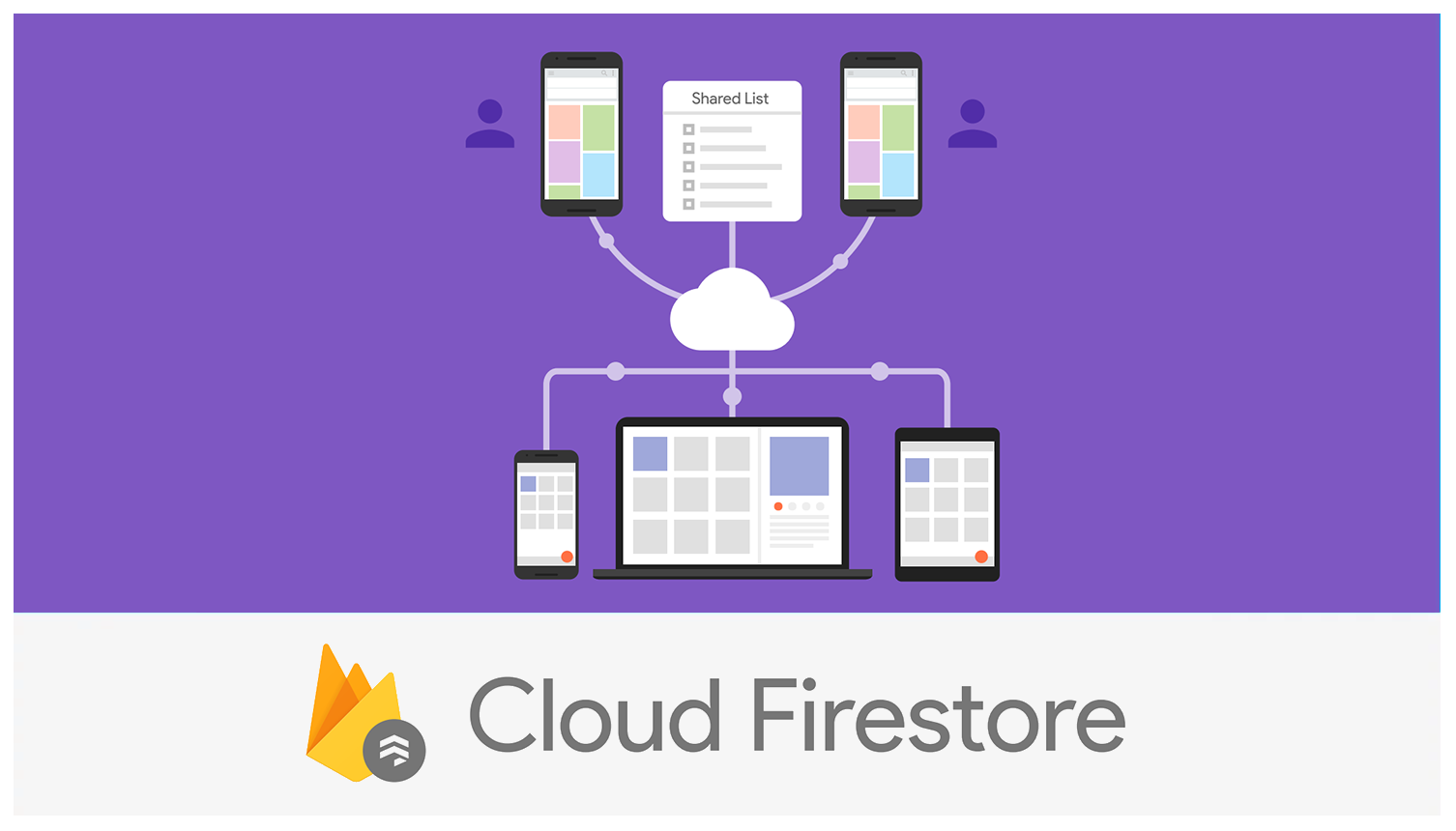 ทาง Firebase ได้ปล่อย Cloud Firestore ใน beta version
ซึ่งเป็น NoSQL database มีโครงสร้างข้อมูลแบบ Document
พูดง่าย ๆ คือโครงสร้างข้อมูลเดียวกับ MongoDB
แต่อยู่บน Cloud platform นั่นเอง
สามารถใช้ทั้ง iOS, Android และ Web
ตลอดจนสามารถ integate ได้กับของที่มีอยู่ใน Firebase ได้เลย
รวมทั้ง Google Cloud Platform, Cloud function
ยังไม่พอนะ
ตามแนวทางของ Firebase คือใช้ง่ายและรองรับการ scale อีกด้วย
ทาง Firebase ได้ปล่อย Cloud Firestore ใน beta version
ซึ่งเป็น NoSQL database มีโครงสร้างข้อมูลแบบ Document
พูดง่าย ๆ คือโครงสร้างข้อมูลเดียวกับ MongoDB
แต่อยู่บน Cloud platform นั่นเอง
สามารถใช้ทั้ง iOS, Android และ Web
ตลอดจนสามารถ integate ได้กับของที่มีอยู่ใน Firebase ได้เลย
รวมทั้ง Google Cloud Platform, Cloud function
ยังไม่พอนะ
ตามแนวทางของ Firebase คือใช้ง่ายและรองรับการ scale อีกด้วย
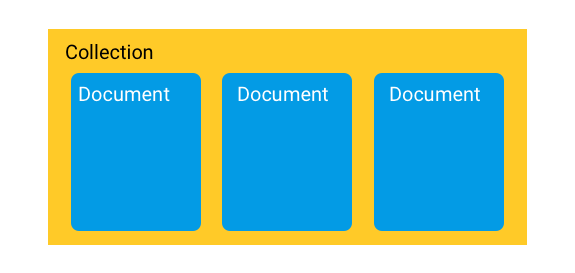 ในการพัฒนาระบบจะมี collection ที่สัมพันธ์กัน หรือ sub-collection
ทำให้การออกแบบง่ายขึ้น
ในการพัฒนาระบบจะมี collection ที่สัมพันธ์กัน หรือ sub-collection
ทำให้การออกแบบง่ายขึ้น
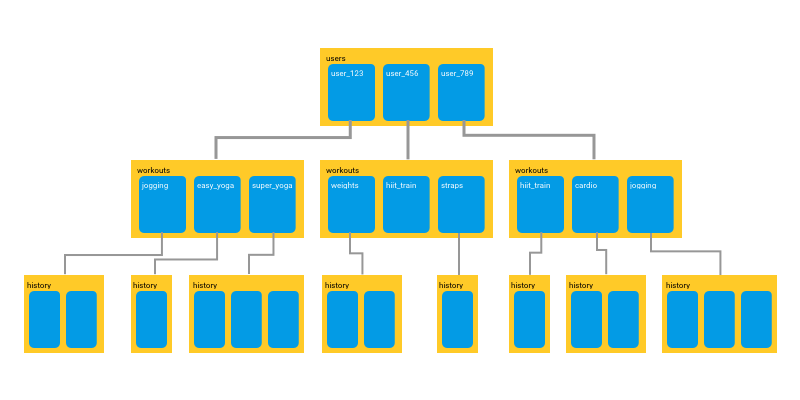 ในการดึงข้อมูล จะดึงเท่าที่จำเป็นเท่านั้น (shallow)
นั่นหมายความว่าไม่ต้องไปดึงข้อมูลที่สัมพันธ์กันมาทั้งหมด
ดังนั้นความสัมพันธ์ที่เราเห็นนั้น
มันเป็นแค่ในแง่ของ logical เท่านั้น
ซึ่งตรงนี้ส่งผลต่อประสิทธิภาพในการดึงข้อมูลอย่างมาก
ในการดึงข้อมูล จะดึงเท่าที่จำเป็นเท่านั้น (shallow)
นั่นหมายความว่าไม่ต้องไปดึงข้อมูลที่สัมพันธ์กันมาทั้งหมด
ดังนั้นความสัมพันธ์ที่เราเห็นนั้น
มันเป็นแค่ในแง่ของ logical เท่านั้น
ซึ่งตรงนี้ส่งผลต่อประสิทธิภาพในการดึงข้อมูลอย่างมาก
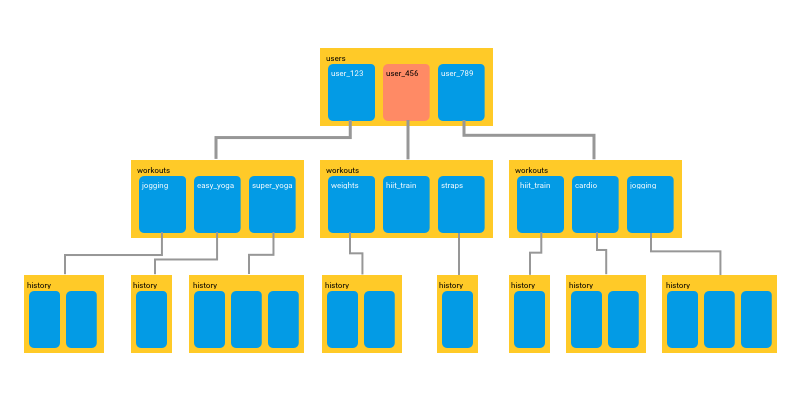 แถมมีคำแนะนำให้สร้าง index อีกด้วย
แถมมีคำแนะนำให้สร้าง index อีกด้วย
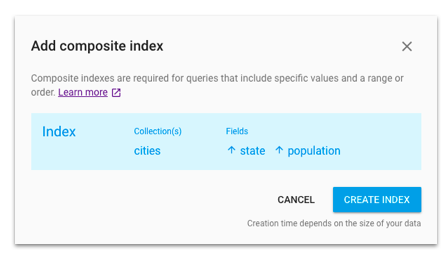 ส่วนเรื่อง security ก็มีมาให้
เพราะว่าได้เตรียมเรื่อง security rule มาให้พร้อมเลย
ทำให้สามารถควบคุมสิทธิ์ในการเข้าถึงข้อมูลได้
ส่วนเรื่อง security ก็มีมาให้
เพราะว่าได้เตรียมเรื่อง security rule มาให้พร้อมเลย
ทำให้สามารถควบคุมสิทธิ์ในการเข้าถึงข้อมูลได้
 ถ้ามีปัญหาอะไรก็ไปถามใน StackOverflow ได้
เพิ่มเติมสำหรับ Android Developer
https://www.youtube.com/watch?v=kDZYIhNkQoM
สำหรับชาว Web Developer
https://www.youtube.com/watch?v=2Vf1D-rUMwE
ขอให้สนุกกับการ coding นะครับ
ถ้ามีปัญหาอะไรก็ไปถามใน StackOverflow ได้
เพิ่มเติมสำหรับ Android Developer
https://www.youtube.com/watch?v=kDZYIhNkQoM
สำหรับชาว Web Developer
https://www.youtube.com/watch?v=2Vf1D-rUMwE
ขอให้สนุกกับการ coding นะครับ

 มีโอกาสคุยกับกลุ่มในสาย Data Science พบว่า
ปัญหาหลัก ๆ ของคนกลุ่มนี้คือ เรื่องการจัดการ environment ที่ใช้งาน
ประกอบไปด้วย
มีโอกาสคุยกับกลุ่มในสาย Data Science พบว่า
ปัญหาหลัก ๆ ของคนกลุ่มนี้คือ เรื่องการจัดการ environment ที่ใช้งาน
ประกอบไปด้วย

 วันนี้ไปร่วมงาน
วันนี้ไปร่วมงาน 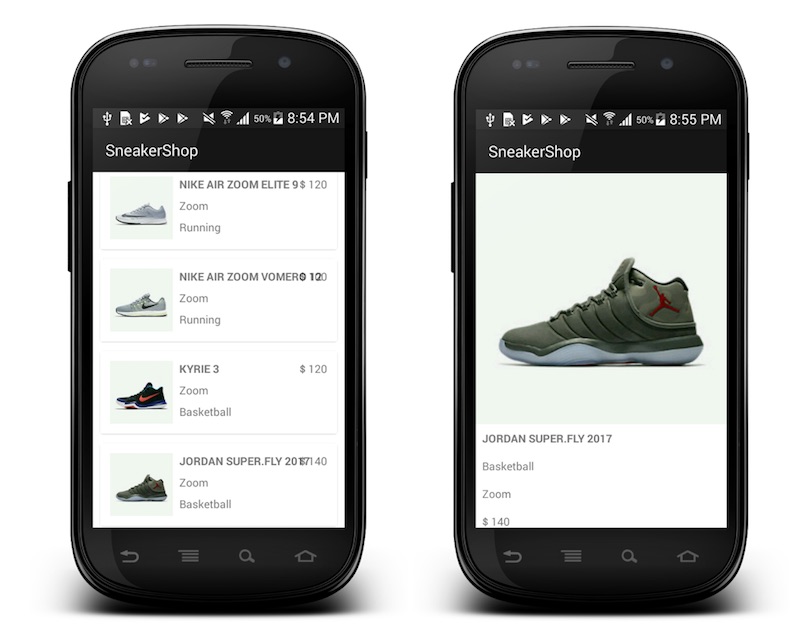

 ก่อนทำงานมานั่งสรุป extension ใน Google Chrome ที่ใช้งานเป็นประจำ
ซึ่งคิดว่าน่าจะมีประโยชน์สำหรับนักพัฒนาบ้าง
แต่เท่าที่ใช้มาคิดว่ามีประโยชน์
แถมช่วยเพิ่ม productivity ด้วยนะ
ลองมาดูว่ามีอะไรบ้าง
1.
ก่อนทำงานมานั่งสรุป extension ใน Google Chrome ที่ใช้งานเป็นประจำ
ซึ่งคิดว่าน่าจะมีประโยชน์สำหรับนักพัฒนาบ้าง
แต่เท่าที่ใช้มาคิดว่ามีประโยชน์
แถมช่วยเพิ่ม productivity ด้วยนะ
ลองมาดูว่ามีอะไรบ้าง
1. 
 ช่วงวันที่ 1 ถึง 5 ตุลาคมที่ผ่านมามีงานใหญ่ของโลก Java คือ
ช่วงวันที่ 1 ถึง 5 ตุลาคมที่ผ่านมามีงานใหญ่ของโลก Java คือ 
 เจอ Infographic เรื่อง
เจอ Infographic เรื่อง 









 จากการ์ตูนขำ ๆ เรื่อง
จากการ์ตูนขำ ๆ เรื่อง 

 UI Testing หรือ User Interface Testing
UI คือส่วนที่ผู้ใช้งานเห็น และใช้งาน
ทั้งการ click และ drag & drop ด้วย mouse
ทั้งการกดปุ่มใน keyboard
รูปแบบของ UI จะมี 2 แบบหลัก ๆ คือ
UI Testing หรือ User Interface Testing
UI คือส่วนที่ผู้ใช้งานเห็น และใช้งาน
ทั้งการ click และ drag & drop ด้วย mouse
ทั้งการกดปุ่มใน keyboard
รูปแบบของ UI จะมี 2 แบบหลัก ๆ คือ

 ในภาษาโปรแกรมต่าง ๆ ไม่ว่าจะเป็น Python, Swift, Scala, Clojure
ล้วนมีสิ่งที่เรียกว่า
ในภาษาโปรแกรมต่าง ๆ ไม่ว่าจะเป็น Python, Swift, Scala, Clojure
ล้วนมีสิ่งที่เรียกว่า 
 คำถามที่น่าสนใจสำหรับนักพัฒนา
code ของระบบงานมี
คำถามที่น่าสนใจสำหรับนักพัฒนา
code ของระบบงานมี 
 อ่านเจอเอกสารเกี่ยวกับ
อ่านเจอเอกสารเกี่ยวกับ 
 สำหรับนักพัฒนาที่เขียน test หรือชุดการทดสอบ นะ !!
มาดูกันว่า ชุดการทดสอบมันส่งกลิ่นแปลก ๆ บ้างหรือไม่ ?
ปกติ code ที่นักพัฒนาสร้างขึ้นมา
มักจะมีสิ่งแปลก ๆ
มักจะส่งกลิ่น หรือ ส่งสัญญาณของปัญหาออกมา
ซึ่งเราเรียกว่า
สำหรับนักพัฒนาที่เขียน test หรือชุดการทดสอบ นะ !!
มาดูกันว่า ชุดการทดสอบมันส่งกลิ่นแปลก ๆ บ้างหรือไม่ ?
ปกติ code ที่นักพัฒนาสร้างขึ้นมา
มักจะมีสิ่งแปลก ๆ
มักจะส่งกลิ่น หรือ ส่งสัญญาณของปัญหาออกมา
ซึ่งเราเรียกว่า 
 การสร้างชุดการทดสอบแบบอัตโนมัติระดับ User Interface ของ Android app นั้น
เป็นเรื่องที่สำคัญมาก ๆ โดยที่ทาง Android ก็ได้เตรียมเครื่องมือและ library ต่าง ๆ ไว้ให้ครบ
ยกตัวอย่างเช่น Espresso และ UIAutomator เป็น
ที่สำคัญยังมี opensource library อื่น ๆ อีก
ไม่ว่าจะเป็น Appium และ Calabash
ดังนั้นการสร้างชุดการทดสอบแบบอัตโนมัติจึงไม่ใช่เรื่องยากหรือเป็นไปไม่ได้เลย
การสร้างชุดการทดสอบแบบอัตโนมัติระดับ User Interface ของ Android app นั้น
เป็นเรื่องที่สำคัญมาก ๆ โดยที่ทาง Android ก็ได้เตรียมเครื่องมือและ library ต่าง ๆ ไว้ให้ครบ
ยกตัวอย่างเช่น Espresso และ UIAutomator เป็น
ที่สำคัญยังมี opensource library อื่น ๆ อีก
ไม่ว่าจะเป็น Appium และ Calabash
ดังนั้นการสร้างชุดการทดสอบแบบอัตโนมัติจึงไม่ใช่เรื่องยากหรือเป็นไปไม่ได้เลย

 อ่านบทความ
อ่านบทความ
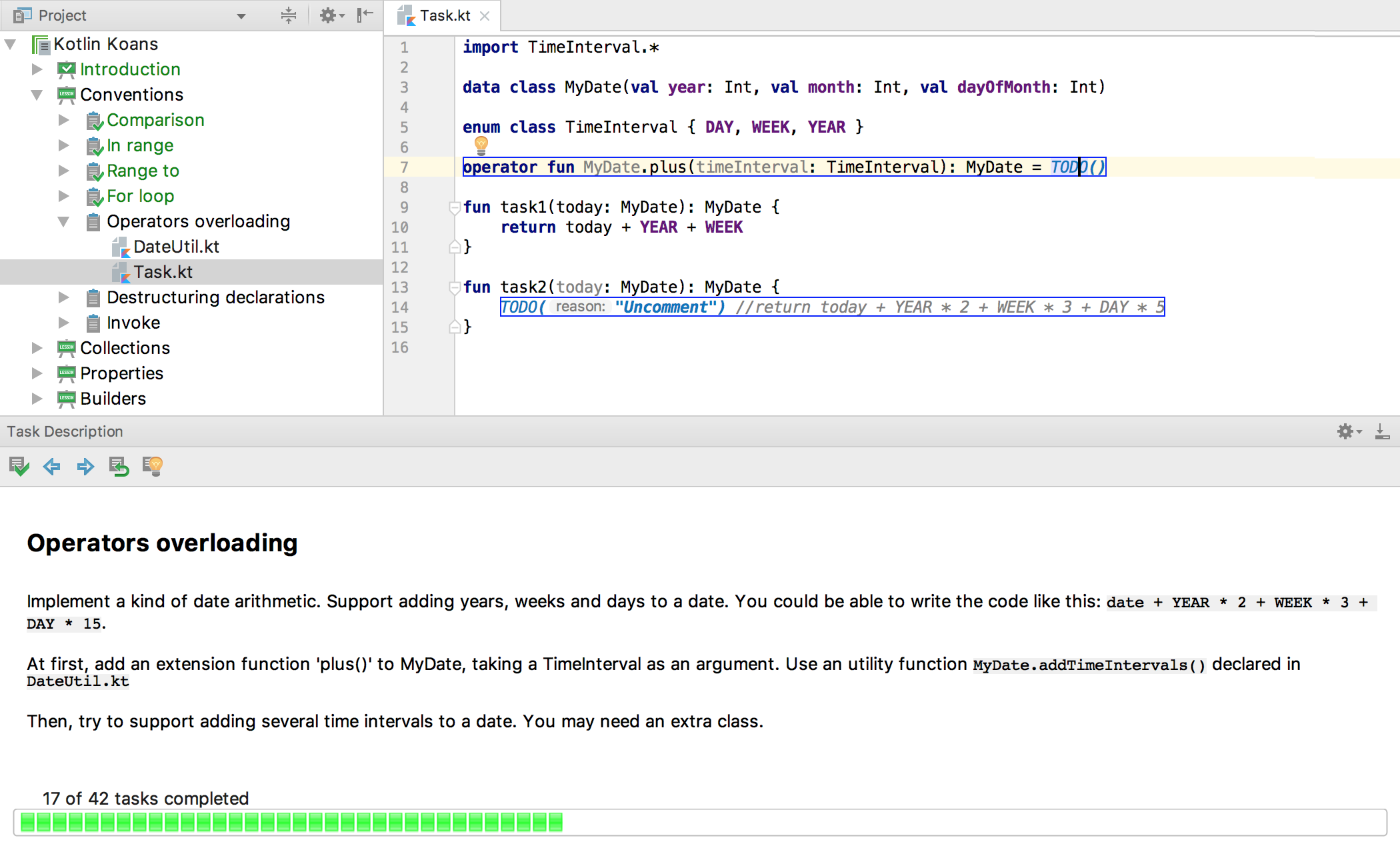 ขอให้สนุกกับการ coding นะครับ
ขอให้สนุกกับการ coding นะครับ

 ช่วงนี้นั่งไล่อ่านหนังสือเก่า ๆ ที่ดองไว้เพียบ
หนึ่งในนั้นคือ หนังสือ
ช่วงนี้นั่งไล่อ่านหนังสือเก่า ๆ ที่ดองไว้เพียบ
หนึ่งในนั้นคือ หนังสือ 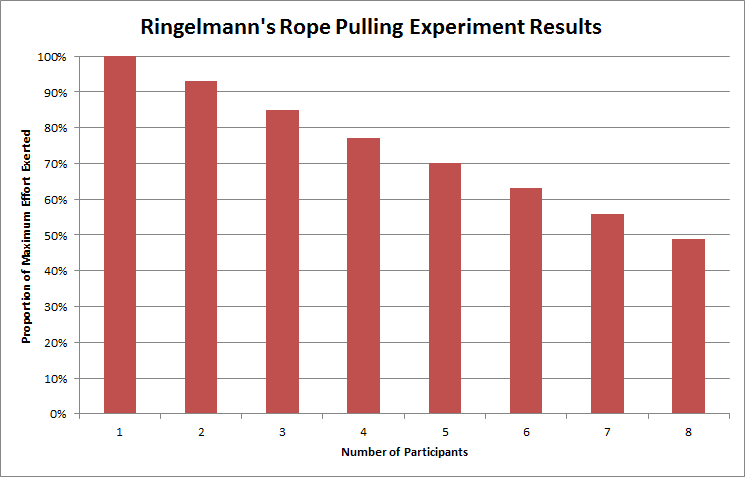 ถ้าผลเป็นแบบนี้เราทำงานเป็นทีมกันไปทำไม ?
ถ้างานที่ไม่ซับซ้อนก็ทำงานคนเดียวได้
แต่โชคไม่ดีที่งานส่วนใหญ่มันจะซับซ้อน
ถ้าผลเป็นแบบนี้เราทำงานเป็นทีมกันไปทำไม ?
ถ้างานที่ไม่ซับซ้อนก็ทำงานคนเดียวได้
แต่โชคไม่ดีที่งานส่วนใหญ่มันจะซับซ้อน




 จาก Post ใน
จาก Post ใน 

 วันนี้มีการพูดถึงเรื่อง
วันนี้มีการพูดถึงเรื่อง 
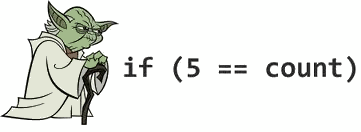
 หลัง ๆ มาจะมีเยอะเลย เช่น
หลัง ๆ มาจะมีเยอะเลย เช่น

 สิ่งมักที่น่าสนใจสำหรับการทดสอบแบบอัตโนมัติ
ส่วนใหญ่มักจะถูกสั่งให้ทำ
ส่วนใหญ่มักจะบังคับให้ทำ
บางครั้งทำแบบไม่เข้าใจว่าทำไมต้องทำ แต่ก็ต้องทำ
ผลที่ออกมาเลยไม่ดี หรือมีก็เหมือนไม่มี
หรือถ้าไม่บังคับก็ไม่ทำ
หรืออาจจะแย่กว่าเดิมอีกต่างหาก
ดังนั้นจึงขอแนะนำแนวทางที่คิดว่าน่าจะดี
เพื่อให้การทดสอบแบบ manual และ อัตโนมัติมันดีและยั่งยืน
มาเริ่มกันเลย
สิ่งมักที่น่าสนใจสำหรับการทดสอบแบบอัตโนมัติ
ส่วนใหญ่มักจะถูกสั่งให้ทำ
ส่วนใหญ่มักจะบังคับให้ทำ
บางครั้งทำแบบไม่เข้าใจว่าทำไมต้องทำ แต่ก็ต้องทำ
ผลที่ออกมาเลยไม่ดี หรือมีก็เหมือนไม่มี
หรือถ้าไม่บังคับก็ไม่ทำ
หรืออาจจะแย่กว่าเดิมอีกต่างหาก
ดังนั้นจึงขอแนะนำแนวทางที่คิดว่าน่าจะดี
เพื่อให้การทดสอบแบบ manual และ อัตโนมัติมันดีและยั่งยืน
มาเริ่มกันเลย

 จาก VDO เรื่อง Modernizing Java Apps with Docker จากงาน
จาก VDO เรื่อง Modernizing Java Apps with Docker จากงาน