![]()
![]()
การนำ
Docker มาใช้ในการพัฒนา software นั้นถือว่าเป็นสิ่งที่น่าสนใจมาก ๆ
บางคนอาจจะบอกว่า น่าจะเป็นความรู้พื้นฐานของนักพัฒนาเลยนะ
แต่ว่าการศึกษาสิ่งใหม่ ๆ ก็ไม่ใช่เรื่องที่ง่ายเลย
ดังนั้นจึงสรุปขั้นตอนการใช้งาน Docker เป็น comand line นะ
พร้อมยกตัวอย่างการใช้งานสำหรับการพัฒนาระบบด้วยภาษา Java
แนะนำการใช้งาน Docker แบบพื้นฐาน
Docker นั้นพัฒนาไปเร็วมาก
ทำให้มี ecosystem ขนาดใหญ่
แต่การศึกษาทั้งหมดเป็นเรื่องที่ไม่ง่าย และ ใช้เวลานานมาก
ดังนั้นใน blog นี้จะเน้นเรื่อง
การใช้งาน
Docker command line
โดยเน้นไปที่การใช้งาน command line ชุดใหม่
ซึ่งมีการปรับเปลี่ยนให้เป็นหมวดหมู่และง่ายต่อการจำมากขึ้น
ผลที่ตามมาคือ พิมพ์เยอะมากขึ้น
ใน blog นี้จะแบ่งชุดคำสั่งเป็นกลุ่ม ๆ
มาเริ่มกันเลย
1. การจัดการ image
Image คือต้นฉบับสำหรับการสร้าง container ต่าง ๆ
โดยที่เราสามารถทำการจัดการได้ดังนี้ เลือกคำสั่งที่ใช้บ่อย ๆ
- สร้าง image ใหม่ขึ้นมา กำหนดขั้นตอนการสร้างจาก Dockerfile
- ทำการลบ image
- ทำการดึง หรือ pull image มาจาก repository เช่น Docker Hub มายังเครื่องเราได้
- ทำการ push image ไปยัง repository
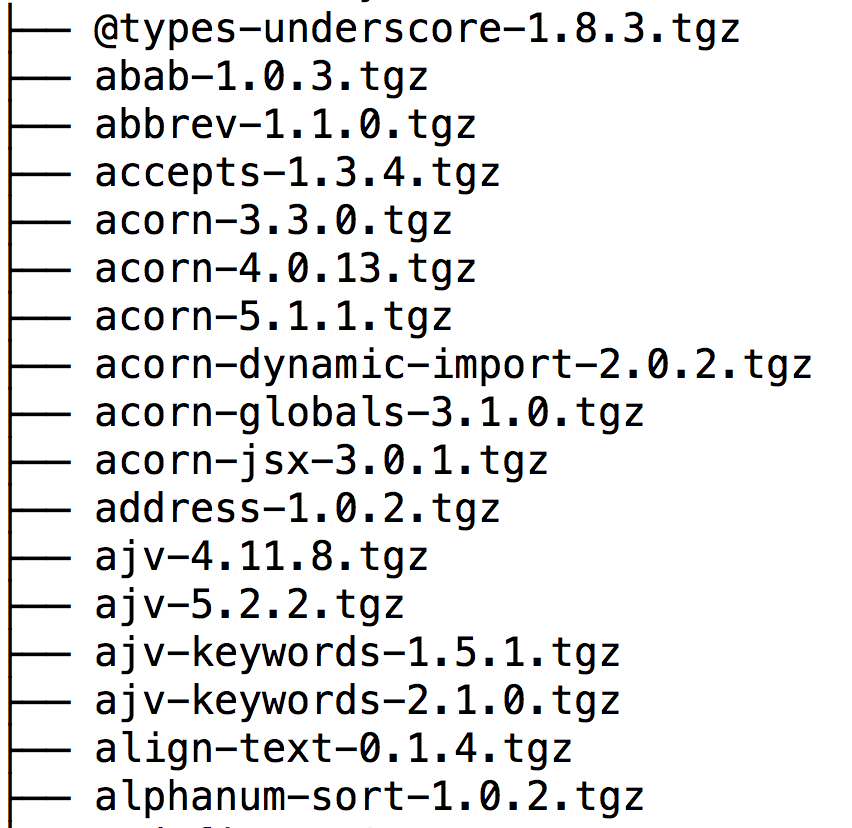
เริ่มต้นจากการเลือก image จาก Docker Hub หรือจาก Official ของสิ่งที่เราต้องการ
ยกตัวอย่างเช่น Java ก็มีให้เลือกทั้ง
OpenJDK และ
Oracle Java
อีกทั้งยังมีจาก community อีกนะ
เลือกได้ตามรสนิยมกันไปเลย
ทั้ง OS เช่น Ubuntu, Alpine เป็นต้น
โดยเราจะเรียกว่า
Base Image นั่นเอง
แสดงดังรูป
![]() เมื่อได้ image ที่ต้องการแล้ว ก็นำมาใช้ได้เลย
เมื่อได้ image ที่ต้องการแล้ว ก็นำมาใช้ได้เลย
สามารถทำการ download image ลงมาด้วยคำสั่ง
[code]
$docker image pull <ชื่อ image>:<ชื่อ tag>
[/code]
ยกตัวอย่างเช่นการใช้งาน image openjdk
ซึ่งมีให้เลือกมากมายทั้ง OS, JDK และ JRE
เราจะใช้งาน openjdk ด้วย tag 9-jdk ดังนี้
[code]
$docker image pull openjdk:9-jdk
[/code]
จากนั้นทำการดูว่า image ถูก download มายังเครื่องของเราหรือไม่
ด้วยคำสั่ง
[code]
$docker image ls
[/code]
ถ้าต้องการลบ image ให้ใช้คำสั่ง
[code]
$docker image rm <ชื่อ image>
[/code]
หรือถ้าต้องการลบ image ที่ไม่ถูกใช้งานเลย
สามารถใช้คำสั่งใหม่คือ
prune ดังนี้
[code]
$docker image prune
[/code]
นี่แค่เริ่มต้นคำสั่งจัดการ image เบื้องต้นเท่านั้น
แต่เพียงพอสำหรับผู้เริ่มต้น
เมื่อได้ image หรือ base image ที่ต้องการแล้ว
ถ้าเราไม่พอใจ สามารถทำการแก้ไขและสร้าง image ใหม่ขึ้นมา
เพื่อให้เหมาะสมกับระบบที่เราต้องการได้
สามารถกำหนดขั้นตอนการสร้าง image ผ่านไฟล์
Dockerfile
ตัวอย่างง่าย ๆ
ต้องการสร้าง image สำหรับการ compile และ run
โปรแกรมที่พัฒนาด้วยภาษา Java คือ javac และ java
มีขั้นตอนดังนี้
- เลือก Base image ซึ่งจะใช้ openjdk:9-jdk
- ทำการสร้าง working directory สำหรับจัดเก็บ source code
- กำหนด endpoint ให้ทำการ run bash shell ขึ้นมา
[gist id="07d5005207469bbe9c7d8da7ca5dd712" file="HelloDockerfile"]
สร้าง image จาก Dockerfile ด้วยคำสั่ง
[code]
$docker image build -t <ชื่อ image>:<ชื่อ tag> .
[/code]
จากตัวอย่างถ้าต้องการสร้าง image ชื่อว่า hello_java ทำได้ดังนี้
[code]
$docker image build -t hello_java .
[/code]
ส่วนการใช้งานต้องสร้าง container ขึ้นมาจาก image นี้ต่อไป
ยกตัวอย่างเช่น
[code]
$docker container run --name java_compile -v $(pwd)/src:/my_project —rm hello_java javac Hello.java
$docker container run --name java_run -v $(pwd)/src:/my_project —rm hello_java java Hello
[/code]
ชีวิตน่าจะดีขึ้น
ลองคิดดูสิว่า ถ้าเราต้องการ run java มากกว่า 1 version
เราจะต้องทำอย่างไร ?
ตัวอย่างที่ซับซ้อนขึ้น
ต้องการสร้าง image สำหรับระบบงานที่พัฒนาด้วยภาษา Java
และต้องทำการ compile และ build ด้วย Apache Maven
ดังนั้นเราต้องกำหนดขั้นตอนการสร้าง image ของเราดังนี้
- เลือก Base image ซึ่งจะใช้ openjdk:9-jdk
- ทำการติดตั้ง package ต่าง ๆ ที่จำเป็นนั่นคือ Apache Maven และ Vim เอาไว้แก้ไข code
- ทำการสร้าง working directory สำหรับจัดเก็บ source code
- กำหนด endpoint ให้ทำการ run bash shell ขึ้นมา
สามารถเขียนใน Dockerfile ได้ดังนี้
[gist id="07d5005207469bbe9c7d8da7ca5dd712" file="Dockerfile"]
ทำการสร้าง image ชื่อว่า my_image ใหม่จาก Dockerfile ด้วยคำสั่ง
[code]
$docker image build -t my_image .
[/code]
โดยการสร้าง image จะใช้เวลานานนิดหน่อย
ถ้าไม่ใสชื่อ tag เข้าไปจะมีค่า default เป็น latest นะ
เพียงเท่านี้เราก็ได้ image ใหม่มาใช้งานกันแล้ว
ในแต่ละบรรทัดของ Dockerfile นั่นหมายถึงจำนวน layer หรือชั้นของ image เราด้วย
สามารถดูได้ว่าแต่ละ image มี layer อะไรบ้างด้วยคำสั่ง
[code]
$docker image history <ชื่อ image>:<ชื่อ tag>
[/code]
เมื่อเราได้ image ที่ต้องการแล้ว
สามารถนำ image นี้ไปเก็บยัง repository ของ Docker ได้
ไม่ว่าจะเป็น Docker hub หรือ registry ของเราเอง ด้วยคำสั่ง
[code]
$docker image push <ชื่อ image>:<ชื่อ tag>
[/code]
มาถึงตรงนี้น่าจะพอทำให้เข้าใจเกี่ยวกับการจัดการ image ขั้นพื้นฐานบ้างแล้ว
แน่นอนว่ายังมีอีกเยอะนะ
แต่อยากขอแนะนำเพิ่มเติมเพื่อให้ศึกษาต่อคือ
2. การจัดการ container
หลังจากที่ได้ image ที่ต้องการแล้ว
สิ่งต่อมาที่จะต้องทำคือ การสร้าง container จาก image เหล่านั้น
เทียบง่าย ๆ คือ การสร้าง instance/object จาก class ใน OOP นั่นเอง
โดยทาง docker ได้เตรียม command line สำหรับการจัดการ container มาให้เพียบ
แต่เรามาใช้งานคำสั่งที่ใช้บ่อย ๆ กัน
เริ่มด้วยการสร้าง container จาก image
[code]
$docker container run<options> <ชื่อ image> <command> <arguments>
[/code]
จะเห็นได้ว่ามีให้ใส่ option ซึ่งมีเยอะมาก ๆ
ดังนั้นมาดูตัวอย่างกัน ใช้ image จากข้างต้น
- สร้าง container ชื่อ demo01
- สร้างจาก image ชื่อว่า my_image
- map path จากเครื่องของเราหรือเรียกว่า host ไปยัง container
- Run container แบบ foreground mode (แสดงว่ายังมี mode อื่นอีกเช่น interactive และ background เป็นต้น)
- ลบ container ทิ้งทันทีหลังจากทำงานเสร็จสิ้น
- Run คำสั่งของ Apache Maven เพื่อ compile และ build ระบบงาน
สร้าง container ด้วยคำสั่ง
[code]
$docker container run --name demo01 -v $(pwd)/src:/my_project --rm my_image mvn clean package
[/code]
เพียงเท่านี้ก็สร้าง container ได้แล้ว
และทำงานตาม command ของ Apache Maven ที่ต้องการ run
มันง่ายและสะดวกมาก ๆ สำหรับนักพัฒนา
ลองคิดดูว่า
ถ้าทุกคนในทีมพัฒนาใช้งาน image เดียวกัน
ถ้าทุกคนในทีมพัฒนาทำการสร้าง container เหมือนกัน
นั่นคือทุกคนมีขั้นตอนการทำงานเหมือนกัน
ที่สำคัญถ้า image นี้เหมือนกับสิ่งที่จะ deploy บน production server
ก็น่าจะลดปัญหาต่าง ๆ ได้มากมาย จริงไหม ?
ถ้าต้องการดูว่ามี container อะไรบ้างก็ใช้คำสั่ง
ตัวอย่างดู container ทั้งหมด ทุกสถานะ
[code]
$docker container ls -a
[/code]
ยังมีคำสั่งอื่น ๆ ที่ใช้จัดการ container ทั้ง stop/start/restart/rm
[code]
$docker container stop <ชื่อ container>
$docker container start <ชื่อ container>
$docker container restart <ชื่อ container>
$docker container rm <ชื่อ container>
[/code]
ถ้าต้องการลบ container ที่ไม่ทำงานสามารถใช้คำสั่ง prune ได้
[code]
$docker container prune
[/code]
ถ้าต้องการลบ container ทั้งหมด ทุกสถานะ
สามารถใช้คำสั่งนี้ได้เลย ใช้บ่อย
[code]
$docker container stop $(docker container ls -a -q)
$docker container rm $(docker container ls -a -q)
[/code]
ยังไม่พอนะ ยังมีชุดคำสั่งสำหรับดู stat/log การทำงานของแต่ละ container ได้อีกด้วย
[code]
$docker container stats <ชื่อ container>
$docker container top <ชื่อ container>
$docker container logs <ชื่อ container>
[/code]
เพียงเท่านี้ก็น่าจะเพียงพอสำหรับการเริ่มต้นจัดการ container นะ
3. การกำหนดจำนวน resource ต่าง ๆ ทั้ง CPU และ Memory ให้ container
[code]
$docker container update<options> container
[/code]
สำหรับชาว Java นั้นเรื่องนี้สำคัญมาก ๆ
เนื่องจากถ้ากำหนดไม่ดี และไม่เข้าใจการทำงานของ JVM แล้ว
ก็อาจเกิดข้อผิดพลาดได้
ยกตัวอย่างเช่นการใช้ resource เกินจำนวนที่กำหนด
สามารถดูปัญหาและการแก้ไขได้จาก
JVM is Docker-aware
คำสั่งสุดท้ายคือ การลบข้อมูลที่ไม่ใช้งานทิ้งไป
ลบทั้ง image, container, volume และ network
รวมไปถึง layer ของจากการสร้าง image อีกด้วย
ซึ่งทำให้เราได้พื้นที่ disk กลับคืนมาอย่างมากมาย
[code]
$docker system prune<options>
[/code]
แต่คำสั่งนี้ไม่ลบพวก container volume นะ
ถ้าอยากจะลบต้องเพิ่ม option -volume เข้าไปด้วย
เพียงเท่านี้น่าจะพอมีประโยชน์สำหรับผู้เริ่มต้นบ้างนะครับ
เริ่มต้นด้วย container เดียวก่อน น่าจะทำให้มีกำลังใจมากยิ่งขึ้น
จากนั้นก็นับสองสามสี่ต่อไปครับ
ยกตัวอย่างเรื่องที่ต้องศึกษาต่อเช่น
ถามว่าชุดคำสั่งเยอะไหม ?
ตอบเลยว่ามาก
ถามว่าต้องจำหมดไหม ?
ตอบเลยว่าไม่
ดังนั้นสิ่งที่สำคัญสุด ๆ ความเข้าใจ และ keyword ที่ต้องการ
ขอให้สนุกกับการ coding ครับ

 ปัญหาอย่างหนึ่งที่มักพบเจอกับทีมพัฒนาคือ
เครื่องผมเครื่องหนูมันทำงานได้นะ
แต่บนเครื่องจริง ๆ กลับทำงานไม่ถูกต้องหรือทำงานต่างกันไป
ไม่ว่าจะเหตุผลใดก็ตาม มันก็คือไม่ถูก
ปัญหาอย่างหนึ่งที่มักพบเจอกับทีมพัฒนาคือ
เครื่องผมเครื่องหนูมันทำงานได้นะ
แต่บนเครื่องจริง ๆ กลับทำงานไม่ถูกต้องหรือทำงานต่างกันไป
ไม่ว่าจะเหตุผลใดก็ตาม มันก็คือไม่ถูก
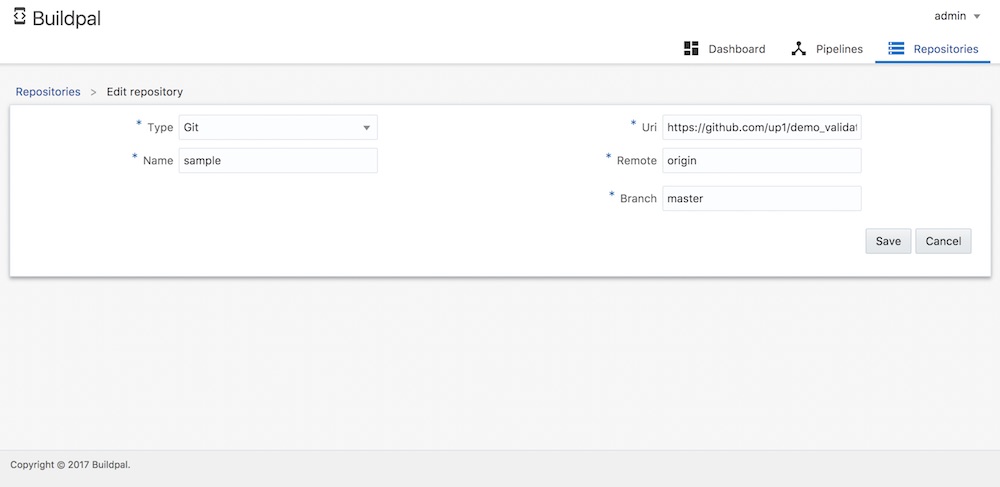 2. ทำการสร้าง Pipeline
สิ่งที่กำหนดคือ เลือก Repository ที่ต้องการ
เลือกใช้ image ที่ต้องการสำหรับสร้าง container
จากนั้นก็เข้าไป execute คำสั่งต่าง ๆใน container กันแบบสบาย ๆ
มาดูตัวอย่างของการใช้งาน Apache Maven เพื่อ compile + test ระบบแบบง่าย ๆ
แสดงดังรูป
2. ทำการสร้าง Pipeline
สิ่งที่กำหนดคือ เลือก Repository ที่ต้องการ
เลือกใช้ image ที่ต้องการสำหรับสร้าง container
จากนั้นก็เข้าไป execute คำสั่งต่าง ๆใน container กันแบบสบาย ๆ
มาดูตัวอย่างของการใช้งาน Apache Maven เพื่อ compile + test ระบบแบบง่าย ๆ
แสดงดังรูป
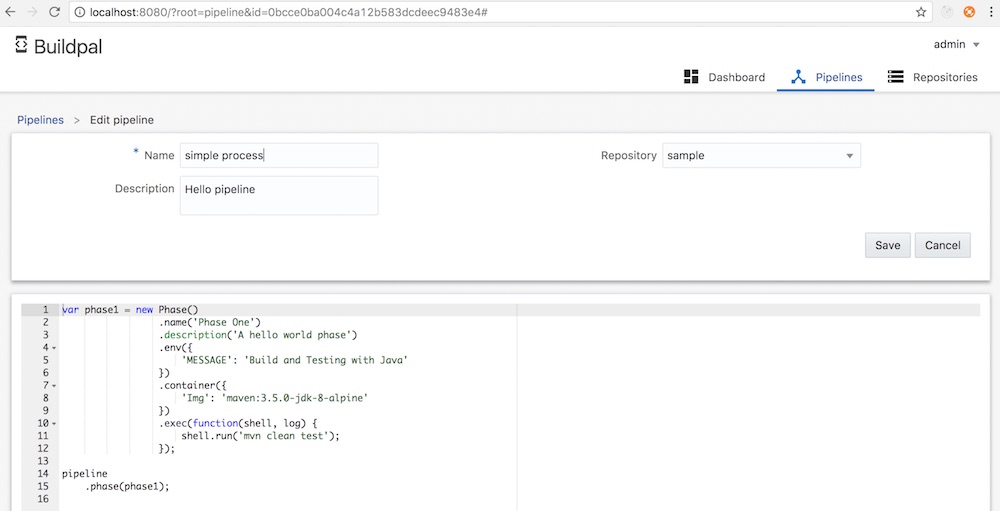 3. ผลการทำงานเป็นดังรูป
3. ผลการทำงานเป็นดังรูป
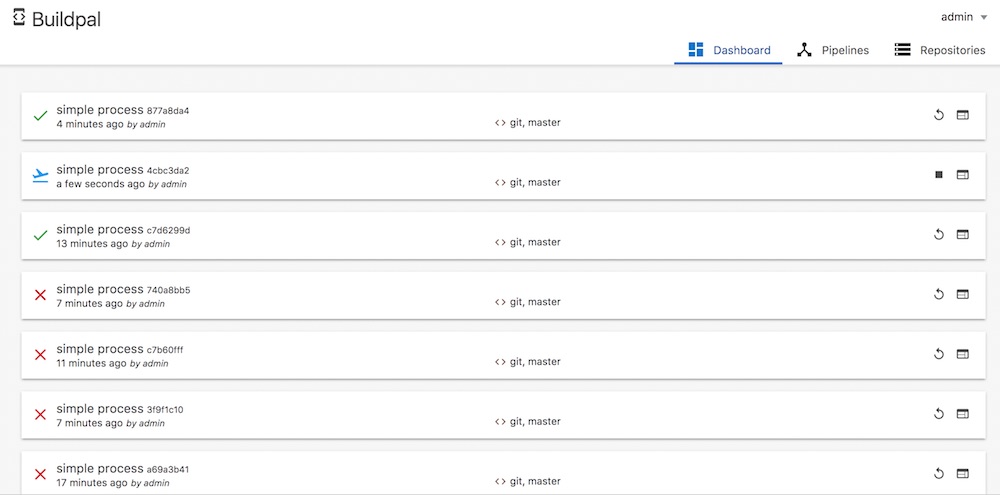 โดยรวม ๆ แล้วก็ใช้งานง่ายดีนะ
ทุกอย่างอยู่ในโลกของ container ด้วย Docker กันไปเลย
ลองใช้กันดูนะครับ
ไม่พอใจก็ลบ container ทิ้งไปซะ ง่ายสุด ๆ
ดังนั้นเครื่องใครก็สามารถทำได้นะครับ
ที่สำคัญถ้าทำ Image และไฟล์ต่าง ๆ ให้เหมือนกัน
ก็จะไม่เกิดปัญหาเครื่องผมทำงานได้นะ !!
ขอให้สนุกกับการ coding ครับ
โดยรวม ๆ แล้วก็ใช้งานง่ายดีนะ
ทุกอย่างอยู่ในโลกของ container ด้วย Docker กันไปเลย
ลองใช้กันดูนะครับ
ไม่พอใจก็ลบ container ทิ้งไปซะ ง่ายสุด ๆ
ดังนั้นเครื่องใครก็สามารถทำได้นะครับ
ที่สำคัญถ้าทำ Image และไฟล์ต่าง ๆ ให้เหมือนกัน
ก็จะไม่เกิดปัญหาเครื่องผมทำงานได้นะ !!
ขอให้สนุกกับการ coding ครับ

 จากบทความเรื่อง
จากบทความเรื่อง 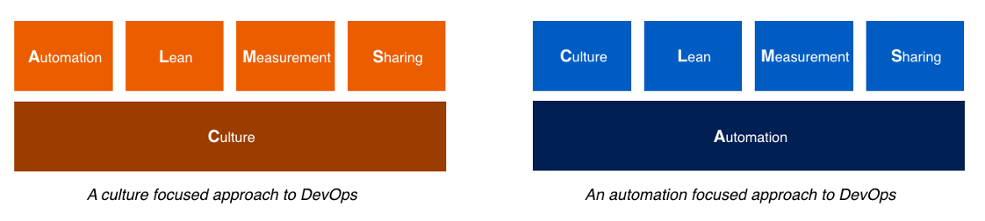 ปัญหาที่ตามมาจากการประยุกต์
จะแบ่งออกเป็น 3 เรื่องใหญ่ ๆ
ปัญหาที่ตามมาจากการประยุกต์
จะแบ่งออกเป็น 3 เรื่องใหญ่ ๆ
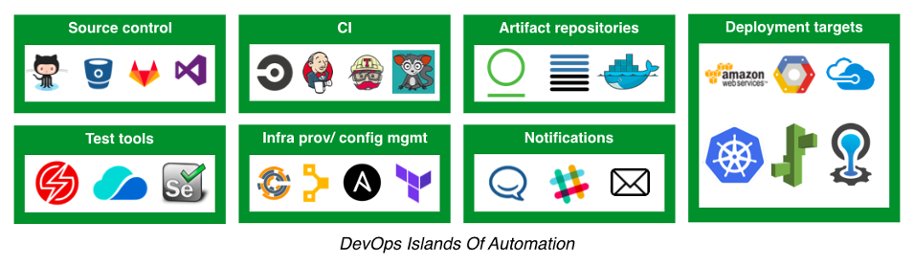
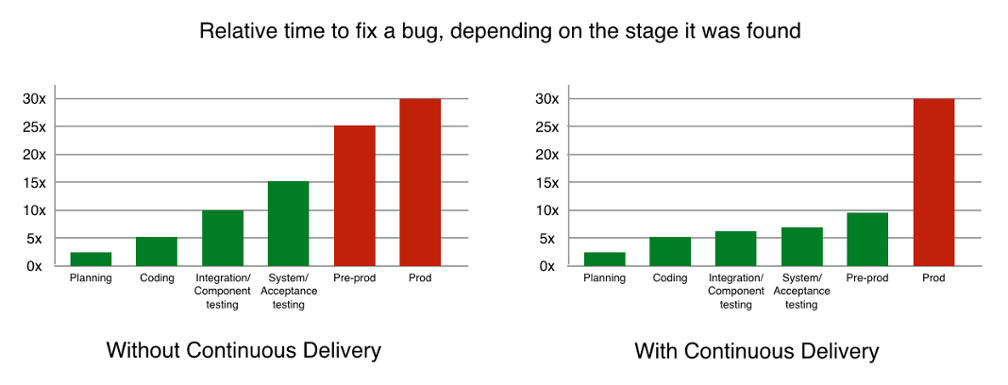 ดังนั้นในแนวคิด DevOps นั้นเรื่องของการทดสอบแบบอัตโนมัติ
จึงมีความสำคัญในลำดับต้น ๆ ของขั้นตอนการพัฒนาเลย
ดังนั้นในแนวคิด DevOps นั้นเรื่องของการทดสอบแบบอัตโนมัติ
จึงมีความสำคัญในลำดับต้น ๆ ของขั้นตอนการพัฒนาเลย

 ก่อนอื่นนักพัฒนาน่าจะคุ้นเคยกับการจัดการเรื่องของ configuration ค่าต่าง ๆ ในระบบ
ยกตัวอย่างเช่น
ก่อนอื่นนักพัฒนาน่าจะคุ้นเคยกับการจัดการเรื่องของ configuration ค่าต่าง ๆ ในระบบ
ยกตัวอย่างเช่น

 ทางทีมพัฒนา Kotlin เพิ่งปล่อย
ทางทีมพัฒนา Kotlin เพิ่งปล่อย  เช้านี้อ่านเจอการพูดคุยเรื่องของความแตกต่างระหว่าง Method และ Computed property ใน
เช้านี้อ่านเจอการพูดคุยเรื่องของความแตกต่างระหว่าง Method และ Computed property ใน 
 วันนี้
วันนี้  วันนี้นั่งดู code ช่วงบ่ายในขณะที่ฝนกำลังถล่ม กทม
เจอชุด comment ที่น่าสนใจ ซึ่งนักพัฒนาทุกคนน่าจะเคยเห็นผ่านตามาแล้ว
ทั้งเกิดจากการ generate แบบอัตโนมัติจาก IDE
ทั้งเขียนจากคนอื่น รวมทั้งตัวเราเองด้วย
นั่นคือ TODO และ FIXME
คำถามที่น่าสนใจคือ
วันนี้นั่งดู code ช่วงบ่ายในขณะที่ฝนกำลังถล่ม กทม
เจอชุด comment ที่น่าสนใจ ซึ่งนักพัฒนาทุกคนน่าจะเคยเห็นผ่านตามาแล้ว
ทั้งเกิดจากการ generate แบบอัตโนมัติจาก IDE
ทั้งเขียนจากคนอื่น รวมทั้งตัวเราเองด้วย
นั่นคือ TODO และ FIXME
คำถามที่น่าสนใจคือ

 วันนี้เข้าไปที่
วันนี้เข้าไปที่ 

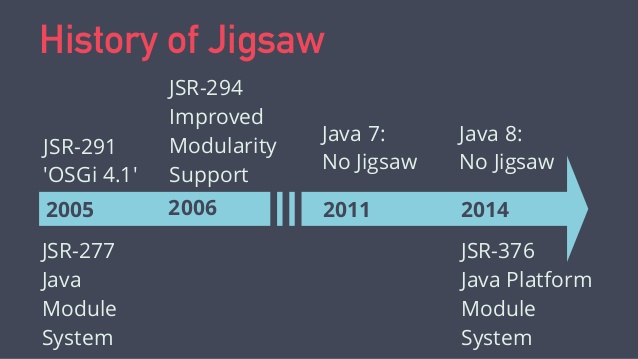 แต่ใน Java 9 ก็ออกมาแล้ว
มันคือ การเปลี่ยนแปลงครั้งสำคัญของ Java กันเลยทีเดียว
ทำให้ Java เป็น modular ง่ายขึ้น
อีกทั้งยังช่วยลดขนาดของ JRE ลงอีกด้วย
รวมทั้งสามารถ custom เฉพาะสิ่งที่ต้องการใช้อีกด้วย
อะไรที่ไม่ใช้ก็เอาออกไป
แต่ใน Java 9 ก็ออกมาแล้ว
มันคือ การเปลี่ยนแปลงครั้งสำคัญของ Java กันเลยทีเดียว
ทำให้ Java เป็น modular ง่ายขึ้น
อีกทั้งยังช่วยลดขนาดของ JRE ลงอีกด้วย
รวมทั้งสามารถ custom เฉพาะสิ่งที่ต้องการใช้อีกด้วย
อะไรที่ไม่ใช้ก็เอาออกไป

 เมื่อหลายวันก่อนพูดคุยเกี่ยวกับ Unit testing
เลยได้มีโอกาสแลกเปลี่ยนมุมมองต่อการเขียนและการนำมาใช้งานนิดหน่อย
ซึ่งสิ่งหนึ่งที่น่าสนใจคือ ความเข้าใจผิด
ยกตัวอย่างเช่น
เมื่อหลายวันก่อนพูดคุยเกี่ยวกับ Unit testing
เลยได้มีโอกาสแลกเปลี่ยนมุมมองต่อการเขียนและการนำมาใช้งานนิดหน่อย
ซึ่งสิ่งหนึ่งที่น่าสนใจคือ ความเข้าใจผิด
ยกตัวอย่างเช่น

 อ่าน
อ่าน 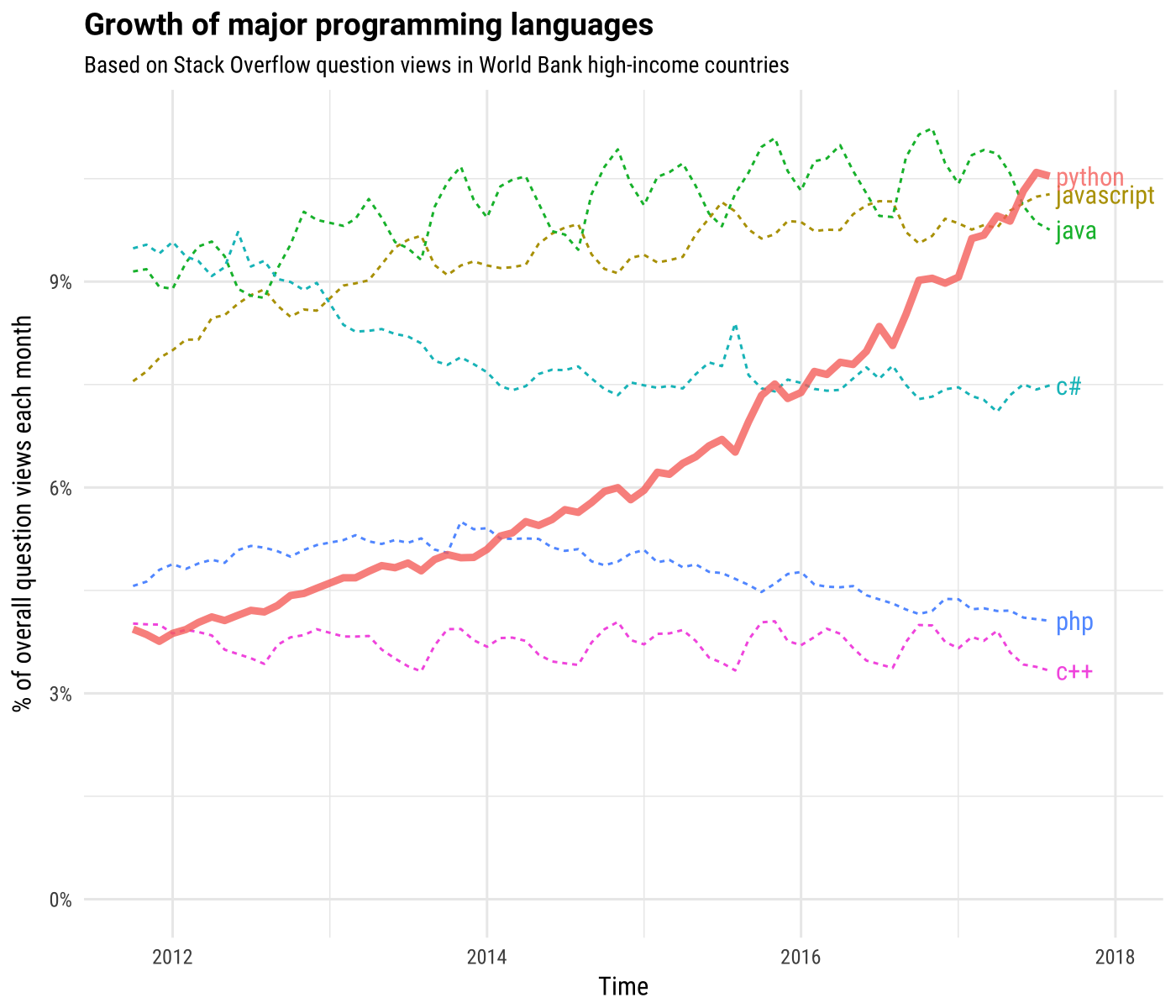
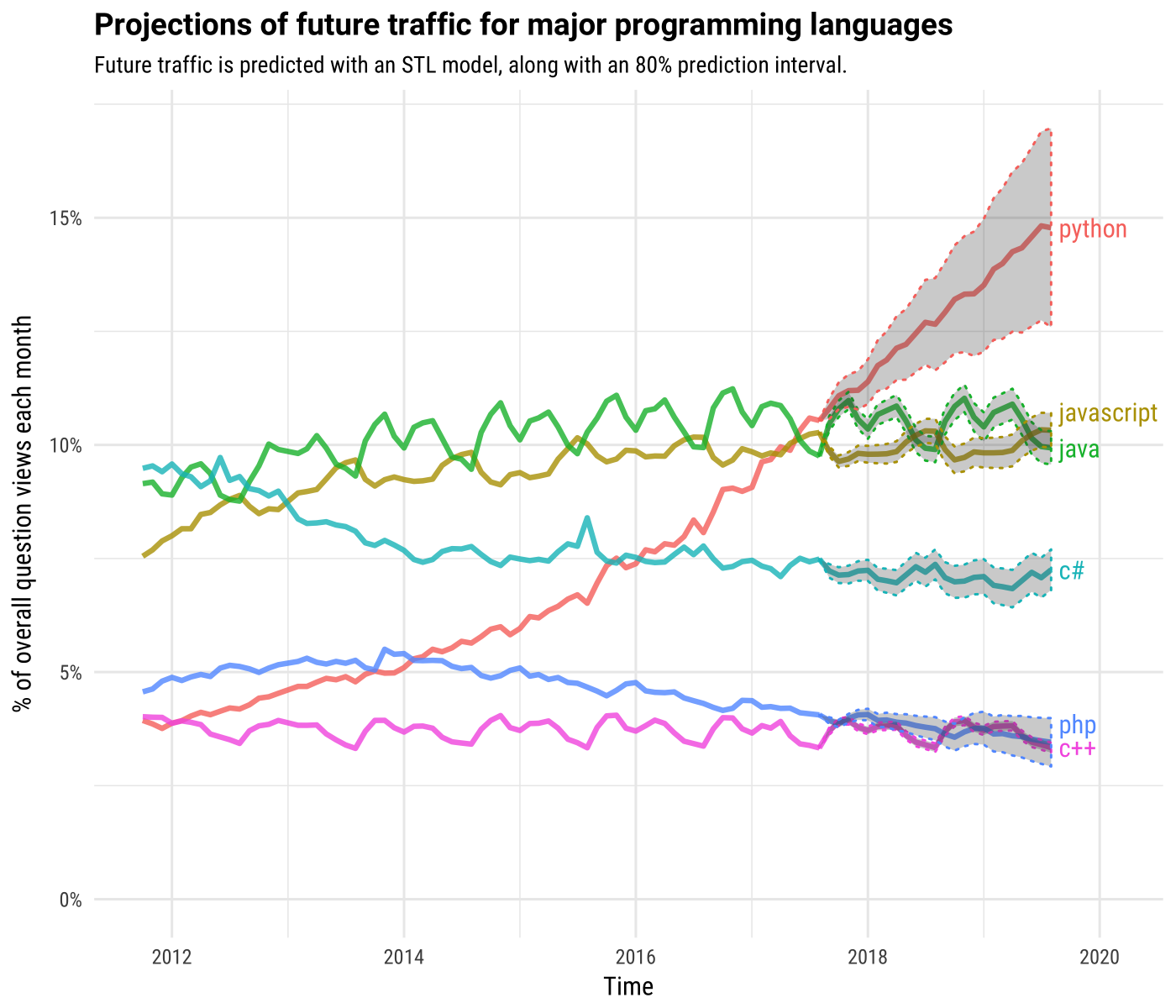
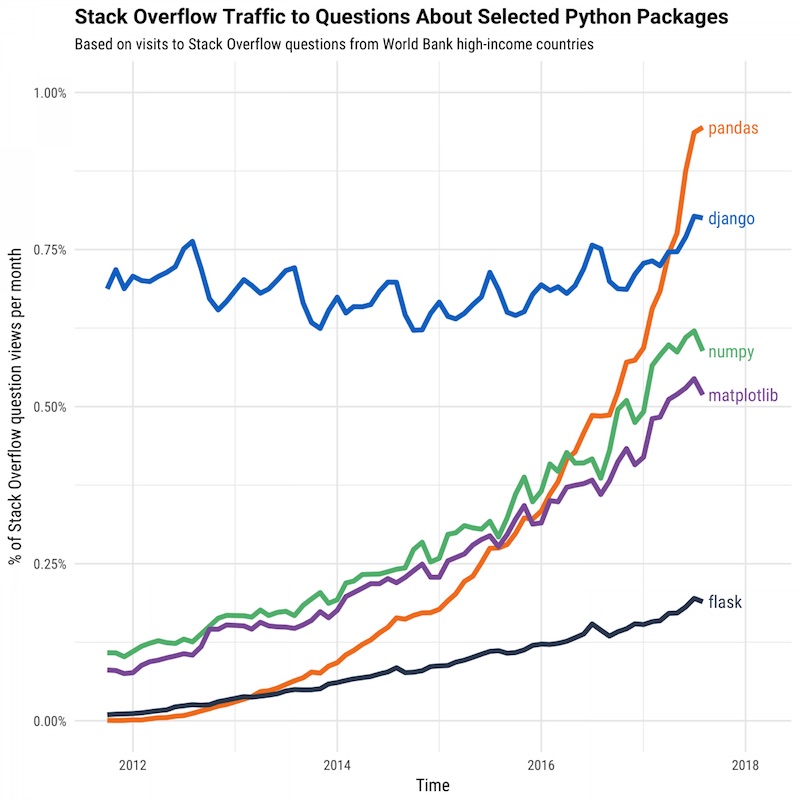
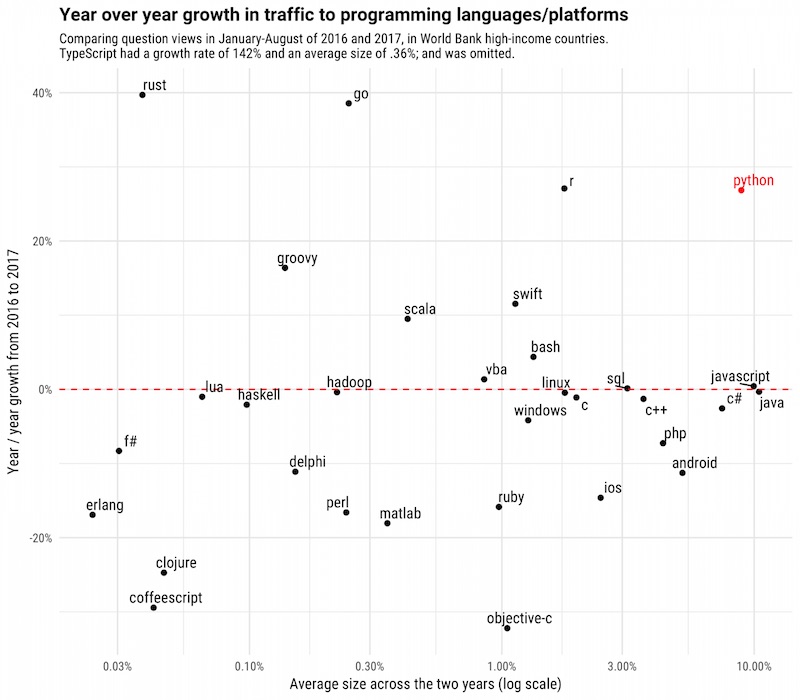
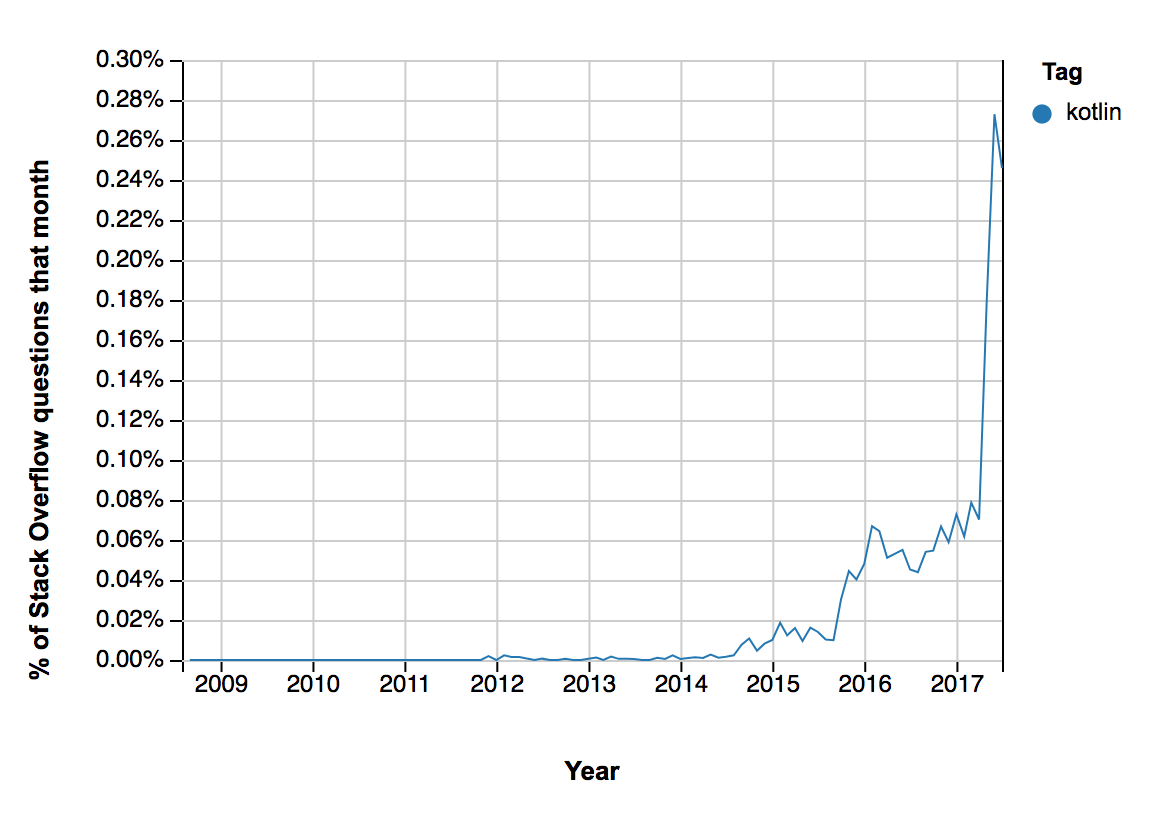
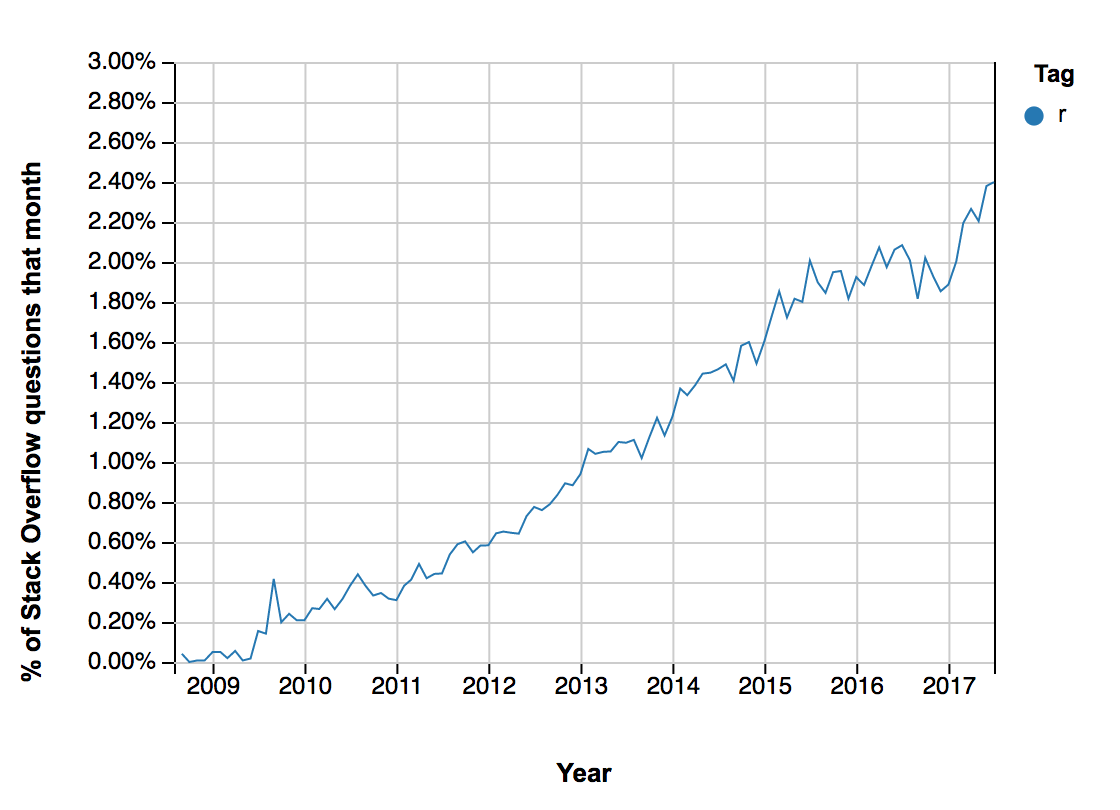
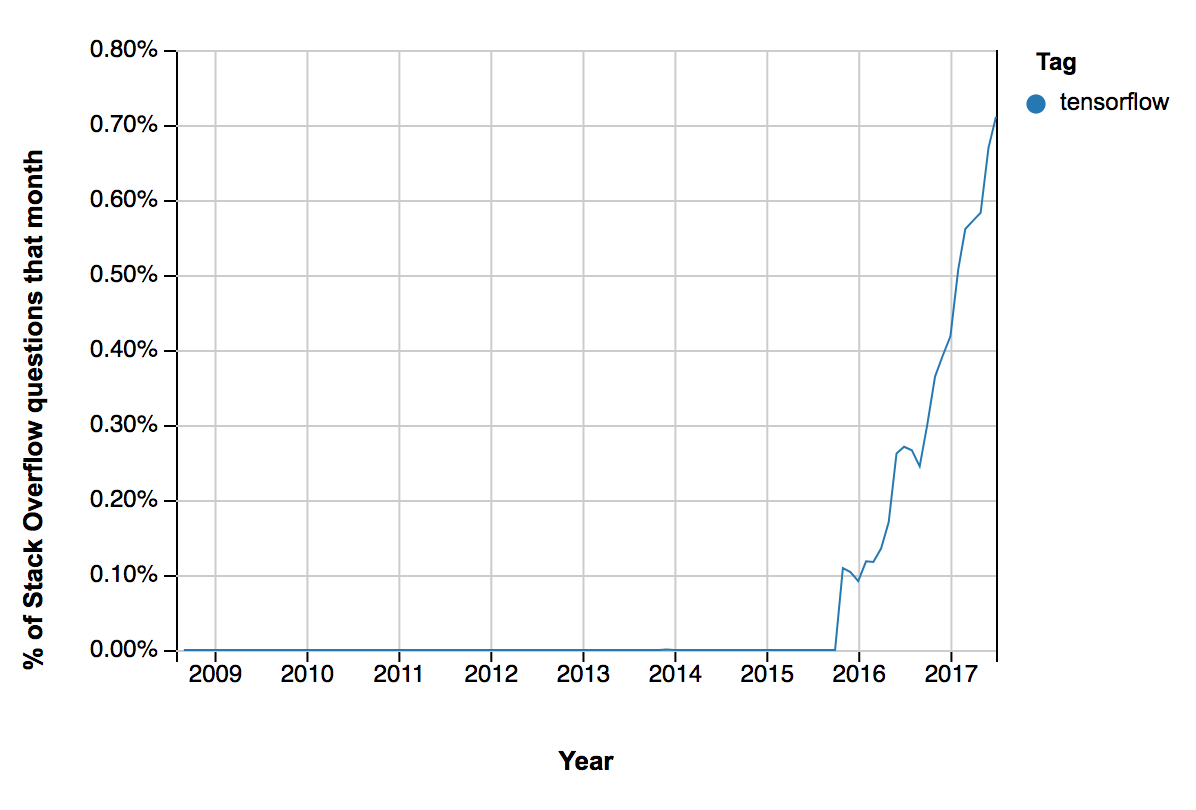
 น่าจะเป็นประโยชน์สำหรับนักพัฒนาบ้างนะครับ
Reference Websites
น่าจะเป็นประโยชน์สำหรับนักพัฒนาบ้างนะครับ
Reference Websites

 การนำ
การนำ 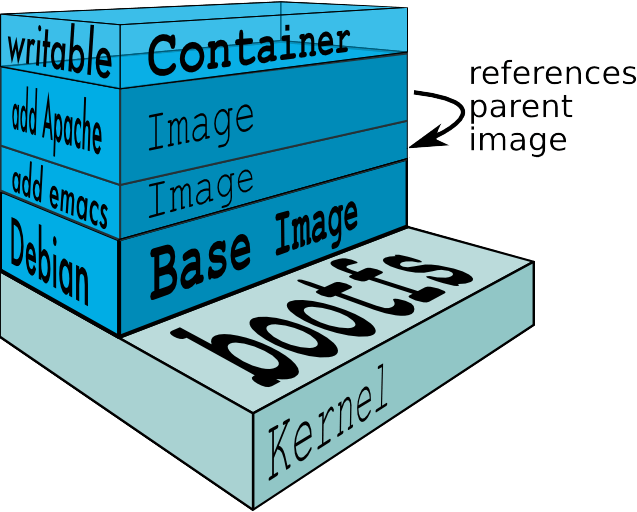 เมื่อได้ image ที่ต้องการแล้ว ก็นำมาใช้ได้เลย
สามารถทำการ download image ลงมาด้วยคำสั่ง
[code]
$docker image pull <ชื่อ image>:<ชื่อ tag>
[/code]
ยกตัวอย่างเช่นการใช้งาน image
เมื่อได้ image ที่ต้องการแล้ว ก็นำมาใช้ได้เลย
สามารถทำการ download image ลงมาด้วยคำสั่ง
[code]
$docker image pull <ชื่อ image>:<ชื่อ tag>
[/code]
ยกตัวอย่างเช่นการใช้งาน image 
 สิ่งที่นักพัฒนาน่าจะต้องรู้สำหรับการพัฒนาระบบงานในปัจจุบัน
นั่นก็คือ
สิ่งที่นักพัฒนาน่าจะต้องรู้สำหรับการพัฒนาระบบงานในปัจจุบัน
นั่นก็คือ 
 เห็นข่าว
เห็นข่าว 


 ระหว่างนั่งรอเครื่องบินไปจังหวัดเชียงใหม่
เจอข้อมูลที่น่าสนใจจาก sensor เกี่ยวกับสภาวะอากาศ
จึงนำมาใช้ฝึกการ cleaning ข้อมูลด้วย
ระหว่างนั่งรอเครื่องบินไปจังหวัดเชียงใหม่
เจอข้อมูลที่น่าสนใจจาก sensor เกี่ยวกับสภาวะอากาศ
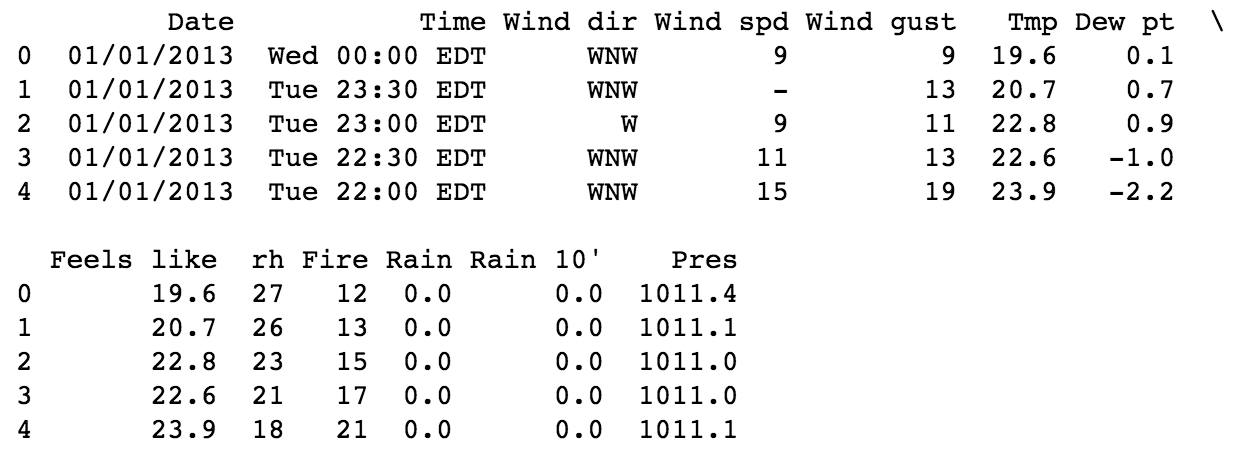
จึงนำมาใช้ฝึกการ cleaning ข้อมูลด้วย  ทำไมมันมีเพียง 1 column ละ ?
จะเห็นได้ว่าข้อมูลในแต่ละ column แบ่งด้วย tab (\t)
ดังนั้นต้องใส่ parameter เพื่อกำหนดตัวแยกหรือ separator เป็น tab (\t)
เพิ่มเติมใน function read_csv() นั่นเอง ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="2.py"]
ผลที่ได้เป็นดังนี้
ซึ่งจะแยกข้อมูลออกเป็น column ตามที่ต้องการ
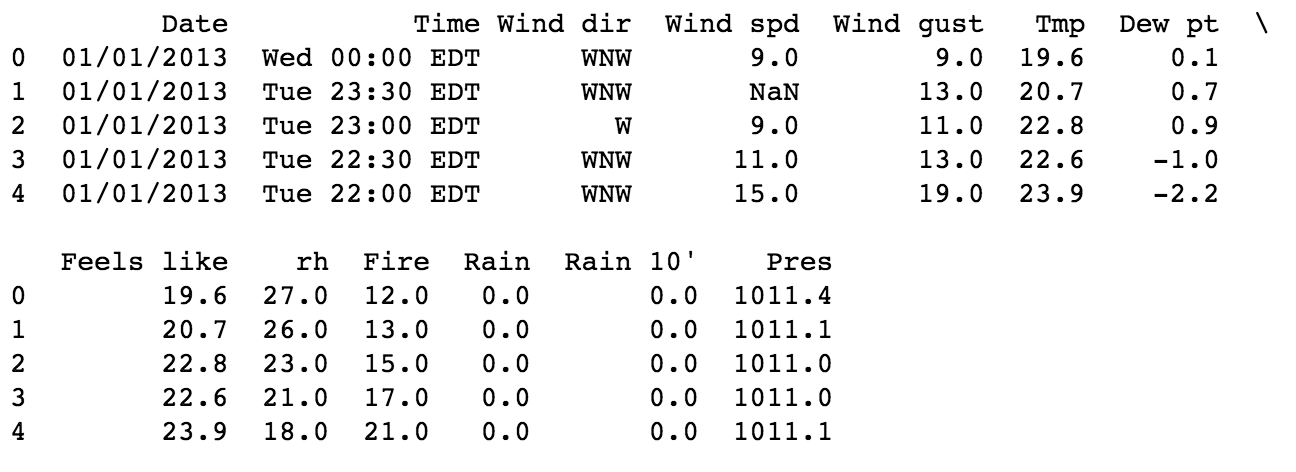
ทำไมมันมีเพียง 1 column ละ ?
จะเห็นได้ว่าข้อมูลในแต่ละ column แบ่งด้วย tab (\t)
ดังนั้นต้องใส่ parameter เพื่อกำหนดตัวแยกหรือ separator เป็น tab (\t)
เพิ่มเติมใน function read_csv() นั่นเอง ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="2.py"]
ผลที่ได้เป็นดังนี้
ซึ่งจะแยกข้อมูลออกเป็น column ตามที่ต้องการ
 จากข้อมูลจะพบว่า มีข้อมูลบางตัวเป็นค่า (-) หรือไม่มีข้อมูลนั่นเอง
ดังนั้นสิ่งที่ต้องคิดและวิเคราะห์คือ จะเปลี่ยนเป็นอะไร เช่น NaN (Not a Number) เป็นต้น
แน่นอนว่า เราสามารถกำหนดใน function read_csv() ได้ ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="2.py"]
ได้ผลการทำงานดังนี้
จากข้อมูลจะพบว่า มีข้อมูลบางตัวเป็นค่า (-) หรือไม่มีข้อมูลนั่นเอง
ดังนั้นสิ่งที่ต้องคิดและวิเคราะห์คือ จะเปลี่ยนเป็นอะไร เช่น NaN (Not a Number) เป็นต้น
แน่นอนว่า เราสามารถกำหนดใน function read_csv() ได้ ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="2.py"]
ได้ผลการทำงานดังนี้
 มาถึงตรงนี้ สิ่งที่แปลก ๆ หน่อยคือ column Date และ Time แยกกัน !!
คำถามที่เกิดขึ้นมาคือ
มีการใช้งานข้อมูล Date และ Time หรือไม่ ? และใช้อย่างไร ?
ถ้าบอกว่าต้องใช้งาน และ จำเป็นต้องรวมทั้งสองให้เป็น column เดียวคือ DateTime
ก็สามารถทำใน function read_csv() ได้เช่นกัน
มาถึงตรงนี้ สิ่งที่แปลก ๆ หน่อยคือ column Date และ Time แยกกัน !!
คำถามที่เกิดขึ้นมาคือ
มีการใช้งานข้อมูล Date และ Time หรือไม่ ? และใช้อย่างไร ?
ถ้าบอกว่าต้องใช้งาน และ จำเป็นต้องรวมทั้งสองให้เป็น column เดียวคือ DateTime
ก็สามารถทำใน function read_csv() ได้เช่นกัน
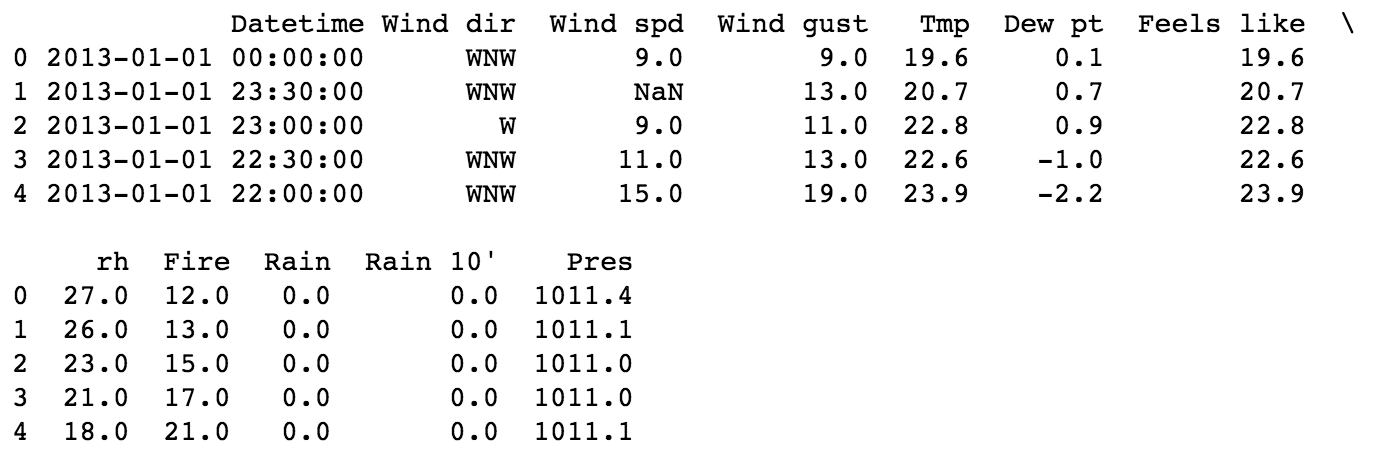 ทำการเรียงข้อมูลกันหน่อย
เนื่องจากข้อมูลของ sensor นั้น จะอยู่ในรูปแบบของ Time-serie
ดังนั้นสิ่งที่เราต้องทำคือ เรียงข้อมูลด้วย Datetime (index)
ซึ่งสามารถเขียน code ได้ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="5.py"]
แสดงผลการทำงานดังนี้
ทำการเรียงข้อมูลกันหน่อย
เนื่องจากข้อมูลของ sensor นั้น จะอยู่ในรูปแบบของ Time-serie
ดังนั้นสิ่งที่เราต้องทำคือ เรียงข้อมูลด้วย Datetime (index)
ซึ่งสามารถเขียน code ได้ดังนี้
[gist id="b055f158ce622d0a1d2d145523774309" file="5.py"]
แสดงผลการทำงานดังนี้
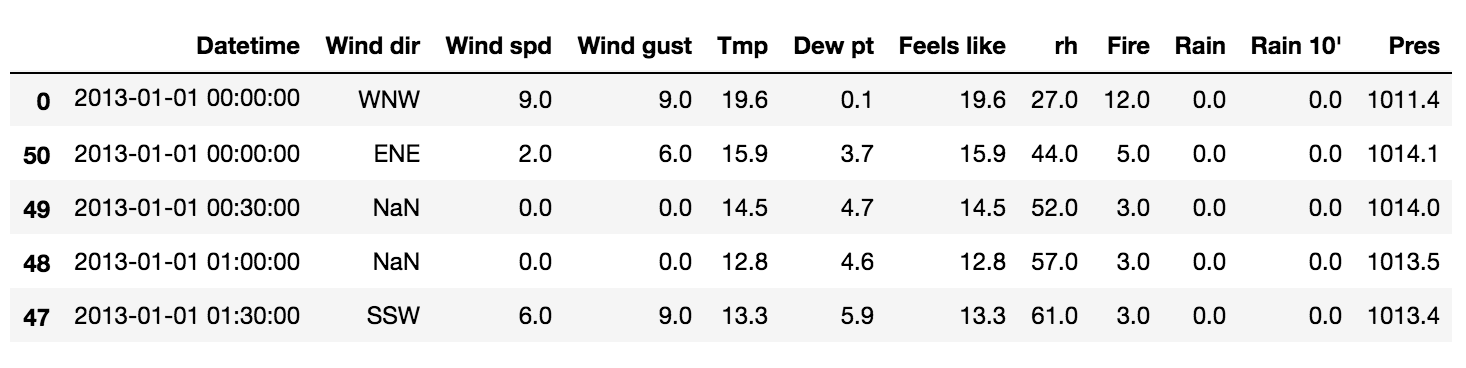 เมื่อลองสังเกตุจะเห็นว่าข้อมูล Datetime มีซ้ำด้วย !!
ทำการตรวจสอบในทุก ๆ วันพบว่ามีเวลาซ้ำกันคือ 00:00:00 (เที่ยงคืน)
เป็นข้อมูลของการเริ่มวันและสิ้นวัน
เมื่อลองสังเกตุจะเห็นว่าข้อมูล Datetime มีซ้ำด้วย !!
ทำการตรวจสอบในทุก ๆ วันพบว่ามีเวลาซ้ำกันคือ 00:00:00 (เที่ยงคืน)
เป็นข้อมูลของการเริ่มวันและสิ้นวัน
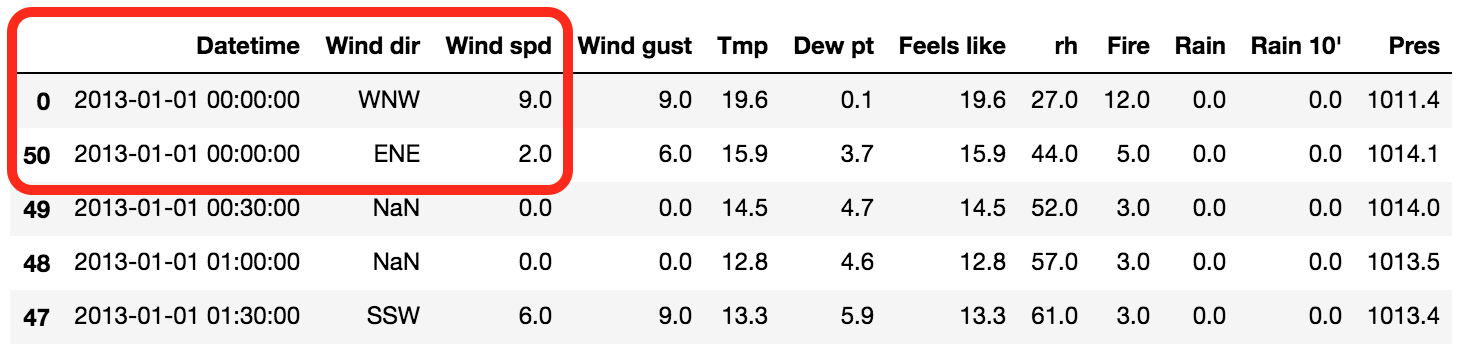 ดังนั้นทำการแก้ไขข้อมูลที่ซ้ำกันก่อน
โดยสามารถเลือกได้ว่าจะเก็บข้อมูลแรกหรือสุดท้าย
[gist id="b055f158ce622d0a1d2d145523774309" file="6.py"]
ได้ผลการทำงานดังนี้
ดังนั้นทำการแก้ไขข้อมูลที่ซ้ำกันก่อน
โดยสามารถเลือกได้ว่าจะเก็บข้อมูลแรกหรือสุดท้าย
[gist id="b055f158ce622d0a1d2d145523774309" file="6.py"]
ได้ผลการทำงานดังนี้
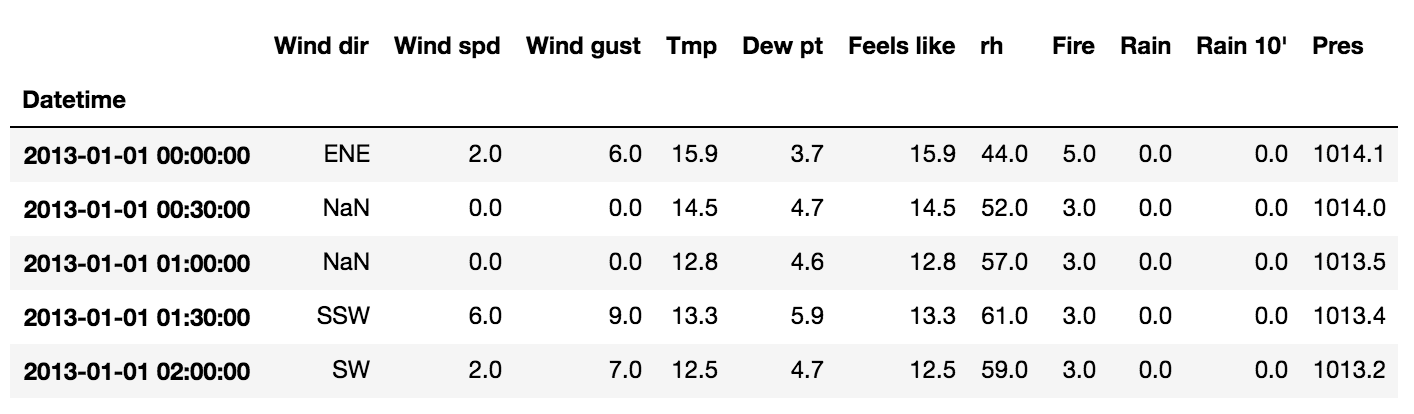 มาถึงตรงนี้น่าจะเรียงข้อมูลได้ดีพอประมาณ
มาถึงตรงนี้น่าจะเรียงข้อมูลได้ดีพอประมาณ
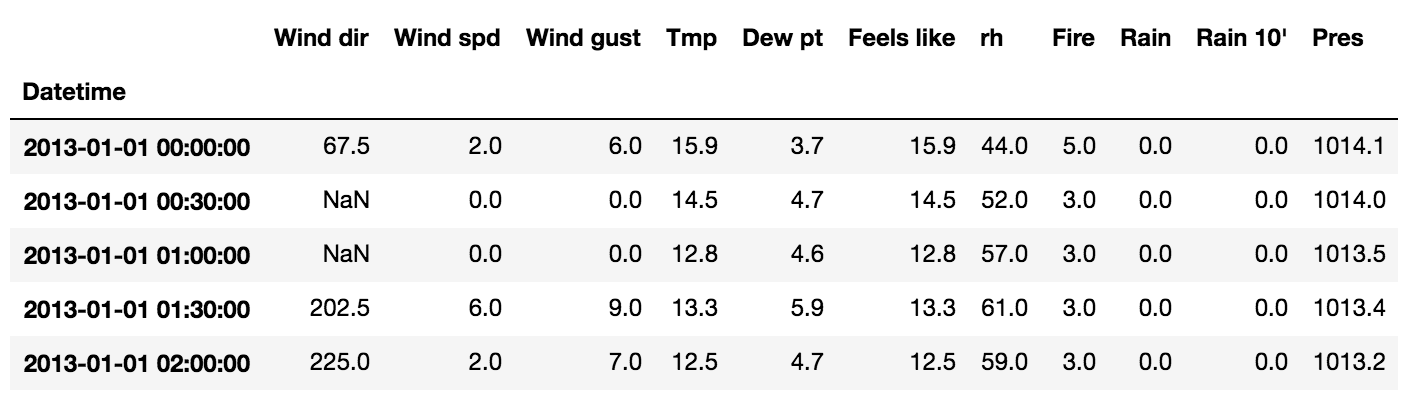
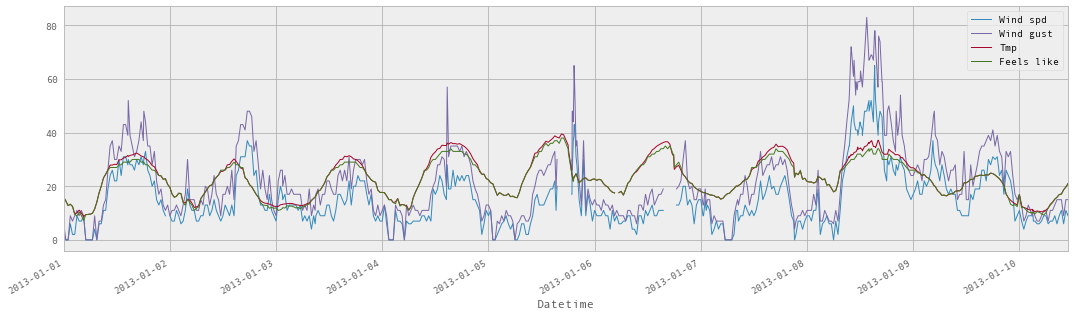 ถ้าสังเกตุดี ๆ จะเห็นว่ามีข้อมูลในบางช่วงไม่มี !!
ทำให้เส้นในกราฟมันขาด ๆ หาย ๆ เป็นช่วง ๆ
แสดงดังรูป
ถ้าสังเกตุดี ๆ จะเห็นว่ามีข้อมูลในบางช่วงไม่มี !!
ทำให้เส้นในกราฟมันขาด ๆ หาย ๆ เป็นช่วง ๆ
แสดงดังรูป
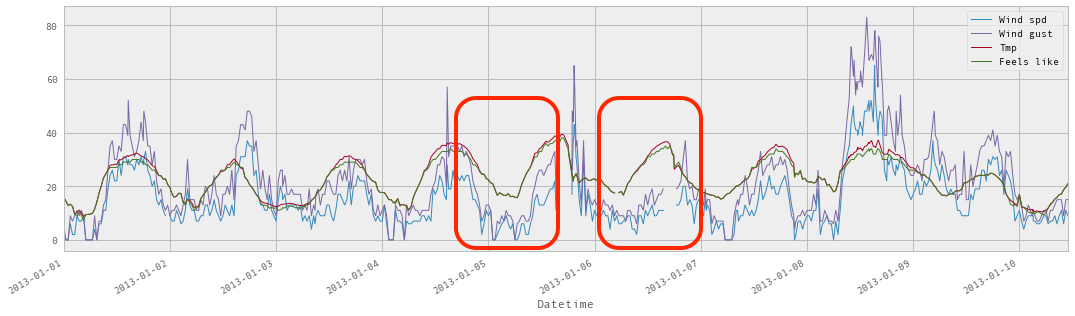 ดังนั้นสิ่งที่เราต้องทำคือ เพิ่มข้อมูลใหม่เข้ามา
เพื่อทำให้กราฟเส้นไม่ขาด
โดยใน pandas library นั้นจะมี Series.interpolate() ให้ใช้งาน
[gist id="b055f158ce622d0a1d2d145523774309" file="10.py"]
ผลที่ได้จะเป็นดังรูป
ดังนั้นสิ่งที่เราต้องทำคือ เพิ่มข้อมูลใหม่เข้ามา
เพื่อทำให้กราฟเส้นไม่ขาด
โดยใน pandas library นั้นจะมี Series.interpolate() ให้ใช้งาน
[gist id="b055f158ce622d0a1d2d145523774309" file="10.py"]
ผลที่ได้จะเป็นดังรูป

 ตั้งแต่วันที่ 29 กันยายน ถึง 1 ตุลาคม มีโอกาศมาแบ่งปันที่เชียงใหม่
ในงาน Give and Take :: Agile for Software Development
ซึ่งครั้งที่จัดที่
ตั้งแต่วันที่ 29 กันยายน ถึง 1 ตุลาคม มีโอกาศมาแบ่งปันที่เชียงใหม่
ในงาน Give and Take :: Agile for Software Development
ซึ่งครั้งที่จัดที่ 
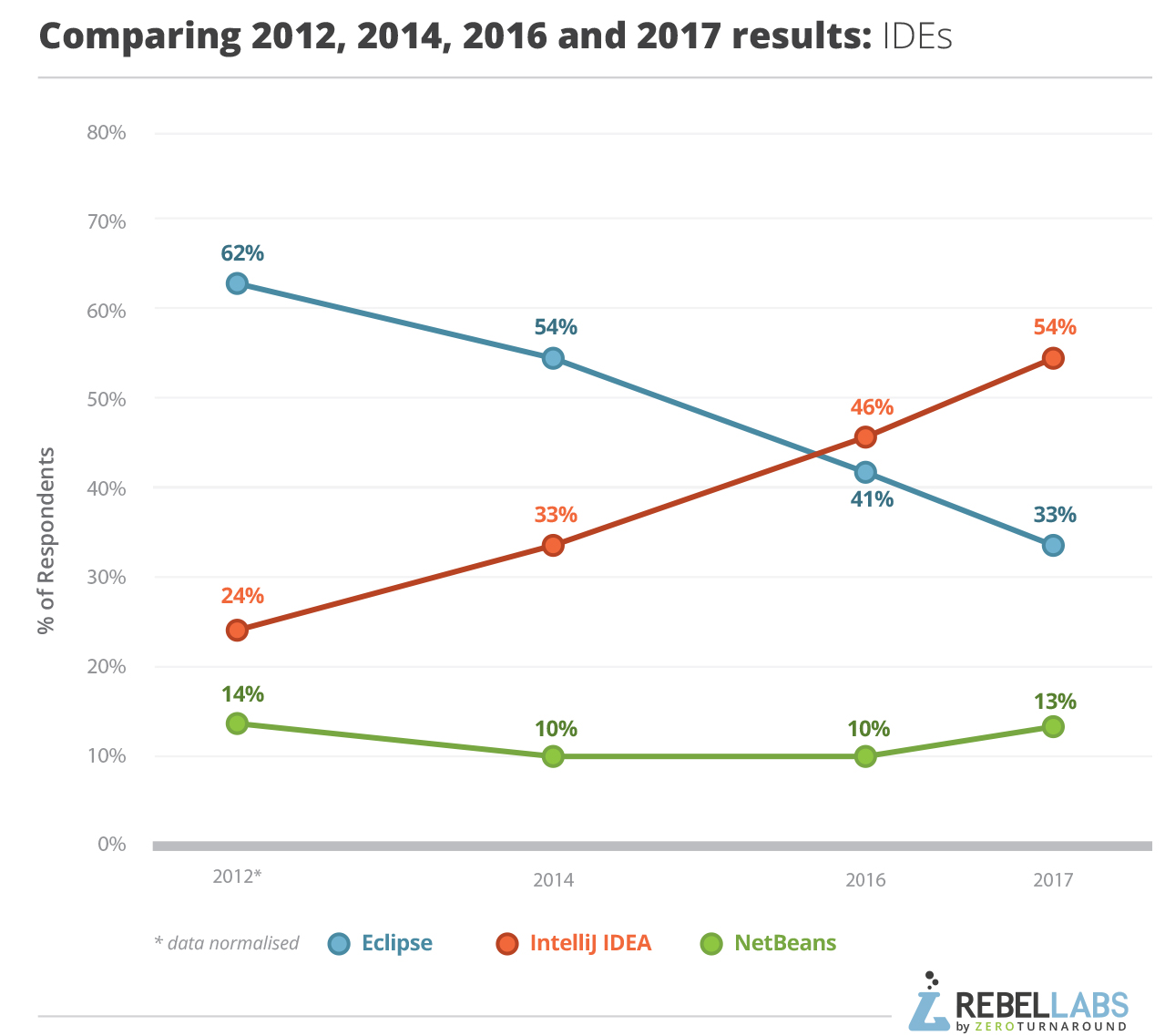
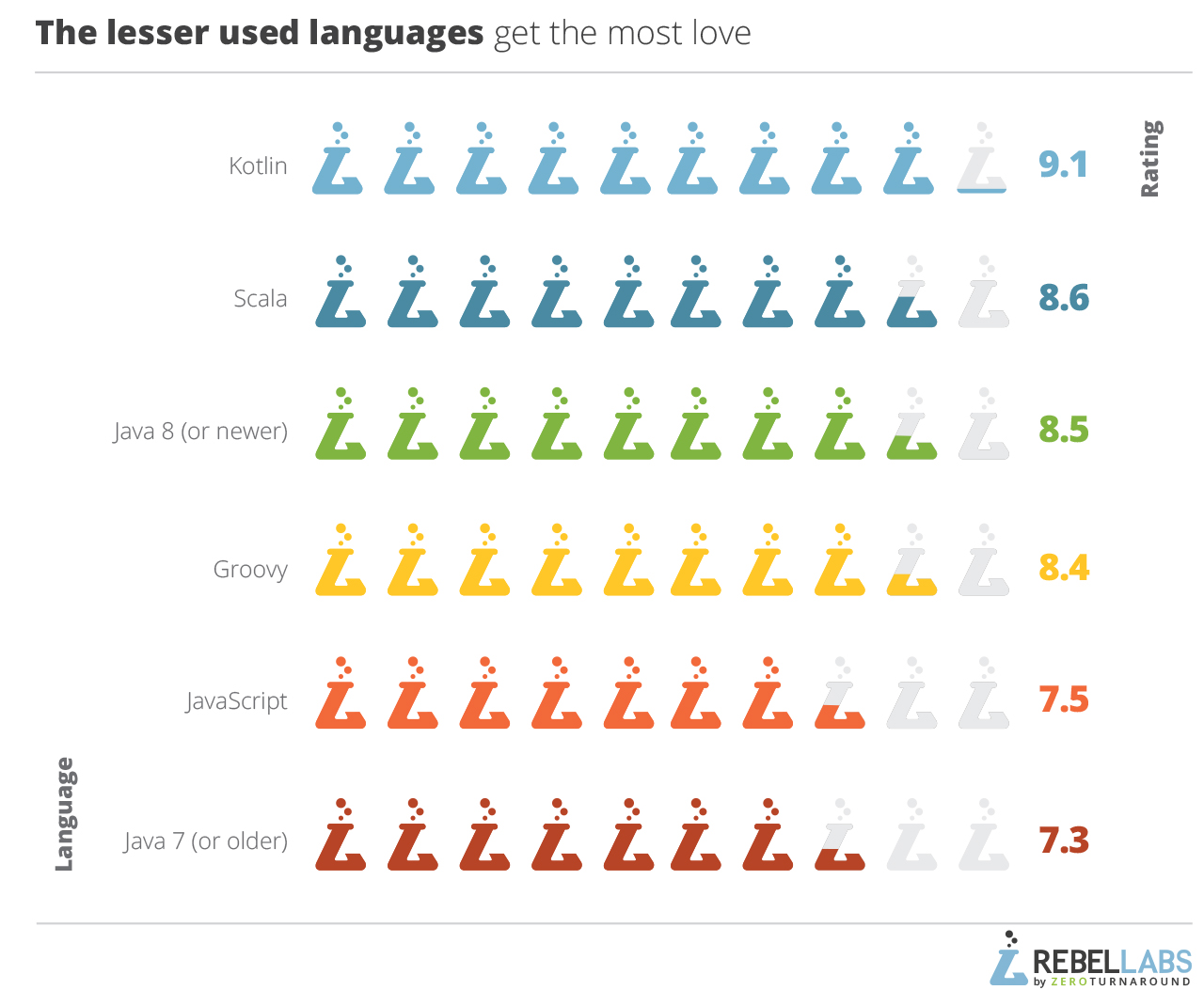
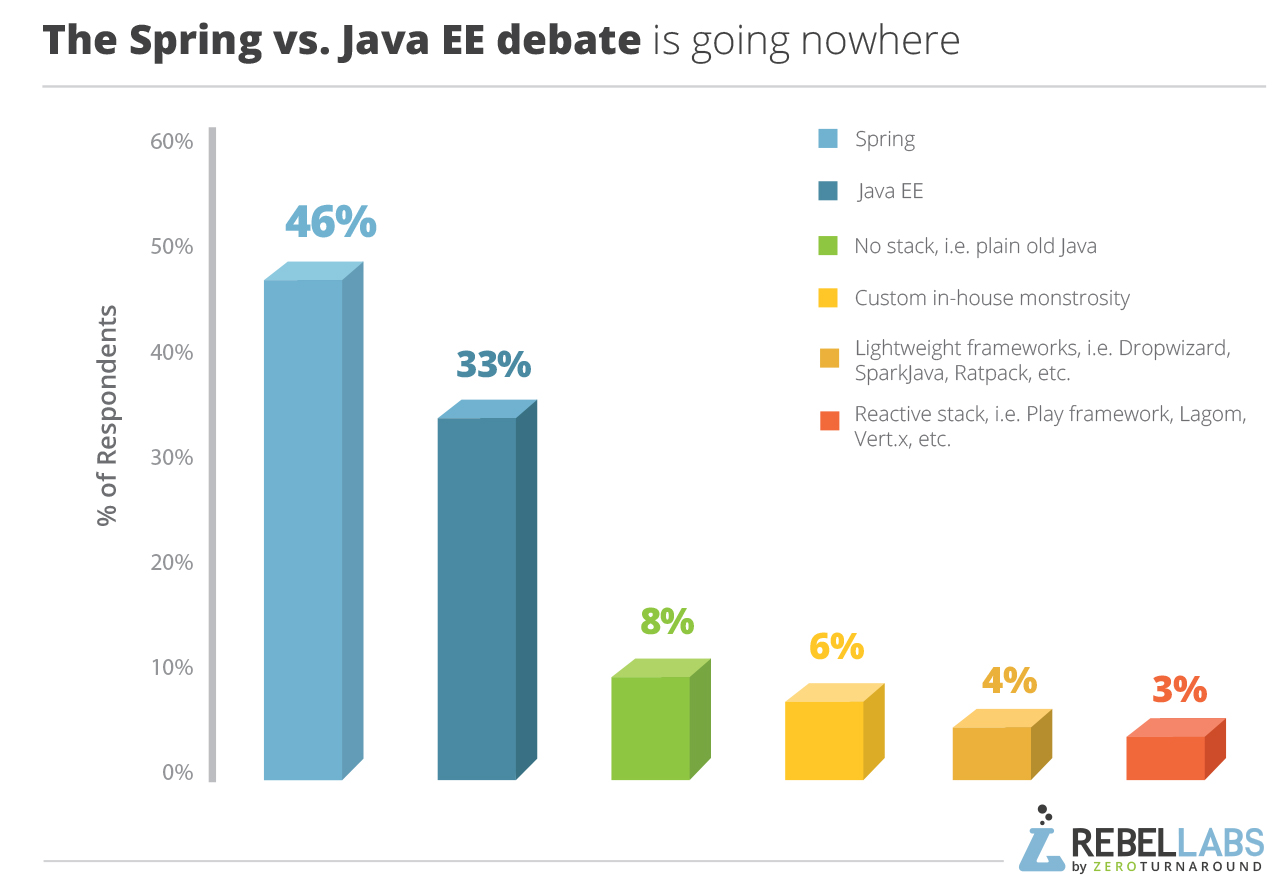
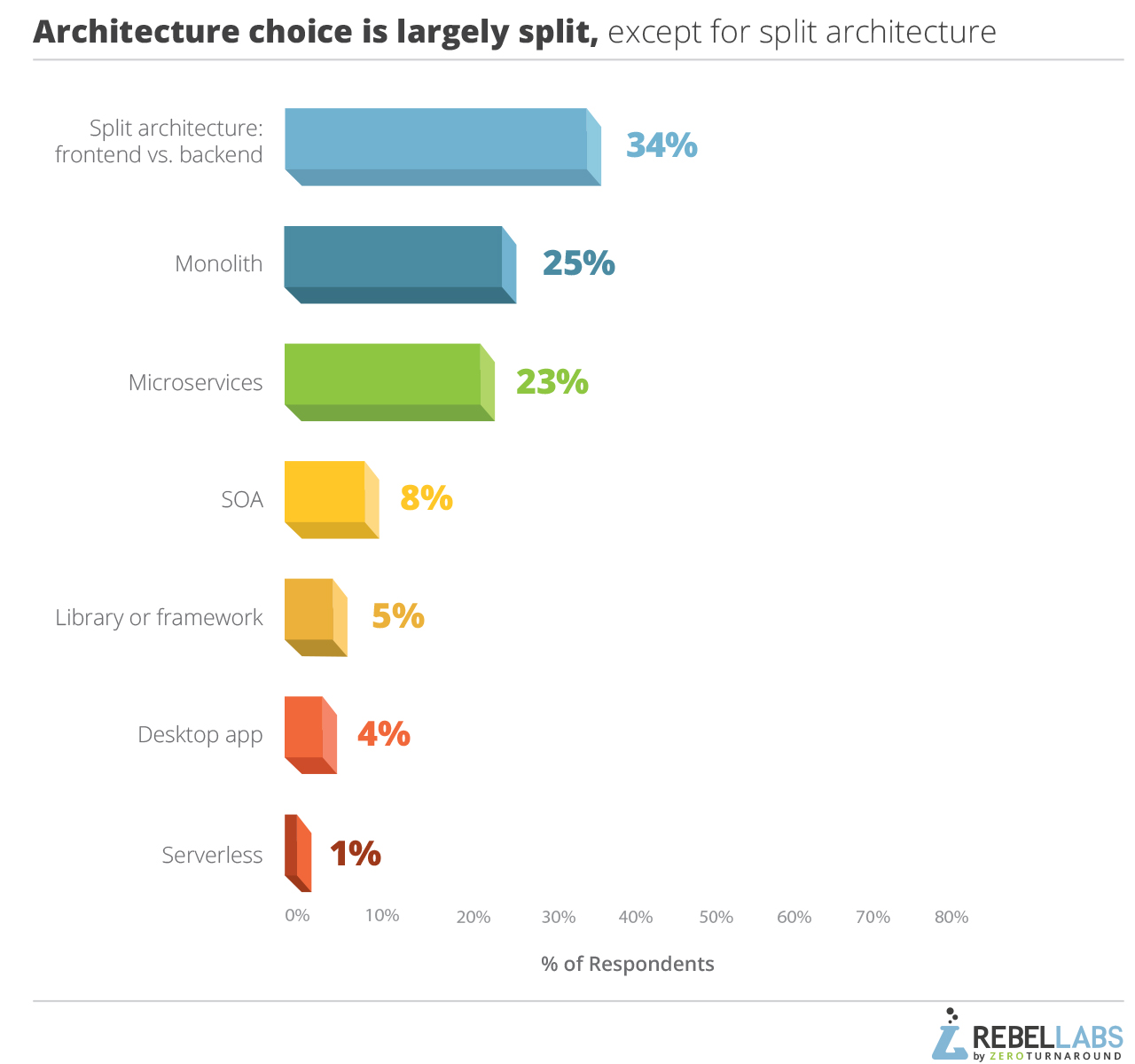
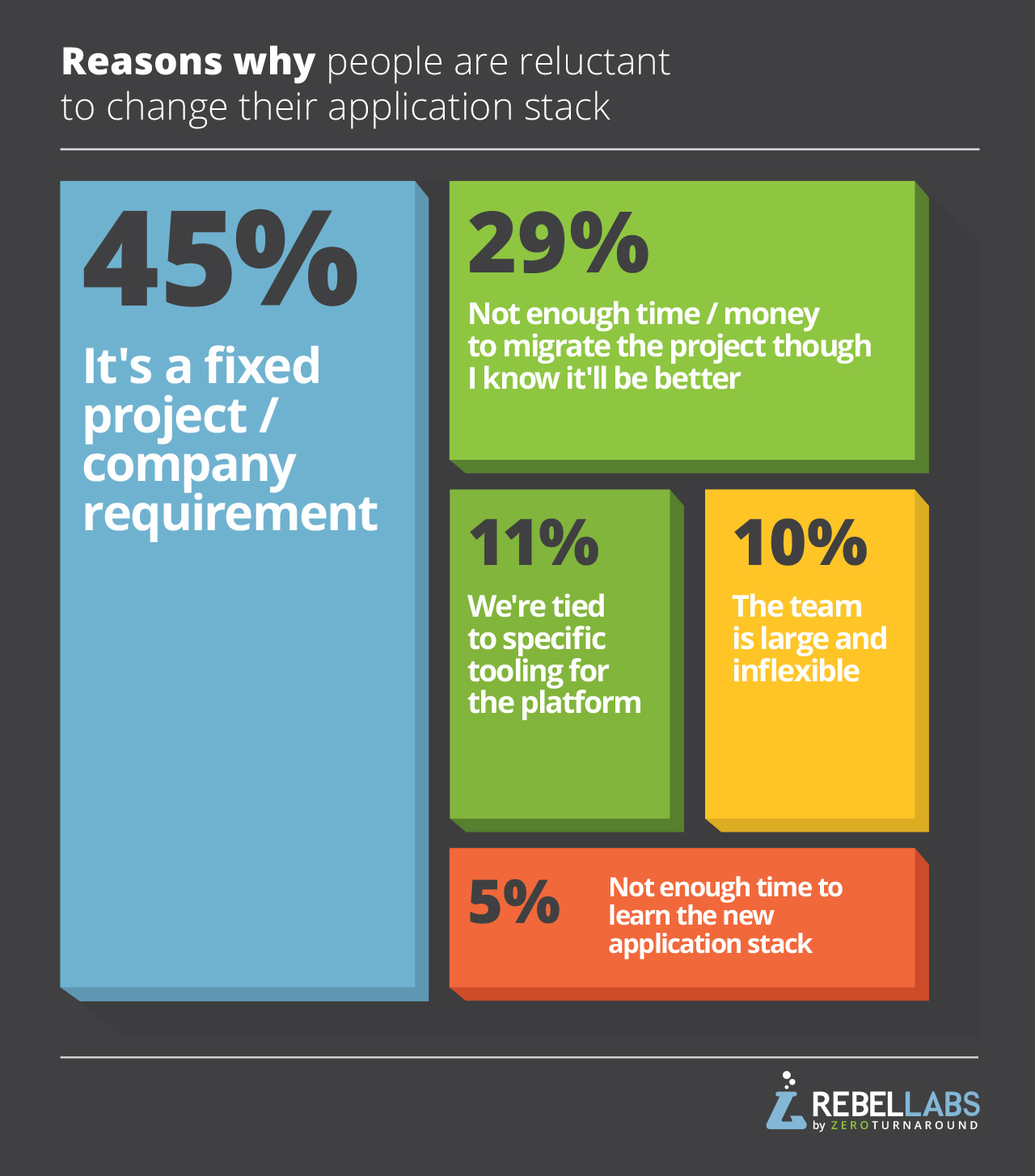
 เช้านี้อ่านผลสรุปเกี่ยวกับการสำรวจเรื่อง
เครื่องมือและเทคโนโลยีสำหรับ Java Developer
ว่ามีอะไรบ้างที่ช่วยเพิ่ม productivity ของการพัฒนา
สามารถดูผลแบบเต็ม ๆ ได้ที่
เช้านี้อ่านผลสรุปเกี่ยวกับการสำรวจเรื่อง
เครื่องมือและเทคโนโลยีสำหรับ Java Developer
ว่ามีอะไรบ้างที่ช่วยเพิ่ม productivity ของการพัฒนา
สามารถดูผลแบบเต็ม ๆ ได้ที่


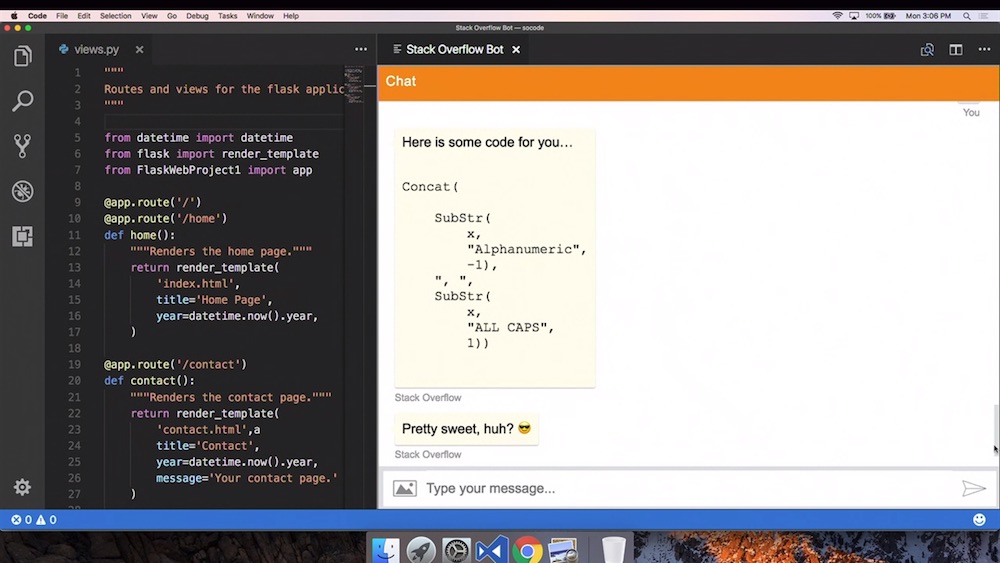 ทีมพัฒนาของ Microsoft ได้พัฒนา Bot สำหรับตอบคำถามหรือปัญหาต่าง ๆ
โดยข้อมูลนำมาจาก
ทีมพัฒนาของ Microsoft ได้พัฒนา Bot สำหรับตอบคำถามหรือปัญหาต่าง ๆ
โดยข้อมูลนำมาจาก 
 วันนี้น้องในทีมแนะนำให้รู้จัก
วันนี้น้องในทีมแนะนำให้รู้จัก  หรือถ้าใครชอบใช้ Docker ผมก็มี Dockerfile ไว้ให้สร้าง Docker image ไว้ใช้เอง
[gist id="499aaa303f803d70a036d8358535951f" file="Dockerfile"]
จากนั้นทำการสร้าง Docker image และ container ด้วยคำสั่ง
[code]
$docker image build -t admin .
$docker container run -d --name admin -p 8080:8080 admin
[/code]
ผลการทำงานก็จะเหมือนกัน
หรือถ้าใครไม่อยากสร้าง Docker image เอง
ก็สามารถไป pull มาจาก
หรือถ้าใครชอบใช้ Docker ผมก็มี Dockerfile ไว้ให้สร้าง Docker image ไว้ใช้เอง
[gist id="499aaa303f803d70a036d8358535951f" file="Dockerfile"]
จากนั้นทำการสร้าง Docker image และ container ด้วยคำสั่ง
[code]
$docker image build -t admin .
$docker container run -d --name admin -p 8080:8080 admin
[/code]
ผลการทำงานก็จะเหมือนกัน
หรือถ้าใครไม่อยากสร้าง Docker image เอง
ก็สามารถไป pull มาจาก 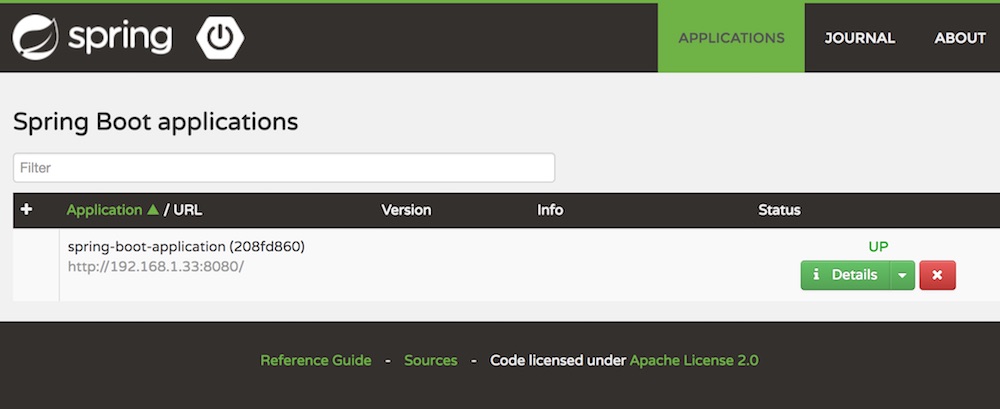
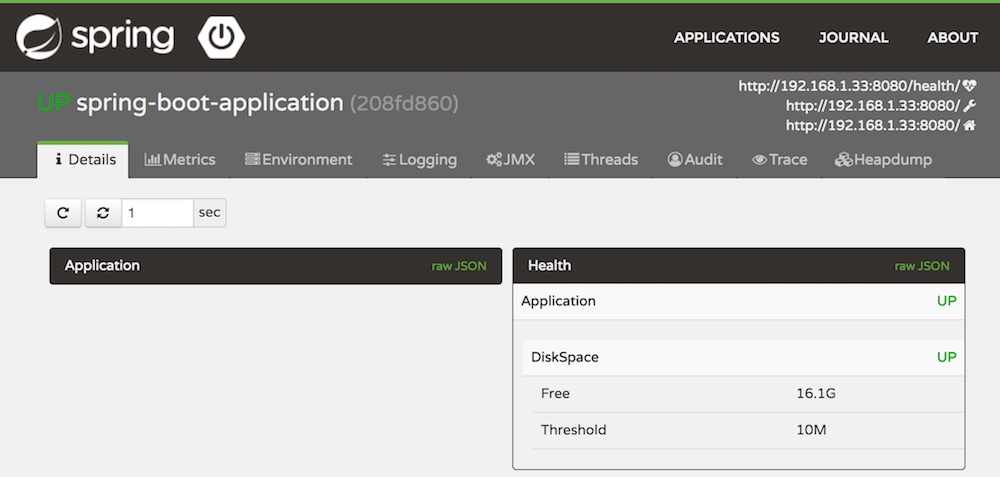 ตัวอย่างของ Logging
ตัวอย่างของ Logging
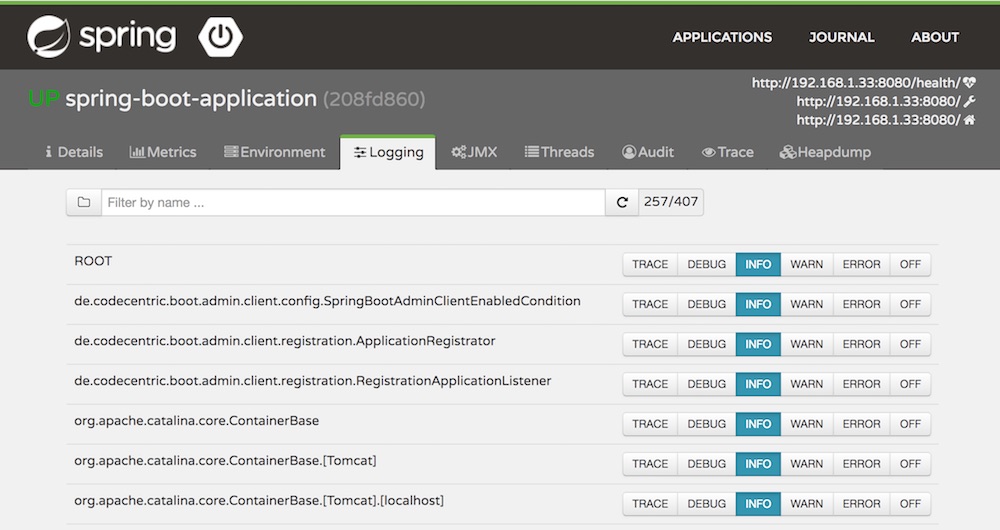 ตัวอย่างของ Trace เพื่อดูการเข้าใช้งาน service
ตัวอย่างของ Trace เพื่อดูการเข้าใช้งาน service
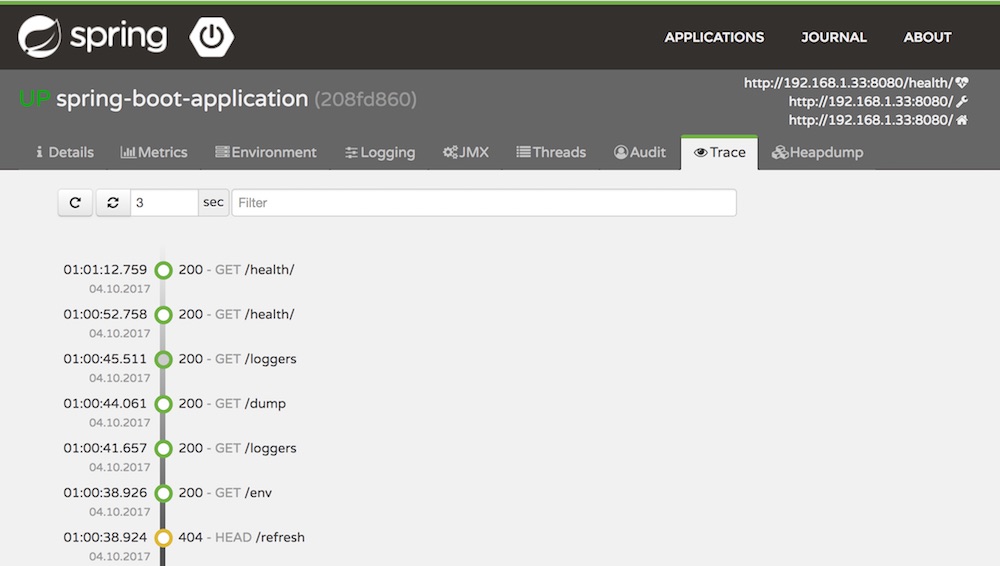 และยังมีการแสดงการเปลี่ยนแปลงสถานะของ service อีกด้วยนะ
และยังมีการแสดงการเปลี่ยนแปลงสถานะของ service อีกด้วยนะ
 ปล. ใน Google Chrome มี notification ด้วยนะ
ปล. ใน Google Chrome มี notification ด้วยนะ


 ในการ build ระบบงานที่พัฒนาด้วย JavaScript และ NodeJS นั้น
ปัญหาหลัก ๆ คือ เรื่องของการติดตั้ง library หรือ dependency ต่าง ๆ
มันเยอะ ใช้เวลามาก แถมต้องทำการตรวจสอบผ่านระบบ network อีก
ถ้าระบบ network มันช้าละ จะยิ่งช้ากว่าเดิมไหม ?
ดังนั้น
ในการ build ระบบงานที่พัฒนาด้วย JavaScript และ NodeJS นั้น
ปัญหาหลัก ๆ คือ เรื่องของการติดตั้ง library หรือ dependency ต่าง ๆ
มันเยอะ ใช้เวลามาก แถมต้องทำการตรวจสอบผ่านระบบ network อีก
ถ้าระบบ network มันช้าละ จะยิ่งช้ากว่าเดิมไหม ?
ดังนั้น