![QAMistakes]()
![QAMistakes]()
จากการลงมือทำ Automated Acceptance Testing นั้น
พบว่ามันไม่ใช่เรื่องง่าย ๆ เลย
ซึ่งมันบั่นทอนชีวิต และ จิตใจอย่างรุนแรง
มันมีเรื่องที่ไม่ควรทำมากมาย
มันไม่มีรูปแบบในการทำที่ตายตัว หรือ ชัดเจน
มันเป็นเรื่องที่ต้องลงมือทำ ดู feedback และปรับปรุงอย่างต่อเนื่อง
ดังนั้นจึงทำการสรุปสิ่งที่ควรทำสำหรับ Automated Acceptance Testing ดังนี้
พบว่าสิ่งที่ยากที่สุด คือ การทำงานร่วมกัน !!
มันง่ายมากที่จะเขียน spec ของงาน
มันง่ายมากที่จะเขียน rule การทำงาน
มันง่ายมากที่จะเขียน data test หรือ example
แต่เรื่องสนุก ๆ มันจะเกิดขึ้น
เมื่อต้องทำการแปลงจากสิ่งที่อยู่ในเอกสารมาเป็น Automated Acceptance Tests เช่น
- ใครกันที่จะมาเขียน ?
- ใครกันที่จะมาดูแล ?
- เมื่อเขียนแล้วสิ่งที่ได้คือ ชุดการทดสอบที่ซับซ้อน อ่านไม่รู้เรื่อง ดูแลยาก ทำงานช้า กลายเป็นปัญหาอีก !!
มันช่างดูขัดแย้งกับเป้าหมายของ Automated Tests นะ ว่าไหม ?
แทนที่จะทำให้เราทำงานได้รวดเร็วขึ้น กลับทำให้ช้าลงไปอีก
แทนที่จะทำให้คุณภาพของระบบงานดีขึ้น กลับไม่ เหมือนไม่ทำอะไรเลย
แทนที่จะ release งานได้เร็ว กลับช้าลงไป หรือ ช้าเหมือนเดิม
แถมยังมีภาระเพิ่มขึ้นอีก !!
ถ้าใครอยู่ในสภาวะนี้ แสดงว่า
สิ่งที่ทำอยู่นั้นไม่น่าจะถูกต้อง หรือ เหมาะกับทีม หรือ งาน นะ !!
ดังนั้นจึงข้อแนะนำสิ่งที่ควรทำ สำหรับ Automated Acceptance Test
1. Acceptance test กับ End-to-End test (e2e) มันต่างกันนะ
หลาย ๆ คนคิด และ เข้าใจว่า มันคือสิ่งเดียวกัน
เพราะว่า มันแยกออกจากกันได้ยากมาก ๆ !!
แต่ในความเป็นจริงมันต่างกันนะ
มาดูความแตกต่างของทั้งสองกันหน่อย
Automated Acceptance Test นั้นจะมีเป้าหมาย และ การทดสอบเพียงอย่างเดียวเท่านั้น
จะทำการทดสอบไปยัง function การทำงานนั้น ๆ โดยตรง
หรือทดสอบไปยัง API หรือ End point ต่าง ๆ เลย
ตัวอย่างเช่น
Given I am a new user
When I visit the product detail
Then I see detail of product A
Automated End-to-End Test นั้นจะครอบคลุม
หรือเป็นเส้นทางการทำงานของระบบตั้งแต่ต้นทางจนถึงปลายทาง
เหมือนกับการใช้งานของผู้ใช้งาน
ซึ่งควรคำกำหนดจำนวน test case ไว้เลย ไม่ให้เยอะจนเกินไป
เนื่องจากใช้เวลาการทดสอบสูงมาก ๆ
ซึ่งต้องพึงระวังอย่างมาก !!
ตัวอย่างเช่น
Given I am a new user
When I visit the product detail
And I add product to my order
Then I see my basket
When I choose and enter my payment detail
And I choose my shipping
Then I see my order confirmation
ดังนั้นควรแยกให้ชัดเจนนะครับ
ซึ่งเราควรเน้นไปที่ Automated Acceptance Test เป็นหลัก
เพราะว่ามันทำงานได้รวดเร็ว และ มีเป้าหมายที่แน่ชัด
2. ให้เน้นว่าต้องการทำอะไร ไม่ใช่เขียนตามระบบงาน
เวลาเขียน scenario ต่าง ๆ ต้องไม่ลงรายละเอียดมากจนเกินไป
เนื่องจากสิ่งที่เราเขียนมานั้น
ต้องให้คนอื่น ๆ เช่น ฝ่าย business อ่าน และ เข้าใจ
พูดง่าย ๆ คือ เขียนให้คนทั่วไปอ่านรู้เรื่อง
รวมทั้งไม่ยาวจนเกินไป
ตัวอย่างเช่น
Given I am a customer
When I go to the promotion page
And I click product A
And I click shipping
Then I see shipping equals 0 THB
เป็นตัวอย่างที่เขียนถึงรายละเอียดของระบบ
หรือการพัฒนามากจนเกินไป
หรือผูกติดกับ technical มากเกินไป
บ่อยครั้งเมื่อเปลี่ยน User Interface กลับมีผลกระทบกับ test อีกด้วย !!
น่าจะเขียนให้ตรงกับความต้องการของเรา
นั่นคือ ต้องการดูว่า product มันฟรีค่าจัดส่งนะ
ตัวอย่างเช่น
Given I am a customer
When I visit the promotion page
Then I see free shipping
ดังนั้นในการเขียน scenario และ feature
ควรเน้นไปที่ว่า ระบบทำอะไร (What)
มากกว่าระบบทำงานอย่างไร (How)
มันจะทำให้เราอ่านง่าย เข้าใจได้ง่าย
แถมเปลี่ยนแปลงได้ง่ายอีกนะครับ
3. การทดสอบต้องเป็นอิสระต่อกัน
ลองคิดดูสิว่า
ถ้าแต่ละการทดสอบมันเป็นอิสระต่อกันแล้ว
เราสามารถแยกการทดสอบออกจากกันได้
เราสามารถให้แต่ละการทดสอบทำงานแบบขนานกันได้
ซึ่งส่งผลให้เวลาการทดสอบน้อยลง
แถมช่วยให้เราหาจุดผิดพลาดได้ง่ายอีกด้วย
ดังนั้นลองคิดดูว่า ถ้ามันเป็นแบบตรงข้าม
จะทำให้การทดสอบมันซับซ้อน
จะทำให้การทดสอบยากลำบากขึ้นมากไหม
จะทำให้การดูแลรักษายากขึ้นมากไหม
4. Automated test มันต้องช่วยลดการทดสอบแบบ manual test ลงไปนะ
การทดสอบนั้น เราไม่ได้เน้นแต่ code coverage เท่านั้น
แต่สิ่งที่เราต้องให้ความสำคัญอย่างมากก็คือ
ประโยชน์จากชุดการทดสอบเหล่านั้นต่างหาก
ดังนั้นลองถามตัวคุณเองสิว่า Automated test ที่เราสร้างขึ้นมานั้น
- มันช่วยลดเวลาในการทดสอบลงไหม ?
- มันช่วยลดเวลาการทำ regression test ลงไหม ?
- มันช่วยเพิ่มคุณภาพให้กับระบบไหม ?
- มันช่วยเรื่อง time to market ไหม ?
- มันช่วยเพิ่มความมั่นใจต่อระบบไหม ?
- มันช่วยทำให้คุณมั่นใจเมื่อต้อง release ระบบไหม ?
คำตอบมันอยู่ที่คุณแล้ว
และผมเชื่อว่า manual test ยิ่งเป็น regression test แล้ว
คงไม่มีใครชอบหรอกนะ !!
5. หน้าที่รับผิดชอบในการดูแล Automated Test เป็นของทุกคนในทีมนะ
ให้เชื่อเถอะว่า
การสร้างทีมเพื่อแยกออกมาเขียน Automated test โดยเฉพาะ
มันไม่เคยได้ดี และ มีประสิทธิภาพที่ดีเลย
เพราะว่า ทีมนี้สนใจเพียงเรื่องการทดสอบ ไม่สนใจระบบเลย
ดังนั้น ถ้าทุกคนในทีมรับผิดชอบเรื่อง คุณภาพ หรือ (Quality Build-in)
มันจะได้ผลลัพธ์ที่แจ่มแมวมาก ๆ
ซึ่งมันอาจจะยากสำหรับการเริ่มต้น
แต่ผลในระยะยาวมันดีอย่างแน่นอน
การทำงานร่วมกันเป็นทีม มันสำคัญอย่างมาก
6. ทำการทดสอบทุกครั้งที่มีการเปลี่ยนแปลง
มีคำถามว่า
จะทดสอบ Automated test บ่อยเท่าไร ?
ตอบได้เลยว่า
ทุกครั้งที่มีการเปลี่ยนแปลง
ไม่ว่าจะเป็น source code
ไม่ว่าจะเป็นชุดการทดสอบ
หรืออะไรก็ตามที่เกี่ยวข้องกับระบบ
จะไม่รอ ให้ครบ 10 test case ก่อน จึงจะทดสอบ
จะไม่รอ ให้ถึงเวลา 16.00 น. ก่อน จึงจะทดสอบ
เพราะว่า สิ่งที่เราต้องการคือ feedback
ของการทดสอบที่รวดเร็ว
เราจะได้รู้ว่าสิ่งที่เราเปลี่ยนแปลงไปนั้น
มันกระทบต่อการทำงานหรือไม่นั่นเอง
ซึ่งมันทำให้คุณมั่นใจทุกการก้าวเดิน
7. ต้อง run test แบบขนาน (Parallel)
เนื่องจากในระบบต่าง ๆ ที่มีชุดของ Automated test นั้น
จะมีจำนวนมากขึ้นเรื่อย ๆ
นั่นหมายความว่า เวลาการทำงานก็นานขึ้นด้วย
ดังนั้น เราต้องลดเวลาการทำงานลงด้วย
การเปลี่ยนจากการ run แบบตามลำดับมาเป็นแบบขนาน
ดังนั้นแต่ละการทดสอบต้องเป็นอิสระต่อกันด้วย
ไม่เช่นนั้นจะทำไม่ได้นะครับ
ที่สำคัญ ไม่ใช่เพียงการทดสอบเร็วขึ้นเท่านั้น
แต่มันยังเป็นการจำลองการใช้งานระบบ
เสมือนว่า ผู้ใช้งานหลาย ๆ คนกำลังใช้งานระบบอีกด้วย
8. ทำการ run Automated End-to-End Test บน production ไปเลย !!
เนื่องจากการทำงาน Automated test
ไม่ว่าจะเป็น Acceptance test และ End-to-End test
ล้วนมีค่าใช้จ่ายที่สูง ดังนั้น
สิ่งที่ได้กลับมาจากการลงทุนต้องมีคุณค่าสมเหตุสมผลด้วยเช่นกัน
เช่น
การ run Enn-to-End test หลักจากที่ทำการติดตั้งระบบบน production server
เพื่อทำให้มั่นใจในการ deploy ว่ามัน work นะ
ซึ่งเป็นคุณค่าที่คุณคู่ควรใช่หรือเปล่า ?
ดังนั้นสิ่งที่คุณ และ ทีมต้องค้นหาก็คือ
คุณค่าที่ได้จากชุดการทดสอบที่สร้างขึ้น
ทั้งการ run บน dev, testing, staging และ production
สุดท้าย อย่าหยุดที่จะทำสิ่งต่าง ๆ เหล่านี้
เนื่องจากทุก ๆ อย่างมันคือ การทดลอง
เพื่อทำให้เราเข้าใกล้เป้าหมายที่ตั้งไว้ของการทำ Automated testing
ซึ่งคุณต้องเรียนรู้ เพื่อ Inspect and Adapt ต่อไปครับ

 วันนี้ได้อ่านบทความเกี่ยวกับ Modern Software Devlopment
ซึ่งเขียนไว้ตั้งแต่ปี 2006 แล้ว
แต่เมื่อได้อ่านทำให้เห็นว่า
ทีมที่ดีควรเป็นอย่างไรบ้างนะ ?
แน่นอนว่าจะประกอบไปด้วยคน หรือ สมาชิกในทีมที่ดีสิ
แต่ละคนต้องมีความรู้ความสามารถ
แต่ละคนต้องทำงานร่วมกันได้ดี
ตรงนั้นเราไม่พูดถึงก็แล้วกัน
มาดู checklist กันดีกว่า ว่าทีมของเรามีไหม ?
วันนี้ได้อ่านบทความเกี่ยวกับ Modern Software Devlopment
ซึ่งเขียนไว้ตั้งแต่ปี 2006 แล้ว
แต่เมื่อได้อ่านทำให้เห็นว่า
ทีมที่ดีควรเป็นอย่างไรบ้างนะ ?
แน่นอนว่าจะประกอบไปด้วยคน หรือ สมาชิกในทีมที่ดีสิ
แต่ละคนต้องมีความรู้ความสามารถ
แต่ละคนต้องทำงานร่วมกันได้ดี
ตรงนั้นเราไม่พูดถึงก็แล้วกัน
มาดู checklist กันดีกว่า ว่าทีมของเรามีไหม ?

 เพิ่งอ่าน blog เรื่อง
เพิ่งอ่าน blog เรื่อง 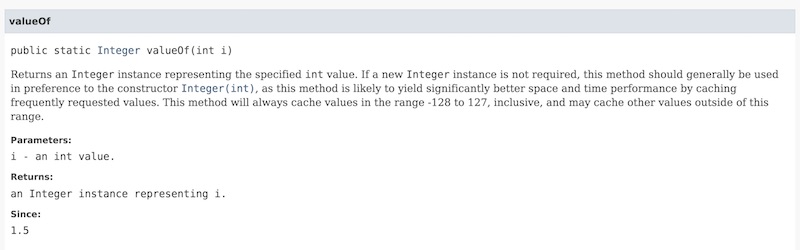

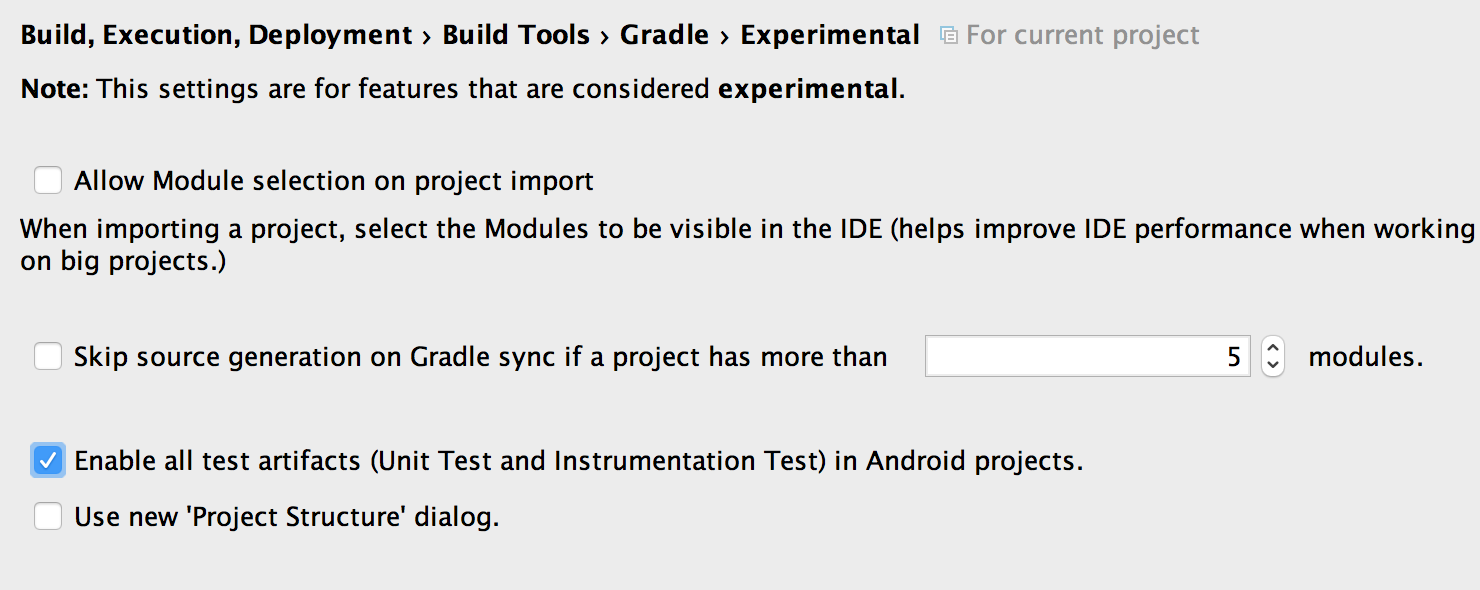
 ทางทีมพัฒนา Android ได้ปล่อย
ทางทีมพัฒนา Android ได้ปล่อย  ส่วนถ้าเป็น Project เก่า ๆ
เข้าไปเปิด Instant Run ให้กับ Project ก่อนนะ
แสดงดังรูป
ส่วนถ้าเป็น Project เก่า ๆ
เข้าไปเปิด Instant Run ให้กับ Project ก่อนนะ
แสดงดังรูป
 จากนั้นให้ทำการ Run project ของเราแบบปกติ
ซึ่งในครั้งแรกจะใช้เวลานานเช่นเดิม
แต่เมื่อทำการแก้ไข code และ Run ใหม่ ด้วย Instant Run
แสดงดังรูป เห็นรูป Run ฟ้าผ่าหรือเปล่าล่ะ ?
จากนั้นให้ทำการ Run project ของเราแบบปกติ
ซึ่งในครั้งแรกจะใช้เวลานานเช่นเดิม
แต่เมื่อทำการแก้ไข code และ Run ใหม่ ด้วย Instant Run
แสดงดังรูป เห็นรูป Run ฟ้าผ่าหรือเปล่าล่ะ ?
 ผลการทำงานจะเร็วขึ้น ดังรูป
ปล. เครื่องทดสอบทำงานช้านะ !!
ผลการทำงานจะเร็วขึ้น ดังรูป
ปล. เครื่องทดสอบทำงานช้านะ !!

 ไม่ว่าจะเป็น Code review, Test-Driven Development และ Continuous Integration
ล้วนเป็นแนวปฏิบัติที่เกิดขึ้นมา
เพื่อทำให้มั่นใจว่า code ที่ถูกสร้างขึ้นมาในแต่ละวัน มันมีคุณภาพที่ดีขึ้น
โดยหลายทีม หลายองค์กร ได้นำไปใช้ในการพัฒนา software
แต่หลาย ๆ ที่ก็ไม่นำแนวปฏิบัติเหล่านี้ไปใช้งาน
หรือนำไปใช้แล้วกลับก่อให้เกิดปัญหาแทน
ดังนั้นมาดูเหตุผลหลัก ๆ ว่ามันคืออะไร ?
ไม่ว่าจะเป็น Code review, Test-Driven Development และ Continuous Integration
ล้วนเป็นแนวปฏิบัติที่เกิดขึ้นมา
เพื่อทำให้มั่นใจว่า code ที่ถูกสร้างขึ้นมาในแต่ละวัน มันมีคุณภาพที่ดีขึ้น
โดยหลายทีม หลายองค์กร ได้นำไปใช้ในการพัฒนา software
แต่หลาย ๆ ที่ก็ไม่นำแนวปฏิบัติเหล่านี้ไปใช้งาน
หรือนำไปใช้แล้วกลับก่อให้เกิดปัญหาแทน
ดังนั้นมาดูเหตุผลหลัก ๆ ว่ามันคืออะไร ?

 วันนี้นั่งดู VDO จากงาน
วันนี้นั่งดู VDO จากงาน ![LavaLayer[5]](http://www.somkiat.cc/wp-content/uploads/2015/11/LavaLayer5.png) คำอธิบาย
จะเห็นได้ว่า แต่ละ version ก็มีรูปแบบที่ต่างกันไป
ทั้งการออกแบบ และ เทคโนโลยีที่ใช้
แต่ทุก ๆ version ยังคงอยู่ และ ถูก deploy ขึ้น production เสมอ
สังเกตไหมว่า ใน version ที่ 4 นั้น
มี 4 วิธีในการแก้ไขปัญหาเดียวกัน !!
ผลที่ตามมา คืออะไรล่ะ ?
ยิ่งนับวันระบบมีความซับซ้อนมากขึ้น
ยิ่งนับวันระบบมีความยุ่งเหยิงมากขึ้น
นั่นคือ โครงสร้าง และ architecture ของระบบยิ่งแย่ลงไปเรื่อย ๆ
คำอธิบาย
จะเห็นได้ว่า แต่ละ version ก็มีรูปแบบที่ต่างกันไป
ทั้งการออกแบบ และ เทคโนโลยีที่ใช้
แต่ทุก ๆ version ยังคงอยู่ และ ถูก deploy ขึ้น production เสมอ
สังเกตไหมว่า ใน version ที่ 4 นั้น
มี 4 วิธีในการแก้ไขปัญหาเดียวกัน !!
ผลที่ตามมา คืออะไรล่ะ ?
ยิ่งนับวันระบบมีความซับซ้อนมากขึ้น
ยิ่งนับวันระบบมีความยุ่งเหยิงมากขึ้น
นั่นคือ โครงสร้าง และ architecture ของระบบยิ่งแย่ลงไปเรื่อย ๆ

 จากงาน
จากงาน 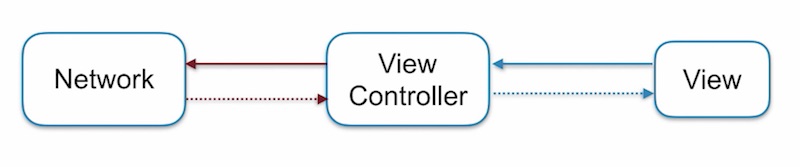 ปัญหาจากรูปแบบการทำงานนี้ คือ
View จะรอไปจนกว่าจะได้ข้อมูลจาก ViewController และ Network
นั่นคือ ViewController มันผูกติดกับ Network อย่างมาก !!
สามารถแก้ไขด้วยการแยก ViewController ออกจาก Network ซะ
ด้วยการเพิ่มอีกหนึ่งส่วน หรือ อีกหนึ่ง layer นั่นคือ Model
เนื่องจาก ViewController นั้นต้องการเพียงข้อมูลเพื่อส่งไปแสดงผลที่ View เท่านั้น
ไม่ได้ต้องการ Network เลย
แสดงการทำงานดังรูป
ปัญหาจากรูปแบบการทำงานนี้ คือ
View จะรอไปจนกว่าจะได้ข้อมูลจาก ViewController และ Network
นั่นคือ ViewController มันผูกติดกับ Network อย่างมาก !!
สามารถแก้ไขด้วยการแยก ViewController ออกจาก Network ซะ
ด้วยการเพิ่มอีกหนึ่งส่วน หรือ อีกหนึ่ง layer นั่นคือ Model
เนื่องจาก ViewController นั้นต้องการเพียงข้อมูลเพื่อส่งไปแสดงผลที่ View เท่านั้น
ไม่ได้ต้องการ Network เลย
แสดงการทำงานดังรูป
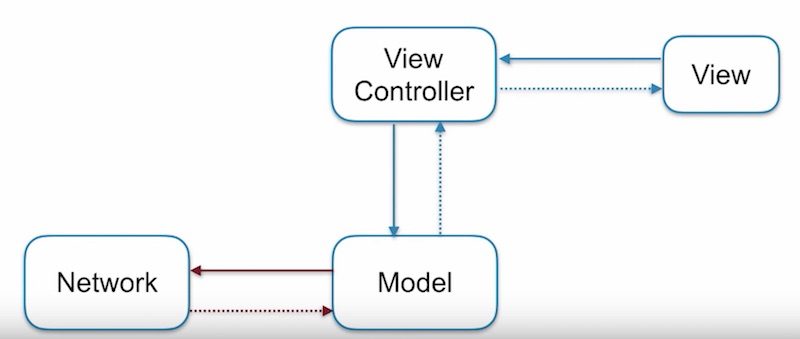 แต่จากรูปแบบนี้ก็ยังคงมีปัญหากับ Network อยู่ใช่ไหม ?
เนื่องจากเราเพียงย้ายให้ Network ไปทำงานกับ Model เท่านั้นเอง
ดังนั้น จะแก้ไขปัญหานี้อย่างไรดีล่ะ ?
สิ่งที่ต้องทำก็คือ Model นั้นให้เป็น Persistent model ที่อยู่บนเครื่อง หรือ Local ซะ
และเพิ่มส่วนของ Application Logic ขึ้นมา
เพื่อทำงานร่วมกับ Network แทน
โดยแบ่งการทำงานเป็นส่วน ๆ ดังนี้
ส่วนที่ 1
เมื่อ Application logic ได้ข้อมูลจาก Network หรือ sync data เรียบร้อยแล้ว
จะทำการส่ง หรือ จัดเก็บไปที่ Persistent Model
แสดงการทำงานดังรูป
แต่จากรูปแบบนี้ก็ยังคงมีปัญหากับ Network อยู่ใช่ไหม ?
เนื่องจากเราเพียงย้ายให้ Network ไปทำงานกับ Model เท่านั้นเอง
ดังนั้น จะแก้ไขปัญหานี้อย่างไรดีล่ะ ?
สิ่งที่ต้องทำก็คือ Model นั้นให้เป็น Persistent model ที่อยู่บนเครื่อง หรือ Local ซะ
และเพิ่มส่วนของ Application Logic ขึ้นมา
เพื่อทำงานร่วมกับ Network แทน
โดยแบ่งการทำงานเป็นส่วน ๆ ดังนี้
ส่วนที่ 1
เมื่อ Application logic ได้ข้อมูลจาก Network หรือ sync data เรียบร้อยแล้ว
จะทำการส่ง หรือ จัดเก็บไปที่ Persistent Model
แสดงการทำงานดังรูป
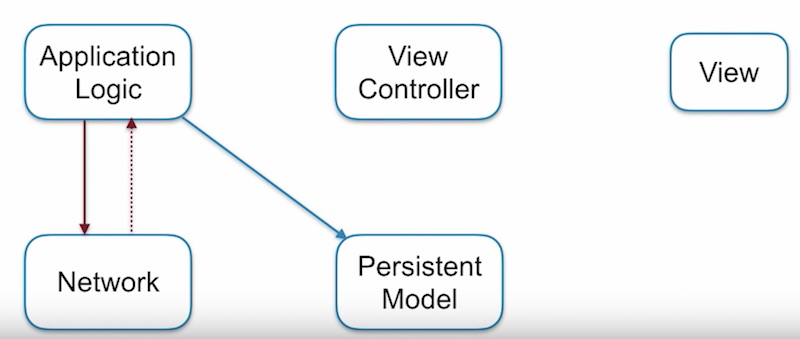 ส่วนที่ 2
ส่วนของ ViewController เมื่อต้องการข้อมูลไปแสดงผลที่ View
ก็ให้ทำการดึงข้อมูลจาก Persistent Model แทน
ซึ่งไม่ต้องรออะไรเลย
แสดงการทำงานดังรูป
ส่วนที่ 2
ส่วนของ ViewController เมื่อต้องการข้อมูลไปแสดงผลที่ View
ก็ให้ทำการดึงข้อมูลจาก Persistent Model แทน
ซึ่งไม่ต้องรออะไรเลย
แสดงการทำงานดังรูป
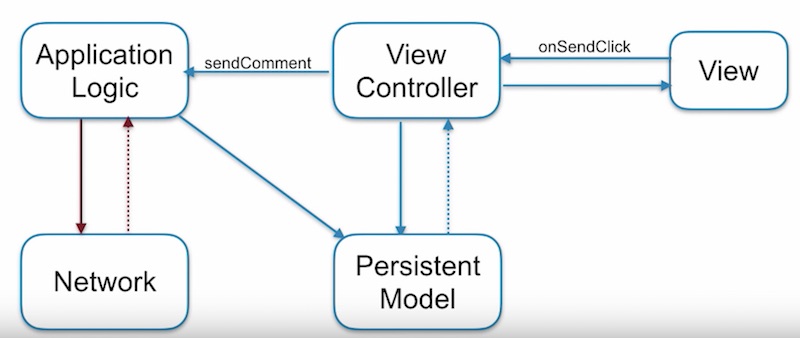
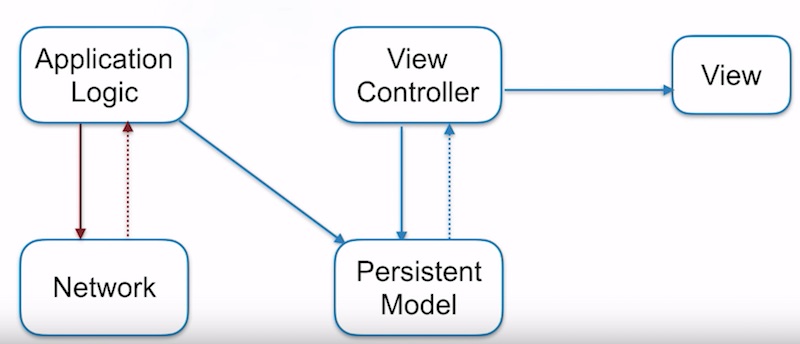 ส่วนที่ 3
เมื่อมีการร้องขอ หรือ ส่งข้อมูลมาจากผู้ใช้งานผ่าน View
จะทำการส่งการร้องขอมายัง ViewController
จากนั้นจะส่งการร้องขอไปยัง Application Logic เพื่อทำงาน
ซึ่งจะทำงาน 2 อย่าง คือ
ส่วนที่ 3
เมื่อมีการร้องขอ หรือ ส่งข้อมูลมาจากผู้ใช้งานผ่าน View
จะทำการส่งการร้องขอมายัง ViewController
จากนั้นจะส่งการร้องขอไปยัง Application Logic เพื่อทำงาน
ซึ่งจะทำงาน 2 อย่าง คือ
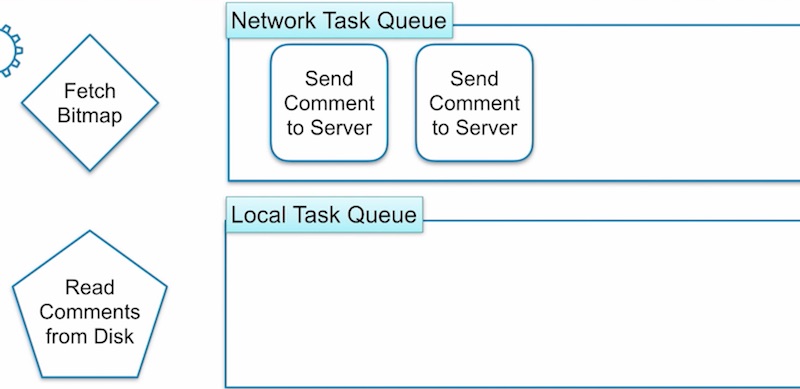
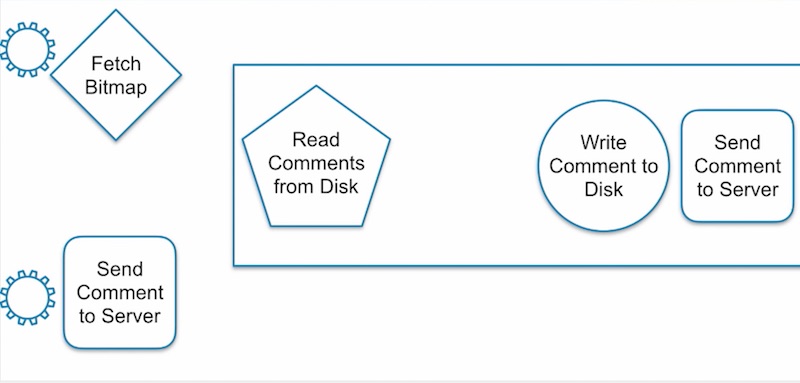 การแก้ไขปัญหานี้คือ ก็ให้แยก queue ของการทำงานให้ทำงานคนละ Thread ไป
นั่นคือ
การแก้ไขปัญหานี้คือ ก็ให้แยก queue ของการทำงานให้ทำงานคนละ Thread ไป
นั่นคือ

 ได้อ่านบทสัมภาษณ์ของคุณ David Heinemeier Hansson หรือ DHH
ผู้สร้าง Ruby On Rails (RoR) และ CTO ของ
ได้อ่านบทสัมภาษณ์ของคุณ David Heinemeier Hansson หรือ DHH
ผู้สร้าง Ruby On Rails (RoR) และ CTO ของ 
 จากหนังสือ
จากหนังสือ 

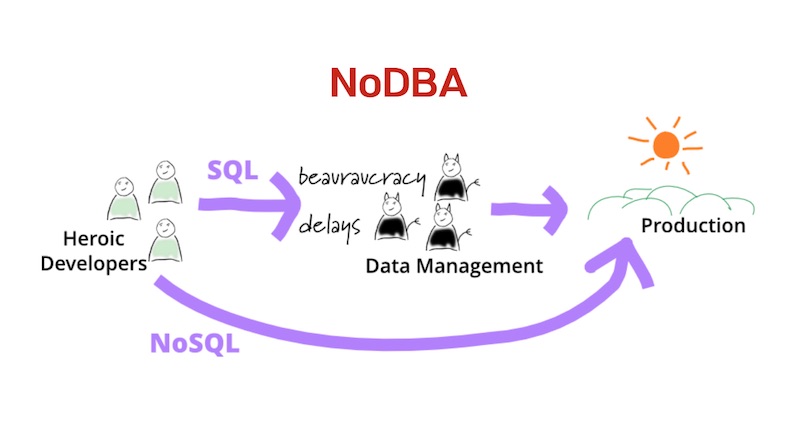 ในปัจจุบัน
ในปัจจุบัน 
 ในปัจจุบันนั้น เชื่อว่า programmer ส่วนใหญ่
น่าจะต้องเคยเข้าใช้งาน
ในปัจจุบันนั้น เชื่อว่า programmer ส่วนใหญ่
น่าจะต้องเคยเข้าใช้งาน 
 ปิดท้ายด้วยผู้ใช้งานในประเทศไทยกันหน่อยสิ (
ปิดท้ายด้วยผู้ใช้งานในประเทศไทยกันหน่อยสิ (
 หรือโทรไปลาป่วย
หรือโทรไปลาป่วย
 Reference Websites
Reference Websites

 จากการลงมือทำ Automated Acceptance Testing นั้น
พบว่ามันไม่ใช่เรื่องง่าย ๆ เลย
ซึ่งมันบั่นทอนชีวิต และ จิตใจอย่างรุนแรง
มันมีเรื่องที่ไม่ควรทำมากมาย
มันไม่มีรูปแบบในการทำที่ตายตัว หรือ ชัดเจน
มันเป็นเรื่องที่ต้องลงมือทำ ดู feedback และปรับปรุงอย่างต่อเนื่อง
ดังนั้นจึงทำการสรุปสิ่งที่ควรทำสำหรับ Automated Acceptance Testing ดังนี้
จากการลงมือทำ Automated Acceptance Testing นั้น
พบว่ามันไม่ใช่เรื่องง่าย ๆ เลย
ซึ่งมันบั่นทอนชีวิต และ จิตใจอย่างรุนแรง
มันมีเรื่องที่ไม่ควรทำมากมาย
มันไม่มีรูปแบบในการทำที่ตายตัว หรือ ชัดเจน
มันเป็นเรื่องที่ต้องลงมือทำ ดู feedback และปรับปรุงอย่างต่อเนื่อง
ดังนั้นจึงทำการสรุปสิ่งที่ควรทำสำหรับ Automated Acceptance Testing ดังนี้

 อ่านบทความเรื่อง
อ่านบทความเรื่อง 

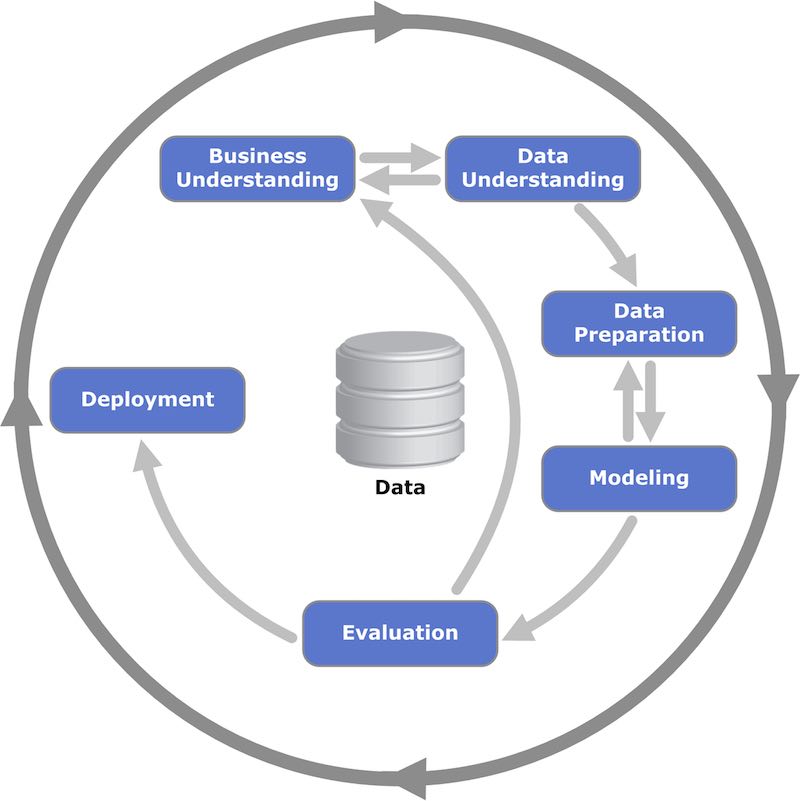
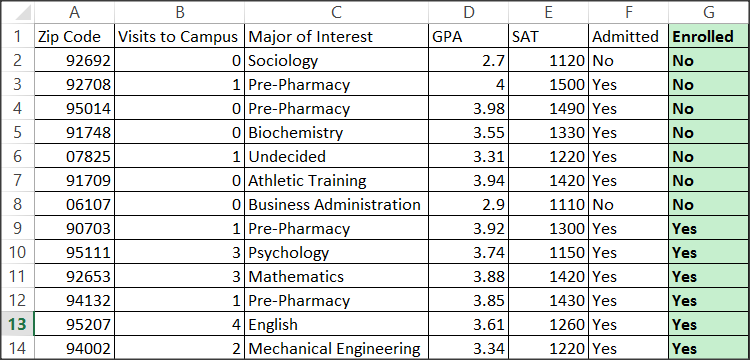
 ในปัจจุบันนั้น พบว่ามีการนำ Data Mining มาใช้เยอะขึ้นมาก ๆ
แต่ส่วนใหญ่ที่พบเจอ
ในปัจจุบันนั้น พบว่ามีการนำ Data Mining มาใช้เยอะขึ้นมาก ๆ
แต่ส่วนใหญ่ที่พบเจอ

 การที่จะพูด หรือ คุยกับเพื่อนร่วมงานในเรื่องของ code
มันเป็นสิ่งที่ยาก และ อาจจะก่อให้เกิด drama ได้
ยิ่งเป็นเรื่อง code ที่มันแย่ ๆ (Bad code) ด้วยแล้ว
ยิ่งมีความเป็นไปได้ว่า อาจถึงขั้นแตกหักได้ !!
ดังนั้น เราลองเปลี่ยนการพูดแบบเบา ๆ กันหน่อยไหม ?
การที่จะพูด หรือ คุยกับเพื่อนร่วมงานในเรื่องของ code
มันเป็นสิ่งที่ยาก และ อาจจะก่อให้เกิด drama ได้
ยิ่งเป็นเรื่อง code ที่มันแย่ ๆ (Bad code) ด้วยแล้ว
ยิ่งมีความเป็นไปได้ว่า อาจถึงขั้นแตกหักได้ !!
ดังนั้น เราลองเปลี่ยนการพูดแบบเบา ๆ กันหน่อยไหม ?


 สำหรับ Java Developer นั้น
การจะสร้าง web application นั้นมันยากเย็นมากนัก
ทั้งวิธีการเขียน code ที่เยอะ
ทั้ง library ต่างๆ ที่ใช้งาน
ทั้ง Web server หรือ Application server
ตลอดจนการ deploy เพื่อทดสอบ
นี่คือกระบวนการพัฒนาแบบคร่าว ๆ
แน่นอนว่า feedback loop มันช้ามาก ๆ
แต่หลาย ๆ คนก็ยังคงทำกันอยู่ ทำไมนะ ?
ดังนั้น เรามาลองสร้าง Web Server และ Web Application ง่าย ๆ ด้วย Spark กันบ้างสิ
ว่ามันช่วยลดงาน และ เพิ่มความเร็วในการพัฒนาบ้างไหม ?
สำหรับ Java Developer นั้น
การจะสร้าง web application นั้นมันยากเย็นมากนัก
ทั้งวิธีการเขียน code ที่เยอะ
ทั้ง library ต่างๆ ที่ใช้งาน
ทั้ง Web server หรือ Application server
ตลอดจนการ deploy เพื่อทดสอบ
นี่คือกระบวนการพัฒนาแบบคร่าว ๆ
แน่นอนว่า feedback loop มันช้ามาก ๆ
แต่หลาย ๆ คนก็ยังคงทำกันอยู่ ทำไมนะ ?
ดังนั้น เรามาลองสร้าง Web Server และ Web Application ง่าย ๆ ด้วย Spark กันบ้างสิ
ว่ามันช่วยลดงาน และ เพิ่มความเร็วในการพัฒนาบ้างไหม ?

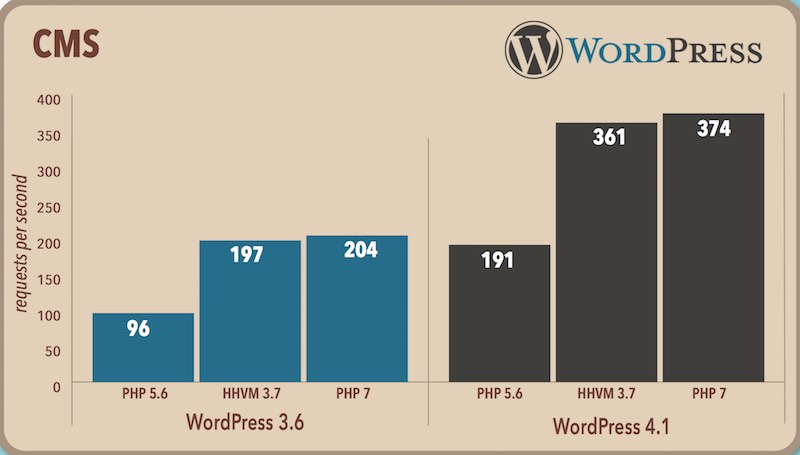
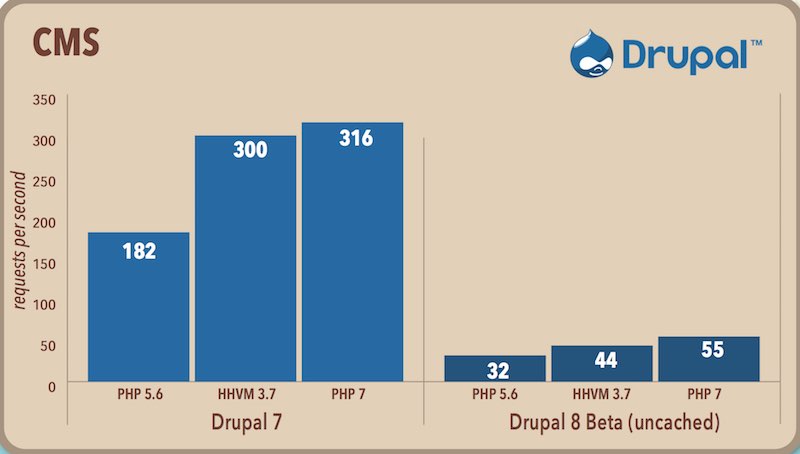
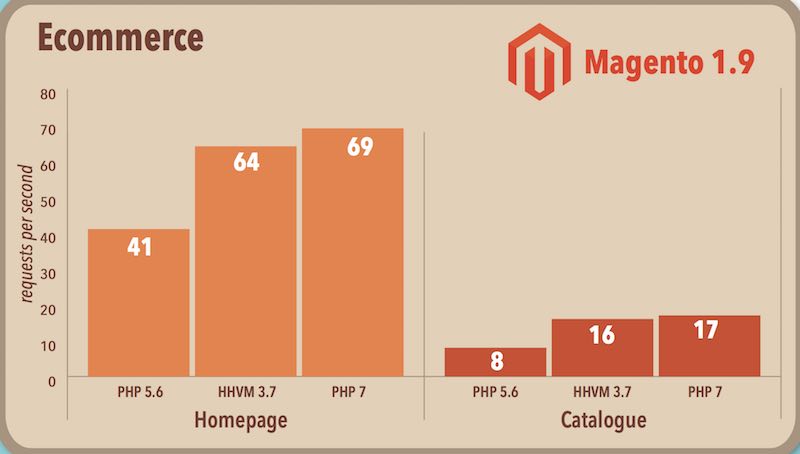
 วันที่ 3 พฤจิกายน 2558 ทีมพัฒนา PHP ได้ปล่อย
วันที่ 3 พฤจิกายน 2558 ทีมพัฒนา PHP ได้ปล่อย 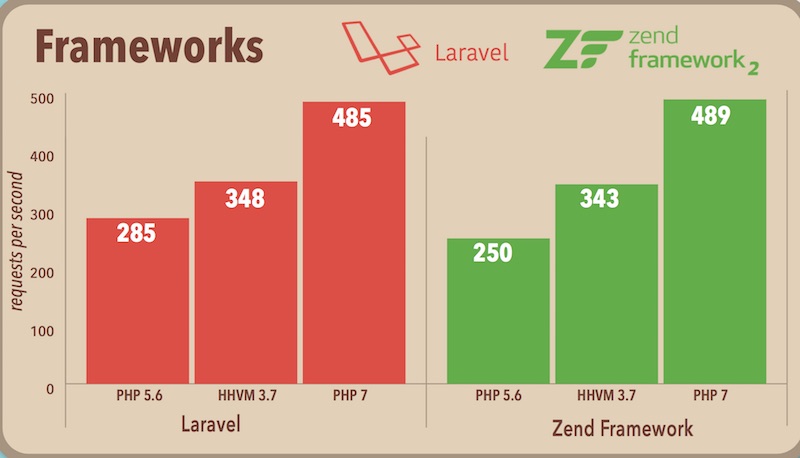
 Reference Websites
Reference Websites

 จากงาน Android Dev Summit 2015 นั้น
มีหัวอีกหัวข้อที่น่าสนใจ คือ
จากงาน Android Dev Summit 2015 นั้น
มีหัวอีกหัวข้อที่น่าสนใจ คือ 
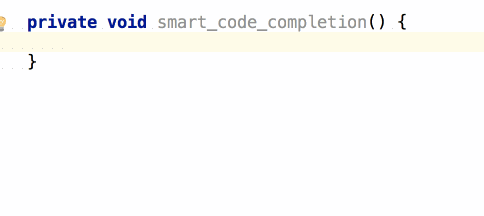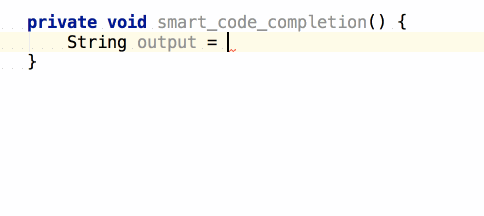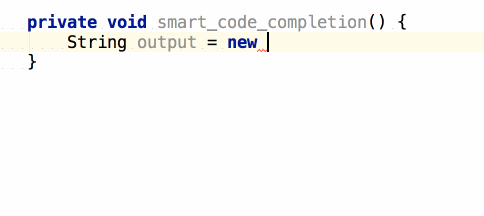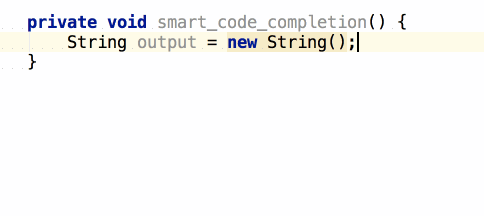

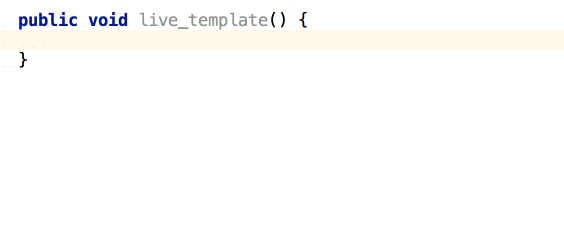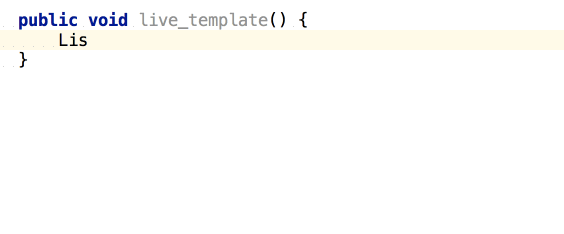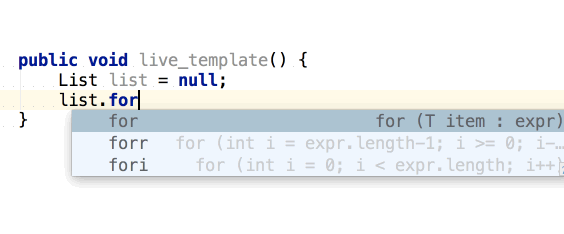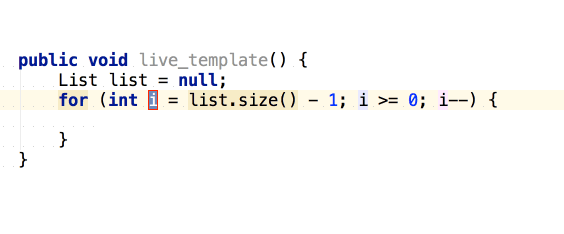
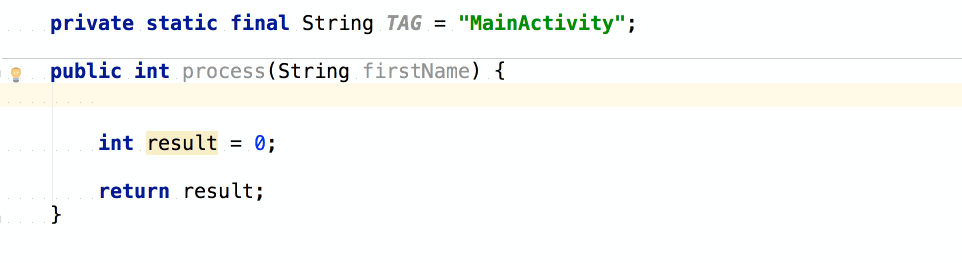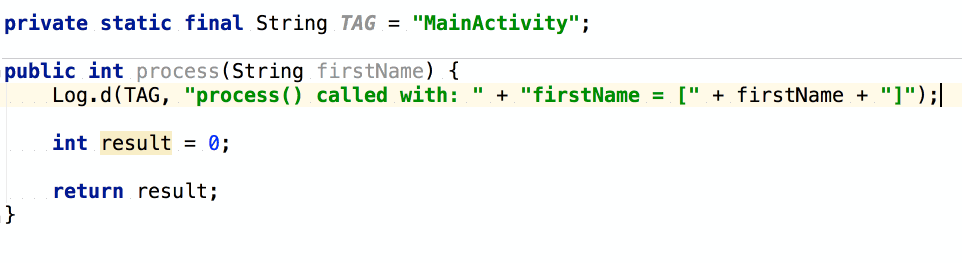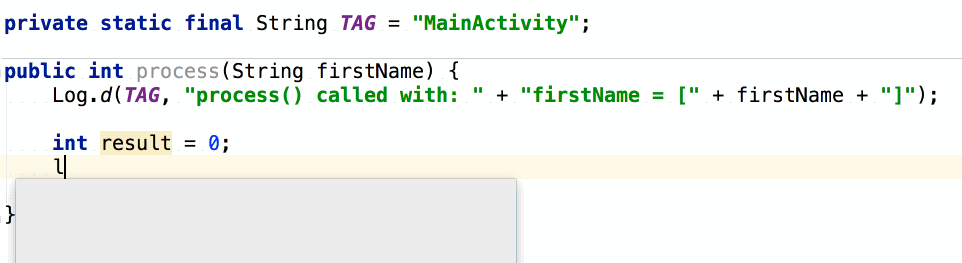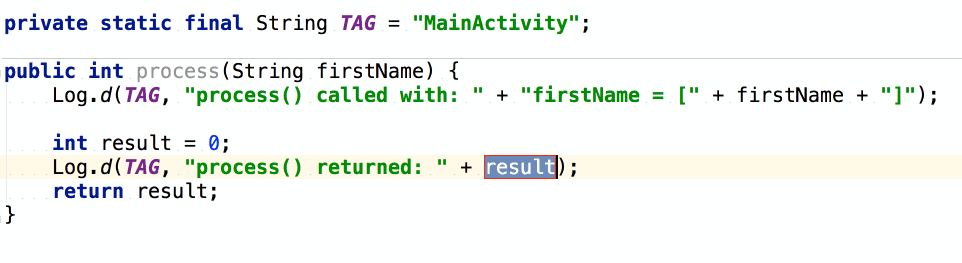
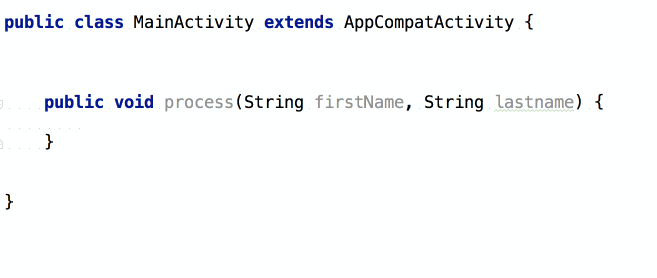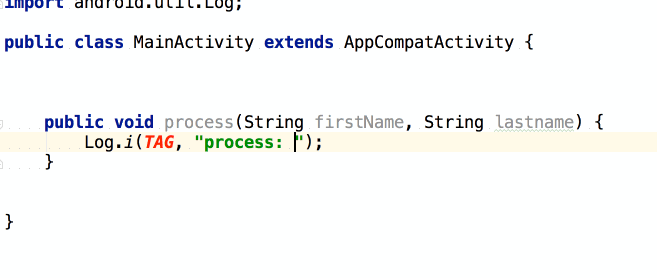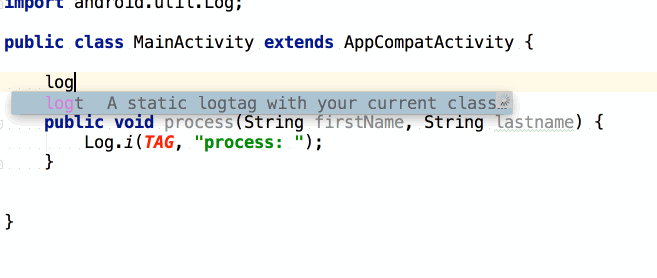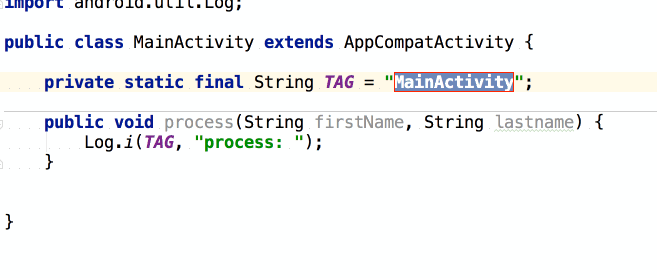 จากนั้นถ้าต้องการเขียน log
ของข้อมูลที่ส่งเข้ามา และ ผลการทำงาน
เราสามารถใช้ logm และ logr ได้เลย
แสดงการใช้งานดังนี้
จากนั้นถ้าต้องการเขียน log
ของข้อมูลที่ส่งเข้ามา และ ผลการทำงาน
เราสามารถใช้ logm และ logr ได้เลย
แสดงการใช้งานดังนี้
 เท่านี้แหละสำหรับ feature ที่มีประโยชน์มาก ๆ ต่อตัวผม
เท่านี้แหละสำหรับ feature ที่มีประโยชน์มาก ๆ ต่อตัวผม



 จากงาน Android Dev Summit 2015 นั้น
นั่งดู VDO เรื่อง
จากงาน Android Dev Summit 2015 นั้น
นั่งดู VDO เรื่อง  คำอธิบาย
ระบบที่ต้องการทดสอบนั้น ผ่าน Frontend server
เมื่อผู้ใช้งานใช้งานแล้วจะต้องติดต่อไปยังระบบ backend 3 ระบบ
โดยที่ End-to-End test นั้นมีเป้าหมาย
เรื่องความเร็วและความน่าเชื่อถือในการทดสอบ
ดังนั้นสิ่งที่เราต้องหลีกเลี่ยงคือ
คำอธิบาย
ระบบที่ต้องการทดสอบนั้น ผ่าน Frontend server
เมื่อผู้ใช้งานใช้งานแล้วจะต้องติดต่อไปยังระบบ backend 3 ระบบ
โดยที่ End-to-End test นั้นมีเป้าหมาย
เรื่องความเร็วและความน่าเชื่อถือในการทดสอบ
ดังนั้นสิ่งที่เราต้องหลีกเลี่ยงคือ
 ซึ่งมันตอบโจทย์เรื่องความเร็ว และ ความน่าเชื่อถือในการทดสอบ End-to-End test
โดยมีขั้นตอนการทดสอบคร่าว ๆ ดังต่อไปนี้
ซึ่งมันตอบโจทย์เรื่องความเร็ว และ ความน่าเชื่อถือในการทดสอบ End-to-End test
โดยมีขั้นตอนการทดสอบคร่าว ๆ ดังต่อไปนี้
 ดังนั้นจึงทำการเปลี่ยนมาใช้ Hermetic UI Testing
นั่นคือการสร้าง Fake server ต่าง ๆ ขึ้นมา
แสดงการทำงานดังรูป
ดังนั้นจึงทำการเปลี่ยนมาใช้ Hermetic UI Testing
นั่นคือการสร้าง Fake server ต่าง ๆ ขึ้นมา
แสดงการทำงานดังรูป
 แต่ปัญหาจากวิธีการนี้ คือ การจัดการ Fake server ต่าง ๆ นั่นเอง
ลองคิดดูสิว่า ถ้ามี server จำนวนมาก ๆ มันจะเป็นอย่างไร !!
เราจำเป็นต้องจัดการให้ดีกว่านี้
เพื่อให้เราแยกส่วนของ Fake server ออกจากการทดสอบได้
รวมทั้งสามารถเปลี่ยนแปลงได้ในขณะ Runtime
นั่นก็คือ การใช้ Dependency Injection
ประกอบกับใน Android มี Build Variant ให้ใช้งาน
ดังนั้น การทดสอบ และ จัดการจึงง่ายขึ้นอย่างมาก ๆ
แสดงการทำงานดังรูป
แต่ปัญหาจากวิธีการนี้ คือ การจัดการ Fake server ต่าง ๆ นั่นเอง
ลองคิดดูสิว่า ถ้ามี server จำนวนมาก ๆ มันจะเป็นอย่างไร !!
เราจำเป็นต้องจัดการให้ดีกว่านี้
เพื่อให้เราแยกส่วนของ Fake server ออกจากการทดสอบได้
รวมทั้งสามารถเปลี่ยนแปลงได้ในขณะ Runtime
นั่นก็คือ การใช้ Dependency Injection
ประกอบกับใน Android มี Build Variant ให้ใช้งาน
ดังนั้น การทดสอบ และ จัดการจึงง่ายขึ้นอย่างมาก ๆ
แสดงการทำงานดังรูป
 มาถึงตรงนี้ น่าจะทำให้เราเข้าใจเกี่ยวกับ Hermetic Testing มากขึ้นแล้วนะ
ดังนั้น กลับไปดู VDO กันต่อสิ !!
มาถึงตรงนี้ น่าจะทำให้เราเข้าใจเกี่ยวกับ Hermetic Testing มากขึ้นแล้วนะ
ดังนั้น กลับไปดู VDO กันต่อสิ !!