![testing]()
![testing]()
วันนี้ได้พูดคุย และ อธิบายเกี่ยวกับ
Test Double ไปนิดหน่อย
จึงนำมาอธิบายเพิ่มเติม พร้อมยกตัวอย่าง
เพื่อทำให้เห็นภาพว่า Test Double แต่ละตัวนั้น
เป็นอย่างไร ใช้งานอย่างไร และ แตกต่างกันอย่างไร
โดยจำอธิบายเฉพาะ Mock, Stub และ Dummy เท่านั้น
เนื่องจากเป็นสิ่งที่ใช้งานบ่อยสุด ๆ แล้ว
มาเริ่มกันเลย
เนื้อหาต่าง ๆ ใน blog นี้อ้างอิงข้อมูลจากบทความเหล่านี้
เนื่องจาก class ส่วนใหญ่ มักจะต้องทำงานร่วมกับ class อื่น ๆ เสมอ
ดังนั้น เมื่อเราเขียน unit test เพื่อทดสอบการทำงาน
เราจำเป็นต้องหลีกเลี่ยงการเรียกใช้งาน class จริง ๆ
ของสิ่งที่ต้องทำงานร่วมกัน
เพื่อให้เราสามารถทดสอบการทำงานได้ตามที่ต้องการ
ซึ่งเทคนิคที่ใช้งานกันคือ
Test Double ซึ่งประกอบไปด้วย 5 ชนิด คือ
- Mock
- Stub
- Spy
- Dummy
- Fake
แต่ขออธิบายพร้อมยกตัวอย่างเฉพาะ Mock, Stub และ Dummy เท่านั้น
เนื่องจากใช้งานบ่อยนั่นเอง
1. Mock
เป็นคำที่ถูกใช้ และ เรียกใช้บ่อยมาก ๆ
และมักจะเรียกแทนตัวอื่น ๆ ใน Test Double กันไปเลย
ดังนั้นมาเข้าใจกับ Mock กันหน่อย
Mock เป็นการตรวจสอบพฤติกรรมการทำงาน ( Behavior verification )
ของ class ที่เราทำงานด้วยว่า
มีการทำงานตามที่เราต้องการ หรือ คาดหวังไว้หรือไม่
ตัวอย่างเช่น
ใน Service ของเราต้องเรียกใช้ DAO เพื่อทำการบันทึกข้อมูล
สิ่งที่เราต้องการ คือ DAO ทำการบันทึกหรือไม่ ?
นั่นหมายถึง method save() ของ DAO ถูกเรียกหรือไม่นั่นเอง
คำถามคือ แล้วจะจะทดสอบได้อย่างไรล่ะ ?
มาดูตัวอย่าง code กัน
เริ่มที่ class UserService กันก่อน ซึ่งเราต้องการที่จะทดสอบ
[gist id="ec087ea9702345027fbf" file="UserService.java"]
คำอธิบาย
จะเห็นได้ว่า class UserService นั้นมี class ที่ทำงานด้วย 2 class คือ
UserDAO และ User
แต่ class ที่เราสนใจพฤติกรรมการทำงานก็คือ UserDAO
ซึ่งเราต้องการรู้ว่า พฤติกรรมการทำงานมันถูกต้องหรือไม่ ?
เมื่อ method createUser() จาก class UserService ถูกเรียกใช้งานแล้ว
method save() ของ class UserDAO ต้องถูกเรียกใช้งานด้วย
เราสามารถเขียนการทดสอบได้ดังนี้
[gist id="ec087ea9702345027fbf" file="UserServiceTest.java"]
คำอธิบาย
ในการทดสอบจะเห็นได้ว่า
ในส่วนของ Test Fixtures หรือ ข้อมูลสำหรับการทดสอบนั้น
เราจะทำการ mock class UserDAO ( ตัวอย่างนี้ใช้ mock library ชื่อว่า
Mockito )
จากนั้นในการทดสอบ
จะทำการตรวจสอบพฤติกรรมการทำงานของ class UserDAO ว่า
มีการเรียกใช้ method save() หรือไม่
ปล. ถ้าไม่ต้องการใช้ mock library
สามารถเขียนเองได้นะครับ
วิธีที่ง่ายที่สุดคือ การ extends จาก class UserDAO นั่นเอง
2. Stub
บางคนจะเรียกว่า
Stub out
หรือเป็นการกำหนดสถานะของสิ่งนั้น ๆ ตามต้องการ
ว่าต้องการให้ object ที่ทำงานด้วยนั้นมีสถานะอย่างไร ?
จะมีสถานะถูก หรือ ผิด ตามที่ต้องการทดสอบ
ดังนั้นจึงเรียกว่า
State verification
นั่นแสดงว่า เราต้องการตรวจสอบสถานะของ object
ว่าถูกต้องตามที่เราคาดหวังหรือไม่ นั่นเอง
ตัวอย่างเช่น
ใน class UserService นั้น จำเป็นต้องทำการตรวจสอบข้อมูลของผู้ใช้งาน
ผ่าน class UserValidationService
ถ้าผ่านจะทำการกำหนดสถานะของผู้ใช้งานให้เป็น TRUE
แต่ถ้าไม่คือ FALSE
มาดูตัวอย่าง code กันดีกว่า
[gist id="ec087ea9702345027fbf" file="UserService2.java"]
ถ้าเราต้องการทดสอบ
โดยให้บันทึกข้อมูลสถานะของผู้ใช้งานเป็น TRUE ล่ะ
เราจะต้องทำอย่างไร ?
สิ่งที่ทำได้ตอนนี้คือ Stub การทำงานของ class UserValidationService มันไปเลย
ดังนั้นถ้าเรียกใช้งานผ่าน method isValid() แล้ว
จะต้อง return ค่า TRUE ออกมาเสมอ
เขียน code ของการทดสอบได้ดังนี้
[gist id="ec087ea9702345027fbf" file="UserServiceTest2.java"]
คำอธิบาย
จะเห็นได้ว่าได้ทำการสร้าง Stub ด้วยการ extends มาจาก class จริง ๆ
โดย stub นี้จะส่งค่า TRUE กลับมาเสมอเมื่อเรียกใช้งาน method isValid()
ทำให้เราสามารถควบคุมสิ่งต่าง ๆ ได้
นั่นส่งผลให้เราสามารถทดสอบการทำงานได้ซ้ำแล้วซ้ำเล่า
นี่คือการตรวจสอบสถานะของการทำงานด้วย Stub
ถ้าถามว่าระหว่าง Mock กับ Stub ใช้อะไรเยอะกว่า
ผมตอบได้เลยว่า ใช้ Stub เยอะกว่ามาก
3. Dummy
ชื่อมันตรงตามตัวเลย คือ ให้เราสร้าง class หน้าโง่ ๆ ขึ้นมา
มันอาจจะไม่มีการ implement อะไรเลย
มีเพียงเพื่อให้ code ของเรา compile ผ่านเท่านั้นเอง
ส่ง dummy เข้าไป เพื่อให้มันครบตามที่ต้องการเท่านั้นเอง
โดย dummy เหล่านี้ไม่สามารถนำไปใช้งานจริง ๆ ได้นะ !!
ตัวอย่างเช่น
จากการทดสอบในตัวอย่างของ Stub นั้น
จะพบว่ามี class หนึ่งที่ไมีถูกใช้งานอะไรเลย
นั่นก็คือ class UserDAO
ดังนั้น ถ้าเราต้องการสร้าง Dummy ของ class UserDAO ขึ้นมาล่ะ
จะต้องทำอย่างไรดี ?
โดยถ้าใครมาเรียกใช้ method ต่าง ๆ ของ class Dummy
จะต้องโยน exception ออกมาเสมอ เพราะว่า มันคือ dummy ไงล่ะ
เอาไปใช้งานจริง ๆ ไม่ได้หรอกนะ
มาดู code กันดีกว่า
[gist id="ec087ea9702345027fbf" file="UserServiceTest3.java"]
ปล. พวก inner class ต่าง ๆ เหล่านี้
ถ้าต้องการใช้ซ้ำ ๆ จากการทดสอบอื่น ๆ แล้ว
แนะนำให้แยกออกไปสร้าง class ใหม่เลยนะ
มาถึงตรงนี้แล้ว เป็นยังไงกันบ้าง ?
น่าจะพอทำให้เห็นภาพของ Mock, Stub และ Dummy ได้ชัดเจนมากยิ่งขึ้น
ส่วนของ Spy กับ Fake ขออธิบายสั้น ๆ ก็แล้วกัน
ไม่เช่นนั้นจะงงกันมากไปกว่าเดิม
4. Spy
ถูกใช้เมื่อเราต้องการทำให้มั่นใจว่า
พฤติกรรมการทำงานของสิ่งที่เราสนใจ
มันทำงานได้ถูกต้องจริง ๆ นะ ( Exclusive behavior verification )
เช่น ต้องเรียกมากกว่า 1 ครั้ง เป็นต้น
แต่ข้อเสียของ Spy ที่เห็นได้ชัด คือ code ของการทดสอบจะผูกติดกับ code จริง ๆ มากจนเกินไป
บางครั้งมันคือการ lock spec ของ code เลย
ดังนั้น เมื่อมีการแก้ไข code จะกระทบต่อส่วนการทดสอบอย่างมาก
5. Fake
เป็นการ implement ที่เหมือนจริงมาก ๆ
บางครั้งเกือบแยกไม่ออกกับของจริงเลยด้วยซ้ำ
ทำให้เป็นข้อเสียหนึ่งของ Fake
แต่มันเหมาะสมกับการจัดการกับบางสิ่งบางอย่าง
ที่ไม่สามารถทดสอบบน production หรือ server จริง ๆ ได้
ตัวอย่างของ Fake ที่ชัดเจนมาก ๆ คือ Memory database
โดยสรุปแล้ว
Test Double ใช้สำหรับการทำงานร่วมกันของ class ต่าง ๆ ในส่วนของการทดสอบ หรือ unit test นั่นเอง
โดย Test Double ที่ใช้มาก ๆ คือ Mock, Stub และ Dummy
ดังนั้น developer ทั้งหลายจะต้องศึกษา เรียนรู้ และ ทำความเข้าใจ
ว่าแต่ละตัวมันคืออะไร
ว่าแต่ละตัวใช้งานอย่างไร
ว่าแต่ละตัวแตกต่างกันอย่างไร
สุดท้ายจริง ๆ
ถ้าต้องการให้การทดสอบมันทำได้ง่าย ๆ
แต่ละส่วนการทำงาน หรือ แต่ละ class
ต้องไม่ผูกมัดกันแน่น (Loose coupling) นะ
ต้องแยกเป็นอิสระต่อกัน (Isolation)
เชื่อเถอะว่า ถ้า code มันทดสอบได้ยาก
แสดงว่า code ที่เขียนขึ้นมามันก็ยาก แถมผูกมัดกันแบบแน่น ๆ ( ลองหา new ใน code ดูสิ !! )
ซึ่งเป็นที่มาของ spaghetti code นั่นเอง

 วันนี้ได้อ่านบทความเรื่อง How to prevent eventual crappiness
ซึ่งได้อธิบายไว้ว่า
วันนี้ได้อ่านบทความเรื่อง How to prevent eventual crappiness
ซึ่งได้อธิบายไว้ว่า



 เชื่อว่า Developer ทุกคนนั้นใช้เวลาส่วนใหญ่อยู่หน้า computer
บางคนใช้เวลามากกว่า 8 ชั่วโมงต่อวัน
เพื่อสร้างสรรค์สิ่งต่าง ๆ ขึ้นมา
ทั้งมีคุณค่า และ ไร้ซึ่งคุณค่า
มันเป็นโลกที่ใคร ๆ ก็สามารถสร้างได้
และสามารถพัฒนาต่อยอด เพื่อให้เติบโตขึ้นได้เรื่อย ๆ
และสามารถเชื่อมโยงกับระบบต่าง ๆ ได้อีกด้วย
แต่โลกใบนี้เราไม่ได้ทำอยู่คนเดียวนะ
การทำงานเหล่านี้ต้องทำงานกันเป็น TEAM
ดังนั้น จะทำอะไรต้องคิด และ ใส่ใจกันหน่อยสิ
เชื่อว่า Developer ทุกคนนั้นใช้เวลาส่วนใหญ่อยู่หน้า computer
บางคนใช้เวลามากกว่า 8 ชั่วโมงต่อวัน
เพื่อสร้างสรรค์สิ่งต่าง ๆ ขึ้นมา
ทั้งมีคุณค่า และ ไร้ซึ่งคุณค่า
มันเป็นโลกที่ใคร ๆ ก็สามารถสร้างได้
และสามารถพัฒนาต่อยอด เพื่อให้เติบโตขึ้นได้เรื่อย ๆ
และสามารถเชื่อมโยงกับระบบต่าง ๆ ได้อีกด้วย
แต่โลกใบนี้เราไม่ได้ทำอยู่คนเดียวนะ
การทำงานเหล่านี้ต้องทำงานกันเป็น TEAM
ดังนั้น จะทำอะไรต้องคิด และ ใส่ใจกันหน่อยสิ

 คำถาม
ถ้าต้องการกำหนดให้แต่ละ Sampler ใน
คำถาม
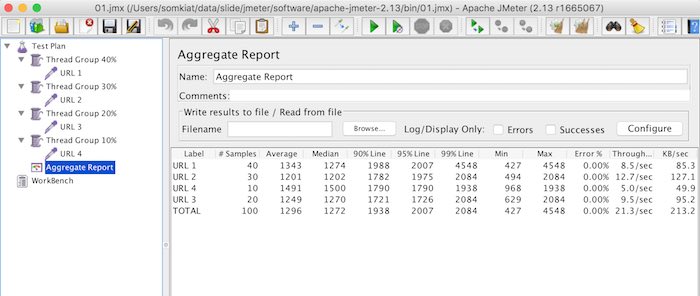
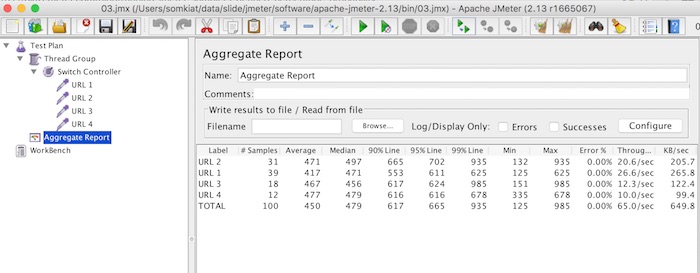
ถ้าต้องการกำหนดให้แต่ละ Sampler ใน 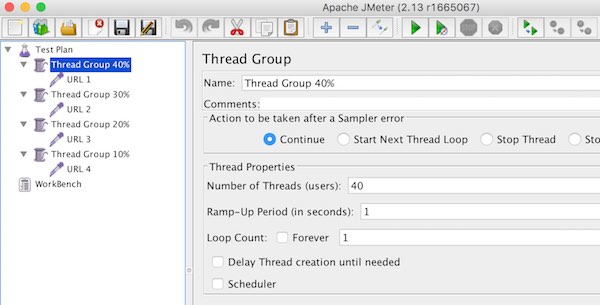 ผลการทดสอบเป็นดังรูป
ผลการทดสอบเป็นดังรูป
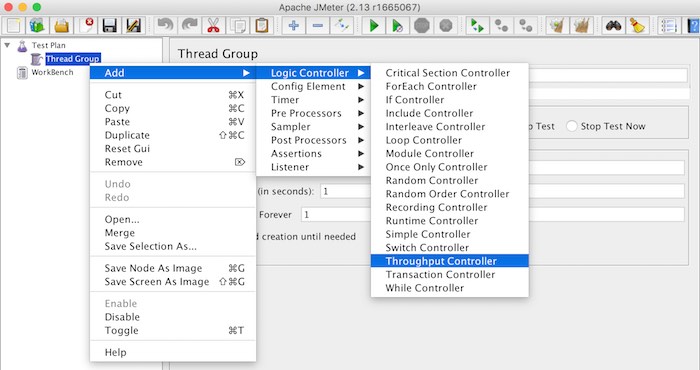 โดยแต่ละ Controller สามารถกำหนดให้เป็น Percent Executions
และกำหนดค่าดังรูป
โดยแต่ละ Controller สามารถกำหนดให้เป็น Percent Executions
และกำหนดค่าดังรูป
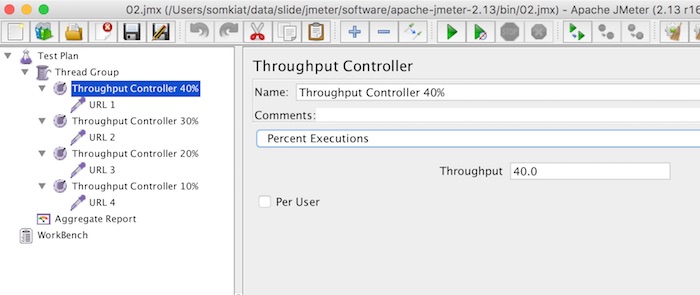 ผลการทดสอบเป็นดังรูป
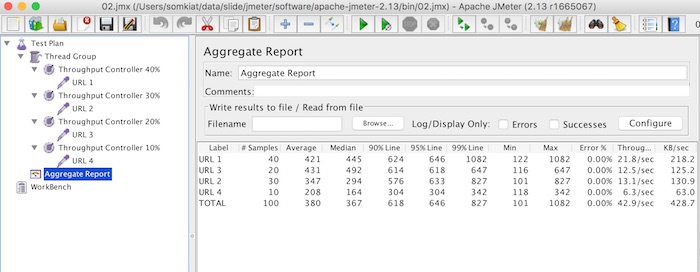
ผลการทดสอบเป็นดังรูป
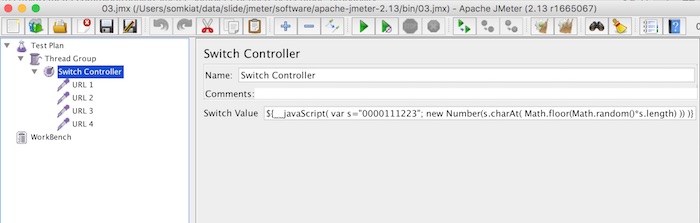
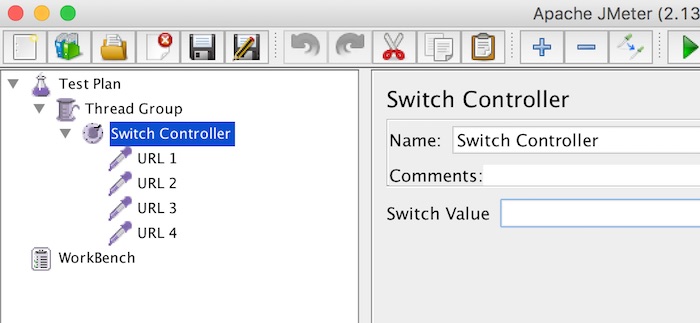 สิ่งที่ยากก็คือ แล้วใน Switch value มันมีค่าอะไรได้บ้าง ?
ตอบได้เลยว่า เป็นได้ทั้ง integer และ string
จากรูปข้างบน
ถ้าเราต้องการให้ URL 1 ทำงาน จะกำหนดค่าเป็น 0 หรือ URL 1
ถ้าเราต้องการให้ URL 2 ทำงาน จะกำหนดค่าเป็น 1 หรือ URL 2
คำถาม
แล้วเราจะกำหนดค่าอย่างไรให้มัน dynamic หรือ กระจายผู้ใช้งานไปแต่ละ URL ล่ะ ?
คำตอบ
มันยากนะ
แต่ลองงคิดหน่อยสิ ว่า สิ่งที่ทำได้คือ
การ Random ตัวเลข และ กำหนดน้ำหนักซะ
โดยการให้น้ำหนักจะเป็นดังนี้
สิ่งที่ยากก็คือ แล้วใน Switch value มันมีค่าอะไรได้บ้าง ?
ตอบได้เลยว่า เป็นได้ทั้ง integer และ string
จากรูปข้างบน
ถ้าเราต้องการให้ URL 1 ทำงาน จะกำหนดค่าเป็น 0 หรือ URL 1
ถ้าเราต้องการให้ URL 2 ทำงาน จะกำหนดค่าเป็น 1 หรือ URL 2
คำถาม
แล้วเราจะกำหนดค่าอย่างไรให้มัน dynamic หรือ กระจายผู้ใช้งานไปแต่ละ URL ล่ะ ?
คำตอบ
มันยากนะ
แต่ลองงคิดหน่อยสิ ว่า สิ่งที่ทำได้คือ
การ Random ตัวเลข และ กำหนดน้ำหนักซะ
โดยการให้น้ำหนักจะเป็นดังนี้
 ผลการทดสอบเป็นดังรูป
ซึ่งแน่นอนว่าผลไม่ถูกต้องตามที่เราต้องการ
เนื่องจากเป็นการ Random ให้ให้น้ำหนักเท่านั้นเองนะ
แต่ก็ใกล้เคียงกับสิ่งที่ต้องการเช่นเดียวกัน
ผลการทดสอบเป็นดังรูป
ซึ่งแน่นอนว่าผลไม่ถูกต้องตามที่เราต้องการ
เนื่องจากเป็นการ Random ให้ให้น้ำหนักเท่านั้นเองนะ
แต่ก็ใกล้เคียงกับสิ่งที่ต้องการเช่นเดียวกัน
 ลองดูว่าทั้งสามวิธีนี้
วิธีไหนที่เหมาะกับ use case มากที่สุด
ลองดูว่าทั้งสามวิธีนี้
วิธีไหนที่เหมาะกับ use case มากที่สุด

 ในบทที่ 12 เรื่อง Go Faster! จากหนังสือ
ในบทที่ 12 เรื่อง Go Faster! จากหนังสือ 
 มาดูกันหน่อยว่า
ข้อมูลแนวโน้มของเทคโนโลยี และ เครื่องมือต่าง ๆ
จาก
มาดูกันหน่อยว่า
ข้อมูลแนวโน้มของเทคโนโลยี และ เครื่องมือต่าง ๆ
จาก 
 จากหนังสือ
จากหนังสือ 
 ลองคิดดูสิว่า
ถ้าเราเขียน customer test หรือ Acceptance test มาแทนที่ requirement
มันน่าจะดีกว่าไหมนะ ?
มันจะช่วยลดงานเอกสารลงไปไหมนะ ?
มันน่าจะช่วยเพิ่มคุณค่าให้กับ product หรือเปล่านะ ?
ลองคิดดูสิว่า
ถ้าเราเขียน customer test หรือ Acceptance test มาแทนที่ requirement
มันน่าจะดีกว่าไหมนะ ?
มันจะช่วยลดงานเอกสารลงไปไหมนะ ?
มันน่าจะช่วยเพิ่มคุณค่าให้กับ product หรือเปล่านะ ?


 ข้อมูลจาก
ข้อมูลจาก 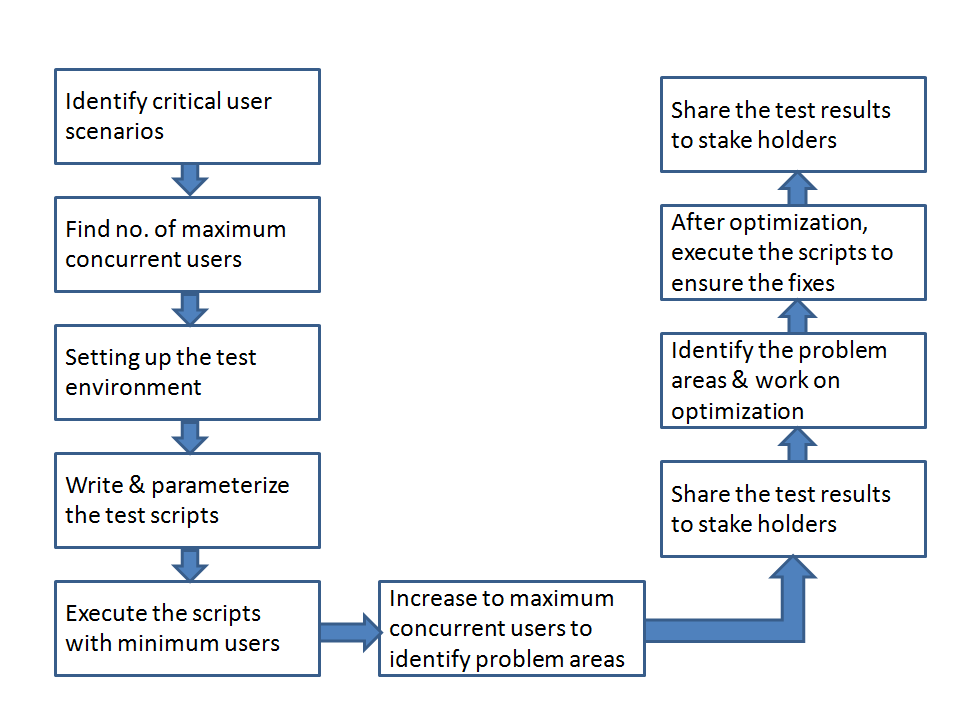

 วันนี้ได้พูดคุย และ อธิบายเกี่ยวกับ
วันนี้ได้พูดคุย และ อธิบายเกี่ยวกับ 
 จากบทความเรื่อง
จากบทความเรื่อง 
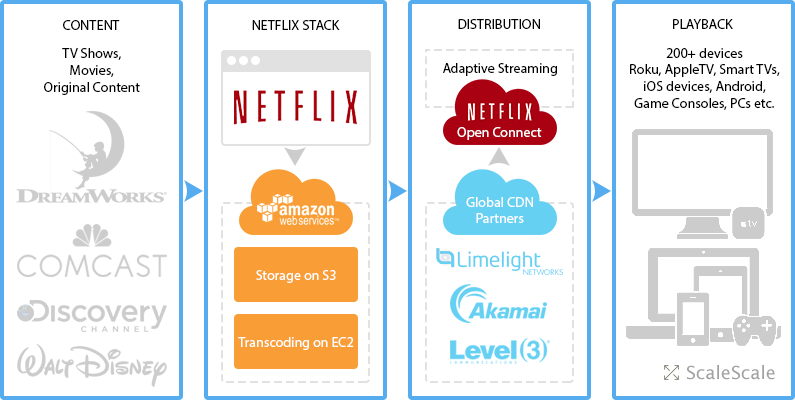
 จากบทความเรื่อง
จากบทความเรื่อง 




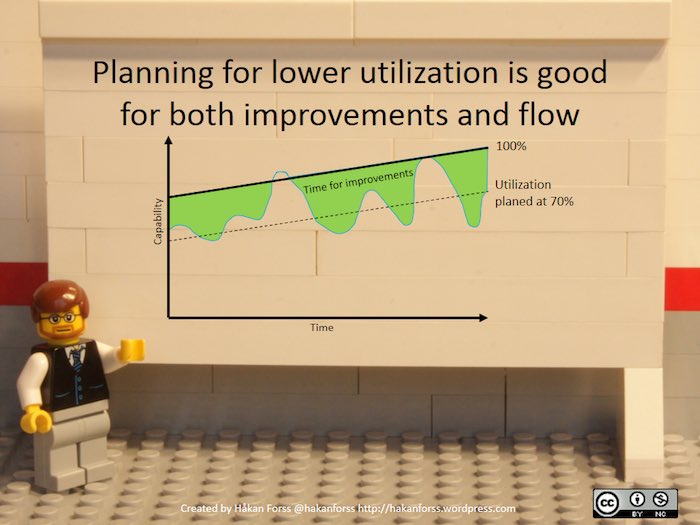







 การสร้างชุดของ Automated test หรือ การทดสอบแบบอัตโนมัติ มันทำได้ยากมาก ๆ
โดยเฉพาะพวกระบบ Legacy
หรือ ระบบที่อยู่มาอย่างยาวนาน
หรือ ระบบที่ไม่ได้เขียน Automated test มาตั้งแต่เริ่มต้น
รวมทั้งยังพบว่า
ทีมพัฒนาส่วนใหญ่จะไม่ลงทุนเพื่อเขียนอีกต่างหาก
เนื่องจากคิดว่า เราคงทำไม่ได้หรอก
เนื่องจากคิดว่า มันสิ่งเปลืองเวลา
เนื่องจากคิดว่า ระบบของเรามันแตกต่าง
เนื่องจากคิดว่า ระบบที่เราสร้างมันไม่สามารถเขียน Automated test ได้หรอกนะ
ซึ่งเป็นแนวคิดที่ไม่ถูกต้อง และ นำไปสู่หายนะในที่สุด
ทำไมนะ ?
บทความนี้ นำข้อมูลมาจาก Blog เรื่อง
การสร้างชุดของ Automated test หรือ การทดสอบแบบอัตโนมัติ มันทำได้ยากมาก ๆ
โดยเฉพาะพวกระบบ Legacy
หรือ ระบบที่อยู่มาอย่างยาวนาน
หรือ ระบบที่ไม่ได้เขียน Automated test มาตั้งแต่เริ่มต้น
รวมทั้งยังพบว่า
ทีมพัฒนาส่วนใหญ่จะไม่ลงทุนเพื่อเขียนอีกต่างหาก
เนื่องจากคิดว่า เราคงทำไม่ได้หรอก
เนื่องจากคิดว่า มันสิ่งเปลืองเวลา
เนื่องจากคิดว่า ระบบของเรามันแตกต่าง
เนื่องจากคิดว่า ระบบที่เราสร้างมันไม่สามารถเขียน Automated test ได้หรอกนะ
ซึ่งเป็นแนวคิดที่ไม่ถูกต้อง และ นำไปสู่หายนะในที่สุด
ทำไมนะ ?
บทความนี้ นำข้อมูลมาจาก Blog เรื่อง 
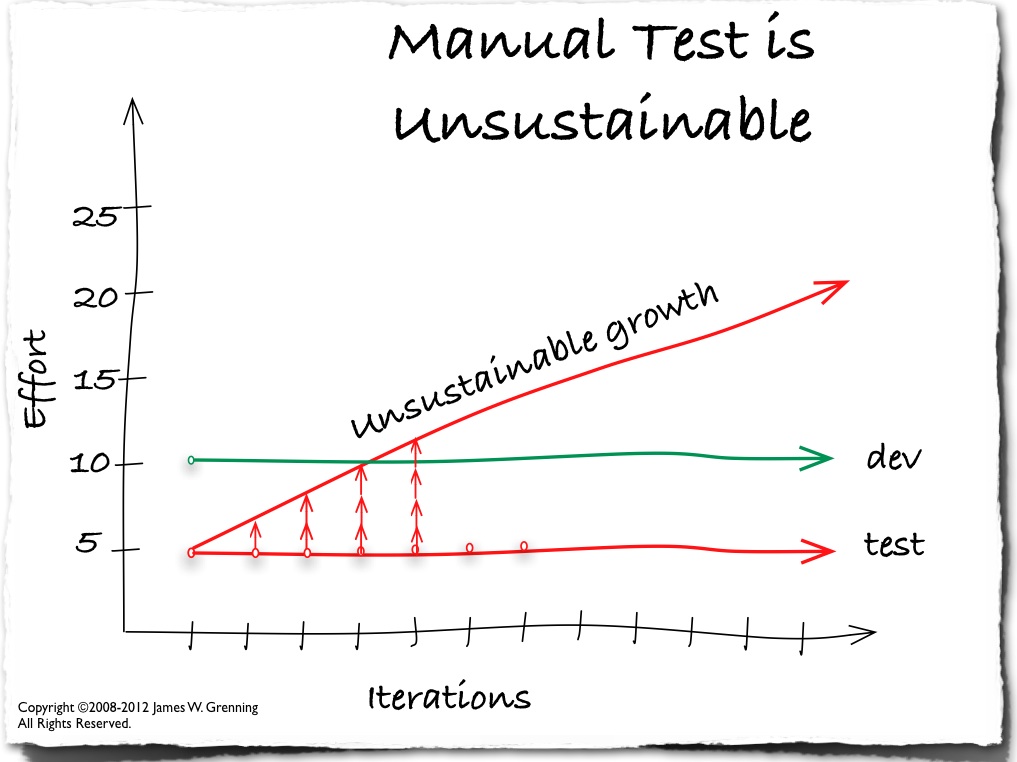
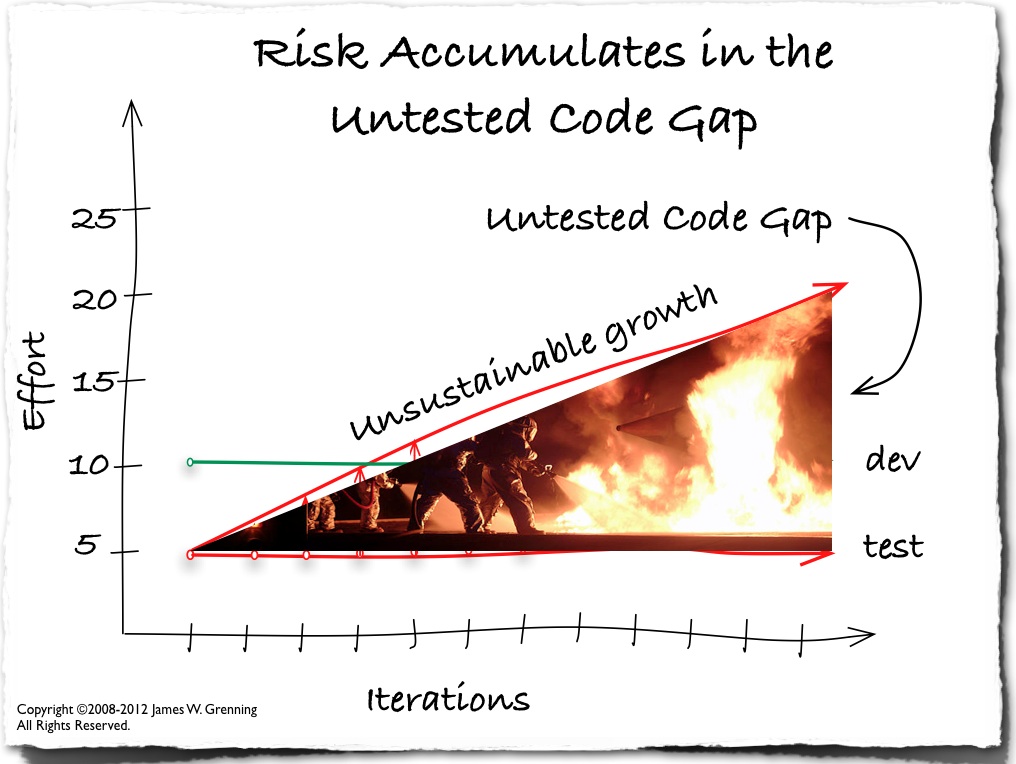

 จาก blog เรื่อง
จาก blog เรื่อง 


 จาก blog เรื่อง
จาก blog เรื่อง 
 จาก Engineering blog ของ Pinterest เรื่อง
จาก Engineering blog ของ Pinterest เรื่อง 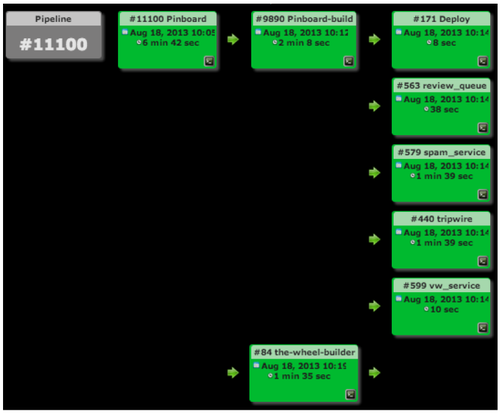
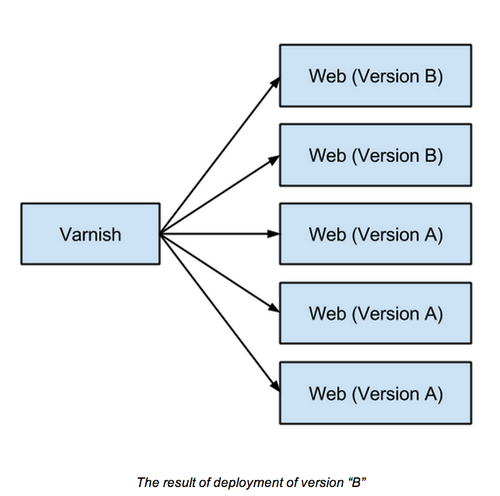

 ปีนี้ไม่ได้ไปร่วมงาน
ปีนี้ไม่ได้ไปร่วมงาน 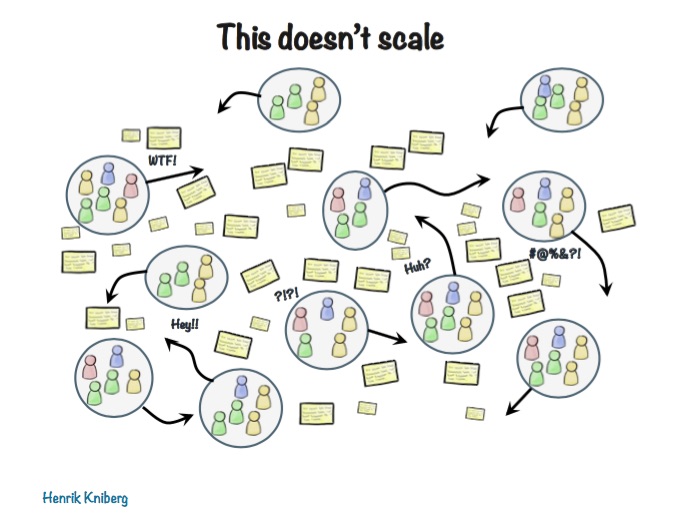
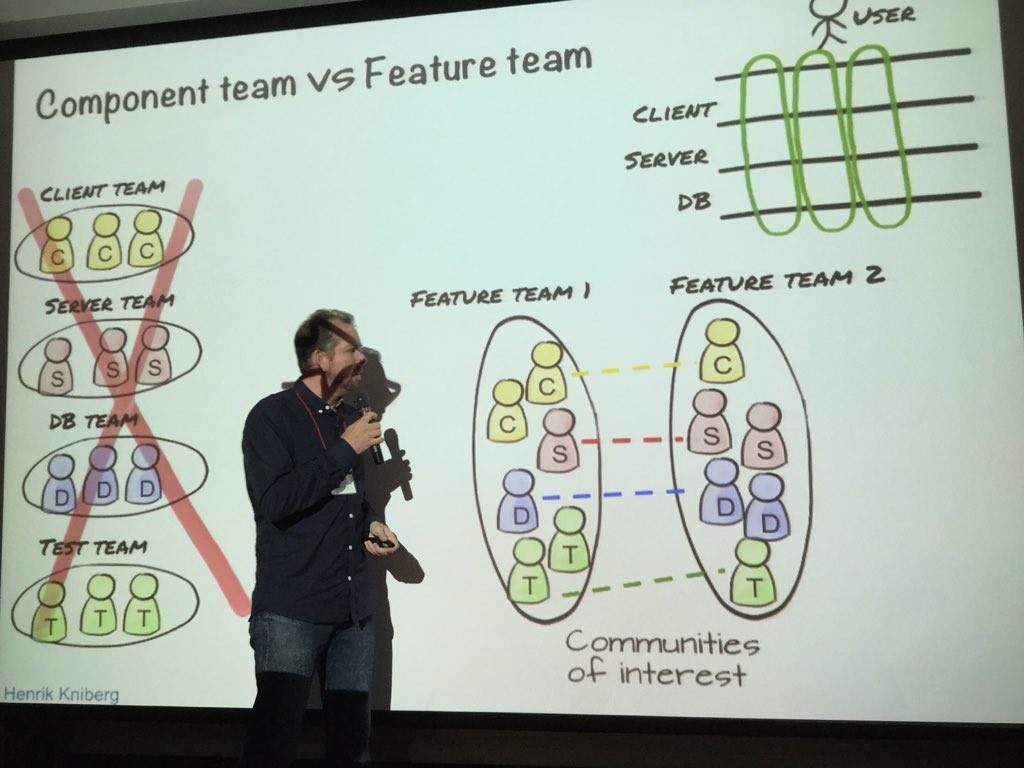
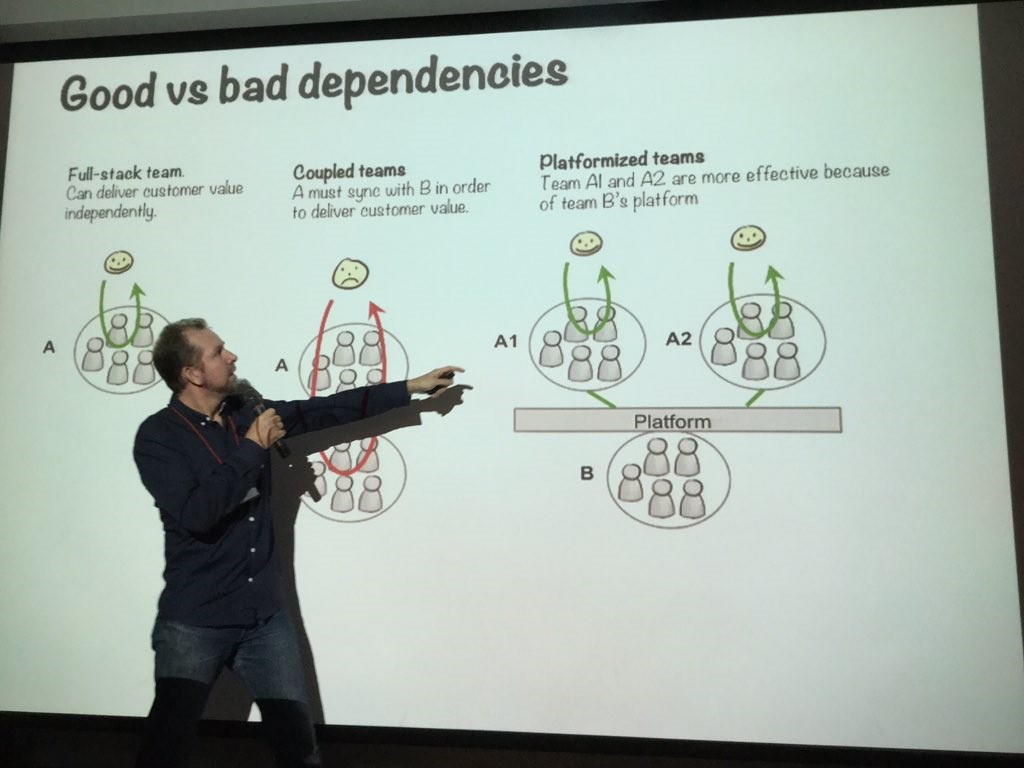
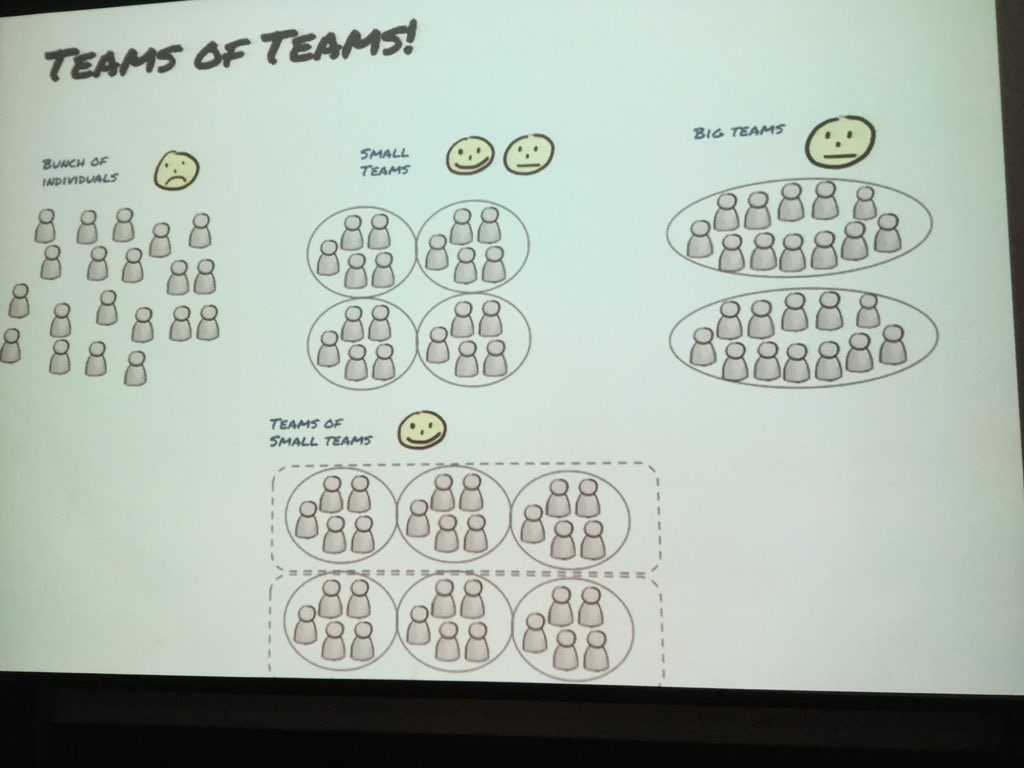
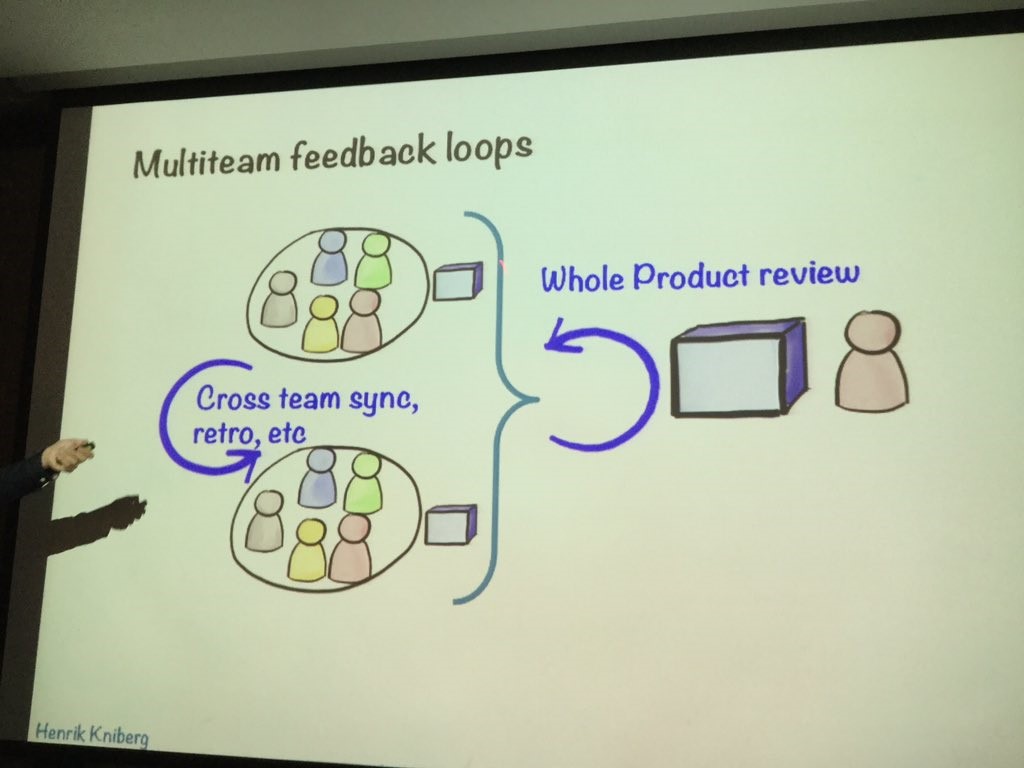
 โดยในการ Scaling Agile ต้องรู้และเข้าใจสิ่งต่าง ๆ เหล่านี้ มิเช่นนั้นจะนำไปสู่หายนะได้
โดยในการ Scaling Agile ต้องรู้และเข้าใจสิ่งต่าง ๆ เหล่านี้ มิเช่นนั้นจะนำไปสู่หายนะได้
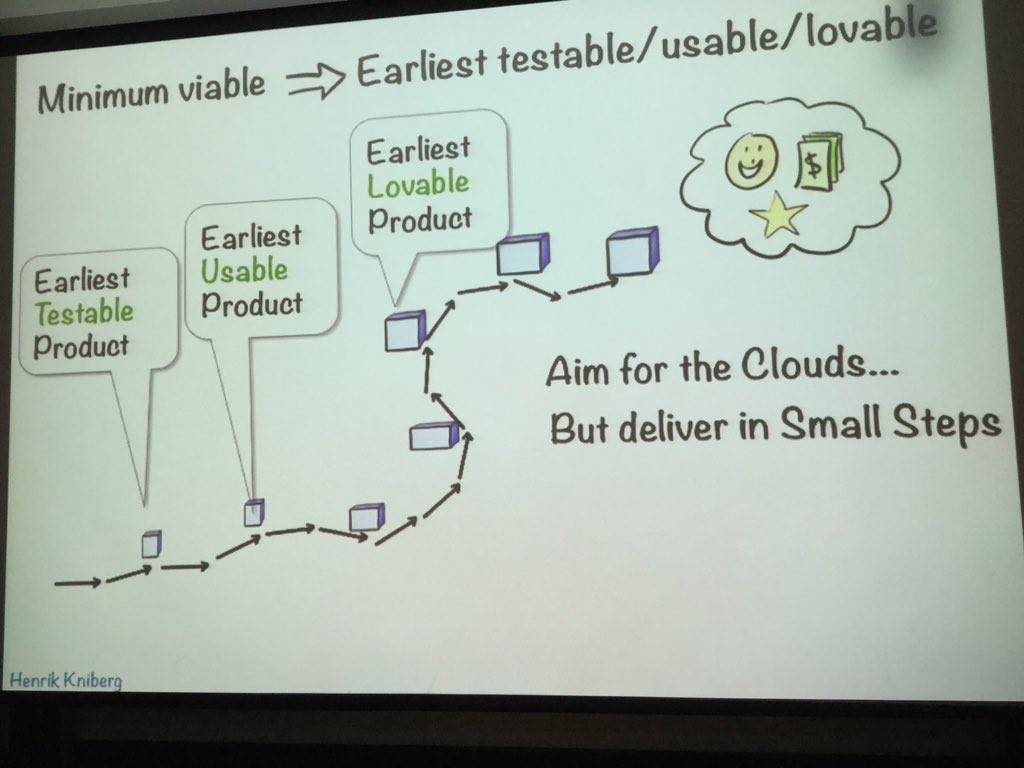
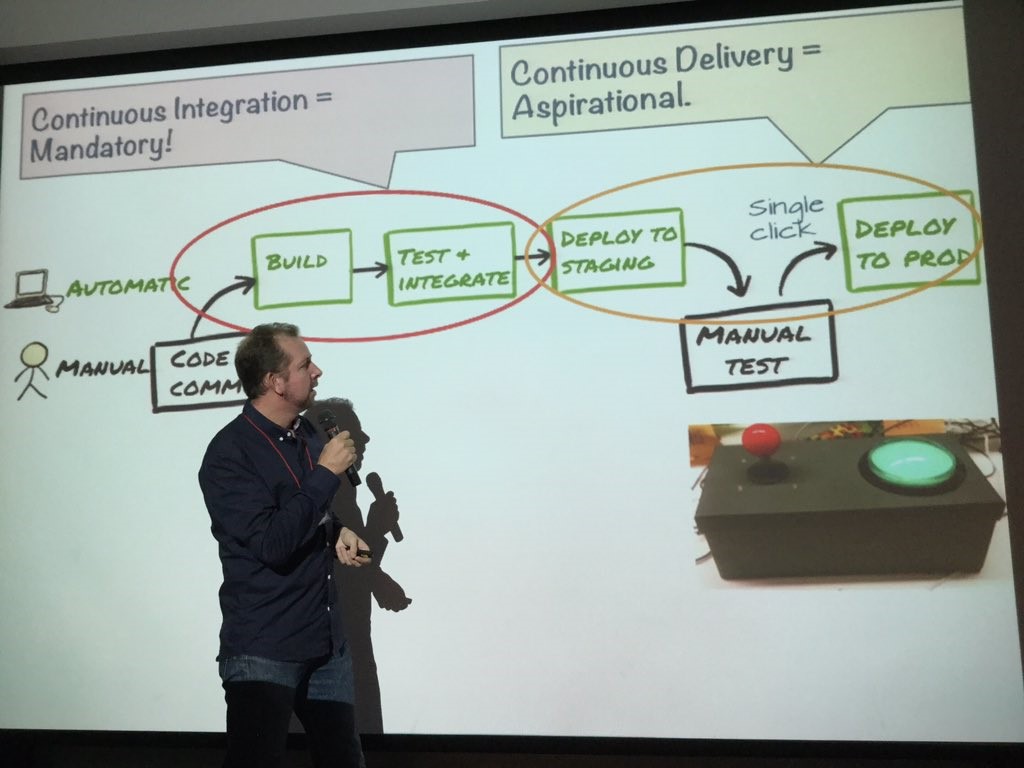
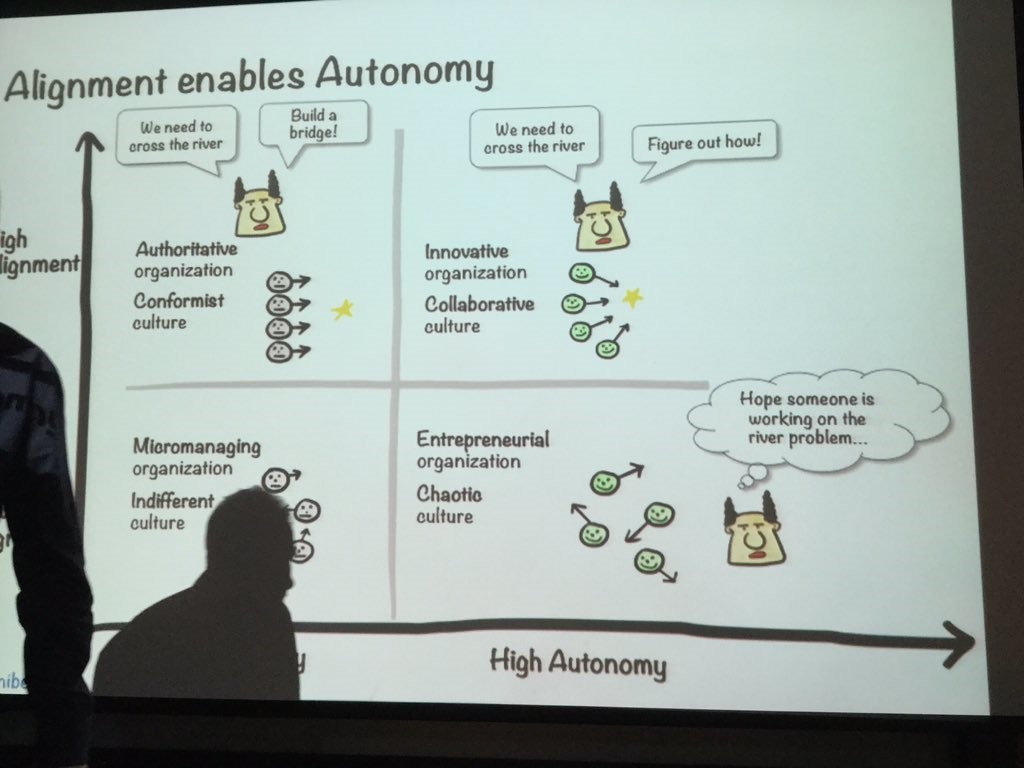

 ไม่ได้ไปร่วมงาน แต่ได้อ่านได้แปล ก็ ok ล่ะ !!
ไม่ได้ไปร่วมงาน แต่ได้อ่านได้แปล ก็ ok ล่ะ !!
 หลังจากที่รู้จักกับ Elasticsearch ตั้งแต่ verison 0.9 มาจนถึง 2.0 นั้น
มีความสามารถต่าง ๆ เปลี่ยนแปลงไปมากมาย
หนึ่งในนั้นคือ Mapping หรือ การกำหนดโครงสร้างของข้อมูล
มาดูว่าควรทำการกำหนด mapping อย่างไร
เพื่อให้ทำงานได้ดียิ่งขึ้น
สามารถใช้ได้ทั้ง version 1.7 และ 2.0
หลังจากที่รู้จักกับ Elasticsearch ตั้งแต่ verison 0.9 มาจนถึง 2.0 นั้น
มีความสามารถต่าง ๆ เปลี่ยนแปลงไปมากมาย
หนึ่งในนั้นคือ Mapping หรือ การกำหนดโครงสร้างของข้อมูล
มาดูว่าควรทำการกำหนด mapping อย่างไร
เพื่อให้ทำงานได้ดียิ่งขึ้น
สามารถใช้ได้ทั้ง version 1.7 และ 2.0