![code-quality-00]()
![code-quality-00]()
นั่งดู VDO เรื่อง
Code Quality Lessons Learned จาก CodeClimate.com
ตั้งคำถามที่น่าสนใจเกี่ยวกับ Code Quality ไว้ดังนี้
- Code Quality คืออะไร ?
- ใช้อะไรวัดค่าความซับซ้อนของ code ?
- ทำไม code ของ project เก่า ๆ ถึงดูแลยากนักล่ะ ?
- ขนาดของ code ในแต่ละ Pull request สำหรับการ review ควรเป็นเท่าไรดี ?
- เมื่อไรที่ code แย่ ๆ ไม่ใช่ปัญหา ?
- อะไรบ้างที่เป็นตัวขัดขวาง Clean code ?
เท่านี้ก็น่าสนใจแล้ว
จึงทำการสรุปไว้นิดหน่อย
ส่วนตัวเต็ม ๆ ลองไปฟังจาก VDO ได้ครับแค่ 1 ชั่วโมงเอง
1. Code Quality คืออะไร ?
สิ่งที่ตรงข้ามกับ Code Quality คือ
Legacy code
ซึ่งมีความหมายมากมาย เช่น
- Code ที่เขียนจากคนอื่น ๆ
- Code ที่เขียนจากตัวเราเองเมื่อ 2 สัปดาห์ก่อน
- Code ที่ไม่มี test
สิ่งที่น่ากลัวมาก ๆ สำหรับ Code Quality คือ
มันมีความหมายมากมายเช่นกัน
ดังนั้นสิ่งที่ทีมต้องระวังอย่างมากคือ
เมื่อพูดถึง Code Quality แล้วหมายถึงอะไรกันแน่
ดังนั้นควรต้องตกลงกัน ต้องพูดคุยกัน
เพื่อให้เข้าใจตรงกัน เช่น
- Code ที่อ่านง่าย เข้าใจง่าย
- Code ที่มีการทดสอบที่ดี
- Code ที่มีชุดการทดสอบครอบคลุม
- Code ที่ไม่มี bug
- Code ที่ทำการ refactor มาแล้ว
- Code ที่มีเอกสารอธิบายชัดเจน
- Code ที่สามารถขยายเพิ่มได้ง่าย
- Code ที่ทำงานได้อย่างรวดเร็ว
พูดคุยและตกลงกันภายในทีมให้เรียบร้อยนะ
เพราะว่า นั่นคือเป้าหมายของทุกคนในทีม
ซึ่งมีคำพูดที่น่าสนใจคือ
Any code less decomposed than mine is a mess.
Any code more decomposed.
นั่นคือ
code ที่เอาทุกสิ่งทุกอย่างมารวมกันไว้ในที่เดียว หรือพวก
God class/method
ทำให้เกิด Spaghetti code ก็ไม่ใช่สิ่งที่ดี
หรือ code ที่แยกการทำงานต่าง ๆ ออกจากกัน มากจนเกินไป
เราจะพบได้จากระบบที่นำเอา Design pattern มาใช้งานตั้งแต่แรกเริ่ม
ซึ่งเราเรียกว่า over-engineering ก็ไม่ใช่สิ่งที่ดี
ดังนั้นแต่ละระบบล้วนแตกต่างกัน ต้องปรับเปลี่ยนให้เหมาะสมกันไป
2. ใช้อะไรวัดค่าความซับซ้อนของ code ?
และใช้ตัวชี้วัดอะไรบ้าง เช่น
ทีมลองตัดสินใจร่วมกันนะครับ
ซึ่งอย่างน้อยให้ใช้ LOC มาเป็นตัวชี้วัด
เช่น ในแต่ละ class/method ควรไม่เกินกี่บรรทัดดี ?
3. ทำไม code ของ project เก่า ๆ ถึงดูแลยากนักล่ะ ?
เนื่องจาก code แย่ ๆ มันถูกสร้างออกมาอย่างต่อเนื่องไงล่ะ
เริ่มจากแรงกดกันจากส่วนต่าง ๆ ทั้งจากภายนอกและภายใน
รวมทั้งสิ่งเล็ก ๆ ที่เรียกว่า
Deadline
ทำให้นักพัฒนาทุกคนสนใจแต่ ทำให้เสร็จ ทำให้เสร็จ ทำให้เสร็จ
โดยไม่ได้สนใจ และ ใส่ใจใน code เลยว่าดีหรือไม่
และ code เหล่านั้นมันกลับทำให้ project พัฒนาช้าไปกว่าเดิม !!
และจะอยู่ในวงจรนี้ไปเรื่อย ๆ
แสดงดังรูป
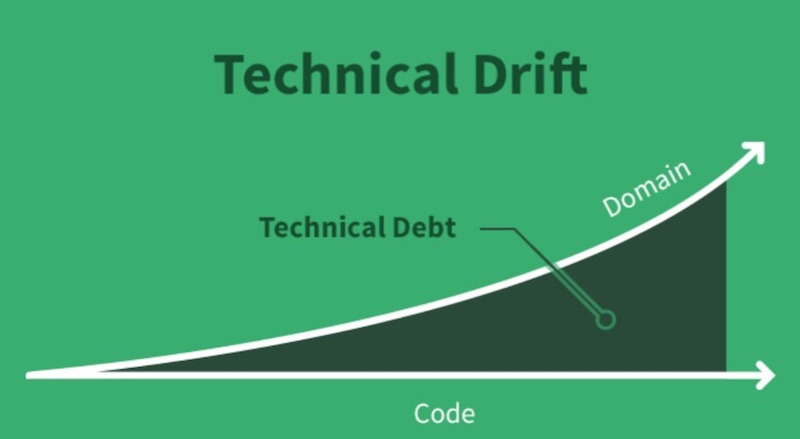
![code-quality]() นั่นคือเมื่อเวลาผ่านไป Technical Debt ก็ยิ่งมากขึ้น
นั่นคือเมื่อเวลาผ่านไป Technical Debt ก็ยิ่งมากขึ้น
รวมทั้ง Domain หรือ Business ก็เปลี่ยนไปเรื่อย ๆ
ทำให้ code มีจำนวนสูงขึ้น
Code ที่ไม่ใช้งานก็เยอะขึ้น
เป็นแบบนี้ไปเรื่อย ๆ ทำให้ code เหล่านี้ดูแลได้ยากขึ้นเรื่อย ๆ
ดังรูป
![code-quality-02]() จากปัญหาเหล่านี้เราจะทำอย่างไรดีล่ะ ?
จากปัญหาเหล่านี้เราจะทำอย่างไรดีล่ะ ?
เพื่อทำให้ code หรือระบบของเรามันดีขึ้น
ซึ่งมีให้เลือก 2 แบบคือ
- Big design คือ คิดใหม่ ทำใหม่ ออกแบบใหม่ เขียนใหม่หมดเลย !!
- Iterative design คือ ค่อย ๆ ปรับเปลี่ยน ค่อย ๆ แก้ไขไปเรื่อย ๆ ซึ่งให้นำแนวคิด The Boy Scout Rule มาใช้
4. ขนาดของ code ในแต่ละ Pull request สำหรับการ review ควรเป็นเท่าไรดี ?
นั่นคือในการ review code แต่ละครั้งนั้น
จำนวน LOC ควรเป็นเท่าไรดี ?
จากบทความเรื่อง
11 proven practices for more effective, efficient peer code review
อธิบายไว้ว่า
ยิ่ง Pull request มีขนาดใหญ่มาก
ยิ่งหา issue/bug ต่าง ๆ ได้น้อยลง
ดังนั้นคำแนะนำคือ
ในการ review code แต่ละครั้ง LOC ไม่ควรเกิน 400 บรรทัดนะ
ซึ่งเป็นการ review code โดยใช้คน ไม่ได้ใช้เครื่องมือ
นั่นหมายความว่า คนเรามีข้อจำกัดนะ
ยิ่ง code เยอะ ก็ไม่อยากจะ review กัน !!
5. เมื่อไรที่ code แย่ ๆ ไม่ใช่ปัญหา ?
เรื่องนี้มันขึ้นอยู่กับ business ล้วน ๆ
เช่น
- ทำแล้วทิ้ง
- ต้องการพิสูจน์อะไรบางอย่าง
- business model เปลี่ยนบ่อยมาก ๆ
- code ที่ไม่มีการเปลี่ยนแปลงเลย
ดังนั้นการจะเขียน code แย่ ๆ จึงไม่ใช่ปัญหาอะไรมากมาย
แต่ถ้าเป็น product ที่คุณต้องดูแลไปนาน ๆ แล้ว
code แย่ ๆ จะสร้างปัญหาให้คุณแน่นอน
6. อะไรบ้างที่เป็นตัวขัดขวาง Clean code ?
ซึ่งทำให้เกิด code ที่แย่ ๆ ขึ้นมามากมายขนาดนี้ !!
เริ่มด้วยการขาดความสนใจ ขาดความใส่ใจในสิ่งที่กำลังทำ
ต่อมาคือ ขาดความรู้และความสามารถ
บางครั้งเราไม่รู้ด้วยว่า สิ่งที่เราทำไปนั้นเป็นสิ่งที่ไม่ดี
บางครั้งเราไม่รู้ด้วยซ้ำว่า จะแก้ไขอย่างไร
และบ่อยครั้งที่ requirement เปลี่ยนบ่อยมาก ๆ
ดังนั้นเราก็ทำให้มันเสร็จ ๆ ไปเถอะ
เดี๋ยวก็เปลี่ยนแปลงอีก
ซึ่งมันกลายเป็นสาเหตุหรือข้ออ้างหลักสำหรับการสร้าง code แย่ ๆ เลยนะ !!
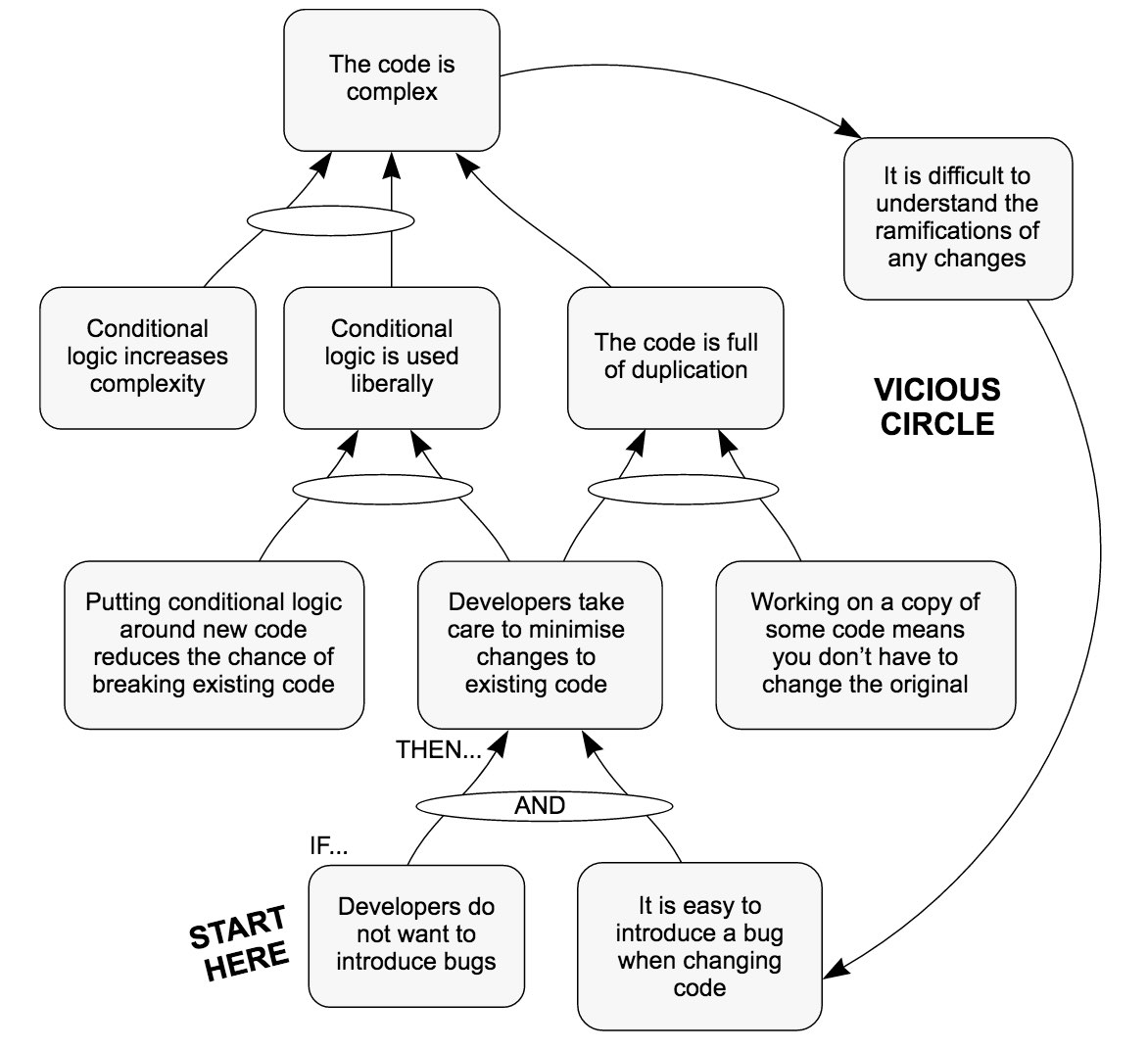
จากบทความเรื่อง
Why do teams fail to sustain code quality?
อธิบายสาเหตุของ code ที่ซับซ้อน
แน่นอนว่า มันยากต่อการดูแล และ ง่ายต่อการเกิด bug อย่างมาก
แสดงดังรูป
![code-quality-03]() แต่สาเหตุหลักของ Code แย่ ๆ คือ ความกลัว (Fear)
แต่สาเหตุหลักของ Code แย่ ๆ คือ ความกลัว (Fear)
กลัวที่จะไม่ทัน
กลัวที่จะโดนด่า
กลัวที่แก้ไขไปแล้ว จะทำให้ระบบทำงานไม่ได้ ทั้งที่รู้และไม่รู้
กลัวที่แก้ไขไปแล้ว จะทำให้ตัวเองมีภัย
กลัวที่จะ ...
ดังนั้นมาลดความกลัวเหล่านี้กันเถอะ เช่น
- Automated testing
- Operational metrics
- Code review
- Static analysis
- Pair programming
สุดท้ายแล้ว
ยังมีอะไรให้เรียนรู้อีกมากมาย
ยังมีอะไรให้ปรับปรุงอีกมากมาย
ดังนั้น
เรื่องของวินัย
เรื่องของความสามารถ
เรื่องของอารมณ์และความรู้สึกร่วม
มันต้องมาและไปพร้อม ๆ กัน
วันนี้เราเรียนรู้อะไรบ้างแล้วหรือยัง ?
วันนี้เราปรับปรุงความสามารถให้ดีขึ้นแล้วหรือยัง ?
วันนี้เราเขียน code แล้วหรือยัง ?

 ในการพัฒนา software ได้นำเอาแนวคิด Continuous Integration(CI) เข้ามาใช้งาน
ซึ่งผมคิดว่าเป็นสิ่งที่ขาดไม่ได้เลย
เพื่อช่วยทำให้ทีมทำการ integrate บ่อย ๆ
เพื่อช่วยทำให้ software ที่สร้างค่อย ๆ เติบโตอย่างยั่งยืน
เพื่อช่วยทำให้ทีมได้รับ feedback กลับมาอย่างรวดเร็วทั้งดีและร้าย
เพื่อจะได้แก้ไขและปรับปรุงได้อย่างทันท่วงที
ในการพัฒนา software ได้นำเอาแนวคิด Continuous Integration(CI) เข้ามาใช้งาน
ซึ่งผมคิดว่าเป็นสิ่งที่ขาดไม่ได้เลย
เพื่อช่วยทำให้ทีมทำการ integrate บ่อย ๆ
เพื่อช่วยทำให้ software ที่สร้างค่อย ๆ เติบโตอย่างยั่งยืน
เพื่อช่วยทำให้ทีมได้รับ feedback กลับมาอย่างรวดเร็วทั้งดีและร้าย
เพื่อจะได้แก้ไขและปรับปรุงได้อย่างทันท่วงที

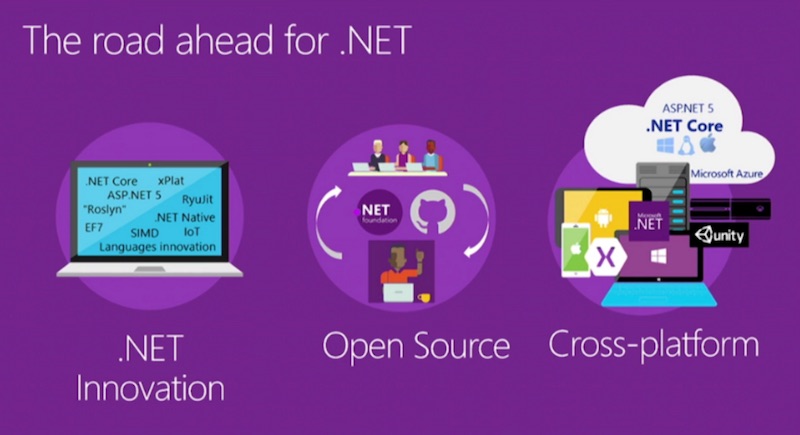 บริษัท Microsoft ได้เปิดตัว
บริษัท Microsoft ได้เปิดตัว 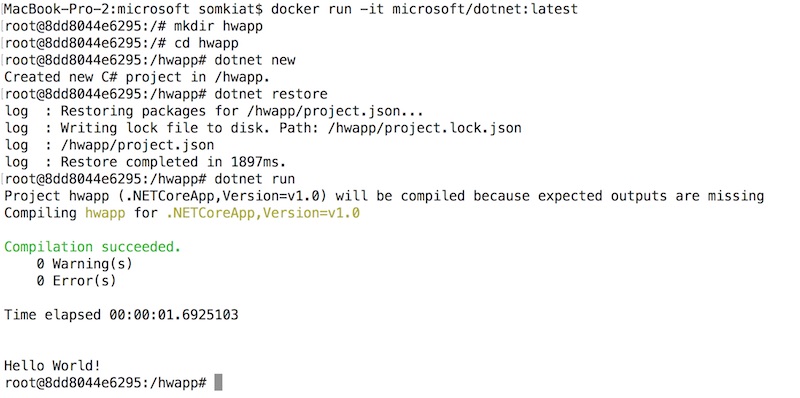 จะเห็นว่าใช้งานไม่ยากเลยนะ
จากนั้นมาดูขนาดของ image ของ Microsoft .Net หน่อยว่ามีขนาดเท่าไร
พบว่ามีขนาด 548.6 MB
ซึ่งมีขนาดใหญ่พอสมควรแต่รับได้นะ !!
จากนั้นลองมาสร้างระบบงานจริง ๆ กันดีกว่า
แนะนำให้ไปอ่านเอกสารจาก
จะเห็นว่าใช้งานไม่ยากเลยนะ
จากนั้นมาดูขนาดของ image ของ Microsoft .Net หน่อยว่ามีขนาดเท่าไร
พบว่ามีขนาด 548.6 MB
ซึ่งมีขนาดใหญ่พอสมควรแต่รับได้นะ !!
จากนั้นลองมาสร้างระบบงานจริง ๆ กันดีกว่า
แนะนำให้ไปอ่านเอกสารจาก 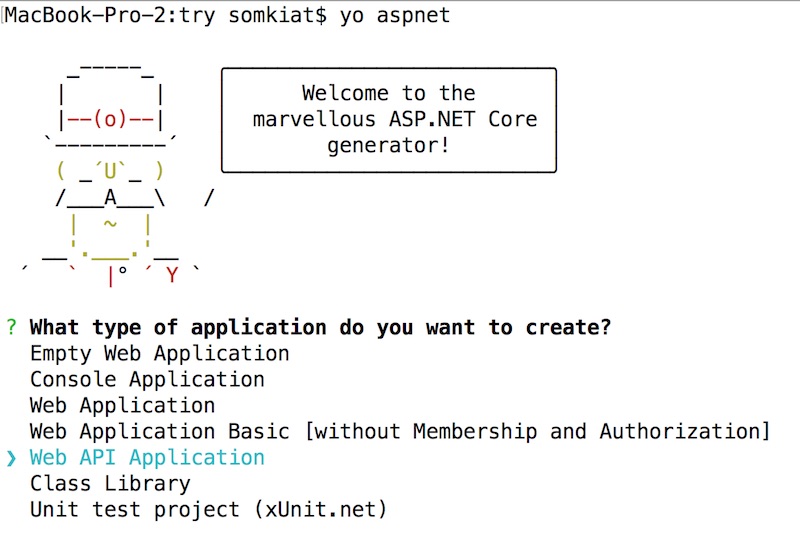 จากนั้นทำการตั้งชื่อ project ซะ
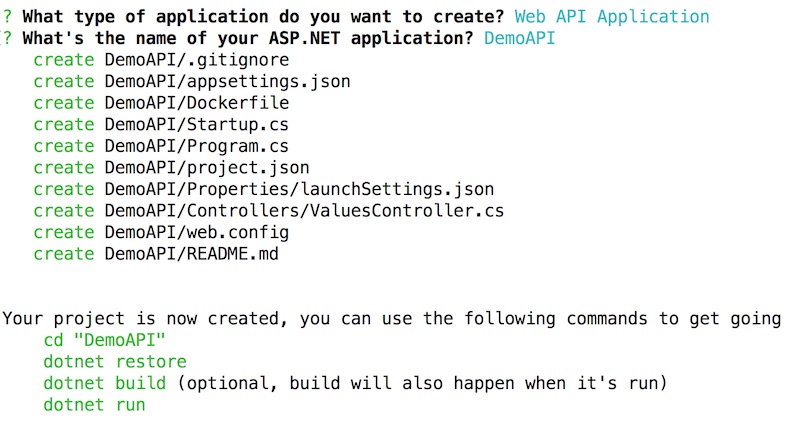
แล้ว Yeoman จะทำการสร้าง project เริ่มต้นให้ดังรูป
แถมอธิบายขั้นตอนการ run ให้พร้อม
จากนั้นทำการตั้งชื่อ project ซะ
แล้ว Yeoman จะทำการสร้าง project เริ่มต้นให้ดังรูป
แถมอธิบายขั้นตอนการ run ให้พร้อม
 จากนั้นทำการเปิด code ขึ้นมาดูหน่อย
ซึ่งผมใช้ Visual Studio Code แสดงดังนี้
จากนั้นทำการเปิด code ขึ้นมาดูหน่อย
ซึ่งผมใช้ Visual Studio Code แสดงดังนี้
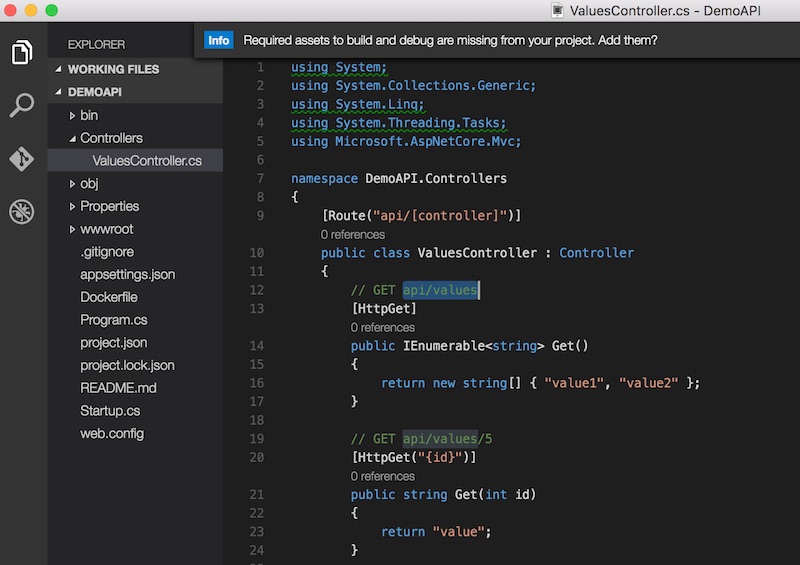 สำหรับคนที่ติดตั้ง .Net Core ไว้ที่เครื่อง
สามารถทำการทดสอบ run ได้ดังนี้
[code]
$dotnet restore
$dotnet build
$dotnet run
[/code]
จากนั้นก็ทดสอบใช้งานผ่าน browser ด้วย url
สำหรับคนที่ติดตั้ง .Net Core ไว้ที่เครื่อง
สามารถทำการทดสอบ run ได้ดังนี้
[code]
$dotnet restore
$dotnet build
$dotnet run
[/code]
จากนั้นก็ทดสอบใช้งานผ่าน browser ด้วย url 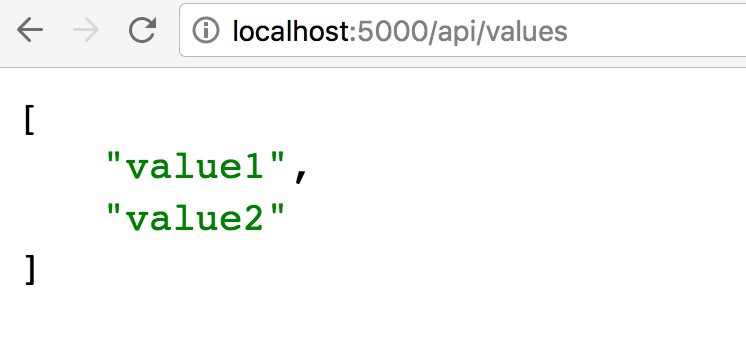 เท่านี้ก็ใช้งานได้แล้ว ง่ายไหมล่ะ !!
ยังไม่พอนะ พอดีไปเห็นใน project พบว่ามีไฟล์ Dockerfile มาให้ด้วย
ดังนั้นสามารถ run บน Docker ได้อีกด้วย
มาลองใช้งานกันดีกว่า
[code]
$docker build -t api .
$docker run -it -p 5000:5000 --rm --name api api
[/code]
เพียงเท่านี้ก็ใช้งานผ่าน Docker ได้เลย
เป็นวิธีการที่ง่าย ๆ มาก
ซึ่ง Developer ทุกคนสามารถใช้งานได้เลย
รออะไรอยู่ ไปลองใช้งานกันเลยครับ
เท่านี้ก็ใช้งานได้แล้ว ง่ายไหมล่ะ !!
ยังไม่พอนะ พอดีไปเห็นใน project พบว่ามีไฟล์ Dockerfile มาให้ด้วย
ดังนั้นสามารถ run บน Docker ได้อีกด้วย
มาลองใช้งานกันดีกว่า
[code]
$docker build -t api .
$docker run -it -p 5000:5000 --rm --name api api
[/code]
เพียงเท่านี้ก็ใช้งานผ่าน Docker ได้เลย
เป็นวิธีการที่ง่าย ๆ มาก
ซึ่ง Developer ทุกคนสามารถใช้งานได้เลย
รออะไรอยู่ ไปลองใช้งานกันเลยครับ

 จากคำถามใน Quora.com เรื่อง
จากคำถามใน Quora.com เรื่อง
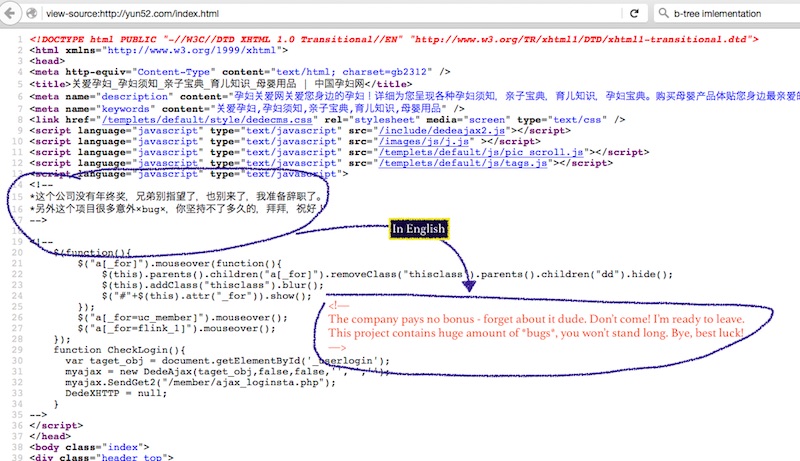 ถ้าเจอ code แบบนี้ไม่น่าจะชอบกันนะ !!
[code]
IF TIMEDIFF >=5
SAY "THE SYSTEM IS FUCKED, PLEASE BEAR WITH US"
SLEEP(10)
ENDIF
[/code]
ถ้าเจอแบบนี้จะกล้าแก้ไขไหม ?
[code]
//When I wrote this, only God and I understood what I was doing
//Now, God only knows
/* You are not expected to understand this */
//
// Dear maintainer:
//
// Once you are done trying to 'optimize' this routine,
// and have realized what a terrible mistake that was,
// please increment the following counter as a warning
// to the next guy:
//
// total_hours_wasted_here = 42
//
[/code]
ถ้าเจอ comment แบบนี้ ก็เอาที่สบายใจกันนะ
[code]
if (counts < 0xFF567812 ) // Programmer1 - WTF is this magic number bullshit
// Programmer2 - I have no fucking clue. I've been trying to figure it out for years.
// Programmer1 - We should figure this out and comment it
// Programmer3 - Did we ever figure this out?
// Programmer2 - No
[/code]
หรือเจอ code แบบนี้จะทำการ comment หรือปรับปรุงกันดีนะ ?
ถ้าเจอ code แบบนี้ไม่น่าจะชอบกันนะ !!
[code]
IF TIMEDIFF >=5
SAY "THE SYSTEM IS FUCKED, PLEASE BEAR WITH US"
SLEEP(10)
ENDIF
[/code]
ถ้าเจอแบบนี้จะกล้าแก้ไขไหม ?
[code]
//When I wrote this, only God and I understood what I was doing
//Now, God only knows
/* You are not expected to understand this */
//
// Dear maintainer:
//
// Once you are done trying to 'optimize' this routine,
// and have realized what a terrible mistake that was,
// please increment the following counter as a warning
// to the next guy:
//
// total_hours_wasted_here = 42
//
[/code]
ถ้าเจอ comment แบบนี้ ก็เอาที่สบายใจกันนะ
[code]
if (counts < 0xFF567812 ) // Programmer1 - WTF is this magic number bullshit
// Programmer2 - I have no fucking clue. I've been trying to figure it out for years.
// Programmer1 - We should figure this out and comment it
// Programmer3 - Did we ever figure this out?
// Programmer2 - No
[/code]
หรือเจอ code แบบนี้จะทำการ comment หรือปรับปรุงกันดีนะ ?
 ขยันกันไปถึงไหนนะ สำหรับการเขียน comment
[gist id="9f28126836bf265523d08bed1183acad" file="01.txt"]
ขยันกันไปถึงไหนนะ สำหรับการเขียน comment
[gist id="9f28126836bf265523d08bed1183acad" file="01.txt"]
 ต่อมาคือ พยายามสูงมาก ๆ
ต่อมาคือ พยายามสูงมาก ๆ
 Geek เท่านั้นถึงจะเข้าใจ
Geek เท่านั้นถึงจะเข้าใจ
 ประกาศจ้างงานกันแบบนี้เลย !!
ประกาศจ้างงานกันแบบนี้เลย !!
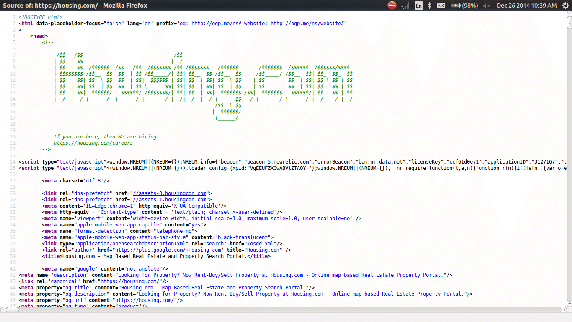 อันนี้น่ากลัวมาก ๆ
อันนี้น่ากลัวมาก ๆ
 ปิดท้ายด้วย comment นี้ล่ะกัน สาธุ !!
ปิดท้ายด้วย comment นี้ล่ะกัน สาธุ !!

 ในช่วงวันหยุดมาศึกษาสิ่งใหม่ ๆ กันหน่อย
หรือว่าใหม่ของผมแต่อาจจะเก่าของคนอื่นก็ได้ !!
สำหรับนักพัฒนา iOS app นั้น
ต้องสร้างระบบ Backend/API หรือ Server-side มาใช้งานเสมอ
ซึ่งมักจะพัฒนาด้วยภาษาอื่น ๆ เช่น Java, PHP, Node.js, Rail และ Go เป็นต้น
ทำให้ต้องเรียนรู้มากขึ้น
ทำให้ต้องมีทีมมากขึ้น
ในช่วงวันหยุดมาศึกษาสิ่งใหม่ ๆ กันหน่อย
หรือว่าใหม่ของผมแต่อาจจะเก่าของคนอื่นก็ได้ !!
สำหรับนักพัฒนา iOS app นั้น
ต้องสร้างระบบ Backend/API หรือ Server-side มาใช้งานเสมอ
ซึ่งมักจะพัฒนาด้วยภาษาอื่น ๆ เช่น Java, PHP, Node.js, Rail และ Go เป็นต้น
ทำให้ต้องเรียนรู้มากขึ้น
ทำให้ต้องมีทีมมากขึ้น
 ประกอบไปด้วย
ประกอบไปด้วย
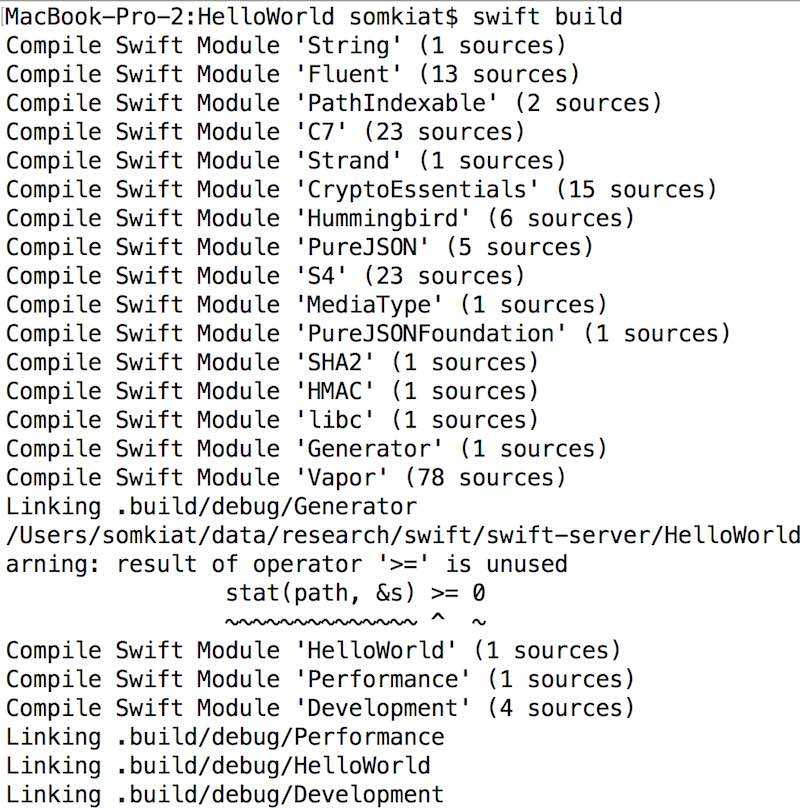 [code]
$.build/debug/HelloWorld
[/code]
จากนั้นเข้าใช้งานผ่าน browser ที่ url=
[code]
$.build/debug/HelloWorld
[/code]
จากนั้นเข้าใช้งานผ่าน browser ที่ url=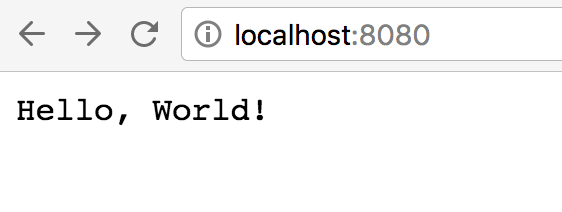 และทดสอบ response ในรูปแบบ JSON ดังนี้
และทดสอบ response ในรูปแบบ JSON ดังนี้ 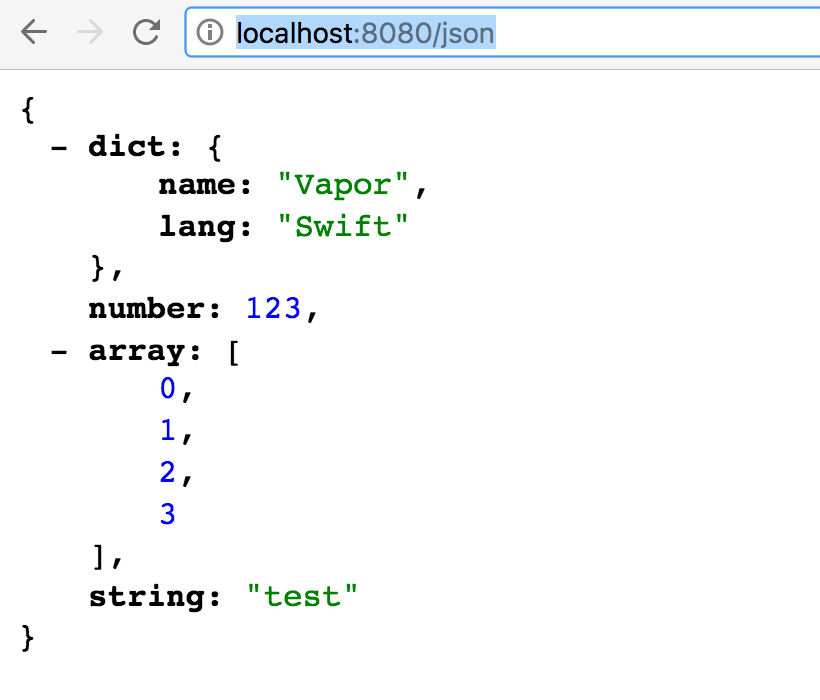

 ทำไมในการพัฒนา software
ถึงมี bad code หรือ code ที่มันแย่ ๆ ขึ้นมาเพียบเลย ?
หรือว่าจำนวนนักพัฒนาที่สามารถเขียน code ให้มีคุณภาพมีน้อยกันนะ ?
หรือว่ามันมีเหตุผลอื่น ๆ อีกนะ ?
เราลองมาค้นหาคำตอบกันหน่อยสิ
ทำไมในการพัฒนา software
ถึงมี bad code หรือ code ที่มันแย่ ๆ ขึ้นมาเพียบเลย ?
หรือว่าจำนวนนักพัฒนาที่สามารถเขียน code ให้มีคุณภาพมีน้อยกันนะ ?
หรือว่ามันมีเหตุผลอื่น ๆ อีกนะ ?
เราลองมาค้นหาคำตอบกันหน่อยสิ
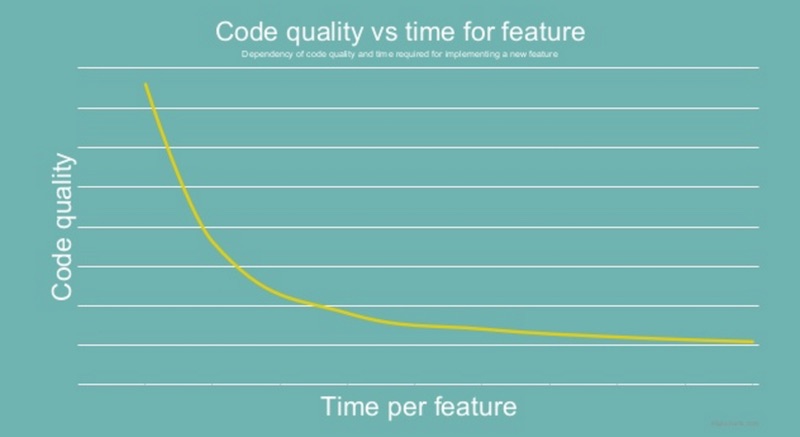

 ในการพัฒนา Mobile app ส่วนใหญ่นั้น
จำเป็นต้องทำงานร่วมกับ Server-side API ผ่านระบบ network
ไม่ว่าจะเป็น RESTful API และ Web Service
ปัญหาที่มักเกิดขึ้นเสมอก็คือ
ในการพัฒนา Mobile app ส่วนใหญ่นั้น
จำเป็นต้องทำงานร่วมกับ Server-side API ผ่านระบบ network
ไม่ว่าจะเป็น RESTful API และ Web Service
ปัญหาที่มักเกิดขึ้นเสมอก็คือ

 วันนี้นั่งดูและเขียน code ด้วยภาษา Swift สำหรับพัฒนา iOS app
พบว่าในหลาย ๆ ส่วนการทำงานใช้ Delegate pattern
เพื่อเชื่อมต่อการทำงานในแต่ละส่วน เช่น
วันนี้นั่งดูและเขียน code ด้วยภาษา Swift สำหรับพัฒนา iOS app
พบว่าในหลาย ๆ ส่วนการทำงานใช้ Delegate pattern
เพื่อเชื่อมต่อการทำงานในแต่ละส่วน เช่น

 ในปัจจุบันไปงานไหน ๆ ก็มีแต่คนพูดถึง
ในปัจจุบันไปงานไหน ๆ ก็มีแต่คนพูดถึง 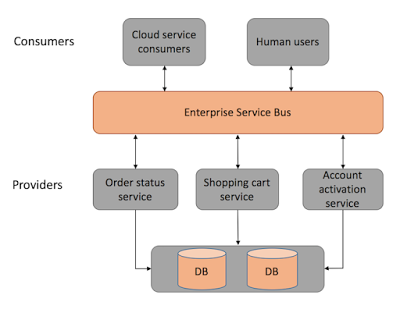
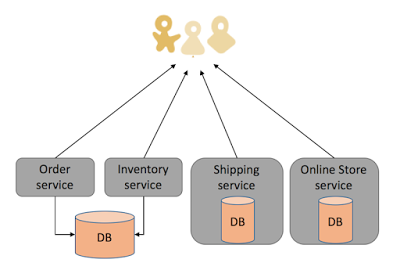
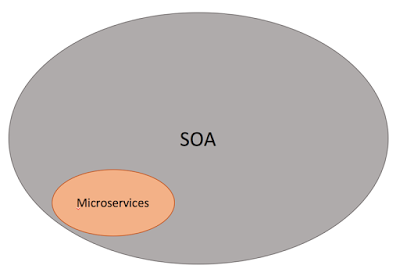
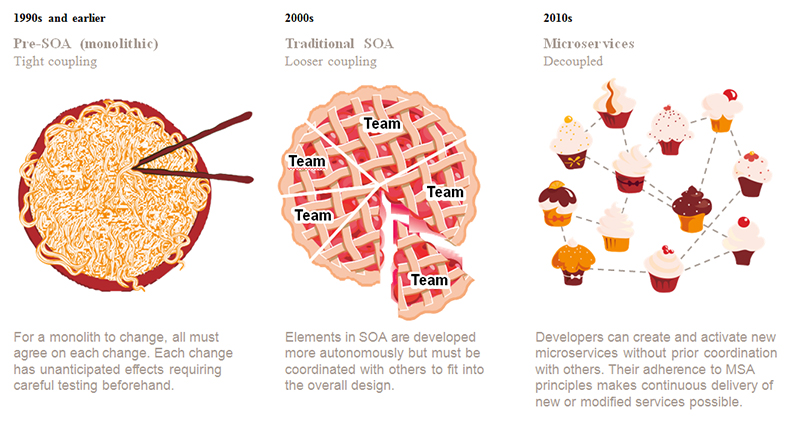 โดยแต่ละ service ของ SOA และ Microservice
สามารถแบ่งไปให้แต่ละทีม หรือ หลาย ๆ ทีมพัฒนาได้
สามารถใช้เทคโนโลยีในการพัฒนาที่แตกต่างกันได้
โดยแต่ละ service ของ SOA และ Microservice
สามารถแบ่งไปให้แต่ละทีม หรือ หลาย ๆ ทีมพัฒนาได้
สามารถใช้เทคโนโลยีในการพัฒนาที่แตกต่างกันได้




 เช้านี้อ่านเจอบทความเรื่อง
เช้านี้อ่านเจอบทความเรื่อง 

 แก้ไขสำหรับการติดตั้ง
แก้ไขสำหรับการติดตั้ง 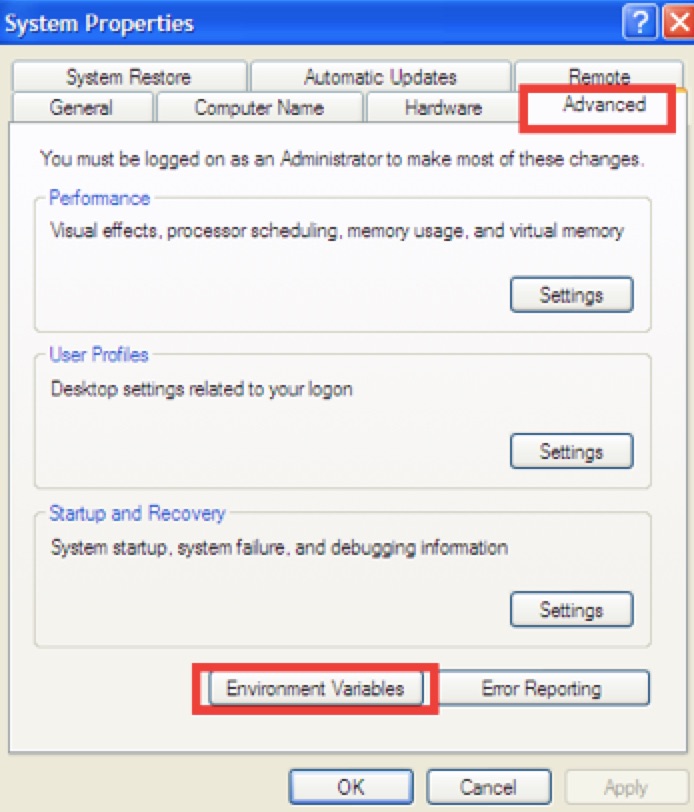 ให้ทำการสร้าง แก้ Environment Variables ในส่วนของ System Variable หรือ User Variable ก็ได้
โดยใส่ค่าดังนี้
1. ทำการกำหนด PYTHON_HOME สำหรับกำหนด path ที่ติดตั้ง Python
Variable=PYTHON_HOME
Value=c:\Python27
2. ทำการกำหนด PATH
Variable=PATH
Value=.;%PYTHON_HOME%;%PYTHON_HOME%\scripts;%PATH%
แสดงดังรูป
ให้ทำการสร้าง แก้ Environment Variables ในส่วนของ System Variable หรือ User Variable ก็ได้
โดยใส่ค่าดังนี้
1. ทำการกำหนด PYTHON_HOME สำหรับกำหนด path ที่ติดตั้ง Python
Variable=PYTHON_HOME
Value=c:\Python27
2. ทำการกำหนด PATH
Variable=PATH
Value=.;%PYTHON_HOME%;%PYTHON_HOME%\scripts;%PATH%
แสดงดังรูป
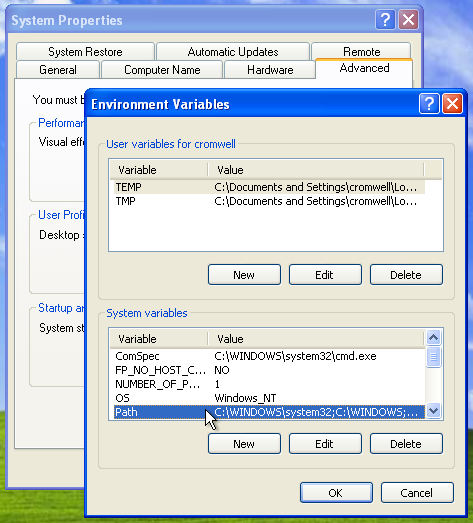 จากนั้นทำการกด ok ok ok และปิด command line
แล้วทำการเปิด command line ขึ้นมาใหม่
พิมพ์คำสั่ง python จะไม่เกิด error อีกแล้ว
จากนั้นทำการกด ok ok ok และปิด command line
แล้วทำการเปิด command line ขึ้นมาใหม่
พิมพ์คำสั่ง python จะไม่เกิด error อีกแล้ว


 เมื่อวานนั่งดู Code การพัฒนา iOS ด้วยภาษา Swift
โจทย์เดียวกันจาก developer 4 คน
แต่โครงสร้างของ code ที่ออกมานั้นเหมือนกัน
นั่นคือเป็น MVC(Model View Controller) ในรูปแบบของ Apple
ซึ่งส่วนใหญ่จะนำไปสู่ MVC ที่ย่อมาจาก Massive ViewController มากกว่านะ !!
และนั่นคือความหายนะที่กำลังมาเยือนนักพัฒนาโดยทั้งรู้และไม่รู้ตัว
เมื่อวานนั่งดู Code การพัฒนา iOS ด้วยภาษา Swift
โจทย์เดียวกันจาก developer 4 คน
แต่โครงสร้างของ code ที่ออกมานั้นเหมือนกัน
นั่นคือเป็น MVC(Model View Controller) ในรูปแบบของ Apple
ซึ่งส่วนใหญ่จะนำไปสู่ MVC ที่ย่อมาจาก Massive ViewController มากกว่านะ !!
และนั่นคือความหายนะที่กำลังมาเยือนนักพัฒนาโดยทั้งรู้และไม่รู้ตัว
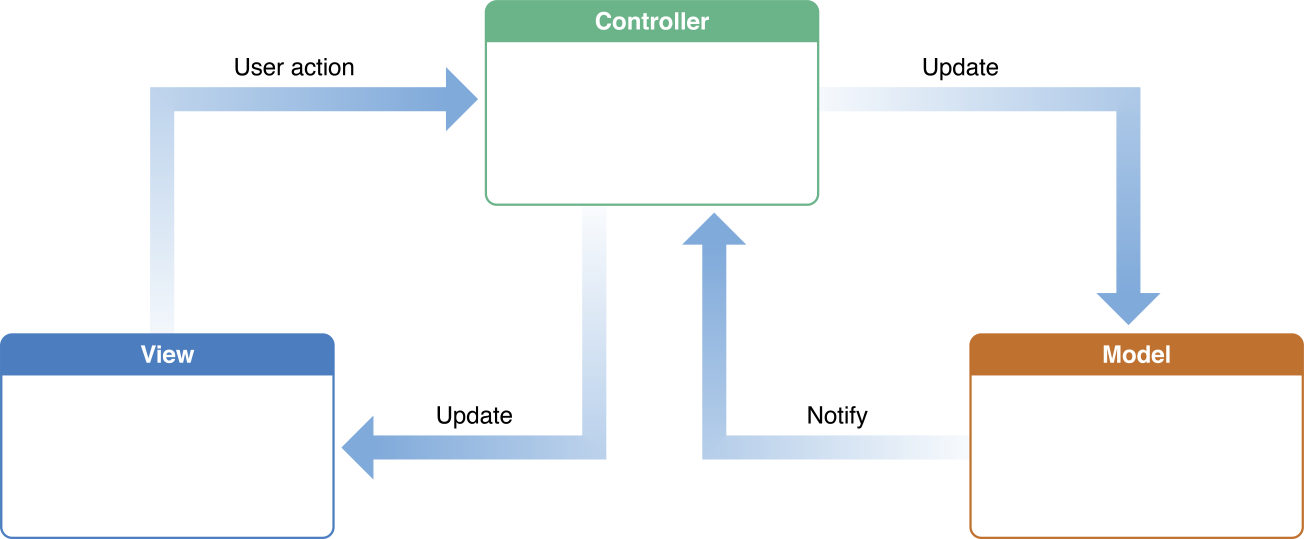
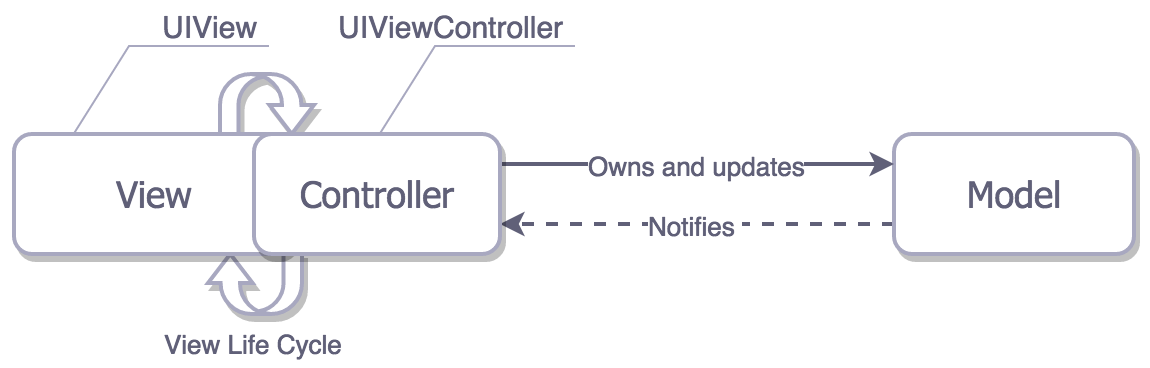 ซึ่งเป็นโครงสร้างที่เอื้อต่อการสร้าง Massive ViewController อย่างมาก
เนื่องจากทำการรวม View Life Cycle เข้ากับ Controller
ทำให้พวก business logic ต่าง ๆ รวมอยู่ในนั้นด้วย
ทำได้เพียงแยกส่วนของ data หรือ Model ออกมาเท่านั้น
ทำให้ใน ViewController นั้นจะใช้งานพวก
Delegate และ Datasource ของทุก ๆ อย่างเสมอ เช่น TableView และ SwipeView เป็นต้น
ผลที่ตามมาคือ
View คุยกับ Model โดยตรง หรือ ทำการส่ง Model ไปให้ View ซะงั้น !!
นั่นคือ ข้อขัดแย้งอย่างรุนแรงต่อ MVC
และเราพบเห็นได้บ่อยมาก ๆ ใน ViewController ของ iOS app
และนักพัฒนาทุกคนก็มองว่า มันเป็นเรื่องปกติ ไม่ได้ผิดอะไร !!
เมื่อเวลาผ่านไปนานขึ้น ขนาดของ ViewController ต่าง ๆ ก็ใหญ่โตขึ้นเรื่อย ๆ
นี่แหละคือที่ไปที่มาของ Massive ViewController
ยังไม่พอนะ เมื่อต้องเขียน Unit testing ด้วยแล้ว !!
ปัญหามันหนักมาก ๆ
เนื่องจาก ViewController มันเยอะไปหมด
code ผูกติดกันอย่างแน่นหนา
ทั้ง View ทั้ง Controller ทั้ง Business logic
หวังว่าระบบที่พัฒนาหรือดูแลกันอยู่ ไม่น่าจะเป็นเช่นนี้นะครับ
ซึ่งเป็นโครงสร้างที่เอื้อต่อการสร้าง Massive ViewController อย่างมาก
เนื่องจากทำการรวม View Life Cycle เข้ากับ Controller
ทำให้พวก business logic ต่าง ๆ รวมอยู่ในนั้นด้วย
ทำได้เพียงแยกส่วนของ data หรือ Model ออกมาเท่านั้น
ทำให้ใน ViewController นั้นจะใช้งานพวก
Delegate และ Datasource ของทุก ๆ อย่างเสมอ เช่น TableView และ SwipeView เป็นต้น
ผลที่ตามมาคือ
View คุยกับ Model โดยตรง หรือ ทำการส่ง Model ไปให้ View ซะงั้น !!
นั่นคือ ข้อขัดแย้งอย่างรุนแรงต่อ MVC
และเราพบเห็นได้บ่อยมาก ๆ ใน ViewController ของ iOS app
และนักพัฒนาทุกคนก็มองว่า มันเป็นเรื่องปกติ ไม่ได้ผิดอะไร !!
เมื่อเวลาผ่านไปนานขึ้น ขนาดของ ViewController ต่าง ๆ ก็ใหญ่โตขึ้นเรื่อย ๆ
นี่แหละคือที่ไปที่มาของ Massive ViewController
ยังไม่พอนะ เมื่อต้องเขียน Unit testing ด้วยแล้ว !!
ปัญหามันหนักมาก ๆ
เนื่องจาก ViewController มันเยอะไปหมด
code ผูกติดกันอย่างแน่นหนา
ทั้ง View ทั้ง Controller ทั้ง Business logic
หวังว่าระบบที่พัฒนาหรือดูแลกันอยู่ ไม่น่าจะเป็นเช่นนี้นะครับ

 มีคำถามที่น่าสนใจคือ ATDD, BDD และ SbE มันคืออะไร ?
เหมือน หรือ แตกต่างกันอย่างไรบ้าง ?
มีเป้าหมายเพื่ออะไรบ้าง ?
จากนั้นจึงลองไปค้นหาคำตอบ
ก็พบว่าเรื่องนี้เขาคุยกันมาตั้งแต่ปี 2010 แล้ว
โดยทำการสรุปไว้ในบทความเรื่อง
มีคำถามที่น่าสนใจคือ ATDD, BDD และ SbE มันคืออะไร ?
เหมือน หรือ แตกต่างกันอย่างไรบ้าง ?
มีเป้าหมายเพื่ออะไรบ้าง ?
จากนั้นจึงลองไปค้นหาคำตอบ
ก็พบว่าเรื่องนี้เขาคุยกันมาตั้งแต่ปี 2010 แล้ว
โดยทำการสรุปไว้ในบทความเรื่อง 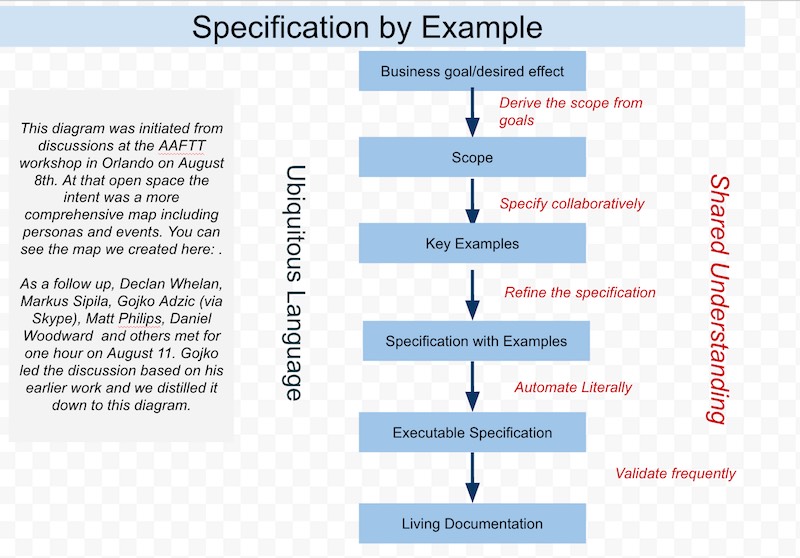

 วันนี้ช่วงพักกลางวันจากงาน
วันนี้ช่วงพักกลางวันจากงาน 
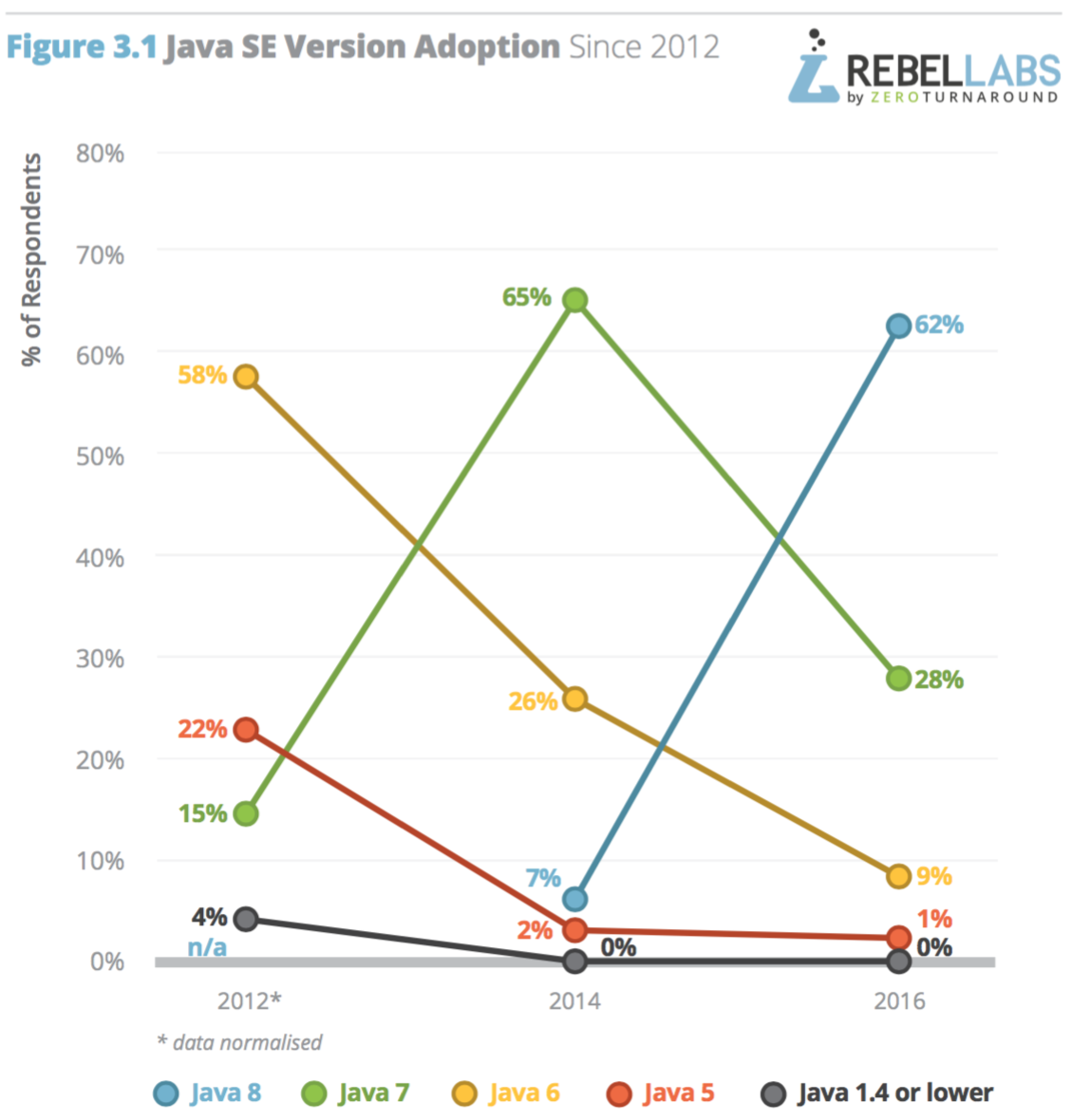
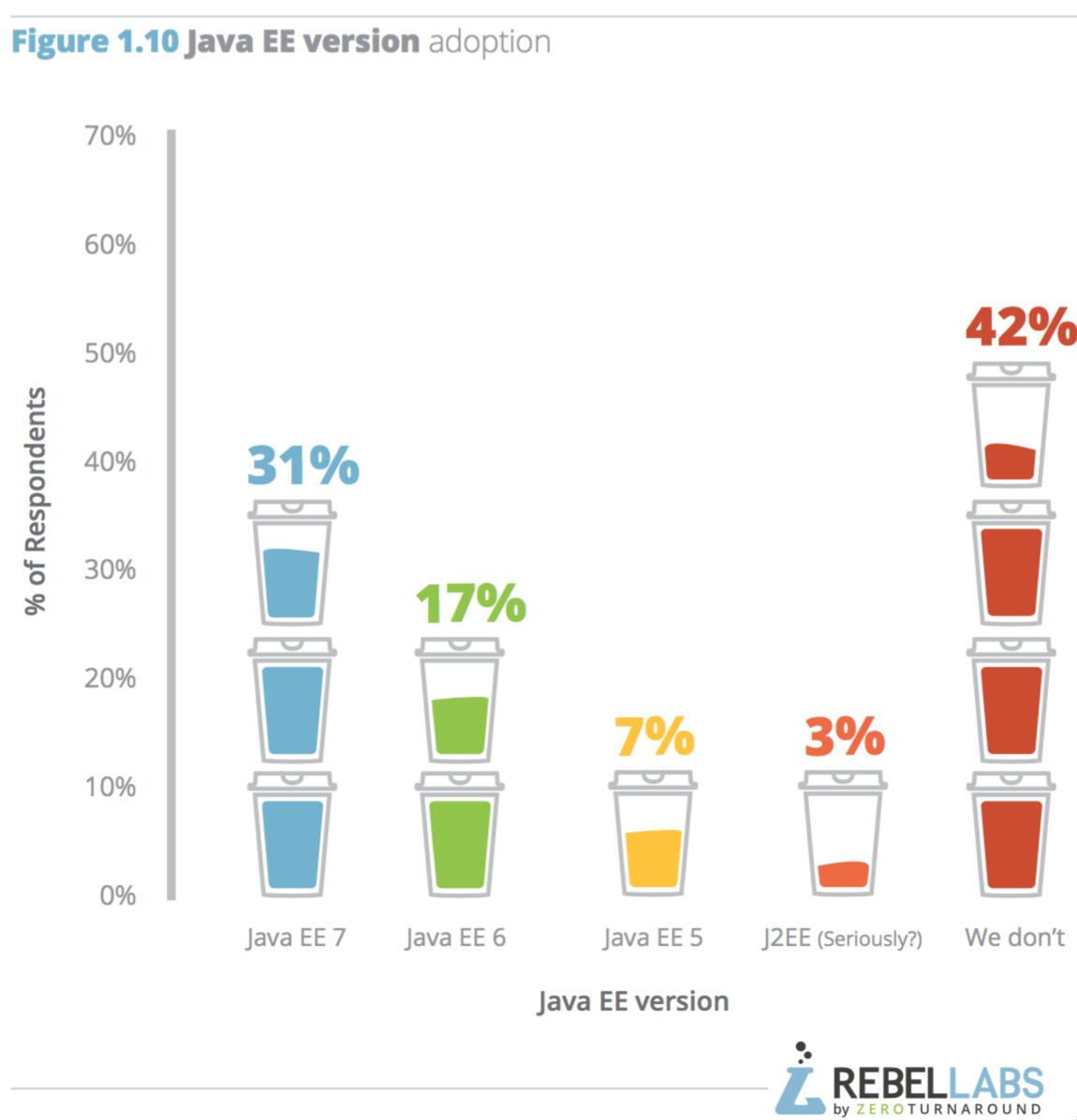
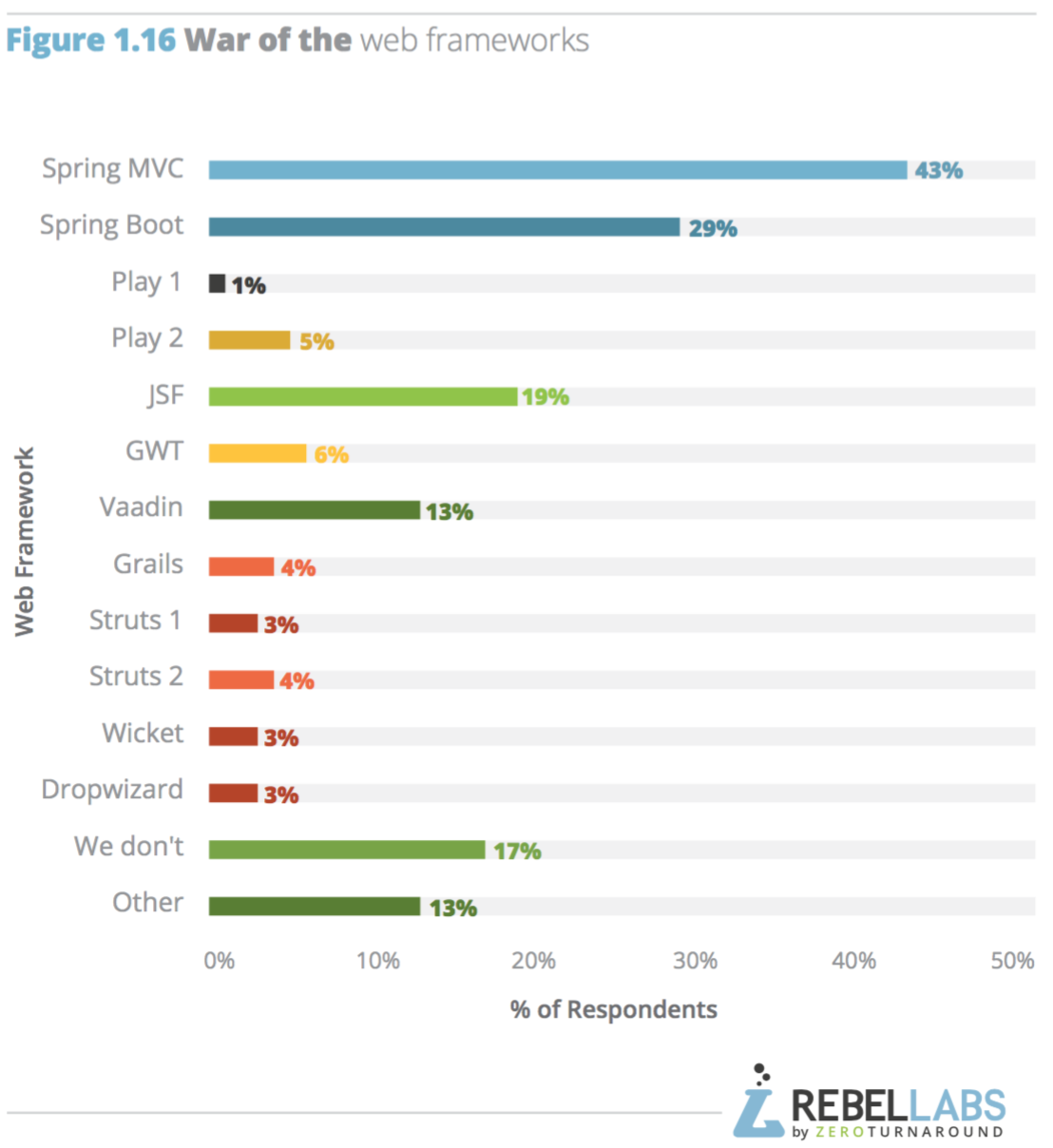
 ในปี 2016 นี้ทาง RebelLabs ทำการสรุปผลสำรวจเรื่องการใช้งาน Java และเทคโนโลยีที่เกี่ยวข้อง
ซึ่งแบ่งออกเป็น 3 ส่วน ดังนี้
ในปี 2016 นี้ทาง RebelLabs ทำการสรุปผลสำรวจเรื่องการใช้งาน Java และเทคโนโลยีที่เกี่ยวข้อง
ซึ่งแบ่งออกเป็น 3 ส่วน ดังนี้
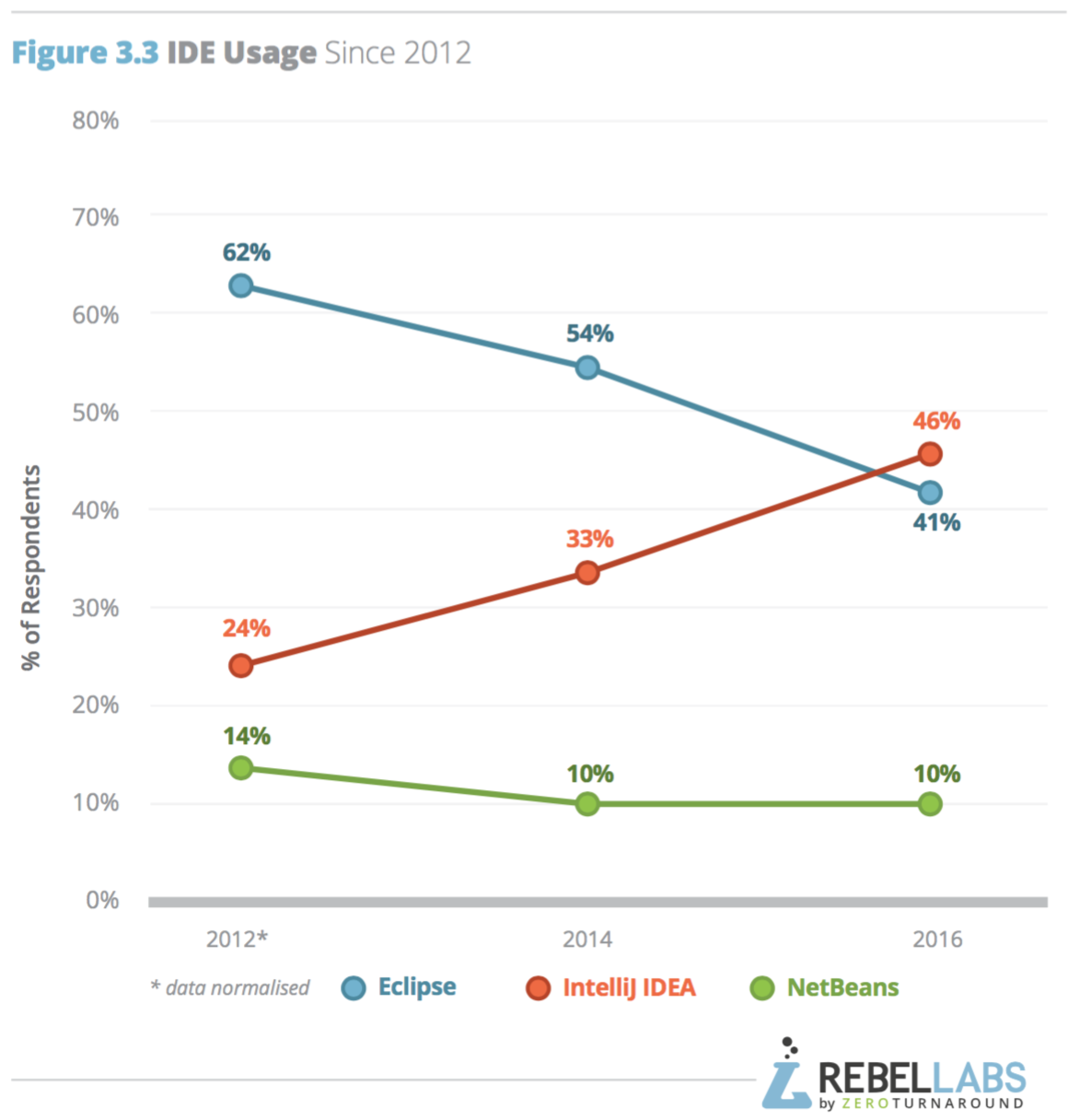
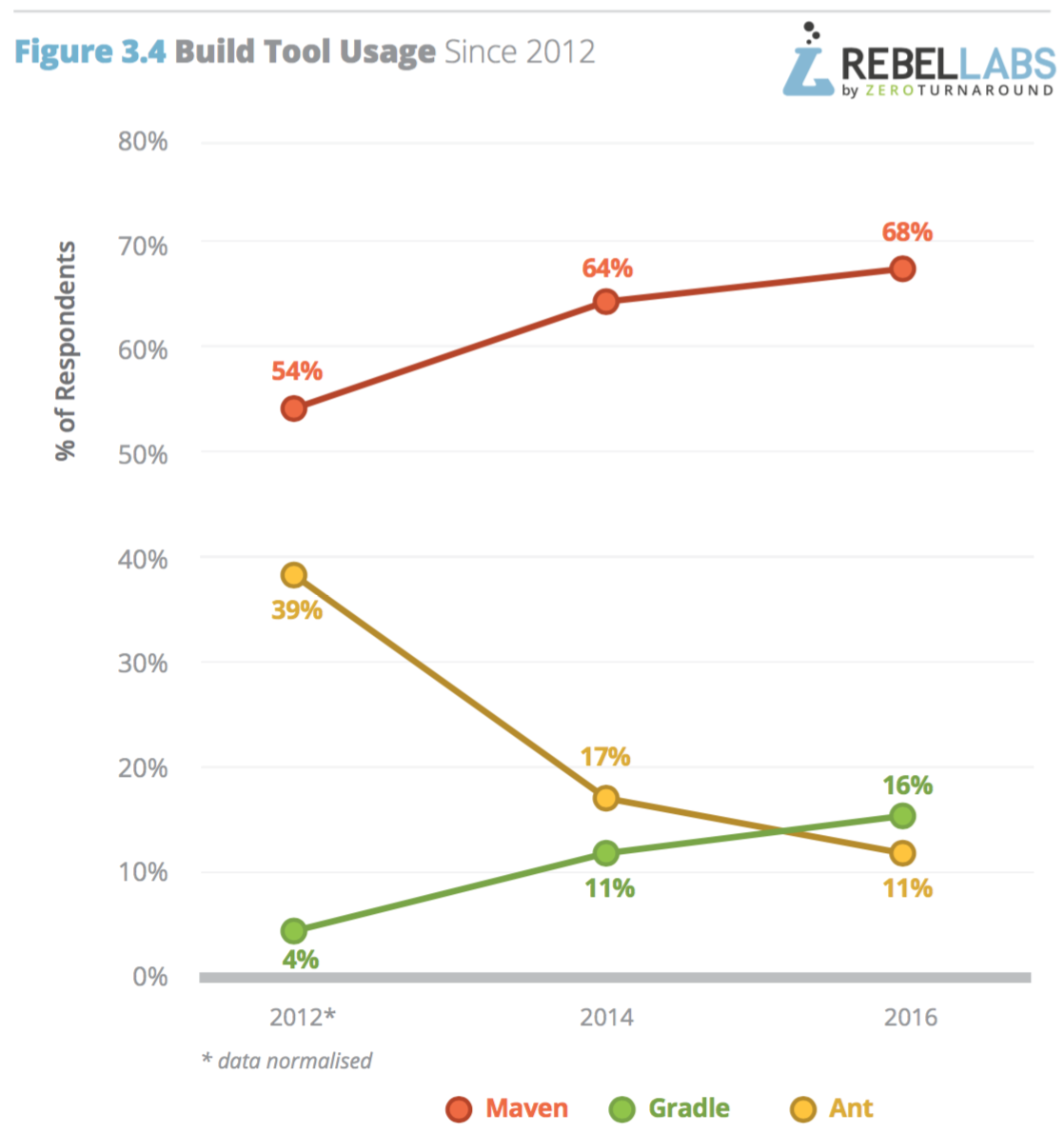
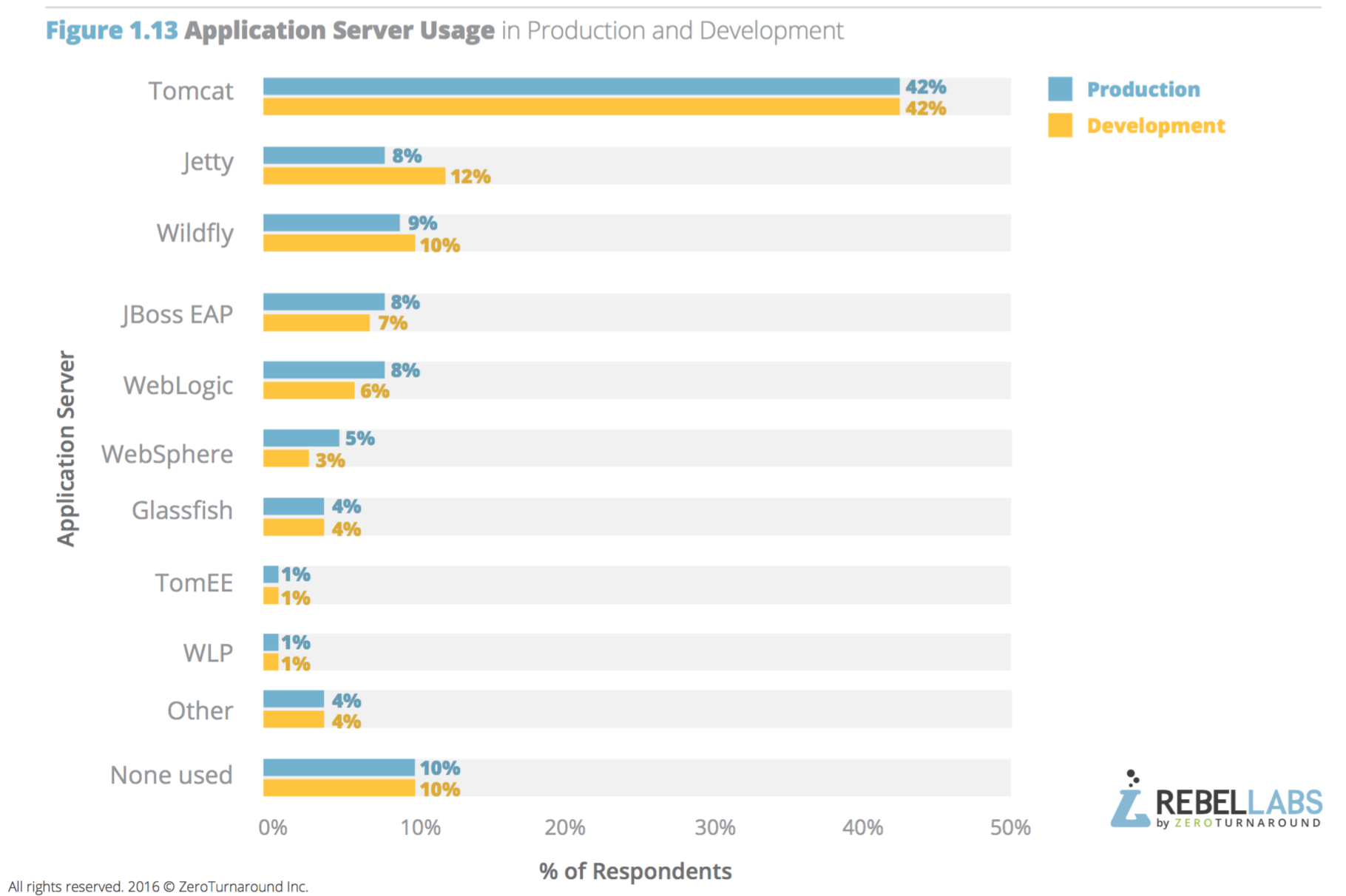
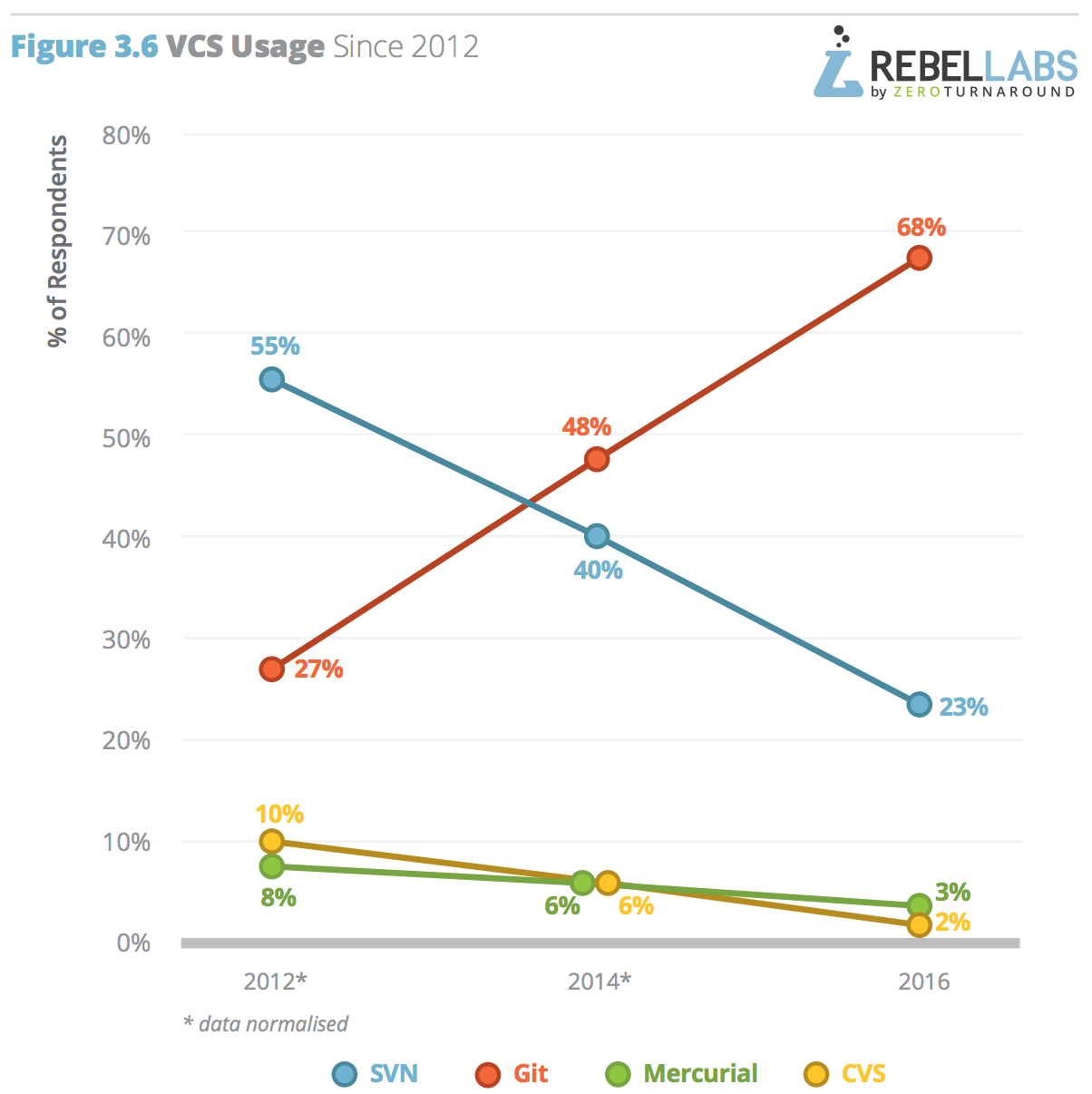
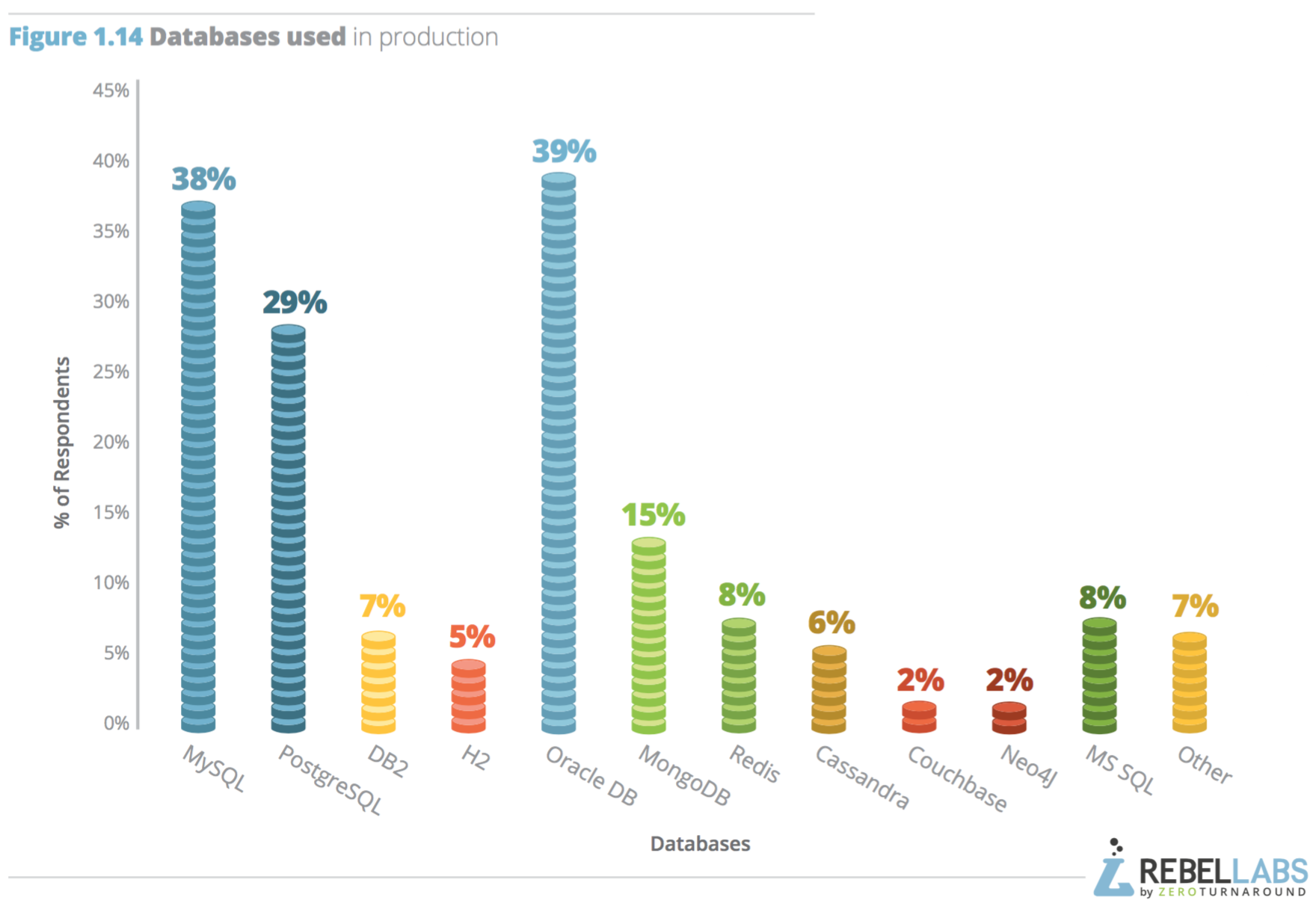
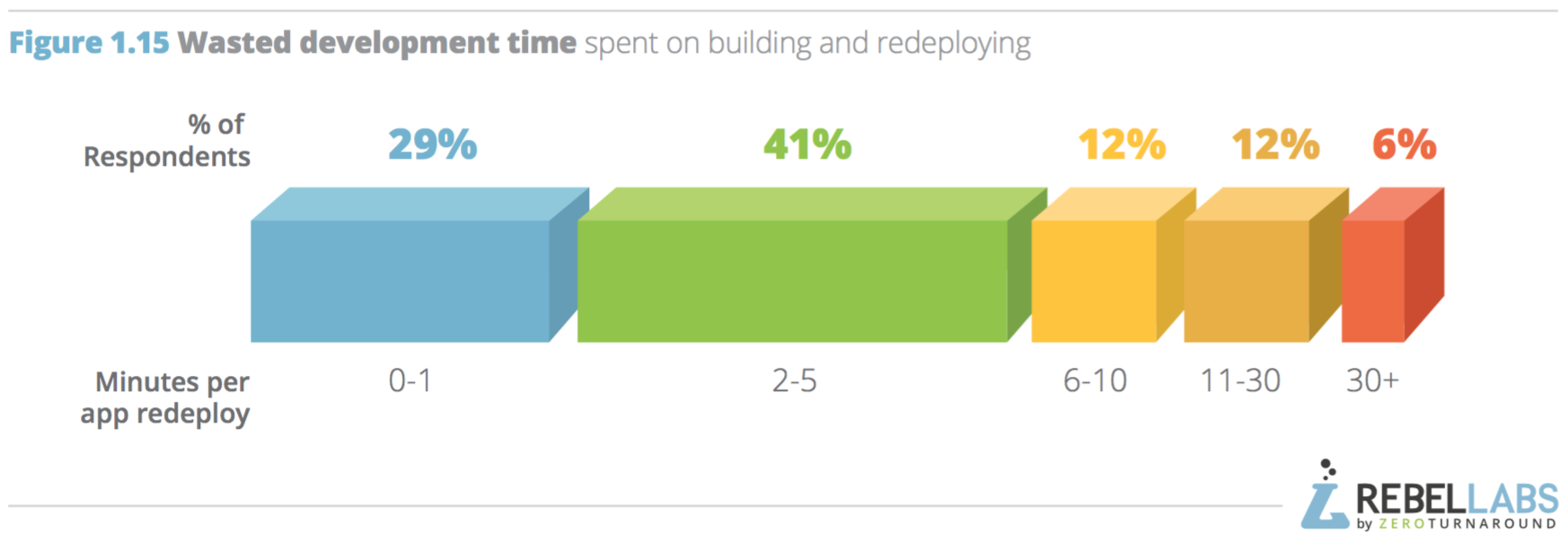
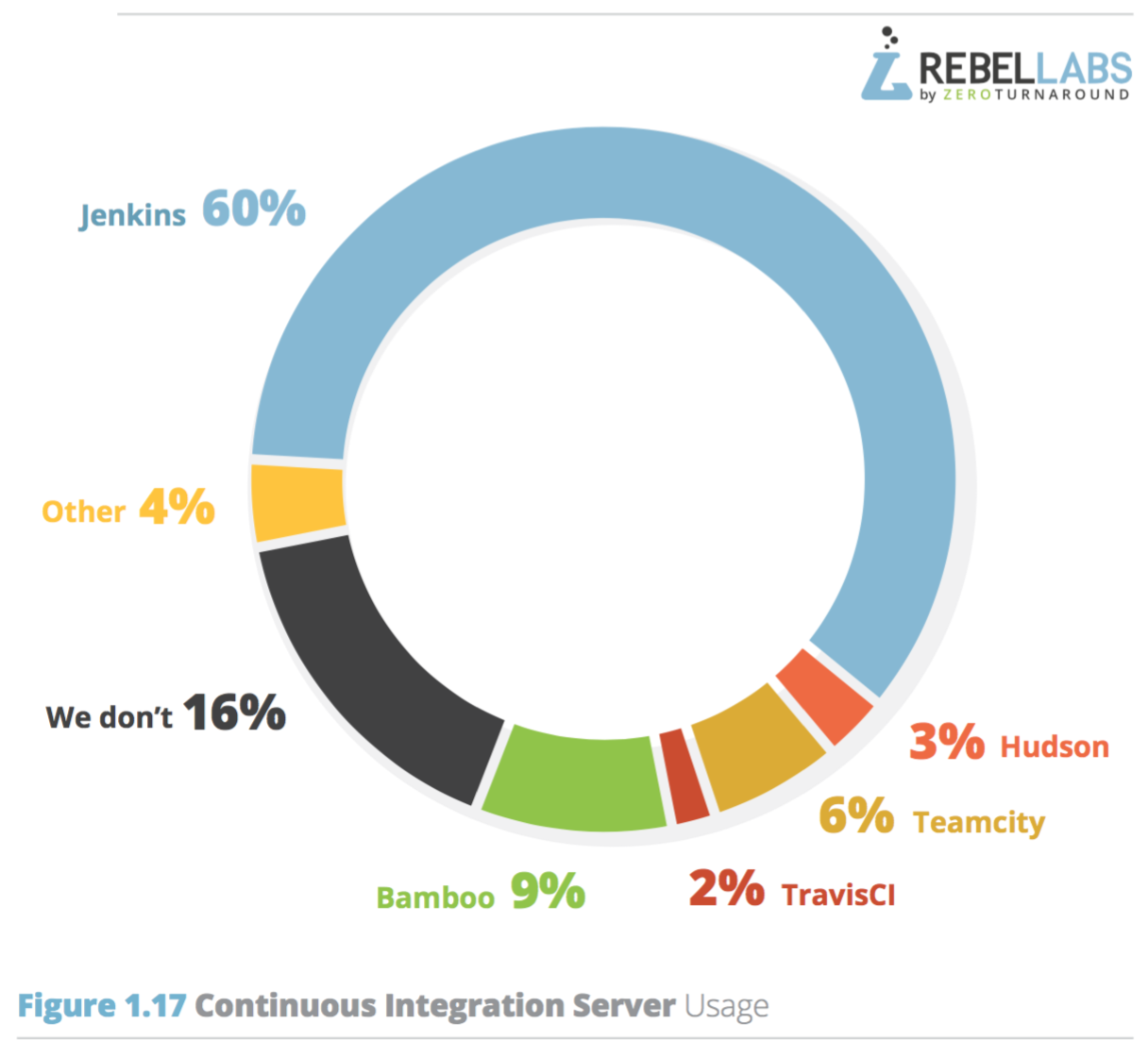

 พอดีมีโอกาสแลกเปลี่ยนแนวทางในการจัดการ Legacy code
จึงทำการสรุปสิ่งที่พูดไปไว้นิดหน่อย
พอดีมีโอกาสแลกเปลี่ยนแนวทางในการจัดการ Legacy code
จึงทำการสรุปสิ่งที่พูดไปไว้นิดหน่อย

 ติดตามข่าวสารเกี่ยวกับ
ติดตามข่าวสารเกี่ยวกับ 
 โดยทุก ๆ task ที่เราเห็นนั้น มันคือ container นั่นเอง
ตรวจสอบโดยใช้คำสั่ง
[code]
$docker ps
[/code]
แสดงดังรูป
โดยทุก ๆ task ที่เราเห็นนั้น มันคือ container นั่นเอง
ตรวจสอบโดยใช้คำสั่ง
[code]
$docker ps
[/code]
แสดงดังรูป
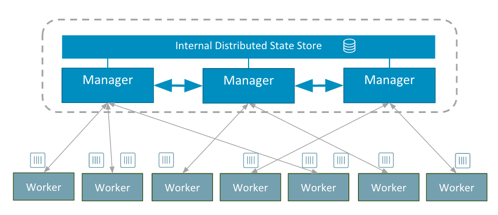


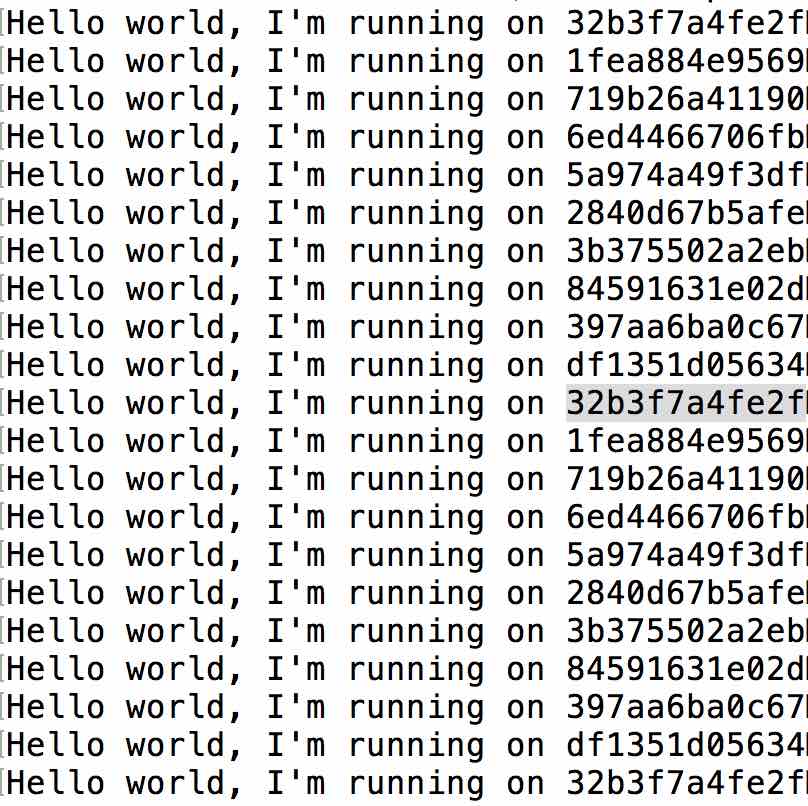 ต่อไปถ้าเอามา Scale พวก Microservice น่าจะง่ายดีนะ
และมีคำถามมากมายจาก Slide เรื่อง
ต่อไปถ้าเอามา Scale พวก Microservice น่าจะง่ายดีนะ
และมีคำถามมากมายจาก Slide เรื่อง 
 นั่งดู VDO เรื่อง
นั่งดู VDO เรื่อง 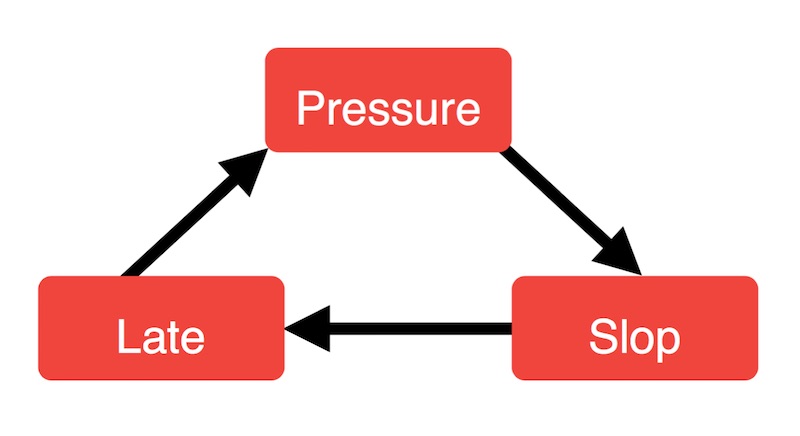 นั่นคือเมื่อเวลาผ่านไป Technical Debt ก็ยิ่งมากขึ้น
รวมทั้ง Domain หรือ Business ก็เปลี่ยนไปเรื่อย ๆ
ทำให้ code มีจำนวนสูงขึ้น
Code ที่ไม่ใช้งานก็เยอะขึ้น
เป็นแบบนี้ไปเรื่อย ๆ ทำให้ code เหล่านี้ดูแลได้ยากขึ้นเรื่อย ๆ
ดังรูป
นั่นคือเมื่อเวลาผ่านไป Technical Debt ก็ยิ่งมากขึ้น
รวมทั้ง Domain หรือ Business ก็เปลี่ยนไปเรื่อย ๆ
ทำให้ code มีจำนวนสูงขึ้น
Code ที่ไม่ใช้งานก็เยอะขึ้น
เป็นแบบนี้ไปเรื่อย ๆ ทำให้ code เหล่านี้ดูแลได้ยากขึ้นเรื่อย ๆ
ดังรูป
 จากปัญหาเหล่านี้เราจะทำอย่างไรดีล่ะ ?
เพื่อทำให้ code หรือระบบของเรามันดีขึ้น
ซึ่งมีให้เลือก 2 แบบคือ
จากปัญหาเหล่านี้เราจะทำอย่างไรดีล่ะ ?
เพื่อทำให้ code หรือระบบของเรามันดีขึ้น
ซึ่งมีให้เลือก 2 แบบคือ
 แต่สาเหตุหลักของ Code แย่ ๆ คือ ความกลัว (Fear)
กลัวที่จะไม่ทัน
กลัวที่จะโดนด่า
กลัวที่แก้ไขไปแล้ว จะทำให้ระบบทำงานไม่ได้ ทั้งที่รู้และไม่รู้
กลัวที่แก้ไขไปแล้ว จะทำให้ตัวเองมีภัย
กลัวที่จะ ...
ดังนั้นมาลดความกลัวเหล่านี้กันเถอะ เช่น
แต่สาเหตุหลักของ Code แย่ ๆ คือ ความกลัว (Fear)
กลัวที่จะไม่ทัน
กลัวที่จะโดนด่า
กลัวที่แก้ไขไปแล้ว จะทำให้ระบบทำงานไม่ได้ ทั้งที่รู้และไม่รู้
กลัวที่แก้ไขไปแล้ว จะทำให้ตัวเองมีภัย
กลัวที่จะ ...
ดังนั้นมาลดความกลัวเหล่านี้กันเถอะ เช่น