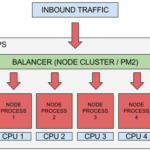
เห็นมีคนลองใช้งานกันเยอะ สำหรับ OpenGPT
สร้าง REST API ด้วยภาษา Go และใช้ Echo framework ทำการทดสอบในส่วนของ API มาลองใช้งานกันดู
ขั้นตอนที่ 1 เริ่มด้วยการออกแบบ API ที่ต้องการก่อน
ถ้า input ดีแล้ว ก็จะทำให้ได้ผลลัพธืที่ดีขึ้น
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="1.txt"]
ทาง ChatGPT จะตอบกลับมาด้วย code พร้อมคำอธิบาย ดังนี้
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="api.go"]
จะเห็นได้ว่ามีการเรียกใช้ function doRegister() แต่ไม่มีการประกาศ
จะได้ code อีกชุดมาดังนี้
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="db.go"]
ขั้นตอนที่ 2 อยากให้เปลี่ยน web framework ไปใช้งาน Echo framework
ทาง ChatGPT ก็จัด code ให้และอธิบายเป็นขั้นตอนดังนี้
ติดตั้ง library การใช้งาน middleware การเขียนในส่วน routing
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="api2.go"]
ขั้นตอนที่ 3 ต้องทำ API testing ด้วย Echo framework ด้วยสิ ถึงจะครบสูตร
ก็จะได้ code ออกมา โดยแนะนำให้ใช้งาน testify library สำหรับการทดสอบอีกด้วย
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="api_test.go"]
จากนั้นก็ถามไปว่า เราจะแยก database ออกจาก testing อย่างไร (isolate)
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="2.txt"]
มาถึงตอนนี้ได้โครงสร้าง code ทำงานเกิน 50% เข้าไปแล้ว
เพิ่มเติมนิดหน่อย คือ การ isolate ระหว่าง routing กับ database ออกจากกันด้วย
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="service.go"]
แล้ว test อย่างไร ก็เลย ถามต่ออีก
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="service_test.go"]
สบายละงานนี้ !!!
ขั้นตอนที่ 4 ทำการสร้าง Dockerfile สำหรับ project นี้
จากที่บอกตรง ๆ ไปว่าให้สร้าง Dockerfile
สิ่งที่ได้เป็นดังนี้ พร้อมทั้งคำอธิบาย และ ขั้นตอนการ run ด้วย
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="Dockerfile"]
ยังไม่พอ ขอให้สร้าง docker-compose.yml สำหรับ project นี้ และ mysql database
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="docker-compose.yml"]
มาถึงตรงนี้ deploy ระบบงานดีกว่านะ
ขั้นตอนที่ 5 ทำการ deploy ไปยัง Digital Ocean เล่น
โดยจะทำการ provisioning server ขึ้นมาใหม่Terraform
เมื่ออธิบายไปให้ ก็จะทำการบอกขั้นตอนตั้งแต่การติดตั้ง การเขียน main.tf และ deploy กันเลย
[gist id="e70dc1fd1cb777afa72b120df70dab1f" file="main.tf"]
เพียงเท่านี้เราก็ได้ code ที่พอจะทำงานและ deploy ได้แล้ว
ตัวอย่าง code และ instruction