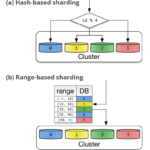
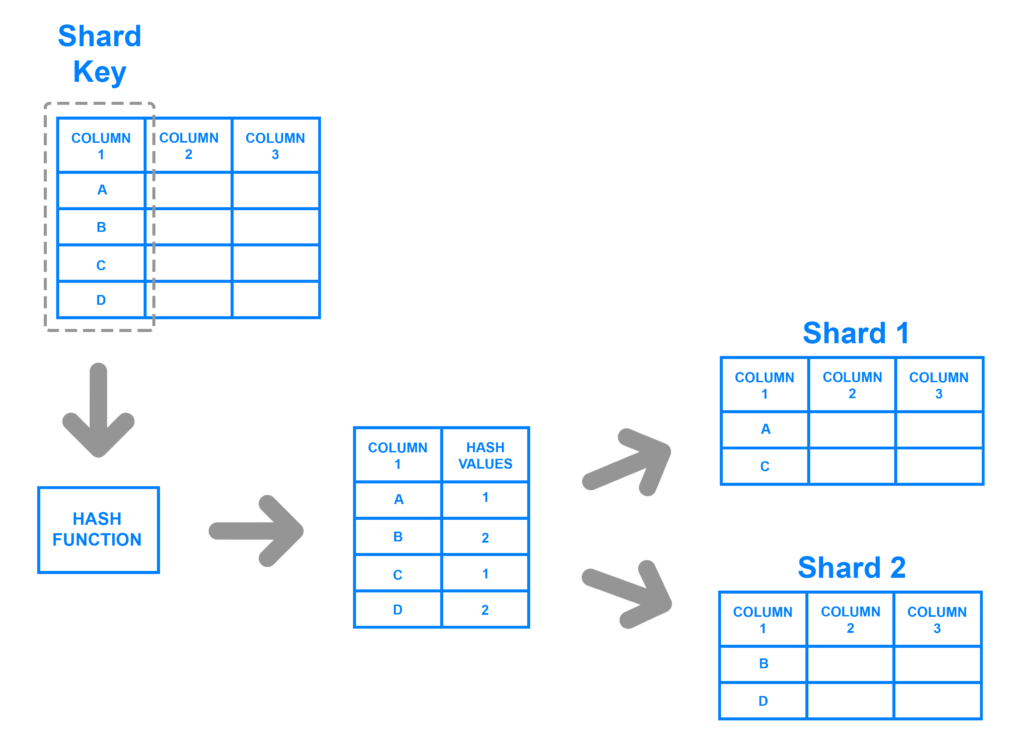
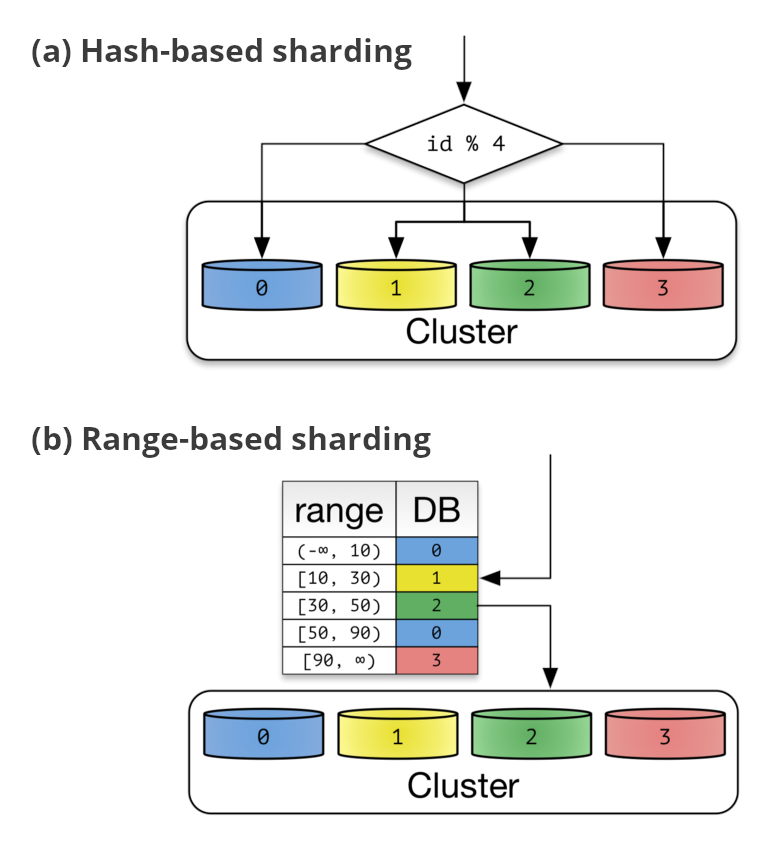
ในการพัฒนาระบบงานนั้น
สิ่งที่สำคัญของ developer ที่ไม่แพ้ไปกว่าการเขียน code เลย
คือการ test หรือ ทดสอบ
และยังเป็นการทดสอบแบบอัตโนมัติอีกด้วย
แน่นอนว่าต้องเขียน code ด้วยอีกชุด
โดยที่เราสามารถสรุปขั้นตอนการพัฒนาและเขียน test
ได้ดังนี้
- เขียน code ที่ error หรือ compile หรือ parse ไม่ผ่าน เพราะว่า library ต่าง ๆ อาจจะยังไม่ครบ ดังนั้นทำให้ผ่าน แล้วไปขั้นตอนต่อไป
- เขียน test แล้วดูว่า error ไหม ซึ่งจะเน้นไปที่การ setup ของ test หรือ initial stage เพื่อทดสอบต่อไป
- ดู failure ของ test ว่าเป็นอย่างไร เพื่อทำความเข้าใจ ว่าทำงานตามที่เราคาดหวังไหม ถ้าไม่เป็นไปตามที่คาดหวังอาจจะเกิดจากขั้นตอนก่อนหน้าก็ได้ ดังนั้นต้องมีความรอบคอบ
- เขียน code เพื่อให้ test ผ่าน ทีละ test ไม่ต้องรีบร้อน
- จากนั้นก็ทำการตรวจสอบว่า code ที่เขียน กับ test ที่สร้างมันครอบคลุม หรือ ทำให้เรามีความเชื่อมั่นไหม ถ้ายังก็แสดงว่ายังไม่สิ่งที่ทำอยู่
- สิ่งที่เราสร้างมีตรงไหนบ้างที่ไม่ดี หรือ อยากปรับปรุง จงทำซะ
- เมื่อทุกอย่าง ok แล้ว มั่นใจแล้ว ก็พัฒนาส่วนอื่น ๆ ต่อไป
- วนอย่างนี้ไปเรื่อย ๆ ทำทีละขั้นตอนไปเรื่อย ๆ
แน่นอนว่า ในการพัฒนา และ เขียน test มันไม่ได้สนุกเลย
แต่เป็นสิ่งที่สำคัญมาก ๆ และขาดไม่ได้
ทุกอย่างเริ่มจากการคิด แล้วจึงลงมือทำ