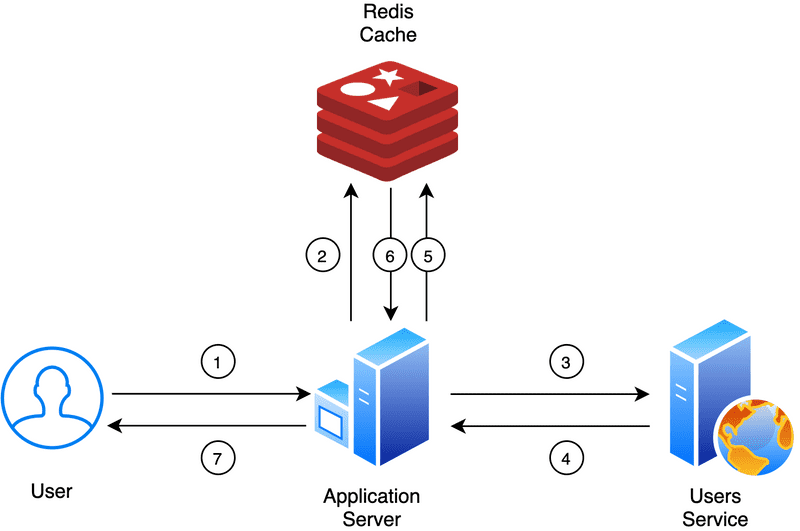
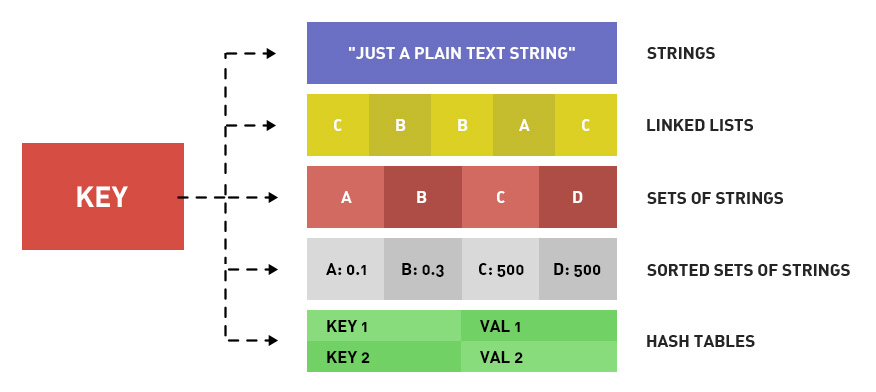
โดยปกติข้อมูลที่เก็บใน Redis จะมี Data model แบบ Key-value
ซึ่ง value สามารถมีรูปแบบของข้อมูลหลัก ๆ ดังนี้
Primitive data type เช่น string และ number
Data structure ประกอบไปด้วย List, Set, Hash, SortedSet เป็นต้น
Image may be NSFW. Clik here to view.
โดยส่วนใหญ่เราจำเป็นต้องทำความเข้าใจว่า ระบบงานของเรานั้น ต้องการใช้ข้อมูลอย่างไร เพื่อให้เลือก data structure ได้อย่างเหมาะสม เนื่องจากการเข้าถึงข้อมูลใน Redis นั้น จะมีการบอกและอธิบายไว้ชัดเจนว่ามี Big O เท่าไร
จึงเริ่มที่การวิเคราะห์ปัญหา และแนวทางแก้ไข สิ่งที่เห็นร่วมกันคือ ในการแก้ไขข้อผิดพลาดต่าง ๆ ทีมควร reproduce ให้ได้ก่อน จากนั้นทำการบันทึกไว้ในรูปแบบของ test case ที่สามารถ run ซ้ำ ๆ ได้ จากนั้นจึงแก้ไข code เพื่อให้ test case เหล่านั้นผ่าน แต่ในการทำงานจริง ๆ มันไม่ง่ายเลย เนื่องจากต้องทำการแก้ไขและปรับปรุงโครงสร้างของ App ให้เอื้อด้วยเช่นกัน อีกทั้งการเพิ่มความสามารถใหม่ ๆ ต้องมี test case คลุมเสมอ เพื่อทำให้มั่นใจยิ่งขึ้น
ไปเจอรูปอธิบายการทำงานของ Web เมื่อเราทำการกรอก URL ใน web browser จากนั้นทำการกดปุ่ม enter มันเกิดอะไรขึ้นบ้าง ก่อนที่เราจะเห็นผลของการทำงาน ซึ่งนำมาจากที่ Dev.to
ไม่มีอะไรมาก เห็นคุยกันเรื่องการทำ API สำหรับดึงข้อมูลรายชื่อจังหวัดของประเทศไทย เพื่อนำมาใช้งานกัน จึงไปค้นหาดุใน Google ก็เจอเยอะเลย แสดงว่าเป็นแนวปฏิบัติปกตินะ !!!
คำถามที่น่าสนใจ จากทีมที่เริ่มนำแนวทางของการทดสอบแบบอัตโนมัติมาใช้งาน ทั้ง Unit testทั้ง API testทั้ง UI test หรือจะเป็น integration, component และ contract test ก็ตาม ปัญหาที่มักจะพบเจอประกอบไปด้วย
ใช้เวลาในการทดสอบเยอะขึ้นเรื่อย ๆ เนื่องจากจำนวน test เยอะขึ้น
มี test case จำนวนมากที่ผ่านบ้าง ไม่ผ่านบ้าง ทั้ง ๆ ที่ไม่ได้เปลี่ยนแปลงอะไร (Flaky test)
เราจะแก้ไขและปรับปรุงอย่างไรดี ?
ปัญหาที่จะแก้ไขคือ เวลาการทดสอบเยอะ
สาเหตุมาจากจำนวนการทดสอบในส่วนของ functional test เยอะเกินไป ทั้ง UI, API และ integration test ต่าง ๆ ดังนั้นจำเป็นต้องกลับมาดูว่า test case อะไรบ้างที่จำเป็น และ ไม่จำเป็นต้องมีก็ได้ หรือทดสอบใน level ต่ำลงมา เช่น component, contract และ unit test มากขึ้น
รวมทั้งการปรับปรุงการทดสอบให้เร็วขึ้น
ทั้งเรื่องของ การเขียน script ทั้งเรื่องของ การ run test ทั้ง parallel และ distributed testing
จากบทความของ Slack เรื่อง How we design out APIs at Slack ทำการสรุปแนวทางในการออกแบบ API ของระบบออกมาว่าเป็นอย่างไรบ้าง เพื่อช่วยทำให้ผู้ใช้งานหรือ developer ใช้งานง่ายขึ้น อีกทั้งช่วยให้การดูแลรักษา API ง่ายขึ้นด้วย ซึ่งควรต้องคิดตั้งแต่การออกแบบกันเลยทีเดียว มิเช่นนั้นแทนที่จะได้ API ที่ดีมีประโยชน์ กลับได้ของที่แย่ ๆ ออกมา โดยมีแนวทางของการออกแบบดังนี้
1. So one thing and do it well
เมื่อเริ่มต้นออกแบบ API นั้น อาจจะมีหลาย ๆ ปัญหาให้แก้ไข ซึ่งอาจจะทำให้เกิดความซับซ้อน และ ยากต่อการทำความเข้าใจ ดังนั้นแนะนำให้เลือกจาก use case หนึ่งมาทำ เพื่อให้ focus มากยิ่งขึ้น
โดยจะเริ่มตั้งแต่การใช้งานภายใน เช่นพนักงานใหม่เข้ามา ให้ลองทำการเปิดและลองใช้งาน API ดูว่า ใช้งานเป็นอย่างไร เริ่มง่ายไหม เร็วไหม
3. Strive for intuitive consistency
API ต้องความสอดคล้องไปในทิศทางเดียวกันและช่วยให้เข้าใจหรือพอเดาได้ว่า API ทำงานอะไร ใช้งานอย่างไรโดยแทบจะไม่ต้องอ่านเอกสารเลยด้วยซ้ำทั้งจากชื่อของ endpointทั้งจากชื่อของ input parameterทั้งจาก output response
โดยเรื่องของ consistency จะมีอยู่ 3 level คือ
Level 1 :: Consistency with Industry standard Level 2 :: Consistency with your product Level 3 :: Consistency with your other API methods
เริ่มจากการตั้งปัญหาที่ต้องการแก้ไขและกำหนด use case ของ API ให้ชัดเจน จากนั้นเริ่มเขียน API spec เพื่อทำการอธิบายสิ่งที่จำเป็นสำหรับ API เพื่อทำให้เข้าใจสิ่งที่จะสร้างอย่างชัดเจน ประกอบไปด้วย