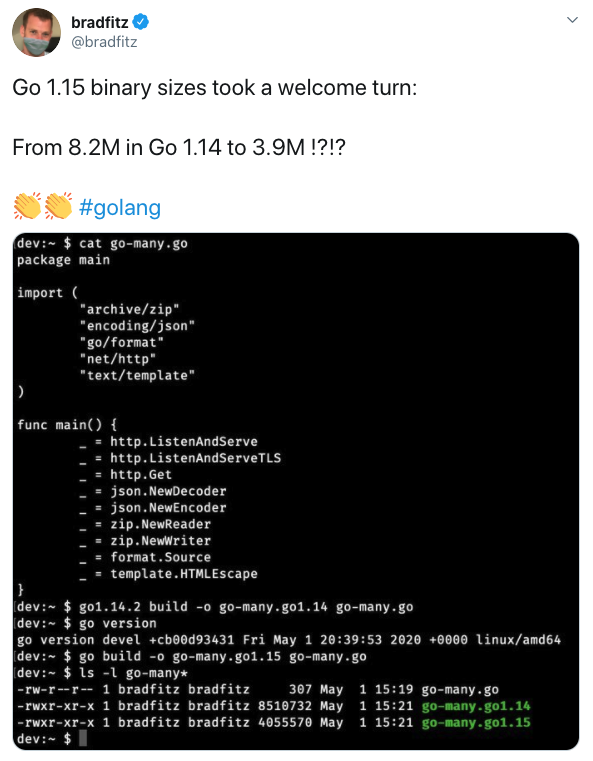
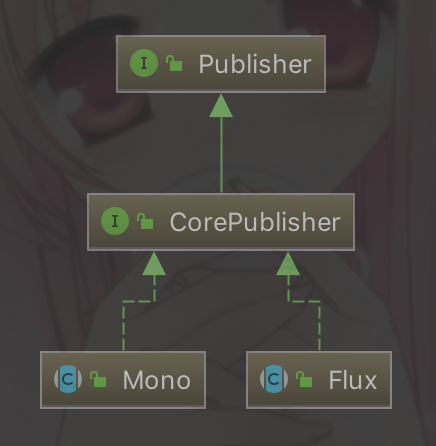
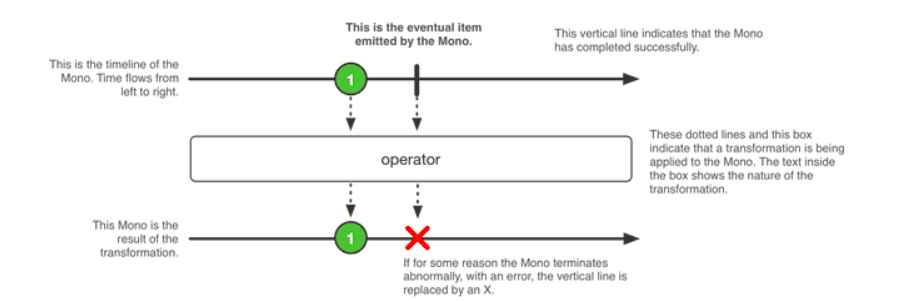
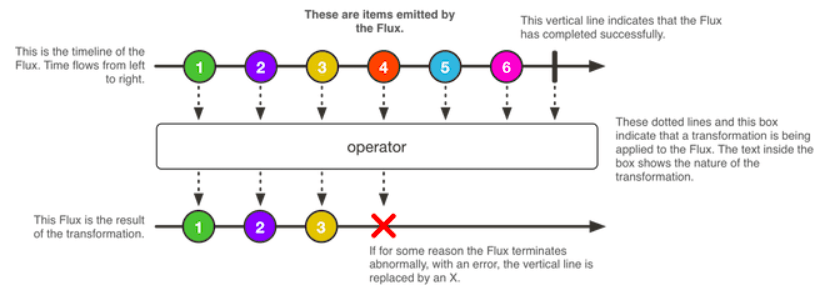
วันนี้ลองไปดูการเชื่อมต่อจาก Google Cloud Run ไปดึงข้อมูล ใน Google Sheets ผ่าน Google Sheets API ได้เลย พบว่ามันทำง่ายดี เพียงแค่ share เอกสาร ให้กับ email ของ Google account ที่ใช้งาน Cloud Run จากนั้นก็เขียน code เพื่อดึงข้อมูลมาใช้งาน รวมทั้ง deploy บน Cloud Run ได้เลย สรุปขั้นตอนไว้ดังนี้
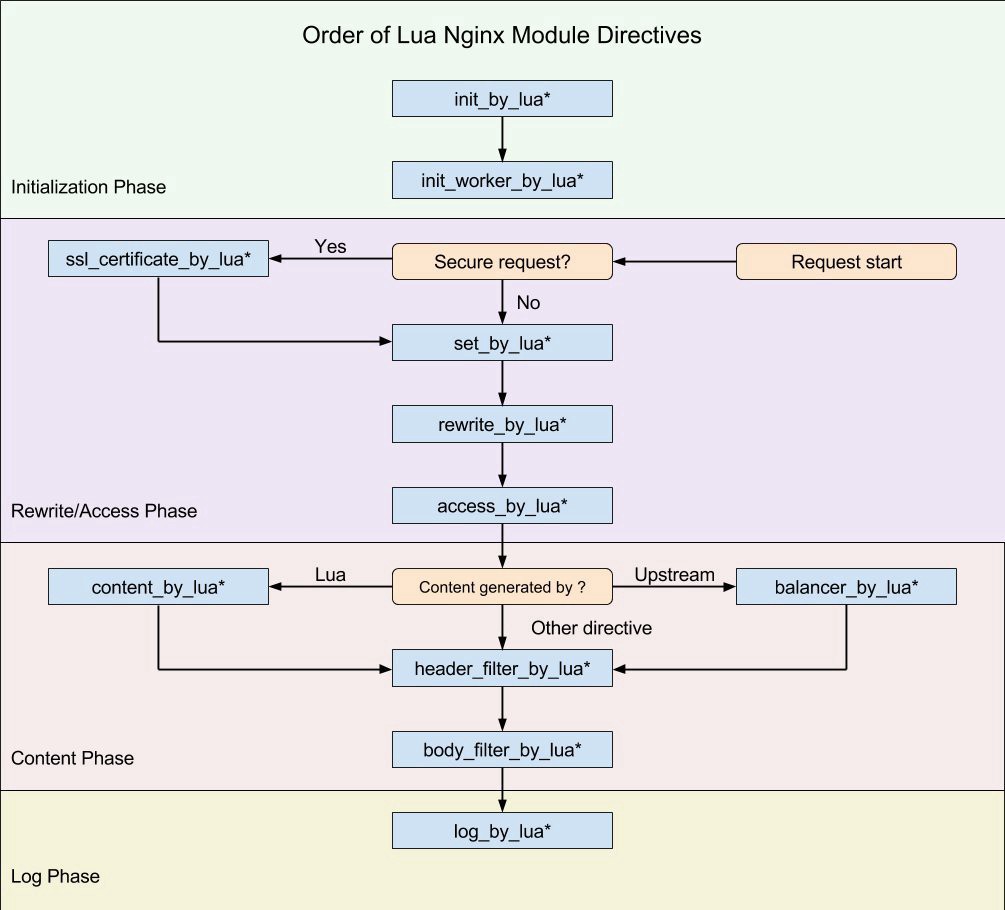
ขั้นตอนท่ี 1 สร้าง Google Sheets ขึ้นมา
ยกตัวอย่างเช่น
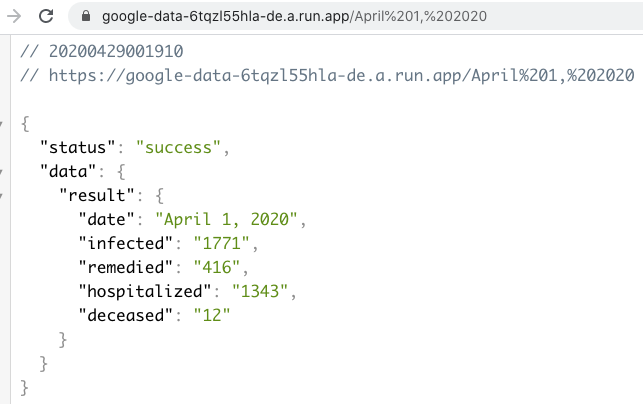
เอกสารที่สร้างขึ้นมาจะมี ID ให้ ยกตัวอย่างเช่น "https://docs.google.com/spreadsheets/d/xxxxxxx "
ดังนั้น ID ของเอกสารนี้คือ xxxxxxx จะเอาไว้ใช้ใน code ที่จะเขียนต่อไป
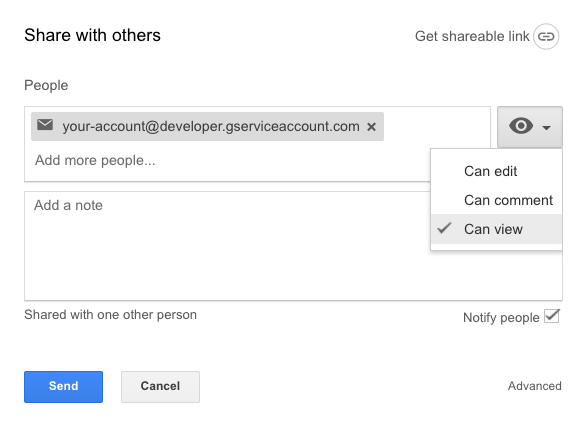
จากนั้นทำการ shared เอกสารนี้ไปยัง email ที่ใช้งาน Google Service ของเรา ให้เพียงแค่ดูได้ก็พอ ไม่ต้องทำการ share แบบ public
ขั้นตอนที่ 2 ทำการเขียน code ด้วยภาษาที่ชอบที่ชอบ
ต้องการสร้าง RESTFul API ไปดึงข้อมูลในวันที่ต้องการจากขั้นตอนที่ 1 ผ่าน Google Sheets API พัฒนาด้วย Node.js
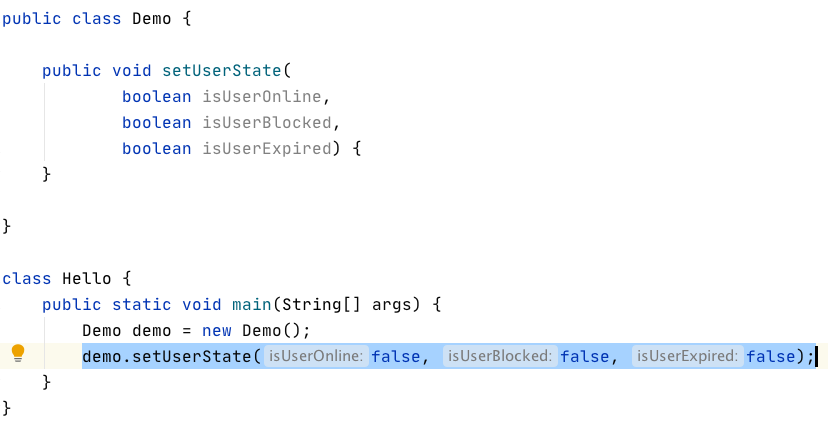
พอดีเพิ่งคุยเรื่องการเขียน test ที่เป็นทำงานแบบอัตโนมัติ จะเน้นที่การเขียน test code และ production code ไปด้วยกัน มีคำถามที่น่าสนใจคือ เหตุผลที่บอกว่าจะไม่เขียน test มันมีเยอะจนทำการสรุปได้ดังนี้ มาดูกันว่ามีเหตุผลอะไรบ้าง
เหตุผลนี้เจอเยอะมาก ๆ คำถามคือ คนเราสามารถทดสอบซ้ำ ๆ จาก test case แรกไปจนถึง test case ล่าสุดได้ไหม ถ้าได้ใช้เวลาเท่าไร บ่อยเพียงใด รวมทั้งยังไม่คุณภาพเช่นเดิม ไม่เปลี่ยนแปลง แน่นอนว่า manual test ไม่สามารถตอบได้เลย ใช่ไหมนะ ?
เหตุผลที่ 7 คือ ลูกค้าไม่จ่ายเงินสำหรับการเขียน test
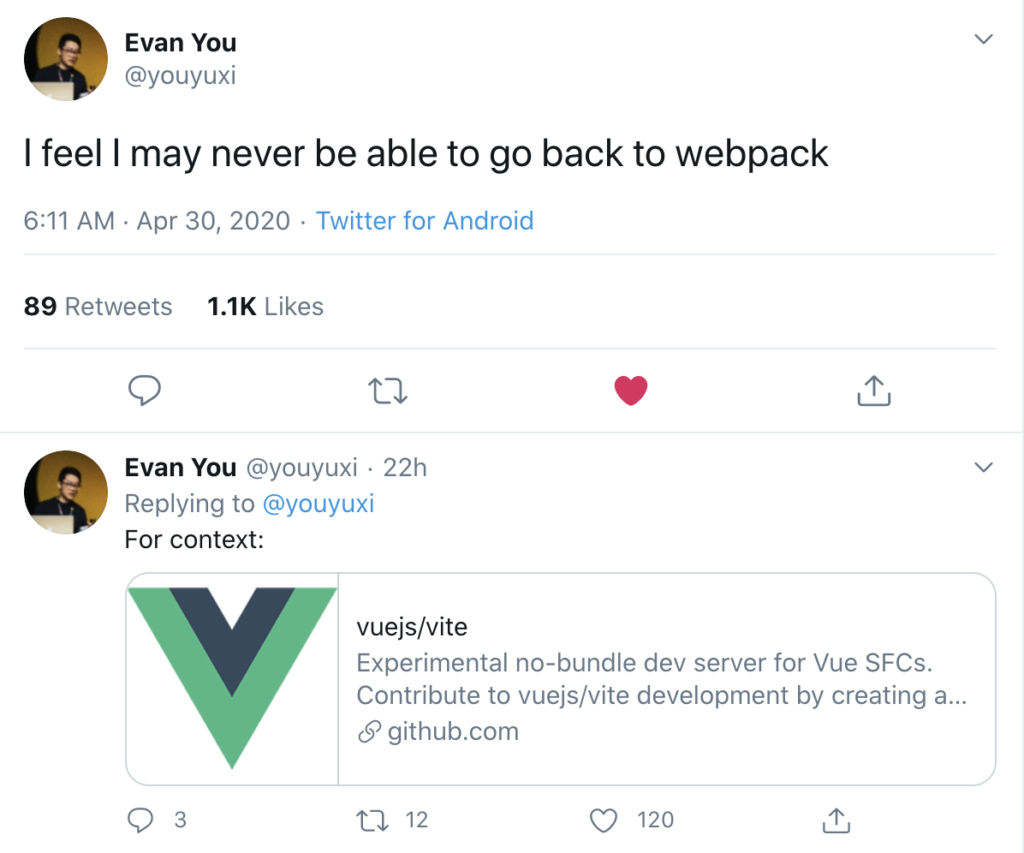
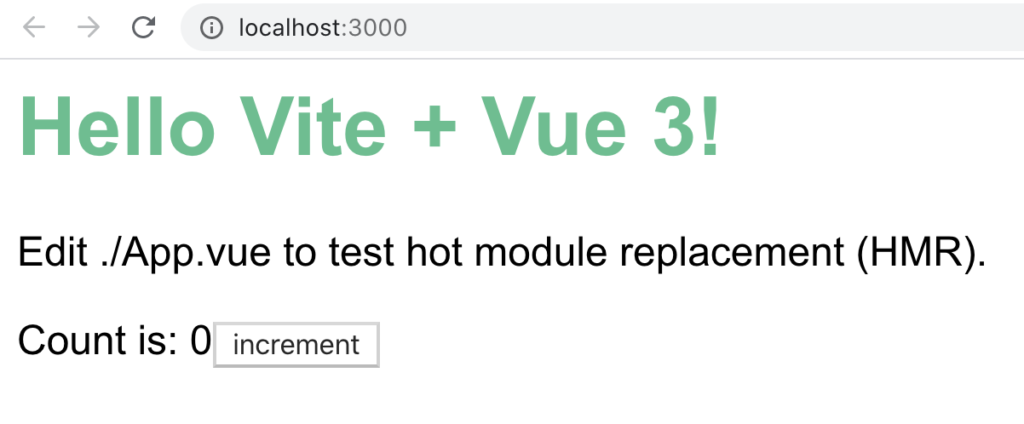
พบว่าง่ายต่อการเริ่มต้น รวมทั้ง hot reload เร็วจริงจังมาก น่าจะทำให้ development flow ดีขึ้นอย่างมาก และจาก commit history พบว่า กำลังพัฒนากันจริงจังมาก ๆ
จากเอกสารของ Vite เขียนไว้ว่า การนำ esbuild มาใช้งานทำการแปลง TypeScript มาเป็น JavaScript เร็วขึ้น 20 ถึง 30 เท่า โดยที่ esbuild เขียนได้ภาษา Go อีกด้วย
Vite uses esbuild to transpile TypeScript into JavaScript which is about 20~30x faster than vanilla tsc, and HMR updates can reflect in the browser in under 50ms.
vite v0.12.0 ⠸ Building for production… [write] dist/assets/index.js 35.44kb [write] dist/assets/style.css 0.11kb [write] dist/index.html 0.25kb Build completed in 1.52s.
ถ้าเจอในขั้นตอนของการ deploy บน production ก็แก้ไขบน production เลยใช่ไหม ? หรือกลับมาเริ่มต้นใหม่ คือ Dev -> Test -> UAT -> Prod ดูชีวิตมันวุ่นวายดีนะ ใครทำอยู่บ้าง ?
วิธีการที่ทำอยู่บ่อย ๆ ในช่วงของการพัฒนา Dev -> Test -UAT คือ