![]()
![]()
ช่วงหลังมีการพูดถึง
The Twelve -Factor App กันเยอะ
แต่ไม่ค่อยบอกหรือแสดงให้ดูว่ามันทำอย่างไรบ้าง ?
ดังนั้นเราลองมาพัฒนาระบบงานแบบง่าย ๆ
ตามแนวคิดนี้กันดู (ตามความเข้าใจที่มีนะ ผิดถูกก็ตามข้างล่างนี้)
มาเริ่มกันดีกว่า
ปล. ยิ่งรู้ว่าผิดเร็ว ก็จะทำถูกได้ไว
ข้อที่ 1 Codebase
One codebase tracked in revision control, many deploys
ทุกสิ่งอย่างเริ่มที่ source code นั่นเอง
ดังนั้นเก็บ source code ใน Version Control System ซะ
เช่น Git, Mercurial และ Subversion เป็นต้น
อย่ามา backup ด้วย folder หรือ thumb drive กันละ !!
ส่งผลให้ง่ายต่อการ deploy source code เหล่านี้
ไปยัง environment ต่าง ๆ ได้ เช่น dev server, test/QA server, staging server และ production server เป็นต้น
แต่เรื่องการจัดการ source code ใน Version Control System นั้นก็ไม่ง่าย
ต้องเอื้อประโยชน์ต่อทีม
ต้องเอื้อประโยชน์ต่อระบบงาน
ต้องเอื้อประโยชน์ต่อองค์กร
นั่นคือเรื่องของ Branch strategy นั่นเอง ทั้ง Single branch, multiple branch, integration หรือ feature branch
นี่คือเรื่องที่สำคัญ
ถ้าสิ่งที่เลือกทำให้ช้าลง แย่ลง ก็น่าจะผิดนะ
ยังไม่พอนะ โครงสร้างของ source code ก็สำคัญ
ทั้งการแยก folder/package ตามหน้าที่การทำงาน
ช่วยให้จัดการและดูแลรักษาง่ายขึ้น
ดังนั้นมาเขียน code กันดีกว่า
อย่าไปเขียนให้ยาก เขียนง่าย ๆ
เป็น code สำหรับสร้าง RESTful API ด้วยภาษา Python และเชื่อมต่อ MySQL database
(เขียนภาษา Go บ่อยแล้ว เปลี่ยนภาษากันบ้าง)
[gist id="4eb6786209e5318ea0ce404239340558" file="api.py"]
จากนั้นทำการ run ด้วยคำสั่ง
[code]
$python api.py
[/code]
ผลการทำงานเป็นดังนี้
[gist id="4eb6786209e5318ea0ce404239340558" file="1.txt"]
ข้อที่ 2 Dependencies
Explicitly declare and isolate dependencies
พวก dependency หรือ library ต่าง ๆ ที่ใช้งานในการพัฒนา
ควรถูกแยกออกมาจาก source code
โดยเราสามารถนำเครื่องมือเข้ามาช่วย
ยกตัวอย่างเช่น
- Gem bundler สำหรับภาษา Ruby
- Apache Maven/Gradle สำหรับภาษา Java
- Pip สำหรับภาษา Python
ในระบบตัวอย่างพัฒนาด้วยภาษา Python จึงใช้งานผ่าน Pip
ซึ่งทำการประกาศ dependency หรือ library ที่ใช้งาน
ในไฟล์ requirements.txt ดังนี้
[gist id="4eb6786209e5318ea0ce404239340558" file="requirements.txt"]
จากนั้นทำการติดตั้ง dependency ด้วยคำสั่ง
[code]
$pip install -r requirements.txt
[/code]
ยังไม่พอนะ เรื่องของ depenedncy มันยังลามไปถึง System dependency ด้วย
ทั้งเรื่องของ version ของ python และ pip ที่ใช้งาน
ซึ่งแก้ไขด้วยการใช้งาน
virtualenv
การใช้งานก็ไม่ได้ยากเลย ดังนี้
[code]
$virtualenv env --no-site-packages
$source env/bin/activate
[/code]
แต่ถ้าต้องการแยกตั้งแต่ระบบปฏิบัติการไปเลย
คงต้องมาใช้พวก Containerization แล้วเช่น
Docker เป็นต้น
แต่ตอนนี้ยังไม่ถึงเวลา เดี๋ยวค่อยนำมาใช้กัน
ข้อที่ 3 Config
Store config in the environment
ระบบงานที่พัฒนาควรทำการจัดเก็บ configuration ต่าง ๆ ใน environment variable ซะ
เพื่อทำให้สามารถ deploy source code เดียวกันได้ในทุก ๆ enviroment เช่น dev, test/qa และ production เป็นต้น
จาก source code จากข้อที่ 1 นั้น
เราสามารถแยก configuration ที่เกี่ยวกับ database ออกมา
แล้วไปเก็บไว้ใน environment variable ได้
ปล. คิดว่าคงไม่มีใครทำการ hard code หรอกนะ
อย่างน้อยก็น่าจะเก็บไว้ในไฟล์ configuration แน่นอน
มาลองเขียนกันหน่อย ไม่ได้ยากเลย
[gist id="4eb6786209e5318ea0ce404239340558" file="api2.py"]
จากนั้นตอน run ก็กำหนดค่าต่าง ๆ ตามที่ใจต้องการ
มันทำให้ระบบงานมีความยืดหยุ่นมากยิ่งขึ้น
[gist id="4eb6786209e5318ea0ce404239340558" file="run.sh"]
ถ้าเป็นพวก Docker และ Kubernetes นี่ง่ายมาก ๆ
Docker ไปใช้ environment ได้เลย
ส่วน Kubernetes ไปใช้งาน ConfigMap แบบชิว ๆ
ข้อที่ 4 Backing services
Treat backing services as attached resources
ในแต่ละส่วนที่ทำงานกับระบบงานของเรานั้นต้องไม่ผูกมัดกันแบบแน่น
ยกตัวอย่างเช่น Database, External storage, Message queue
ต้องสามารถเปลี่ยนได้ง่าย โดยไม่ทำการแก้ไข code เลย
หรือเพียงแค่เปลี่ยน configuration เท่านั้น
นั่นคือการเปลี่ยนแปลงต้องไม่กระทบการทำงาน
นั่นคือมองสิ่งต่าง ๆ เหล่านี้เป็น service หรือจำเป็นต้องมี abstraction layer/interface เข้ามากั้น
ถ้ามองไปยังโลกของ containerization นั้นง่ายมาก ๆ
ต้องการเปลี่ยน database จาก MySQL ไปเป็น PostgreSQL
ทำได้ง่าย ๆ ด้วยการสร้าง container ใหม่ที่ทำหน้าที่จัดการข้อมูลผ่าน PostgreSQL
จากนั้นก็ทำการ rollout ใหม่ หรือทำการ restart container ที่เกี่ยวข้อง ก็เท่านั้นเอง
หรือถ้าเพียงแค่เปลี่ยน configuration ใน environment variable ได้ก็จบเลย (อย่าลืม restart ด้วย)
กลับมามองที่ระบบงานตัวอย่างของเราบ้าง
ถ้าเราต้องการเปลี่ยน database จาก MySQL ไปเป็น database อื่นละ
เราจะทำอย่างไรดี ?
จากที่ทำมานั้น พบว่ามี 3 แบบที่พอเป็นไปได้คือ
- 1. ถ้า database ที่เราเลือกใช้ ทำการกำหนดค่าเหมือน MySQL ก็จบ (ไม่ค่อยมี) ไม่ต้องแก้ไข code
- 2. ทำการแยกส่วนของการจัดการข้อมูลจาก database ไปเป็น service ใหม่เลย แล้วคุยกันผ่าน HTTP protocol เช่น RESTful API จากนั้นถ้าต้องการเปลี่ยน database ก็ไปสร้าง service ใหม่เลย จากนั้นเปลี่ยน configuration ของผู้ใช้งานให้ไปเรียก service ใหม่ เพียงเท่านี้ก็จบ
- 3. ถ้าการเปลี่ยน database ยังคงเป็น RDBMS เหมือนเดิม เราสามารถใช้งานพวก Object Oriented Mapping (ORM) มาใช้ได้นะ เช่น SQLAlchemy เป็นต้น จากนั้น URL ของการเชื่อมต่อ database ต่าง ๆ จะเหมือนกันเลย เพียงย้ายมากำหนดผ่าน environment variable ก็เรียบร้อย
อยากใช้แบบไหน ก็เอาที่ถนัดและเอาอยู่นะครับ
เพราะว่าแบบแรก ถ้าได้ก็โชคดีไป
เพราะว่าแบบที่สองและสามนั้น เราต้องไปแยก service ออกมา จาก 1 เป็น 2 ก่อน จากนั้นจึงค่อยสร้างและเปลี่ยนใหม่
มาดูตัวอย่างในแบบที่ 3 กันหน่อย
แก้ไขง่าย ๆ ด้วยการใช้งาน Flask SQLAlchemy
[gist id="4eb6786209e5318ea0ce404239340558" file="api3.py"]
ทำการง่าย ๆ ด้วยการกำหนด DATABASE_URL ก็พอ
[code]
$export DATABASE_URL=mysql+mysqlconnector://user:password@localhost/demo
$python api.py
[/code]
จากนั้นถ้าต้องการเปลี่ยน database ก็เพียงเปลี่ยน DATABASE_URL เท่านั้น
แต่ต้องเป็น database ที่ SQLAlchemy สนับสนุนเท่านั้นนะ
เขียนไปเขียนมาเริ่มยาวเกินไปแล้ว
ดังนั้นเอาไว้ต่อที่เหลืออีก blog ก็แล้วกัน
ตัวอย่าง source code อยู่ที่
Github::Up1::Demo 12 Factor App
ขอให้สนุกกับการ coding ครับ

 เพิ่งไปแบ่งปันเรื่องของ Code Quality
มีหนึ่งเรื่องที่น่าสนใจคือ dead code
หรือ code ที่ไม่ถูก execute
หรือ code ที่ไม่ถูกใช้งาน
หรือ code ที่ comment ไว้ ทั้ง ๆ ที่ใช้ version control
หรือหนักสุดคือ code ที่สร้าง feature ที่ไม่มีผู้ใช้งาน
คำถามคือ
ทุกวันนี้เรายังดูแลรักษา code เหล่านี้ไว้กันหรือไม่ ?
ลองตอบกันหน่อยนะ
สิ่งที่น่าสนใจคือ
ทำไมเรายังเก็บ code ที่ไม่ใช้งานจากข้างต้นกันไว้นะ ?
ยิ่งนับวันมันจะมีจำนวนมากขึ้นเรื่อย ๆ อย่างไม่หยุดยั้ง
ยิ่งนับวันมันยิ่งทำให้เราช้าลงไปเรื่อย ๆ
ทั้งการอ่านและทำความเข้าใจ code
ทั้งเวลาในการ build ที่สูงขึ้น
ทั้งการดูแลรักษาที่ยากลำบากขึ้น
ทั้งผลกระทบต่าง ๆ ที่อาจจะเกิดขึ้น
ทำไมนะ
เพิ่งไปแบ่งปันเรื่องของ Code Quality
มีหนึ่งเรื่องที่น่าสนใจคือ dead code
หรือ code ที่ไม่ถูก execute
หรือ code ที่ไม่ถูกใช้งาน
หรือ code ที่ comment ไว้ ทั้ง ๆ ที่ใช้ version control
หรือหนักสุดคือ code ที่สร้าง feature ที่ไม่มีผู้ใช้งาน
คำถามคือ
ทุกวันนี้เรายังดูแลรักษา code เหล่านี้ไว้กันหรือไม่ ?
ลองตอบกันหน่อยนะ
สิ่งที่น่าสนใจคือ
ทำไมเรายังเก็บ code ที่ไม่ใช้งานจากข้างต้นกันไว้นะ ?
ยิ่งนับวันมันจะมีจำนวนมากขึ้นเรื่อย ๆ อย่างไม่หยุดยั้ง
ยิ่งนับวันมันยิ่งทำให้เราช้าลงไปเรื่อย ๆ
ทั้งการอ่านและทำความเข้าใจ code
ทั้งเวลาในการ build ที่สูงขึ้น
ทั้งการดูแลรักษาที่ยากลำบากขึ้น
ทั้งผลกระทบต่าง ๆ ที่อาจจะเกิดขึ้น
ทำไมนะ

 วันนี้ได้เข้าเรียน
วันนี้ได้เข้าเรียน 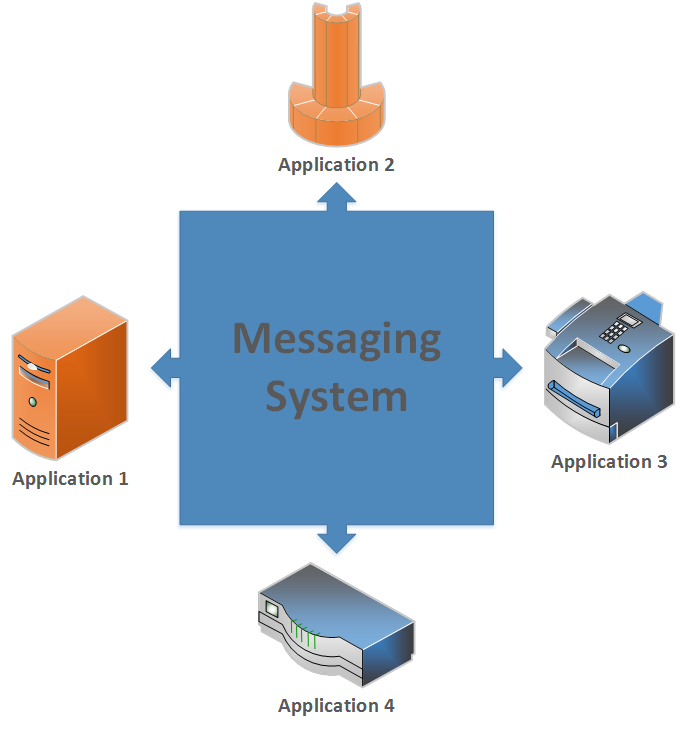
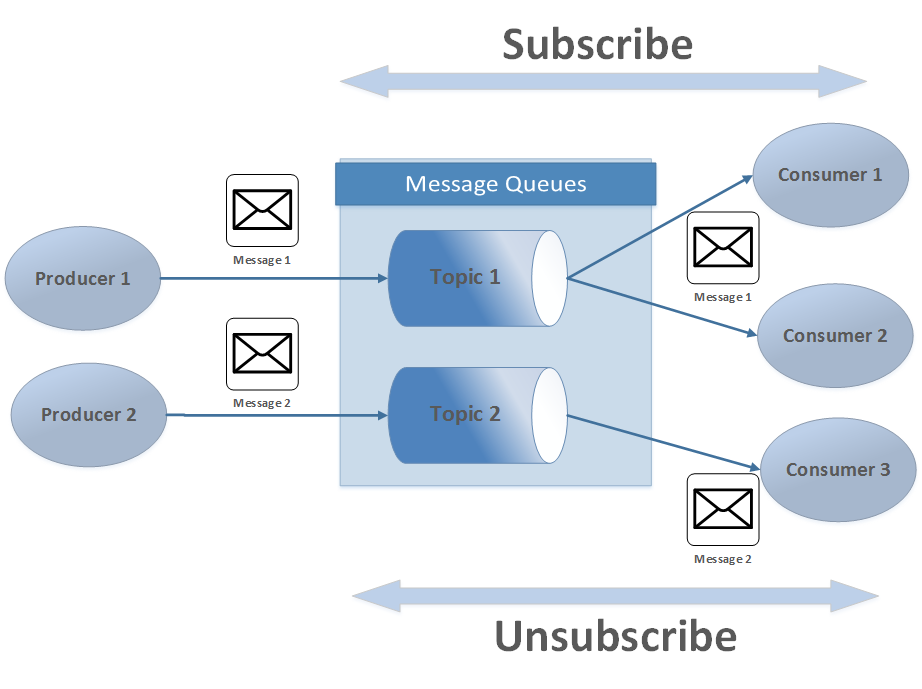
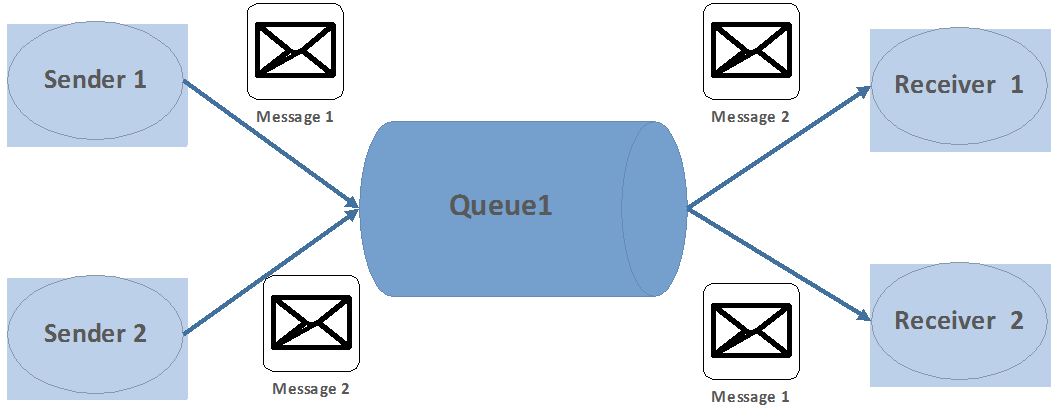 Point-to-Point แบ่งได้ 2 แบบตามการทำงาน คือ
Point-to-Point แบ่งได้ 2 แบบตามการทำงาน คือ
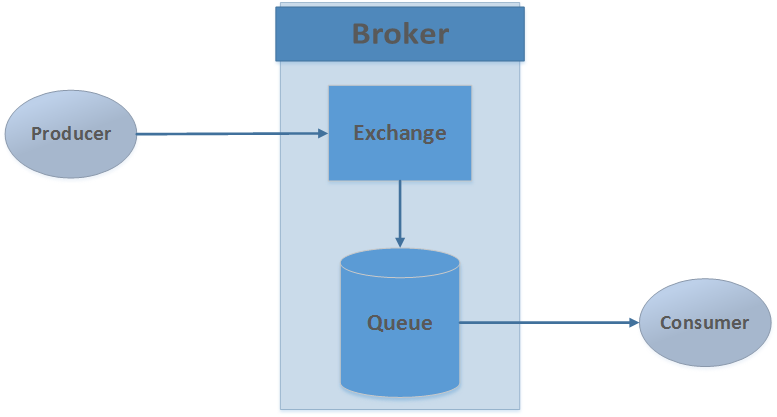 จากรูปนั้น
Producer จะทำการส่งข้อมูลไปยัง Broker
จากนั้น Broker จะส่งข้อมูลไปยัง consumer ต่อไป
แต่ใน Broker นั้นจะมี component ชื่อว่า Exchange
Exchange ทำการส่งข้อมูลที่ได้รับเข้ามาไปยัง (routing) queue ตามที่กำหนดในข้อมูล
ดังนั้นการส่งข้อมูลจะต้องทำการกำหนดค่าต่าง ๆ มาตามที่ต้องการ (Smart Consumer)
ส่วน Consumer ก็ทำตามข้อมูลที่ส่งเข้ามาก็พอ ไม่ต้องคิดมาก (Dumb consumer)
โดยรูปแบบการทำงานของ broker มีหลายรูปแบบดังนี้
จากรูปนั้น
Producer จะทำการส่งข้อมูลไปยัง Broker
จากนั้น Broker จะส่งข้อมูลไปยัง consumer ต่อไป
แต่ใน Broker นั้นจะมี component ชื่อว่า Exchange
Exchange ทำการส่งข้อมูลที่ได้รับเข้ามาไปยัง (routing) queue ตามที่กำหนดในข้อมูล
ดังนั้นการส่งข้อมูลจะต้องทำการกำหนดค่าต่าง ๆ มาตามที่ต้องการ (Smart Consumer)
ส่วน Consumer ก็ทำตามข้อมูลที่ส่งเข้ามาก็พอ ไม่ต้องคิดมาก (Dumb consumer)
โดยรูปแบบการทำงานของ broker มีหลายรูปแบบดังนี้
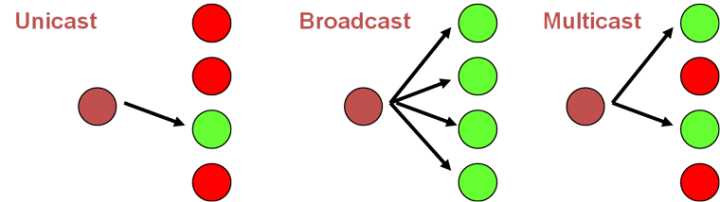

 หลังจากที่ใน
หลังจากที่ใน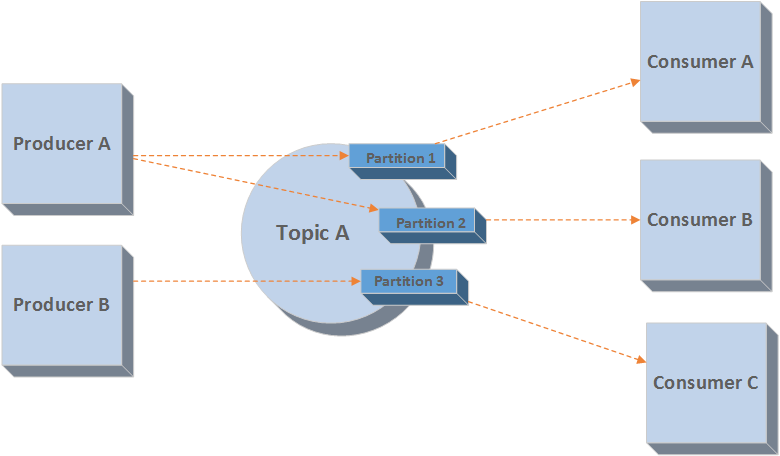
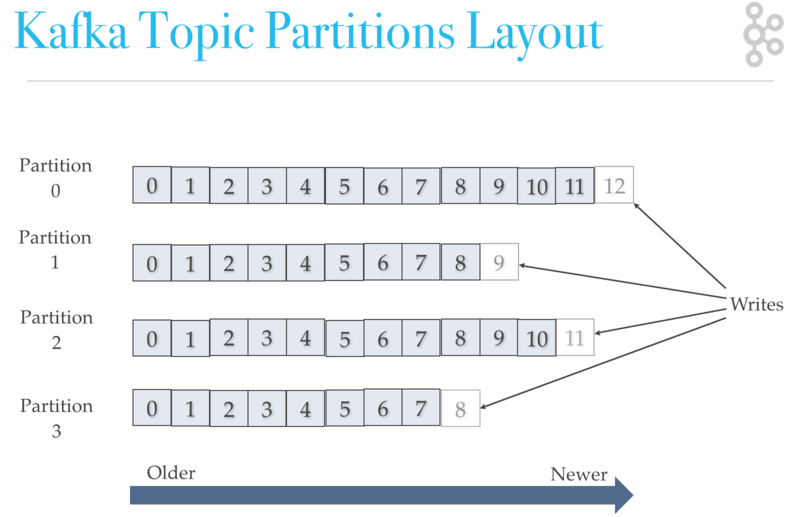 จากรูปในแต่ละ partition นั้นข้อมูลจะถูกเรียงลำดับเสมอ
จากรูปในแต่ละ partition นั้นข้อมูลจะถูกเรียงลำดับเสมอ
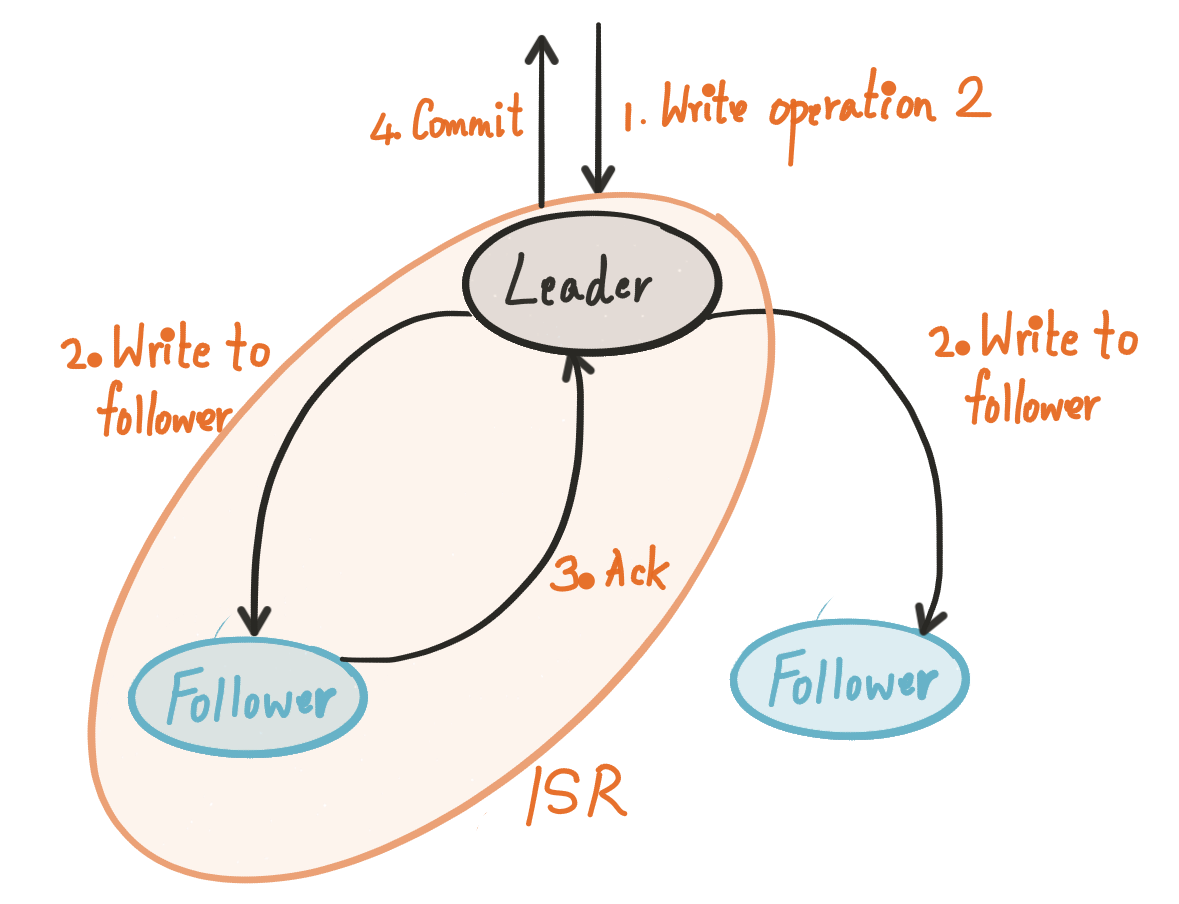
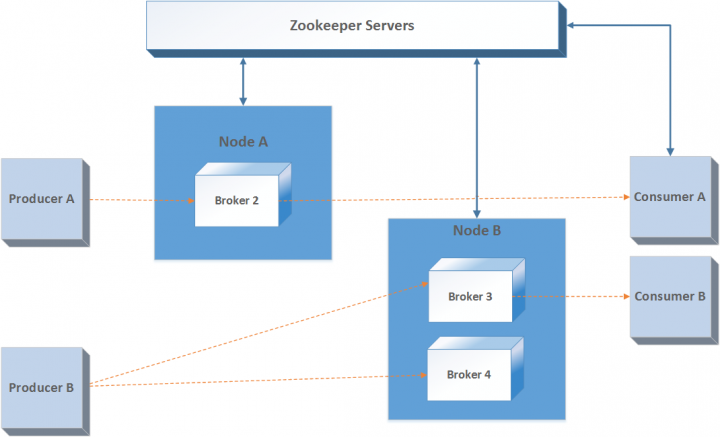 ยังไม่พอนะ แต่ละ partition ของแต่ละ topic ที่จัดเก็บใน Kafka broker หลักหรือเรียกว่า Leader
ทำหน้าจัดการการอ่านเขียนนั่นเอง
และจะมีการจัดเก็บไว้ใน Kafka broker ที่มีสถานะเป็น Follower ด้วย
ซึ่งจะทำ replicate ข้อมูลมาเก็บไว้ เป็นการ backup นั่นเอง
ตรงนี้ขึ้นอยู่กับการ configuration ในส่วนของ relication factor
Follower นั้นจะถูกเลือกมาเป็น Leader เมื่อ Leader เกิด fail ขึ้นมา
คำถามคือใครเป็นคนเลือก Leader ?
ตอบง่าย ๆ คือ Zookeeper ไงละ
ยังไม่พอนะ แต่ละ partition ของแต่ละ topic ที่จัดเก็บใน Kafka broker หลักหรือเรียกว่า Leader
ทำหน้าจัดการการอ่านเขียนนั่นเอง
และจะมีการจัดเก็บไว้ใน Kafka broker ที่มีสถานะเป็น Follower ด้วย
ซึ่งจะทำ replicate ข้อมูลมาเก็บไว้ เป็นการ backup นั่นเอง
ตรงนี้ขึ้นอยู่กับการ configuration ในส่วนของ relication factor
Follower นั้นจะถูกเลือกมาเป็น Leader เมื่อ Leader เกิด fail ขึ้นมา
คำถามคือใครเป็นคนเลือก Leader ?
ตอบง่าย ๆ คือ Zookeeper ไงละ

 ตอนนี้ Go 1.11 ได้ออก RC2 มาแล้ว นั่นหมายความว่าตัว final ใกล้เข้ามาทุกที
ดังนั้นมาลองสร้าง module ด้วยภาษา Go กันหน่อย
ซึ่งเป็น feature ใหม่ที่น่าสนใจ
โดยใน blog นี้จะมีเรื่องต่าง ๆ ดังนี้
ตอนนี้ Go 1.11 ได้ออก RC2 มาแล้ว นั่นหมายความว่าตัว final ใกล้เข้ามาทุกที
ดังนั้นมาลองสร้าง module ด้วยภาษา Go กันหน่อย
ซึ่งเป็น feature ใหม่ที่น่าสนใจ
โดยใน blog นี้จะมีเรื่องต่าง ๆ ดังนี้

 ช่วงนี้พูดถึง
ช่วงนี้พูดถึง  จะพบว่ามีส่วนการทำงานเพียบเลย
แต่สิ่งแรกที่อยู่ใกล้แต่ละ service มากที่สุดคือ Proxy หรือ Envoy proxy หรือ Sidecar proxy
ทำให้ Istio สามารถจัดการสิ่งต่าง ๆ ตามด้านบนได้ง่าย
ที่สำคัญสามารถกำหนด rule และ policy ต่าง ๆ ได้อีกด้วย
โดยไม่ต้องไปทำการแก้ไข code
เช่น
จะพบว่ามีส่วนการทำงานเพียบเลย
แต่สิ่งแรกที่อยู่ใกล้แต่ละ service มากที่สุดคือ Proxy หรือ Envoy proxy หรือ Sidecar proxy
ทำให้ Istio สามารถจัดการสิ่งต่าง ๆ ตามด้านบนได้ง่าย
ที่สำคัญสามารถกำหนด rule และ policy ต่าง ๆ ได้อีกด้วย
โดยไม่ต้องไปทำการแก้ไข code
เช่น


 จาก session Architecture Components in Real Life (Android) ในงาน
จาก session Architecture Components in Real Life (Android) ในงาน 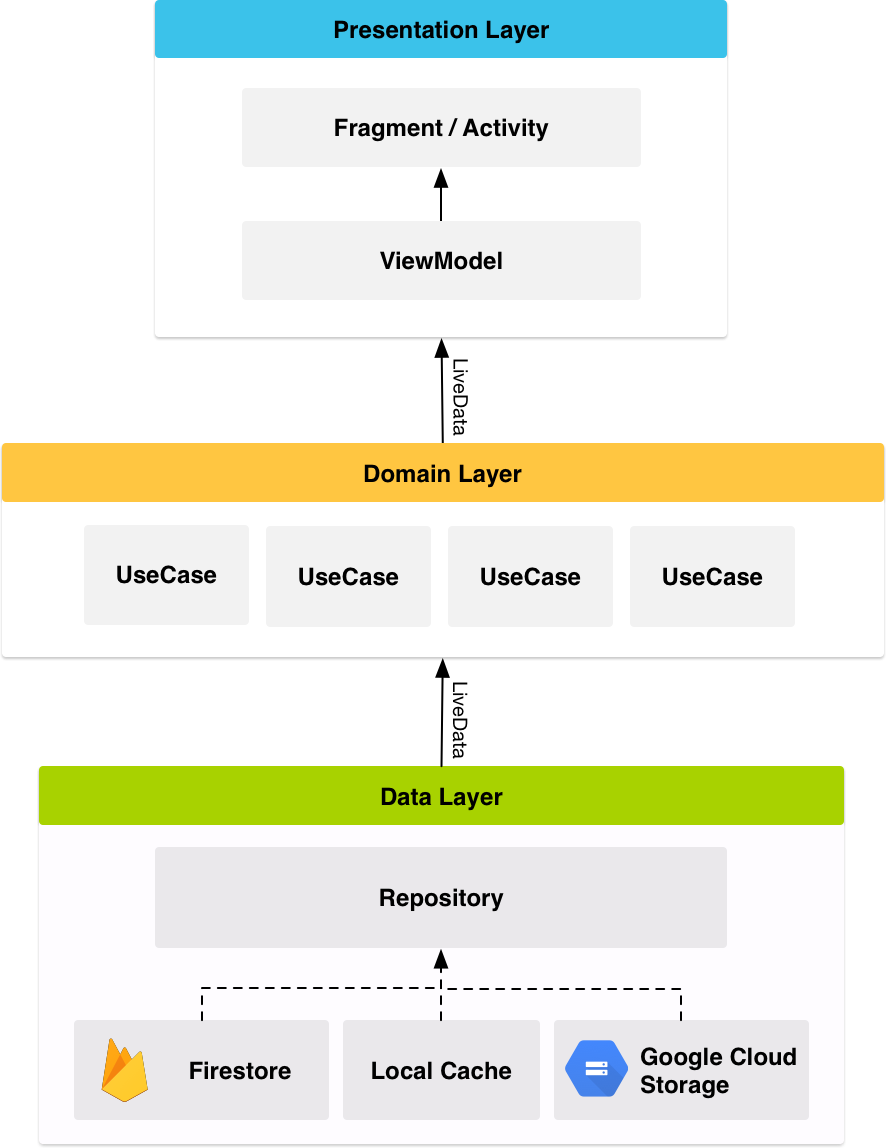 จากรูปโครงสร้างของ app ประกอบไปด้วย
จากรูปโครงสร้างของ app ประกอบไปด้วย
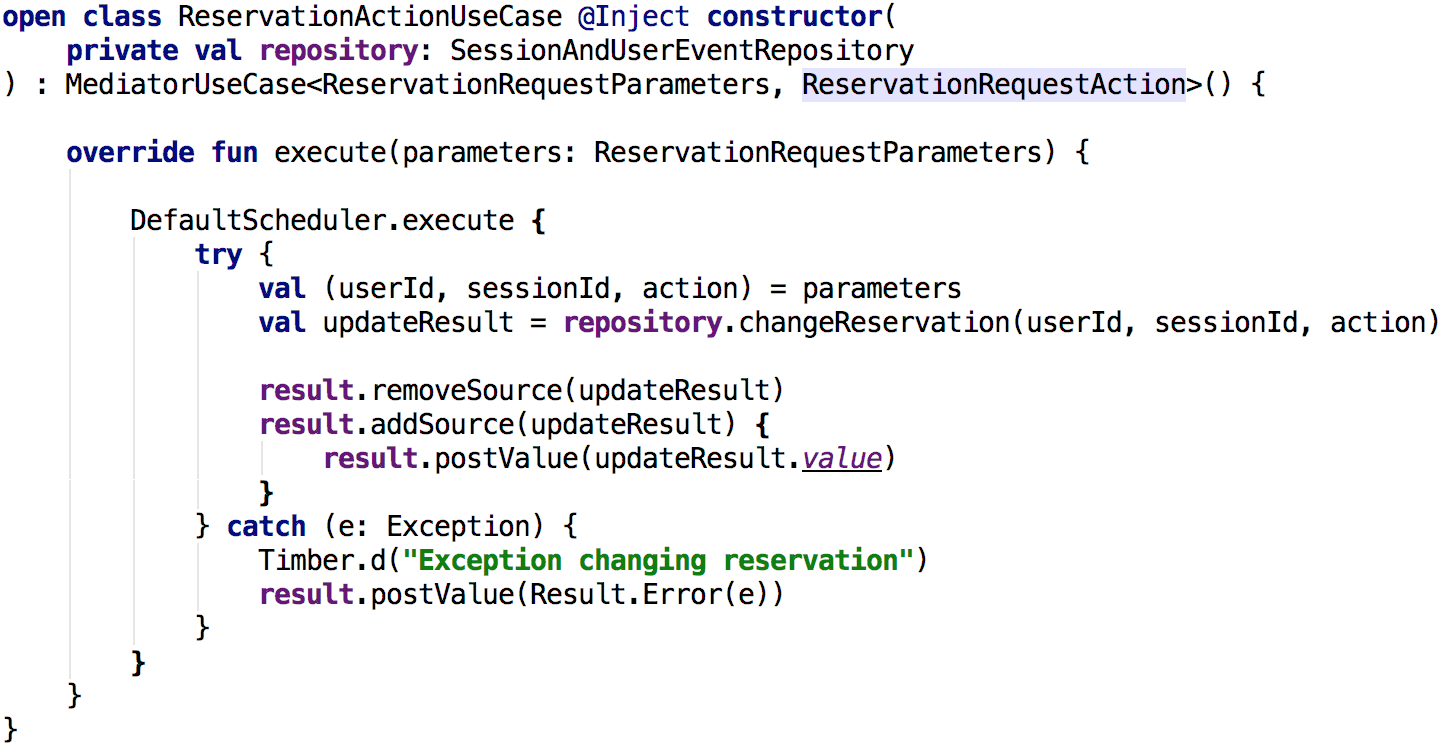
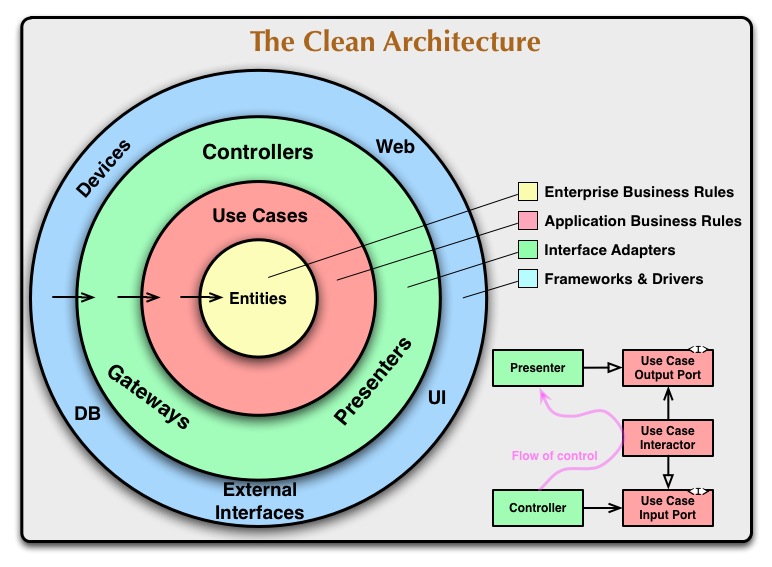 ยกตัวอย่างของ Use Case ที่อยู่ใน module shared
ยกตัวอย่างของ Use Case ที่อยู่ใน module shared


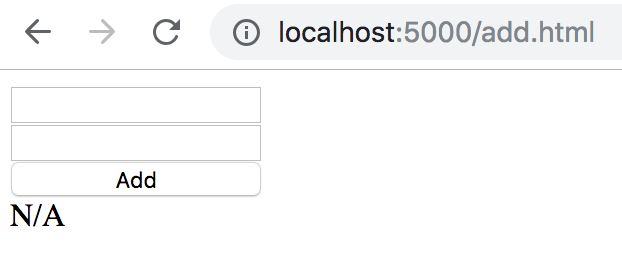
 ทำการ compile ได้เลย
[code]
$GOARCH=wasm GOOS=js go build -o add.wasm add.go
[/code]
ทำการ compile ได้เลย
[code]
$GOARCH=wasm GOOS=js go build -o add.wasm add.go
[/code]

 ในการทดสอบระบบ web application ผ่าน Robotframework ด้วย Library ชื่อว่า
ในการทดสอบระบบ web application ผ่าน Robotframework ด้วย Library ชื่อว่า 
 หลังจากอธิบายเกี่ยวกับ
หลังจากอธิบายเกี่ยวกับ 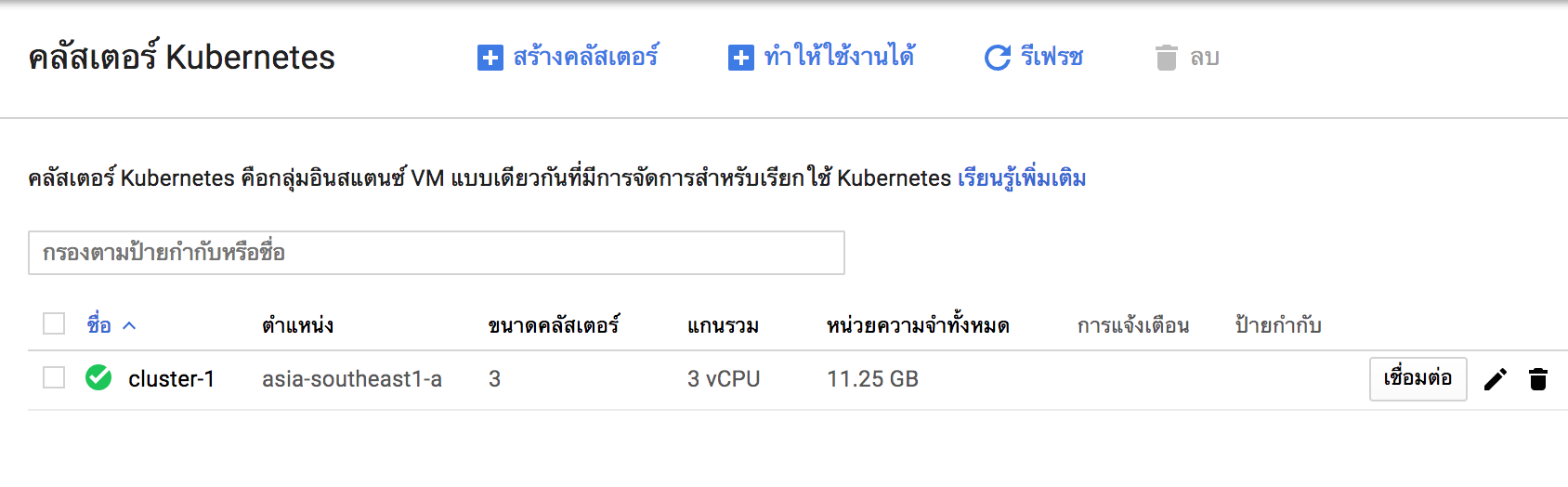
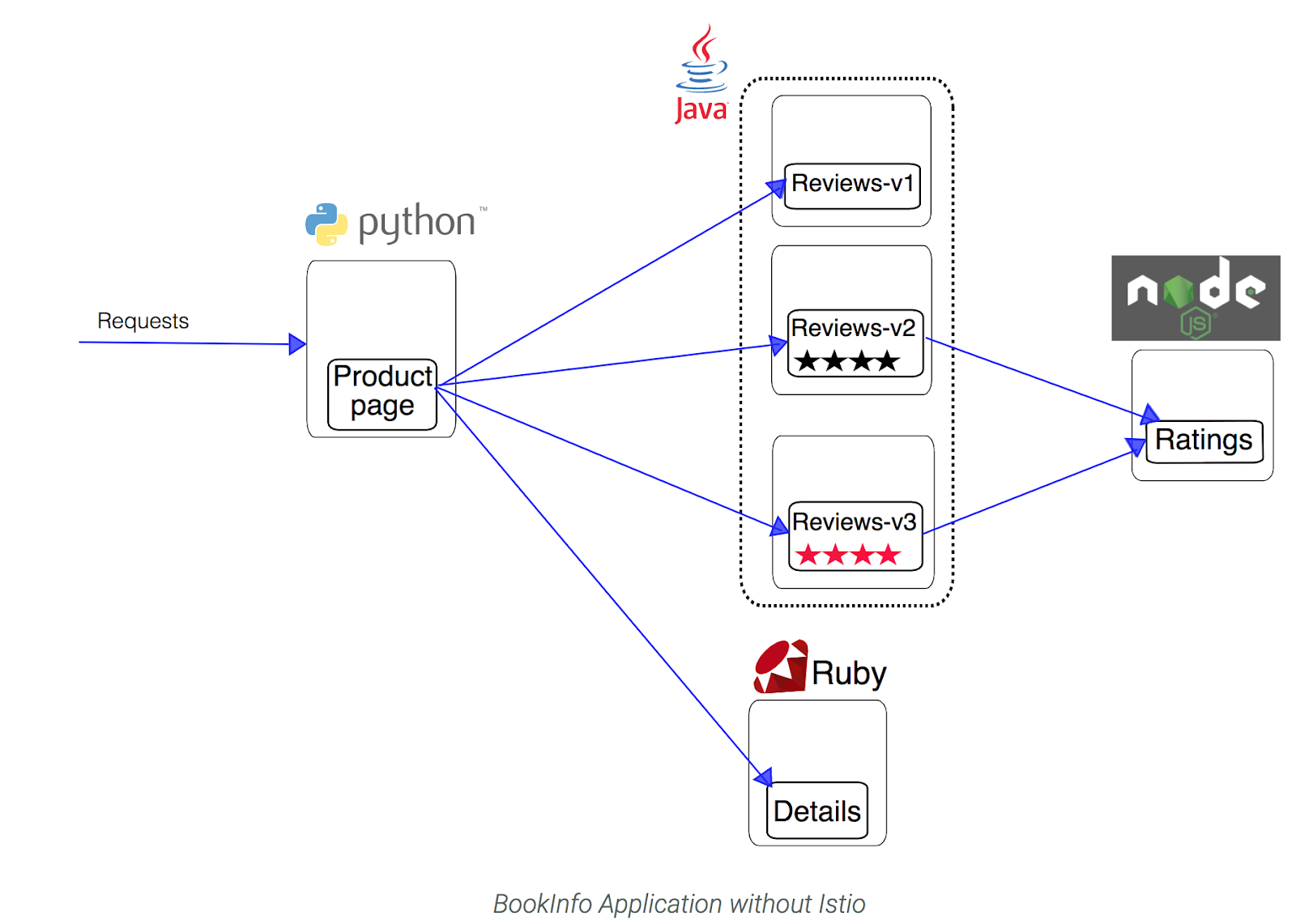 โดยที่ configuration อยู่ในไฟล์ samples/bookinfo/platform/kube/bookinfo.yaml
มันคือ Kubernetes configuration นั่นเอง
ถ้าเราทำการ deploy แบบปกติผ่าน kubectl
ก็จะได้ Pods และ Services ต่าง ๆ เป็นปกติ
แน่นอนว่า ไม่มีการใช้ความสามารถของ Istio เลย เช่น Envoy sidecar
เนื่องจากค่า default นั้นจะปิดไว้ ดังนั้นเปิดซะ
ทำได้ดังนี้
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="4.txt"]
ทำการ deploy ระบบตัวอย่างกันเลย รออะไร
จะใช้เวลารอให้สร้าง Pods กันนานหน่อยนะ
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="5.txt"]
และให้ลองสังเกตุว่า
ในแต่ละ Pods จะมี 2 container
นั่นหมายความว่า Istio จะทำการสร้าง Envoy sidecar ให้เรียบร้อย
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="6.txt"]
โดยที่ configuration อยู่ในไฟล์ samples/bookinfo/platform/kube/bookinfo.yaml
มันคือ Kubernetes configuration นั่นเอง
ถ้าเราทำการ deploy แบบปกติผ่าน kubectl
ก็จะได้ Pods และ Services ต่าง ๆ เป็นปกติ
แน่นอนว่า ไม่มีการใช้ความสามารถของ Istio เลย เช่น Envoy sidecar
เนื่องจากค่า default นั้นจะปิดไว้ ดังนั้นเปิดซะ
ทำได้ดังนี้
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="4.txt"]
ทำการ deploy ระบบตัวอย่างกันเลย รออะไร
จะใช้เวลารอให้สร้าง Pods กันนานหน่อยนะ
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="5.txt"]
และให้ลองสังเกตุว่า
ในแต่ละ Pods จะมี 2 container
นั่นหมายความว่า Istio จะทำการสร้าง Envoy sidecar ให้เรียบร้อย
[gist id="e8e1d02bb50fdc15aca141a460a14e99" file="6.txt"]
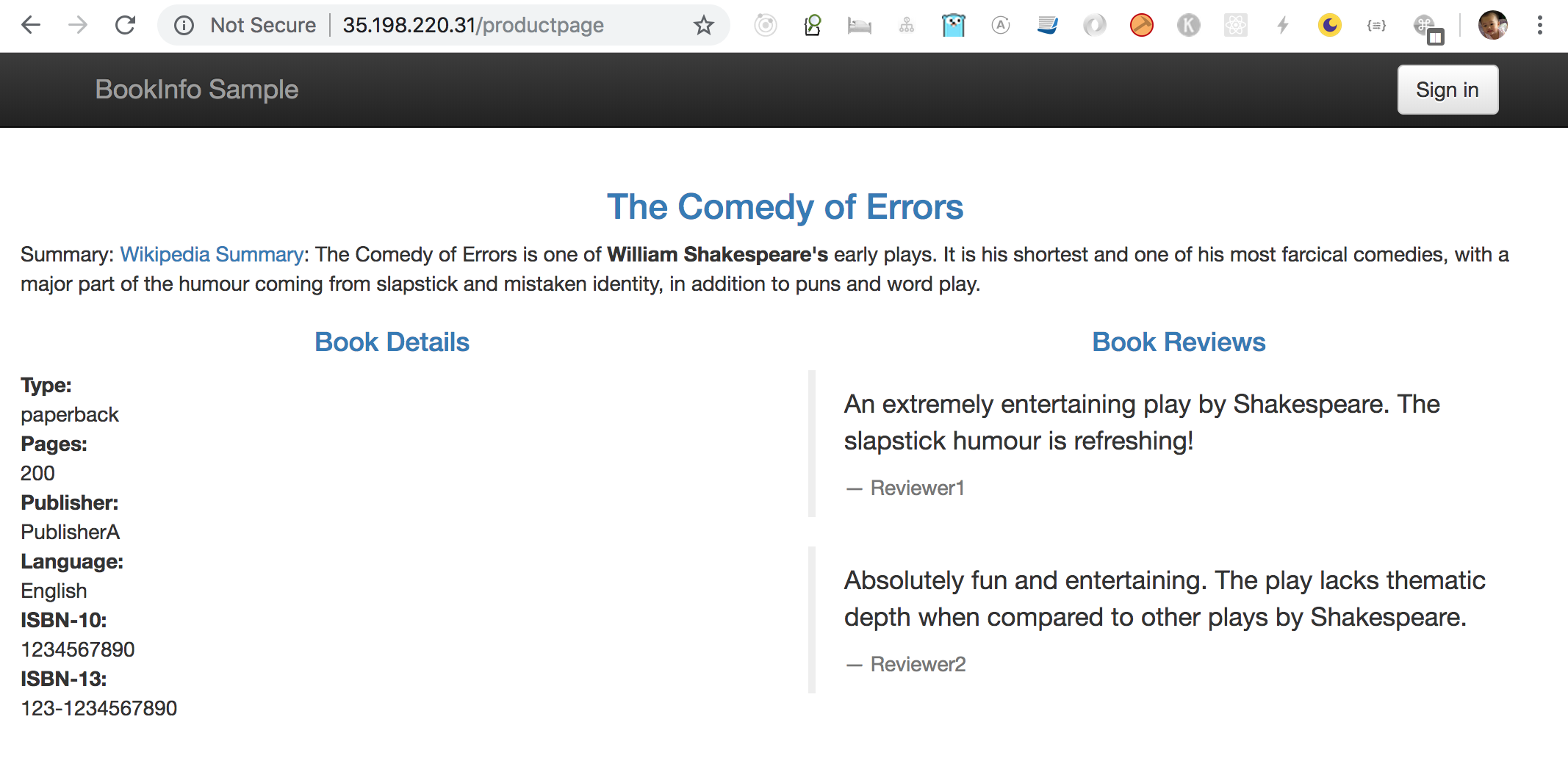 แค่ติดตั้งก็เหนื่อยใช้ได้เลยนะ
ไว้มาดูความสามารถอื่น ๆ กันต่อไป เช่น Routing, Telemetry และ Authentication/Authorization เป็นต้น
น่าจะมีประโยชน์ต่อการพัฒนามากยิ่งขึ้น
ขอให้สนุกกับการ coding ครับ
แค่ติดตั้งก็เหนื่อยใช้ได้เลยนะ
ไว้มาดูความสามารถอื่น ๆ กันต่อไป เช่น Routing, Telemetry และ Authentication/Authorization เป็นต้น
น่าจะมีประโยชน์ต่อการพัฒนามากยิ่งขึ้น
ขอให้สนุกกับการ coding ครับ

 ช่วงวันหยุดหยิบหนังสือ
ช่วงวันหยุดหยิบหนังสือ 

 มี
มี
 ช่วงหลังมีการพูดถึง
ช่วงหลังมีการพูดถึง 
 หลังจากที่ลองพัฒนา
หลังจากที่ลองพัฒนา
 มาทำความรู้จักกับ 4 ข้อสุดท้ายสำหรับ
มาทำความรู้จักกับ 4 ข้อสุดท้ายสำหรับ 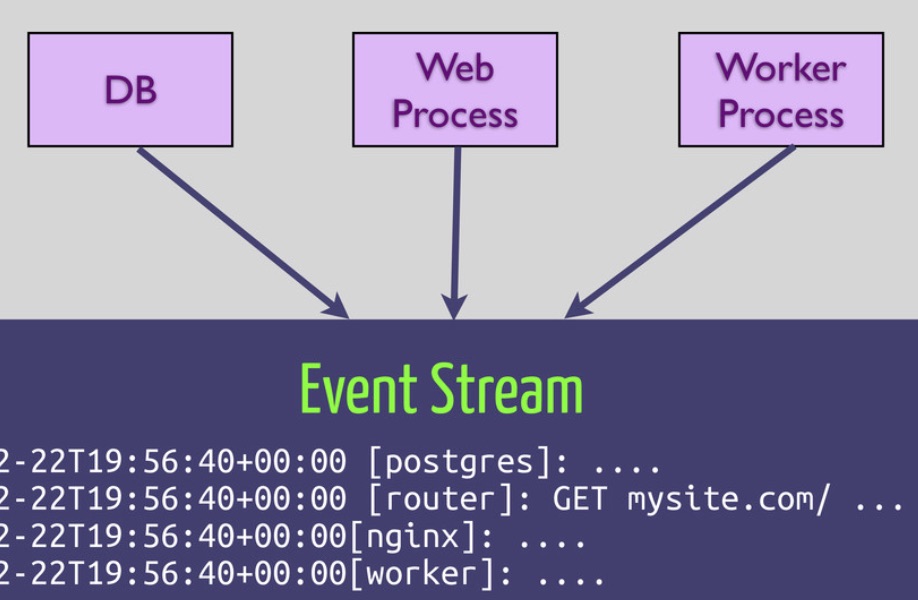

 Code ที่ดีนั้นอาจจะไม่ได้สร้างหรือส่งมอบ product ที่ดีเสมอไป
แต่ code ที่ดีมันกลับทำให้คนที่ดูแลง่าย และ มีชีวิตที่สงบสุขมากขึ้น
คำว่า Code ที่ดีนั้นมีหลายรูปบบ หลายความหมาย
ตามแต่ประสบการณ์ ความรู้ และ สิ่งแวดล้อม
แต่มุมมองที่น่าสนใจคือ
Code ที่ดีมันน่าจะต้องเพิ่มหรือปรับปรุง productivity ให้กับเราสิ
จากที่ได้พูดคุยกับเหล่านักพัฒนาก็แนะนำดังนี้
Code ที่ดีนั้นอาจจะไม่ได้สร้างหรือส่งมอบ product ที่ดีเสมอไป
แต่ code ที่ดีมันกลับทำให้คนที่ดูแลง่าย และ มีชีวิตที่สงบสุขมากขึ้น
คำว่า Code ที่ดีนั้นมีหลายรูปบบ หลายความหมาย
ตามแต่ประสบการณ์ ความรู้ และ สิ่งแวดล้อม
แต่มุมมองที่น่าสนใจคือ
Code ที่ดีมันน่าจะต้องเพิ่มหรือปรับปรุง productivity ให้กับเราสิ
จากที่ได้พูดคุยกับเหล่านักพัฒนาก็แนะนำดังนี้


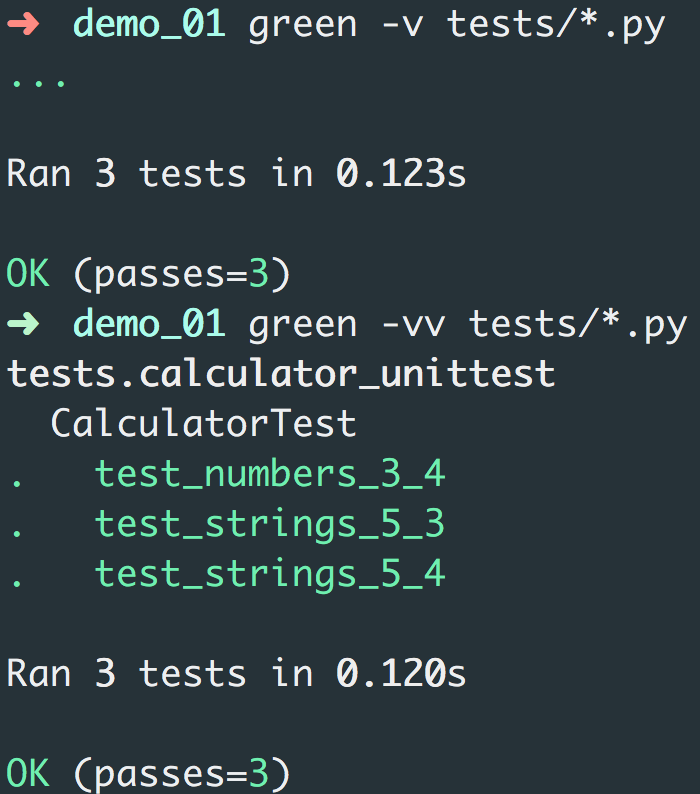

 ไปฟังเรื่อง Goroutine, Channel และ Parallelism จากงาน
ไปฟังเรื่อง Goroutine, Channel และ Parallelism จากงาน 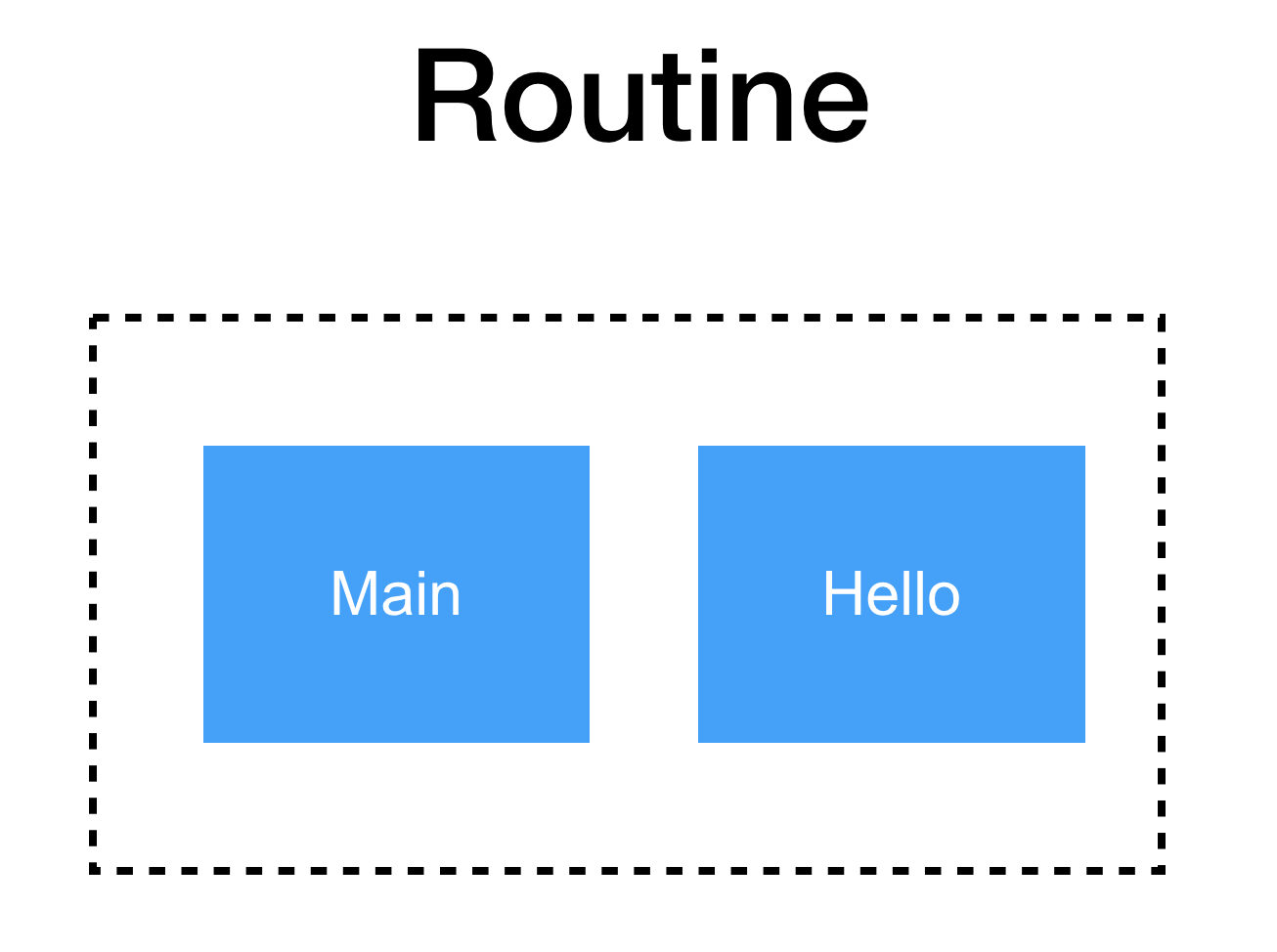 โดยที่จาก code นั้น main() ไม่สามารถเข้าถึงผลการทำงานจาก hello() ได้เลย
และทำการ hack ในส่วนของ main นิดหน่อย เพื่อให้รอการทำงานของ hello()
ด้วยการให้ main() รอด้วยการ sleep
เพราะว่าทั้งสองส่วนทำงานแยกกันอย่างชัดเจน
โดยที่จาก code นั้น main() ไม่สามารถเข้าถึงผลการทำงานจาก hello() ได้เลย
และทำการ hack ในส่วนของ main นิดหน่อย เพื่อให้รอการทำงานของ hello()
ด้วยการให้ main() รอด้วยการ sleep
เพราะว่าทั้งสองส่วนทำงานแยกกันอย่างชัดเจน
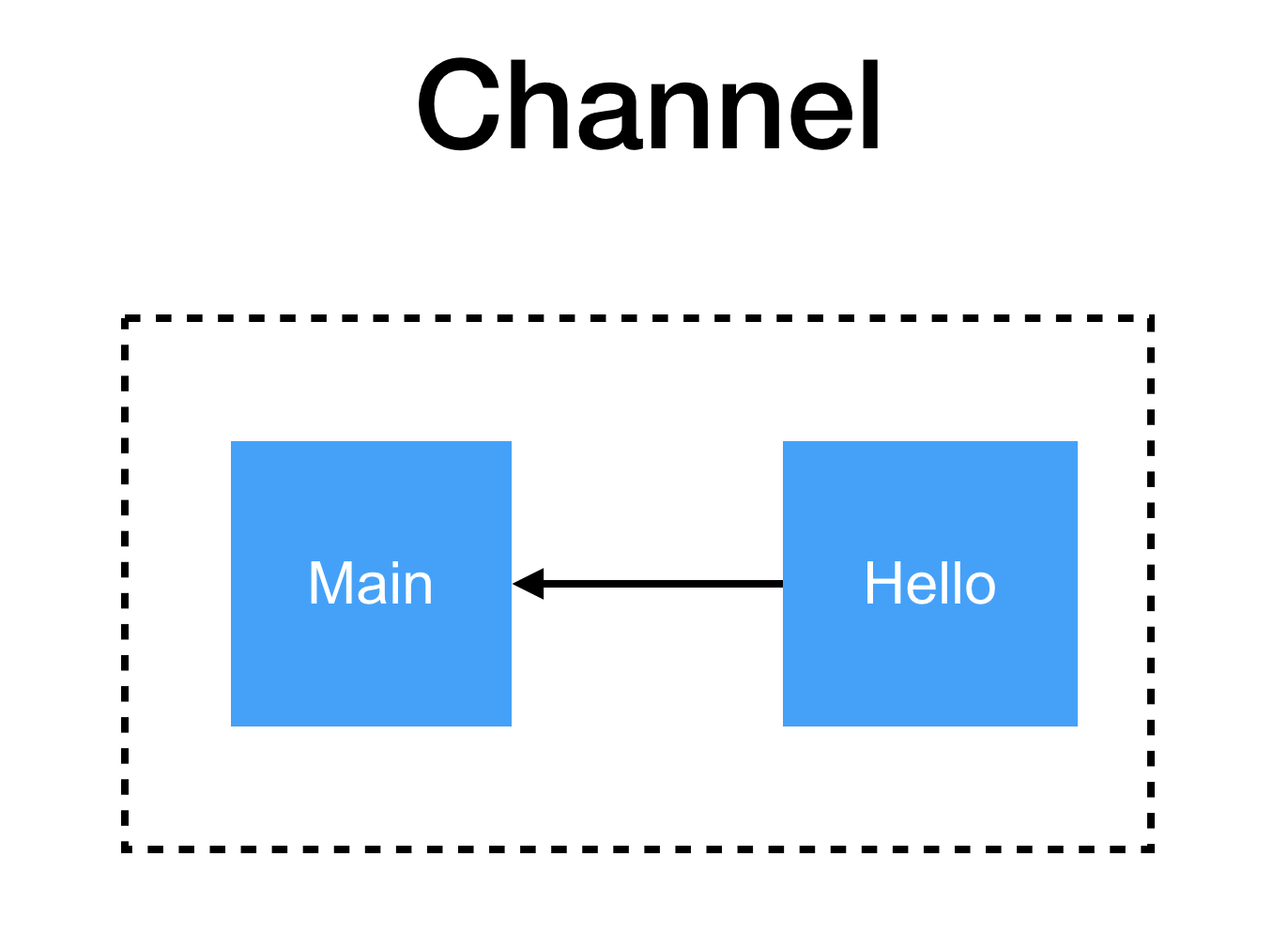 เขียน code ได้ดังนี้
[gist id="a6ee1c4f93dea97af1590ec91406922b" file="demo2.go"]
ทำการ run ดังนี้
[gist id="a6ee1c4f93dea97af1590ec91406922b" file="2.txt"]
คำอธิบาย
ทำการสร้าง channel ชื่อว่า result โดยชนิดข้อมูลที่ส่งใน channel คือ string
จากนั้นทำการส่งไปยัง hello()
ใน hello() จะพบว่า ผลลัพธ์ของการทำงานจะถูกส่งเข้าไปยัง channel ที่ส่งมา
สุดท้ายใน main() จะรอผลการทำงานจาก channel ด้วย <-result
ทำให้ไม่ต้องใช้ sleep() รออีกต่อไป
ดังนั้นถ้าจะเขียนรูปให้ถูกมากยิ่งขึ้นจะเป็นดังรูป
ซึ่งเป็นการทำงานแบบ unidirection หรือ ทางเดียวเท่านั้น
เขียน code ได้ดังนี้
[gist id="a6ee1c4f93dea97af1590ec91406922b" file="demo2.go"]
ทำการ run ดังนี้
[gist id="a6ee1c4f93dea97af1590ec91406922b" file="2.txt"]
คำอธิบาย
ทำการสร้าง channel ชื่อว่า result โดยชนิดข้อมูลที่ส่งใน channel คือ string
จากนั้นทำการส่งไปยัง hello()
ใน hello() จะพบว่า ผลลัพธ์ของการทำงานจะถูกส่งเข้าไปยัง channel ที่ส่งมา
สุดท้ายใน main() จะรอผลการทำงานจาก channel ด้วย <-result
ทำให้ไม่ต้องใช้ sleep() รออีกต่อไป
ดังนั้นถ้าจะเขียนรูปให้ถูกมากยิ่งขึ้นจะเป็นดังรูป
ซึ่งเป็นการทำงานแบบ unidirection หรือ ทางเดียวเท่านั้น
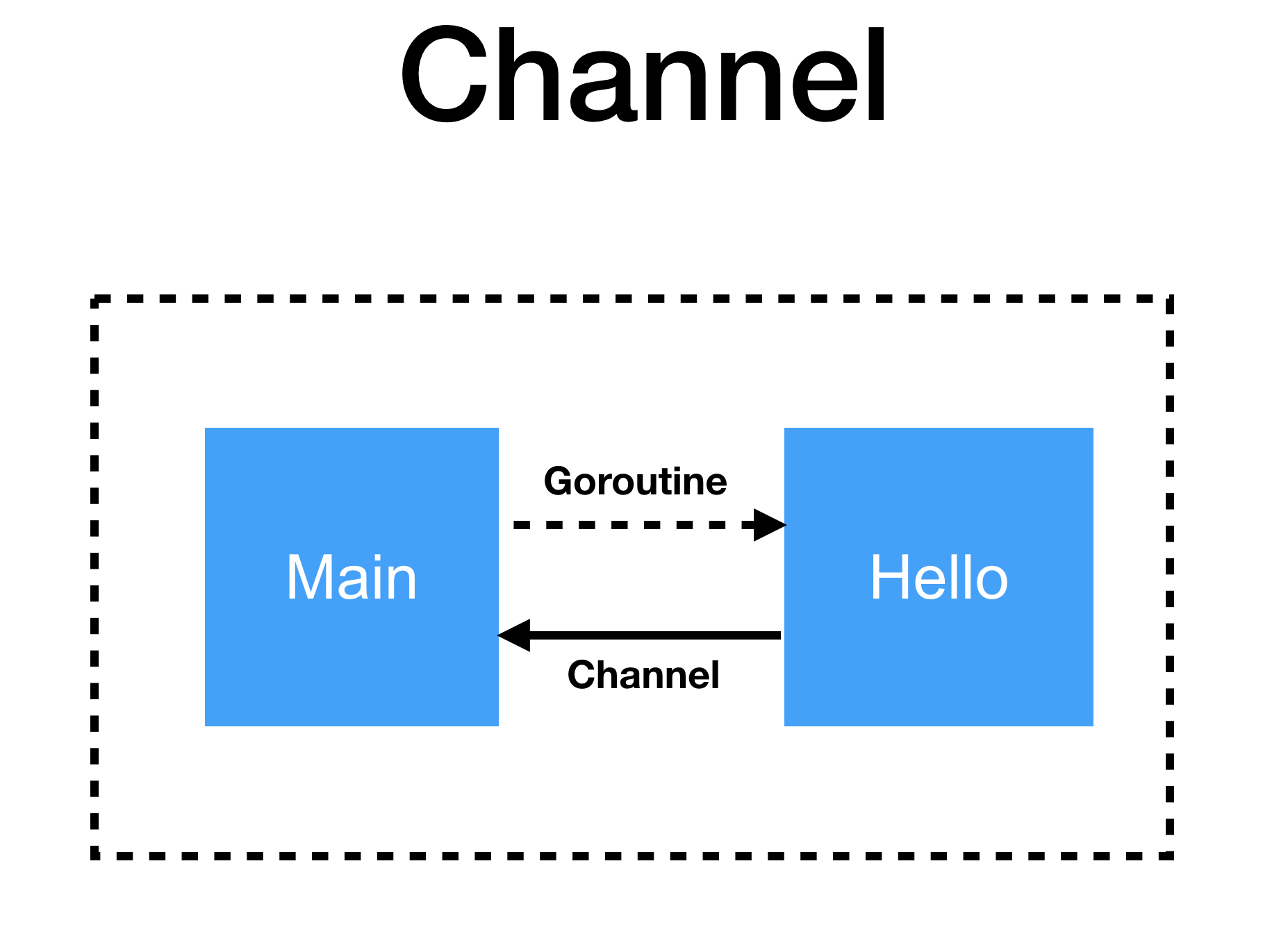
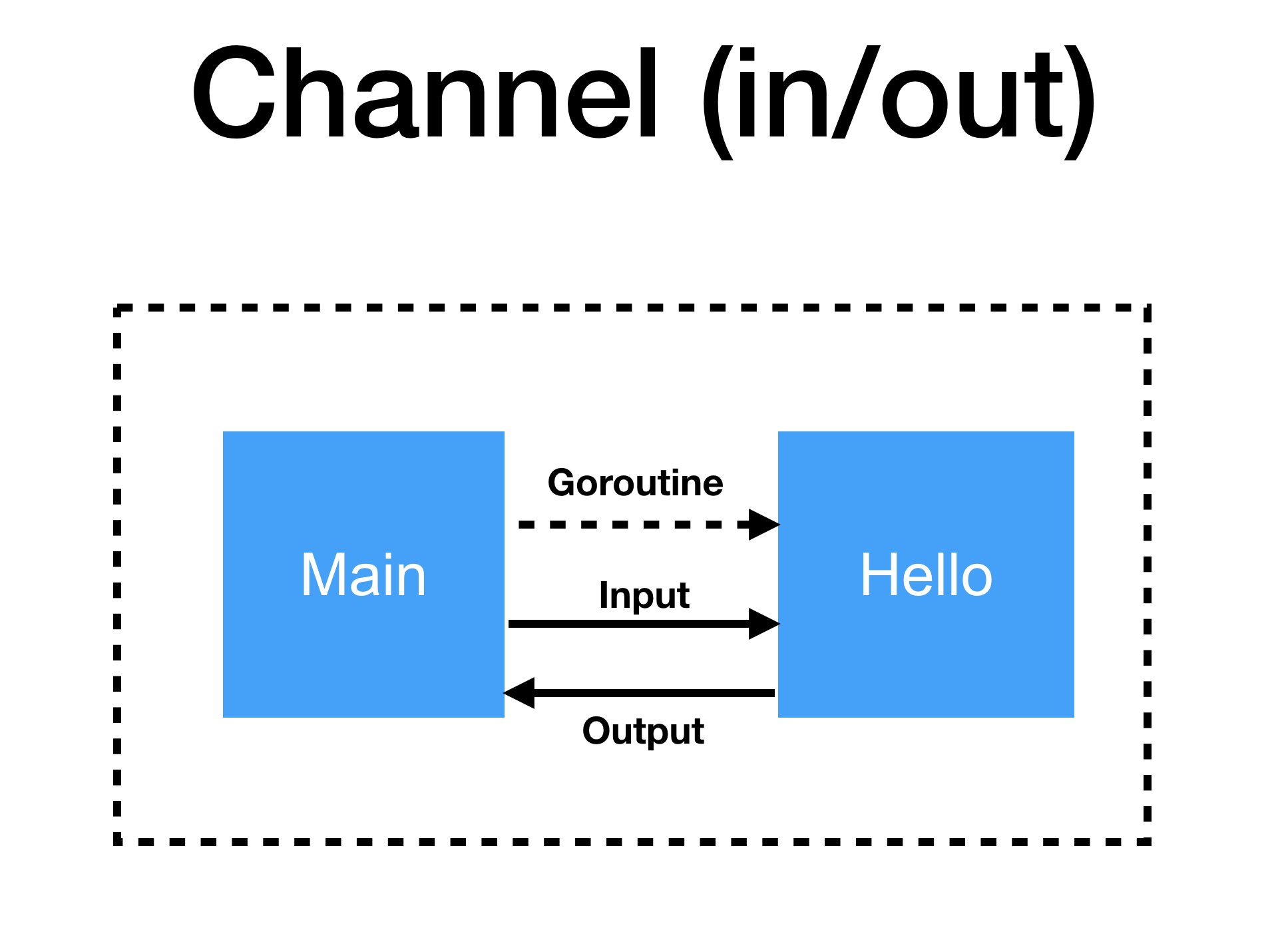 สังเกตุว่าใน function hello() นั้นจะมี channel สองตัวที่ต่างกัน
สังเกตุว่าใน function hello() นั้นจะมี channel สองตัวที่ต่างกัน



 มาร่วมงาน
มาร่วมงาน 

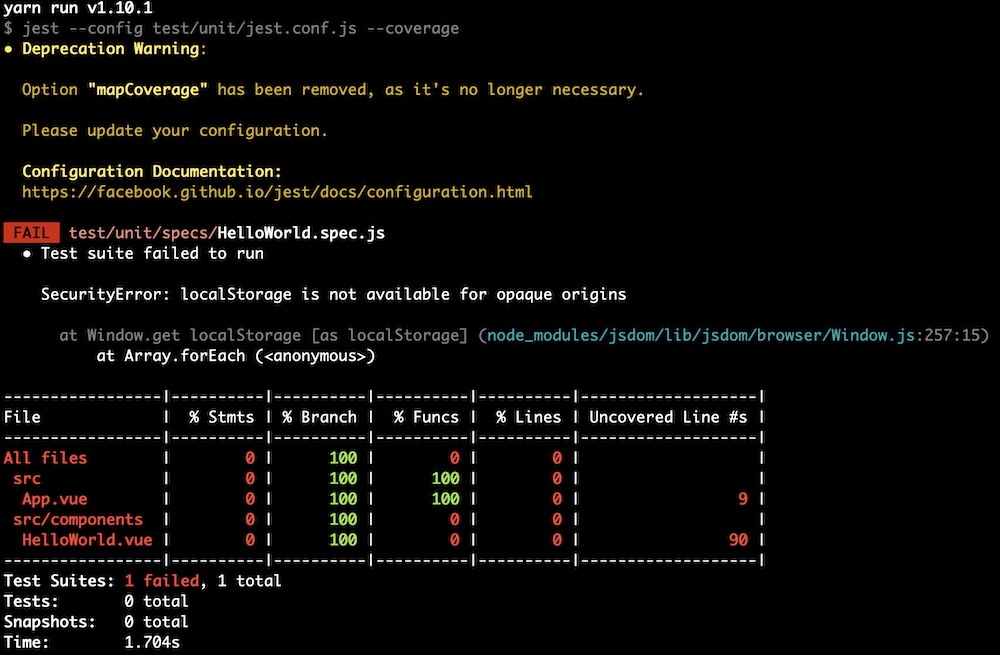
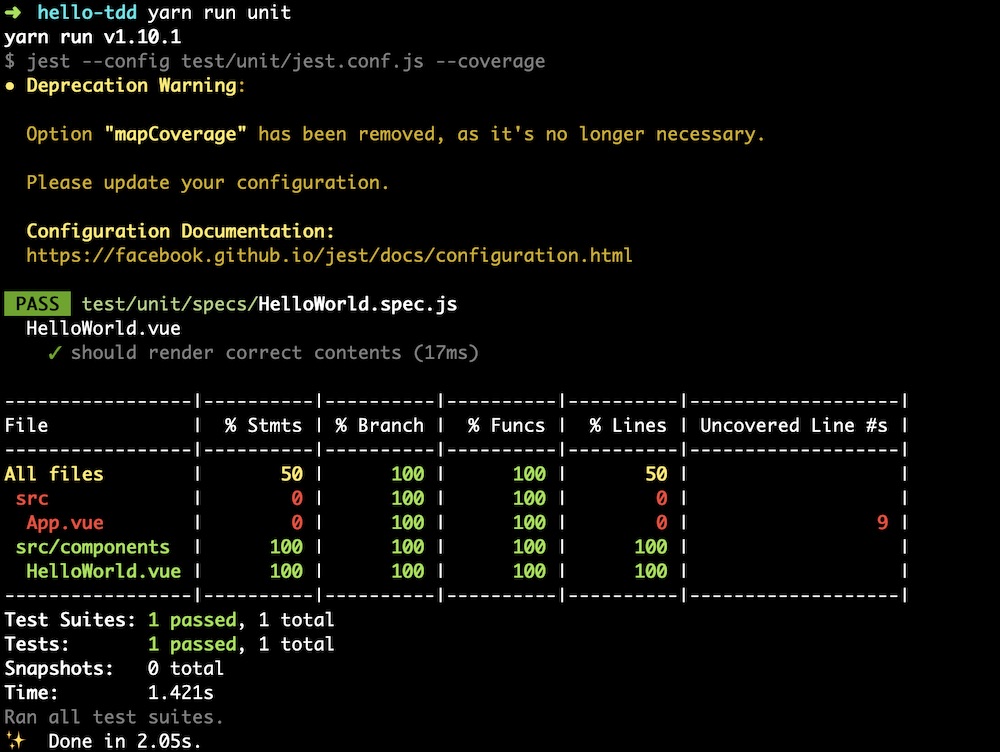
 มาลอง run unit test กันหน่อย
[code]
$yarn run unit
[/code]
ผลที่ได้คือ Error สิครับ ไม่พอ warning เกี่ยวกับ Jest config อีก
สงสัยไม่ค่อยมีใครใช้ Jest ไหมหว่า
ผลการทำงานเป็นดังนี้
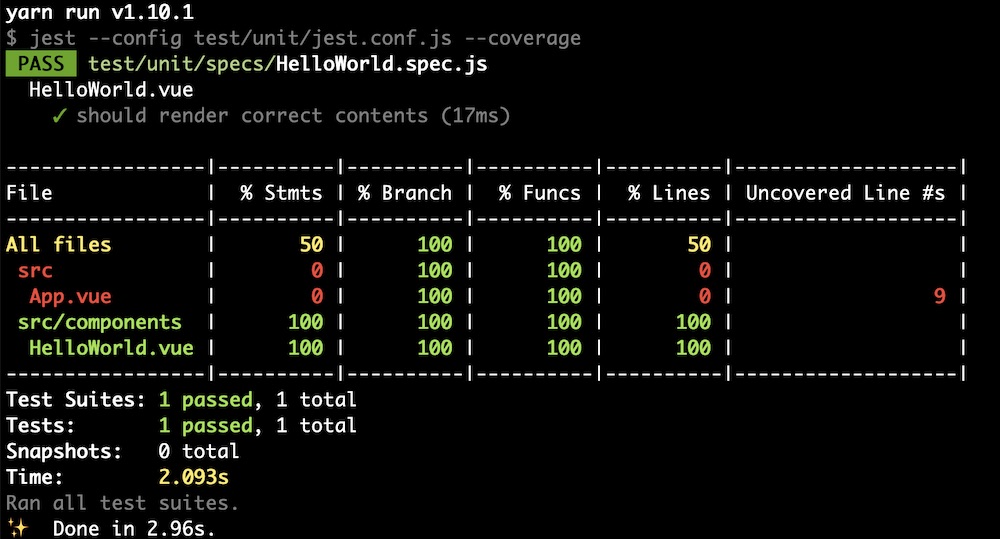
มาลอง run unit test กันหน่อย
[code]
$yarn run unit
[/code]
ผลที่ได้คือ Error สิครับ ไม่พอ warning เกี่ยวกับ Jest config อีก
สงสัยไม่ค่อยมีใครใช้ Jest ไหมหว่า
ผลการทำงานเป็นดังนี้

 จากบทความเรื่อง
จากบทความเรื่อง 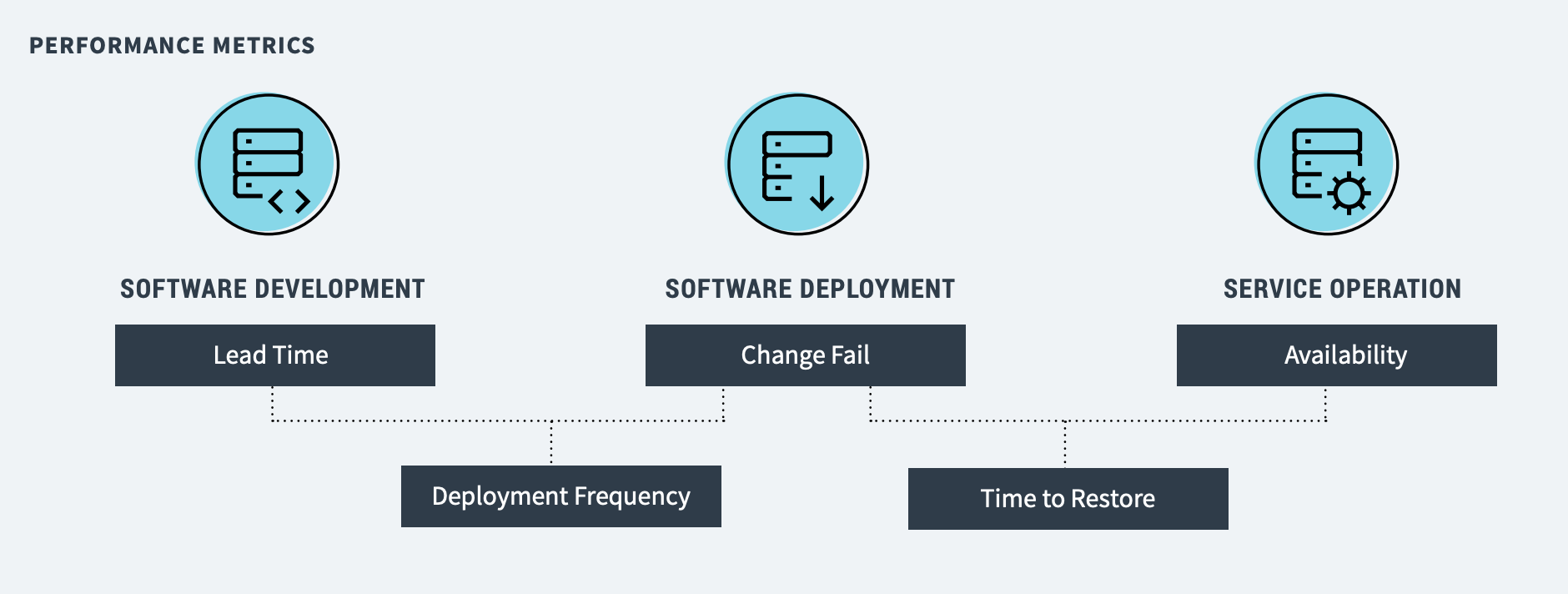 ต่อมาสิ่งที่สำคัญมาก ๆ คือ Focus outcome, not output
นั่นคือให้สนใจคุณค่าที่ได้ส่งมอบออกไปให้ทาง business และลูกค้า
มากกว่าจะให้ความสนใจไปกับปริมาณของสิ่งที่ทำ
อีกสิ่งที่สำคัญคือ ความผิดพลาดมันเกิดขึ้นได้เสมอ
แต่เรากลับพบว่า
ถ้าเมื่อเกิดข้อผิดพลาดขึ้นมาแล้ว
มักจะส่งผลให้เราเพิ่มขั้นตอนการทำงานมากขึ้น
มักจะส่งผลให้เรา deploy ได้ช้าลง
มักจะส่งผลให้เรา deploy ได้น้อยลง
เพราะว่าเราต้องทำการตรวจสอบและทดสอบ เพื่อความถูกต้องมากยิ่งขึ้น
จากผลการสำรวจพบว่า
ระบบที่มีความผิดพลาดสูงนั้น มักจะมาจาก
การ deploy แต่ละครั้งมีขนาดที่ใหญ่
และไม่สามารถ deploy ได้บ่อย
แต่องค์กรที่มีการนำ DevOps ไปใช้แล้วได้ผลเชิงบวกนั้น
แต่ละครั้งในการ deploy จะมีขนาดไม่ใหญ่
สามารถ deploy ได้ตามความต้องการ
ในแต่ละวันสามารถ deploy ได้หลายครั้ง
ผลที่ตามมาคือ ข้อผิดพลาดจากการ deploy ก็น้อยลงอีกด้วย
เมื่อเปรียบเทียบกับกลุ่มที่ทำการ deploy ประมาณสัปดาห์หรือเดือนละครั้ง
ตรงนี้น่าจะทำให้เห็นแนวทางดี ๆ บ้างนะ
ต่อมาสิ่งที่สำคัญมาก ๆ คือ Focus outcome, not output
นั่นคือให้สนใจคุณค่าที่ได้ส่งมอบออกไปให้ทาง business และลูกค้า
มากกว่าจะให้ความสนใจไปกับปริมาณของสิ่งที่ทำ
อีกสิ่งที่สำคัญคือ ความผิดพลาดมันเกิดขึ้นได้เสมอ
แต่เรากลับพบว่า
ถ้าเมื่อเกิดข้อผิดพลาดขึ้นมาแล้ว
มักจะส่งผลให้เราเพิ่มขั้นตอนการทำงานมากขึ้น
มักจะส่งผลให้เรา deploy ได้ช้าลง
มักจะส่งผลให้เรา deploy ได้น้อยลง
เพราะว่าเราต้องทำการตรวจสอบและทดสอบ เพื่อความถูกต้องมากยิ่งขึ้น
จากผลการสำรวจพบว่า
ระบบที่มีความผิดพลาดสูงนั้น มักจะมาจาก
การ deploy แต่ละครั้งมีขนาดที่ใหญ่
และไม่สามารถ deploy ได้บ่อย
แต่องค์กรที่มีการนำ DevOps ไปใช้แล้วได้ผลเชิงบวกนั้น
แต่ละครั้งในการ deploy จะมีขนาดไม่ใหญ่
สามารถ deploy ได้ตามความต้องการ
ในแต่ละวันสามารถ deploy ได้หลายครั้ง
ผลที่ตามมาคือ ข้อผิดพลาดจากการ deploy ก็น้อยลงอีกด้วย
เมื่อเปรียบเทียบกับกลุ่มที่ทำการ deploy ประมาณสัปดาห์หรือเดือนละครั้ง
ตรงนี้น่าจะทำให้เห็นแนวทางดี ๆ บ้างนะ