![]()
![]()
ช่วงนี้ลองศึกษาภาษาโปรแกรมใหม่ ๆ เล่นดูบ้าง หนึ่งในนั้นคือ ภาษา
Elm
ซึ่งมีความสามารถที่น่าสนใจ เช่น
- JavaScript Interop
- No runtime exception (อันนี้น่าสนใจมาก ๆ)
- Great performance
- Enforced somatic versioning
ดังนั้นลองมาเรียนรู้ภาษา Elm ด้วยแนวทาง TDD กันหน่อยดีกว่า
เริ่มต้นด้วยการติดตั้ง
สามารถทำการติดตั้งง่าย ๆ แต่ละ OS ได้ที่
Install Elm
หลังจากที่ติดตั้งแล้ว จะมีชุดคำสั่งให้ใช้ดังนี้
- elm-repl (Read Eval Print Loop)
- elm-reactor
- elm-make
- elm-package
เป้าหมายของการเรียนรู้
ประกอบไปด้วย
สร้าง project อย่างไร ?
จะพัฒนาระบบด้วยการเขียน Test ทำอย่างไร ?
โดยใช้โจทย์สุด classic คือ
FizzBuzz
การทดสอบจะใช้ package ชื่อว่า
elm-test
เพราะว่า มันสวยและง่ายดี ที่สำคัญชอบรูปแบบการใช้งานนั่นเอง
มาเริ่มกันเลย
ขั้นตอนที่ 1 สร้าง project กัน
ในการสร้าง project ด้วยคำสั่ง
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step01.txt"]
ผลที่ได้คือ โครงสร้างของ project เป็นดังรูป
![]() แน่นอนว่า
แน่นอนว่า
มี folder src สำหรับเก็บ production code
มี folder tests สำหรับเก็บชุดการทดสอบนั่นเอง
โดยจะมีตัวอย่างของชุดการทดสอบให้ด้วย
จากนั้นทำการ run test ด้วยคำสั่ง
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step02.txt"]
เพียงเท่านี้เราก็สามารถเริ่มเรียนรู้
การพัฒนาระบบด้วยภาษา Elm กันได้แล้ว
ปล. ถ้าสังเกตุจะเห็นว่ามี link สำหรับการเขียน test ให้ด้วยนะ !!
ขั้นตอนที่ 2 มาเขียน test แรกกันดีกว่า
โดยจะทำการสร้างไฟล์ชื่อว่า
FizzbuzzSpec.elm ขึ้นมา
เขียน test case ได้ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="test01.elm"]
จากนั้นทำการ run test จะได้ผลการทดสอบดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="test01.txt"]
คำอธิบาย
เกิด error ขึ้นมาเนื่องจากหา variable ชื่อว่า
say ใน module ต่าง ๆ ไม่เจอ
นั่นคือการบอกว่า เราต้องสร้าง module ที่มี variable ชื่อว่า say ขึ้นมา
เพื่อรับค่า 1 เข้าไป จากนั้นทำการ return "1" ออกมา
ขั้นตอนที่ 3 ทำการสร้าง module ใหม่ชื่อว่า Fizzbuzz อยู่ใน folder src
ทำการสร้างไฟล์ชื่อว่า
Fizzbuzz.elm
ซึ่งจะมี function/method ชื่อว่า
say
ได้ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="Fizzbuzz01.elm"]
ขั้นตอนที่ 4 ทำการแก้ไขไฟล์ FizzbuzzSpec.elm ให้เรียกใช้งาน Fizzbuzz module
ด้วยการ import module เข้ามาดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="test02.elm"]
จากนั้นทำการทดสอบสิ ได้ผลการทดสอบดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step03.txt"]
ผลการทดสอบคือ fail นั่นเอง
เนื่องจากคาดหวังว่าต้องได้ผลลัพธ์คือ 1
ขั้นตอนที่ 5 ทำให้การทดสอบผ่านแบบง่ายสุด ๆ
เขียน code ได้ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="Fizzbuzz02.elm"]
จากนั้นทำการ run test ได้ผลดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step04.txt"]
ผลที่ได้คือผ่านแล้วววววว
ขั้นตอนที่ 6 ทำการสร้าง test case ที่สองคือ 3 จะพูดว่า Fizz
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="test03.elm"]
ผลการทดสอบไม่ผ่านแน่นอน แสดงดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step05.txt"]
ขั้นตอนที่ 7 มาเขียน code เพื่อให้ test ผ่านกันอีกรอบ
การแก้ไขปัญหามีหลายแบบ แล้วแต่จะเลือก
โดยผมเลือกใช้ case expression ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="Fizzbuzz03.elm"]
ขั้นตอนที่ 8 ทำการเขียน test และเขียน code เพื่อให้ test ผ่านกันต่อไป
นั่นคือ case 5 จะพูดว่า
Buzz
สามารถเขียน code เพื่อแก้ไขปัญหาได้ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="Fizzbuzz04.elm"]
นั่นคือ case 15 จะพูดว่า
FizzBuzz
สามารถเขียน code เพื่อแก้ไขปัญหาได้ดังนี้
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="Fizzbuzz05.elm"]
ตัวอย่างของ source code ทั้งหมดอยู่ที่
Github :: Learn Elm
มาถึงตรงนี้ก็พอจะทำให้ผมสามารถเริ่มต้นเรียนรู้ภาษา elm
แบบงู ๆ ปลา ๆ ได้บ้างแล้ว
จากนี้ก็ลองไปศึกษาส่วนอื่น ๆ กันต่อไป
ขอให้สนุกกับการ coding นะครับ

 ช่วงนี้มีโอกาสมาเขียนและ review code ที่พัฒนาด้วย React กันนิดหน่อย
ปัญหาหลักที่พบเจอคือ
การออกแบบ react component สำหรับระบบงาน
ในแต่ละ component ทำงานมากเกินไป
ในแต่ละ component reuse ได้ยาก
ในแต่ละ component ทดสอบได้ยาก
ดังนั้นเรามาเข้าใจกับการออกแบบ component ที่น่าจะดีกันหน่อย
ช่วงนี้มีโอกาสมาเขียนและ review code ที่พัฒนาด้วย React กันนิดหน่อย
ปัญหาหลักที่พบเจอคือ
การออกแบบ react component สำหรับระบบงาน
ในแต่ละ component ทำงานมากเกินไป
ในแต่ละ component reuse ได้ยาก
ในแต่ละ component ทดสอบได้ยาก
ดังนั้นเรามาเข้าใจกับการออกแบบ component ที่น่าจะดีกันหน่อย

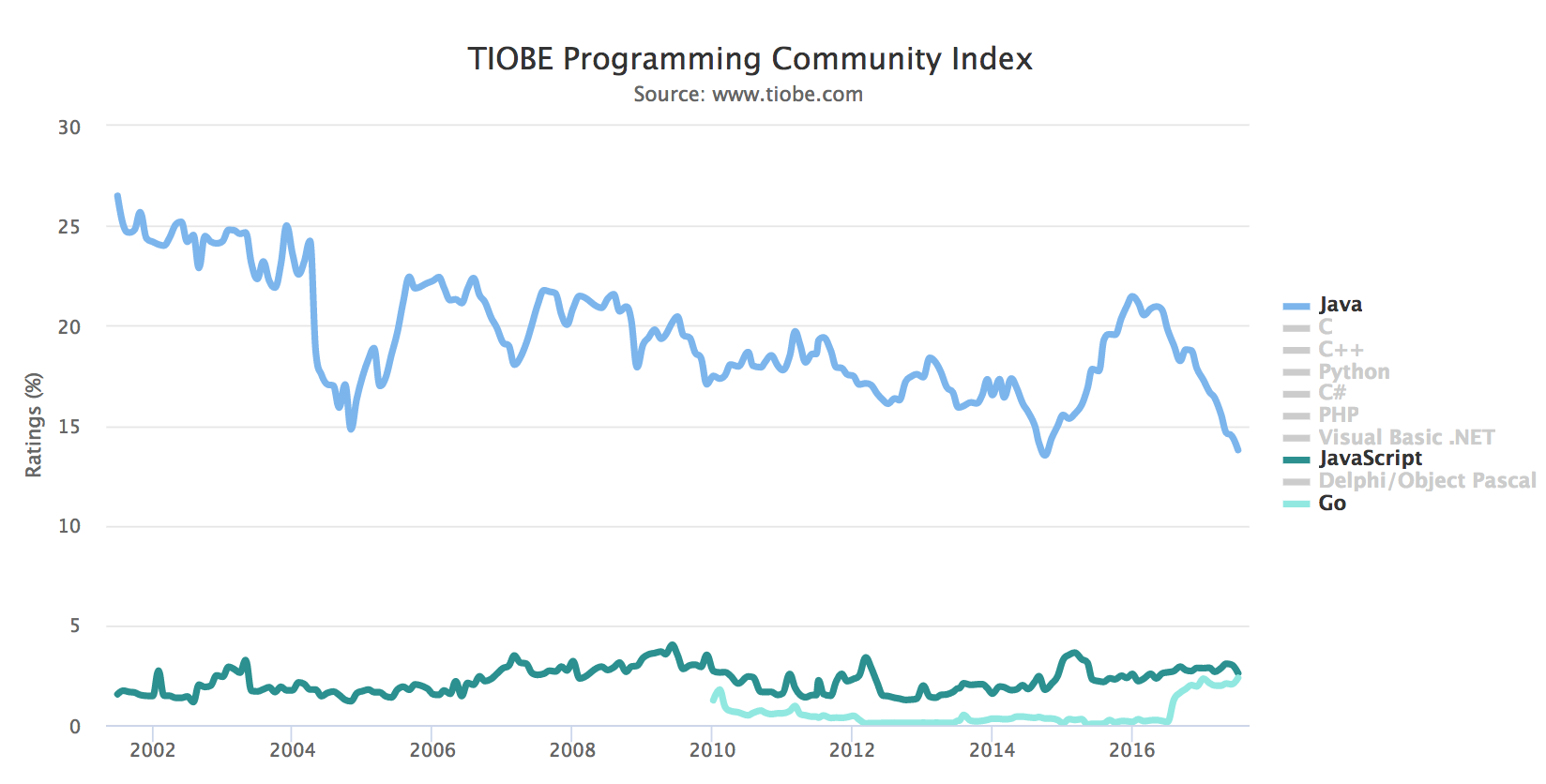
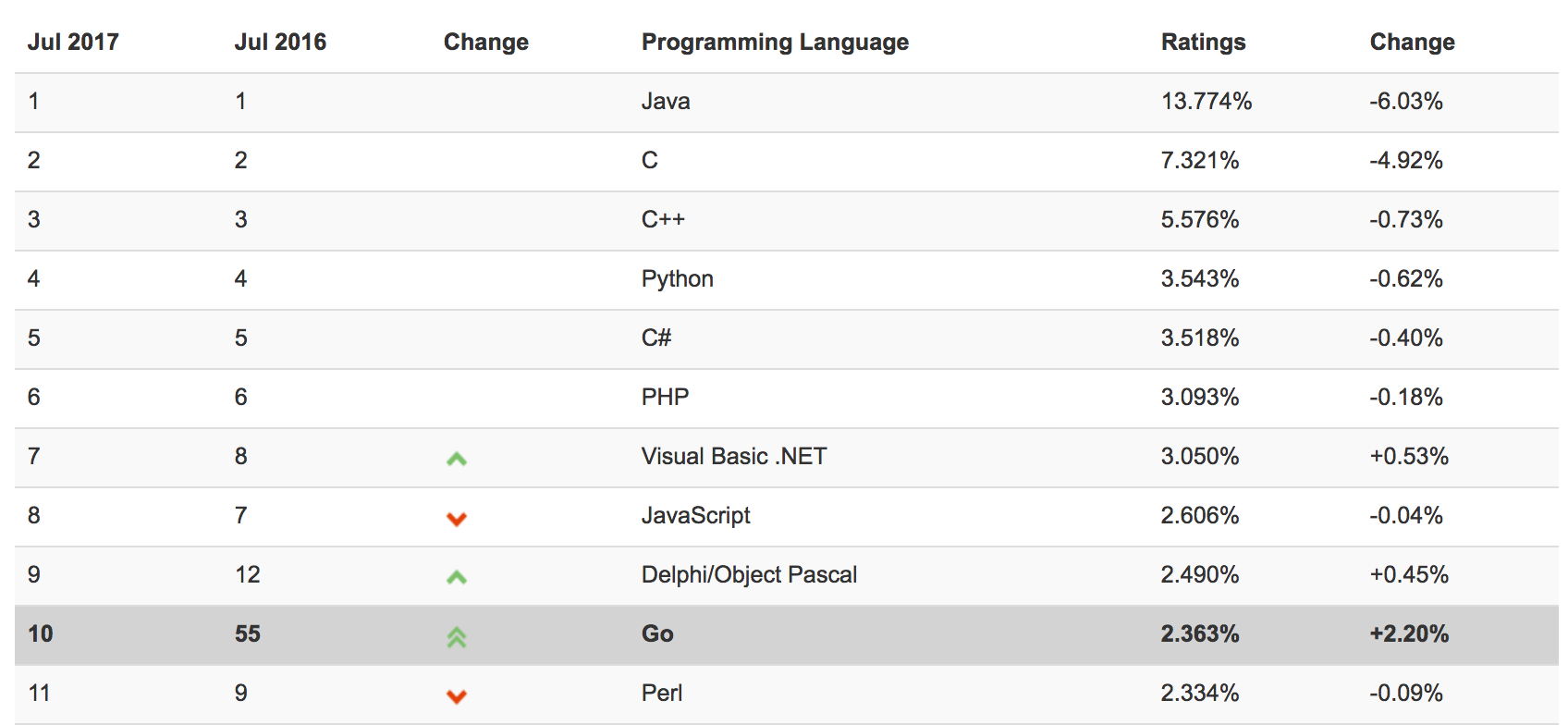
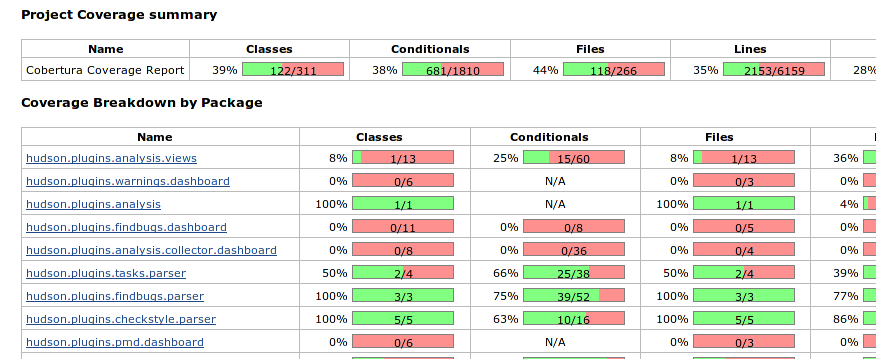
 ข้อมูลจาก
ข้อมูลจาก 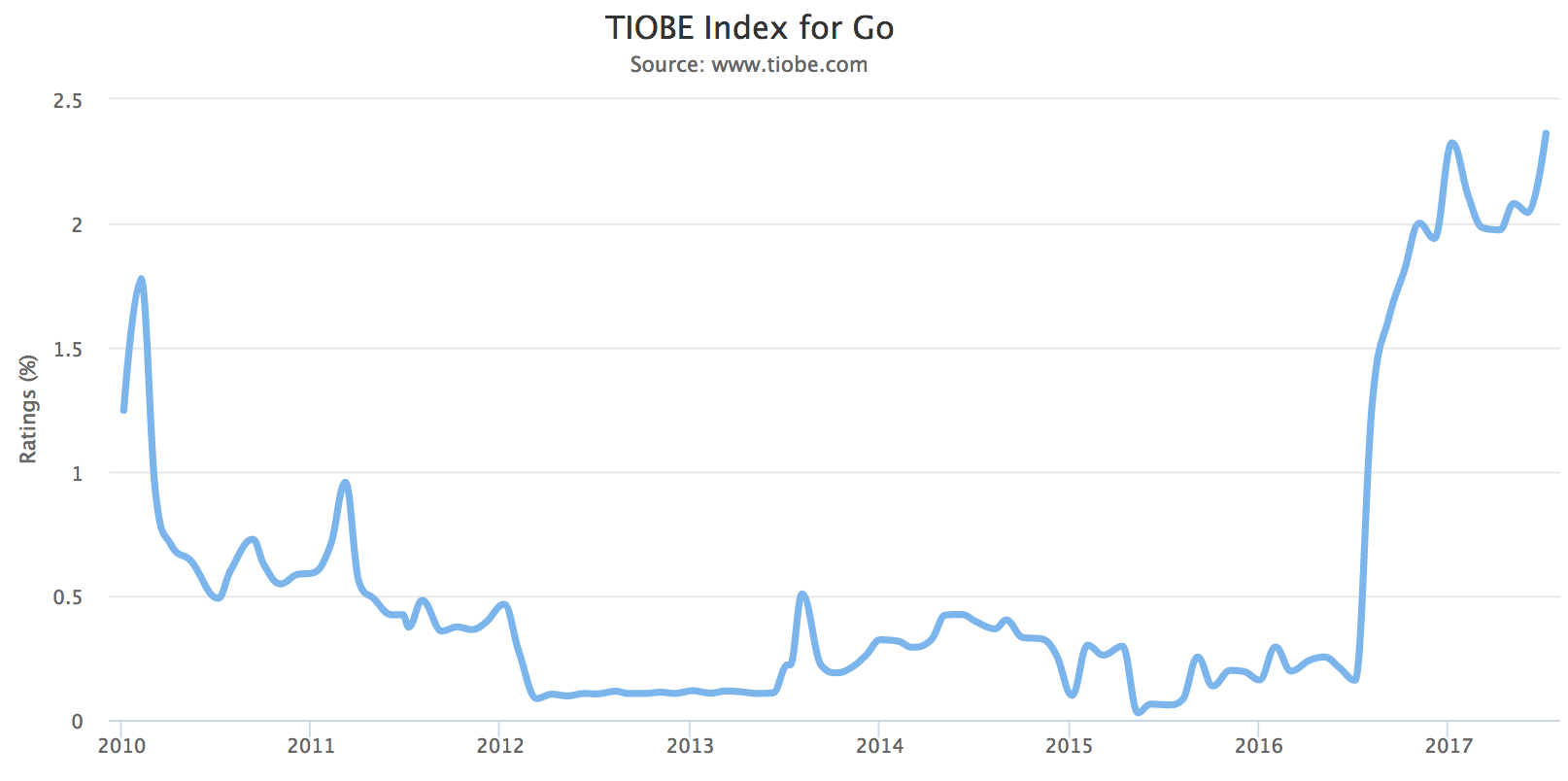

 ปัญหาที่พบเจอ
ปัญหาที่พบเจอ

 แน่นอนว่า
มี folder src สำหรับเก็บ production code
มี folder tests สำหรับเก็บชุดการทดสอบนั่นเอง
โดยจะมีตัวอย่างของชุดการทดสอบให้ด้วย
จากนั้นทำการ run test ด้วยคำสั่ง
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step02.txt"]
เพียงเท่านี้เราก็สามารถเริ่มเรียนรู้
การพัฒนาระบบด้วยภาษา Elm กันได้แล้ว
ปล. ถ้าสังเกตุจะเห็นว่ามี link สำหรับการเขียน test ให้ด้วยนะ !!
แน่นอนว่า
มี folder src สำหรับเก็บ production code
มี folder tests สำหรับเก็บชุดการทดสอบนั่นเอง
โดยจะมีตัวอย่างของชุดการทดสอบให้ด้วย
จากนั้นทำการ run test ด้วยคำสั่ง
[gist id="44c5df38006c8f37da1b9996ca96c4ab" file="step02.txt"]
เพียงเท่านี้เราก็สามารถเริ่มเรียนรู้
การพัฒนาระบบด้วยภาษา Elm กันได้แล้ว
ปล. ถ้าสังเกตุจะเห็นว่ามี link สำหรับการเขียน test ให้ด้วยนะ !!



 ทางธนาคารแห่งประเทศไทย หรือ Bank Of Thailand (BOT)
ได้เปิด
ทางธนาคารแห่งประเทศไทย หรือ Bank Of Thailand (BOT)
ได้เปิด 
 เก็บตกจากการไปฟังเรื่อง
เก็บตกจากการไปฟังเรื่อง 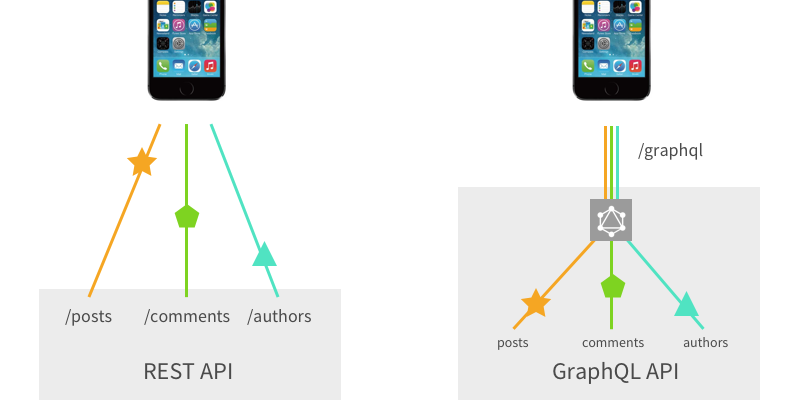

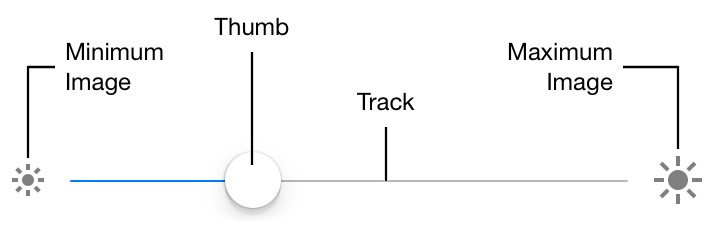
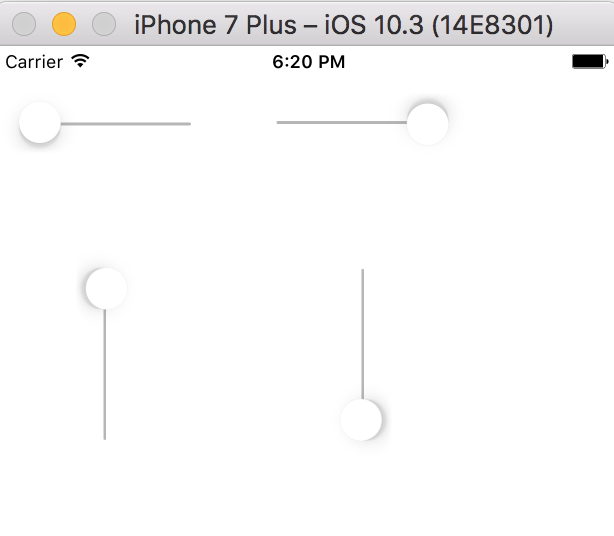 จากการศึกษาและทดลองของการหมุนในแต่ละรูปแบบ
ก็มีการคำนวณที่แตกต่างกัน
ทั้งแกนที่ใช้งานคือ แกม x และแกน y
รวมทั้งจุดเริ่มต้นของ Thumb ว่าอยู่ตรงไหนอีกด้วย
และจุดที่ต้องการให้เลื่อนไป
โดยค่า default มีค่าตั้งแต่ 0 ถึง 1
โดยอีก 3 แบบสามารถเขียน code เพื่อควบคุม UISlider ได้ตามความต้องการ
ซึ่งใส่จากซ้ายไปขวา และ บนลงล่างดังนี้
[gist id="940dccb99e41c272e5bdb00f887fcab3" file="2.swift"]
ตัวอย่างของ source code อยู่ที่
จากการศึกษาและทดลองของการหมุนในแต่ละรูปแบบ
ก็มีการคำนวณที่แตกต่างกัน
ทั้งแกนที่ใช้งานคือ แกม x และแกน y
รวมทั้งจุดเริ่มต้นของ Thumb ว่าอยู่ตรงไหนอีกด้วย
และจุดที่ต้องการให้เลื่อนไป
โดยค่า default มีค่าตั้งแต่ 0 ถึง 1
โดยอีก 3 แบบสามารถเขียน code เพื่อควบคุม UISlider ได้ตามความต้องการ
ซึ่งใส่จากซ้ายไปขวา และ บนลงล่างดังนี้
[gist id="940dccb99e41c272e5bdb00f887fcab3" file="2.swift"]
ตัวอย่างของ source code อยู่ที่ 
 หลังจากงาน
หลังจากงาน 

 อ่านเจอบทความเกี่ยวกับการเปลี่ยนระบบ search engine ของ Yelp มาใช้ Elasticsearch
อ่านเจอบทความเกี่ยวกับการเปลี่ยนระบบ search engine ของ Yelp มาใช้ Elasticsearch

 ว่าง ๆ มารวบรวมคำสั่งและ shortcut ที่ใช้ประจำ
ผ่าน terminal บน MacOs ของตัวเองไว้นิดหน่อย
เขียนไว้กันลืม
ว่าง ๆ มารวบรวมคำสั่งและ shortcut ที่ใช้ประจำ
ผ่าน terminal บน MacOs ของตัวเองไว้นิดหน่อย
เขียนไว้กันลืม

 ช่วงนี้มีโอกาสใช้งาน Array ของ
ช่วงนี้มีโอกาสใช้งาน Array ของ 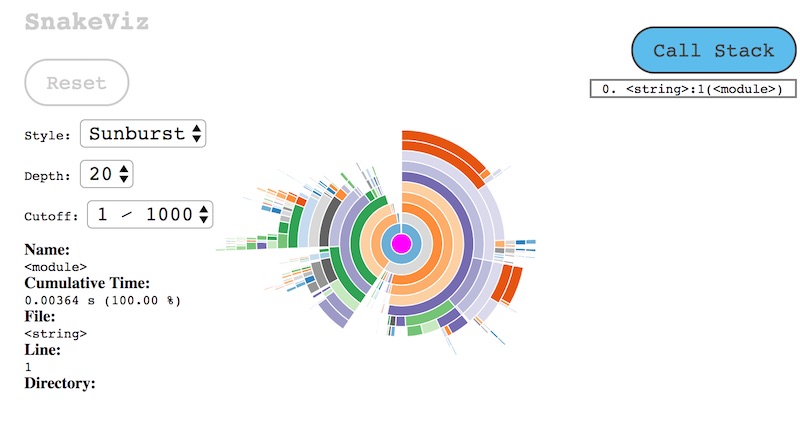 อาจจะดูแล้วยังงง ๆ ดังนั้นมาเปรียบเทียบกับการเข้าถึงข้อมูลใน array ของ Numpy
แสดงผลดังนี้ ซึ่งไม่มีการเรียกหรือทำงานอะไรที่ซับซ้อนเลย
จึงทำให้ผลการทำงานเร็วกว่ามาก ๆ
อาจจะดูแล้วยังงง ๆ ดังนั้นมาเปรียบเทียบกับการเข้าถึงข้อมูลใน array ของ Numpy
แสดงผลดังนี้ ซึ่งไม่มีการเรียกหรือทำงานอะไรที่ซับซ้อนเลย
จึงทำให้ผลการทำงานเร็วกว่ามาก ๆ
 ขอให้สนุกกับการ coding ครับ
ขอให้สนุกกับการ coding ครับ

 สำหรับภาษา Python นั้นเหมาะกับการทำ Data Analysis อย่างมาก
เนื่องจากมี ecosystem และพวก library ต่าง ๆ ให้ใช้มากมาย
แต่ในความมากมายนั้น กลับกลายเป็นภัยสำหรับผู้เริ่มต้น
ดังนั้นจึงสรุป library หลัก ๆ สำหรับผู้เริ่มต้นไว้นิดหน่อย
ค่อย ๆ ศึกษาและใช้งานกันไปนะ
สำหรับภาษา Python นั้นเหมาะกับการทำ Data Analysis อย่างมาก
เนื่องจากมี ecosystem และพวก library ต่าง ๆ ให้ใช้มากมาย
แต่ในความมากมายนั้น กลับกลายเป็นภัยสำหรับผู้เริ่มต้น
ดังนั้นจึงสรุป library หลัก ๆ สำหรับผู้เริ่มต้นไว้นิดหน่อย
ค่อย ๆ ศึกษาและใช้งานกันไปนะ



 สำหรับชาว React และ React Native แล้วนั้น
ผมคิดว่าน่าจะใช้
สำหรับชาว React และ React Native แล้วนั้น
ผมคิดว่าน่าจะใช้  ขอให้สนุกกับการ coding ครับ
Reference Websites
ขอให้สนุกกับการ coding ครับ
Reference Websites

 จากบทความเรื่อง
จากบทความเรื่อง 
 เมื่อวานเจอ code ที่น่าสนใจใน Slack ของ Kotlinlang
แต่สิ่งที่สำคัญและน่าสนใจกว่าคือ ความสามารถใน code ของภาษา Kotlin นั่นเอง
มันมีหลายสิ่งที่ควรค่าต่อการหยุดดูและศึกษา
ดังนั้นมาลองดู code กันขำๆ กันหน่อย
[gist id="b414a4f8430ad0d014c05ec74ef37f46" file="tip.kt"]
ที่สำคัญ code ชุดนี้ทำงานได้ด้วยนะ
ซึ่งสามารถทดสอบ run ด้วยคำสั่ง
[code]
$kotlinc tip.kt -include-runtime -d tip.jar
$java -jar tip.jar
[/code]
ได้ผลคือ โยน exception ออกมาดังนี้
[code]
Exception in thread "main" ┻━┻
at ┻━┻.<clinit>(tip.kt:1)
at TipKt.main(tip.kt:11)
[/code]
เมื่อวานเจอ code ที่น่าสนใจใน Slack ของ Kotlinlang
แต่สิ่งที่สำคัญและน่าสนใจกว่าคือ ความสามารถใน code ของภาษา Kotlin นั่นเอง
มันมีหลายสิ่งที่ควรค่าต่อการหยุดดูและศึกษา
ดังนั้นมาลองดู code กันขำๆ กันหน่อย
[gist id="b414a4f8430ad0d014c05ec74ef37f46" file="tip.kt"]
ที่สำคัญ code ชุดนี้ทำงานได้ด้วยนะ
ซึ่งสามารถทดสอบ run ด้วยคำสั่ง
[code]
$kotlinc tip.kt -include-runtime -d tip.jar
$java -jar tip.jar
[/code]
ได้ผลคือ โยน exception ออกมาดังนี้
[code]
Exception in thread "main" ┻━┻
at ┻━┻.<clinit>(tip.kt:1)
at TipKt.main(tip.kt:11)
[/code]

 จากการ
จากการ 




 ขอเข้าห้องน้ำไปอ้วกก่อนครับ
ขอเข้าห้องน้ำไปอ้วกก่อนครับ

 สิ่งที่น่าสนใจสำหรับ
สิ่งที่น่าสนใจสำหรับ 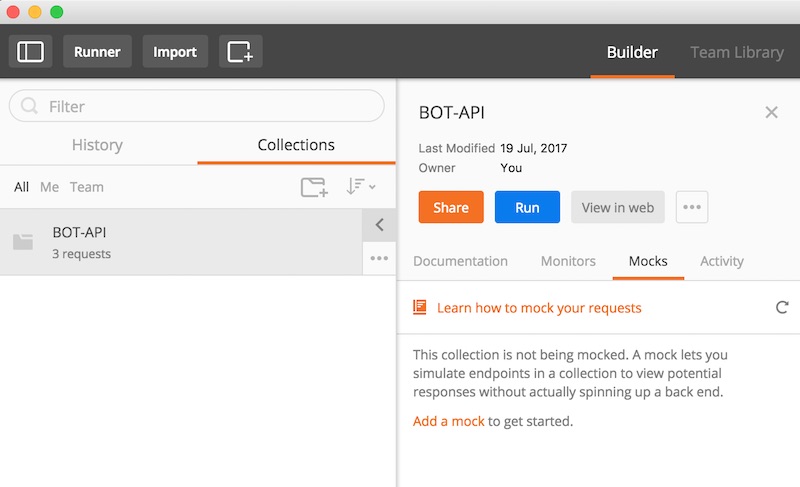
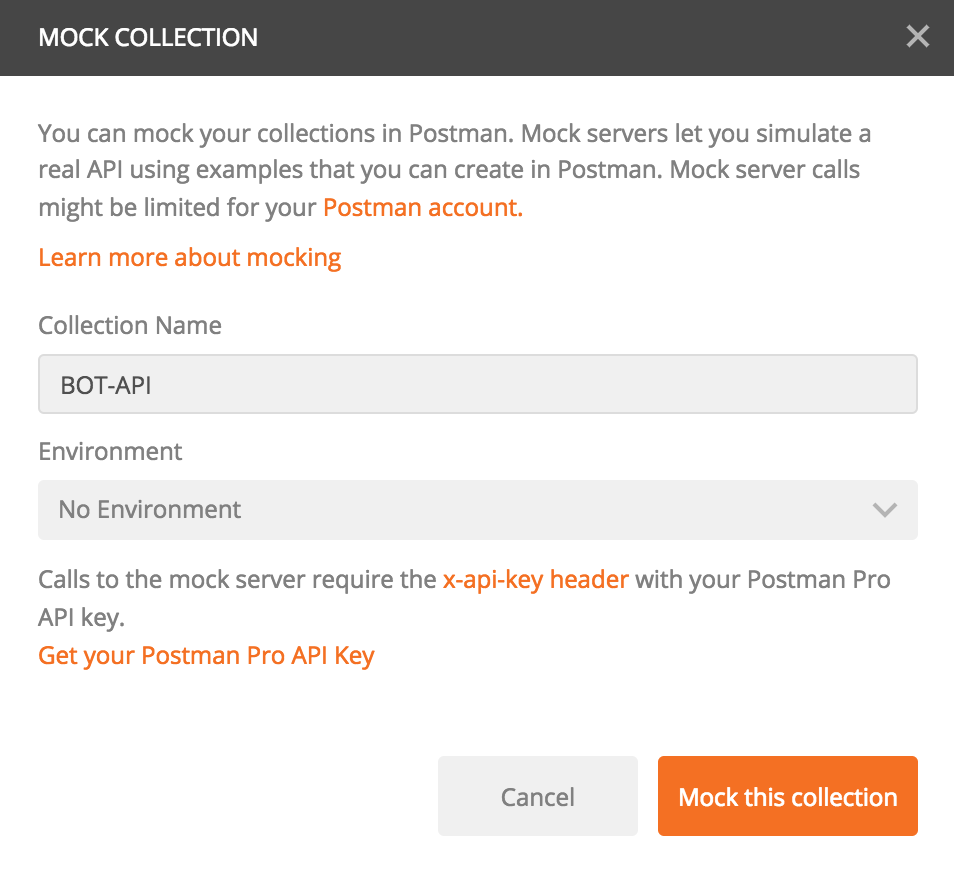 ทำการกดปุ่ม Mock this collection
โดย Postman จะสร้าง URL ของ Mock server มาให้
ซึ่งเราจะนำ URL นี้ไปใช้ต่อไป
ทำการกดปุ่ม Mock this collection
โดย Postman จะสร้าง URL ของ Mock server มาให้
ซึ่งเราจะนำ URL นี้ไปใช้ต่อไป
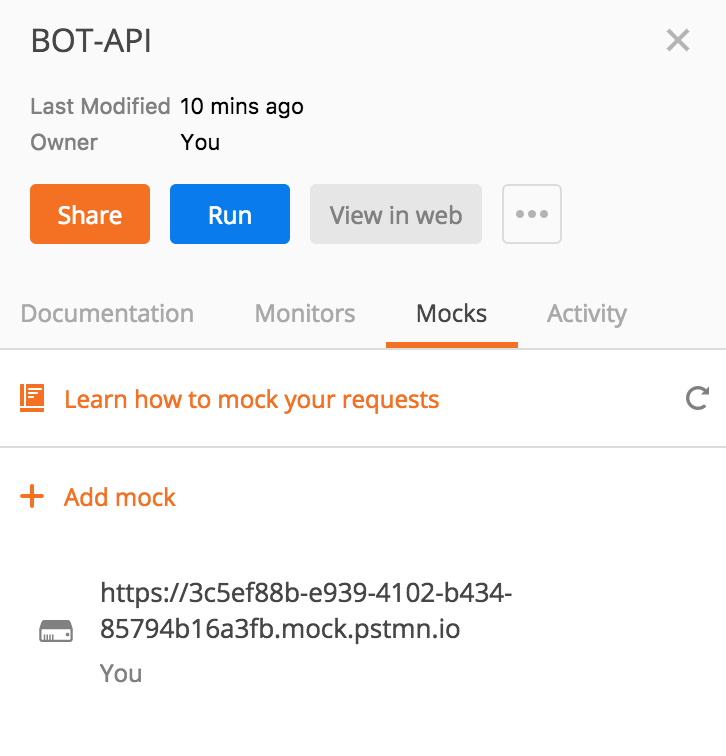 จากนั้นทำการสร้าง Environment ใหม่ชื่อว่า Mock
จะได้นำไปใช้งานง่าย ๆ ดังรูป
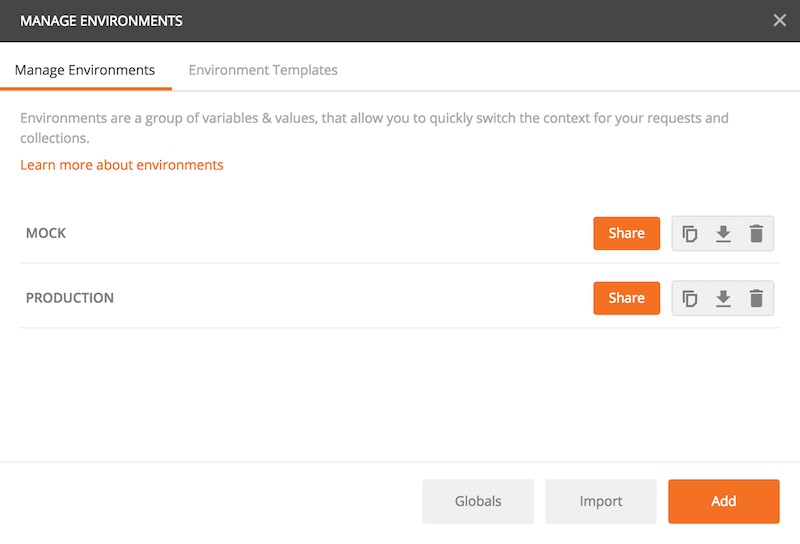
จากนั้นทำการสร้าง Environment ใหม่ชื่อว่า Mock
จะได้นำไปใช้งานง่าย ๆ ดังรูป
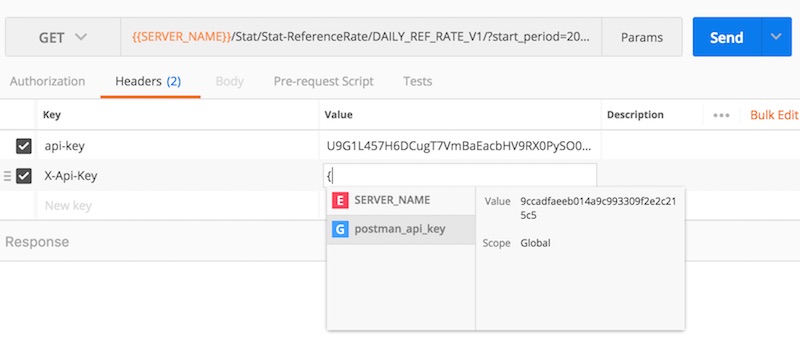
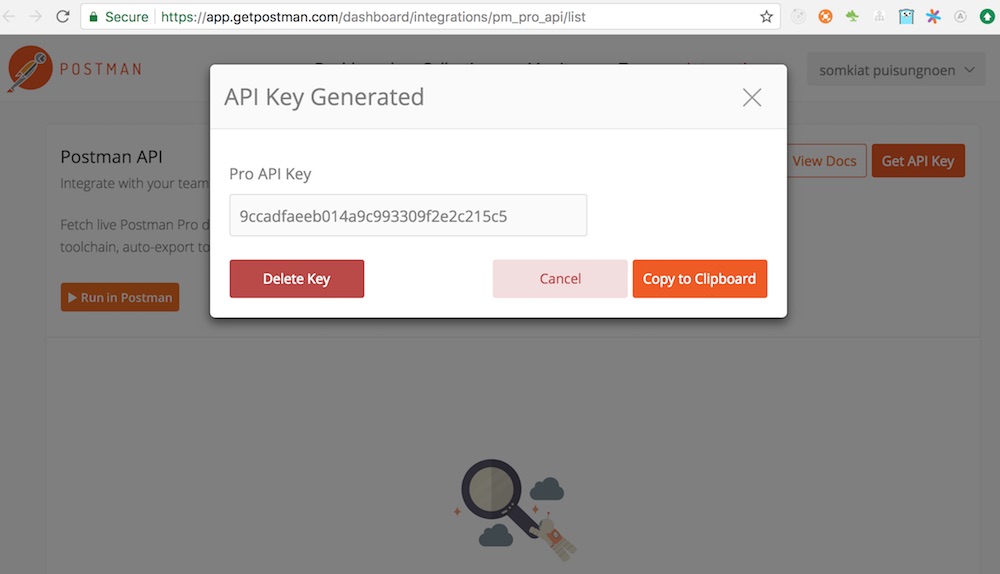 จากนั้นนำ API Key จาก Postman มาใส่ใน Header ของทุก ๆ Request
โดยใช้ชื่อว่า X-Api-Key
แต่แนวทางที่ดีกว่าคือ สร้าง Global variable ชื่อว่า postman_api_key ไว้
เพื่อจะได้ใช้งานได้จากทุก ๆ Request
จากนั้นนำ API Key จาก Postman มาใส่ใน Header ของทุก ๆ Request
โดยใช้ชื่อว่า X-Api-Key
แต่แนวทางที่ดีกว่าคือ สร้าง Global variable ชื่อว่า postman_api_key ไว้
เพื่อจะได้ใช้งานได้จากทุก ๆ Request
 จากนั้นก็มาสร้าง Header ใน Request ซะ
จากนั้นก็มาสร้าง Header ใน Request ซะ
 เพื่อความสะดวกขึ้นไปอีกก็ให้ทำการสร้าง Preset ไว้เลย
การสร้าง Preset
เพื่อความสะดวกขึ้นไปอีกก็ให้ทำการสร้าง Preset ไว้เลย
การสร้าง Preset
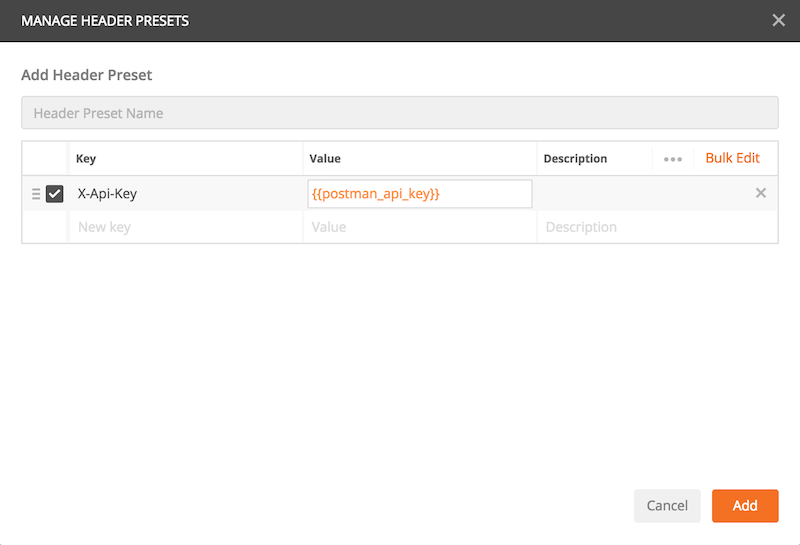 การใช้งาน Preset
การใช้งาน Preset
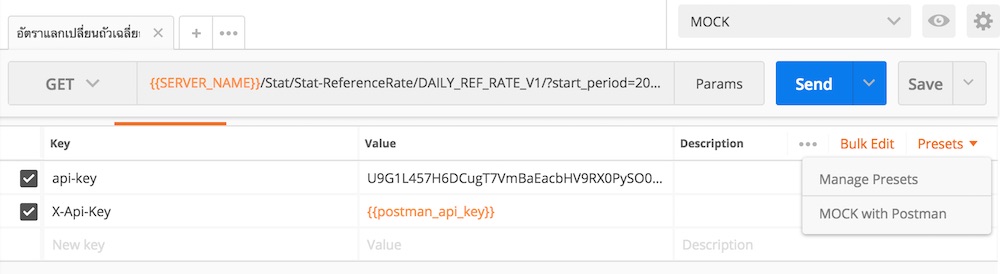
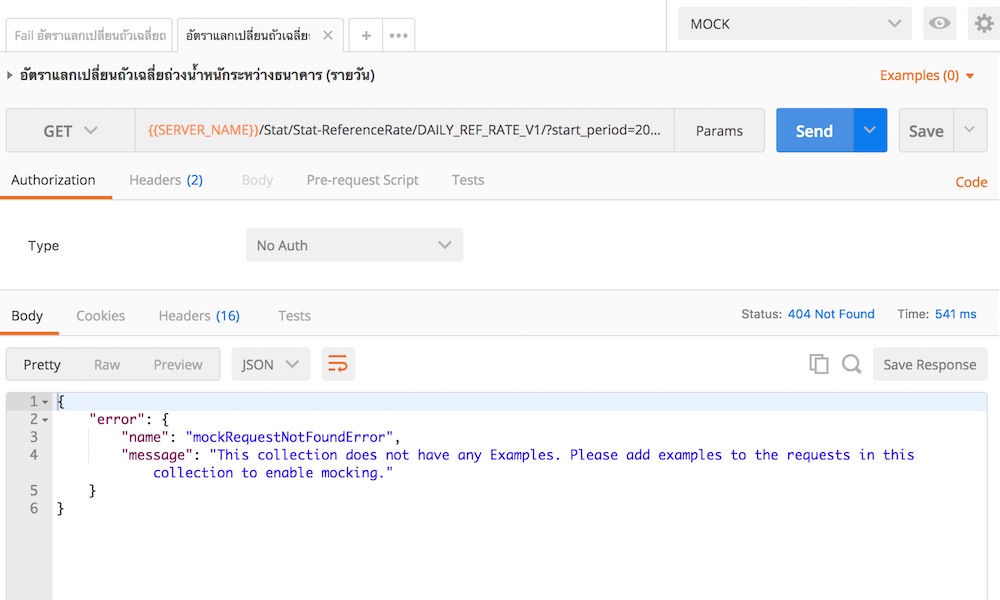 ดังนั้นทำการ Add Example เข้าไปในแต่ละ Request
แต่จะเอา Example มาจากไหน ?
ตอบง่าย ๆ เลยคือ ก็ทำการเอามาจาก API จริง ๆ ไง !!
ดังนั้นให้เปลี่ยน environmemt ไปยัง API จริง
จากนั้นก็เพิ่ม response เหล่านั้นไปยัง Example ต่อไปดังนี้
ดังนั้นทำการ Add Example เข้าไปในแต่ละ Request
แต่จะเอา Example มาจากไหน ?
ตอบง่าย ๆ เลยคือ ก็ทำการเอามาจาก API จริง ๆ ไง !!
ดังนั้นให้เปลี่ยน environmemt ไปยัง API จริง
จากนั้นก็เพิ่ม response เหล่านั้นไปยัง Example ต่อไปดังนี้
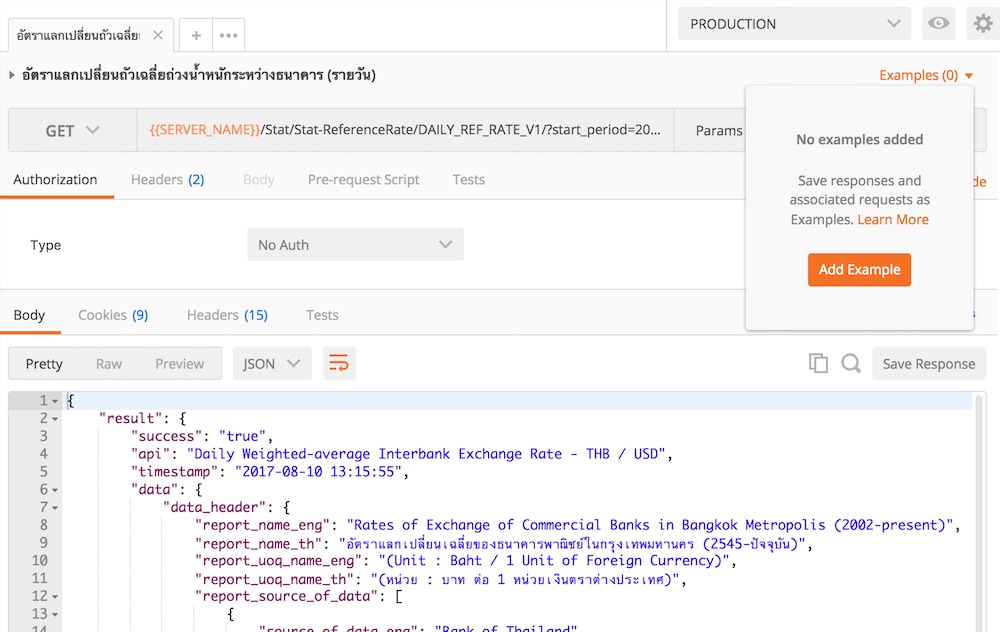 จากนั้นทำการ Run Request และเปลี่ยนไปใช้ Mock environment ได้ดังนี้
ไม่เกิด error แล้วนะ
จากนั้นทำการ Run Request และเปลี่ยนไปใช้ Mock environment ได้ดังนี้
ไม่เกิด error แล้วนะ
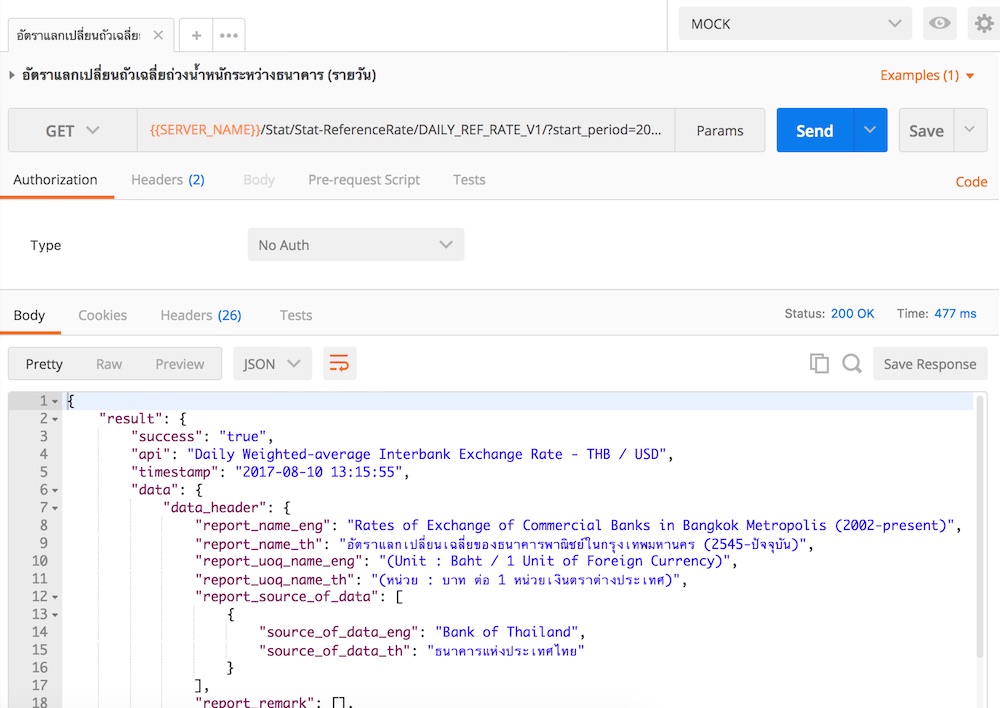 ที่สำคัญในแต่ละ Request/API สามารถเพิ่ม Example ได้หลาย ๆ กรณีทั้ง success และ failure ได้เลย
โดยสามารถอ่านเอกสารเพิ่มเติมได้ที่
ที่สำคัญในแต่ละ Request/API สามารถเพิ่ม Example ได้หลาย ๆ กรณีทั้ง success และ failure ได้เลย
โดยสามารถอ่านเอกสารเพิ่มเติมได้ที่