

ทางทีมงานพัฒนาระบบ SoundCloud และ DigitalOcean
ทำการอธิบายเพิ่มเติมเรื่องสิ่งที่จำเป็นหรือต้องเตรียมพร้อม
ก่อนเข้าสู่โลกของ Microservices
ซึ่งยังคงอ้างอิงไปยังบทความ Microservice Prerequisites ของคุณ Martin Fowler
จากบทความข้างต้นอธิบายเพิ่มเติมในสิ่งที่ขาดหายไป
หลังจากที่ทำงานย้ายจากระบบเดิมที่เป็น Monolith มาเป็น Microservices
ประกอบไปด้วย 7 เรื่องดังนี้
- Rapid provisioning of compute resources
- Basic monitoring
- Rapid deployment
- Easy to provision storage
- Easy access to the edge
- Authentication/Authorisation
- Standardised RPC
มาดูรายละเอียดในแต่ละข้อกัน
1. Rapid provisioning of compute resources
การเตรียม resource ต่าง ๆ สำหรับระบบงานนั้น
อาจจะเป็นทั้งเครื่อง server จริง ๆ
อาจจะเป็นทั้ง VM
อาจจะเป็นทั้ง container
อาจจะเป็นทั้ง function
หรืออาจจะรวมหลาย ๆ อย่างเข้าด้วยกัน
เพื่อใช้สำหรับการ deploy ระบบงานหรือ service ที่ออกแบบและพัฒนาขึ้นมา
ยิ่งทำการแยกเป็น service เล็ก ๆ ตามแนวคิดของ Microservices ด้วยแล้ว
ยิ่งก่อให้เกิดความซับซ้อน (Complexity) มากยิ่งขึ้น
การเตรียมและสร้าง ennvironement เหล่านี้หรือที่เรียกว่า Compute resource นั้น
ใช้เวลาเท่าไร ?
เร็วตามความต้องการหรือไม่ ?
แน่นอนว่า ยังต้องมีคุณภาพ มีความปลอดภัยด้วย
รวมทั้งต้องสามารถรองรับการใช้งานที่สูงขึ้นในแต่ละ service อีกด้วย
2. Basic monitoring
ระบบที่ออกแบบตามแนวคิดของ Microservices นั้นคือ
ระบบที่มีความซับซ้อน (เอาอยู่หรือไม่)
ดังนั้นสิ่งที่จำเป็นมาก ๆ คือ
ต้องเอามันให้อยู่
ควบคุมให้ได้
พร้อมทั้งทำนายหรือดูแนวโน้มสิ่งที่ใกล้จะเกิดขึ้นได้
เพราะว่า ระบบเหล่านี้ มีการเปลี่ยนแปลงบ่อย มีการ deploy และ redeploy บ่อย
ดังนั้น เรื่องระบบ Monitoring ของระบบเป็นสิ่งที่ขาดไม่ได้เลย
ทั้ง centralize logging
ทั้ง infrastructure monitoring
ทั้ง network monitoring
ทั้ง distributed tracing
ทั้ง dashboard เพื่อสรุปข้อมูลเชิงตัวเลขของระบบ (Metric)
ทั้ง alert system ที่คอยแจ้งปัญหา หรือ จุดที่อาจจะก่อให้เกิดปัญหาในอนาคตอันใกล้
เพื่อเตรียมรับมือนั่นเอง
เป้าหมายเพื่อลดเวลา MTTR (Mean Time To Recovery)
นั่นคือเวลาที่แก้ไขปัญหานั่นเอง ยิ่งน้อยยิ่งดี
โดยที่ใน MTTR ประกอบไปด้วย
- Mean Time To Detection คือเวลาการหาจุดที่ผิด
- Mean Time To Recovery คือเวลาการแก้ไขให้กลับสู่สภาวะปกติ

ดังนั้นสิ่งที่สำคัญมาก ๆ ของระบบ Monitoring คือ
การ detect หรือตรวจหาสาเหตุของปัญหาจากการเปลี่ยนแปลงนั่นเอง
เพื่อจะได้ทำการแก้ไขได้รวดเร็วขึ้น
3. Rapid deployment
จากข้อที่สองนั้น
ถ้าเราตรวจสอบหาสาเหตุของปัญหาได้แล้ว จึงจะสามารถการแก้ไขได้
หลังจากแก้ไขแล้วนั้น ต้องทำการ deploy ระบบงาน
แน่นอนว่า การ deploy ก็ต้องรวดเร็ว เสถียรและมีความน่าเชื่อถือด้วย
มิฉะนั้นแล้ว เวลาในการแก้ไขและ recovery จะไม่เร็วเลย
ถ้าระบบงานเป็นแบบ monolith แล้ว
การ deploy จะเป็นแบบ manual หรือใช้คนทำเป็นหลัก
เพราะว่าระบบมีความซับซ้อนสูง
มีการเปลี่ยนแปลงเยอะ
มีผลกระทบมากมาย
ทำงานร่วมกันกับหลาย ๆ ทีม หลาย ๆ คน
แต่เมื่อทำการออกแบบตามแนวคิดของ Microservices แล้ว
จำนวน service ที่ deploy จะเยอะขึ้น
ส่งผลให้การ deploy แบบ manual กลายเป็นปัญหาขึ้นมา
ดังนั้นเราจำเป็นต้องมีระบบการ deploy แบบอัตโนมัติขึ้นมานั่นเอง
เพื่อลดระยะเวลาและความพยายามในการ deploy ลง
4. Easy to provision storage
ส่วนใหญ่ระบบ Monolith ที่เปลี่ยนมายัง Microservices นั้น
มักพบว่าใช้ database ขนาดใหญ่ร่วมกัน (Shared database/storage)
เพราะว่าจัดการและดูแลง่าย
เมื่อมีคนใช้จำนวนมาก จึงต้องทำการ replica ขึ้นมา
เพื่อลดความเสี่ยงของการล่มและข้อมูลหาย
แต่ปัญหาจะตามมา
เมื่อต้องทำการแก้ไขโครงสร้างของ table ใน database แล้ว
เราต้องมั่นใจว่า การแก้ไขนั้นต้องไม่กระทบต่อการทำงานของทั้งระบบ
เมื่อย้ายมายัง Microservices แล้ว
service ที่ดีนั้น จำเป็นต้องมีที่จัดเก็บข้อมูลแยกกันไป
นั่นคือลดการ JOIN ข้อมูล
แน่นอนว่า มีทั้งข้อดีและข้อเสีย
ข้อดีคือ ข้อมูลจัดเก็บแยกกันและเก็บเท่าที่ใช้งาน
ข้อเสียคือ การจัดการความถูกต้องของข้อมูล
เมื่อมีการทำงานข้าม service จะจัดการ transaction อย่างไร ?
อีกอย่างคือ อาจจะเกิดข้อมูลซ้ำซ้อนระหว่าง service จะจัดการอย่างไร ?
การจัดการที่จัดเก็บข้อมูลจึงสำคัญมาก ๆ
แต่ส่วนใหญ่มักจะหลงลืม
ไปสนใจแต่การ deploy และ provisioning server มากกว่า
ดังนั้นจึงต้องมีจัดการเรื่องนี้ที่ดี
ทั้งการ replica
ทั้งการ backup
ทั้งการจัดการเรื่องความปลอดภัย
ทั้งการ tuning
ทั้งการ monitoring และ metric ต่าง ๆ ด้วยเสมอ
แต่ถ้าทีมในบริษัทไม่มีความรู้เรื่องต่าง ๆ เหล่านี้
ก็อาจจะต้องหาผู้เชี่ยวชาญมาช่วย
หรือไปใช้บริการจาก Cloud provider ต่าง ๆ
5. Easy access to the edge
ในแต่ละ service ที่พัฒนาด้วยแนวทางของ Microservices
มักจะมีขนาดเล็ก ทำงานจบในตัวเอง
ทีมพัฒนามักจะมีขนาดไม่ใหญ่
ทดสอบได้ไม่ยาก
Deploy ก็เร็วขึ้น
แต่ประเด็นหลัก ๆ คือ service ที่เราสร้างขึ้นมานั้น
จะให้คนภายนอกหรือผู้ใช้งานเข้าถึง service อย่างไร ?
เพราะว่าระบบปกติหรือแบบเดิม
ก็ให้คนภายนอกใช้งานแบบปกติ
รวมทั้งจะจัดการเรื่องต่าง ๆ เหล่านี้อย่างไร
- Rate limit
- Access log
- Feature-flag หรือ feature toggle
- Security
- Monitoring
- Metric
- Alert system
- Request routing
วิธีที่แบบง่าย ๆ คือ เปิดให้เข้าใช้แบบปกตินั่นเอง
เข้าถึงตรง ๆ เลยดังรูป
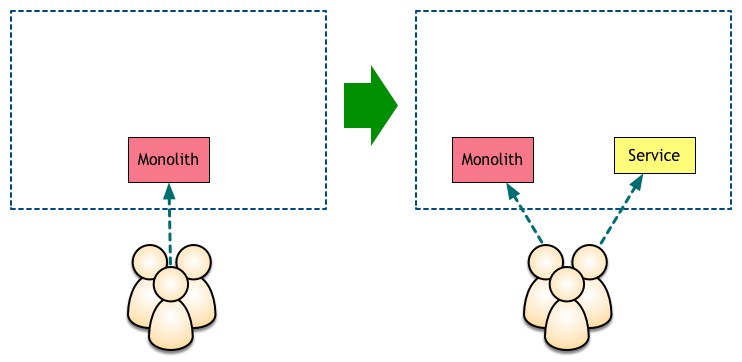
วิธีการดังรูปนั้น
Service จะผูกมัดกับผู้ใช้งาน เหมาะมากถ้ามี service ไม่เยอะ
แต่ถ้าจำนวน service เยอะขึ้น ทำให้จัดการยากขึ้น
ส่งผลฝั่งผู้ใช้งานมีความซับซ้อนมากขึ้นไปอีก
รวมทั้งอาจก่อให้เกิดปัญหาหรือเหตุการณ์ที่ไม่คาดหวังขึ้นมาเยอะมาก
ดังนั้น จึงมีแนวคิดในการแก้ไขนี้ด้วยรูปแบบที่เรียกว่า Gateway
จากบทความต้นฉบับอธิบายว่า
เริ่มต้นด้วยการใช้ระบบ Monolith มาเป็น Gateway ก่อน แสดงดังรูป
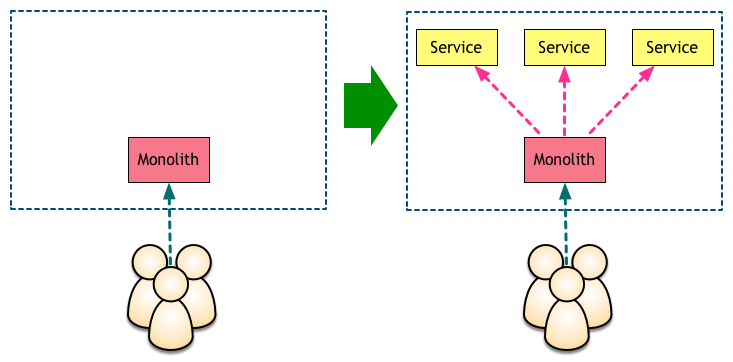
แต่เมื่อมีจำนวน service เยอะขึ้นอีก
ทำให้การเพิ่ม service และการ deploy Monolith มีความลำบากมากยิ่งขึ้น
รวมถึง technology ที่ใช้พัฒนาก็ไม่รองรับการใช้งานจำนวนมาก ๆ ได้
ดังนั้นจึงทำการเปลี่ยนไปใช้ Gateway ที่เหมาะสมกว่า
โดยอาจจะใช้ API Gateway ที่ทำงานเรื่องนี้ได้ดีมาใช้
หรือจากบทความจำสร้าง Gateway ขึ้นมาตาม BFF pattern (Backend-For-Frontend)
6. Authentication/Authorisation
เรื่องสำคัญต่อมาของแต่ละ service คือ
ใครที่สามารถใช้งาน service ได้บ้าง ?
คำถามคือ เราจะจัดการเรื่องนี้อย่างไร ?
ในบทความจะเริ่มจากให้แต่ละ service
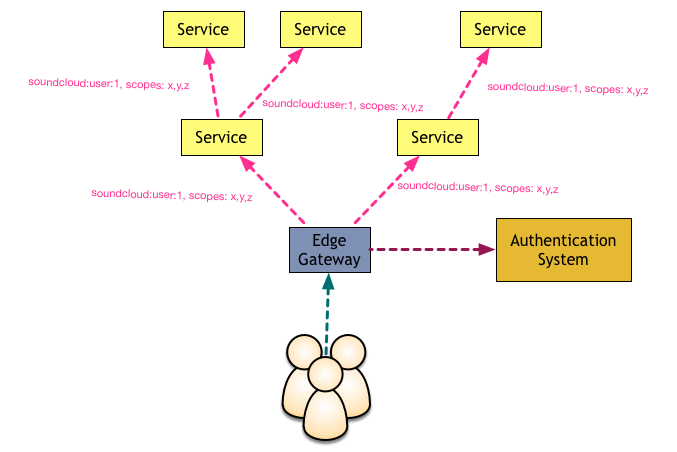
ตรวจสอบสิทธิ์ในการเข้าใช้งานจาก Authentication system แสดงดังรูป
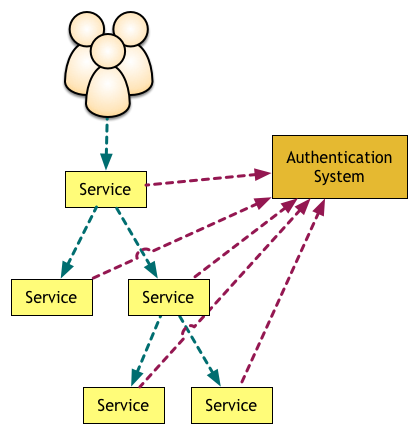
ปัญหาที่เกิดขึ้น มีการทำงานส่วนการตรวจสอบสิทธิ์การใช้งานซ้ำ ๆ กันเยอะมาก
รวมทั้งเกิด overhead ในการติดต่อไปยัง Authentication system สูงมาก ๆ
แต่เมื่อเปลี่ยนมีใช้ Gateway แล้ว
ข้อมูลต่าง ๆ จะจัดเก็บไว้ใน memory ที่ Gateway
ทำให้ไม่ต้องไปดึงข้อมูลจาก Authentication system บ่อยเกินไป
ถ้าตรวจสอบ request แล้วว่ามีสิทธิ์ใช้งานแล้ว
Gateway จะทำการ redirect request ไปยัง service ที่อยู่หลัง Gateway ดังรูป
7. Standardised RPC
เรื่องสุดท้ายคือ รูปแบบของการติดต่อสื่อสารระหว่าง service
เหมือนภาษาในการพูดคุยว่าเป็นอย่างไร
ยกตัวอย่างเช่น
การติดต่อสื่อสารผ่าน HTTP และข้อมูลอยู่ในรูปแบบ JSON
แต่ไม่ได้อธิบายถึง
การส่งข้อมูลของการ authentication และ authorisation
การจัดการเรื่อง paging ของข้อมูล
การจัดการเรื่อง tracing ของ request ต่าง ๆ
การจัดการเมื่อเกิดปัญหาขึ้นมา
ดังนั้น ควรต้องกำหนดรูปแบบที่เป็นมาตรฐานของ service ของเรา
ในบทความอธิบายว่า
รูปแบบการติดต่อสื่อสารที่ใช้นั้น เมื่อมีการใช้งานมากขึ้น
ก่อให้เกิดปัญหาเรื่อง performance
ดังนั้นจึงเปลี่ยนไปใช้ protocol ที่เหมาะสมเช่น
ถ้ามีการส่งข้อมูลจำนวนมาก จะไปใช้งาน Apache Thrift
หรืออาจจะไปใช้ gRPC สำหรับการติดต่อสื่อสารภายในหรือแบบ private
ทั้ง 7 เรื่องนี้เป็นสิ่งสำคัญมาก ๆ ก่อนที่จะก้าวเข้าสู่ Microservices อย่างยั่งยืน
มิเช่นนั้น แทนที่จะมีประโยชน์กลับก่อให้เกิดโทษร้ายแรงได้
ซึ่งน่าจะมีประโยชน์สำหรับใครที่คิดจะเริ่มต้น
เหรียญมีสองด้านเสมอ
ดังนั้นก่อนจะเริ่มใช้งาน
ต้องเข้าใจก่อนว่า
ปัญหาของเราคืออะไร ?
ต้องการแก้ไขอะไร ?
เป้าหมายคืออะไร ?
จากนั้นจึงค่อยลงมือแก้ไข วัดผล และย้อนกลับมาดูและปรับปรุงต่อไป