

มีโอกาสไปแบ่งปันเรื่อง Distributed Tracing ในงาน Go Get TH Meetup ครั้งที่ 5 โดยเนื้อหาประกอบไปด้วย
- Observability ของระบบงาน
- Tracing ระบบงาน
- ตัวอย่าง code การใช้งาน tracing ด้วยภาษา Go
มาเริ่มกันเลย
ระบบงานมักจะประกอบด้วยส่วนการทำงานมากมาย
คำถามคือ เราควรมีอะไรมาช่วยดูหรือตรวจสอบการทำงานของระบบกันไหม ?
ในระบบงานต่าง ๆ นั้นควรจะมี Observability
เพื่อใช้ดูการทำงานของระบบ
เพื่อใช้ทดสอบการทำงานของระบบ ประกอบไปด้วย
- Audit logging
- Application metric
- Distributed tracing
- Health check API
- Exception tracking
- Log aggregation
- Log deployment and change
สิ่งต่าง ๆ เหล่านี้ล้วนเกิดมา
เพื่อช่วยให้เรารู้ปัญหาและแก้ไขได้รวดเร็วยิ่งขึ้น
หรือลดเวลา MTTR (Mean Time To Recovery)
ยกตัวอย่างเช่น
เราจะมี dashboard แสดงค่าต่าง ๆ และระบบ alert เพื่อแจ้งปัญหาให้เรารู้ได้ทันที
ซึ่งข้อมูลต่าง ๆ จะเป็นตัวเลขหรือ metric นั่นเอง
จากนั้นถ้าระบบงานประกอบไปด้วยส่วนตการทำงานมากมาย
คำถามคือ เราจะรู้ได้อย่างไรว่า
ปัญหาที่เกิดขึ้นของระบบนั้น มันอยู่ตรงส่วนไหน ?
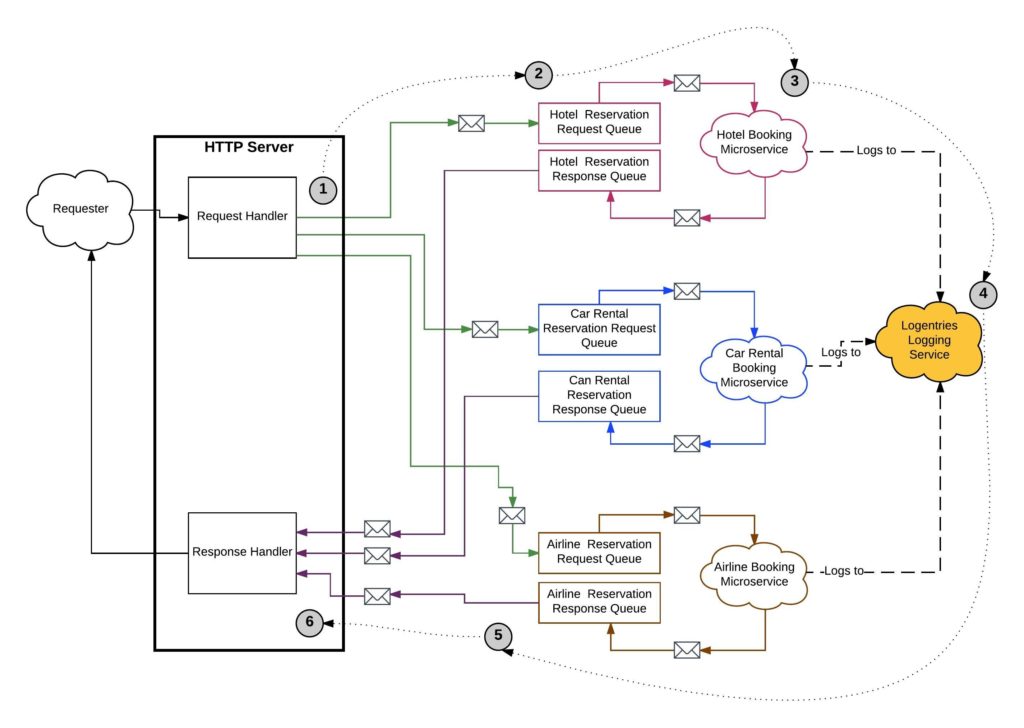
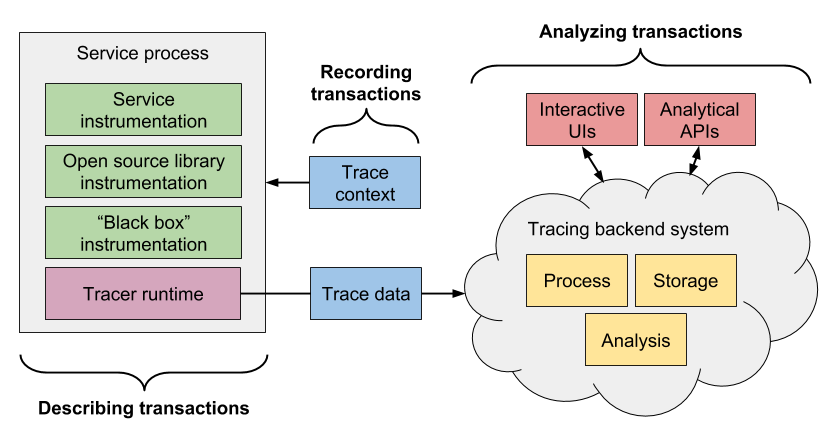
หนึ่งในวิธีการดูคือ การ Tracing นั่นเอง แสดงดังรูป
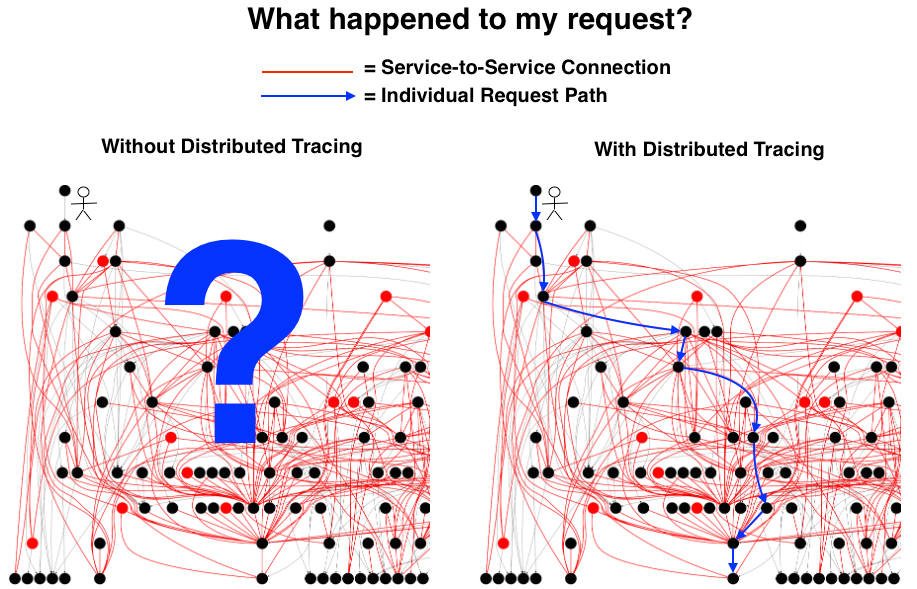
จากนั้นสามารถนำรายละเอียดเพิ่มเติมมาจาก logging ได้อีก
แต่จะนำมาใช้ไม่ได้เลย
ถ้าระหว่าง logging และ tracing ไม่มีสิ่งที่สัมพันธ์กัน
สิ่งนั้นก็คือ tracing id หรือ correlation id นั่นเอง แสดงดังรูป
ดังนั้นเรื่องของ tracing จึงมีความสำคัญขึ้นมา
ยิ่งในระบบที่อยู่อย่างกระจาย
หรือยิ่งมาสู่แนวทางของ Microservices ที่มี service จำนวนมากมาย
จึงเกิดแนวคิดของ Distributed tracing ขึ้นมา
ทำหน้าที่ tracking และ analyzing ว่าในแต่ละ request ที่เกิดขึ้นมานั้น
มันไปส่งผลหรือทำงานกับ service หรือส่วนการทำงานใดบ้าง
เพื่อทำให้เรารู้ได้อย่างทันท่วงที เหมือนกับการ X-Ray ร่างกายนั่นเอง
ระบบ Distributed tracing จะตอบคำถามเหล่านี้
- แต่ละ request ที่เกิดขึ้นมานั้น ผ่านส่วนการทำงานใดบ้าง
- ส่วนการทำงานใดเป็นปัญหาหรือเป็นคอขวดของระบบ
- ส่วนการทำงานใดที่ช้าทั้งจากการทำงานภายในและระบบ network
- แต่ละส่วนการทำงานเกิดอะไรขึ้นบ้าง นั่นคือต้องมีรายละเอียดของการทำงานด้วย
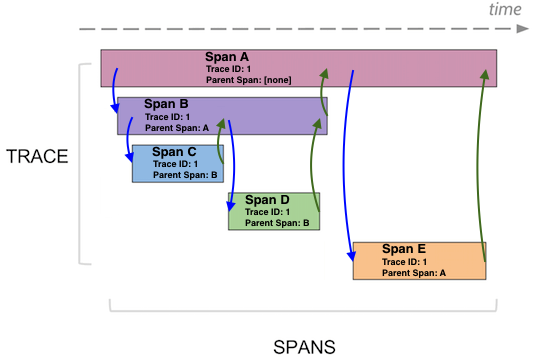
มาดูโครงสร้างของ Tracing กันบ้าง
ประกอบไปด้วย 2 คำคือ
- Trace คือภาพรวมของการทำงานในแต่ละ request โดยประกอบไปด้วย span จำนวนมาก
- Span คือส่วนการทำงานย่อย ๆ มีทั้งอยู่ใน service เดียวกันหรือต่าง service
ซึ่งในแต่ละ Span สามารถมีความสัมพันธ์กับแบบ parent-child
เพื่อทำให้เห็นลำดับการทำงานที่ชัดเจนมากยิ่งขึ้น
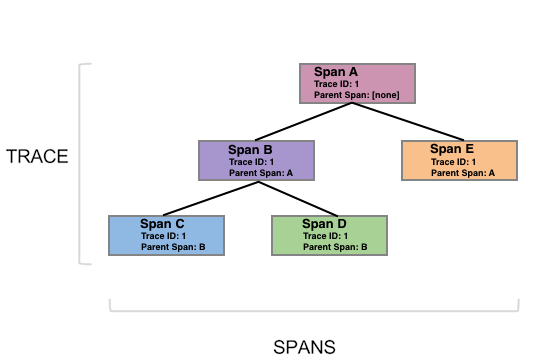
จากแนวคิดนี้จะเห็นได้ว่า มีสิ่งที่มีความสำคัญแต่ยังไม่พูดถึงคือ
- รูปแบบของ Tracing message เป็นอย่างไร
- จัดเก็บข้อมูล Tracing อย่างไร
- ทำการแสดงผลหรือวิเคราะห์อย่างไร
เรื่องของ Tracing message นั้น
ได้มีการกำหนดมาตรฐานขึ้นมา นั่นก็คือ
ทั้งสอง project มีส่วนการทำงานคล้าย ๆ กัน ตามจริงใช้แทนกันได้
แต่ OpenTracing นั้นเกิดมามีเป้าหมายเฉพาะ service เท่านั้น
ส่วน OpenCensus นั้นจะกว้างกว่าคือ
สามารถ integrate เข้ากับ software หรือระบบต่าง ๆ ไปเลย
แต่เท่าที่ไปดูทั้งสอง project มาพบว่า
มีแนวคิดที่ทำการรวมทั้งสอง project เข้าด้วยกัน ไว้ต้องลองดูกันต่อไป
ต่อมาก็เรื่องที่จัดเก็บและแสดงผลของ Tracing
จากที่เคยใช้มาจะมี
โดยใน meetup นั้นทำการเลือกใช้ Jaeger
ใช้ OpenTracing ในการจัดการรูปแบบของ tracing message
ซึ่งทำการสร้าง Trace ชื่อว่า service-1 ประกอบไปด้วย Span จำนวน 3 span คือ
- Call เป็น span ที่อยู่ภายใต้ trace
- step-1เป็น span ที่เป็นลูกของ span ที่ 1
- Span เป็น span ที่เป็นลูกของ span ที่ 2 แต่สามารถสร้างจาก context ได้
มาดูตัวอย่าง code กัน ซึ่งทำให้การทำ Tracing ง่ายขึ้น
ทั้งภายใน service เดียวกัน หรือ ต่าง service
ผลการทำงานจะส่งข้อมูลไปยัง Jaeger ดังรูป
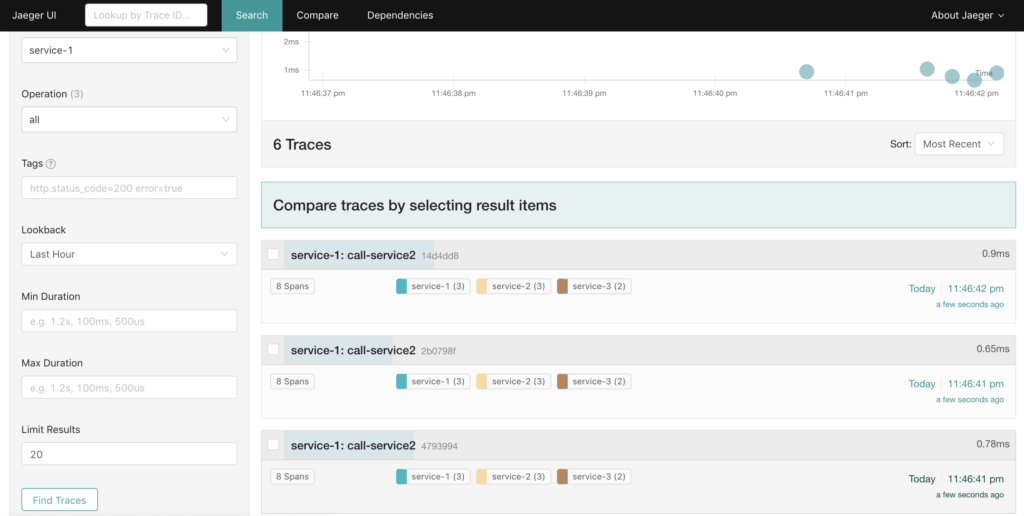
มาดูรายละเอียดของแต่ละ trace กัน
ช่วยทำให้เราเห็นการทำงานของระบบงานชัดเจนขึ้นมา
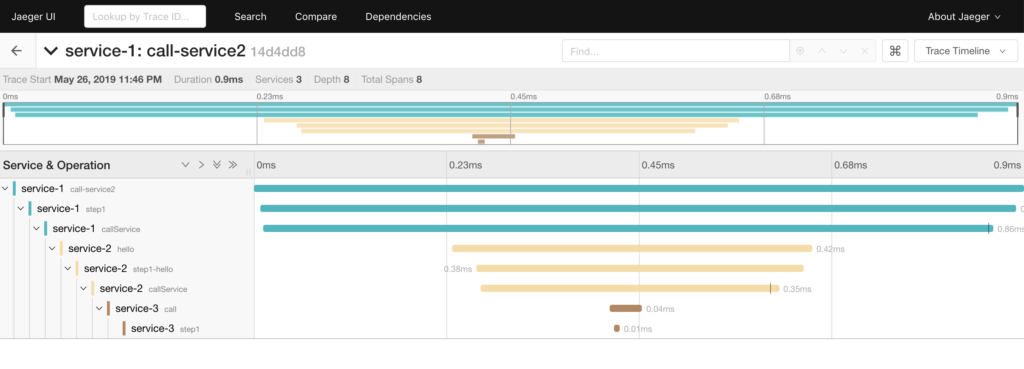
แถมทำการสร้าง graphความสัมพันธ์ของ service ต่าง ๆ ในระบบงานให้อีกด้วย

ตัวอย่าง code อยู่ที่ GitHub:Up1
Slide อยู่ที่ Slideshare