![]()
![]()
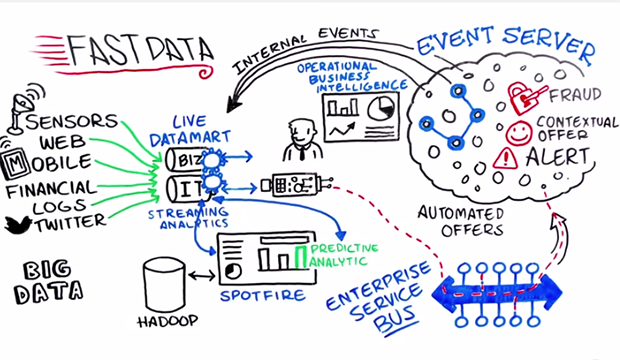
โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่
ขนาดของข้อมูลนั้นกลายเป็นเรื่องปกติไปแล้ว
ทั้งจาก business transaction, operation, logging และ IoT
แต่สิ่งที่สำคัญมากกว่าคือ
ความเร็วของระบบให้ทันต่อความต้องการ
เพื่อใช้ในการวิเคราะห์และตัดสินใจต่อไป
ยิ่งระบบสมัยใหม่ ทำการจัดเก็บข้อมูลการใช้งานเยอะมาก ๆ
ทั้งสถิติการใช้งาน เช่นการ click การ view และ การดู
เพื่อเรียนรู้พฤติกรรมการใช้งาน และ ปรับปรุงระบบได้อย่างทันท่วงที
ดังนั้นจำเป็นต้องมีกระบวนการจัดเก็บ ทำความสะอาด
วิเคราะห์ และแสดงผลได้เร็ว ดี ละเอียดและเข้าใจได้ง่าย
![]()
มีทางเลือกสำหรับระบบจัดการสิ่งต่าง ๆ เหล่านี้คือ
ซื้อ
ทำเอง
ให้คนอื่นทำให้
เลือกเอาเองนะครับ
แต่ในบทความนี้เราลองมาดูว่า โครงสร้างที่น่าจะเหมาะสมกับ Fast data เป็นอย่างไรบ้าง ?
ซึ่งต้องการให้การประมวลผลเร็ว ๆ
ดังนั้นน่าจะต้องคิดใหม่ ทำใหม่กัน
เพราะว่า จะมาประมวลผลแบบ batch หรือ offline คงไม่เพียงพอต่อความต้องการ
โดยในการจะสร้างระบบนั้นต้องพิจารณาในเรื่องของ
- การนำข้อมูลเข้าที่มีประสิทธิภาพ
- การจัดเก็บข้อมูลและการดึงข้อมูลที่ยืดหยุ่น
- การวิเคราะห์ข้อมูลที่สะดวกและหลากหลาย
- การแสดงผล
หรืออาจจะมองไปถึงเรื่องของ
Reactive คือ การขยายเข้าหรือออกตามความต้องการได้
Resilient และ
Responsive คือ สามารถทำงานได้ แม้จะมีส่วนใด ๆ ที่ล่มไป
มาดูในแต่ละส่วนกัน
1. การนำข้อมูลเข้า
โดยข้อมูลเข้ามีที่มามากมาย
มีรูปแบบที่แตกต่างกันเช่น plain text, JSON, XML
เป็นส่วนที่บอกว่า ข้อมูลจะเข้ามาสู่ระบบมากน้อยเพียงใด
โดยปกติจะมีขั้นตอนดังนี้
- Parsing
- Validation
- Cleansing
- De-duping
- Transformation
แนวทางที่น่าสนใจของการนำข้อมูลเข้าคือ
การทำงานควรเป็นแบบ Asynchronous
เช่นการส่งข้อมูลในแต่ละขั้นตอน ถ้ามารอกันคงช้าน่าดู
ส่วนพวกการทำ parsing จนถึง transform ข้อมูลนั้นใช้ resource ต่าง ๆ เยอะมาก
ดังนั้นก็ควรทำงานแบบขนานกันไปด้วย
นั่นคือ ควรมีการนำระบบ Messaging-Oriented Middleware (MOM) มาใช้
ซึ่งมีเครื่องมือต่าง ๆ มากมายเช่น
- Apache Kafka
- Akka Stream
- ActiveMQ
- RabbitMQ
- JBoss AMQ
โดยตัวที่แนะนำ คือ Apache Kafka
2. การจัดเก็บข้อมูล
แนะนำให้ทดลองใช้งานหลาย ๆ อย่าง
เพื่อให้เข้าใจ
เพื่อให้รู้ว่าเหมาะหรือไม่กับระบบงานของเรา
ซึ่งเชื่อเถอะว่า ทุก ๆ ปัญหาที่เราพบเจอนั้น มักจะมี solution หรือการแก้ไขไว้แล้ว
ดังนั้นไม่จำเป็นต้องสร้างขึ้นมาใหม่จากศูนย์เอง
ทั้งปัญหาเรื่องการอ่านข้อมูล
ทั้งปัญหาเรื่องการเขียนข้อมูล
ทั้งปัญหาเรื่องการแก้ไขข้อมูล
โดยที่จัดเก็บข้อมูลที่ดีจะช่วยลด
เวลาในการออกแบบ
เวลาในการประมวลผล
เวลาในการ transfer ข้อมูล
ประหยัดที่จัดเก็บ
ต่อมาสิ่งที่นำมาใช้งานต้องสามารถ configuration ได้ง่าย
และปรับแต่งตามที่ต้องการได้
ทั้งการ replication และ ความถูกต้องของข้อมูล
ในส่วนของการออกแบบ data model นั้น
มันขึ้นอยู่กับระบบและการนำไปใช้งาน
แต่ให้เน้นไปที่ performance เป็นหลัก
ในส่วนของเครื่องมือก็มีให้เลือกใช้เพียบ เช่น
- Apache Cassandra
- Couchbase
- Apache Hive
- Riak
- Redis
- MongoDB
- MariaDB
โดยตัวที่แนะนำ คือ Apache Cassandra
3. การประมวลผลข้อมูล
สำหรับระบบ Fast data นั้นมีการประมวลผลทั้ง Batching และ Streaming รวมกันไป
นั่นคือเลือกวิธีการให้เหมาะสมกับงานนั่นเอง
ยกตัวอย่างเช่น
ระบบงานต้องการการทำงานแบบ realtime คงไม่ใช้วิธีการแบบ batching หรอกนะ
หรือถ้ามีระบบ ETL แบบเดิม ๆ อยู่ ซึ่งทำงานแบบ bacthing
คงไม่มีใครบ้าระห่ำย้ายมาทำงานแบบ realtime หรือ streaming หมดหรอกนะ
โดยที่เครื่องมือบางตัวอาจจะแบ่งการทำงานเป็นส่วนเล็ก ๆ
แต่ละส่วนการทำงานจะทำงานแบบ bactching หรือ micro-batching
จากนั้นตัวควบคุมการทำงานหลักทำงานแบบ streaming
ซึ่งวิธีการทำงานแบบนี้จะเรียกว่า hybrid
อีกเครื่องคือ จะทำการบน disk หรือ memory ดีละ
ก็เหมือนข้างต้นนั่นเอง
ทำงานบน disk ไปหมดก็ไม่ดี มันช้า
ทำงานบน memory ไปหมดก็ไม่ได้ มันเปลือง
เราพูดถึงความเร็วคือ data locallly มากกว่า
นั่นคือ ประมวลผลข้อมูลที่อยู่ใกล้ ๆ
ซึ่งเร็วต่อการทำงาน และ transfer ข้อมูล
ดังนั้นเครื่องมือหลาย ๆ ตัว
จะทำงานแบบการกระจายข้อมูลไปในแต่ละที่
จากนั้นจึงรวมผลการทำงานเข้าด้วยกัน
คุ้น ๆ กับวิธีการทำงานหรือไม่ ?
โดยเครื่องมือมีให้ใช้เยอะมาก ๆ ยกตัวอย่างเช่น
- Apache Spark
- Apache Flink
- Apache Storm
- Apache Beam
- Tensorflow
โดยตัวที่แนะนำ คือ Apache Spark สำหรับ micro-batching และ Apache Flink สำหรับ streaming
4. การแสดงผลข้อมูล
เป็นส่วนที่ใช้อธิบายผลการประมวลผลข้อมูลให้ผู้ใช้งานทั่วไปเข้าใจได้ง่าย
เป็นขั้นตอนที่ไม่ง่ายเลย
เนื่องจากต้องใช้ศาตร์และศิลป์เยอะสูงมาก ๆ
ที่สำคัญต้องโดนใจ ถูกต้อง เข้าใจง่ายและเร็ว
ดังนั้น การ process เยอะ ๆ ในขณะแสดงผลเป็นสิ่งต้องห้ามอย่างมาก
ข้อมูลก่อนนำมาแสดงผล ต้องเป็นข้อมูลที่สรุปมาแล้ว
เช่นข้อมูลตามหมวดหมู และ ตามช่วงเวลาเป็นต้น
ข้อมูลแต่ละชุดทำขึ้นมาเพื่อการแสดงผลแบบเฉพาะเจาะจงเท่านั้น
อย่านำข้อมูลชุดเดียวแล้วไปแสดงในทุกรูปแบบ
มิเช่นนั้นจะช้าอย่างมาก
ส่วนของเครื่องมือก็เยอะนะ ยกตัวอย่างเช่น
- Notebook report เช่น Jupiter notebook และ Apache Zeppelin
- Tableau
- D3.js
- Gephi
แต่ทั้งหมดนี้ ต้องการ infrastructure ที่ดีด้วยเช่นกัน
ดังนั้น operation จำเป็นต้องปรับและเปลี่ยนด้วย
จากที่เคยทำแต่ scale-up ต้องเปลี่ยนมาเป็น scale-out
รวมทั้งเรื่องการนำ opensource มาใช้งาน
แนวคิดและแนวปฏิบัติ DevOps จึงมีความสำคัญอย่างมาก
เพื่อลดการ rework ต่าง ๆ ลงไป
เช่นทีมพัฒนาสามารถทดสอบระบบ
บน environment ที่เหมือนหรือคล้ายกับ production เป็นต้น
ส่วนของเครื่องมีในการจัดการก็มีเยอะมากเช่นเดิม
- Docker
- Kubernetes
- Spinnaker
- Apache Mesos
ทั้งหมดนี้เป็นคำแนะนำเล็ก ๆ น้อย ๆ สำหรับระบบ Fast Data
เพื่อช่วยทำให้การจัดการข้อมูลมีประสิทธิภาพที่ดีขึ้นตั้งแต่
การนำข้อมูลเข้า
การจัดเก็บข้อมูล
การประมวลผลข้อมูล
การแสดงผลข้อมูล
Reference Websites
https://www.oreilly.com/ideas/from-big-data-to-fast-data

 โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่
โดยปกตินั้นข้อมูลมีการเปลี่ยนแปลงอยู่เสมอ
ยิ่งในปัจจุบันอัตราการเปลี่ยนแปลงสูงมาก ๆ
ทั้ง Volume, Velocity และ Variety
ทำให้เครื่องมือต่าง ๆ ที่มีอยู่อาจจะไม่เพียงพอต่อความต้องการ
ทั้งการจัดเก็บ
ทั้งการรวบรวม
ทั้งการวิเคราะห์ ประมวลผล ซึ่งมีความซับซ้อน
และต้องการให้ทำงานแบบ realtime
ดังนั้นเราต้องการวิธีการใหม่ เครื่องมือใหม่ ๆ architecture ใหม่