![]()
![]()
จากบทความเรื่อง
Demystifying Data Science For All
ทำการบักทึกการพูดเกี่ยวกับ The Practice of Data Science
หรือแนวปฏิบัติของ Data Science ประกอบไปด้วย
- People คือ คน หน้าที่ และ ความสามารถ ต้องทำงานเป็นทีม
- Process คือขั้นตอนการทำงานของ Data Science
- Tool คือเครื่องมือและ platform ต่าง ๆ
มีความน่าสนใจอย่างมาก
จึงทำการแปลและสรุปไว้นิดหน่อย
Data Science คืออะไร
คือแนวทางในการ extract value หรือการสะกัดเอาคุณค่า ความรู้และ insight จากข้อมูล
โดยใช้วิธีการจาก Computer Science และสถิติ
ประโยชน์ที่ได้รับคือ
ช่วยให้เราตัดสินใจได้ดีขึ้น
พร้อมทั้งการสร้างและปรับปรุง algorithm ต่าง ๆ
เพื่อให้ผลลัพธ์ที่ได้ดีขึ้นอีกด้วย
ทำไม Data Science จึงมีความสำคัญ
มี 2 เหตุผลหลักคือ
1. จำนวนข้อมูลที่มีจำนวนเยอะมาก ๆ (Big Data)
2. ประสิทธิภาพของหน่วยประมวลผลที่สูงมาก ๆ (Technology เช่น GPU และ High Performance Computing)
ดังนั้นสิ่งที่เราต้องการคือ
Data professional (คนที่มีความสามารถใน Data Science)
ซึ่งสามารถนำ data และ technology มาใช้
เพื่อเข้าถึง insight และเข้าใจของสิ่งต่าง ๆ ที่ยังไม่รู้
แน่นอนว่า มีความต้องการคนในด้านนี้สูงมาก ๆ
ในบทความจะอธิบาย Data Science ไว้ 3 ส่วนคือ People, Process และ Tool
1. People
จากผลการสำรวจจาก Data professional กว่า 500 คนว่า ทำอะไรบ้าง ?
เพื่อต้องการทำความเข้าใจว่า
ทำงานอะไร อย่างไร ?
มีตำแหน่ง หน้าที่รับผิดชอบอะไรบ้าง ?
มีความสามารถอะไรบ้าง ?
ได้ผลดังนี้
- ตำแหน่ง Researcher มากที่สุด ( Scientist และ นักสถิติ )
- ตำแหน่งรองลงมาคือ Domain Expert, Creative และ Developer
- ความสามารถใน Data Science แบ่งออกเป็น 25 เรื่อง
- แบ่งกลุ่มความสามารถใน Data Science ออกเป็น 5 กลุ่ม ประกอบไปด้วย Business Domain, Math/Statistic, Technology และ Programming
แสดงดังรูป
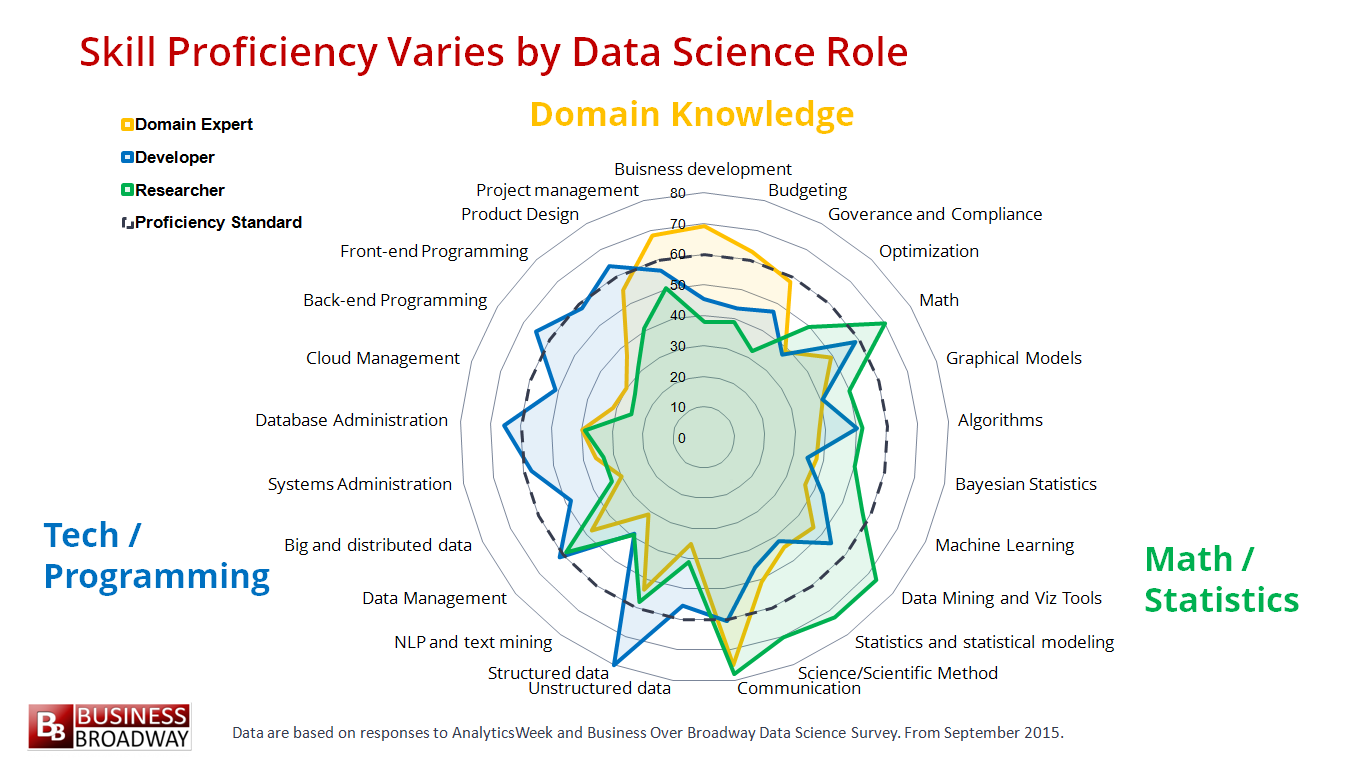
![]() ในแต่ละตำแหน่งก็จะมีความสามารถที่แตกต่างกันไป
ในแต่ละตำแหน่งก็จะมีความสามารถที่แตกต่างกันไป
ยกตัวอย่างเช่น
กลุ่มของ Researcher หรือนักวิจัย มีความสามารถเด่นในกลุ่ม Math/Statistic
กลุ่มของ Data pros หรือ Developer มีความสามารถเด่นในกลุ่มของ Technology/Programming
กลุ่มของ Business manager หรือ Domain Expert มีความสามารถเด่นในกลุ่มของ Domain knowledge
ปล. ในบทความบอกว่า ไม่ชอบตำแหน่ง Data Scientist
เนื่องจากมันเป็นชื่อที่คลุมเครือหรือไม่ชัดเจนเลย
ว่าต้องมีหน้าที่และความสามารถอะไรบ้าง ?
การที่จะหาคนที่มีความสามารถเด่นในทุกกลุ่มนั้นมันยากมาก ๆ
ดังนั้นการทำงานเป็น
ทีมจึงมีความสำคัญอย่างมากนั่นคือ
Domain Expert เพื่อช่วยกำหนดปัญหา ตั้งสมมุติฐาน และอธิบายผล
Developer เพื่อช่วยเข้าถึงข้อมูลในส่วนต่าง ๆ ที่ต้องการ
Researcher เพื่อช่วยสร้างและรวมข้อมูล วิเคราะห์ข้อมูล และอธิบายผล
2. Process
ขั้นตอนเพื่อให้ได้มาซึ่ง insight และความรู้จากข้อมูลมันสำคัญมาก ๆ
ทั้ง Analytic, Data mining และ Data science workflow
โดยที่ Data professional ควรมีขั้นตอนการทำงานที่ชัดเจน
จากผลการสำรวจพบว่าขั้นตอนที่ได้รับความนิยมประกอบไปด้วย
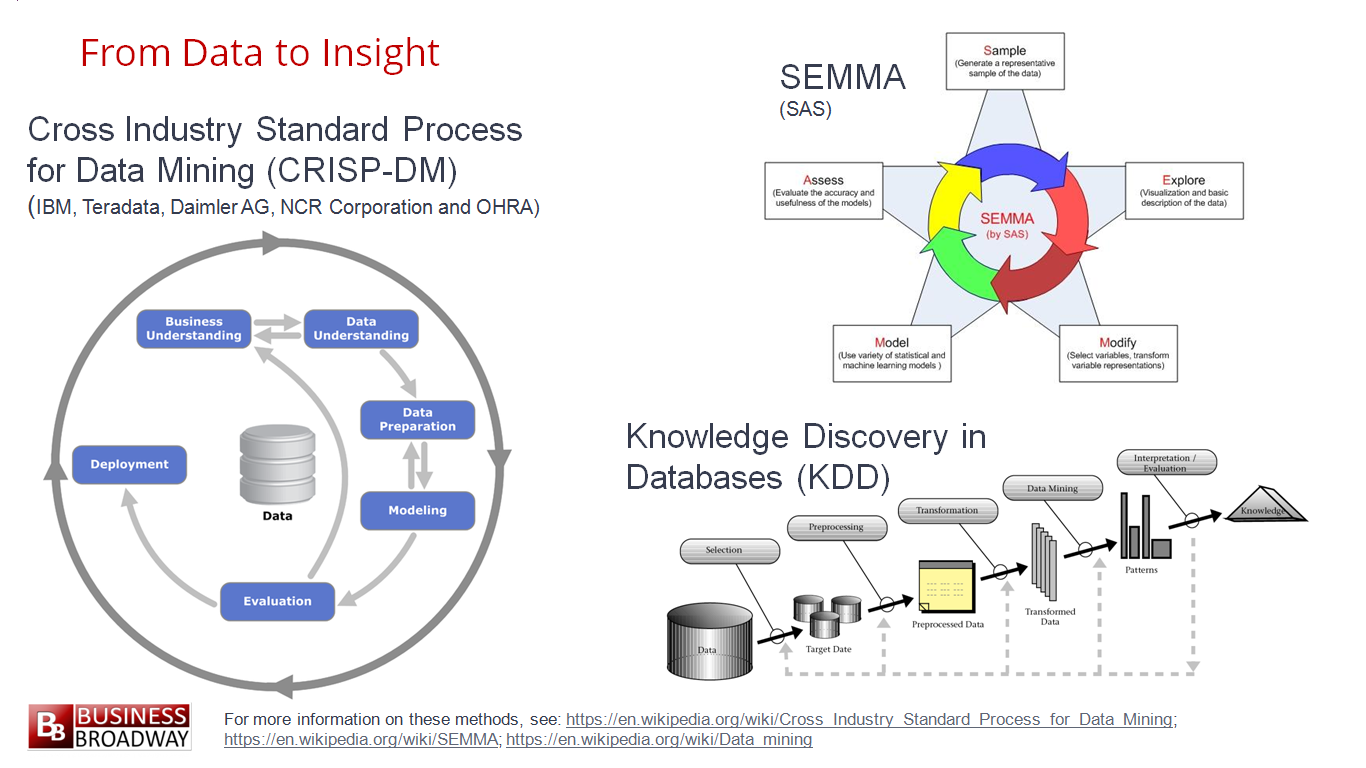
- CRISP-DM (CRoss Industry Standard Process for Data Mining)
- SEMMA (Sample Explore Modify Model Assess)
- KDD (Knowledge Discovery in Databases)
ในแต่ละวิธีการนั้นทำการอธิบายขั้นตอนการทำงานต่าง ๆ
ทั้ง data selection
ทั้ง data preparation
ทั้ง data modeling
ทั้ง data model deployment
ความแตกต่างที่เห็นได้อย่างชัดเจนของทั้ง 3 วิธีการคือ
CRISP-DM นั้นจะเริ่มด้วยความรู้ความเข้าใจทาง business ก่อน
เพื่อช่วยให้การทำงานในขั้นตอนอื่น ๆ ชัดเจนมากยิ่งขึ้น
แสดงดังรูป
![]() โดยที่วิธีการต่าง ๆ นั้นคล้ายกับ Scientific Method เลย
โดยที่วิธีการต่าง ๆ นั้นคล้ายกับ Scientific Method เลย
เป็นสิ่งที่นักวิทยาศาสตร์ใช้กันมานานแล้ว
สำหรับการเข้าถึง insight ของข้อมูล
เพื่อให้ได้ความรู้ใหม่ ๆ
เพื่อให้ได้ความถูกต้องมากยิ่งขึ้น
เพื่อนำเอาความรู้ที่มีอยู่มารวมหรือทำงานร่วมกัน
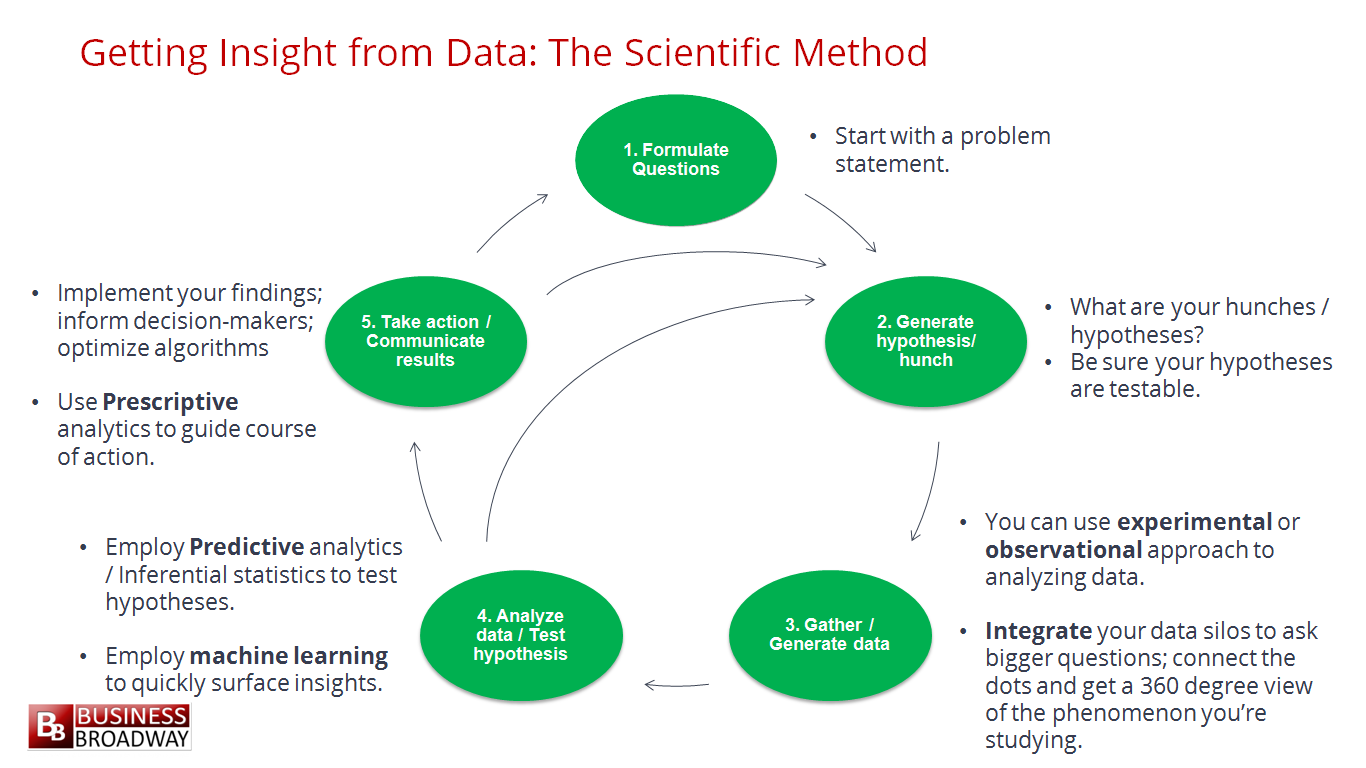
มีการทำงาน 5 ขั้นตอนดังนี้
1. Formulate a question
2. Generate a hypothesis
3. Gather/Generate data
4. Analyze data
5. Communicate results หรือ Take action จากข้อสรุปต่าง ๆ
แสดงดังรูป
![]()
ปล. ในบทความอธิบายว่า
คำว่า Data Science นั้นใช้คำซ้ำกันเกินไป
เนื่องจาก Science นั้นต้องใช้ข้อมูลอยู่แล้ว
เพื่อทำการทดสอบข้อสันนิษฐานและแนวคิดต่าง ๆ
นั่นคือ Data หรือข้อมูล คือหัวใจของ Science
ดังนั้น Data Science คือ Science
3. Tool
สิ่งที่ขาดไม่ได้เลยคือ เครื่องมือ และ platform
เพื่อช่วยทำให้เข้าถึงข้อมูลได้ตามที่ต้องการ
ทั้งการจัดการข้อมูล
ทั้งการรวมข้อมูลจากกลากหลายแหล่ง
ทั้งการวิเคราะห์
ทั้งการแสดงผล
Data Science Tool
เป็นเครื่องมือที่ใช้ในการเข้าถึงและวิเคราะห์ข้อมูล
จากผลการสำรวจพบว่า
เครื่องมือที่เหล่า Developer หรือ Data pros นิยมใช้ประกอบไปด้วย
R, Python, SQL, IBM SPSS และ SAS
Data Science Platform
เป็นสิ่งที่ทำให้ Data professional จากหลากหลายส่วน
ทำงานร่วมกันได้อย่างราบรื่นและมีประสิทธิภาพ
ทั้งการจัดการข้อมูล
ทั้งการรวมข้อมูลจากกลากหลายแหล่ง
ทั้งการวิเคราะห์
ทั้งการแสดงผล
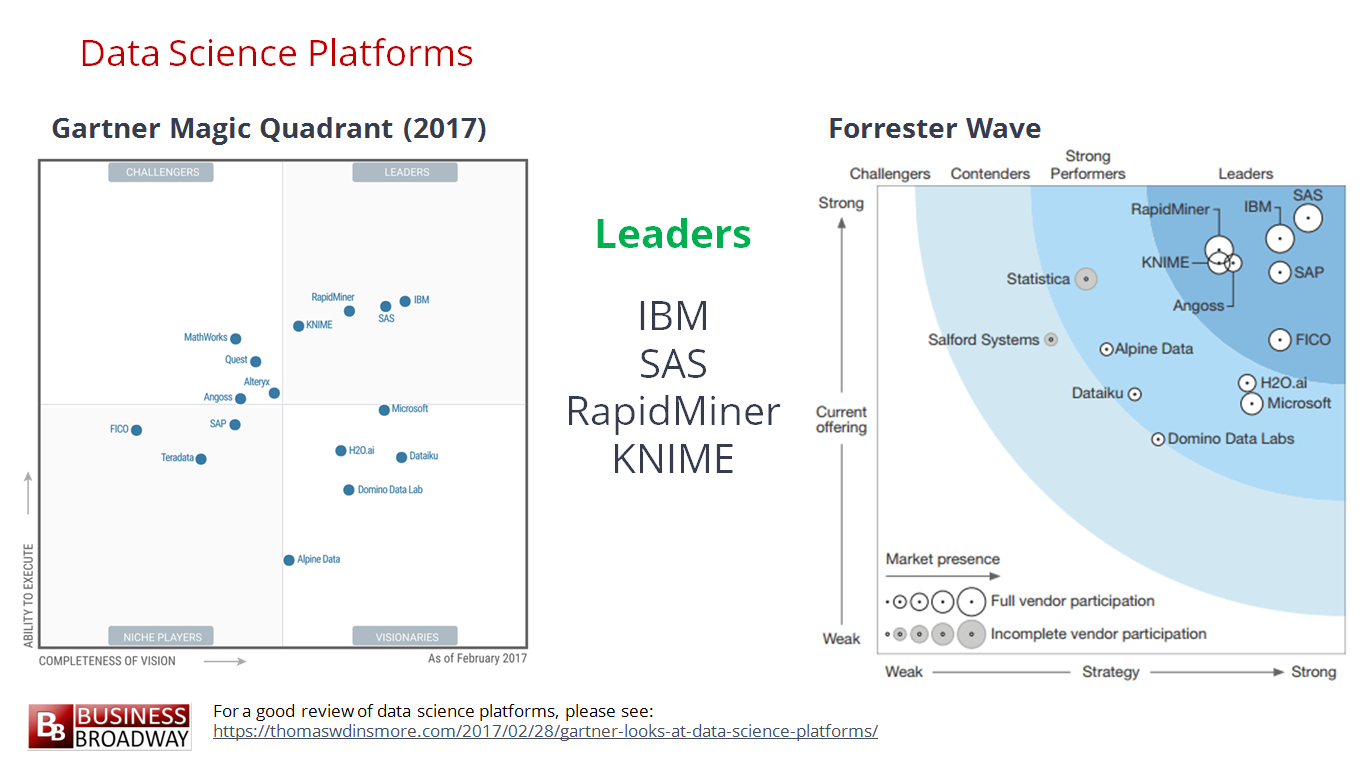
โดย platform ที่อยู่ในอันดับต้น ๆ ประกอบไปด้วย
IBM, SAS, RapidMiner และ KNIME
แสดงดังรูป
![]()
ขอให้สนุกกับโลกของ Data ครับ

 จากบทความเรื่อง Demystifying Data Science For All
ทำการบักทึกการพูดเกี่ยวกับ The Practice of Data Science
หรือแนวปฏิบัติของ Data Science ประกอบไปด้วย
จากบทความเรื่อง Demystifying Data Science For All
ทำการบักทึกการพูดเกี่ยวกับ The Practice of Data Science
หรือแนวปฏิบัติของ Data Science ประกอบไปด้วย
 ในแต่ละตำแหน่งก็จะมีความสามารถที่แตกต่างกันไป
ยกตัวอย่างเช่น
กลุ่มของ Researcher หรือนักวิจัย มีความสามารถเด่นในกลุ่ม Math/Statistic
กลุ่มของ Data pros หรือ Developer มีความสามารถเด่นในกลุ่มของ Technology/Programming
กลุ่มของ Business manager หรือ Domain Expert มีความสามารถเด่นในกลุ่มของ Domain knowledge
ในแต่ละตำแหน่งก็จะมีความสามารถที่แตกต่างกันไป
ยกตัวอย่างเช่น
กลุ่มของ Researcher หรือนักวิจัย มีความสามารถเด่นในกลุ่ม Math/Statistic
กลุ่มของ Data pros หรือ Developer มีความสามารถเด่นในกลุ่มของ Technology/Programming
กลุ่มของ Business manager หรือ Domain Expert มีความสามารถเด่นในกลุ่มของ Domain knowledge
 โดยที่วิธีการต่าง ๆ นั้นคล้ายกับ Scientific Method เลย
เป็นสิ่งที่นักวิทยาศาสตร์ใช้กันมานานแล้ว
สำหรับการเข้าถึง insight ของข้อมูล
เพื่อให้ได้ความรู้ใหม่ ๆ
เพื่อให้ได้ความถูกต้องมากยิ่งขึ้น
เพื่อนำเอาความรู้ที่มีอยู่มารวมหรือทำงานร่วมกัน
มีการทำงาน 5 ขั้นตอนดังนี้
1. Formulate a question
2. Generate a hypothesis
3. Gather/Generate data
4. Analyze data
5. Communicate results หรือ Take action จากข้อสรุปต่าง ๆ
แสดงดังรูป
โดยที่วิธีการต่าง ๆ นั้นคล้ายกับ Scientific Method เลย
เป็นสิ่งที่นักวิทยาศาสตร์ใช้กันมานานแล้ว
สำหรับการเข้าถึง insight ของข้อมูล
เพื่อให้ได้ความรู้ใหม่ ๆ
เพื่อให้ได้ความถูกต้องมากยิ่งขึ้น
เพื่อนำเอาความรู้ที่มีอยู่มารวมหรือทำงานร่วมกัน
มีการทำงาน 5 ขั้นตอนดังนี้
1. Formulate a question
2. Generate a hypothesis
3. Gather/Generate data
4. Analyze data
5. Communicate results หรือ Take action จากข้อสรุปต่าง ๆ
แสดงดังรูป
 ขอให้สนุกกับโลกของ Data ครับ
ขอให้สนุกกับโลกของ Data ครับ