![]()
![]()
หลังจากที่ดู VDO เรื่อง
The Evolution of Reddit.com's Architecture
ทำการอธิบาย architecture ของระบบ
Reddit.com
ว่าเป็นอย่างไรบ้าง
ใช้อะไรบ้าง
มีวิวัฒนาการอย่างไรบ้าง
มาดูกันนิดหน่อย น่าจะพอมีประโยชน์สำหรับการพัฒนาระบบงาน
สิ่งที่น่าสนใจคือ architecture นั้นจะถูกปรับเปลี่ยนไปตามปัญหาที่เกิดขึ้น
สถิติที่น่าสนใจก่อนดู architecture คือ
- 1 ล้าน post ต่อวัน
- 5 ล้าน comment ต่อวัน
- 75 ล้าน vote ต่อวัน
- ค้นหา 70 ล้านครั้งต่อวัน
มาดู Architecute หลักกันหน่อย
![]() คำอธิบาย
คำอธิบาย
- Frontend พัฒนาด้วย Node.js
- R2 คือ monolith system เป็นระบบดั้งเดิมพัฒนาด้วยภาษา Python ตั้งแต่ปี 2008 (ชื่อคุ้น ๆ นะ R2)
- API, Search, Thing, Listing และ Rec คือ service ที่ถูกแยกออกมาจาก R2 ยังพัฒนาด้วยภาษา Python เช่นเดิม
- Protocol ที่ใช้สื่สารระหว่าง client-service คือ HTTP และ Thrift ซึ่งขึ้นอยู่กับ client
- ใช้ CDN (Content Network Delivery) ในการแยก request ไปยังส่วนงานต่าง ๆ
สิ่งที่น่าสนใจมาก ๆ คือ R2
ซึ่งเป็นระบบดั้งเดิมของ Reddit.com
แน่นอนว่ามันมีความซับซ้อนสูงมาก
เพราะว่าทุกสิ่งอย่างรวมกันอยู่ที่นี่
การ deploy ก็ต้อง deploy code เหมือนกันในทุก ๆ server
ทั้ง ๆ ที่แต่ละเครื่องก็แยกทำงานต่างกัน
แต่ด้วยความเป็น
monolith จึงต้องทำแบบนี้
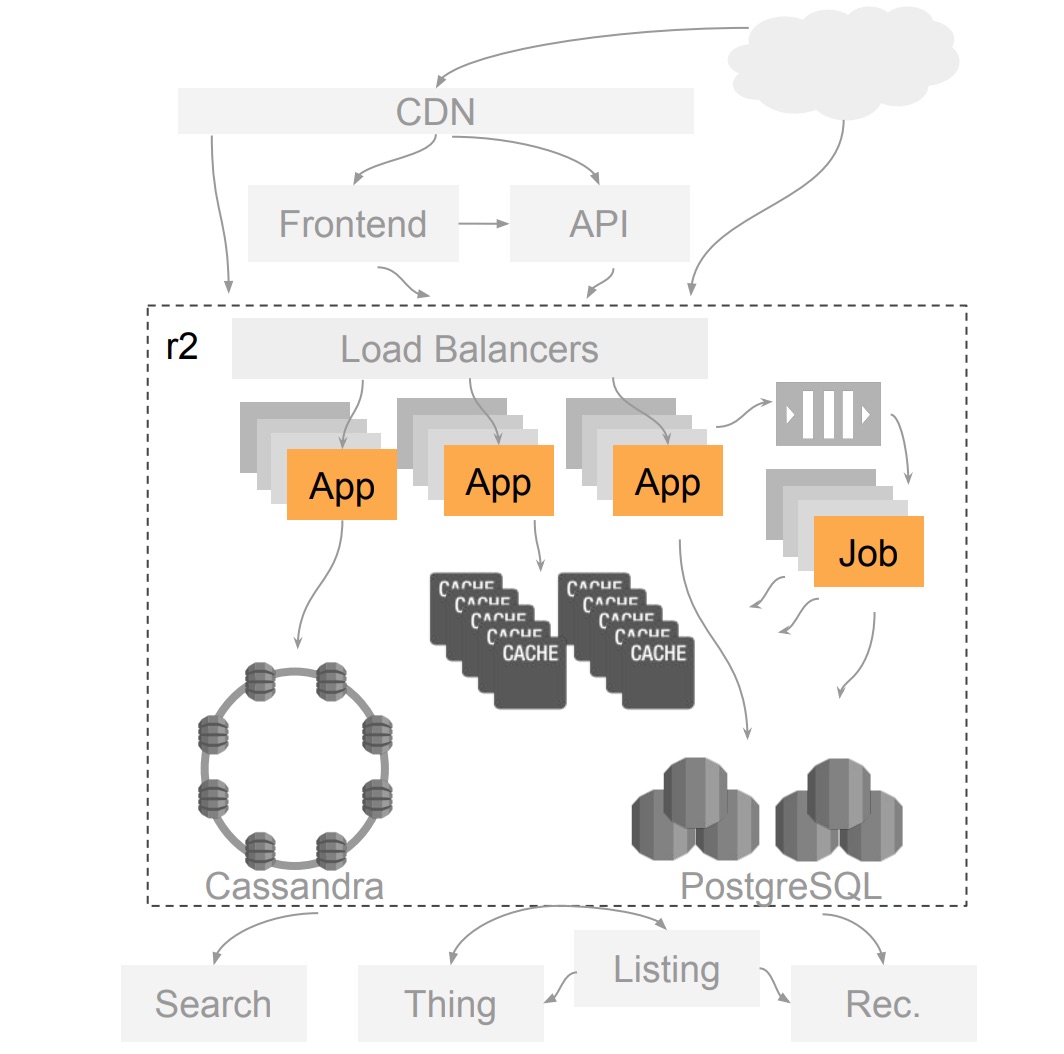
ใช้ Load Balance ในการกระจายงานไปยัง app หรือ service ต่าง ๆ
ส่วนงานที่ทำงานแบบ asynchronous จะผ่านระบบ Job Queue (
RabbitMQ)
Caching นั้นใช้
Memcached ในการจัดการ
ถ้าระบบฐานข้อมูลหลักจะใช้
PostgreSQL (Relational) และ
ThinkDB (Key-value)
ส่วนการเขียนหนัก ๆ จะใช้
Cassandra ซึ่ง feature ใหม่ ๆ จะใช้ทั้งหมด
แสดงดังรูป
![]()
มาดูใน service สักตัว คือ Listing service
มีความน่าสนใจเป็นอย่างมาก
สำหรับการแสดงรายชื่อของหัวข้อต่าง ๆ นั่นเอง
เช่น hot, new และ top เป็นต้น
แสดงดังรูป
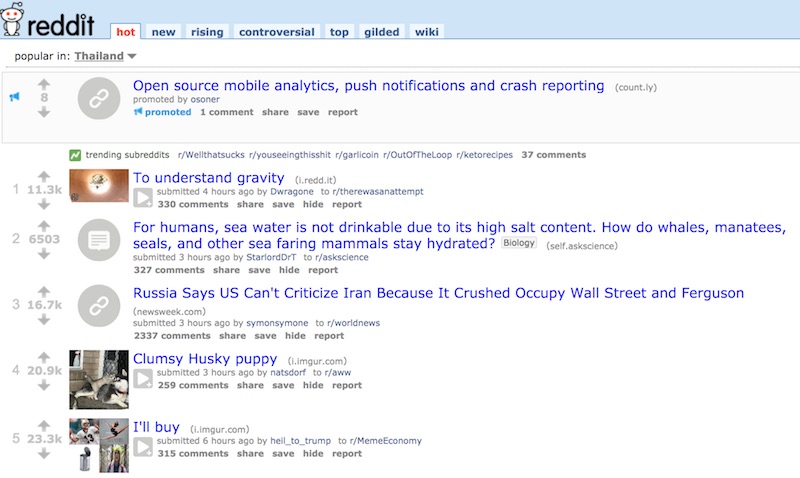
![]() ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ถ้าเป็นคำสั่ง SQL ทั่วไปก็เพียง
select * from links order by hot(ups, downs);
ส่วนผลการดึงข้อมูลก็ทำ caching ไว้
โดยที่ caching จะถูกทำลายเมื่อมีหัวข้อใหม่และมีการ vote !!
ถ้าดูจากสถิติของการ vote แล้ว
คิดว่า caching มันจะช่วยอะไรไหม ?
แน่นอนว่า ไม่ได้ช่วยอะไรเลย !!
เพราะว่าข้อมูลมันเปลี่ยนอยู่ตลอดเวลา
ดังนั้นจึงเกิดแนวคิดใหม่ ๆ เพื่อแก้ไขปัญหา
การแก้ไขปัญหาในเบื้องต้นคือ
คือการ denormalize ข้อมูลจากนั้น
เขียนข้อมูลไปที่ Cassanda
อ่านข้อมูลจาก Memcached
ส่วนเรื่องของการ vote นั้น
จะส่งไปยัง Vote queue (RabbitMQ)
ทำให้การระบบทำงานได้ดีขึ้น caching มีประสิทธิภาพดีขึ้น
แต่ว่าปัญหาเกิดขึ้นมาอีกเมื่อกลางปี 2012
พบว่ามีช่วงที่การใช้งานสูงมาก ๆ
ทำให้การ vote ช้ามาก ๆ
เนื่องจากมีงานค้างใน Vote queue สูงมาก
บางงานรอนานถึง 1 ชั่วโมง
ซึ่งโดนผู้ใช้งานด่ามาอย่างมาก !!
การแก้ไขคือ
เพิ่มจำนวน processor consumer ให้มากขึ้น
วิธีการนี้กลับทำให้แย่ลง !!
ดังนั้นจึงต้องคิดใหม่ ประกอบไปด้วย
- ทำการ lock vote processor/consumer ไม่ให้ทำงานในช่วงเวลาหนึ่ง หรือการตั้ง timer นั่นเอง ให้เท่ากับเวลาประมวลผล
- ทำการแบ่งของ Job queue ออกตาม Subreddit
ทำให้สถานการณ์ของระบบดีขึ้น กลับมาปกติ
แต่ว่าปลายปี 2012 ก็เกิดปัญหาขึ้นมาอีก !!
ระบบการทำงานช้าลงอีกแล้ว
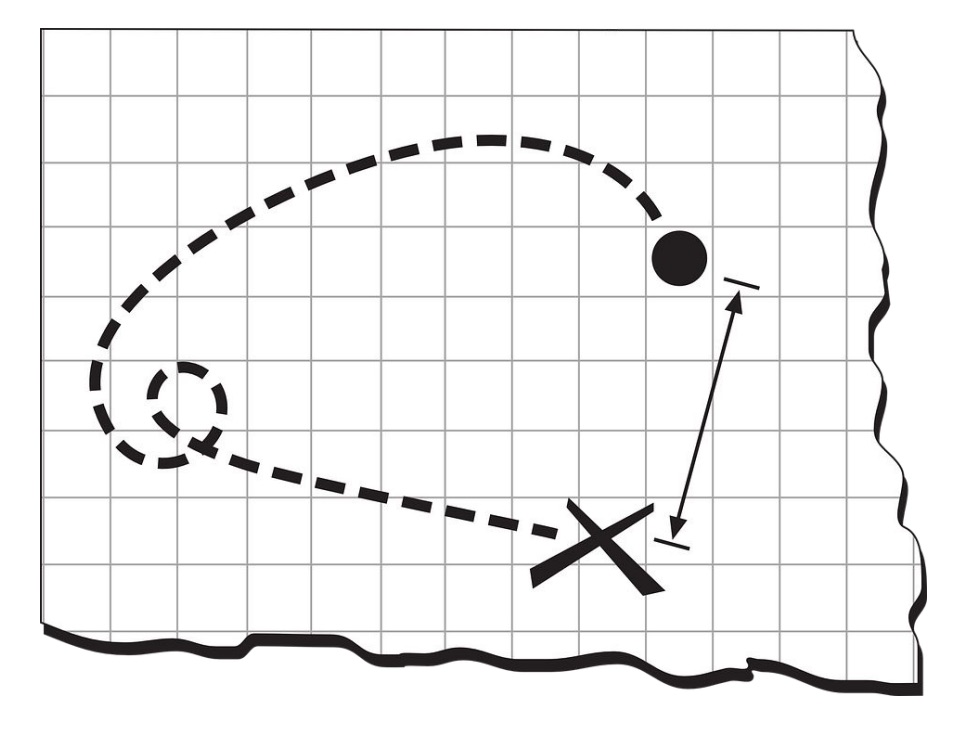
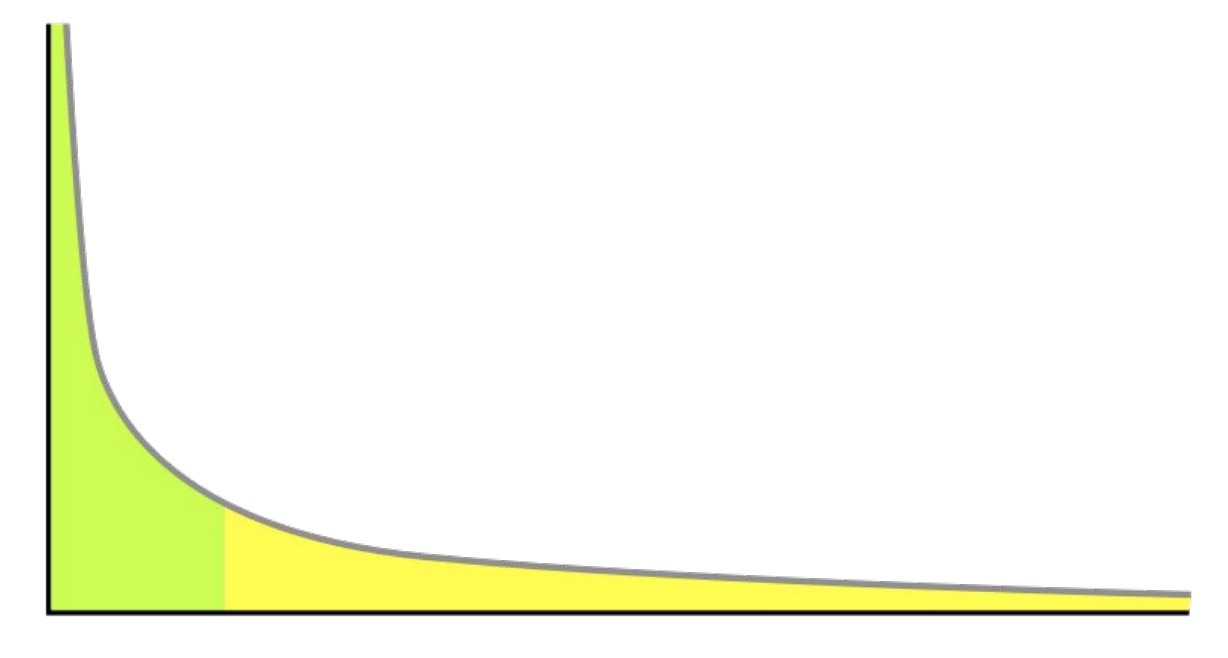
เมื่อดูข้อมูลจากค่าเฉลี่ยของเวลาการ lock และ processing ก็ดูดี
แต่ปัญหาที่แท้จริงอยู่ที่
99th percentile
นั่นคือการ vote ในกลุ่มย่อย ๆ เข้าไปอีก ทำงานช้ามาก ๆ
![]() เมื่อลงไปดูในรายละเอียดพบว่า
เมื่อลงไปดูในรายละเอียดพบว่า
มีการ post link ของ domain อื่น ๆ เข้ามายัง Reddit.com เยอะมาก ๆ
หนึ่งในนั้นคือ imgur.com
ซึ่งส่งผลต่อการเปลี่ยนแปลงการ caching ของ Listing
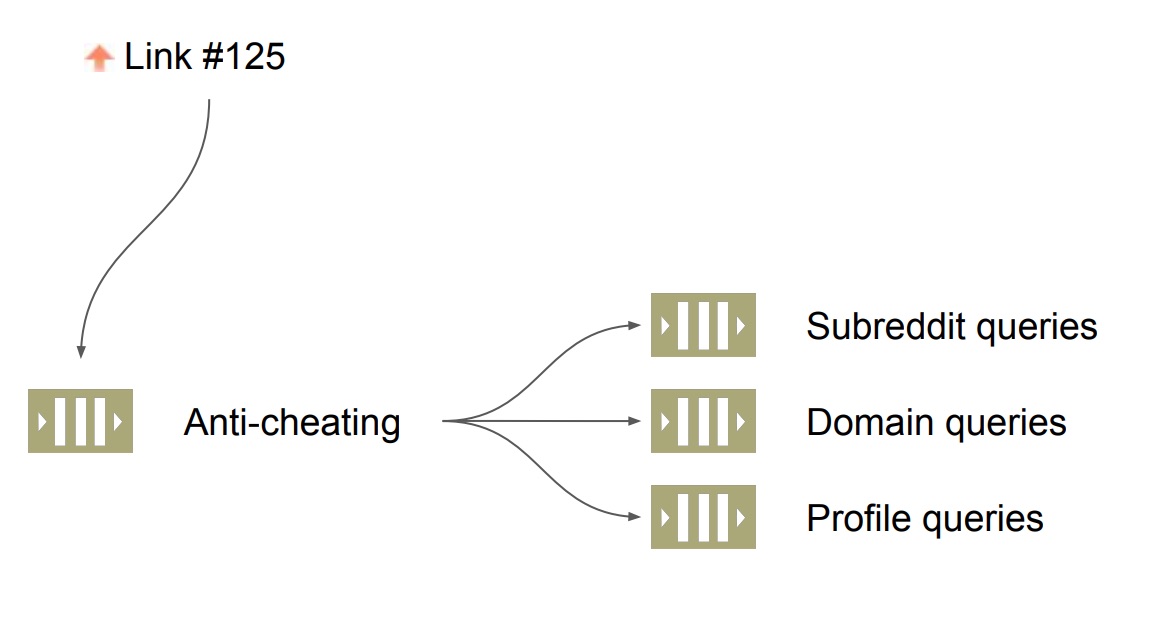
ดังนั้นจำเป็นต้องแยก Job queue ออกตาม domain เพิ่มเข้ามาอีก
ในตอนนี้ระบบ Job queue จะแยกตาม
![]()
สิ่งที่ทีมพัฒนาได้เรียนรู้คือ
การใช้ lock/partition และ timer ช่วยให้สามารถแก้ไขปัญหาเบื้องต้นไปได้
การ lock มีผลต่อจำนวน throughput ที่ลดลง ดังนั้นใช้เท่าที่จำเป็น
การทำ partition หรือแบ่งข้อมูลเป็นส่วน ๆ ช่วยทำให้จำนวนข้อมูลในการทำงานน้อยลง
99th percentile ช่วยทำให้เจอต้นเหตุของปัญหา
แสดงรูปแบบการเรียนรู้ของ Listing service
![]()
สิ่งที่กำลังจะทำต่อไปเกี่ยวกับ Listing service คือ
- หา data model ใหม่ ๆ ที่ลดการ lock ข้อมูล
- ใช้ machine learning และ offline batching ในการทำ personalized listing
ยังมีเรื่องอื่น ๆ ที่น่าสนใจ แนะนำให้ลองไปฟังดูครับสนุกดี
The Evolution of Reddit.com's Architecture

 หลังจากที่ดู VDO เรื่อง The Evolution of Reddit.com's Architecture
ทำการอธิบาย architecture ของระบบ Reddit.com
ว่าเป็นอย่างไรบ้าง
ใช้อะไรบ้าง
มีวิวัฒนาการอย่างไรบ้าง
มาดูกันนิดหน่อย น่าจะพอมีประโยชน์สำหรับการพัฒนาระบบงาน
สิ่งที่น่าสนใจคือ architecture นั้นจะถูกปรับเปลี่ยนไปตามปัญหาที่เกิดขึ้น
หลังจากที่ดู VDO เรื่อง The Evolution of Reddit.com's Architecture
ทำการอธิบาย architecture ของระบบ Reddit.com
ว่าเป็นอย่างไรบ้าง
ใช้อะไรบ้าง
มีวิวัฒนาการอย่างไรบ้าง
มาดูกันนิดหน่อย น่าจะพอมีประโยชน์สำหรับการพัฒนาระบบงาน
สิ่งที่น่าสนใจคือ architecture นั้นจะถูกปรับเปลี่ยนไปตามปัญหาที่เกิดขึ้น
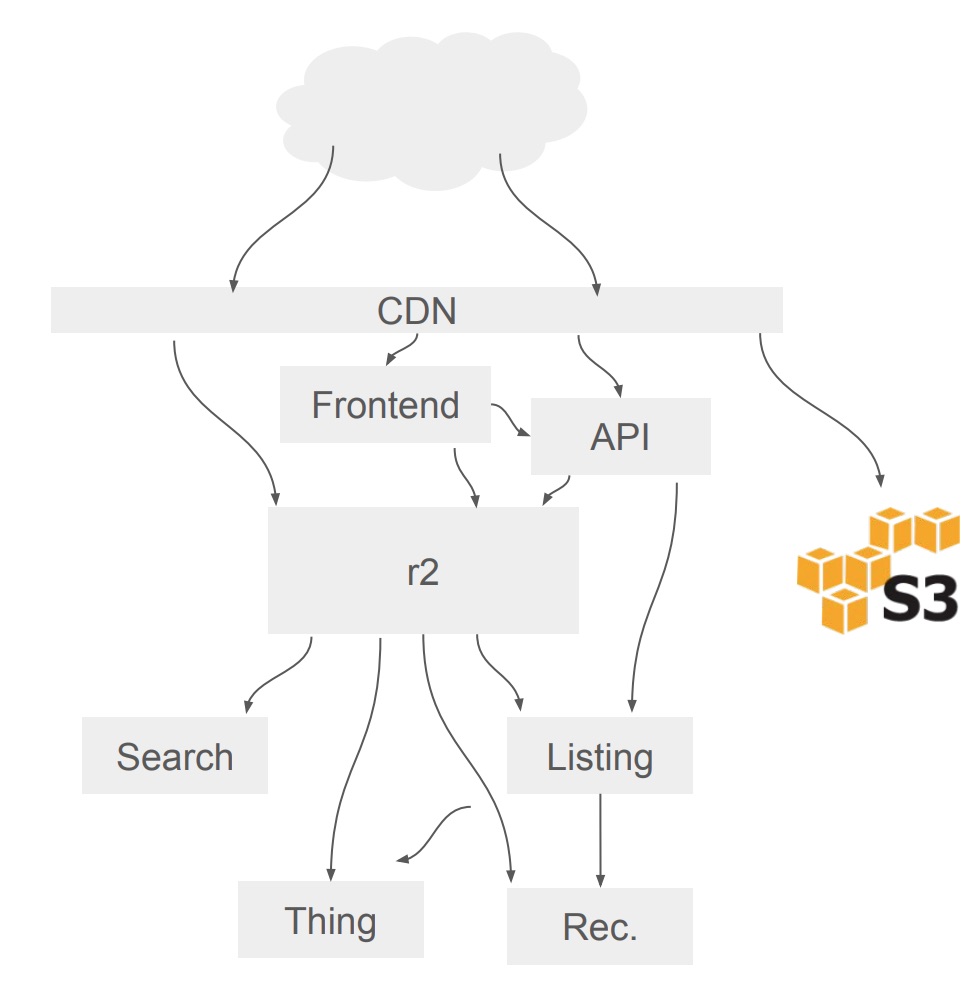 คำอธิบาย
คำอธิบาย
 ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ถ้าเป็นคำสั่ง SQL ทั่วไปก็เพียง select * from links order by hot(ups, downs);
ส่วนผลการดึงข้อมูลก็ทำ caching ไว้
โดยที่ caching จะถูกทำลายเมื่อมีหัวข้อใหม่และมีการ vote !!
ถ้าดูจากสถิติของการ vote แล้ว
คิดว่า caching มันจะช่วยอะไรไหม ?
แน่นอนว่า ไม่ได้ช่วยอะไรเลย !!
เพราะว่าข้อมูลมันเปลี่ยนอยู่ตลอดเวลา
ดังนั้นจึงเกิดแนวคิดใหม่ ๆ เพื่อแก้ไขปัญหา
ตัวอย่างของหัวข้อที่ hot ทำการเรียงจากคะแนนการ vote
ถ้าเป็นคำสั่ง SQL ทั่วไปก็เพียง select * from links order by hot(ups, downs);
ส่วนผลการดึงข้อมูลก็ทำ caching ไว้
โดยที่ caching จะถูกทำลายเมื่อมีหัวข้อใหม่และมีการ vote !!
ถ้าดูจากสถิติของการ vote แล้ว
คิดว่า caching มันจะช่วยอะไรไหม ?
แน่นอนว่า ไม่ได้ช่วยอะไรเลย !!
เพราะว่าข้อมูลมันเปลี่ยนอยู่ตลอดเวลา
ดังนั้นจึงเกิดแนวคิดใหม่ ๆ เพื่อแก้ไขปัญหา
 เมื่อลงไปดูในรายละเอียดพบว่า
มีการ post link ของ domain อื่น ๆ เข้ามายัง Reddit.com เยอะมาก ๆ
หนึ่งในนั้นคือ imgur.com
ซึ่งส่งผลต่อการเปลี่ยนแปลงการ caching ของ Listing
ดังนั้นจำเป็นต้องแยก Job queue ออกตาม domain เพิ่มเข้ามาอีก
ในตอนนี้ระบบ Job queue จะแยกตาม
เมื่อลงไปดูในรายละเอียดพบว่า
มีการ post link ของ domain อื่น ๆ เข้ามายัง Reddit.com เยอะมาก ๆ
หนึ่งในนั้นคือ imgur.com
ซึ่งส่งผลต่อการเปลี่ยนแปลงการ caching ของ Listing
ดังนั้นจำเป็นต้องแยก Job queue ออกตาม domain เพิ่มเข้ามาอีก
ในตอนนี้ระบบ Job queue จะแยกตาม