Image may be NSFW.
Clik here to view.
Clik here to view.
 ทาง Elastic ได้ปล่อย Elasticsearch 6.0.0 ออกมา
ต้องบอกว่า Elastic Stack สินะ
เพราะว่า product ทุกตัวจะปล่อยออกมาพร้อมกันทั้งหมด
เช่น Elasticsearch, Kibana และ Logstash (ELK)
ดังนั้นมาดูกันหน่อยว่ามีอะไรเปลี่ยนแปลงไปบ้าง
ทาง Elastic ได้ปล่อย Elasticsearch 6.0.0 ออกมา
ต้องบอกว่า Elastic Stack สินะ
เพราะว่า product ทุกตัวจะปล่อยออกมาพร้อมกันทั้งหมด
เช่น Elasticsearch, Kibana และ Logstash (ELK)
ดังนั้นมาดูกันหน่อยว่ามีอะไรเปลี่ยนแปลงไปบ้าง
เริ่มต้นด้วยหัวใจของระบบคือ Apache Lucene 7.0.1
มันคือ Full-text seach engine นั่นเอง ตั้งแต่ 6.x ขึ้นมาทำการปรับปรุงเรื่อง performance ทั้งการจัดเก็บ การบีบอัดและการดึงข้อมูล ทำให้ทำงานเร็วขึ้น ใช้ storage น้อยลง Image may be NSFW.Clik here to view.
ส่วนเรื่องที่น่าสนใจคือ Breaking Change ใน 6.0.0
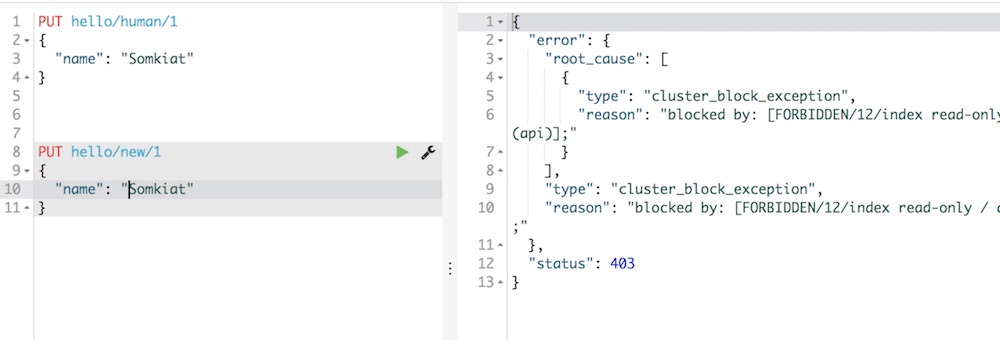
คิดว่าจะจะกระทบเยอะพอควร นั่นก็คือ ในแต่ละ index มีได้เพียง type เดียวเท่านั้น !! หรือพูดง่าย ๆ คือใน 1 database สามารถมี table ได้เพียง 1 table เท่านั้น เหตุผลหลักคือ ข้อมูลใน index เดียวกันนั่นมีการจัดเก็บที่กระจัดกระจายเกินไป ส่งผลต่อประสิทธิภาพการทำงานของ Apache Lucene นั่นก็คือ การบีบอัดข้อมูล อีกอย่างเมื่อแยกข้อมูลตามแต่ละ index แล้ว ทำให้จัดการและ configuration ค่าต่าง ๆ ได้ง่ายขึ้น ตัวอย่าง error message เมื่อสร้าง type มากกว่า 1 type ใน index Image may be NSFW.Clik here to view.
การ migrate ข้อมูลมายัง Elasticsearch 6.0.0
ถ้าใช้งาน Elasticsearch 2.x หรือก่อนหน้า สามารถใช้ reindex API ได้ แต่ผมแนะนำให้ export และ import data ดีกว่านะเรื่องสำคัญคือ Operation ต่าง ๆ
โดยใน version หลัง ๆ จะเน้นเรื่องของ Zero-downtime สำหรับการ upgrade node ต่าง ๆ ใน cluster ใช้การ rolling upgrade รวมทั้งการ restart และ recovery จะรวดเร็วขึ้นด้วย Sequence IDs ทำให้สามารถ replay การทำงานที่ขาดหลายไปในแต่ละ shard ได้มีอีกหนึ่งความสามารถที่น่าสนใจมั้ง
คือการค้นหาข้อมูลข้าม cluster ได้ ยกตัวอย่างเช่น cluster A ใช้ elasticsearch 5.x cluster B ใช้ elasticsearch 6.x สามารถใช้ความสามารถชื่อ Cross Cluster Search ได้ ทำให้ cluster B ไม่จำเป็นต้อง migrate มาเป็น elastic search 6.xปรับปรุงประสิทธิภาพของการ query ข้อมูล
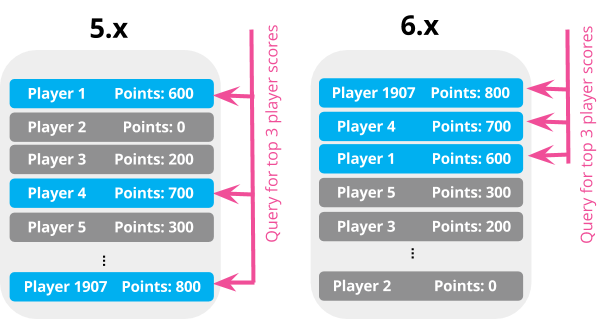
ในการ query ข้อมูลใน Elasticsearch ใช้ resource เยอะพอควร ยิ่งมีการเรียงลำดับข้อมูลยิ่งกินเพิ่มอีกมากมาย ดังนั้นใน 6.0.0 จึงเปลี่ยนด้วยการสร้าง index sorting ขึ้นมา นั่นคือในแต่ละ segment ของ Apache Lucene จะมีข้อมูลที่ถูกเรียงลำดับตามที่เราต้องการไว้ตั้งแต่การทำ indexing ทำให้ได้ผลลัพธ์จากการ query เร็วขึ้น การทำงานภายในน้อยลง เนื่องจากใน version ก่อนหน้าต้องทำการดึง document มาจากทุก ๆ segment เพราะว่าแต่ละ document จะถูกสร้างและเรียงลำดับตาม id ของ document และกระจายแต่ละ document ไปในแต่ละ segment จากนั้นจึงนำมาเปรียบเทียบ ก่อนได้ผลที่ต้องการ ซึ่งใช้เวลาและ resource สูงมาก ๆ ดังนั้นสิ่งที่ต้องทำในการสร้างและ configuration index คือ กำหนดไปเลยว่า index จะทำการเรียงลำดับด้วย field/property อะไรบ้าง นั่นคือ ต้องคิดหรือตั้งคำถามก่อนเลยว่า แต่ละ index จะทำอะไรบ้าง ไม่ใช่เพียงเก็บ ๆ ไปเถอะนะ ตัวอย่างของ scores index ต้องการดึงข้อมูลมาแสดงใน leaderboard นั่นคือ แสดงข้อมูลคนที่ได้คะแนนสูง ๆ มาแสดง ทำได้ดังนี้ [gist id="6c6cff73a024ed156856aa03a8b15dc8" file="1.txt"] การเก็บข้อมูลของ Elasticsearch จะเป็นดังรูป Image may be NSFW.Clik here to view.
 สุดท้ายอย่าลืมดู log การทำงานด้วยว่ามีอะไรที่ Deprecated บ้างนะครับ
สามารถดูการเปลี่ยนแปลงต่าง ๆ ได้ที่ Release notes
สุดท้ายอย่าลืมดู log การทำงานด้วยว่ามีอะไรที่ Deprecated บ้างนะครับ
สามารถดูการเปลี่ยนแปลงต่าง ๆ ได้ที่ Release notes
จะรออะไรกันละ ไป Download กัน
