
จากบทความเรื่อง Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%
ทำการอธิบายสำหรับการย้ายระบบที่อยู่ในรูปแบบของ distributed Microservices
มาเป็น Monolith หรือถ้าพูดให้ตรง ๆ คือ ย้ายออกจาก AWS Lambda นั่นเอง
ซึ่งผลที่ได้รับกลับมาคือ
- Scale ระบบได้สูงขึ้น
- ระบบมีความ Resilience คือ เมื่อมีปัญหาสามารถ recovery กลับมาทำงานปกติได้ดี
- ที่สำคัญลดค่าใช้จ่ายไปมากกว่า 90%
ดังนั้นมาดูกันว่าทาง Prime Video ทำอย่างไรบ้าง ซึ่งน่าสนใจมาก ๆ
โดย service ที่ทำการเปลี่ยนแปลงคือ Audio/Video Monitoring Service
ทำหน้าที่ดังนี้
- Monitor ในแต่ละ stream ที่ผู้ใช้งานดู ซึ่งทำงานแบบอัตโนมัติ สำหรับการตรวจสอบคุณภาพของ Video จากนั้นก็จะ trigger เข้าสู่กระบวนการแก้ไขต่อไป
- มีทีม Video Quality Analysis (VQA) คอยดูคุณภาพของเสียงและภาพของ Video
ระบบนี้ไม่ได้ออกแบบมาเพื่อการ scale มากนัก
ทำให้เมื่อมี concurrency สูง ๆ ก็ให้เกิดปัญหาตามมาคือ
scale ได้ไม่ดี แถมต้องมีค่าใช้จ่ายที่สูงมาก ๆ อีกด้วย
ทำให้กลายเป็นปัญหาคอขวดของระบบไปอีก
ดังนั้นจึงต้องทำให้กลับมาดูว่า architecture ของระบบเป็นอย่างไร
"โดยเป้าหมายหลักเพื่อลดค่าใช้จ่าย และการ scale"
มาดู Architecture และ Technology ที่ใช้กันหน่อย
หลัก ๆ จะใช้ AWS Lambda จะแยกส่วนการทำงานเป็นแต่ละ component
นั่นคือ จะมี serverless แยกกันไปเพียบ ตามที่จะแบ่งกันไป (Distributed component)
ประกอบไปด้วย component ดังนี้
- Media conversion ตรงนี้ทำงานร่วมกับ Amazon S3 ดังนั้นเมื่อมีการดูเยอะ ๆ ก็ดึงข้อมูลจาก S3 เยอะ แพงไหนนะ ?
- Defect detector เมื่อผ่านการ convert มาแล้วจะ trigger มาทำงานที่นี่ เพื่อทำการตรวจสอบคุณภาพ ก็อ่านจาก S3 อีกนั่นเอง !! ถ้าเจอปัญหาก็ trigger ไปยัง Notification เพื่อแจ้งต่อไป ส่วนปัญหาที่พบเจอเก็บใน S3 อีก bucket หนึ่ง
- Realtime Notification ใช้งาน Amazon SNS (Simple Notification Service)
และมีตัวจัดการ หรือ orchestrator คือ AWS Step Functions
ซึ่งเป็นตัวการใหญ่ของปัญหาในระบบนี้
โดย architecture นี้ถูกสร้างมาเพื่อให้เริ่มต้นพัฒนาได้ง่ายและรวดเร็ว
และในทางทฤษฎี แต่ละ component มีความเป็นอิสระแก่กัน
น่าจะทำให้การ scale ง่าย !!
แต่ในความเป็นจริงพบว่า scale ยาก
แถมค่าใช้จ่ายโดยรวมก็สูงขึ้นมาก มากจนยอมรับไม่ได้ !!
มี 2 ส่วนหลัก ๆ ที่เป็นปัญหาคอขวด และ มีค่าใช้จ่ายสูงมาก ๆ คือ
- AWS Step Functions หรือตัว orchestrate นั่นเอง เนื่องจากมี component เยอะ การใช้งานสูง ทำให้เกิด state transition เยอะ และก็คิดค่าใช้จ่ายตามจำนวน state transition ด้วย (เรื่อง cost estimation ต้องคิดไหมนะ) ใช้จนเกิน limit ของ account นั่นก็ยิ่งทำให้ค่าใช้จ่ายสูงแบบโหดร้ายอีก

- ส่วนที่สองคือ การเก็บข้อมูลเพื่ออ่านเขียน video frame หรือ รูปภาพ ใน Amazon S3 นั่นเอง เพื่อให้แต่ละ component มาใช้งาน พบว่าการใช้งาน S3 แบบ Tier 1 จาก AWS Lambda นั้นมีค่าใช้จ่ายที่สูงมาก ๆ
แสดง Architecture แรกเริ่มดังรูป
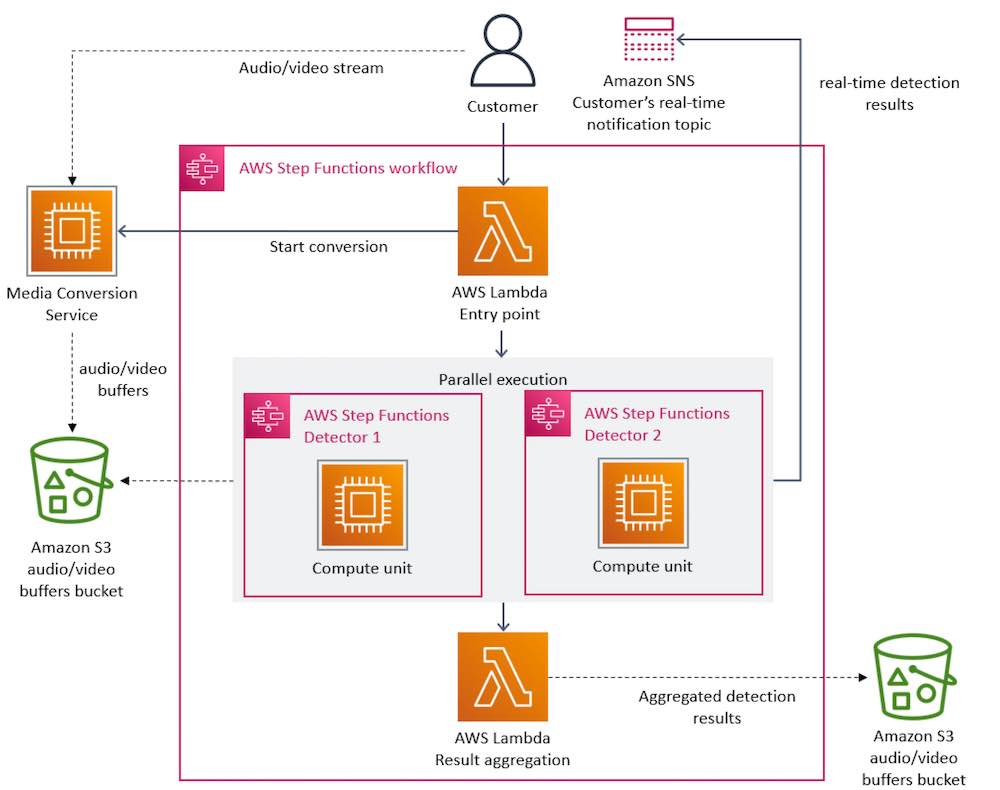
จากปัญหาข้างต้น จึงนำมาสู่ Architecture ใหม่
ที่ต้องการลดปัญหาคอขวดของการ scale และ ลดค่าใช้จ่าย
ด้วยการตัด AWS Lamba และ Amazon S3 ที่เก็บ video frame ออกไป
เรื่องจากพบว่าใน use case นี้ ระบบแบบ distributed นั้นไม่ได้ตอบโจทย์
โดยแนวทางใหม่ก็รวมแต่ละ component มาอยู่ใน process เดียวกันไปเลย
ซึ่งทำงานอยู่บน Amazon Elastic Container Service
ย้ายข้อมูล video frame ที่เก็บใน S3 มาอยู่ใน Memory แทน
ตารางเปรียบเทียบระหว่าง Container กับ Serverless
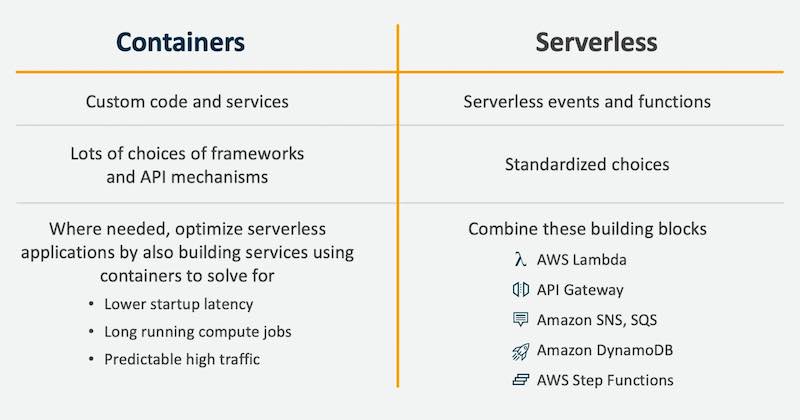
แนะนำเพิ่มเติมคือ Amazon EC2 compute saving plans สำหรับการลดค่าใช้จ่าย
แสดง Architecture ใหม่ ดังรูป
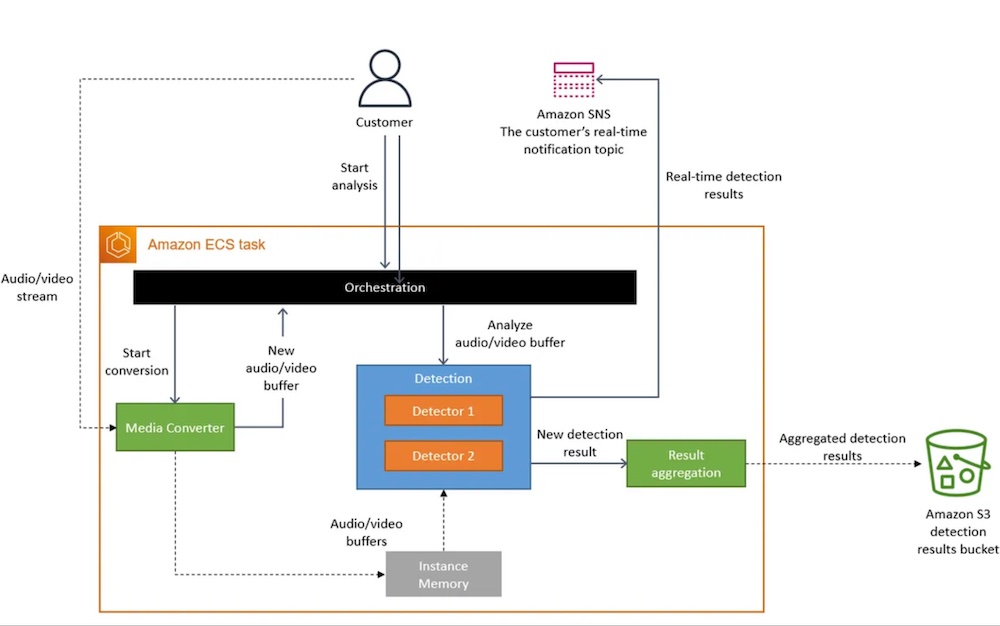
จาก architecture ใหม่ก็ช่วยแก้ไขปัญหาที่ตั้งไว้ แต่ก็มีปัญหาใหม่ ๆ ตามมา เช่น
การ scale ของ Defect detector นั้น จะทำการ scale แบบ vertical แทน
ทำไปจนถึง limit ของ instance ที่จะมีให้
จนต้องทำการ scale ด้วยการ copy code มายัง instance ใหม่
จากนั้นก็ทำ layer กลางขึ้นมา
เพื่อกระจาย request ของผู้ใช้งานไปตาม instance ต่าง ๆ นั่นเอง
เป็น AWS Lambda นั่นเอง
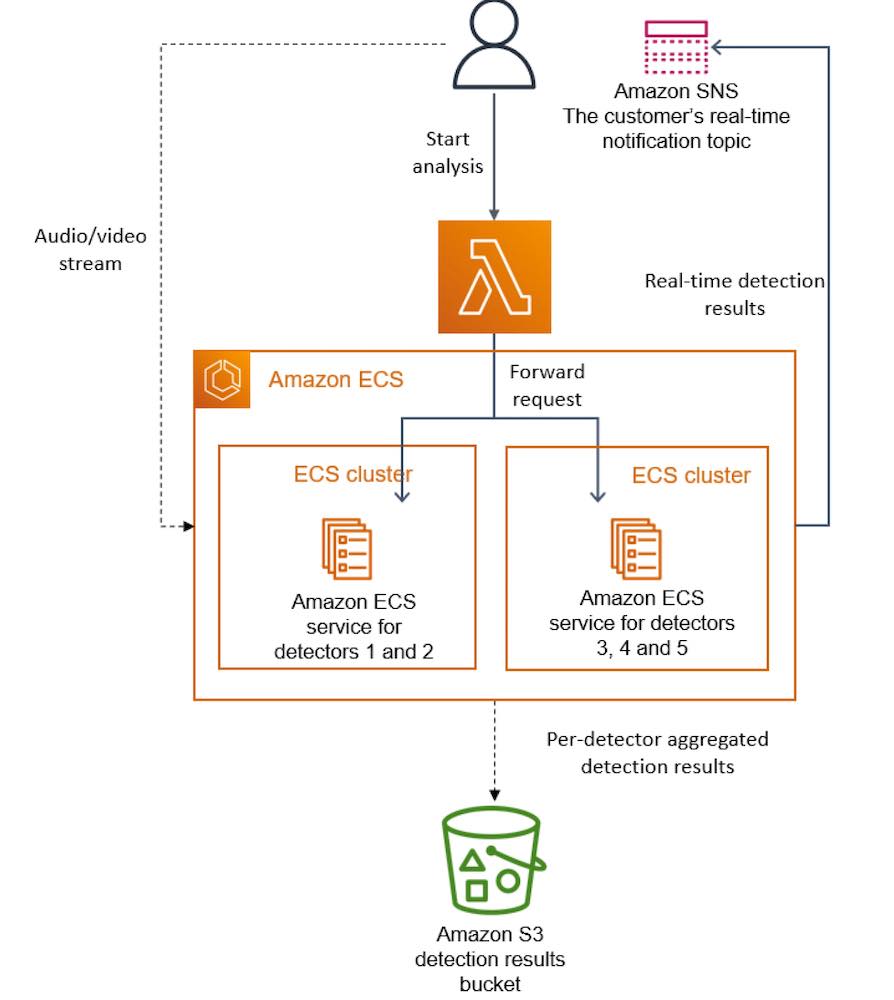
สิ่งที่ได้เรียนรู้กับแนวทางนี้มีอะไรบ้าง ?
- ในแต่ละ use case มีแนวทางเหมาะสมที่แตกต่างกันไป จะเห็นได้ว่า เป็นแนวทางที่เริ่มได้ง่ายและรวดเร็ว แต่เมื่อถึงจุดหนึ่งก็จะเกิดปัญหาที่ต้องเลือกทางแก้ไข ดังนั้นระบบงานควรต้องปรับปรุงอยู่อย่างสม่ำเสมอ ไม่ควรใช้คำว่าเดี๋ยวก่อน หรือ ใช้เงินเพื่อแก้ไขปัญหาอย่างเดียว
- ในการย้ายระบบมาตัวใหม่ทำได้เร็ว เนื่องจากของเดิมทำการแบ่ง component ออกมาอย่างชัดเจน ทำให้การ reuse หรือ migrate มาระบบใหม่ง่ายและรวดเร็วขึ้น ตรงนี้น่าสนใจมาก ๆ
- ไม่ว่าจะ Microservices, Serverless นั้นมันคือ tool ที่ช่วยเหลือทางด้านการ scale แต่ใช่ว่าจะแก้ไขได้ทุก use case ดังนั้นต้องเข้าใจถึงปัญหาและความต้องการก่อนเสมอ
- สิ่งที่สำคัญคือ การปรับปรุงแต่ละครั้ง เรามีตัวชี้วัดอะไรบ้าง
Reference Websites