

จากงาน Firebase Dev Day 2023 นั้น
เข้ามาฟังเรื่อง Building a more Efficient Firestore Web App พอ
เป็นเรื่องที่น่าสนใจมาก ๆ สำหรับการใช้งาน Firestore ใน web application ของเรา
เน้นในเรื่องของการใช้งานให้ถูกต้องตามที่ต้องการ
รวมทั้งยังช่วยลดค่าใช้จ่ายลงไปอีกด้วย
เนื่องจากระบบงานส่วนใหญ่อัตราการ read จะมากกว่า write มาก ๆ
ดังนั้นถ้านำ Firestore มาใช้ในงานที่อ่านเยอะ ๆ
ค่าใช้จ่ายก็สูงตาม
ดังนั้นเราจำเป็นต้องรู้และเข้าใจวิธีการจัดการ หรือ แก้ไขด้วย
มิใช่ ใช้ไปเรื่อย ๆ แล้วก็เปลี่ยน free plan ไปเป็นเสียเงิน
แบบที่ยังไม่รู้ปัญหาว่าเพราะว่าอะไร
ยกตัวอย่างเช่น
- เช่น ความแตกต่างของการใช้งาน getDocs() และ onSnapshot() ?
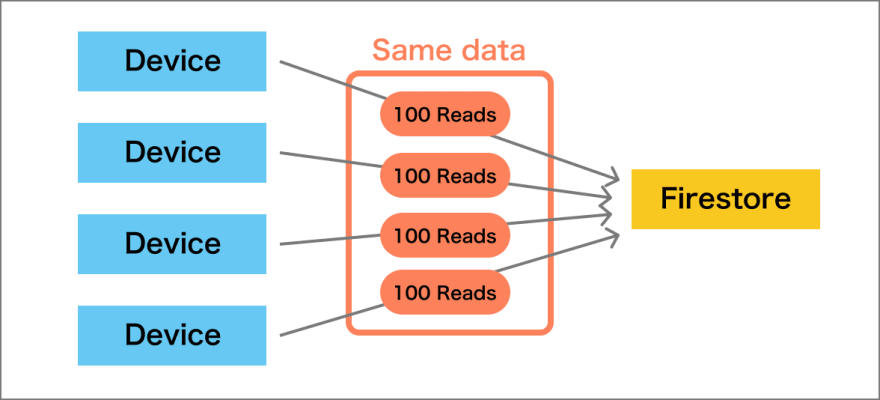
- ระบบแสดงผลจ้อมูลที่ไม่ค่อยเปลี่ยนแปลง แล้วมีผู้ใช้งานจำนวนมาก การไปอ่านจาก firestore ทุกครั้งคงไม่ดี
- การนับจำนวนของเอกสาร เช่นการใช้ count() นั้น ก็ทำให้การ read สูงเยอะอีก แนะนำให้ใช้ aggregate query จะดีกว่านะ
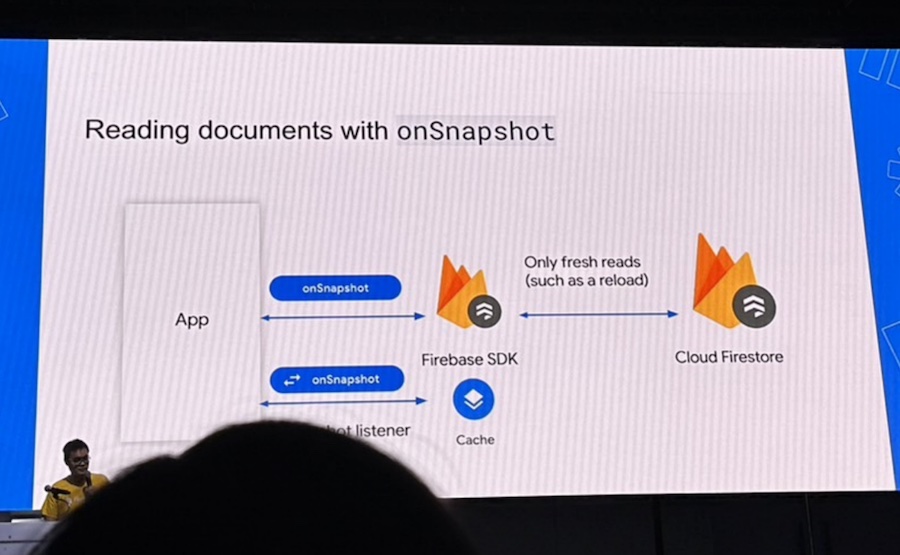
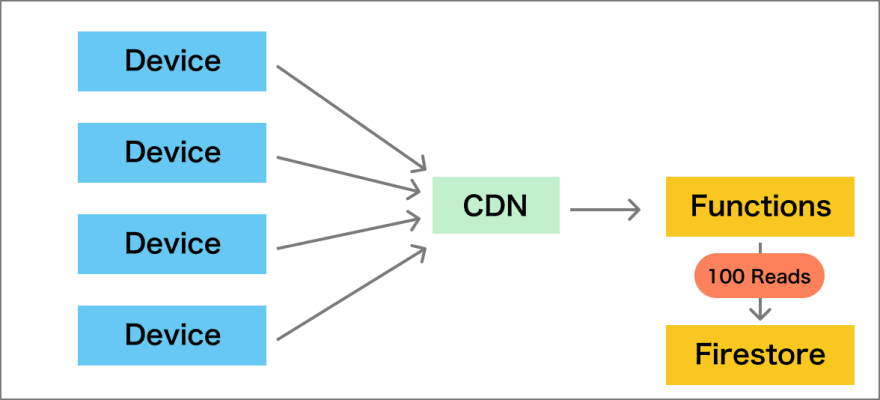
การแก้ไขเรื่องการอ่านมาก ๆ ก่อนหน้านี้อาจจะแก้ไขด้วย
การเอา CDN มากั้นไปเลยในฝั่ง frontend
ส่วนทาง Firestore ก็แนะนำมา 2 ทางคือ
- การใช้งาน Firestore data bundle
- การใช้งานร่วมกับ Readtime database
การใช้งาน Firestore data bundle
จะทำการสร้างข้อมูลที่ใช้งานบ่อย ๆ ขึ้นมา และไม่ค่อยเปลี่ยนแปลง
หรือเป็นพวก configuration ต่าง ๆ ที่ต้อง load ตอน startup หน้าจอ
มีรูปแบบเป็น binary นั่นหมายถึงเราสามารถไปเก็บใน binary storage ได้
ดังนั้นในฝั่งของ client นั้นสามารถนำ bundle ที่สร้างไปใช้งานได้เลย
เหมือนกับ caching data นั่นเอง
ทำให้ลดการเข้าถึง Firestore ลงไป
แต่ถ้ามีข้อมูลที่เป็น private/sensitive data ก็ไม่ควรเก็บใน bundle นะ !!
รวมทั้งข้อมูลที่เปลี่ยนบ่อย ๆ
แต่ปัญหาที่ตามมาคือ ถ้า Data Bundle มีขนาดใหญ่ละ ?
จะจัดการอย่างไร
เพราะว่าแน่นอน caching data ฝั่ง client ใหญ่ขึ้น ภาระหนัก !!
หรือการเข้าถึง หรือ ค้นหาข้อมูลก็ช้าลงไปอีก
ดังนั้นจากปัญหาก่อนหน้า ก็ได้ปัญหาใหม่มาอีก
ซึ่งแนวทางการแก้ไขก็คือ Client-Side Indexing
มีมาใน Firestore SDK นั่นเอง
ปกติทำในฝั่ง server เท่านั้น แต่ก็มีใน client ด้วยเช่นกัน

ปล. การเลือก tech stack มันมันก็สำคัญ
แต่การเข้าใจ tech ที่เลือก และการใช้งานให้ถูกก็สำคัญด้วยเช่นกัน
การ scale มันต้องมาพร้อมกับ cost ที่สมเหตุสมผล
Reference Websites