เห็นว่ามีการ share บทความเรื่อง
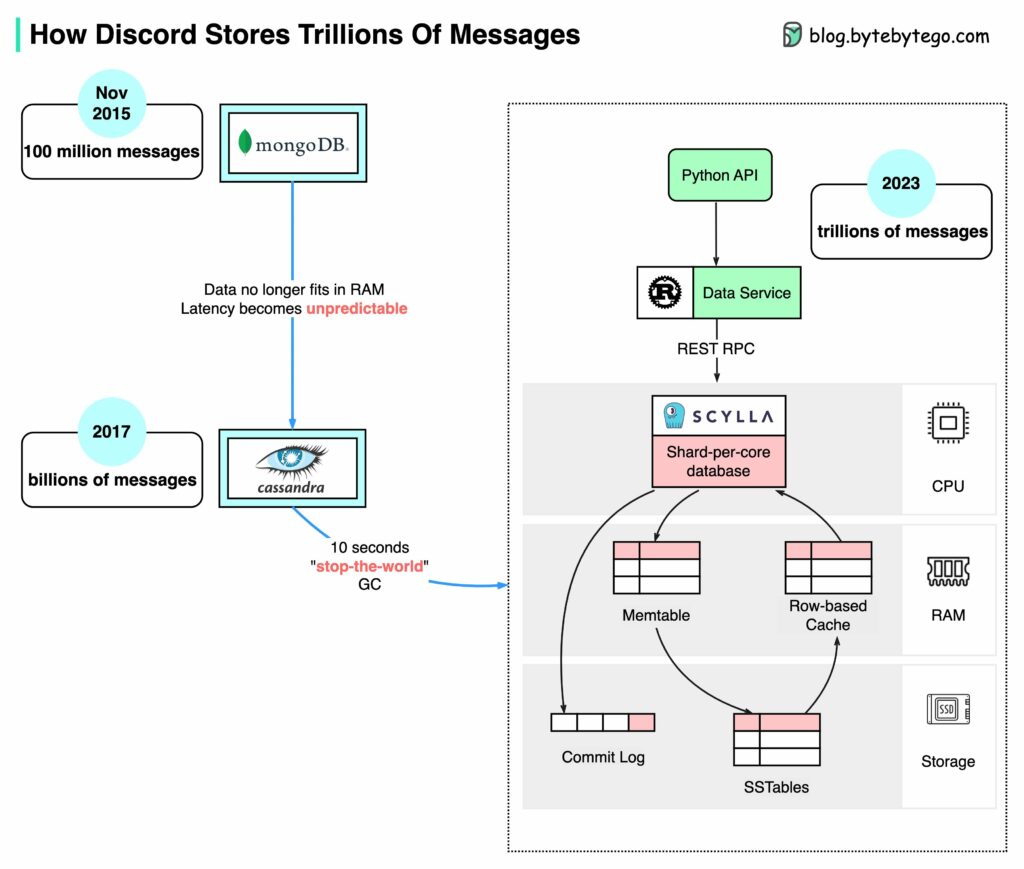
HOW DISCORD STORES TRILLIONS OF MESSAGES ?
ซึ่งเป็นบันทึกการเปลี่ยนแปลง database ที่ใช้เก็บข้อมูล
ที่พูดคุยต่าง ๆ ในระบบ Discord
จาก MongoDB -> Cassandra -> ScyllaDB
ทำให้เราเห็น use case และ เหตุผลในการเปลี่ยนแปลง
นั่นคือการแก้ไขปัญหานั่นเอง
จึงทำการสรุปสิ่งที่สนใจเอาไว้ดังนี้
สิ่งที่ผมสนใจคือ database ที่เลือกใช้
โดยเริ่มต้นจากการใช้งาน MonogoDB
เป็น NoSQL แบบ Document-based
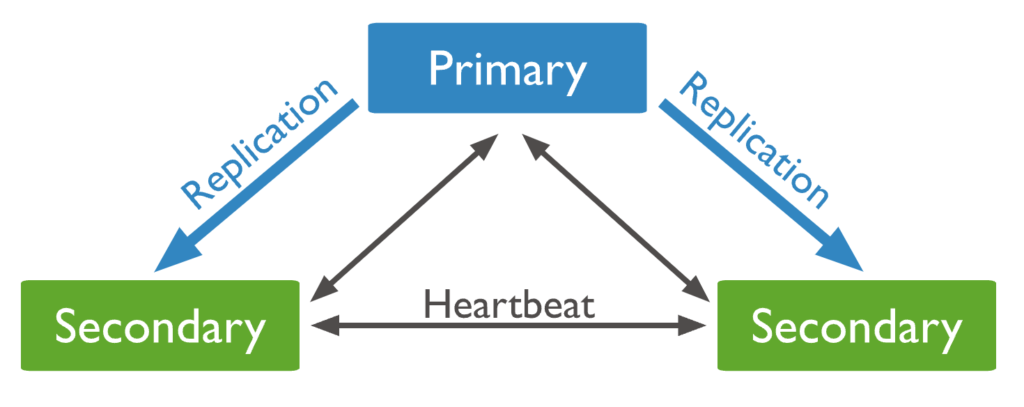
ซึ่งมีโครสร้างแบบ primary for write + secondary for read (Replication)
ตัวอย่างการ deploy แบบ replica set
แต่เมื่อข้อมูลมีเกิน 100 ล้าน document แล้ว
ทำให้ข้อมูลใหญ่กว่า memory
ส่งผลให้เวลาการจัดการข้อมูลผ่าน MongoDB มีปัญหา ช้าบ้างเร็วบ้าง
ทำให้เกิดปัญหาต่อระบบ
ดังนั้นจึงต้องทำการเปลี่ยนแปลง !!
โดยสิ่งที่เลือก ต้องตรงกับความต้องการดังนี้
- Linear Scalability
- การดูแลรักษาง่าย
- เมื่อเกิดปัญหาสามารถ recovery แบบอัตโนมัติได้
- รองรับอัตราการ read/write แบบ 50/50 ได้ดี
- รองรับการทำ caching ของแต่ละกลุ่มข้อมูลของ user
- รองรับ full text search
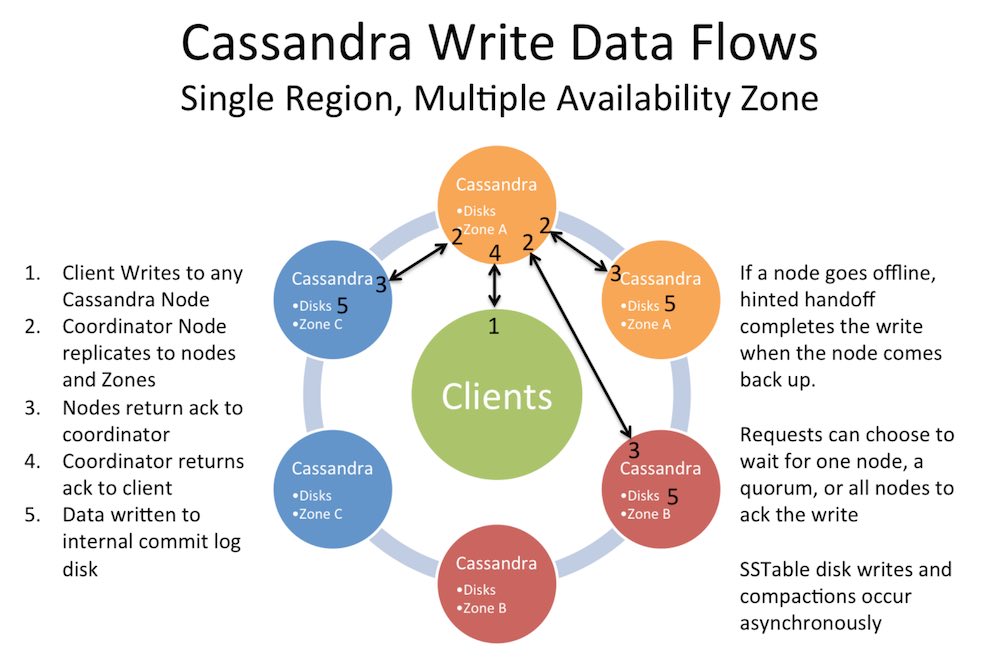
ซึ่งจากความต้องการเหล่านี้ จึงเลือก Cassandra มาใช้งาน
เป็น NoSQL แบบ Wide-column based
เน้นที่ Availability มากกว่า Consistency
ในเรื่องความถูกต้องจึงต้องมีวิธีการตรวจสอบข้อมูลเยอะหน่อย
ผลจากการเปลี่ยนแปลงทำให้การ write และ read เร็วขึ้นอย่างมาก
- Latency ของการ write < 1 ms
- Latency ของการ read < 5 ms
ระบบทำงานได้ปกติ ไม่มีปัญหาอะไร
จนมาถึงปี 2022 นั้น ข้อมูลที่จัดเก็บมาถึงหลักล้านล้าน (trillion)!!
พร้อมกับ Cassandra 177 node
มาพร้อมกับปัญหาเรื่อง latency ที่เหวี่ยงไปมา
จากเรื่องการทำงานของ Garbase Collector(GC) ของ JVM !!
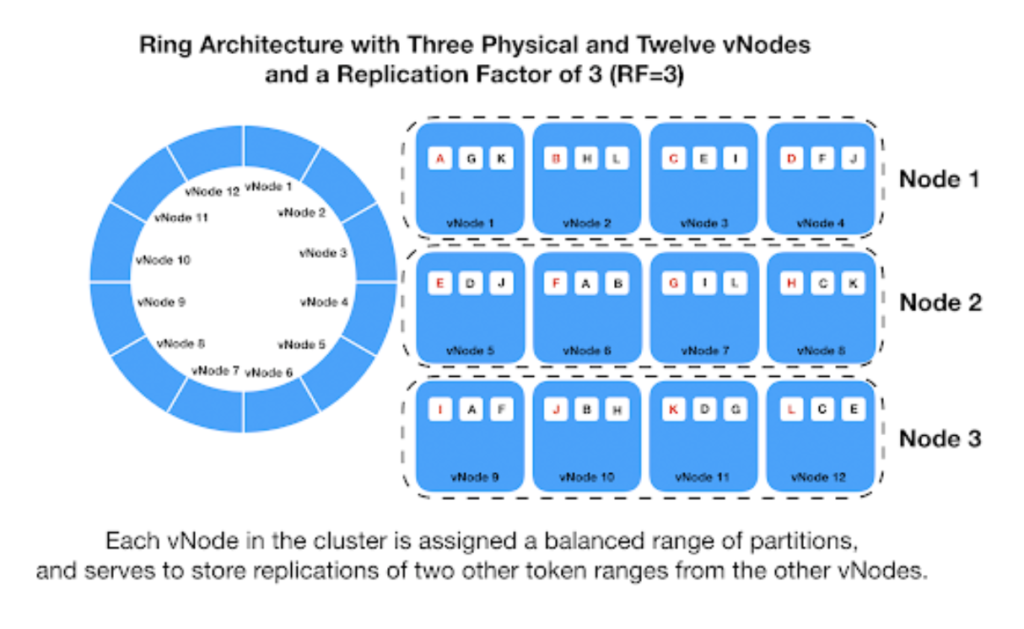
และปัญหา Hot partition ที่มาจากการแบ่งข้อมูลตาม key ที่กำหนด
ดังนั้นถ้ามีข้อมูลใน partition ไหนใช้งานสูง ก็ส่งผลต่อความเร็วอีก !!
จึงได้เวลาของการเปลี่ยนแปลงอีกครั้ง
นั่นคือการเลือกใช้ ScyllaDB
เป็นตัวแทนของ Cassandra
พัฒนาด้วยภาษา C++ จึงไม่มีปัญหาเรื่อง GC
และยังมี API ที่ compatibility กับ DynamoDB และ Cassandra อีกด้วย
แต่เรื่องของ Hot partition ยังคงมี
จึงทำการแก้ไขด้วยการสร้าง Data Layer ขึ้นมาด้วยภาษา Rust
อยู่ระหว่าง API ที่เขียนด้วยภาษา Python กับ Database นั่นเอง
ของเดิม API ยิงไปที่ Database ตรง ๆ เลย
โดยใน Data Layer ทำหน้าที่ดังนี้
- ถ้ามีการดึงข้อมูลเดิม ๆ ซ้ำกันมา จะมีเพียง request แรกเท่านั้นที่วิ่งไปยัง Database ทำหน้าที่ Caching data นั่นเอง
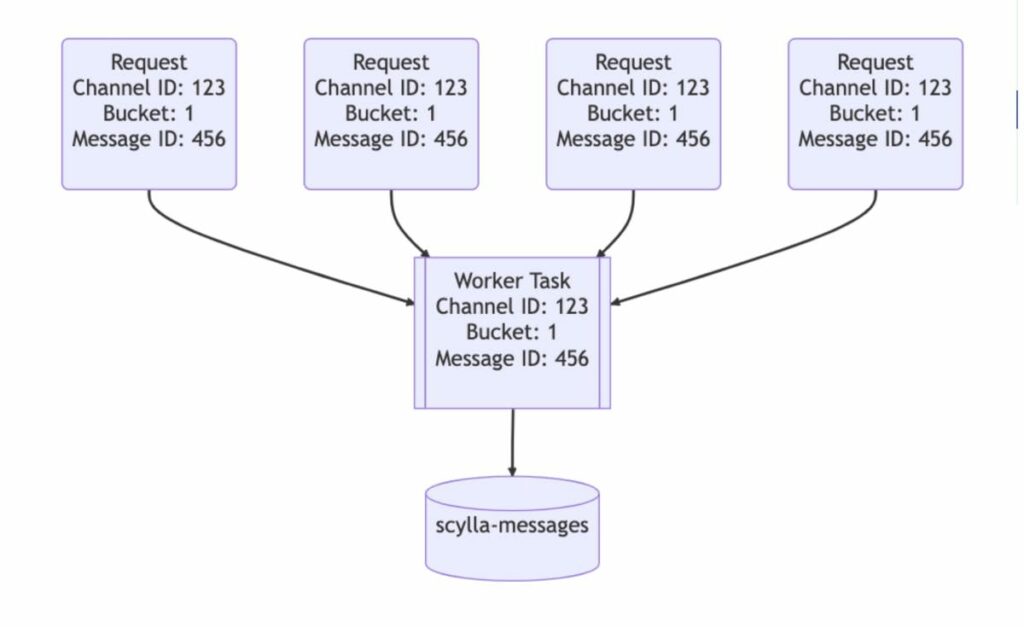
- ทำการเตรียม routing key ไว้สำหรับการจัดการ message ให้ไปอยู่ใน channel ต่าง ๆ เพื่อดึงข้อมูลจาก database เป้าหมายเพื่อลดปัญหาเรื่อง Hot partition
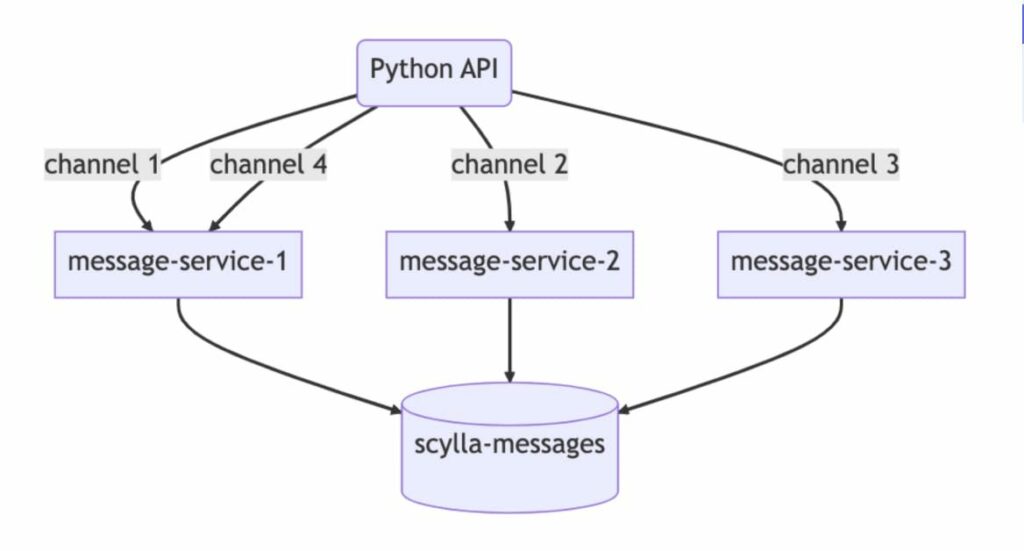
นั่นหมายความว่าทางทีม Discord พยายาม
ลดจำนวน request ที่วิ่งไปยัง Database ลงให้มากที่สุด
อีกเรื่องที่น่าสนใจคือ การ migrate data จาก Cassandra มายัง ScyllaDB
แบบไม่ให้มี downtime !!
ต้องไปอ่านรายละเอียดเพิ่มอีก
ดูเพิ่มเติมได้ที่