
เห็นเรื่องการเปลี่ยนจาก Elasticsearch มาเป็นของ Clickhouse
ก็ทำให้ไปอ่านบทความเก่าตั้งแต่ปี 2018
เรื่อง HTTP Analytics for 6M requests per second using ClickHouse
ว่าด้วยเรื่องการวิเคราะห์ traffic ปริมาณสูง
ว่า architecture ของระบบมีวิวัฒนาการอย่างไร
เพื่อให้รองรับข้อมูลที่สูงมาก ๆ
นั่นคือ architecture ของ Data pipeline
มาดูกัน
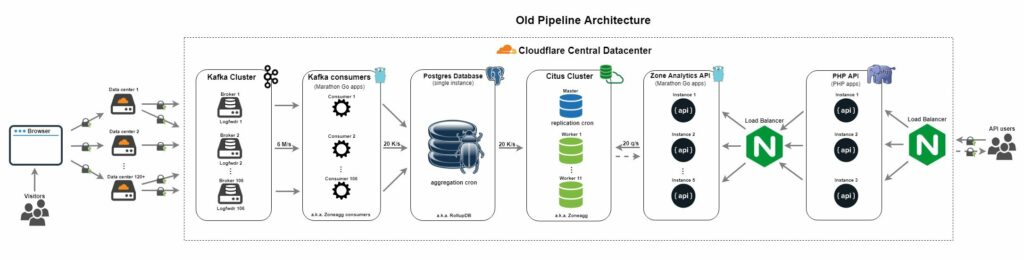
Architecture ของ Data pipeline แบบเก่า
ซึ่งสร้างมาตั้งแต่ปี 2014 โดยใช้เครื่องมือต่าง ๆ เหล่างนี้
- Apache Kafka สำหรับรับข้อมูล HTTP traffic จากผู้ใช้งานต่าง ๆ เข้ามายัง pipeline
- โดย consumer ของ Apache Kafka นั้น จะนำข้อมูลมาเก็บใน PostgreSQL ซึ่งทำการ aggregate data ตามการใช้งานทั้ง partition, zone รวมทั้งข้อมูลในระดับนาที ชั่วโมง วัน เดือน ทำให้ง่ายต่อการใช้งานต่อไป
- ทำการ scale out ตัว PostgreSQL ด้วย CitusDB เพื่อนำไป analyze ต่อไป
- Analyze API พัฒนาด้วยภาษา Go
- ใช้งานผ่าน PHP API
- Load balance ใช้งาน NGINX
แสดงดังรูป
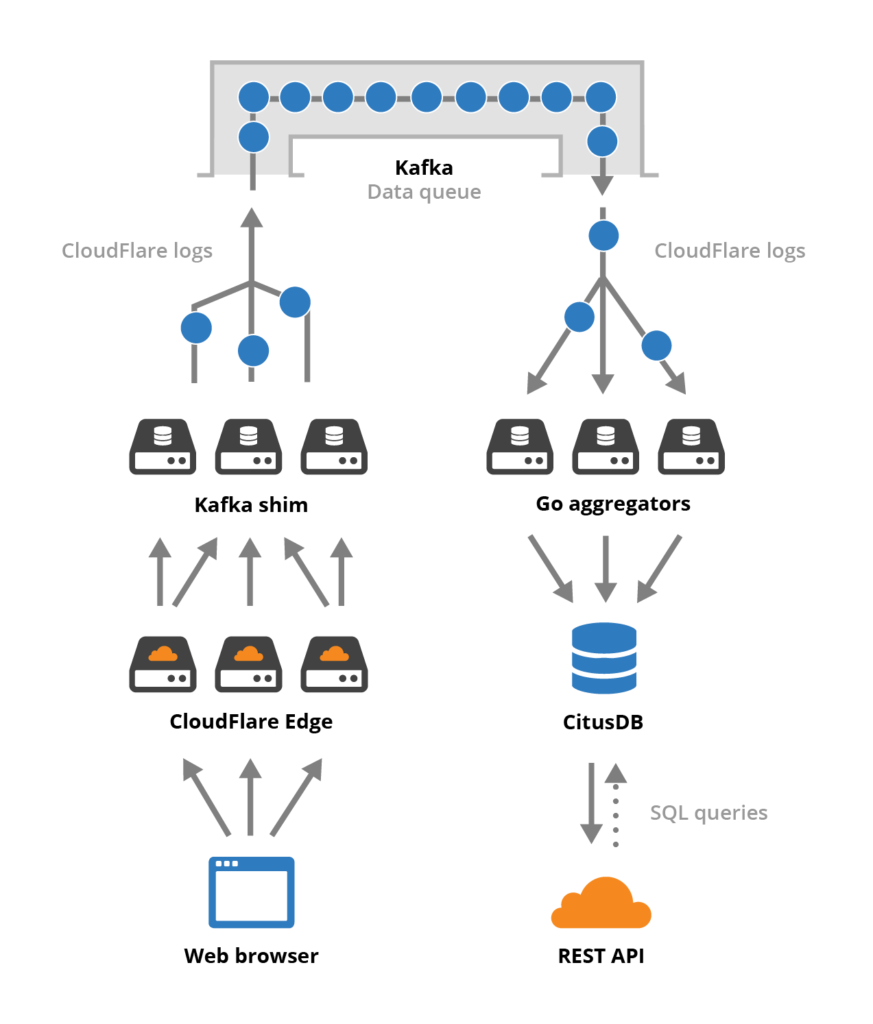
แสดง Flow การไหลของ traffic ที่เข้ามา ดังรูป
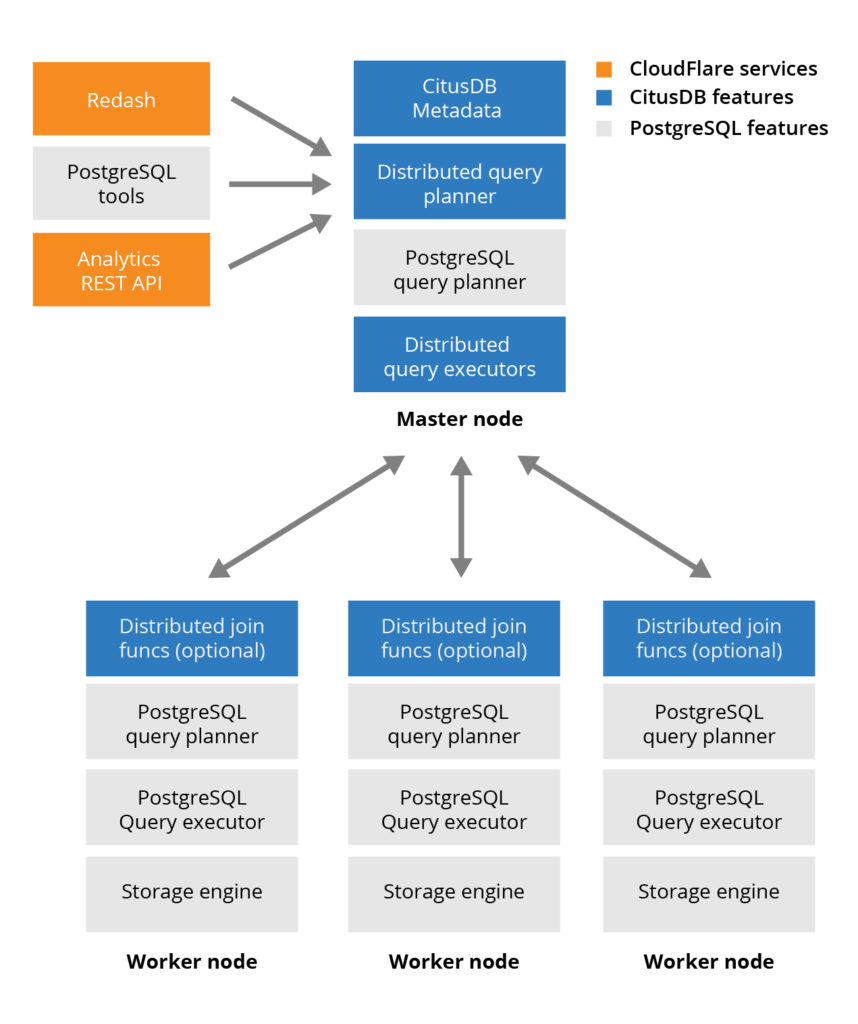
ส่วน CitusDB มีโครงสร้างการทำงานดังรูป
จาก architecture ข้างต้นนั้น ทำงานได้ดี
แต่เมื่อจำนวน HTTP traffic เพิ่มจาก
1 ล้าน request ต่อวินาที มาเป็น 6 ล้าน request ต่อวินาทีแล้ว
ทำให้มีปัญหาเกิดขึ้น
โดยมีจุดอ่อนหรือปัญหาดังนี้
- PostgreSQL และ CitusDB กลายเป็น Single point of failure
- Code มีความซับซ้อนมาก ๆ ทั้ง bash script และ SQL ในการ aggregation ข้อมูล รวมถึง code ที่พัฒนาด้วยภาษา Go ก็เยอะ ทำให้ยากต่อการดูแลรักษา
- มี dependency เยอะเกินไป และผูกมัดกันเกินไป ถ้ามีส่วนใดพังไป ก่อให้เกิดพังทั้ง pipeline
- ค่าใช้จ่ายในการดูแลสูง ทั้งซับซ้อน ข้อผิดพลาดก็เยอะ ใช้เวลาแก้ไขก็นาน
ดังนั้นจึงพยายามปรับปรุง Data pipeline นี้ใหม่
เพื่อรองรับ และ แก้ไขปัญหาต่าง ๆ ที่เกิดขึ้น
ความพยายามแรกคือ การใช้งาน Apache Flink สำหรับ stream processing
ซึ่งใช้กับ project อื่น ๆ มาแล้ว
แต่ก็มีปัญหาเรื่องการ scale ให้รองรับข้อมูลระดับ 6 ล้าน request ต่อวินาที
จากนั้นได้ลองนำเอา pipeline จากทีม DNS ที่ทำ DNS analytic pipeline ที่ทำงานบน ClickHouse
เป็น database แบบ column-base
ซึ่งพบว่าเหมาะกับงาน และ จำนวน traffic นี้มาก ๆ
ช่วยให้ scale out และลดปัญหาไปได้เยอะ
ทำให้ระบบมี up time ที่ดี
รวมทั้ง performance ที่ดี
ตัวอย่างข้อมูลที่จัดเก็บมีมากกว่า 100 columns
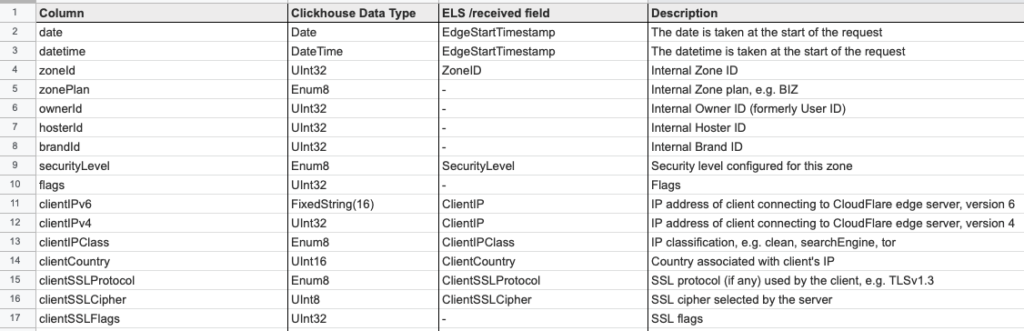
เรื่องการออกแบบ schema ของข้อมูล สำคัญมาก ๆ
เพื่อทำให้มั่นใจว่า เหมาะสมต่อการจัดเก็บและใช้งาน
จากนั้นทำ benchmark เพื่อดูผลการทำงาน

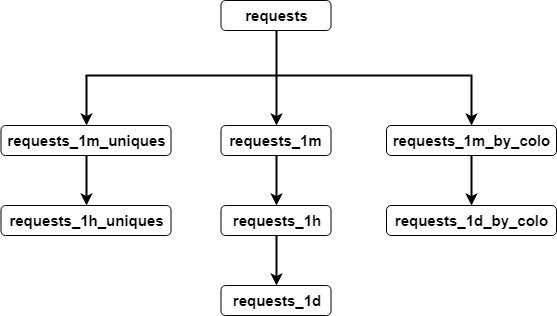
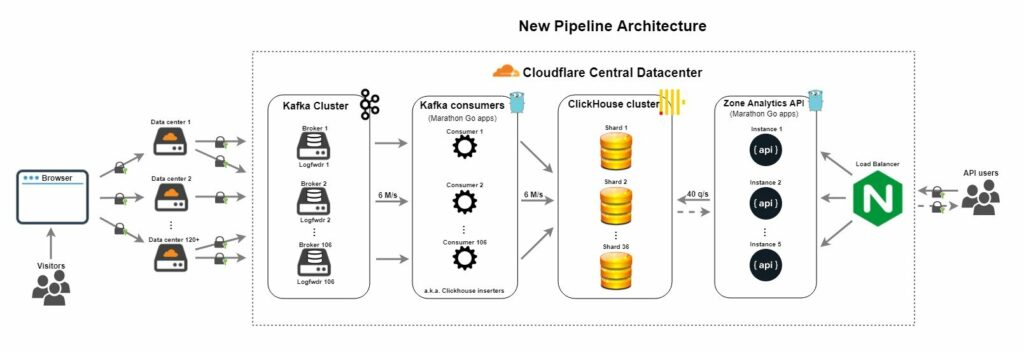
โดยจากการออกแบบและสร้าง จะได้ data pipeline ใหม่
ประกอบไปด้วยเครื่องมือดังนี้
- Apache Kafka เพื่อรับ request เช่นเดิม
- ผลการทำงานจาก Kafka consumer จะเก็บไว้ที่ ClickHouse แทนที่ PostgreSQL และ CitusDB
- คนใช้งานวิ่งมาที่ Analytic API ที่พัฒนาด้วยภาษา Go ได้เลย
จาก architectureใหม่ สามารถรองรับได้มากกว่า 7 ล้าน request ต่อวินาที
แสดงดังรูป
อีกเรื่องคือรูปแบบของข้อมูลที่ใช้งาน จะใช้ Cap'n Proto
ซึ่งเล็กและเร็วกว่า Protobuf อีกนะ
น่าสนใจมาก ๆ

ข้อดีของ Data pipeline ตัวใหม่ ประกอบไปด้วย
- ไม่มี Single point of failure
- Fault-tolerant ตายใครตายมัน ไม่ส่งผลต่อส่วนอื่น ๆ
- Scale ได้ง่ายขึ้น
- ลดความซับซ้อนลงไปมาก
- ปรับปรุงในเรื่องของ throughput และ latency ของ API
- ง่ายต่อการดูแลรักษา และ จัดการ
- ที่สำคัญสุด ๆ ลดปัญหา หรือ incident นั่นคือระบบมีความเสถียร และ น่าเชื่อถือขึ้นมาก
เป็นการปรับปรุงที่น่าสนใจ ทั้งแนวคิด การแก้ไข
รวมถึงเครื่องมือและ technology ต่าง ๆ