Image may be NSFW.
Clik here to view.
เห็นใน feed มาการ share บทความเรื่อง
How to design a system to scale to your first 100 million users ?
มีรายละเอียดเยอะมาก ๆ
หนึ่งในเรื่องที่สนใจคือ การ scaling database (RDBMS)
เนื่องจากยังคงเป็นที่นิยมในการใช้งาน
ตัวอย่างความนิยมของ Database model ต่าง ๆ จาก DB Engine Ranking 2021
Clik here to view.
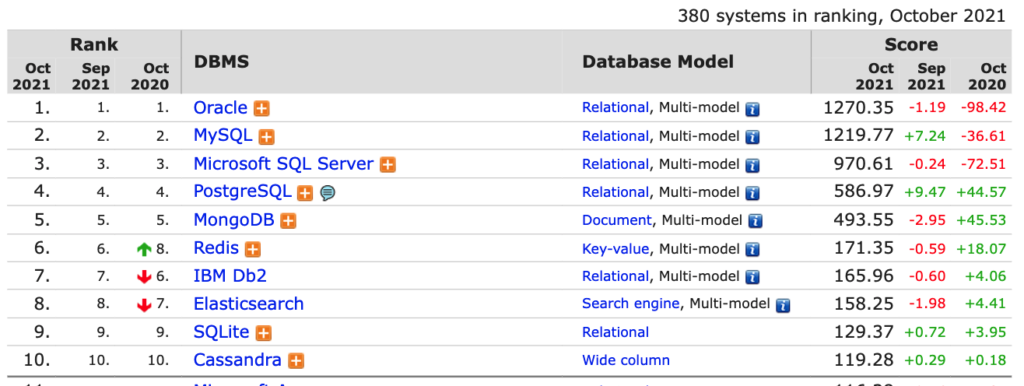
โดยวิธีการ scale RDBMS ที่แนะนำมาดังนี้
- Replication
- Federation
- Sharding
- Denomalization
- SQL tuning
Replication
เริ่มด้วย Master-Slave replication
ทำการ copy ข้อมูลจาก database หลักออกมา
โดย database server จะมี 2 กลุ่มคือ
- Master สำหรับเปลี่ยนแปลงข้อมูล ทั้งเขียน แก้ไข และ ลบ
- Slave สำหรับการอ่านข้อมูล สามารถเพิ่มจำนวน server ได้
เมื่อข้อมูลใน Master มีการเปลี่ยนแปลง
จากนั้นจะทำ update ข้อมูลไปยัง Slave ด้วย
จะเป็นทั้งแบบ sync และ async
แน่นอนว่าจะมีเวลาที่ข้อมูลจะไม่เท่ากัน หรือ lag time
ซึ่งต้องระวังไว้ด้วย
ที่สำคัญถ้า Master ล่มลงไป จะส่งผลให้ไม่สามารถเปลี่ยนแปลงข้อมูลได้
ส่วนการอ่านยังคงทำงานได้ เพราะว่าไปที่ Slave
แต่เราสามารถ promote Slave ไปเป็น Master ได้อีกด้วย
หรืออาจจะทำ Multi-master replication ได้อีกด้วย
จะเยอะไปไหน
ยิ่งทำยิ่งซับซ้อนนะ
Federation
เป็นการแบ่ง database ตาม feature หรือกลุ่มของการทำงาน
ไม่รวมข้อมูลใน database เดียวกับแบบเยอะ ๆ หรือ monolith
ทำให้สามารถจัดเตรียม database ให้เหมาะกับข้อมูลของ feature นั้น ๆ ได้ง่ายขึ้น
ลด single point of failure และ เพิ่มการทำงานให้ดีขึ้น
แต่ระวังการแบ่งผิดด้วยละ
Sharding
อีกชื่อหนึ่งคือ การ partition data ออกไป
ทำการแบ่งข้อมูลแยกออกไปตามที่ต้องการ เช่น
- ข้อมูลแยกตามการ hash function
- ข้อมูลแยกตามทวีป ภาค ตามจังหวัด
แต่ต้องดูด้วยว่า use case การใช้งานข้อมูลเป็นอย่างไร
มิเช่นนั้น อาจจะมีการใช้ข้อมูลที่แตกต่างกัน
ทำให้บาง databaseจะใช้งานหนักหรือน้อย
รวมทั้งระวังการ rebalance data ใหม่ด้วย
จะสังเกตได้ว่าทั้ง Federation และ Sharding
เป็นวิธีการแบ่งข้อมูลขนาดใหญ่ ให้มีขนาดเล็กลง
และเหมาะสมต่อการใช้งานอีกด้วย
เพราะว่า ถ้าข้อมูลมีขนาดใหญ่มาก ๆ การ scale ก็ยากตามเช่นกัน
Denormalization
เป็นแนวคิดตรงข้ามกับ Nomalization
ที่พยายามจะเก็บข้อมูลให้มีประสิทธิภาพมากที่สุด
แต่ปัญหาตามมาคือ การดึงข้อมูลมาใช้งาน
เพราะว่ามักจะพบว่ามีการ join ข้อมูลจาก table ต่าง ๆ มากมาย
ยิ่งข้อมูลมากขึ้น table มากขึ้น
การดึงข้อมูลจะใช้เวลาและ resource จำนวนมาก
ส่งผลให้ระบบไม่สามารถรองรับผู้ใช้งานจำนวนมากได้
ดังนั้นจึงเป็นที่มาของ Denormalization
ใช้สำหรับการออกแบบการเก็บข้อมูลเพื่อการอ่าน (Design for read)
อีกอย่างถ้าข้อมูลมีจำนวนมาก ๆ
ควรต้องคัดข้อมูลให้เหลือเท่าที่จะใช้งานอีกด้วย
เพื่อลดเวลาและ resource ของการดึงข้อมูลอีกด้วย
แต่ละวิธีการนั้น เราควรต้องรู้และเข้าใจก่อน
จากนั้นกลับมาดูว่า วิธีการใดเหมาะกับปัญหาหรืองานของเรา