
ตอนเช้าเจอบทความว่าด้วยเรื่องของ Delta Lake
สะกดถูกแล้ว เพราะว่า ไม่ใช่ Data Lake นะ
อ่านเจอแล้วก็งง ๆ ว่า มันคืออะไร
เลยลองหาข้อมูล เพื่อทำให้เข้าใจมากขึ้น
สรุปสั้น ๆ ไว้ดังนี้
Delta Lake คืออะไร ?
เป็น open-source storage layer ที่จะทำงานอยู่บน existing database/data store
ไม่ว่าจะเป็น data lake, RDBMD และ NoSQL ใด ๆ ก็ตาม
เพื่อเพิ่มความสามารถอื่น ๆ ที่จำเป็นต่อการใช้งาน
ยกตัวอย่างเช่น
กลุ่มงานสาย AI และ Machine Learning เป็นต้น
รวมทั้งรองรับข้อมูลทั้งแบบ realtime, stream และ batch processing
พยายามสนับนุน ACID อีกด้วย
แต่ยังคงประสิทธิภาพของการดึงข้อมูล
โดย Delta Lake จะมี schema 2 รูปแบบคือ
- Schema-on-read
- Schema-on-write
แสดงดังรูป
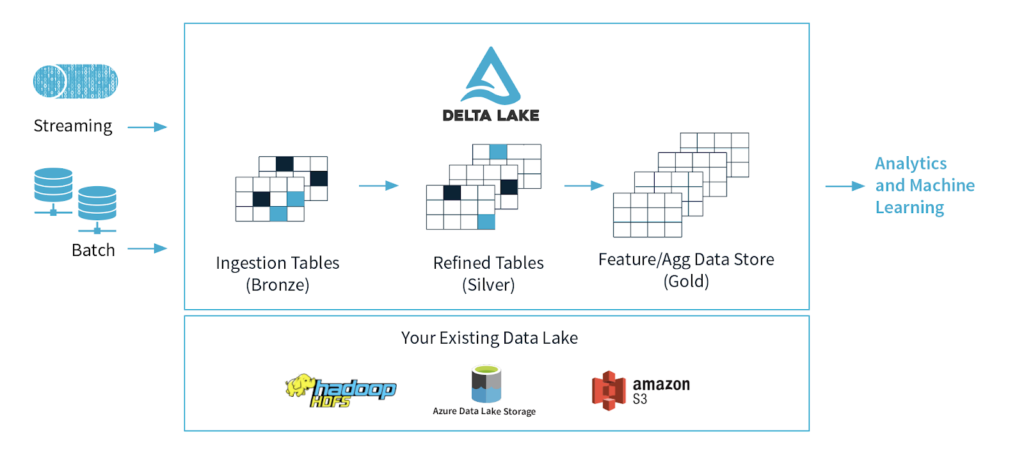
เป้าหมายของ Delta Lake มีอะไรบ้าง
ทำการตรวจสอบข้อมูลขาเข้าได้ว่า เกิดข้อผิดพลาดหรือไม่
ดังนั้นข้อมูลแต่ละตัวจะมีคุณสมบัติ Atomicity
โดยใช้หลักการของ transaction log มาช่วย
ทำให้ข้อมูลถูกต้องอยู่อย่างเสมอ
รวมทั้งเรื่องความถูกต้องของข้อมูลขาเข้า
ทั้งจาก batching และ stream ซึ่งเป็นแนวทางของ Lambda architecture เลย
เมื่อมีการเขียนทับข้อมูลเดิม (ลบและเขียน) แล้ว
แต่เกิดข้อผิดพลาดขึ้นมาข้อมูลเหล่านั้นจะไม่เห็นในการดึงหรือ query ข้อมูล
รองรับการทำงานพร้อม ๆ กันได้ดีกว่าแนวทางของการ lock หรือ optimistic lock
อีกอย่างมีการตรวจสอบ schema ของข้อมูลอีกด้วยหรือ schema validation นั่นเอง
จะทำงานก่อนจะ commit ข้อมูลนั้น ๆ
ทำให้ไม่ทำการเขียนทับข้อมูลที่มี schema ต่างกันกัน
แต่ก็สนับสนุนเรื่องของ schema evolution
นั่นคือ การเปลี่ยนแปลง schema-on-write
จะทำการ configuration เพื่อให้สามารถทำการ merge schema ได้
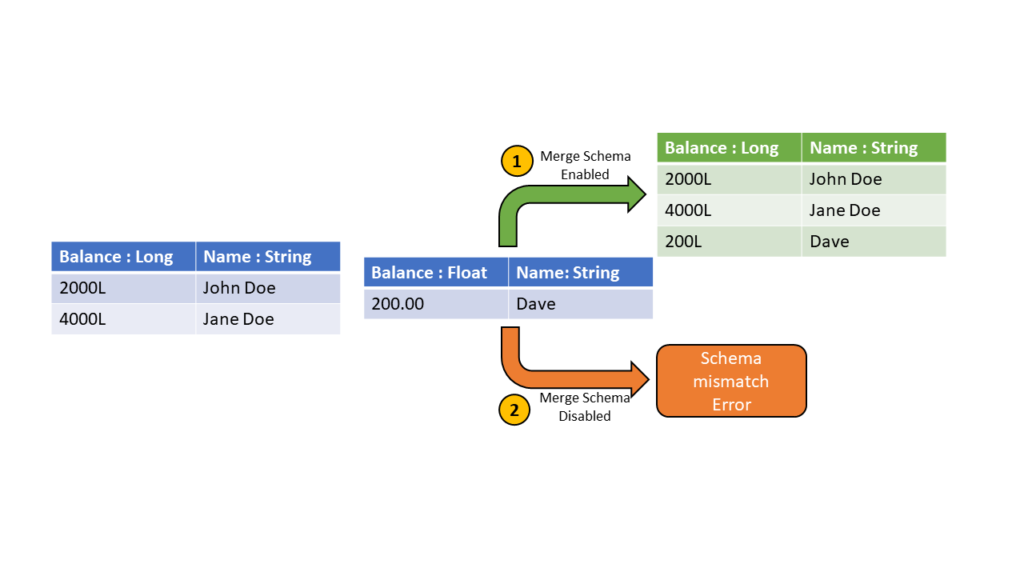
ในส่วนการจัดการ version ของ data ได้นำ Time travel เข้ามาช่วย
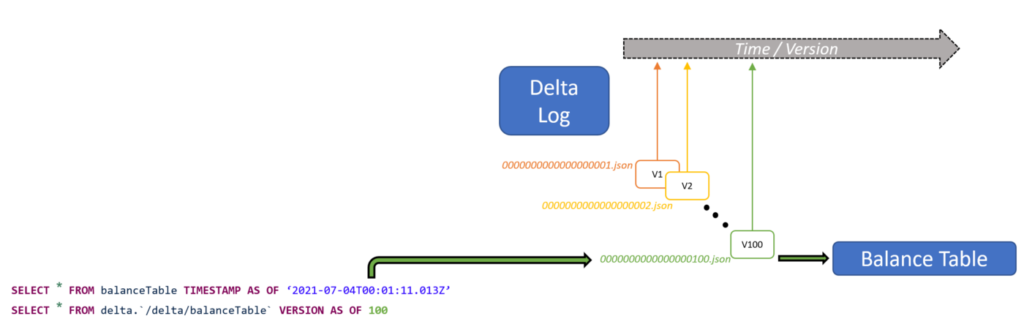
เป็นอีกแนวทางที่น่าสนใจ
ศึกษากันไว้ดูครับ
Reference Websites
https://towardsdatascience.com/why-is-delta-lake-becoming-increasingly-popular-1e45c29cc7d2