

จากบทความเรื่อง Engineering For Failure
ทำการอธิบายถึงระบบงานที่มีความซับซ้อนมากขึ้น
แต่ละส่วนงานแยกกันทำงาน
ยกตัวอย่างเช่น service, database และ caching ต่าง ๆ
แน่นอนว่า การติดต่อสื่อสารกันผ่านระบบ network
อาจจะเกิดข้อผิดพลาดในการติดต่อสื่อสารได้
ดังนั้นเป็นสิ่งที่ต้องคิดและหาวิธีการจัดการ
เมื่อเกิดข้อผิดพลาดขึ้นมา (Design for failure)
ยิ่งมีส่วนงานแยกกันทำงานมากเท่าไร
โอกาสการเกิดข้อผิดพลาดก็มากขึ้นเท่านั้น
อาจจะส่งผลให้ระบบมีปัญหา
ทั้งทำงานช้าและประสบการณ์ที่ไม่ดีต่อผู้ใช้งาน
ดังนั้นมาดูกันว่า ในบทความดังกล่าวสรุปวิธีการจัดการอย่างไรไว้บ้าง
วิธีการที่ 1 Retrying
เมื่อมีปัญหาของการส่ง request ขึ้นมา
ก็ทำการ retry หรือพยายามส่ง request นั้นไปใหม่
โดยมีการกำหนด timeout ที่เหมาะสม
สำหรับการส่ง request ต่าง ๆ
เป็นวิธีการที่มักใช้กันบ่อย ๆ
แต่การ retry นั้นก็ก่อให้เกิดจำนวน load ที่มากขึ้นเช่นกัน
ยกตัวอย่างเช่น
ในช่วงเวลาหนึ่ง ๆ มี request ที่ fail จำนวน 10,000 request
นั่นหมายความว่าจะมีการ retry ใหม่อีก 10,000 request !!!
จะทำแบบนี้ไปเรื่อย ๆ หรือไม่นะ ?
ดังนั้นแนวทางนี้อาจจะต้องมีพร้อมกับ Circuit breaker ด้วย
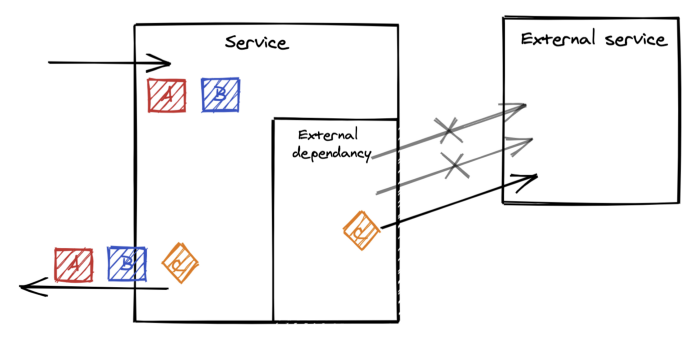
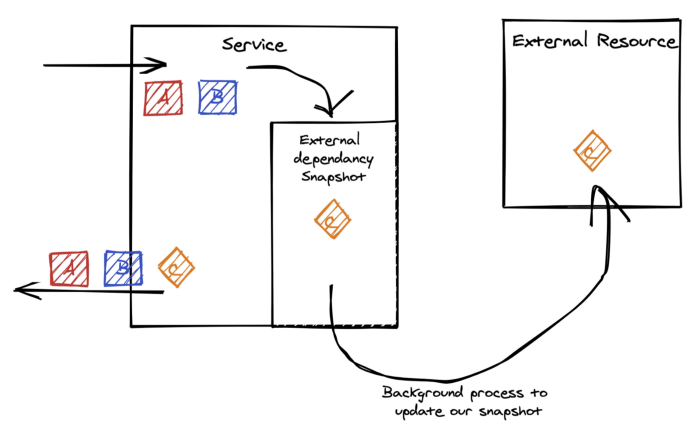
วิธีการที่ 2 Prefetching
ทำการดึงข้อมูลจากระบบปลายทางมาเก็บไว้ก่อน
โดยทำงานแบบ background process
แน่นอนว่า จะไม่กระทบต่อการทำงานหลักของระบบ
เป็นอีกวิธีการที่แยกออกไปจากการทำงานหลักไปเลย
เหมาะสมกับการดึงข้อมูลที่ไม่เปลี่ยนแปลงหรือเปลี่ยนแปลงไม่บ่อย
เป็นการดึงข้อมูลที่จะใช้งานมาไว้ก่อนล่วงหน้า
ถ้าดีหน่อย ก็พิจารณาจากพฤติกรรมการใช้งาน
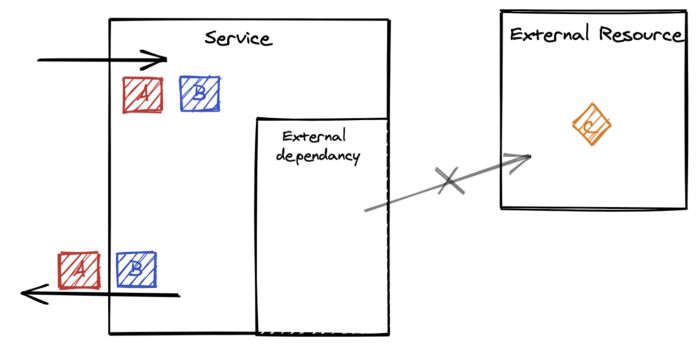
วิธีการที่ 3 Best effort
เป็นอีกวิธีการที่ เมื่อเกิดปัญหาขึ้นมาแล้วก็จะยังทำงานต่อไป
ทั้ง ๆ ที่ไม่ได้รับข้อมูลจากระบบ
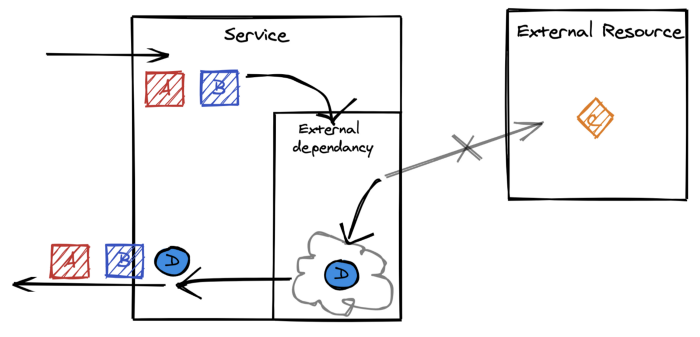
วิธีการที่ 4 Falling back to previous or estimated results
เมื่อเกิดปัญหาขึ้นมาแล้ว จะทำการนำข้อมูลหรือผลการทำงานก่อนหน้ามาใช้งาน
หรือใช้ข้อมูลที่เหมาะสมกับเหตุการณ์นั้น ๆ มาใช้งานต่อไป
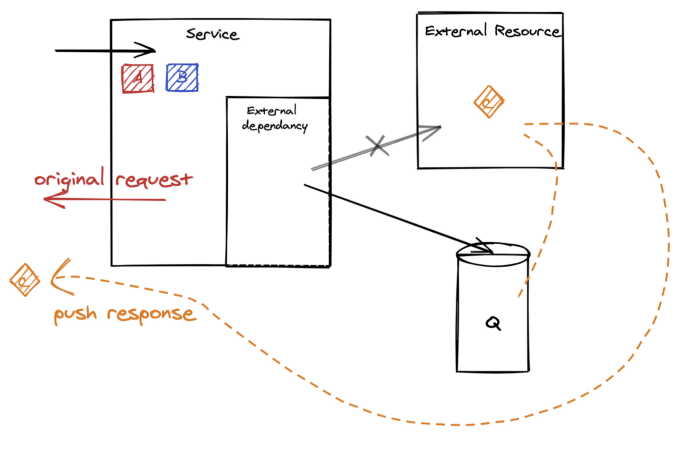
วิธีการที่ 5 Delay a response
ในบางกรณีนั้น เมื่อเกิดปัญหาแล้ว
ให้ทำการบันทึก request นั้น ๆ ไว้ใน messaging server หรือพวก queue
จากนั้นจึงทำการ process ในภายหลัง
และทำการส่งผลการทำงานนั้น ๆ กลับไปยัง consumer
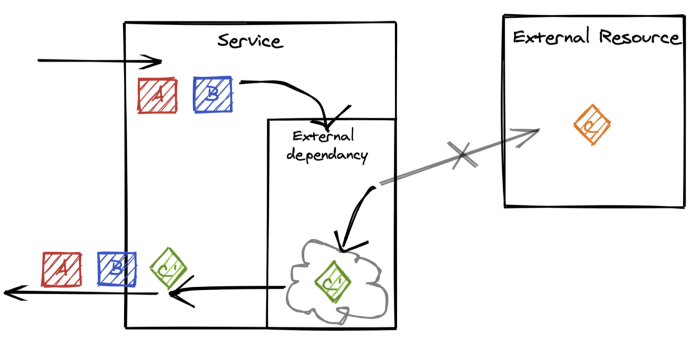
วิธีการที่ 6 Implement simplified fallback logic
ในบางครั้ง อาจจะต้องมีการพัฒนาส่วนของ logic เพิ่มเติม
ในฝั่ง consumer หรือผู้เรียกใช้งาน
อาจจะไม่เทียบเท่าของจริง แต่ยังสามารถทำงานได้
เพื่อช่วยทำให้ request ต่าง ๆ ทำงานเสร็จสมบูรณ์
นี่คือวิธีการที่น่าสนใจ สำหรับการจัดการเมื่อเกิดข้อผิดพลาดขึ้นมา
ลองนำไปใช้งานกันดูครับ
น่าจะพอมีประโยชน์บ้าง