
หลังจากมีโอกาสไปแนะนำเกี่ยวกับ SQL and NoSQL มานั้น
หนึ่งเรื่องพื้นฐานที่น่าสนใจคือการ
tuning หรือปรับปรุงการดึงข้อมูลจาก RDBMS ด้วย SQL นั่นเอง
โดยสำหรับการเริ่มต้นแล้วนั้น
มีคำแนะนำสำหรับเขียน SQL ให้ดีขึ้นดังนี้
- ใช้งาน EXISTS แทน COUNT หรือ IN ไปเลย สำหรับการตรวจสอบข้อมูลว่ามีหรือไม่
- ทำการดึงข้อมูลเท่าที่จะใช้เท่านั้น ดังนั้นหลีกเลี่ยงการใช้งาน SELECT * ไปซะ
- ใช้ SELECT DISTINCT เท่าที่จำเป็นเท่านั้น หรือไม่ใช่เลยจะดีมาก ๆ เพราะคำสั่งนี้ใช้ resource เยอะมาก ๆ
- แนะนำให้ใช้ INNER JOIN มากกว่า Cross JOIN ใน Where clause เพื่อลดปัญหาเรื่อง performance สำหรับข้อมูลขนาดใหญ่
- ลดการใช้ sub-query สำหรับข้อมูลที่เกี่ยวข้องกันลงไป ให้ไปใช้การ JOIN แทน เช่น LEFT JOIN เป็นต้น
- หลีกเลี่ยงการใช้งาน wild card สำหรับการค้นหาทั้ง prefix และ suffix พร้อมกัน เช่น %keyword% บอกเลยว่าบรรลัยแน่นอน
- ลดการใช้ HAVING สำหรับกรองข้อมูลในแต่ละกลุ่มจากการ aggregation โดยให้ไปใช้ใน Where clause แทน
- ลดการ JOIN ของข้อมูลลงไป ด้วยการออกแบบในมุมมองของการใช้งานเป็นหลัก หรือลดปัญหาด้วยการทำ pre-processing หรือ data pre-stage ไว้ก่อน สำหรับพวกการทำ report ต่าง ๆ
- ในการออกแบบก็อย่า normalize มากจนเกินไป
- การเลือก data type ของแต่ละ column ให้เหมาะสม เพราะว่า ส่วนใหญ่มักจะเผื่อ เช่นพวก char, varchar และ text เป็นต้น ต้องรู้และเข้าใจก่อนว่า ข้อมูลที่เราจะจัดเก็บเป็นอย่างไร มิเช่นนั้นแล้วมันเปลือง resource
- ระมัดระวังการใช้งาน พวก data type ชนิด nchar, nvarchar เพราะว่าจะทำการจัดเก็บข้อมูลเพิ่มเป็น 2 เท่าจากปกติ
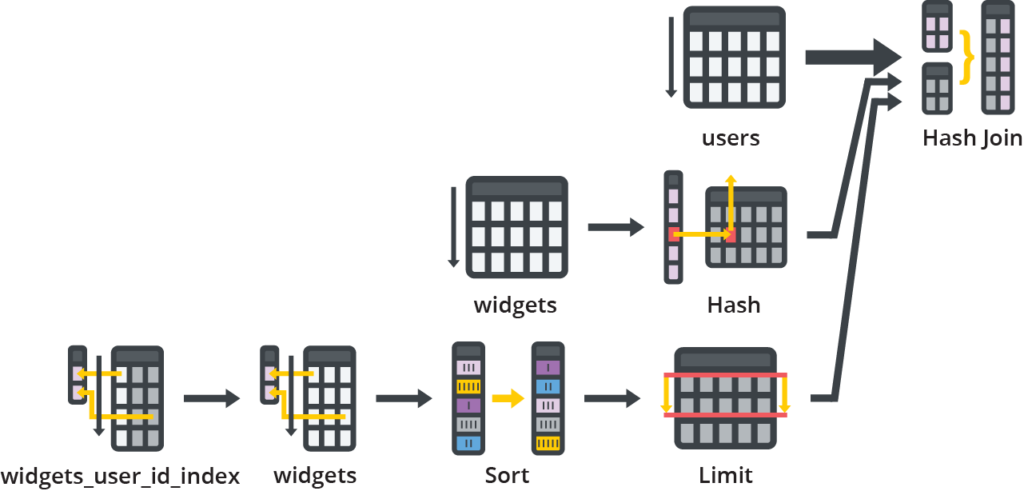
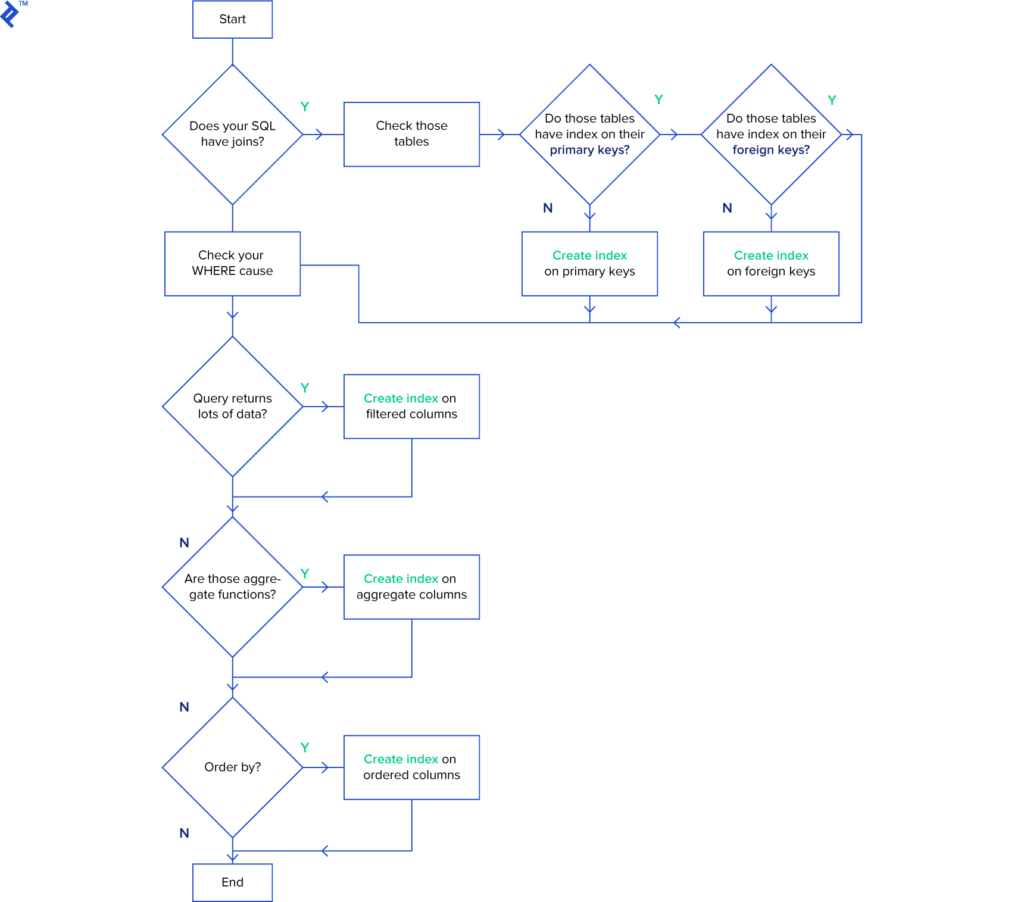
- เรื่องของ Index นั้นสำคัญมาก ๆ สร้างและต้องวัดประสิทธิภาพด้วยว่า ดีไหม ใช้เพื่อที่เยอะไหม รวมทั้งอะไรที่ไม่ได้ใช้ก็ลบไปด้วย
- ตอนที่เขียน SQL query มานั้น อย่าลืม EXPLAN query ด้วยเสมอ อย่าไปทำก่อน deploy ละ !!!
- อย่าลืมดู slow sql log และแก้ไข
เป็นคำแนะนำเล็ก ๆ น้อย ๆ
ค่อย ๆ แก้ไข ค่อย ๆ ปรับปรุง
แล้วจะดีขึ้นเองครับและอย่าลืมวัดผลด้วย