

ว่าง ๆ เลยมาลองเล่นตัว Spring WebFlux และ R2DBC (Reactive Relational Database Connectivity)
ซึ่งเป็นคู่ขวัญที่ทำงานแบบ non-blocking
นั่นหมายความว่า สามารถรองรับจำนวน concurrent user ได้เยอะขึ้น
รวมทั้งยังมีการใช้งาน CPU และ Memory ที่มีประสิทธิภาพกว่าด้วย
เมื่อเทียบกับ Spring boot + REST + JDBC/JPA ปกติ
ดังนั้นลองมาเล่นเพื่อทำความรู้จักกันหน่อย
โดยที่ Spring WebFlux น่าจะอธิบายด้วยภาพนี้
ความแตกต่างระหว่าง Reactive vs Servlet
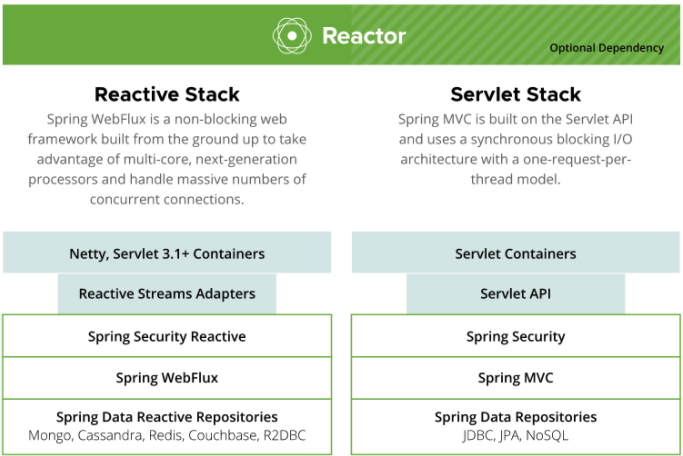
ซึ่งทำงานแบบ Non-blocking
ดังนั้นถ้ามีการเชื่อมต่อไปยัง Database ก็น่าจะเป็น Non-blocking เช่นกัน
นั่นก็คือต้องทำงานผ่าน R2DBC นั่นเอง
โดยที่มี database ไม่กี่ตัวที่สนับสนุน
หนึ่งในนั้นคือ PostgreSQL จึงเป็นที่มาของการใช้ใน blog นี้นั่นเอง
เป้าหมายของ blog นี้คือ
- เรียนรู้เริ่มต้นกับ Spring WebFlux
- ลองใช้งาน Spring Data R2DBC
เริ่มด้วยการสร้าง project จากที่เดิม คือ Spring Initializr
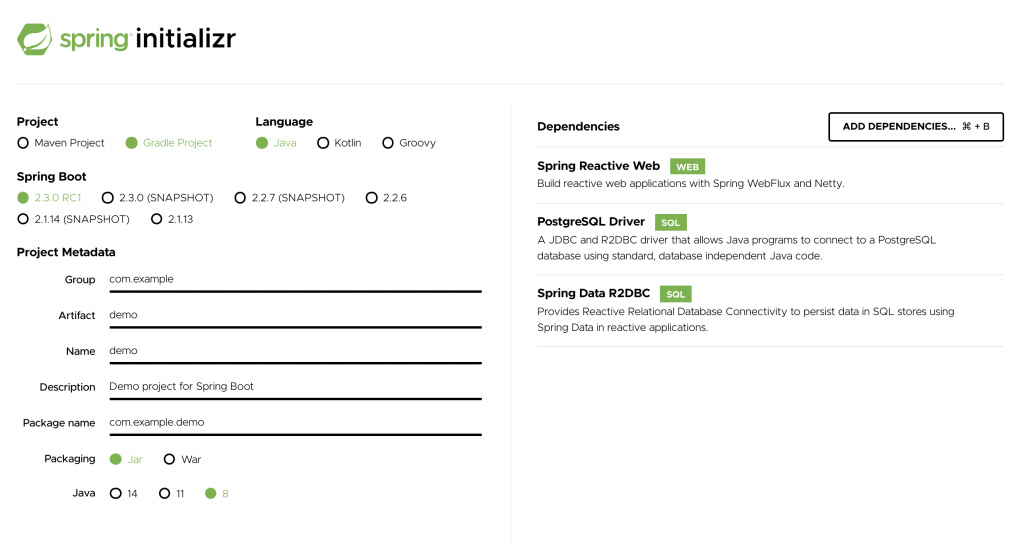
จากนั้นก็สร้าง Controller และ Repository ตามขั้นตอน
แต่เราจะใช้ Spring WebFlux + Spring Data R2DBC แทน
Code ตัวอย่างไปดูเพิ่มได้ที่ GitHub:: Up1
ตัวอย่างของ Controller ที่ใช้งาน Spring WebFlux
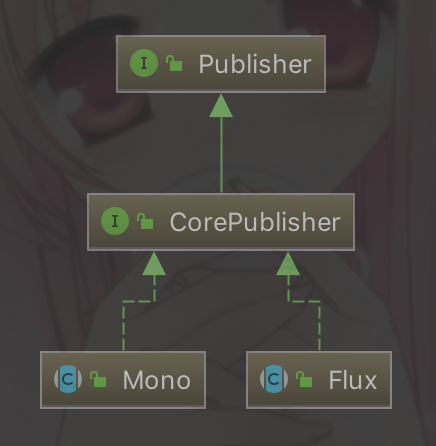
สิ่งที่เราเขียนใน Controller นั้นจะเรียกว่า Publisher
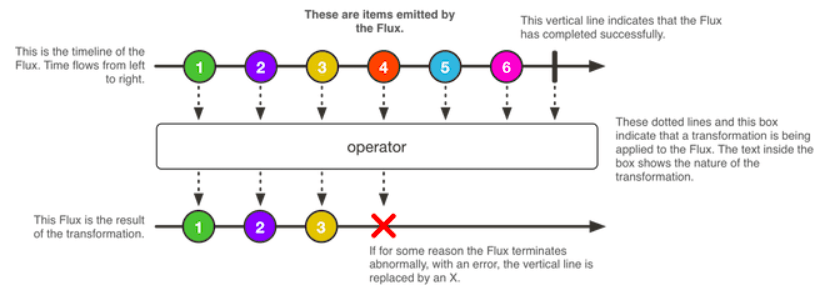
โดยจะมี implementation 2 ตัวคือ Mono กับ Flux จาก code ข้างต้น สำหรับผมจะงงว่า Mono มันต่างจาก Flux อย่างไร ? เพื่อให้เข้าใจง่าย ๆ คือ
- Mono สำหรับการ return ข้อมูล 0 หรือ 1 อย่าง
- Flux สำหรับการ return ข้อมูล 0 หรือ มากกว่า 1 อย่าง เช่นพวก List อะไรพวกนี้
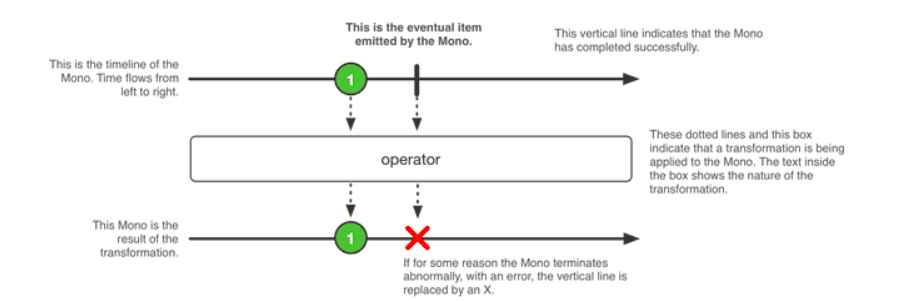
1. Mono
2. Flux
จากนั้นลองทำการ run
พบว่า start ได้แม้ยังไม่ได้ทำการ start database server !!
เพียงเท่านี้ก็ใช้งานได้แบบง่าย ๆ แล้ว
สุดท้ายมาดูผลการทำงานหน่อย
- R2DBC นั้นมี database ที่รองรับไม่เยอะ ตัวอย่างที่ใช้งานคือ PostgreSQL
- ใน Spring Data Reactive ทำงานกับ Spring WebFlux ได้เลย คือ MongoDB, Redis, Cassandra และ Couchbase เป็นต้น
- ที่สำคัญ JDK มี Loom project ที่น่าจะมาใน JDK 15 นั้นมี Java Fibers อาจจะทำให้อนาคตของ R2DBC เปลี่ยนไปก็ได้
- R2DBC ยังไม่สามารถทำงานร่วมกับ JPA ได้ จึงมี Spring Data R2DBC ให้ใช้งาน
- การทำงานของ Spring WebFlux + R2DBC จะทำงานได้ดี ใช้ resource มีประสิทธิภาพเมื่อจำนวน concurrent สูง จากการทดสอบจะแตกต่างเมื่อมี concurrent 200 ขึ้นไป ทั้ง response time, CPU/memory usage